La Paz. Deep Learning. 2021
Durante la última década, la explosión de la cantidad de datos disponibles, la optimización de algoritmos y la evolución constante de la potencia informática han permitido que la inteligencia artificial (IA) realice cada vez más tareas humanas [1]. Y desde hace un tiempo la inteligencia artificial se ha convertido en una poderosa herramienta para devolvernos al pasado. Lo demuestran la cada vez mayor cantidad de imágenes y videos restaurados a través de diferentes técnicas de inteligencia artificial, como por ejemplo la capacidad de colorear videos en blanco y negro.
En términos de coloración de imágenes y videos la Inteligencia artificial ha evolucionado y durante los últimos años se ha observado una mejora significativa. Ya que la coloración manual requiere una gran cantidad de tiempo y es un proceso costoso, la aplicación de técnicas de inteligencia artificial es una gran opción para este tipo de tareas porque es capaz de trabajar por sí misma y colorear automáticamente en un corto periodo de tiempo [2].
Problemática
Existen pocos registros filmográficos que capturen la vida cotidiana de antaño de nuestro país es por ello que quisimos tener otra perspectiva de estos videos añadiendo color a los pocos que encontramos.
Objetivo
Extraer imágenes de videos antiguos para darles color haciendo uso de una red GAN, para posteriormente generar un video a color.
Dataset
El dataset se pudo obtener a partir de videos encontrados en youtube, de tipo documental y grabaciones de los distintos paisajes de Bolivia, se usaron 10 videos distintos ya que se tienen videos antiguos a color, que tienen un color más opaco, otros videos de los paisajes con un color más definido pero con una calidad no mayor a 480p, y otro con una calidad mayor. No se tomaron todos los frames de estos ya que se optó por usar los frames significativos y asi no tener varios frames de una misma escena.





Selección del modelo y técnicas usadas
La arquitectura usada para colorear mediante Inteligencia Artificial fue la de Unet-GAN por su gran capacidad para sintetizar las características de las imágenes lo que mejora ampliamente los resultados finales.
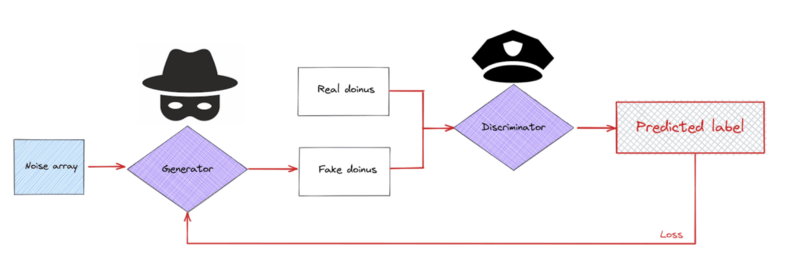
Una red generativa antagonica (GAN) tiene dos redes. Una es el discriminador que intentará discriminar entre imágenes reales y falsas. Y la segunda red de la GAN es el generador que se encargará de generar imágenes falsas pero muy cercanas a las imágenes originales más bien podemos decir que las imágenes falsas estarán en la misma distribución de las imágenes originales.
UNET se utiliza básicamente en problemas de segmentación de imágenes donde las dimensiones de entrada y salida son las mismas. GAN intenta generar nuevas imágenes a partir de un ruido aleatorio. Entonces, el generador de GAN tiene muy pocas dimensiones en la entrada, pero la salida es en gran dimensión. Puede usar UNET como generador en el GAN (pix2pix usa esto).
En este caso, generará imágenes falsas no a partir de ruido aleatorio sino de otra imagen de referencia. Tiene otras opciones como red deconvolución, codificador automático, etc.
Al inicio se realizó la obtención de videos, se segmentó los videos en frames que se usaron como ground truths, se estandarizó las imágenes a un tamaño y se hizo la conversión de los frames RGB a grayscale para usarlos como inputs. Al finalizar con el proceso de colorización se unió los frames resultantes para convertirlos de nuevo en video.
Análisis de resultados
En la gráfica 1 podemos observar la pérdida del discriminador y la del generador y se puede ver que existe una tendencia exponencial y que la pérdida es estacionaria en el valor 0.4 para el discriminador y 0 para el generador.
Se puede apreciar en las imágenes de entrenamiento con 600 épocas que se llega a tener un color correcto, pero no tan intenso como en las imágenes RGB reales, también se puede ver que llega a tener errores cuando se tiene una sección con mayor brillo en la imagen, como ser rayos del sol o secciones de blanco.
Con las imágenes de testeo se puede ver que las imágenes se llegan a colorear pero se sigue teniendo el problema con las secciones de brillo y que tiene una mayor predisposición a la gama de rojos y azules.
En las imagenes del video en blanco y negro elegido para poner a prueba nuestro modelo se tiene una buena coloracion siendo que al ser una grabacion de la ciudad de La Paz-Bolivia se tiene más imagenes de edificios no se necesita tener una gran variedad de colores, el color más intenso que se ve es en el cielo.
Conclusión y recomendaciones
Se logró implementar un modelo con arquitectura Unet-GAN capaz de colorear imágenes en blanco y negro y con el conjunto de las imagenes coloreadas se obtuvo un video a color, todo este proceso nos permitio familiarizarnos con modelos de Inteligencia Artificial del tipo Deep Unsupervised Learning, preparación de datasets, lenguaje Python, librerias especializadas en Deep learning y Colab como herramienta para la implementacion de nuestro modelo. Los resultados son aceptables sin embargo quedan algunas falencias que subsanar como que ciertas imágenes con brillo que forman parte de nuestro dataset de entrenamiento presentan error al momento de ser reproducidas por la GAN, además algunas colorizaciones no son completas, esto debido a que el dataset no contaba con muchas variaciones de color, por lo tanto es recomendable ampliar la paleta de colores con las que se realiza el entrenamiento.project_color.mp4Edit descriptiondrive.google.com
Bibliografía
[1] Una introducción básica a las GAN (Generative Adversarial Networks). (n.d.). Retrieved December 4, 2021, from https://ichi.pro/es/una-introduccion-basica-a-las-gan-generative-adversarial-networks-217887110266867
[2] film colorization, colorize video, colorize black and white videos, colorize video software, film colorization software, colorization of film. (n.d.). Retrieved December 4, 2021, from https://pixbim.com/film-colorization
Códigos
- Código para la recoleccion del dataset a partir de videos descargados de youtube
- Código para el entrenamiento del modelo
- Código para la implementación de los pesos del modelo previamente guardados
Presentación del proyecto: DemoDay
Repositorio
En el siguiente repositorio se encuentra el código usado para desarrollar esa aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Lapaz/2021.DL/Coloracion-de-videos-main
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!Saturdays.AI
WRITTEN BY
Daniela Centellas Yucra

Saturdays.AI
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.