
Zaragoza. Primera Edición. 2022
¡Cómo nos ha cambiado la vida en los últimos años!
Una pandemia mundial, un asalto a la Casa Blanca, una Filomena, una erupción de un volcán, hasta el comienzo de un conflicto entre naciones ? ¡… y un curso de IA en Zaragoza!
Una ventosa tarde de viernes, tres intrépidos zaragozanos comenzamos nuestra andadura en este ámbito.

Somos el equipo Aragón Feliz, venimos de diferentes mundos, pero compartimos un interés común por la Inteligencia Artificial, y buscamos ampliar y aplicar los conocimientos adquiridos durante el programa de Saturdays AI. El equipo está conformado por:
· Fernando Jiménez
· Héctor Soria
· Virginia Navarro
Y gracias a la ayuda de nuestros mentores del programa Saturdays IA, que nos han dado la base, hemos podido acometer este proyecto.
Cuando desde Saturdays AI-Zaragoza nos plantearon desarrollar un proyecto basado en IA, nos planteamos varias preguntas.

Y es que la contingencia sanitaria Covid-19 ha ocasionado circunstancias excepcionales con alto impacto en la sociedad, confinamiento masivo, soledad, incertidumbre, crisis económica, sanitaria y social, lo cual ha generado diferentes tipos de reacciones en la población, incrementando las patologías presentes tanto físicas como psíquicas, problemas económicos, entre otros.
Algunos datos
Según la Confederación de Salud Mental España en el estudio #saludmentalvscovid19 (https://consaludmental.org/centro-documentacion/salud-mental-covid19/)

Los datos están claros, toda esta situación ha tenido un alto impacto ya en la sociedad y probablemente se irá manifestando todavía más a lo largo de los próximos años.
A nosotros personalmente nos preocupa, pero… ¿es algo que preocupa?
Diferentes fuentes muestran que sí, que es un tema que preocupa en todos los rangos de edades, veamos por ejemplo esta encuesta realizada a un perfil más joven.

Pero ¿qué podríamos hacer nosotros?, ¿cómo podríamos revertir este efecto?, ¿cómo podríamos hacer que la balanza se inclinara hacia el otro polo opuesto: la Felicidad?
Para empezar, ¿qué es la Felicidad y cómo concretamos esa Felicidad? ¿Qué es lo que a cada uno de nosotros nos hace felices?
Según esta encuesta podemos ver qué aspectos concretos se valoran cuando se piensa en Felicidad.
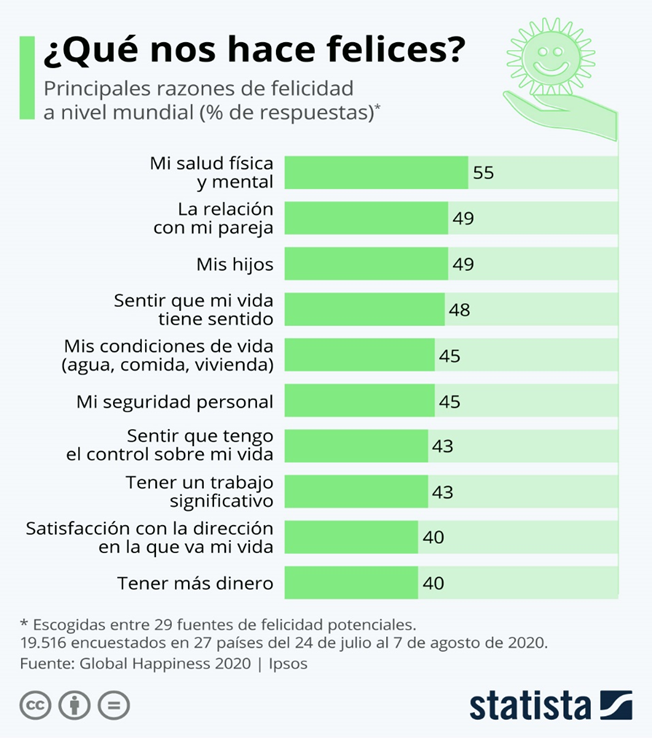
Y las siguientes preguntas que nos surgieron entonces fueron:
¿Cómo estábamos antes?
¿Cómo estuvimos durante los picos más altos de la pandemia?
¿Cómo se fue modulando ese estado conforme íbamos navegando en las olas y en las diferentes curvas?
¿Cómo estamos ahora realmente?
En definitiva …
¿Cómo tomamos consciencia del viaje emocional que hemos sufrido?
¿Cómo lo hemos ido concretando en el lenguaje?
Pero sobre todo…
¿Cómo lo traducimos a algo medible que poder analizar?
¿Somos capaces de anticiparnos y a través de las palabras, detectar estados y lanzar posibles alertas que con las debidas herramientas faciliten el cambio?
¿Cuál es el problema a resolver?
Nuestros primeros planteamientos
Con todas las preguntas anteriores fuimos conscientes de la magnitud del problema que estábamos considerando.
Para empezar, ¿cómo íbamos a poder medir todo esto? ¿Es posible generar algún indicador e información oportuna acerca del impacto emocional en las personas y de cómo éstas, consciente o inconscientemente, lo reflejan a través de su lenguaje?
¿Es posible a través de algoritmos de análisis de sentimientos y tópicos, detectar preocupaciones relacionadas con la contingencia sanitaria, así como otras situaciones a nivel general que le pueden afectar a cada individuo?
Uno de los principales handicaps al que nos enfrentamos es la correcta interpretación del lenguaje, para lo que existen numerosas técnicas y recursos dentro del PLN (Procesado del Lenguaje Natural). En nuestro caso, nos enfocamos en el español, un idioma en el que, aunque ampliamente usado, todavía se están desarrollando y mejorando algoritmos y modelos de IA verdaderamente eficientes que den resultados precisos, a diferencia del Inglés.
Bien, después de toda esta reflexión, éste iba a ser entonces nuestro reto inicial.
Problema
Dada la situación de pandemia vivida a lo largo del último año queremos analizar cómo esta situación ha podido afectar a la percepción general a nivel psicológico de los ciudadanos de Aragón, y cómo ha podido influir este estado respecto a diferentes temáticas (inferidas o prefijadas) en sus comentarios en diferentes medios, redes sociales, prensa, etc.
Quizá, ¿demasiado ambicioso?…
Quizá sí, por lo que intentamos acotar nuestro alcance y a partir de ahí evaluar si era viable realizarlo, por lo que nos centramos en el siguiente problema.
Problema acotado
Existe una alta complejidad a la hora de realizar un análisis de sentimientos (necesidad de datasets etiquetados manualmente por parte de expertos, tiempo para realizar esta anotación manual, la ambigüedad del lenguaje y subjetividad de las emociones, impacto del idioma con el que vamos a trabajar y alto riesgo de errores). Siendo conscientes de esta complejidad, desarrollamos nuestros objetivos principales.
¿Cuál es nuestro objetivo?
Objetivo realista
Brindar a la sociedad una herramienta que dé una clasificación o etiquetado automático de la Felicidad y subsane la complejidad de una evaluación manual, facilite esta labor y reduzca la ambigüedad y el error.
Demostrar que la herramienta es viable y desarrollar toda la metodología necesaria para llegar a ese etiquetado automático.
Objetivo WOW
Desarrollar un modelo que analice la evolución del sentimiento de los ciudadanos en Aragón respecto a diferentes temáticas (extraídas del propio contexto o predefinidas en base a una categorización estándar), teniendo en cuenta diferentes fuentes como redes sociales, prensa, etc. Y en función del análisis llevado a cabo, que realice recomendaciones y proporcione herramientas con el objeto de mitigar el impacto negativo en su estado emocional.
Disponible para público general, organismos públicos y medios de comunicación.
Objetivo con Impacto Social
Nuestro eje rector está englobado dentro de los Objetivos de Desarrollo Sostenible, en concreto en el 3. Salud y bienestar, aunque al ser tan amplio tiene repercusión en muchos más objetivos.

Manos a la obra. Desarrollo del Proyecto
Para la ejecución del proyecto hemos seguido la siguiente metodología iterativa basada en el estándar CRISP-DM (Cross Industry Standard Process for Data Mining).
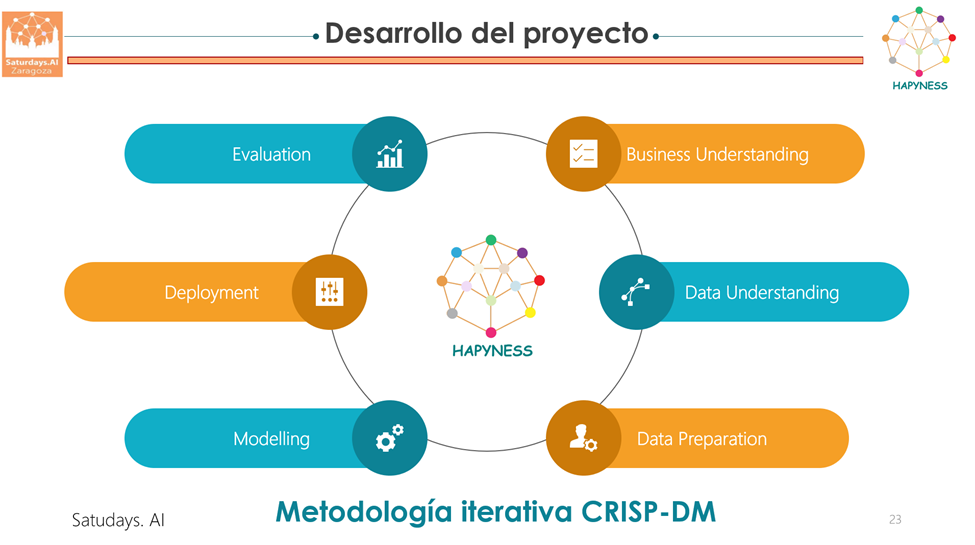
Fase I. COMPRENSIÓN DEL PROBLEMA
En este momento del proyecto, trabajamos en la identificación de recursos, restricciones, problemáticas y procesos involucrados.
Como hemos ido comentando, sin duda el periodo de pandemia ha sido una etapa de alto impacto emocional, pero en este concepto tan global, ¿entendemos todos de la misma forma estas emociones?
Empezamos por las emociones
Problemas del lenguaje
Trabajaremos sobre textos escritos, por lo que comenzamos a plantearnos qué posibles problemas nos podíamos encontrar a la hora de gestionar y analizar este tipo de información.

Además, nuestro modelo, en la medida de lo posible, debería reconocer y considerar diferentes fenómenos lingüísticos relevantes para interpretar de forma autónoma la opinión de los usuarios. Así, en la práctica, debería tener en cuenta y poder reconocer la ironía, la negación y las emociones, entre otras cuestiones.
Como reflexión final, por todo lo anterior, vimos clara la dificultad de extraer las emociones de los textos, lo cual nos llevó a plantearnos construir un diccionario propio y como primera aproximación plantearnos un algoritmo de clasificación semi-automático.
Fase II. COMPRENSIÓN DE LOS DATOS
Y continuamos con los datos, el caballo de batalla de todos los proyectos.
A. Fuentes de datos y problemáticas en su obtención

No contábamos con un dataset etiquetado específico de Aragón y sobre la pandemia y nos planteamos cómo resolver el problema sin utilizar textos de otros ámbitos y épocas. Pero, aun así, se han utilizado los disponibles para hacer una comparación cualitativa de nuestra solución.
Encontramos diferentes fuentes de datos que podrían sernos útiles y estuvimos navegando en ellas para ver cuál podría sernos más valiosa, ya que necesitábamos un dataset previamente categorizado.

Datos etiquetados
Inicialmente utilizamos el corpus de TASS, por lo que acudimos a la Sociedad Española de Procesamiento del Lenguaje Natural (SEPLN), a través de la cual se creó el TASS, que es un Taller de Análisis de Sentimiento en español organizado cada año http://tass.sepln.org/
La carpeta con los datos fue solicitada a la organización y se nos concedió el permiso para usarla.
Revisando la data nos encontramos con diferentes archivos de tweets, agrupados por países y años. No todos tienen la misma categorización, diversos archivos tienen diferentes esquemas dependiendo de que edición del TASS sean, algunos de ellos están etiquetados con su sentimiento (polaridad — positivo/negativo/neutro-, o con emociones como feliz/triste).

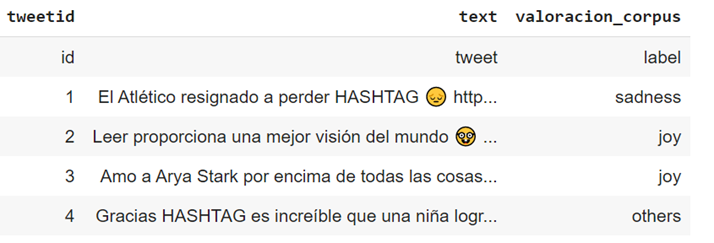
Los archivos del corpus están en formato XML, que hemos procesado y adaptado para que nuestro modelo lo comprenda, transformando los datos a un formato .csv, “Comma Separated Values”, para poder proceder con la siguiente fase.
Datos no etiquetados
En cuanto a los datos para evaluar el modelo seguimos dos vías:
1) Por un lado volvimos a utilizar los datos de test del Corpus TASS, cuya estructura de los archivos es similar a esta:

2) y por otro recopilamos datos directamente desde Twitter gracias a la herramienta Tweepy que nos permitió realizar la búsqueda de publicaciones de usuarios en esta red social a través de su API, durante el periodo de pandemia. La selección de publicaciones se realizó con los siguientes criterios: Aragón, covid, fecha, geolocalización,…
Para poder hacer este proceso, creamos una cuenta en Twitter/desarrollador para poder empezar a descargar los tweets.
Utilizamos como referencia este artículo:
Tardaron un poco en darnos acceso, pero finalmente lo conseguimos y pudimos seguir avanzando en esta parte.
La estructura de los archivos es similar a esta:

B. Características que nos interesaría considerar
Y empezamos a considerar qué variables podrían ser relevantes en nuestro estudio para ayudarnos a conseguir nuestro objetivo (aunque probablemente no dispongamos de todas ellas).

Fase III. PREPARACIÓN DE LOS DATOS

- Análisis exploratorio de los datos (EDA)
Para nuestro análisis, el dataset inicial cuenta con la siguiente descripción:

Como hemos mencionado, el corpus contiene múltiples niveles de polaridad. No obstante, hay diferencias entre diferentes archivos, por ejemplo, algunos archivos sólo tienen los niveles Positivo, Negativo y Neutral, mientras que otros incluyen un nivel adicional denominado None.Por lo tanto, si quisiéramos trabajar con todos los archivos conjuntamente, deberíamos convertir la polaridad en una variable dicotómica (binaria) con los valores (Positivo=1, Negativo=0).
En nuestro caso, partimos de los que partían de positivo-negativo para pasar después a Feliz-Triste, que se adecuaba más a la categorización que podríamos conseguir de nuestro diccionario que está asociado a los términos Felicidad/Tristeza
- Pretratamiento y limpieza de los datos
Previo al análisis y modelado necesitamos hacer un proceso de eliminación de ruido y normalización.
Creamos la funcion limpia_tweet() que va a eliminar stopwords y algunos caracteres peculiares de Twitter, posteriormente fuimos ajustando esta limpieza debido al ruido de la data y a los problemas que nos iba planteando el código.
1. Se eliminaron las stopwords como: de, con, por, …entre otras.
2. Se eliminó cualquier tipo de mención, RTs, #, links, URLs.
3. Se eliminó cualquier tipo de puntuación.
4. Se buscaron abreviaturas y textos con jergas cibernéticas como: “u” para “you”, “ur” para “your”, “k” para “que”, entre otras.
5. Se eliminaron emojis, y cualquier tipo de valor alfanumérico, caracteres numéricos, vinculados a monedas, porcentajes, etc…
6. Se exploraron los datos, analizando las palabras más comunes en los Tweets.
Una vez que se ha realizado el proceso, el texto limpio se almacena en una nueva columna ‘tweets_transform’:
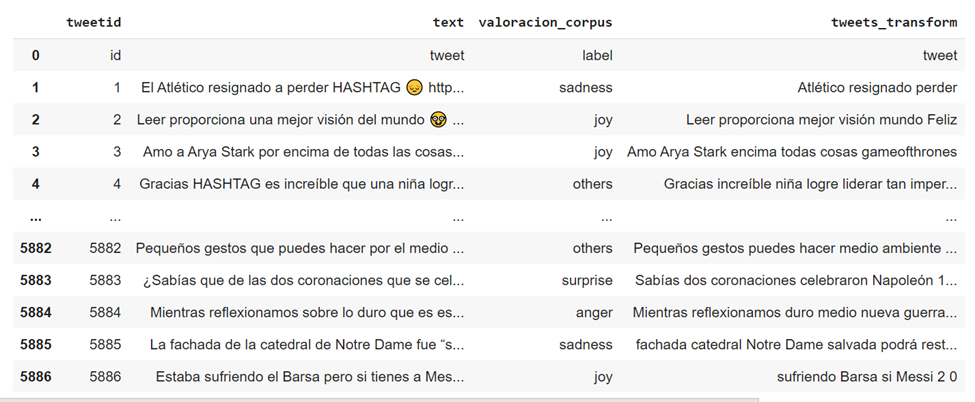
- Procesamiento del texto
Para poder tratar matemáticamente los tweets preprocesados, tenemos que extraer y estructurar la información contenida en el texto. Para ello, usaremos la clase sklearn.feature_extraction.CountVectorizer.
CountVectorizer convierte la columna de texto en una matriz en la que cada palabra es una columna cuyo valor es el número de veces que dicha palabra aparece en cada tweet.
De esta forma podemos trabajar con estos vectores en vez de con texto plano.
Para cada tweet realizaremos el siguiente proceso:
1. Tokenización: este paso convierte una cadena de texto en una lista de palabras (tokens)
2. Conversión a minúsculas
3. Eliminar stopwords. Se llama stopwords a las palabras que son muy frecuentes pero que no aportan gran valor sintáctico. Ejemplos de stopwords en español serían: de, por, con…
4. Filtros semánticos (Stemming/lematización) es el proceso por el cual transformamos cada palabra en su raíz. Por ejemplo, las palabras maravilloso, maravilla o maravillarse comparten la misma raíz y se consideran la misma palabra tras el stemming.
5. Creación de una bolsa de palabras.
Con WordCloud visualizamos las palabras más utilizadas en el dataset:

- Verificación de la calidad de los datos
Comprobamos si con estos datos nos es suficiente o es necesario tratar algún dato más (data, geolocalización, etc..) o construir nuevos datos a partir de la información existente (valoración).
- Construcción de una estructura de datos para el posterior entrenamiento y evaluación del modelo
A. Datos de geolocalización
B. Datos Fecha. Transformación para adecuarlos al formato necesario para la gráfica de evolución.
Fase IV. MODELADO
¿Cómo lo podemos abordar?

Variante 1: Resolver el problema con técnicas de clasificación, específicamente “análisis de sentimiento”, que tiene como clases o etiquetas de sentimiento: “positivo”, “negativo” o “neutral”. Para ello, será necesario conseguir un data set con dichas etiquetas que estén relacionadas con Aragón (por ejemplo, data sets de Twitter) o buscar información textual (por ejemplo, periódicos regionales, etc.) y previamente clasificarlos usando etiquetas de sentimiento (a través de un proceso manual, o bien automatizado usando diccionarios).
Variante 2: Resolver el problema aplicando técnicas de agrupamiento. En este caso, sería necesario recopilar información textual (por ejemplo, periódicos regionales, Twitter, etc.) y agrupar la información, y analizar estos grupos.
Todo el código y los datos utilizados, por si quieres consultarlo en mayor detalle, los tienes disponibles en nuestro respositorio de Github: https://github.com/FJDevelop/HaPyness-Saturdays-AI
A. Modelo de valoración basado en el diccionario (clasificación semi-supervisada)
Creación de un diccionario

Con el objetivo de poder hacer este proceso de clasificación semi-automática necesitábamos disponer de un diccionario con el que poder comparar y clasificar. Ante la dificultad de encontrar uno especialmente válido en castellano, decidimos crear nuestro propio diccionario, y estos fueron los pasos que fuimos siguiendo:
- Creación Diccionario inicial que nos permite detectar los valores Feliz (+1) y Triste (-1), y con ello hacer una valoración automática. Fuente: http://www.ideasafines.com.ar/buscador-ideas-relacionadas.php
- Realizamos un análisis del sesgo palabras (30% Positivas 70% Negativas).
- Realizamos una valoración del volumen de palabras 3000 (ya que podría influirnos después en el procesamiento y ejecución del código)
- Búsqueda de alternativas. Valoración posibilidad de utilizar un diccionario reducido.
- Decisión sobre el diccionario final.
El diccionario está incialmente basado en 3000 palabras relacionadas con ‘felicidad’ y ‘tristeza’.
Tras el post procesado intensivo de las mismas y formateado, se ha ajustado el vocabulario a las 2600 palabras con la menor ambigüedad posible.
Las 3000 palabras han sido revisadas manualmente, para eliminar ambigüedades y errores de valoración.
En la generación de este diccionario, siguiendo este documento de referencia, que explica cómo extraer características relevantes de un corpus textual:
https://www.geeksforgeeks.org/using-countvectorizer-to-extracting-features-from-text/
Utilizamos countvectorizer: convierte textos (= tweets procesados) en filas, los pasa a minúsculas (pero conserva los acentos), y en cada columna aparecen las palabras utilizadas (su frecuencia en la frase), en orden alfabético. El ejemplo que se muestra aquí es muy sencillo.
Del objeto resultante podemos extraer:
– un diccionario con las palabras encontradas (se obtiene directamente mediante ‘vectorizer. vocabulary’)
– la matriz para analizar, con las frecuencias (en unos pasos sencillos)

Problemática:
Había miles de palabras y llevó mucho tiempo, por lo que, del resultado inicial, decidimos acotarlo a las pestañas más útiles (son las amarillas), suficientes para valoración “Feliz/Triste”, ya que trabajar con más valores (Muy feliz, feliz, triste, muy triste) nos implicaría mucho más tiempo de desarrollo y queríamos avanzar en el resto de la metodología y evaluación de nuestra solución. Los datos de entrada a este proceso se muestran a continuación, donde junto con el diccionario elaborado manualmente se analiza el corpus etiquetado y mapeado a las etiquetas de Felicidad/Tristeza para completar el vocabulario de valoración.

Creamos un modelo que ejecuta el siguiente algoritmo:
a. Importa el vocabulario
· Prepara stopwords españolas del vocabulario
· Aplica funciones steemer
b. Prepara el vocabulario stemmed
c. Lee los tweets
d. Aplica filtros limpieza
e. Valora sentimientos sobre los textos con el vocabulario steemed, creando un nuevo campo valoración calculada.
f. Guarda los tweets valorados en ficheros distintos según el resultado comparativo frente a los textos etiquetados (Ok, errores, sospechosas)


Con respecto al fichero con las palabras sospechosas, realizamos un análisis del mismo para comprobar si nuestro proceso estaba funcionando correctamente.

Nos dimos cuenta de que las que salían tenían cierto sentido, si se quitaban parece que podría empeorar, por lo que haría falta tener otra lista “palabras interesantes”, donde mirar antes de quitarlas, lo cual suponía un esfuerzo adicional considerable, por lo que decidimos abordarlo posteriomente si nos daba tiempo.
Como causa considerábamos que sin contexto las palabras son muchas veces ambiguas, por lo que como con lo que habíamos obtenido hasta ese momento, obteníamos un 60% acierto, y no parece fácil de aumentar cuantitativamente, decidimos continuar con el fichero OUT_es con las dos columnas (Valoracion_corpus y Valoracion_calculada) con el que podríamos alimentar la parte de IA.
B. Modelos tradicionales de Machine Learning (clasificación supervisada)
El objetivo de este problema de Machine Learning es predecir el sentimiento de los tweets incluidos en nuestro fichero usando el corpus de TASS como training data (datos para entrenar al modelo predictivo).
Hay que puntualizar que el dataset se ha divido en TRAIN y EVAL/DEV



Las 15 palabras más utilizadas antes del stemming

Representación Numérica
Después del stemming, creamos una bolsa de palabras (Bag of Words, BoW), que es una representación de cada documento en base a las palabras únicas que aparecen entre todos los documentos disponibles, a partir de la unión de todas las frases junto con la cantidad de veces que aparece cada palabra.
Con la idea de compensar aquellas de mayor frecuencia, aplicamos TF-IDF (TermFrequency–Inverse DocumentFrequency), que nos indica la relevancia de un término en el documento, teniendo en cuenta el ámbito en el que se suele usar (corpus).
Selección Algoritmos ML
A continuación listamos el conjunto de algoritmos de aprendizaje automático que hemos considerado en esta fase (se ha utilizado el etiquetado manual original como clases verdaderas):
Random Forest Classifier





SVM




XGBoost




Aplicación teniendo en cuenta el módulo Valoración
Random Forest

SVM

XGBoost

Dado que RF es el que mejor resultado da con la valoración humana, en términos de clasificación, quisimos mejorar el modelo de RF para la valoración algorítmica. Para ello empleamos un GridSearchCV en los dos tipos de valoración, humana y algoritmia. En el caso de la valoración humana parece que no se mejora el resultado, parece que estamos en el máximo valor alcanzable aunque también es probable, que sea un máximo local y no global.
Por otro lado, en la valoración algorítmica conseguimos mejorar el resultado del modelo, usando los mismos parámetros de calidad: Accuracy, Recall, Precision y F1.



☝ ¡eh! ¡que mejoramos de forma significativa! Vamos a guardar el modelo, por si las moscas ?
C. Agrupamiento…
Aplicamos el modelo Kmeans, pero lo cierto es que no nos resultó demasiado útil, no conseguimos conclusiones demasiado claras ni obtuvimos conjuntos de términos muy claros, quizá podríamos conseguir mejores resultados realizando una labor adicional de limpieza de datos o quizá tener más volumen de tweets como para poder sacar conclusiones.



TSNEt-DistributedStochasticNeighborEmbedding


Para poder visualizar palabras en 2D vamos modificando diferentes parámetros de la función word2vec. Las que más influencia tienen en nuestro sistema son el número máximo de palabras consideradas y el número de veces que una palabra tiene que estar repetida en el texto para ser considerada representativa. Como podemos ver en la representación de tsne, es difícil sacar conclusiones. Se debería limpiar mejor el texto para evitar la dependencia de los acentos o terminar de eliminar caracteres que solo añaden ruido como ‘ji’ o ‘san’.
D. Aplicación sobre datos de TEST (no etiquetados)
Seguimos los mismos pasos sobre los tweets obtenidos y no etiquetados previamente para evaluar la potencia de los modelos ante textos no vistos previamente y de otros dominios. A continuación vemos los resultados.
Partimos de un análisis exploratorio de los datos y pretratamiento de los mismos.



Vemos cuáles son las palabras más comunes


Aplicamos el módulo de valoración para obtener la valoración calculada:


Aplicamos ahora modelos de Machine Learning y analizamos resultados (tomando como referencia la valoración calculada):
Random Forest Classifier

SVM

XGBoost

El modelo de RF, de nuevo, es el más prometedor, por lo que volvemos a usar GridSearchCV para ver si podemos mejorar la clasificación.

? no hay mucha mejora que digamos, parece que no es muy bueno generalizando…
Fase V. EVALUACIÓN DE RESULTADOS
Todo el código y los datos utilizados, por si quieres consultarlo en mayor detalle, los tienes disponibles en https://github.com/FJDevelop/HaPyness-Saturdays-AI
A. Comparación de modelos de ML

Entre los diferentes modelo de ML utilizando directamente las clases etiquetadas manualmente, el SVM es el que arroja unos resultados ligeramente superiores.
B. Comparación de modelos de ML vs Valoración

Se puede observar que el modelo de valoración tiene un desempeño próximo a los modelos automáticos tradicionales de ML.
C. Evaluación sobre tweet directamente obtenidos
Evaluación de los resultados de los modelos en relación con la evaluación de tweets no etiquetados previamente
Utilizando los mejores modelos previamente entrenados y guardados (model.pkl), se observan algunas diferencias:


Por tanto: comparando los modelos en distintos escenarios

Como se puede ver en la imagen, el valorado automático en una muestra de novo tiene una menor capacidad de clasificación que en la muestra original. La heterogeneidad de la muestra y una limpieza menos eficaz conlleva una menor potencia.
D. Análisis de la variación de la percepción Felicidad/Tristeza
Transformamos el campo fecha, y clasificamos aquellos tweets que pertenecen a una fase precovid o que corresponden a la etapa covid


Se observa un mayor desequilibrio en la etapa covid, con comentarios más cercanos a la tristeza que en el periodo precovid, donde a pesar de predominar la tristeza los resultados eran mucho más cercanos
Visualización de la evolución

Vemos que aplicando Machine Learning el resultado predice tweets más negativos, en general.
Fase VI. Despliegue
Para la puesta en producción de los modelos finales y los resultados obtenidos, utilizamos Streamlit que es una librería de Python de código abierto que facilita la creación y el uso compartido de aplicaciones web personalizadas para el aprendizaje automático y la ciencia de datos.
Nuestra aplicación en streamlit es un Valorador de felicidad que te permite realizar el análisis del texto que introduzcas, dando como resultado la valoración del mismo, así como las palabras que han determinado esa valoración.


Por otro lado, permite la visualización de la evolución de los sentimientos en cuanto a Felicidad/Tristeza en la muestra seleccionada.
Conclusiones

Las conclusiones obtenidas tras el desarrollo y resolución del objetivo general son:
Con respecto a las vinculadas con nuestros objetivos:
Hemos conseguido desarrollar una herramienta de etiquetado automático para Felicidad y tristeza con un porcentaje de acierto satisfactorio (63% respecto al corpus y de un 53,2% con respecto al modelo de Machine Learning respecto al etiquetado automático), que puede facilitar la labor y evitar la complejidad de un etiquetado manual.
Además, hemos desarrollado un modelo que analiza la evolución del sentimiento en este caso de los ciudadanos en Aragón respecto a las emociones felicidad y tristeza inferidas de sus comentarios en rrss, que nos permite ver claramente el impacto que la pandemia u otros acontecimientos significativos han tenido en su percepción y bienestar.
A nivel general, las principales conclusiones que hemos obtenido son:
– El concepto de Felicidad y Tristeza no es común a todas las personas tanto en la expresión como en la evaluación, por lo que esto puede afectar en la valoración por la dificultad de estandarizar la expresión de un sentimiento.
– La complejidad de interpretación de los tweets es tan grande que puede tener un gran impacto tanto la subjetividad de la persona como la del momento de la evaluación. Para solucionar este se podría realizar una votación entre varias personas a nivel de vocabulario y a nivel de tweets.
– Riesgo de confusión entre positividad-negatividad y felicidad -tristeza a la hora de valorar las palabras.
– Sesgo de la fuente elegida Twitter (redes sociales más tendenciosas que otras, mensaje de 280 caracteres puede limitar la expresión de la emoción, ¿accesible a toda la tipología de la población?).
– Sesgo en el lenguaje, que se traslada a nuestro diccionario. Ponderación de las palabras felices y tristes (30 -70).
– Riesgo de pérdida de información en el pretratamiento: En el proceso de pretratamiento de los tweets con objeto de facilitar el proceso, hemos eliminado elementos que nos podrían ampliar el análisis, por ejemplo, emoticonos o hahtags (#), con lo que puede que se haya desvirtuado la valoración final (fase evolución 20.0).
– Importancia del contexto en el análisis y la valoración.
– El resultado de los tres modelos que hemos utilizado han sido muy parecidos, aunque el modelo Random Forest parece que es el que mejor se adapta a la clasificación y dominio bajo estudio, a tenor de los resultados, puede deberse al volumen de la muestra, aunque se podría evolucionar buscando mejores parámetros en SVM y XGboost o probar redes neuronales.
– Existen numerosas técnicas y recursos dentro del PLN (Procesado del Lenguaje Natural) en inglés, pero no están tan desarrolladas en español, lo cual dificultaba en nuestro caso la aplicación.
Mejoras y Evolución
Como posibles propuestas de evolución de la herramienta

ML Funcionalidades del análisis:
- Explorar y analizar más en profundidad los resultados de Kmeans
- Explorar y analizar las opciones que brindan los Word Embeddings
- Mejorar resultados de los modelos con hiper parámetros
- Utilizando técnicas de NLP realizar búsquedas semánticas (agrupación-clusters, tópicos, similitud de perfiles, predicción de tendencias)
- Explorar redes neuronales
Fuentes:
- Extender el análisis a mayor volumen de tweets
- Aplicar nuestro modelo a otra tipología de fuentes (redes sociales, prensa,…)
- Análisis de las cuentas que generan los tweets
Análisis de emociones:
- Ampliar el diccionario a más categorías de emociones
- Incorporar análisis emoticonos, hashtag en la valoración
- Incorporar análisis del sarcasmo y la negación en la valoración
- Incorporar análisis del contexto (del mismo tweet y del contexto del propio tweet)
- Incorporar análisis emocional
- Análisis personalizado tweets vinculados a una persona para la valoración de su estado emocional
Visualización:
- Incorporar mapas de geolocalización de los tweets para análisis de valoraciones por zonas.
- Gráfico radial de análisis emociones personalizado
Alertas y recomendaciones:
- Sistema de alertas en función del estado emocional.
- Recomendación temáticas concretas adaptadas a ese análisis personalizado.
- Recomendaciones genéricas accesibles a todos los perfiles
- Identificación perfiles críticos y alertas asociadas (prevención del suicidio, índices depresión…)
Agradecimientos
A todo el equipo de Saturdays AI, y sobre todo al equipo de Saturdays AI Zaragoza, en especial a Rosa Montañés, Mª del Carmen Rodríguez, Rocío Aznar y Rafael del Hoyo ya que sin ellos no habría sido posible.
La experiencia ha sido muy agradable y recomendable, con una metodología de aprendizaje muy efectiva basada en la práctica, ¡Gracias por todo vuestro apoyo, paciencia y dedicación!
Y a ti, por haber llegado hasta aquí en la lectura del artículo.
Referencias:
Github
Todo el código y los datos utilizados los tienes disponibles en https://github.com/FJDevelop/HaPyness-Saturdays-AI/tree/main
Vocabulario relacionado con felicidad y tristeza http://www.ideasafines.com.ar/buscador-ideas-relacionadas.php
Datasets
Tass Corpus:
Acceso personalizado al Corpus de TASS
http://tass.sepln.org/tass_data/download.php
https://gplsi.dlsi.ua.es/sepln15/es/taller-de-analisis-de-sentimientos-en-la-sepln-tass
Análisis del Sentimientos
NRC Word-Emotion Association Lexicon (aka EmoLex)
https://saifmohammad.com/WebPages/NRC-Emotion-Lexicon.htm
Sentiment Analysis in Python
https://neptune.ai/blog/sentiment-analysis-python-textblob-vs-vader-vs-flair
Desarrollos
Ejemplo sentimental Analysis en español
https://pybonacci.org/2015/11/24/como-hacer-analisis-de-sentimiento-en-espanol-2/
Análsis de tweets
https://www.cienciadedatos.net/documentos/py25-text-mining-python.html
Información de interés
Herramienta para realizar la Demo.
Streamlit: https://docs.streamlit.io/library/get-started/create-an-app
Información Covid
Datos salud Mental afectación coronavirus
https://consaludmental.org/sala-prensa/manifiesto-salud-mental-covid-19/
Datos estadísticas encuestas
Integrantes
- Fernando Jiménez
- Héctor Soria
- Virginia Navarro
Presentación del proyecto: Demoday
Repositorio
Se puede encontrar el código de este proyecto en GitHub
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!