Zaragoza. Primera Edición. 2022
La desertificación se produce por la degradación de la tierra que se da en zonas secas: áridas, semiáridas y subhúmedas secas. La actividad humana y las variaciones climáticas están entre las causas de esta degradación del suelo, que impacta en los ecosistemas y en los recursos y modos de vida de los habitantes de las zonas afectadas. Estas zonas secas son aquellas con un índice de aridez (IA=P/ETP) inferior a 0,65.
España es uno de los territorios que sufre esta problemática. En Aragón el 75% del territorio está en riesgo de desertización. El cambio climático y el incremento de las temperaturas amenazan las tierras semiáridas que predominan en el Valle del Ebro, desde la ciudad de Huesca hacia el sur. Identificar a tiempo estas zonas será de gran ayuda para el apoyo a la toma de acciones que permitirán mitigar el impacto que la desertificación trae sobre la seguridad alimentaria así como la reducción de la pérdida de hábitats naturales y biodiversidad, todo esto, alineado con los Objetivos de Desarrollo Sostenible de Naciones Unidas.

Para identificar estas zonas se propone un proceso que gestione el reconocimiento mediante imágenes satelitales de las zonas de desertificación en Aragón y permita realizar una aproximación a la predicción de posibles futuras zonas desérticas con el objetivo de aplicar políticas más eficientes referentes a la reforestación de las zonas afectadas, y nuevos tratamientos de cultivos. Con apoyo de la iniciativa Saturdays.AI Zaragoza, cuyo objetivo es acercar la IA a todos los ciudadanos y aplicarla a problemas sociales, queremos dar solución o una aproximación a resolver este escenario que nos hemos planteado como equipo de trabajo.
Es entonces, cuando nos planteamos las siguientes inquietudes, ¿Cómo es posible calcular si hay o no desertificación en una zona determinada?, ¿qué imágenes pueden funcionar para este propósito?, ¿Cómo la IA nos puede apoyar para predecir estos valores? A lo largo de este artículo intentaremos dar solución a estas cuestiones.
Imágenes Satelitales
Las herramientas de teledetección hacen posible la visualización y cálculo de cambios que ocurren sobre la superficie terrestre, aquellas que nos interesan, los que corresponden a la teledetección pasiva (Definición de Teledetección), en nuestro caso concreto, captan la radiación solar reflejada por la superficie. Es bien sabido que organismos vivos reflejan y absorben radiación solar en forma diferente a como lo hacen los objetos inertes como calles o edificios. Aprovechando este principio, los satélites generan imágenes que contienen estas diferencias en forma de Niveles Digitales y bandas, que se traducen en unidades numéricas que se corresponden con los valores de longitudes de onda de las diferentes secciones del espectro electromagnético (Espectro electromagnético y teledetección). En resumen, miden la radiación reflejada por objetos como edificios o autopistas o entes vivos como bosques o vegetación en general.
Índice de vegetación NDVI
Los cambios en la vegetación con el soporte de las imágenes satelitales se pueden medir de diferentes formas, una de ellas es extrayendo índices de vegetación, “Los Índices de Vegetación son combinaciones de las bandas espectrales registradas por los satélites de Teledetección” (¿Cuál es el índice de Vegetación NDVI?) que permiten identificar vegetación sobre la superficie terrestre. Es allí,con ayuda de estos índices en donde se resaltan y se pueden analizar numéricamente las propiedades de la vegetación como tal.
El NDVI es el Índice de Vegetación Diferencial Normalizado, NDVI por sus siglas en inglés. Este índice es un parámetro calculado que se basa en los valores capturados por el instrumento satelital donde identifica patrones del espectro electromagnético que se corresponden con la reflectividad de coberturas vegetales. Este índice permite ayudar a distinguir fácilmente vegetación en imágenes satelitales.
Los patrones del espectro electromagnético para identificar la vegetación muestran que la vegetación absorbe la sección de radiación solar que corresponde al rojo. A su vez se reflejan valores elevados en el infrarrojo cercano y podremos identificar valores multiespectrales brillantes en esta banda ( Valores Espectrales del NDVI).
Así podemos diferenciar cubiertas vegetales en diferentes estados. Nuestro índice podrá ser obtenido mediante la siguiente relación:
NDVI = (Banda infrarroja cercana — Banda roja) / (Banda infrarroja cercana + Banda roja)
O lo que es lo mismo, y en términos de nomenclatura cuando trabajamos las bandas multiespectrales:
NDVI = (NIR — RED) / (NIR + RED)
Una vez se ha calculado el índice para cada uno de los píxeles de la imagen, los valores posibles oscilan entre -1 y 1.
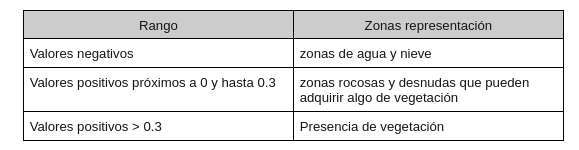
Cuanto mayor sea el valor más frondosa será la vegetación hasta adquirir valores próximos a 1.
Manipulando la imagen
Para comprender mejor cómo podemos usar estos valores entre bandas y niveles digitales, es importante identificar las propiedades de una imagen en general y cómo se ven estos valores a nivel de computación.
El ordenador o los métodos de computación, estructuran las imágenes en matrices con valores (i,j) estos valores (i,j) representan numéricamente el valor en términos computacionales de dicha coordenada sobre la imagen original (sin digitalizar). Cada uno de estos valores es lo que se denomina “pixel”
Para imágenes satelitales ocurre algo similar,la única diferencia radica en los valores para cada píxel, en este caso representan en niveles digitales para valores de reflectancia de radiación solar (espectro electromagnético) reflejada por el objeto terrestre sobre el cual el instrumento (el satélite) está midiendo.
Obtención y preparación de datos
Obtención
Ya que se hará un análisis sobre cambios en la superficie terrestre, las imágenes satelitales que se eligieron fueron del instrumento Sentinel 2A. Para la obtención de datos usamos la librería de Python SentinelSat para la descarga de imágenes en el área que nos interesa. Es de anotar que las imágenes se han tomado con los siguientes condicionantes: para un área específica detallada en un fichero .json, para la misma tesela (zona de captura de imagen del satélite) y sección de órbita para garantizar que se está tomando la misma zona de estudio para diferentes momentos de tiempo.
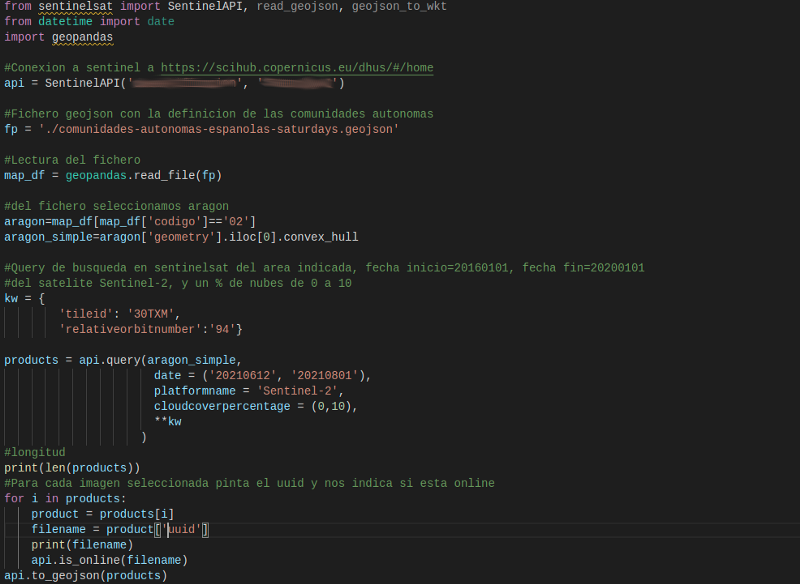
NOTA: Para la obtención y captura de los datos se han descargado las imágenes de Sentinel con un porcentaje de nubes máximo de 10%.
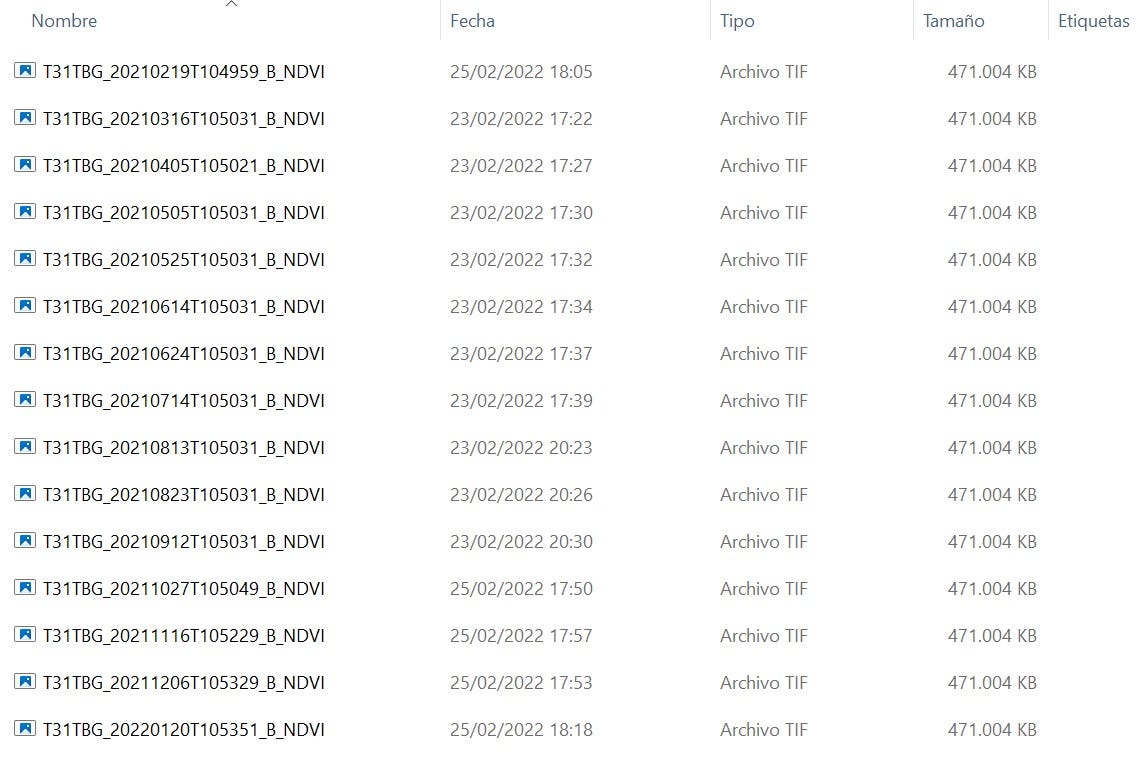
Una vez ejecutado el script para la descarga de imágenes del satélite, se descarga una serie de ficheros zip que contienen cada uno la siguiente estructura al momento de descomprimirlos:
Cada una de las imágenes Sentinel vienen dadas con un consecutivo de nombre de imagen con la siguiente estructura:
MS2_MSILLL_YYYYMMDD
Donde:
- MS2: identifica la misión de Sentinel 2, pudiendo encontrar S2A (para Sentinel 2A) o S2B (para Sentinel 2B)
- MSI: indica el instrumento de operación (MultiSpectral instrument)
- LLL: indica el nivel de procesado del producto pudiendo encontrar los niveles L0, L1C, L1B o L2A
- YYYY: designa el momento temporal UTC (año) en el que fue tomada la imagen
- MM: designa el momento temporal UTC (mes) en el que fue tomada la imagen
- DD: designa el momento temporal UTC (día) en el que fue tomada la imagen
Las descargas de Sentinel para el proyecto fueron:
Preparación
Una vez obtenidas las imágenes, sobre ellas calcularemos los índices NDVI mediante Script en Python.
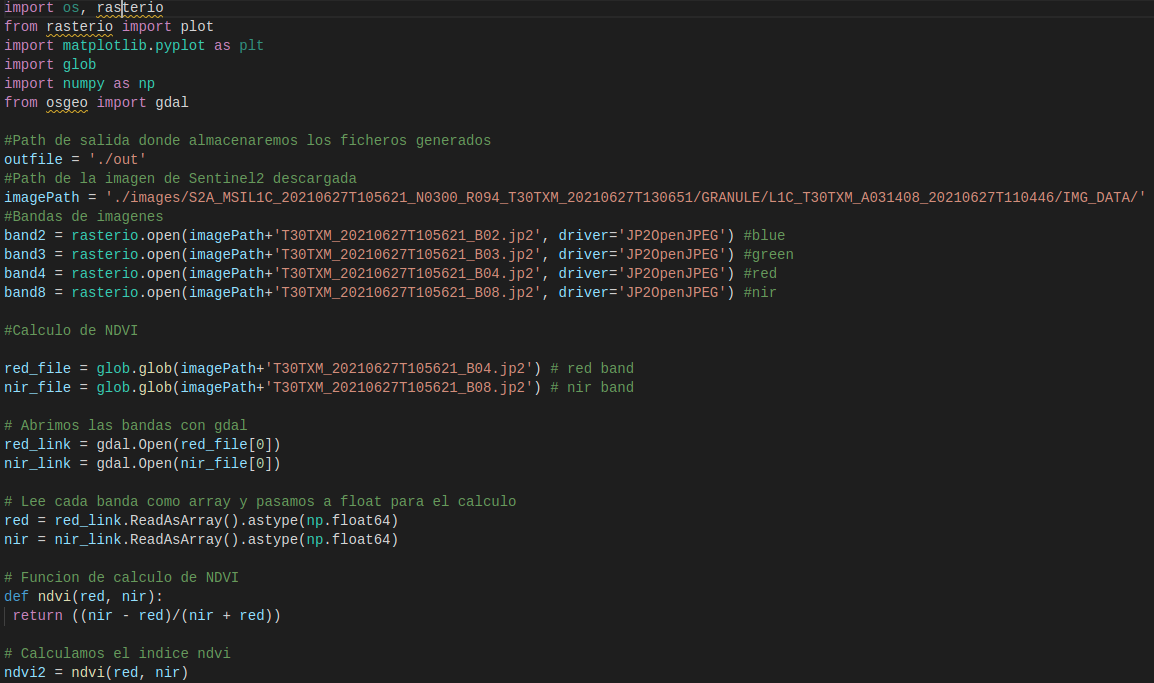
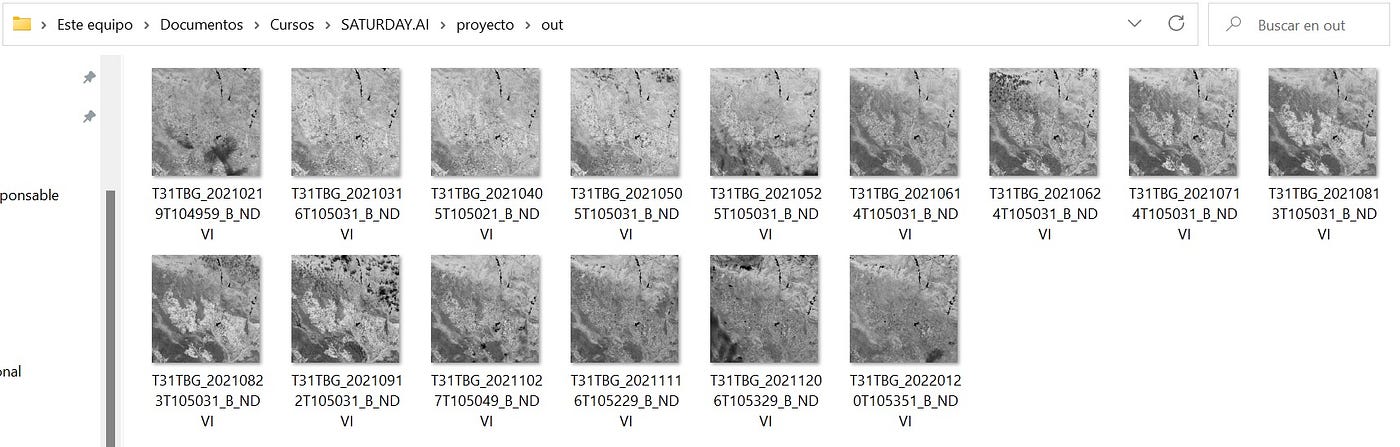
Para entender la salida de este script, las imágenes con el NDVI calculado (nuevos ficheros tif), se debe tener en cuenta que esta transformación imágenes nos da lugar a una imagen compuesta por una matriz de valores donde cada valor corresponde a un pixel (representación en la imagen) y este valor oscila entre -1 y 1. Recordando el apartado de Índice de Vegetación, a partir de 0.3 entendemos que hay vegetación para ese píxel (valor de matriz).
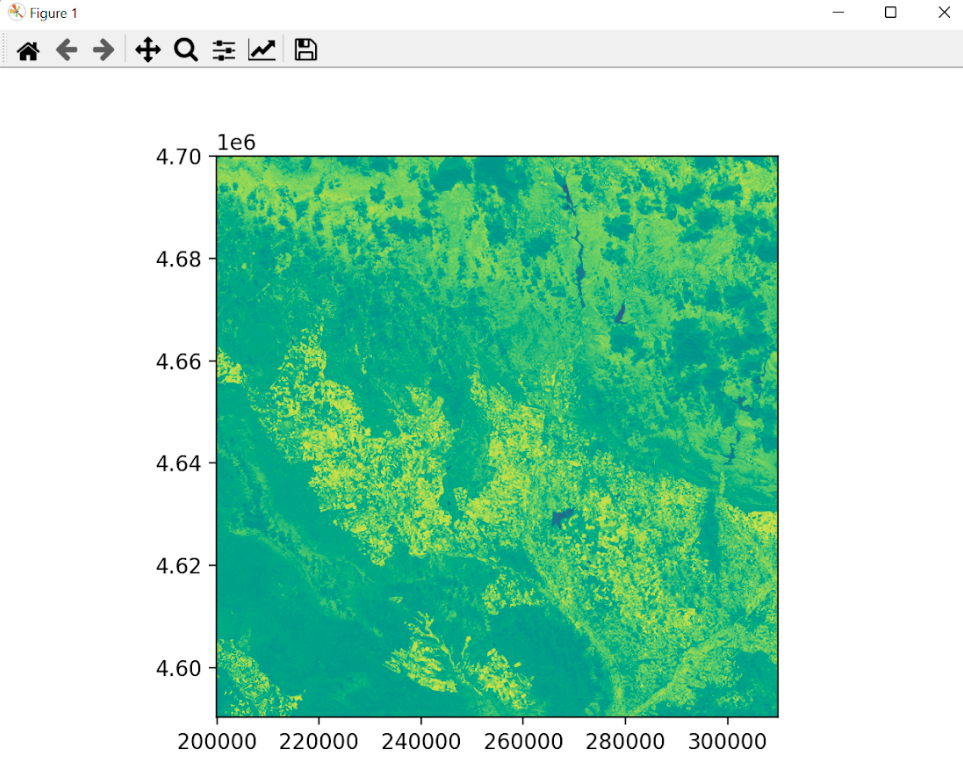
¿Y la predicción de valores de desertificación?
Ya estamos en el punto en donde, hemos identificado la zona sobre la que trabajaremos, hemos hallado los índices de vegetación para estas zonas en diferentes momentos de tiempo, ahora continuaremos con el establecimiento de una relación entre los valores medidos y cómo estos cambian en el tiempo (nuestra variable continua) para anticipar un conjunto de nuevos valores.
Deseamos construir un modelo que describa la relación entre las variables de estudio, con el fin, principalmente, de predecir los valores de una variable a partir de los valores de la otra. Elegiremos Random Forest Regressor ya que tenemos un conjunto de valores numéricos que hemos considerado como categorías (cada imagen con su matriz específica) y luego promediamos la salida de cada árbol de decisión usando este algoritmo ( Definición de Random Forest regressor. Material Saturdays AI. Zaragoza. Edición I. 2021–2022. Sesión Regresores).
Como este es un modelo de Machine Learning Supervisado, tomaremos las imágenes con el NDVI calculado, solo una zona de las misma para el aprendizaje del modelo y la zona siguiente de las imágenes para la predicción futura de índices NDVI.
Evaluación
Entrenamiento
Para el entrenamiento del algoritmo, se tomaron 5 imágenes con NDVI calculado y una imagen adicional como salida conocida. De cada una de las imágenes se ha elegido un subset de igual tamaño para añadirlos a un vector en Python. Lo anterior se realiza por capacidad de procesamiento de las máquinas disponibles, las imágenes originales tienen dimensiones de 10.000×10.000 píxeles que no es posible procesar de forma ágil y eficiente con los recursos disponibles en el grupo de trabajo.
Nota Aclaratoria: Cada imagen de NDVI calculado tiene un tamaño de 470MB aproximadamente, por lo que 6 de ellas nos da un estimado de 2,8GB para hacer el procesamiento de este dataset.
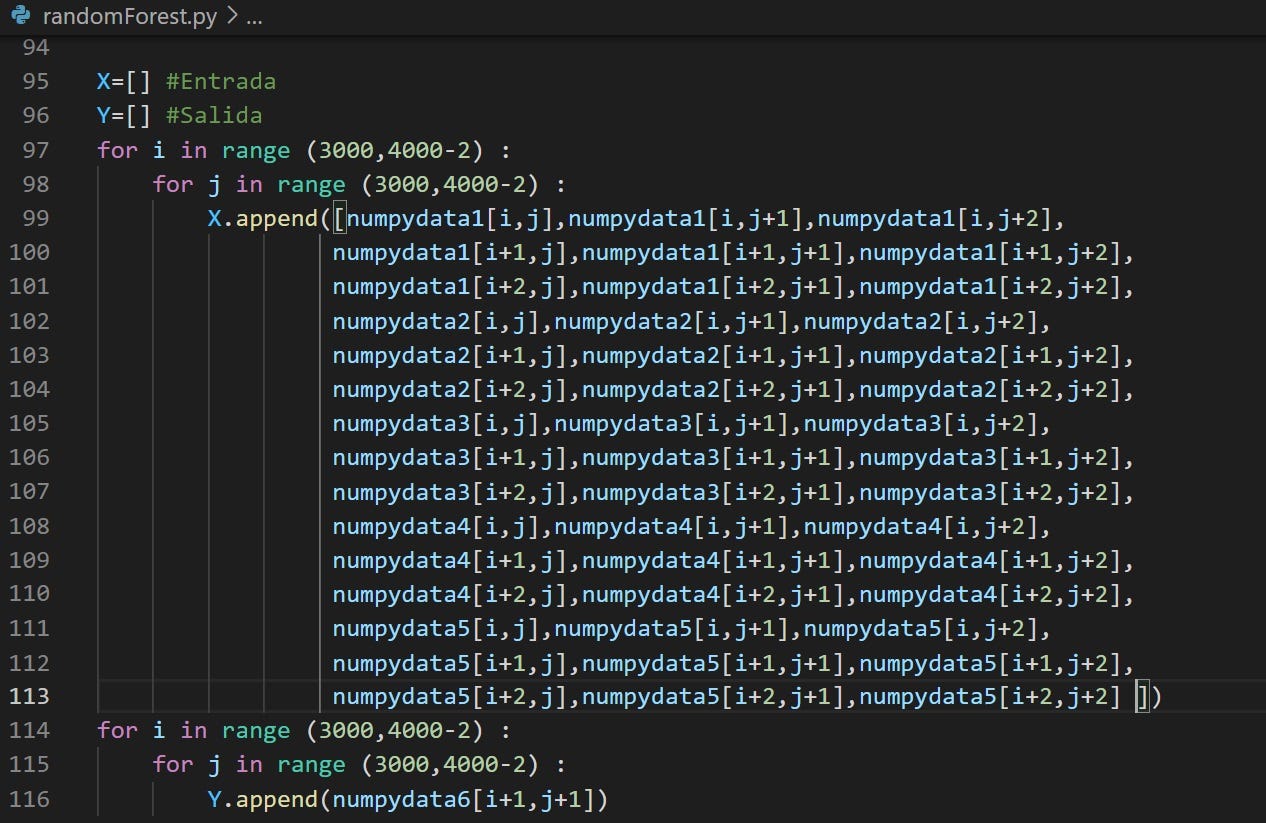
Con ayuda de la librería sklearn establecemos un set de entrenamiento para el algoritmo con el que poder “enseñarle” cómo puede intentar predecir los siguientes valores y ejecutar la siguiente fase de prueba (testing).
Prueba
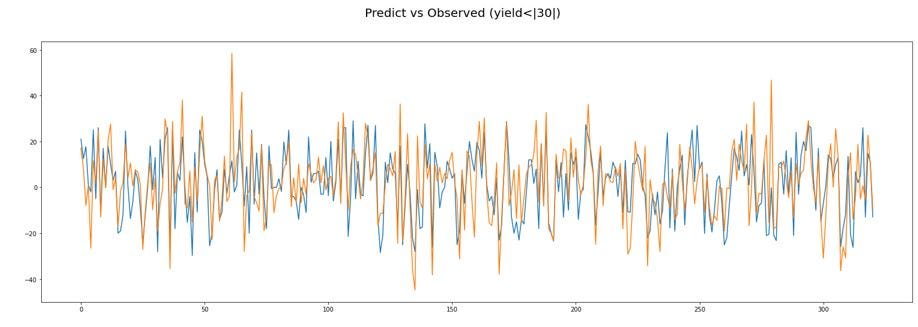
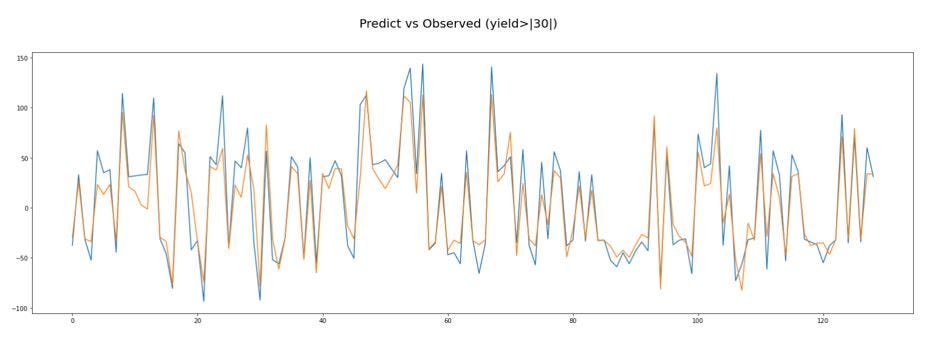
Para probar el algoritmo, se tomaron las mismas 5imágenes con el NDVI calculado pero esta vez, el subset elegido corresponde a otra porción de la imagen. En el entrenamiento hemos elegido una sección, para la prueba (test) elegimos una sección distinta.
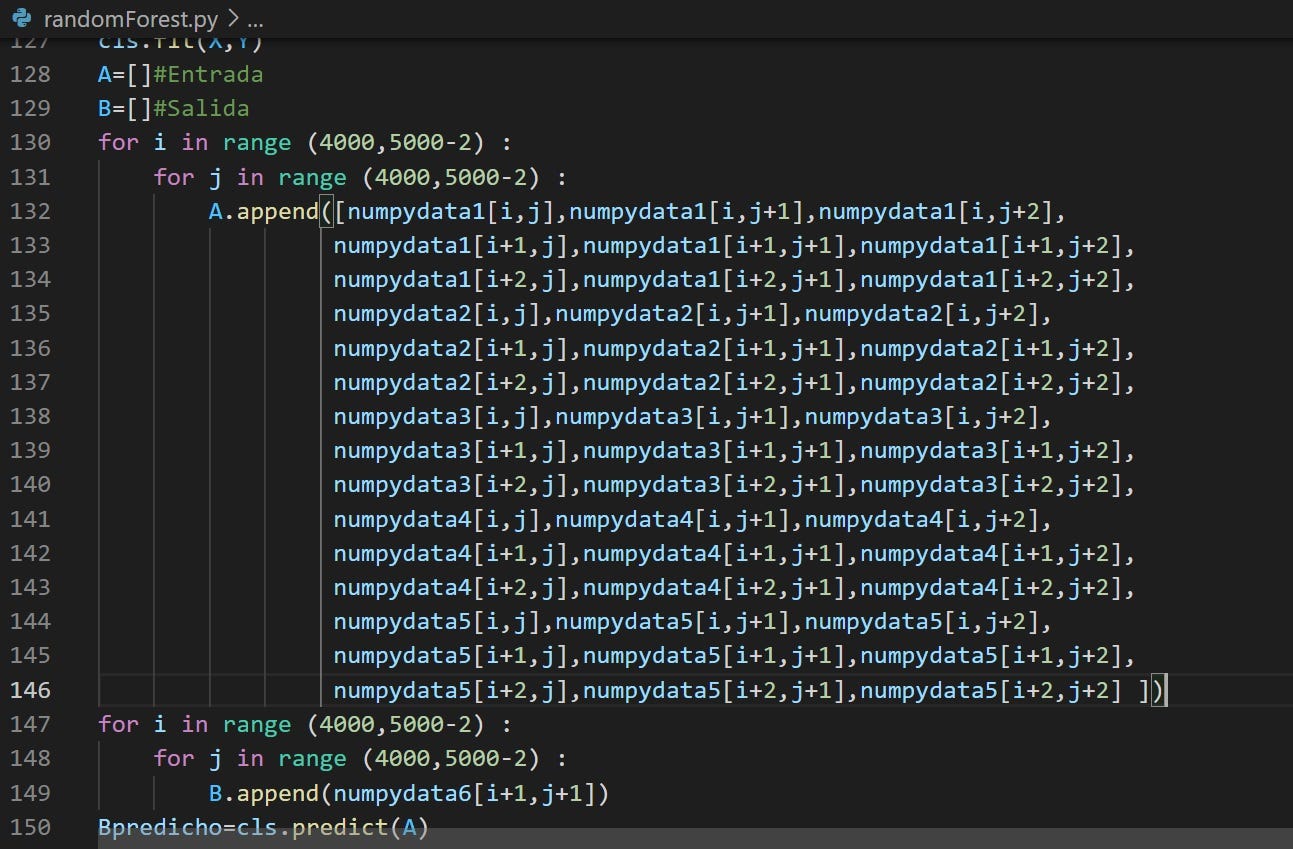
El margen de error para la imagen predicha es el siguiente:

Es necesario saber si el algoritmo es capaz de predecir correctamente una imagen. Utilizaremos una imagen que ya se tiene para validar la efectividad del algoritmo a la hora de predecir el resultado.
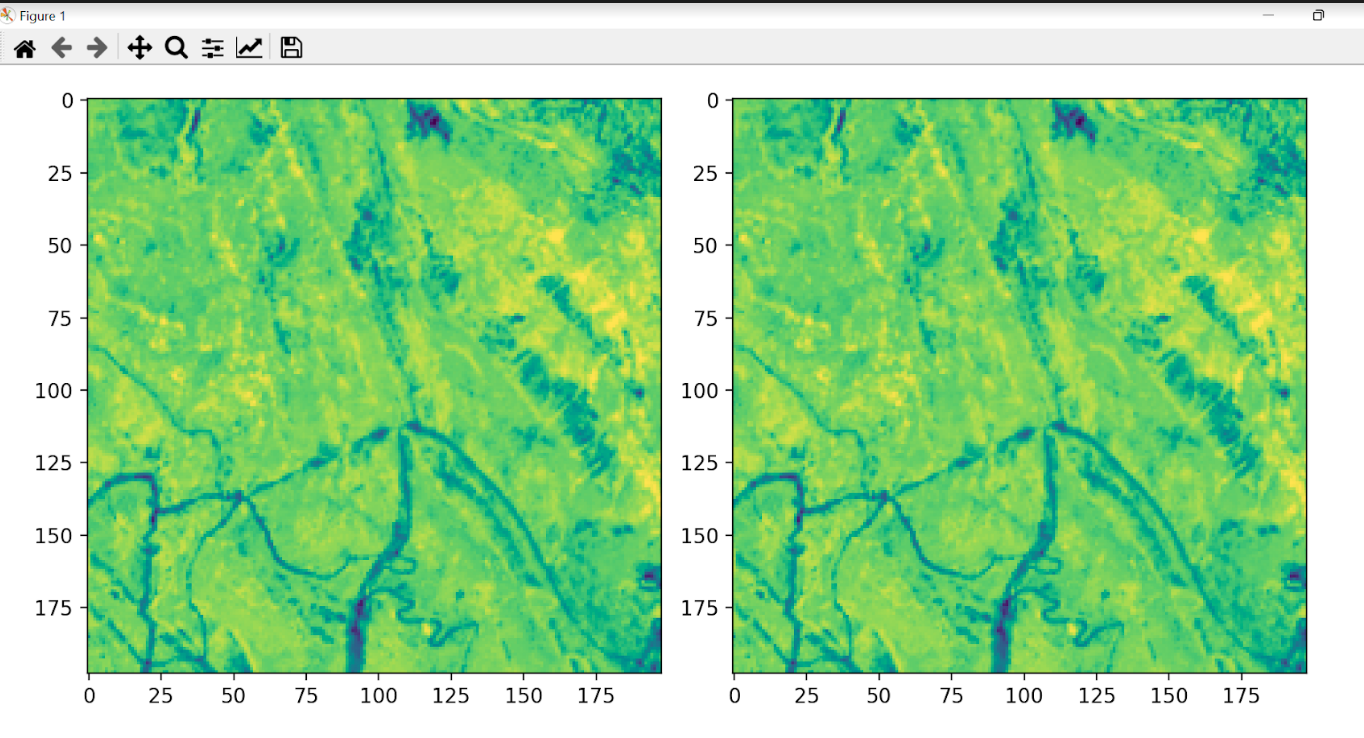
Visualización en Streamlit
En la página desertIAragon se encuentra desplegada la aplicación de Streamlit para visualizar los cambios en NDVI calculados
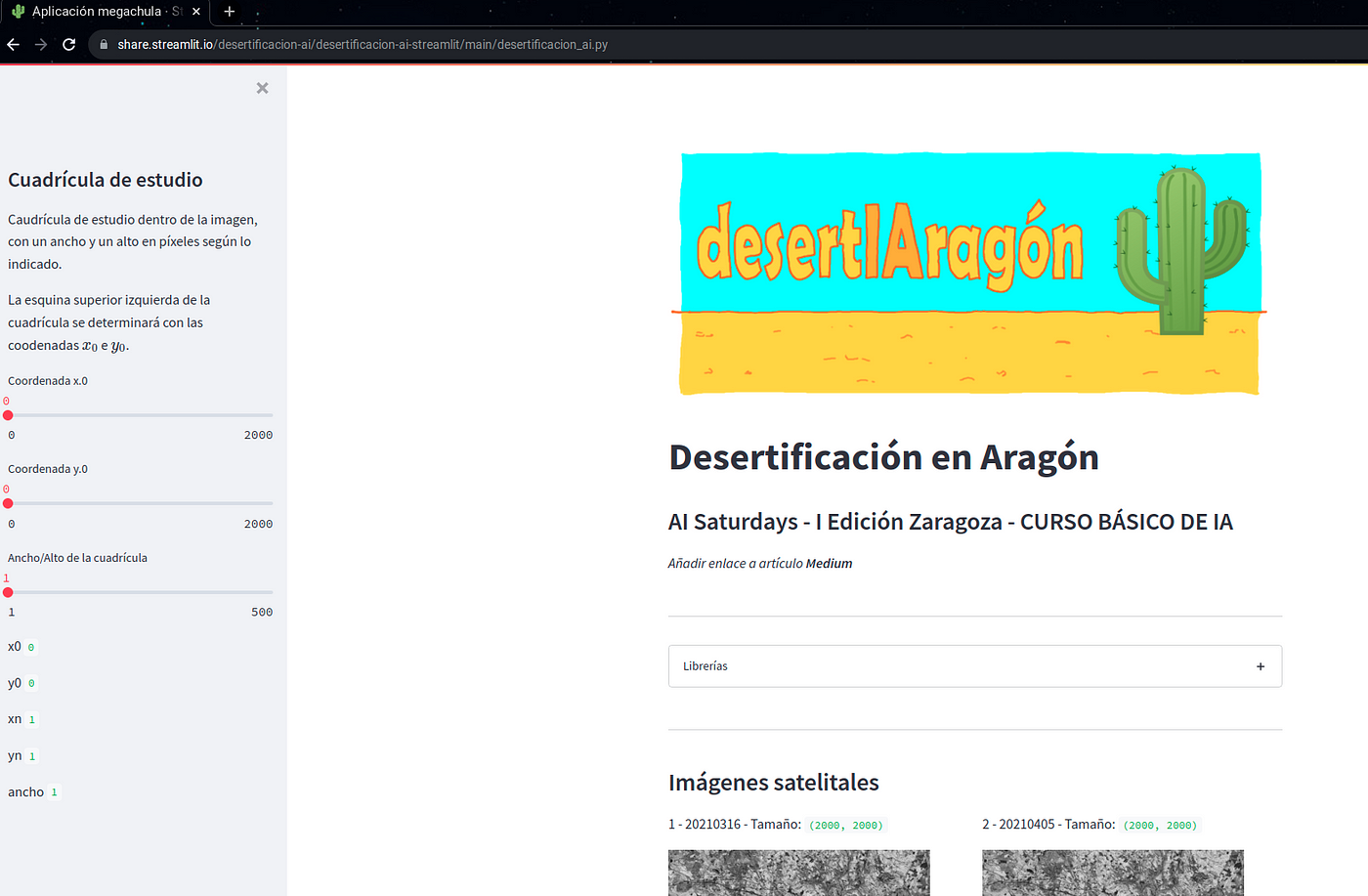
En la sección Imágenes Satelitales, encontramos un subset de 2000×2000 píxeles de las imágenes extraídas del sitio web de Sentinel:

La sección de cuadrículas de estudio, nos permite elegir la coordenada deseada para mostrar los cambios en el NDVI calculado y sus valores. Elegir la coordenada en las opciones disponibles en el panel izquierdo:


Predicción
El sistema se entrena con una porción igual de cada una de las imágenes 1 a 5. Esta porción es un recuadro de coordenadas aleatorias y dimensiones igual al ancho/alto de la cuadrícula indicado en la banda lateral (en Streamlit).
La razón de elegir un recuadro reducido es el elevado coste computacional que tiene el entrenamiento del sistema. Este coste puede estar rondando aproximadamente 5 minutos de procesamiento para un fragmento inferior a 250 píxeles de dimensión, en un ordenador con una RAM de 8GB y un procesador: Intel Core I5 2,67 Ghz.
De esta forma la aplicación puede mostrar unos resultados de una forma relativamente ágil. Para el test se ha elegido las imágenes de las cuadrículas 1 a 5 con las que se ha obtenido el índice NDVI.
La predicción se hace con la cuadrícula 6. Se compara la imagen original con la predicha por la IA.
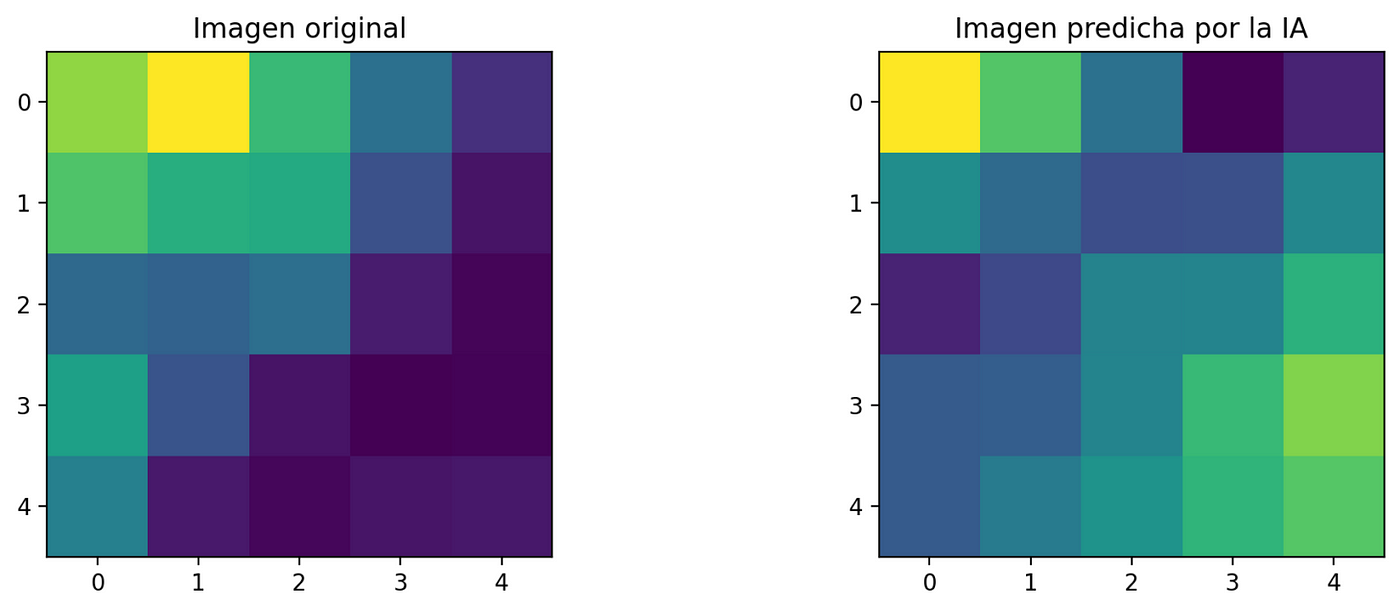
Datos generales de las imágenes:
Coordenadas de la esquina superior izquierda: i_0i0 * j_0j0 = 0 * 0 px Coordenadas de la esquina superior derecha: i_nin * j_njn = 5 * 5 px
Error cuadrático promedio: 0.03719
Conclusiones
- Existe software propietario como ERDAS para facilitar el cálculo de NDVI y algoritmos de regresión para predecir comportamientos, sin embargo, alineados con los principios de Saturdays.AI: acercar la IA a todos los ciudadanos y aplicarla a problemas sociales, hemos optado por una solución basada en herramientas de código abierto y disponibles para todo público.
- Este proyecto tiene la potencialidad de explorar como una fase siguiente la capacidad de procesamiento de datos para imágenes de dimensiones más grandes, ya sea en resolución espacial o temporal, de forma más eficiente en la nube. Tomando ventajas como procesamiento en paralelo o distribuido se podrán añadir más entradas al algoritmo y procesamientos más complejos que no se pueden suplir con los recursos actuales
- La desertificación sobre las zonas evaluadas se puede predecir de forma eficiente, con un margen de error bastante reducido para la primera fase de evaluación. A nivel numérico es posible establecer dónde la vegetación se ha ido perdiendo a lo largo del tiempo y predecir sus valores futuros para tomar acciones a tiempo sobre estas zonas y evitar así, nuevas zonas de desertificación.
Integrantes del proyecto
Presentación del proyecto: Demoday
Repositorio
Se puede encontrar el código de este proyecto en GitHub
Adicionalmente, el código de visualización se puede encontrar en : GitHub Streamlit
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!