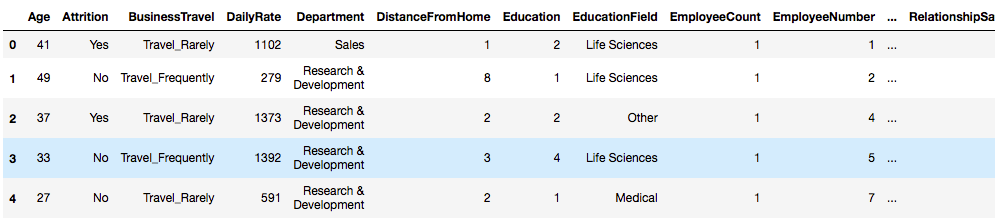
La Paz. Deep Learning. 2021
La Paz 2021. Las técnicas de Inteligencia Artificial tienen muchas aplicaciones actuales en el campo de las fotografías. Una de ellas tiene que ver con la manipulación de imágenes, campo en el cual se inscribe nuestro proyecto.
En particular, la restauración de imágenes (image restoration) es el proceso de recuperar una imagen a partir de una versión degradada. Image restoration es un caso de estudio que normalmente es tratado con procesamiento de imágenes. Se parte de la idea de que la imagen ha pasado a través de una función de degradación y se le ha añadido ruido; la restauración entonces consistirá en revertir el proceso y recuperar la imagen original.
El propósito de este proceso es “compensar” o “deshacer” aquellos defectos que generaron la degradación de la imagen, obteniendo un estimado de la imagen original.
La degradación puede provenir de diferentes fuentes, como la difuminación de movimiento (motion blur), ruido, desenfoque de la cámara o una combinación de todas éstas. También hablaremos de degradación al referirnos a aquellas fotografías impresas o negativos que sufrieron cualquier tipo de desgaste debido al envejecimiento del papel, polvo, manchas, etc.
De manera tradicional, una vez identificado el tipo de degradación, es posible procesar la imagen con un tratamiento de procesamiento de imágenes. Existen diferentes estudios y especializaciones con respecto a estos procesos, especialmente para revertir el ruido agregado a la función de degradación. Cada caso es único, por lo cual el tiempo de procesamiento puede llegar a ser muy largo. Al mismo tiempo, podemos encontrar estudios de fotografía que ofrecen el servicio de restauración aplicando técnicas de edición digital, lo cual resulta costoso.
Por otro lado, tenemos los films negativos fotográficos producidos por las cámaras analógicas que son preservados por varios tipos de usuarios, desde historiadores y bibliotecarios hasta quienes simplemente desean conservar recuerdos familiares. Estas películas normalmente deben pasar por un proceso químico (revelado) para la obtención de la fotografía física que describe la escena que fue capturada con la cámara analógica.
Existen técnicas de manipulación de la imagen digital de un negativo para obtener la imagen que correspondería a la revelada en el proceso tradicional. Estas técnicas siguen una secuencia de pasos que consisten en ajustar ciertos parámetros de la imagen que van más allá de la inversión de colores, algo que también se debe hacer imagen por imagen.
DESCRIPCIÓN DEL PROBLEMA y OBJETIVO
La selección de la técnica de procesamiento de imágenes que debe aplicarse a la imagen degradada proviene de una apreciación visual y resulta subjetiva. Muchas veces debemos aplicar varias técnicas en cascada para obtener un resultado óptimo. Este proceso consume tiempo, es específico a cada caso que se presente y en la mayoría de los casos no se puede paralelizar.
¿Y si pudiéramos utilizar la inteligencia artificial para crear un solo modelo que sea capaz de restaurar la imagen degradada sin necesidad de categorizar el tipo de degradación, cómo también realizar el revelado de las fotografías a partir de los negativos en film?
Éste es precisamente nuestro objetivo. Utilizaremos técnicas de Inteligencia Artificial para construir un modelo de restauración de fotografías que podrá recuperar la imagen original a partir de las degradaciones descritas y/o a partir de los negativos fotográficos. Para hacer el desafío más interesante incluiremos además imágenes en formato blanco y negro que deberán ser coloreadas; y también imágenes con regiones suprimidas, es decir taparemos regiones de la escena simulando manchas o rasguños que pudieran haber eliminado por completo estas regiones. Por más que existen modelos que hacen ciertas funciones que describimos, una de las dificultades será el de combinar todas estas restauraciones (colorización, revelado, restauración e incluso generación creativa) en un sólo modelo.
SELECCIÓN DE LOS MODELOS
El proyecto presentado está basado en varias librerías de Fast.ai, que proporcionan herramientas de manipulación de fotografías mediante inteligencia artificial, de datasets para entrenamientos e incluso de modelos pre entrenados que son un buen punto de partida. La arquitectura general escogida es la de trabajar con una GAN (Generative Adversarial Network), que es apropiada para resolver nuestra problemática.
La estructura general utilizada consiste en un generador de imágenes, que intenta crear imágenes con la mejor calidad posible, ya sea en el color, la resolución, la textura… Por otra parte se entrena un discriminador que debe distinguir entre las imágenes reales dadas cómo input y las imágenes generadas por el generador. Finalmente se hace un tercer entrenamiento donde se combinan los dos modelos anteriores, lo que crea la GAN: en este proceso ambos modelos compiten y obligan a mejorarse el uno al otro.
Nuestro modelo generador ya viene pre entrenado y consta de dos partes. La primera son las convoluciones que llevan una imagen de input hacia dimensiones cada vez más pequeñas, y la otra parte es cuando se hace el camino inverso para recuperar una nueva imagen de las mismas dimensiones que la que se tiene como input. La arquitectura total es UNET, que tiene como particularidad que cierta información del proceso de reducción de la imagen se le envía directamente a su contraparte (cuando las dimensiones son equivalentes). Este proceso se puede ver en la siguiente imagen.
De igual manera, las diferentes operaciones y convoluciones utilizadas están basadas en una arquitectura CNN (Convolutional Neural Network) Resnet34 (34 capas de profundidad), que utiliza bloques residuales o de identidad durante las operaciones de convolución. Cuando cargamos este modelo, se puede entrenar solo la parte de la derecha (aproximadamente 20 millones de parámetros) utilizando la opción freeze(), o se puede entrenar el modelo entero (aprox. 40 millones de parámetros) con la opción unfreeze(). En este momento del proceso, y viendo que se utiliza una loss function de Mean Squared Error (MSELossFlat()), el generador solo intenta acercarse lo más posible a los valores de los píxeles de la imagen original. Sin embargo, esto no es suficiente para capturar, por ejemplo, el entorno de los píxeles, en específico ciertas texturas que son muy importantes para obtener una imagen correcta y de buena resolución. Es por eso que se utiliza el generador junto al discriminador en una estructura GAN.
El discriminador (también llamado critic) utiliza una loss function de cross-entropy con logits permitiendo una clasificación binaria (BCEWithLogitsLoss()), que está bien adaptada a su objetivo. Antes de entrenar la GAN, el discriminador se puede entrenar entre imágenes creadas por el generador y los input reales. Sin embargo, lo que más nos interesa es el entrenamiento de la GAN.
En esta etapa, los dos modelos generador y discriminador se entrenan juntos. La idea es utilizar un switcher que decidirá si es momento de entrenar el generador para mejorar las imágenes creadas y confundir al discriminador, o al contrario entrenar el discriminador cuando un cierto umbral de imágenes están siendo clasificadas como reales cuando en realidad son creadas por el generador.
Este proceso se lo puede realizar iterativamente cambiando el tamaño de las imágenes con las cuales va trabajando el modelo, yendo de dimensiones más pequeñas a las más grandes. De esta manera, el modelo va mejorando progresivamente. Esta técnica se utiliza por ejemplo para mejorar la resolución de las imágenes que se le da al modelo de Inteligencia Artificial y mejorar así las fotografías.
PREPARACIÓN Y CONSTRUCCIÓN DEL DATA SET
Es bien sabido que uno de los aspectos más importantes en la construcción de cualquier modelo inteligente son los datos. Es así que pusimos énfasis en la obtención, preparación y construcción de un dataset que nos pudiera proporcionar todo el espectro de degradaciones que requerimos que nuestro modelo sea capaz de reconstruir y que contemos con la cantidad y variedad necesaria.
Trabajamos con el dataset VOC2012 y ColorizationDataSet como datos iniciales (imágenes variadas a color y sin defectos). Decidimos utilizar 9895 imágenes en total. A una mitad se le aplicó un proceso de negativización artificial gracias a un preprocesamiento de imagenes y para la otra mitad se tomó en cuenta las imágenes en blanco y negro. A todas éstas imágenes se le aplicó un segundo procesamiento de imágenes dónde a un 65% se le aplicó algún tipo de degradación como ser compresión jpeg, ruido sal y pimienta, difuminado (blur), entre otros; y a un 25% se aplicó una degradación más importante cómo son unos huecos o manchas en varios sectores de las imágenes. A continuación podemos ver varios ejemplos de este tratamiento.
Para el entrenamiento del modelo, se dividió el dataset en un train set de 8906 imágenes y un test set de 989 imágenes.
EVALUACIÓN DE MODELOS
Para entrenar nuestro modelo, utilizamos la GPU proporcionada por Google Colab. Antes del entrenamiento de la GAN, se puede entrenar el generador y el discriminador con sus respectivas loss function detalladas en el punto 4.
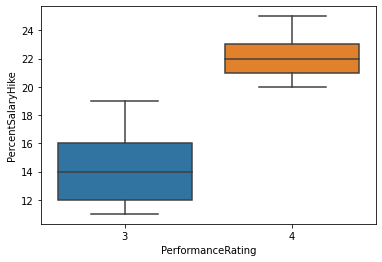
Para el generador, vemos que existe una cierta mejora al avanzar el número de épocas, tanto para el train set como para el test set. Hay que tener en cuenta que esto es sólo una parte del entrenamiento del generado,que en realidad se hará durante el entrenamiento de la GAN.
Para el discriminador, de igual manera se lo puede entrenar solo, y en esta etapa podemos llegar a un accuracy de hasta 95 %, lo que demuestra que antes de entrenar la GAN, le es muy fácil distinguir las imágenes reales de aquellas producidas por el generador.
Durante el entrenamiento de la GAN, se utilizan otras loss function un tanto modificadas tanto para el generador como discriminador. Sin embargo, para evaluar el modelo final, se necesita hacer una verificación visual ya que las loss function de ambos no nos proporcionan información relevante porque ambas funciones irán mejorando y empeorando en función de qué modelo se esté entrenando.
ANÁLISIS DE RESULTADOS
Para el entrenamiento del modelo de Inteligencia Artificial especializado en las fotografías se preparó un conjunto de datos de 9895 imágenes de negativos fotográficos (artificiales) y 9895 imágenes a color, cada uno de los negativos tiene una imagen a color relacionada..
El conjunto de datos se dividió en 2 grupos uno de entrenamiento y otro de validación, bajo el siguiente detalle:
– Train (8906 imágenes)
– Valid (989 imágenes)
Para el entrenamiento se consideraron los siguientes grupos de imágenes:
a) Imágenes en blanco y negro.
b) Imágenes sin degradación.
c) Imágenes con ruido gaussiano.
d) Imágenes con degradación y supresión de regiones
Resultados Train:
– Imágenes en blanco y negro
Imagen: image2669.jpg
– Imágenes en negativo sin degradación
Imagen: 2007_000039.jpg
Podemos ver que el modelo hace un buen trabajo al colorear ciertas imágenes negativas, encontrando el color correcto en la mayoría de los objetos de la imagen.
– Imágenes en negativo con ruido gaussiano.
Imagen: 2007_003118.jpg
La restauración de ruido hacia una mejor resolución no está completamente realizada, incluso para el train set. Podemos concluir que hace falta más tiempo de entrenamiento para continuar con el proceso.
– Imágenes en negativo con regiones suprimidas
Imagen: 2007_000033.jpg
Imagen: 2007_000027.jpg
Para las imágenes degradadas con partes enteras faltantes, el modelo reconoce el color que le debe dar a la zona oscura. Por el momento, la resolución es mala, pero con más entrenamiento, esto puede ir mejorando.
Resultados Test Set:
– Imágenes en blanco y negro.
Imagen: image0476.jpg
– Imágenes en negativo sin degradación.
Imagen: image1027.jpg
– Imágenes con ruido gaussiano.
Imagen: image0850.jpg
– Imágenes con Degradación
Imagen: image4988.jpg



Resultados de imágenes que no forman parte del dataset:
A continuación presentamos resultados de predicción del modelo en imágenes completamente nuevas que no se utilizaron durante el entrenamiento. Podemos observar que dependiendo la imagen en blanco y negro, la colorización se hace de manera aceptable en algunas pero casi nada en otras. De igual manera en la segunda imagen se observa que la imagen del resultado ha mejorado la calidad de la imagen en cuanto al ruido que presenta la original. En cuanto a la imágenes en negativo, el modelo hace un buen trabajo en detectar los objetos de la imagen y colorearlos acorde a lo detectado.
CONCLUSIÓN
Este proyecto de Deep Learning nos permitió familiarizarnos con ciertas técnicas de manipulación de imágenes, código en Python, librerías especializadas en Deep Learning así como técnicas de entrenamientos de modelos en ciencia de datos, usando la Inteligencia Artificial aplicándola a las fotografías. Los resultados son aceptables considerando las limitaciones en tiempo de entrenamiento así como en GPU que se tuvieron. Vimos que el modelo puede trabajar tanto con negativos fotográficos como con fotografías antiguas en blanco y negro que pudieran presentar degradaciones leves o fuertes. Sin embargo, queda mucho margen de mejora como por ejemplo vimos que algunas restauraciones de negativos tienen un tinte azul de fondo, probablemente debido al hecho de haber utilizado negativos solo creados artificialmente y no “reales”. Estos negativos pueden presentar diferentes calidades químicas, de material… que pueden variar por modelo o marca. De igual manera es probable que utilizar imágenes degradadas reales aumente el poder del modelo.
BIBLIOGRAFÍA
- VOC2012 DataSet — http://host.robots.ox.ac.uk/pascal/VOC/voc2012/
- Image Colorization DataSet — https://www.kaggle.com/aayush9753/image-colorization-dataset
- https://www.fast.ai/2019/05/03/decrappify/
- Ziyu Wan, Bo Zhang, Dongdong Chen, Pan Zhang, Dong Chen, Jing Liao, and Fang Wen. Old photo restoration via deep latent space translation. arXiv preprint arXiv:2009.07047, 2020.
Silvana Dávila

Presentación del proyecto: DemoDay
¡Más Inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!