La IA está presente en nuestras vidas, pero, ¿qué es la IA? ¿Qué es eso llamado inteligencia artificial? Podemos haber oído el concepto “inteligencia artificial” muchas veces en la televisión, en redes sociales, en el periódico… Pero, no sabemos qué es exactamente: ¿una inteligencia que tienen las máquinas? ¿las hace inteligentes? ¿van a dominar el mundo gracias a esta inteligencia las máquinas? Nada más lejos de la realidad.
La inteligencia artificial está presente en nuestras vidas y va a ser clave en los próximos años en el progreso económico, político y social. Por ello, aquí vamos a ver una definición y caracterización sencilla y entendible de la Inteligencia Artificial, también llamada IA y sus diferentes tipologías.
Breve conceptualización
Si consultamos varios artículos de prensa o académicos nos da la sensación de que no hay una definición homogénea. Lo que solemos entender es que si hablamos de Inteligencia Artificial hablamos de cómo una máquina reproduce las funciones cognitivas humanas, cómo si esas máquinas supieran cómo funciona el cerebro humano. Se desarrolla a partir de algoritmos y se entrena con datos observables, que pueden ser públicos y encontrarse, por ejemplo, en internet o peuden ser privados, producidos por una empresa.
Por otro lado, la definición que nos ofrece la Unión Europea (UE) “«inteligencia artificial» (IA) se aplica a los sistemas que manifiestan un comportamiento inteligente, pues son capaces de analizar su entorno y pasar a la acción –con cierto grado de autonomía– con el fin de alcanzar objetivos específicos” (COM/2018/237 final, Bruselas, 25.4.2018). Y aunque esta definición puede aterrizarnos, como vimos en otro artículo, no hemos de preocuparnos si no lo entendemos del todo, la definición en sí es confusa.
Sin embargo, no podemos olvidarnos de cómo surgió. 1956 y Darmouth, donde se organizó un taller que reunió a grandes pensadores de las redes neuronales, teoría de los autómatas y estudio de la inteligencia., del que saldría la disciplina de la inteligencia artificial. protagonistas de este hecho fueron Allen Newell, Herbert Simon, Marvin Minsky, Arthur Samuel y John McCarthy. Más tarde vendrán los grandes enfrentamientos entre máquinas y ajedrecistas. En la década de los 70, Terry Winograd desarrolla un programa que interrogaba y daba órdenes a un robot que se movía dentro de un mundo de bloques. Ya a partir de los años 2000 entrará IBM y sus supercomputadores, y actualmente no hemos de perder de vista los desarrollos de OpenAI.
Pero, no hemos de olvidarnos de los orígenes más antiguos que podemos rastear de la Inteligencia artificial. Podemos rastrear sus orígenes en Aristóteles y Ctesibio de Alejandría. Ya que, el primero propuso una serie de reglas que guiarían nuestra mente para llegar a conclusiones racionales; y el segundo, construyó una de las primeras máquinas autocontrolada de manera racional, pero esta no poseía razonamiento como tal.
Diferentes categorías de la IA
En otros artículos ya hemos mencionado algunas cuestiones acerca de la categorización de la IA y sus diferentes niveles de riesgo. Pero aquí, para comprender mejor qué es la inteligencia artificial, hemos de tener en cuenta las siguientes categorías en las que se puede clasificar la IA, según Stuart Russell y Peter Norvig:
Sistemas que piensan como humanos. Intentan emular nuestro pensamiento y sus procesos.
Sistemas que actúan como humanos. Intenta emular nuestras acciones y comportamiento, como por ejemplo la robótica.
Sistemas que piensan racionalmente. Intenta emular nuestro pensamiento lógico-racional que haría posible los dos puntos anteriores.
Sistemas que actúan racionalmente. Intenta emular el comportamiento racional humano, lo que podría entenderse como una comprensión y unión de los tres puntos anteriores.
Además, hemos de tener presente también la diferenciación entre inteligencia artificial convencional y computacional. Mientras que la primera es conocida como una IA simbólico-deductiva, la otra es conocida como una IA subsimbólica-deductiva. La IA simbólica deductiva se basa en un modo de operar, tal y como su nombre indica, deductivo; se basa en un análisis formal y estadístico, a partir del cual escoge la solución a un determinado problema. Puede autorregularse y goza de autonomía. Mientras que la IA subsimbólica- deductiva, que se basa en el desarrollo o aprendizaje interactivo, que toma como base datos empíricos.
Para reflexionar
No podemos dejar de pasar por alto que aún no hay una definición explícita y clara sobre lo que es la Inteligencia Artificial. De hecho, actualmente, en vez de hablar en hablar de IA, se habla de Machine learning o Deep learning. Aunque, los últimos avances en IA buscan el Reasoning Learning, no sólo se busca que «sepan» sino que sean capaces de relacionar conceptos entre sí, es decir, intentan emular el «razonar» humano. ¿Curioso verdad?
Alguno de los campos donde tiene una mayor aplicación la inteligencia artificial es en los juegos, medicina, transportes, atención al cliente, medicina, finanzas, industria y , como no, la computación. Sin embargo, en los siguientes años seguro que nos la encontramos en sitios tan dispares como puede ser un restaurante, la tienda de al lado de nuestra casa o en la oficina del ayuntamiento de nuestra ciudad.
Por ello, si quieres saber más sobre IA y conocer qué es el Machine Learning, echa un vistazo a nuestra web para comenzar a formarte en Inteligencia Artificial.
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education
¡Cómo nos ha cambiado la vida en los últimos años!
Una pandemia mundial, un asalto a la Casa Blanca, una Filomena, una erupción de un volcán, hasta el comienzo de un conflicto entre naciones ? ¡… y un curso de IA en Zaragoza!
Una ventosa tarde de viernes, tres intrépidos zaragozanos comenzamos nuestra andadura en este ámbito.
Somos el equipo Aragón Feliz, venimos de diferentes mundos, pero compartimos un interés común por la Inteligencia Artificial, y buscamos ampliar y aplicar los conocimientos adquiridos durante el programa de Saturdays AI. El equipo está conformado por:
· Fernando Jiménez
· Héctor Soria
· Virginia Navarro
Y gracias a la ayuda de nuestros mentores del programa Saturdays IA, que nos han dado la base, hemos podido acometer este proyecto.
Cuando desde Saturdays AI-Zaragoza nos plantearon desarrollar un proyecto basado en IA, nos planteamos varias preguntas.
Y es que la contingencia sanitaria Covid-19 ha ocasionado circunstancias excepcionales con alto impacto en la sociedad, confinamiento masivo, soledad, incertidumbre, crisis económica, sanitaria y social, lo cual ha generado diferentes tipos de reacciones en la población, incrementando las patologías presentes tanto físicas como psíquicas, problemas económicos, entre otros.
Los datos están claros, toda esta situación ha tenido un alto impacto ya en la sociedad y probablemente se irá manifestando todavía más a lo largo de los próximos años.
A nosotros personalmente nos preocupa, pero… ¿es algo que preocupa?
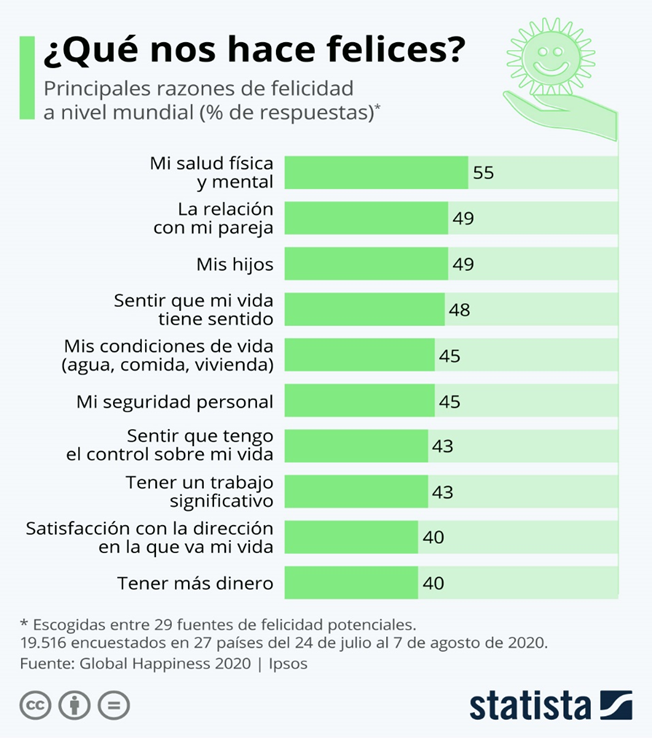
Diferentes fuentes muestran que sí, que es un tema que preocupa en todos los rangos de edades, veamos por ejemplo esta encuesta realizada a un perfil más joven.
Pero ¿qué podríamos hacer nosotros?, ¿cómo podríamos revertir este efecto?, ¿cómo podríamos hacer que la balanza se inclinara hacia el otro polo opuesto: la Felicidad?
Para empezar, ¿qué es la Felicidad y cómo concretamos esa Felicidad? ¿Qué es lo que a cada uno de nosotros nos hace felices?
Según esta encuesta podemos ver qué aspectos concretos se valoran cuando se piensa en Felicidad.
Y las siguientes preguntas que nos surgieron entonces fueron:
¿Cómo estábamos antes?
¿Cómo estuvimos durante los picos más altos de la pandemia?
¿Cómo se fue modulando ese estado conforme íbamos navegando en las olas y en las diferentes curvas?
¿Cómo estamos ahora realmente?
En definitiva …
¿Cómo tomamos consciencia del viaje emocional que hemos sufrido?
¿Cómo lo hemos ido concretando en el lenguaje?
Pero sobre todo…
¿Cómo lo traducimos a algo medible que poder analizar?
¿Somos capaces de anticiparnos y a través de las palabras, detectar estados y lanzar posibles alertas que con las debidas herramientas faciliten el cambio?
¿Cuál es el problema a resolver?
Nuestros primeros planteamientos
Con todas las preguntas anteriores fuimos conscientes de la magnitud del problema que estábamos considerando.
Para empezar, ¿cómo íbamos a poder medir todo esto? ¿Es posible generar algún indicador e información oportuna acerca del impacto emocional en las personas y de cómo éstas, consciente o inconscientemente, lo reflejan a través de su lenguaje?
¿Es posible a través de algoritmos de análisis de sentimientos y tópicos, detectar preocupaciones relacionadas con la contingencia sanitaria, así como otras situaciones a nivel general que le pueden afectar a cada individuo?
Uno de los principales handicaps al que nos enfrentamos es la correcta interpretación del lenguaje, para lo que existen numerosas técnicas y recursos dentro del PLN (Procesado del Lenguaje Natural). En nuestro caso, nos enfocamos en el español, un idioma en el que, aunque ampliamente usado, todavía se están desarrollando y mejorando algoritmos y modelos de IA verdaderamente eficientes que den resultados precisos, a diferencia del Inglés.
Bien, después de toda esta reflexión, éste iba a ser entonces nuestro reto inicial.
Problema
Dada la situación de pandemia vivida a lo largo del último año queremos analizar cómo esta situación ha podido afectar a la percepción general a nivel psicológico de los ciudadanos de Aragón, y cómo ha podido influir este estado respecto a diferentes temáticas (inferidas o prefijadas) en sus comentarios en diferentes medios, redes sociales, prensa, etc.
Quizá, ¿demasiado ambicioso?…
Quizá sí, por lo que intentamos acotar nuestro alcance y a partir de ahí evaluar si era viable realizarlo, por lo que nos centramos en el siguiente problema.
Problema acotado
Existe una alta complejidad a la hora de realizar un análisis de sentimientos (necesidad de datasets etiquetados manualmente por parte de expertos, tiempo para realizar esta anotación manual, la ambigüedad del lenguaje y subjetividad de las emociones, impacto del idioma con el que vamos a trabajar y alto riesgo de errores). Siendo conscientes de esta complejidad, desarrollamos nuestros objetivos principales.
¿Cuál es nuestro objetivo?
Objetivo realista
Brindar a la sociedad una herramienta que dé una clasificación o etiquetado automático de la Felicidad y subsane la complejidad de una evaluación manual, facilite esta labor y reduzca la ambigüedad y el error.
Demostrar que la herramienta es viable y desarrollar toda la metodología necesaria para llegar a ese etiquetado automático.
Objetivo WOW
Desarrollar un modeloque analice la evolución del sentimiento de los ciudadanos en Aragón respecto a diferentes temáticas (extraídas del propio contexto o predefinidas en base a una categorización estándar), teniendo en cuenta diferentes fuentes como redes sociales, prensa, etc. Y en función del análisis llevado a cabo, que realice recomendacionesy proporcione herramientas con el objeto de mitigar el impacto negativo en su estado emocional.
Disponible para público general, organismos públicos y medios de comunicación.
Objetivo con Impacto Social
Nuestro eje rector está englobado dentro de los Objetivos de Desarrollo Sostenible, en concreto en el 3. Salud y bienestar, aunque al ser tan amplio tiene repercusión en muchos más objetivos.
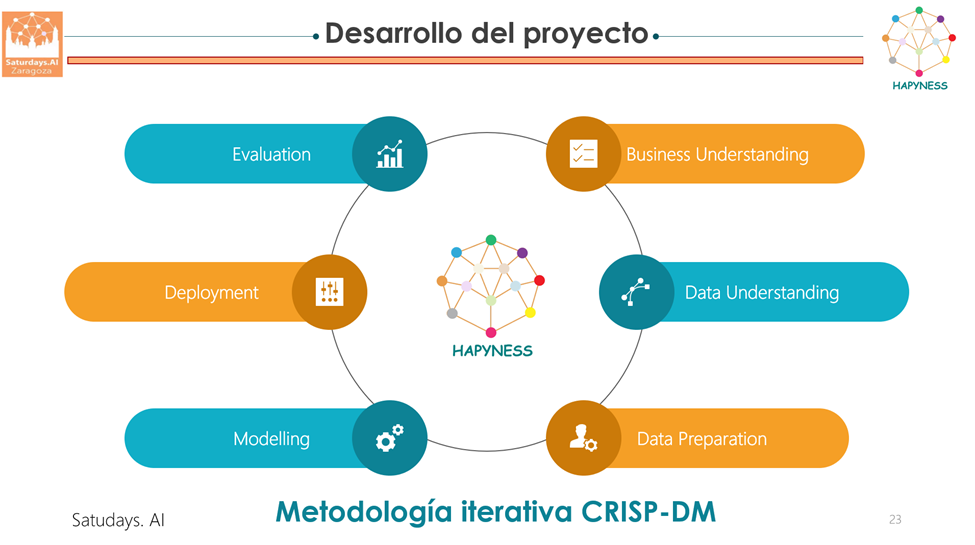
Para la ejecución del proyecto hemos seguido la siguiente metodología iterativabasada en el estándar CRISP-DM (Cross Industry Standard Process for Data Mining).
En este momento del proyecto, trabajamos en la identificación de recursos, restricciones, problemáticas y procesos involucrados.
Como hemos ido comentando, sin duda el periodo de pandemia ha sido una etapa de alto impacto emocional, pero en este concepto tan global, ¿entendemos todos de la misma forma estas emociones?
Trabajaremos sobre textos escritos, por lo que comenzamos a plantearnos qué posibles problemas nos podíamos encontrar a la hora de gestionar y analizar este tipo de información.
Además, nuestro modelo, en la medida de lo posible, debería reconocer y considerar diferentes fenómenos lingüísticos relevantes para interpretar de forma autónoma la opinión de los usuarios. Así, en la práctica, debería tener en cuenta y poder reconocer la ironía, la negación y las emociones, entre otras cuestiones.
Como reflexión final, por todo lo anterior, vimos clara la dificultad de extraer las emociones de los textos, lo cual nos llevó a plantearnos construir un diccionario propio y como primera aproximación plantearnos un algoritmo de clasificación semi-automático.
Fase II. COMPRENSIÓN DE LOS DATOS
Y continuamos con los datos, el caballo de batalla de todos los proyectos.
A. Fuentes de datos y problemáticas en su obtención
No contábamos con un dataset etiquetado específico de Aragón y sobre la pandemia y nos planteamos cómo resolver el problema sin utilizar textos de otros ámbitos y épocas. Pero, aun así, se han utilizado los disponibles para hacer una comparación cualitativa de nuestra solución.
Encontramos diferentes fuentes de datos que podrían sernos útiles y estuvimos navegando en ellas para ver cuál podría sernos más valiosa, ya que necesitábamos un dataset previamente categorizado.
Inicialmente utilizamos el corpus de TASS, por lo que acudimos a la Sociedad Española de Procesamiento del Lenguaje Natural (SEPLN), a través de la cual se creó el TASS, que es un Taller de Análisis de Sentimiento en español organizado cada año http://tass.sepln.org/
La carpeta con los datos fue solicitada a la organización y se nos concedió el permiso para usarla.
Revisando la data nos encontramos con diferentes archivos de tweets, agrupados por países y años. No todos tienen la misma categorización, diversos archivos tienen diferentes esquemas dependiendo de que edición del TASS sean, algunos de ellos están etiquetados con su sentimiento (polaridad — positivo/negativo/neutro-, o con emociones como feliz/triste).
Los archivos del corpus están en formato XML, que hemos procesado y adaptado para que nuestro modelo lo comprenda, transformando los datos a un formato .csv, “Comma Separated Values”, para poder proceder con la siguiente fase.
Datos no etiquetados
En cuanto a los datos para evaluar el modelo seguimos dos vías:
1) Por un lado volvimos a utilizar los datos de test del Corpus TASS, cuyaestructura de los archivos es similar a esta:
2) y por otro recopilamos datos directamente desde Twitter gracias a la herramienta Tweepy que nos permitió realizar la búsqueda de publicaciones de usuarios en esta red social a través de su API, durante el periodo de pandemia. La selección de publicaciones se realizó con los siguientes criterios: Aragón, covid, fecha, geolocalización,…
Para poder hacer este proceso, creamos una cuenta en Twitter/desarrollador para poder empezar a descargar los tweets.
Tardaron un poco en darnos acceso, pero finalmente lo conseguimos y pudimos seguir avanzando en esta parte.
La estructura de los archivos es similar a esta:
B. Características que nos interesaría considerar
Y empezamos a considerar qué variables podrían ser relevantes en nuestro estudio para ayudarnos a conseguir nuestro objetivo (aunque probablemente no dispongamos de todas ellas).
Fase III. PREPARACIÓN DE LOS DATOS
Análisis exploratorio de los datos (EDA)
Para nuestro análisis, el dataset inicial cuenta con la siguiente descripción:
Como hemos mencionado, el corpus contiene múltiples niveles de polaridad. No obstante, hay diferencias entre diferentes archivos, por ejemplo, algunos archivos sólo tienen los niveles Positivo, Negativo y Neutral, mientras que otros incluyen un nivel adicional denominado None.Por lo tanto, si quisiéramos trabajar con todos los archivos conjuntamente, deberíamos convertir la polaridad en una variable dicotómica (binaria) con los valores (Positivo=1, Negativo=0).
En nuestro caso, partimos de los que partían de positivo-negativo para pasar después a Feliz-Triste, que se adecuaba más a la categorización que podríamos conseguir de nuestro diccionario que está asociado a los términos Felicidad/Tristeza
Pretratamiento y limpieza de los datos
Previo al análisis y modelado necesitamos hacer un proceso de eliminación de ruido y normalización.
Creamos la funcion limpia_tweet() que va a eliminar stopwords y algunos caracteres peculiares de Twitter, posteriormente fuimos ajustando esta limpieza debido al ruido de la data y a los problemas que nos iba planteando el código.
1. Se eliminaron las stopwords como: de, con, por, …entre otras.
2. Se eliminó cualquier tipo de mención, RTs, #, links, URLs.
3. Se eliminó cualquier tipo de puntuación.
4. Se buscaron abreviaturas y textos con jergas cibernéticas como: “u” para “you”, “ur” para “your”, “k” para “que”, entre otras.
5. Se eliminaron emojis, y cualquier tipo de valor alfanumérico, caracteres numéricos, vinculados a monedas, porcentajes, etc…
6. Se exploraron los datos, analizando las palabras más comunes en los Tweets.
Una vez que se ha realizado el proceso, el texto limpio se almacena en una nueva columna ‘tweets_transform’:
Procesamiento del texto
Para poder tratar matemáticamente los tweets preprocesados, tenemos que extraer y estructurar la información contenida en el texto. Para ello, usaremos la clase sklearn.feature_extraction.CountVectorizer. CountVectorizer convierte la columna de texto en una matriz en la que cada palabra es una columna cuyo valor es el número de veces que dicha palabra aparece en cada tweet.
De esta forma podemos trabajar con estos vectores en vez de con texto plano.
Para cada tweet realizaremos el siguiente proceso:
1. Tokenización: este paso convierte una cadena de texto en una lista de palabras (tokens) 2. Conversión a minúsculas 3. Eliminar stopwords. Se llama stopwords a las palabras que son muy frecuentes pero que no aportan gran valor sintáctico. Ejemplos de stopwords en español serían: de, por, con… 4. Filtros semánticos (Stemming/lematización) es el proceso por el cual transformamos cada palabra en su raíz. Por ejemplo, las palabras maravilloso, maravilla o maravillarse comparten la misma raíz y se consideran la misma palabra tras el stemming.
5. Creación de una bolsa de palabras.
Con WordCloud visualizamos las palabras más utilizadas en el dataset:
Verificación de la calidad de los datos
Comprobamos si con estos datos nos es suficiente o es necesario tratar algún dato más (data, geolocalización, etc..) o construir nuevos datos a partir de la información existente (valoración).
Construcción de una estructura de datos para el posterior entrenamiento y evaluación del modelo
A. Datos de geolocalización
B. Datos Fecha. Transformación para adecuarlos al formato necesario para la gráfica de evolución.
Fase IV. MODELADO
¿Cómo lo podemos abordar?
Variante 1: Resolver el problema con técnicas de clasificación, específicamente “análisis de sentimiento”, que tiene como clases o etiquetas de sentimiento: “positivo”, “negativo” o “neutral”. Para ello, será necesario conseguir un data set con dichas etiquetas que estén relacionadas con Aragón (por ejemplo, data sets de Twitter) o buscar información textual (por ejemplo, periódicos regionales, etc.) y previamente clasificarlos usando etiquetas de sentimiento (a través de un proceso manual, o bien automatizado usando diccionarios).
Variante 2: Resolver el problema aplicando técnicas de agrupamiento. En este caso, sería necesario recopilar información textual (por ejemplo, periódicos regionales, Twitter, etc.) y agrupar la información, y analizar estos grupos.
A. Modelo de valoración basado en el diccionario (clasificación semi-supervisada)
Creación de un diccionario
Con el objetivo de poder hacer este proceso de clasificación semi-automática necesitábamos disponer de un diccionario con el que poder comparar y clasificar. Ante la dificultad de encontrar uno especialmente válido en castellano, decidimos crear nuestro propio diccionario, y estos fueron los pasos que fuimos siguiendo:
Realizamos un análisis del sesgo palabras (30% Positivas 70% Negativas).
Realizamos una valoración del volumen de palabras 3000 (ya que podría influirnos después en el procesamiento y ejecución del código)
Búsqueda de alternativas. Valoración posibilidad de utilizar un diccionario reducido.
Decisión sobre el diccionario final.
El diccionario está incialmente basado en 3000 palabras relacionadas con ‘felicidad’ y ‘tristeza’.
Tras el post procesado intensivo de las mismas y formateado, se ha ajustado el vocabulario a las 2600 palabras con la menor ambigüedad posible.
Las 3000 palabras han sido revisadas manualmente, para eliminar ambigüedades y errores de valoración.
En la generación de este diccionario, siguiendo este documento de referencia, que explica cómo extraer características relevantes de un corpus textual:
Utilizamos countvectorizer: convierte textos (= tweets procesados) en filas, los pasa a minúsculas (pero conserva los acentos), y en cada columna aparecen las palabras utilizadas (su frecuencia en la frase), en orden alfabético. El ejemplo que se muestra aquí es muy sencillo.
Del objeto resultante podemos extraer:
– un diccionario con las palabras encontradas (se obtiene directamente mediante ‘vectorizer. vocabulary’)
– la matriz para analizar, con las frecuencias (en unos pasos sencillos)
Problemática:
Había miles de palabras y llevó mucho tiempo, por lo que, del resultado inicial, decidimos acotarlo a las pestañas más útiles (son las amarillas), suficientes para valoración “Feliz/Triste”, ya que trabajar con más valores (Muy feliz, feliz, triste, muy triste) nos implicaría mucho más tiempo de desarrollo y queríamos avanzar en el resto de la metodología y evaluación de nuestra solución. Los datos de entrada a este proceso se muestran a continuación, donde junto con el diccionario elaborado manualmente se analiza el corpus etiquetado y mapeado a las etiquetas de Felicidad/Tristeza para completar el vocabulario de valoración.
Creamos un modelo que ejecuta el siguiente algoritmo:
a. Importa el vocabulario
· Prepara stopwords españolas del vocabulario
· Aplica funciones steemer
b. Prepara el vocabulario stemmed
c. Lee los tweets
d. Aplica filtros limpieza
e. Valora sentimientos sobre los textos con el vocabulario steemed, creando un nuevo campo valoración calculada.
f. Guarda los tweets valorados en ficheros distintos según el resultado comparativo frente a los textos etiquetados (Ok, errores, sospechosas)
Ejemplo de comparación entre valoración semi-automática y manual
Con respecto al fichero con las palabras sospechosas, realizamos un análisis del mismo para comprobar si nuestro proceso estaba funcionando correctamente.
Palabras sospechosas
Nos dimos cuenta de que las que salían tenían cierto sentido, si se quitaban parece que podría empeorar, por lo que haría falta tener otra lista “palabras interesantes”, donde mirar antes de quitarlas, lo cual suponía un esfuerzo adicional considerable, por lo que decidimos abordarlo posteriomente si nos daba tiempo.
Como causa considerábamos que sin contexto las palabras son muchas veces ambiguas, por lo que como con lo que habíamos obtenido hasta ese momento, obteníamos un 60% acierto, y no parece fácil de aumentar cuantitativamente, decidimos continuar con el fichero OUT_es con las dos columnas (Valoracion_corpus y Valoracion_calculada) con el que podríamos alimentar la parte de IA.
B. Modelos tradicionales de Machine Learning (clasificación supervisada)
El objetivo de este problema de Machine Learning es predecir el sentimiento de los tweets incluidos en nuestro fichero usando el corpus de TASS como training data (datos para entrenar al modelo predictivo).
Hay que puntualizar que el dataset se ha divido en TRAIN y EVAL/DEV
Las 15 palabras más utilizadas antes del stemming
Representación Numérica
Después del stemming, creamos una bolsa de palabras (Bag of Words, BoW), que es una representación de cada documento en base a las palabras únicas que aparecen entre todos los documentos disponibles, a partir de la unión de todas las frases junto con la cantidad de veces que aparece cada palabra.
Con la idea de compensar aquellas de mayor frecuencia, aplicamos TF-IDF (TermFrequency–Inverse DocumentFrequency), que nos indica la relevancia de un término en el documento, teniendo en cuenta el ámbito en el que se suele usar (corpus).
Selección Algoritmos ML
A continuación listamos el conjunto de algoritmos de aprendizaje automático que hemos considerado en esta fase (se ha utilizado el etiquetado manual original como clases verdaderas):
Random Forest Classifier
SVM
XGBoost
Aplicación teniendo en cuenta el módulo Valoración
Random Forest
SVM
XGBoost
Dado que RF es el que mejor resultado da con la valoración humana, en términos de clasificación, quisimos mejorar el modelo de RF para la valoración algorítmica. Para ello empleamos un GridSearchCV en los dos tipos de valoración, humana y algoritmia. En el caso de la valoración humana parece que no se mejora el resultado, parece que estamos en el máximo valor alcanzable aunque también es probable, que sea un máximo local y no global.
Por otro lado, en la valoración algorítmica conseguimos mejorar el resultado del modelo, usando los mismos parámetros de calidad: Accuracy, Recall, Precision y F1.
☝ ¡eh! ¡que mejoramos de forma significativa! Vamos a guardar el modelo, por si las moscas ?
C. Agrupamiento…
Aplicamos el modelo Kmeans, pero lo cierto es que no nos resultó demasiado útil, no conseguimos conclusiones demasiado claras ni obtuvimos conjuntos de términos muy claros, quizá podríamos conseguir mejores resultados realizando una labor adicional de limpieza de datos o quizá tener más volumen de tweets como para poder sacar conclusiones.
TSNEt-DistributedStochasticNeighborEmbedding
Para poder visualizar palabras en 2D vamos modificando diferentes parámetros de la función word2vec. Las que más influencia tienen en nuestro sistema son el número máximo de palabras consideradas y el número de veces que una palabra tiene que estar repetida en el texto para ser considerada representativa. Como podemos ver en la representación de tsne, es difícil sacar conclusiones. Se debería limpiar mejor el texto para evitar la dependencia de los acentos o terminar de eliminar caracteres que solo añaden ruido como ‘ji’ o ‘san’.
D. Aplicación sobre datos de TEST (no etiquetados)
Seguimos los mismos pasos sobre los tweets obtenidos y no etiquetados previamente para evaluar la potencia de los modelos ante textos no vistos previamente y de otros dominios. A continuación vemos los resultados.
Partimos de un análisis exploratorio de los datos y pretratamiento de los mismos.
Vemos cuáles son las palabras más comunes
Aplicamos el módulo de valoración para obtener la valoración calculada:
Aplicamos ahora modelos de Machine Learning y analizamos resultados (tomando como referencia la valoración calculada):
Random Forest Classifier
SVM
XGBoost
El modelo de RF, de nuevo, es el más prometedor, por lo que volvemos a usar GridSearchCV para ver si podemos mejorar la clasificación.
? no hay mucha mejora que digamos, parece que no es muy bueno generalizando…
Entre los diferentes modelo de ML utilizando directamente las clases etiquetadas manualmente, el SVM es el que arroja unos resultados ligeramente superiores.
B. Comparación de modelos de ML vs Valoración
Se puede observar que el modelo de valoración tiene un desempeño próximo a los modelos automáticos tradicionales de ML.
C. Evaluación sobre tweet directamente obtenidos
Evaluación de los resultados de los modelos en relación con la evaluación de tweets no etiquetados previamente
Utilizando los mejores modelos previamente entrenados y guardados (model.pkl), se observan algunas diferencias:
Por tanto: comparando los modelos en distintos escenarios
Como se puede ver en la imagen, el valorado automático en una muestra de novo tiene una menor capacidad de clasificación que en la muestra original. La heterogeneidad de la muestra y una limpieza menos eficaz conlleva una menor potencia.
D. Análisis de la variación de la percepción Felicidad/Tristeza
Transformamos el campo fecha, y clasificamos aquellos tweets que pertenecen a una fase precovid o que corresponden a la etapa covid
Se observa un mayor desequilibrio en la etapa covid, con comentarios más cercanos a la tristeza que en el periodo precovid, donde a pesar de predominar la tristeza los resultados eran mucho más cercanos
Visualización de la evolución
Vemos que aplicando Machine Learning el resultado predice tweets más negativos, en general.
Fase VI. Despliegue
Para la puesta en producción de los modelos finales y los resultados obtenidos, utilizamos Streamlit que es una librería de Python de código abierto que facilita la creación y el uso compartido de aplicaciones web personalizadas para el aprendizaje automático y la ciencia de datos.
Nuestra aplicación en streamlit es un Valorador de felicidad que te permite realizar el análisis del texto que introduzcas, dando como resultado la valoración del mismo, así como las palabras que han determinado esa valoración.
Por otro lado, permite la visualización de la evolución de los sentimientos en cuanto a Felicidad/Tristeza en la muestra seleccionada.
Conclusiones
Las conclusiones obtenidas tras el desarrollo y resolución del objetivo general son:
Con respecto a las vinculadas con nuestros objetivos:
Hemos conseguido desarrollar una herramienta de etiquetado automático para Felicidad y tristeza con un porcentaje de acierto satisfactorio (63% respecto al corpus y de un 53,2% con respecto al modelo de Machine Learning respecto al etiquetado automático), que puede facilitar la labor y evitar la complejidad de un etiquetado manual.
Además, hemos desarrollado un modeloque analiza la evolución del sentimiento en este caso de los ciudadanos en Aragón respecto a las emociones felicidad y tristeza inferidas de sus comentarios en rrss, que nos permite ver claramente el impacto que la pandemia u otros acontecimientos significativos han tenido en su percepción y bienestar.
A nivel general, las principales conclusiones que hemos obtenido son:
– El concepto de Felicidad y Tristezano es común a todas las personas tanto en la expresión como en la evaluación, por lo que esto puede afectar en la valoración por la dificultad de estandarizar la expresión de un sentimiento.
– La complejidad de interpretación de los tweets es tan grande que puede tener un gran impacto tanto la subjetividad de la persona como la del momento de la evaluación. Para solucionar este se podría realizar una votación entre varias personas a nivel de vocabulario y a nivel de tweets.
– Riesgo de confusión entre positividad-negatividad y felicidad -tristeza a la hora de valorar las palabras.
– Sesgo de la fuente elegida Twitter (redes sociales más tendenciosas que otras, mensaje de 280 caracteres puede limitar la expresión de la emoción, ¿accesible a toda la tipología de la población?).
– Sesgo en el lenguaje, que se traslada a nuestro diccionario. Ponderación de las palabras felices y tristes (30 -70).
– Riesgo de pérdida de información en el pretratamiento: En el proceso de pretratamiento de los tweets con objeto de facilitar el proceso, hemos eliminado elementos que nos podrían ampliar el análisis, por ejemplo, emoticonos o hahtags (#), con lo que puede que se haya desvirtuado la valoración final (fase evolución 20.0).
– Importancia del contexto en el análisis y la valoración.
– El resultado de los tres modelos que hemos utilizado han sido muy parecidos, aunque el modelo Random Forest parece que es el que mejor se adapta a la clasificación y dominio bajo estudio, a tenor de los resultados, puede deberse al volumen de la muestra, aunque se podría evolucionar buscando mejores parámetros en SVM y XGboost o probar redes neuronales.
– Existen numerosas técnicas y recursos dentro del PLN (Procesado del Lenguaje Natural) en inglés, pero no están tan desarrolladas en español, lo cual dificultaba en nuestro caso la aplicación.
Mejoras y Evolución
Como posibles propuestas de evolución de la herramienta
ML Funcionalidades del análisis:
Explorar y analizar más en profundidad los resultados de Kmeans
Explorar y analizar las opciones que brindan los Word Embeddings
Mejorar resultados de los modelos con hiper parámetros
Utilizando técnicas de NLP realizar búsquedas semánticas (agrupación-clusters, tópicos, similitud de perfiles, predicción de tendencias)
Explorar redes neuronales
Fuentes:
Extender el análisis a mayor volumen de tweets
Aplicar nuestro modelo a otra tipología de fuentes (redes sociales, prensa,…)
Análisis de las cuentas que generan los tweets
Análisis de emociones:
Ampliar el diccionario a más categorías de emociones
Incorporar análisis emoticonos, hashtag en la valoración
Incorporar análisis del sarcasmo y la negación en la valoración
Incorporar análisis del contexto (del mismo tweet y del contexto del propio tweet)
Incorporar análisis emocional
Análisis personalizado tweets vinculados a una persona para la valoración de su estado emocional
Visualización:
Incorporar mapas de geolocalización de los tweets para análisis de valoraciones por zonas.
Gráfico radial de análisis emociones personalizado
Alertas y recomendaciones:
Sistema de alertas en función del estado emocional.
Recomendación temáticas concretas adaptadas a ese análisis personalizado.
Recomendaciones genéricas accesibles a todos los perfiles
Identificación perfiles críticos y alertas asociadas (prevención del suicidio, índices depresión…)
Agradecimientos
A todo el equipo de Saturdays AI, y sobre todo al equipo de Saturdays AI Zaragoza, en especial a Rosa Montañés, Mª del Carmen Rodríguez, Rocío Aznar y Rafael del Hoyo ya que sin ellos no habría sido posible.
La experiencia ha sido muy agradable y recomendable, con una metodología de aprendizaje muy efectiva basada en la práctica, ¡Gracias por todo vuestro apoyo, paciencia y dedicación!
Y a ti, por haber llegado hasta aquí en la lectura del artículo.
Se puede encontrar el código de este proyecto en GitHub
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
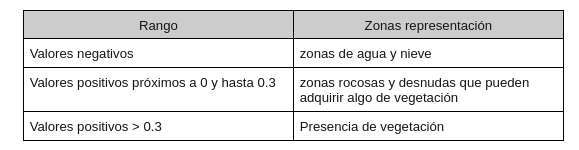
La desertificación se produce por la degradación de la tierra que se da en zonas secas: áridas, semiáridas y subhúmedas secas. La actividad humana y las variaciones climáticas están entre las causas de esta degradación del suelo, que impacta en los ecosistemas y en los recursos y modos de vida de los habitantes de las zonas afectadas. Estas zonas secas son aquellas con un índice de aridez (IA=P/ETP) inferior a 0,65.
España es uno de los territorios que sufre esta problemática. En Aragón el 75% del territorio está en riesgo de desertización. El cambio climático y el incremento de las temperaturas amenazan las tierras semiáridas que predominan en el Valle del Ebro, desde la ciudad de Huesca hacia el sur. Identificar a tiempo estas zonas será de gran ayuda para el apoyo a la toma de acciones que permitirán mitigar el impacto que la desertificación trae sobre la seguridad alimentaria así como la reducción de la pérdida de hábitats naturales y biodiversidad, todo esto, alineado con los Objetivos de Desarrollo Sostenible de Naciones Unidas.
Para identificar estas zonas se propone un proceso que gestione el reconocimiento mediante imágenes satelitales de las zonas de desertificación en Aragón y permita realizar una aproximación a la predicción de posibles futuras zonas desérticas con el objetivo de aplicar políticas más eficientes referentes a la reforestación de las zonas afectadas, y nuevos tratamientos de cultivos. Con apoyo de la iniciativa Saturdays.AI Zaragoza, cuyo objetivo es acercar la IA a todos los ciudadanos y aplicarla a problemas sociales, queremos dar solución o una aproximación a resolver este escenario que nos hemos planteado como equipo de trabajo.
Es entonces, cuando nos planteamos las siguientes inquietudes, ¿Cómo es posible calcular si hay o no desertificación en una zona determinada?, ¿qué imágenes pueden funcionar para este propósito?, ¿Cómo la IA nos puede apoyar para predecir estos valores? A lo largo de este artículo intentaremos dar solución a estas cuestiones.
Imágenes Satelitales
Las herramientas de teledetección hacen posible la visualización y cálculo de cambios que ocurren sobre la superficie terrestre, aquellas que nos interesan, los que corresponden a la teledetección pasiva (Definición de Teledetección), en nuestro caso concreto, captan la radiación solar reflejada por la superficie. Es bien sabido que organismos vivos reflejan y absorben radiación solar en forma diferente a como lo hacen los objetos inertes como calles o edificios. Aprovechando este principio, los satélites generan imágenes que contienen estas diferencias en forma de Niveles Digitales y bandas, que se traducen en unidades numéricas que se corresponden con los valores de longitudes de onda de las diferentes secciones del espectro electromagnético (Espectro electromagnético y teledetección). En resumen, miden la radiación reflejada por objetos como edificios o autopistas o entes vivos como bosques o vegetación en general.
Los cambios en la vegetación con el soporte de las imágenes satelitales se pueden medir de diferentes formas, una de ellas es extrayendo índices de vegetación, “Los Índices de Vegetación son combinaciones de las bandas espectrales registradas por los satélites de Teledetección” (¿Cuál es el índice de Vegetación NDVI?) que permiten identificar vegetación sobre la superficie terrestre. Es allí,con ayuda de estos índices en donde se resaltan y se pueden analizar numéricamente las propiedades de la vegetación como tal.
El NDVI es el Índice de Vegetación Diferencial Normalizado, NDVI por sus siglas en inglés. Este índice es un parámetro calculado que se basa en los valores capturados por el instrumento satelital donde identifica patrones del espectro electromagnético que se corresponden con la reflectividad de coberturas vegetales. Este índice permite ayudar a distinguir fácilmente vegetación en imágenes satelitales.
Los patrones del espectro electromagnético para identificar la vegetación muestran que la vegetación absorbe la sección de radiación solar que corresponde al rojo. A su vez se reflejan valores elevados en el infrarrojo cercano y podremos identificar valores multiespectrales brillantes en esta banda ( Valores Espectrales del NDVI).
Así podemos diferenciar cubiertas vegetales en diferentes estados. Nuestro índice podrá ser obtenido mediante la siguiente relación:
NDVI = (Banda infrarroja cercana — Banda roja) / (Banda infrarroja cercana + Banda roja)
O lo que es lo mismo, y en términos de nomenclatura cuando trabajamos las bandas multiespectrales:
NDVI = (NIR — RED) / (NIR + RED)
Una vez se ha calculado el índice para cada uno de los píxeles de la imagen, los valores posibles oscilan entre -1 y 1.
Valores de NDVI para diferentes zonas. Fuente: propia
Cuanto mayor sea el valor más frondosa será la vegetación hasta adquirir valores próximos a 1.
Manipulando la imagen
Para comprender mejor cómo podemos usar estos valores entre bandas y niveles digitales, es importante identificar las propiedades de una imagen en general y cómo se ven estos valores a nivel de computación.
Derecha: como un ser humano ve una imagen. Izquierda: como la procesa un ordenador. Fuente: Material Satudays.AI, Zaragoza. Edición I. 2021–2022. Tratamiento de Imágenes.
El ordenador o los métodos de computación, estructuran las imágenes en matrices con valores (i,j) estos valores (i,j) representan numéricamente el valor en términos computacionales de dicha coordenada sobre la imagen original (sin digitalizar). Cada uno de estos valores es lo que se denomina “pixel”
Para imágenes satelitales ocurre algo similar,la única diferencia radica en los valores para cada píxel, en este caso representan en niveles digitales para valores de reflectancia de radiación solar (espectro electromagnético) reflejada por el objeto terrestre sobre el cual el instrumento (el satélite) está midiendo.
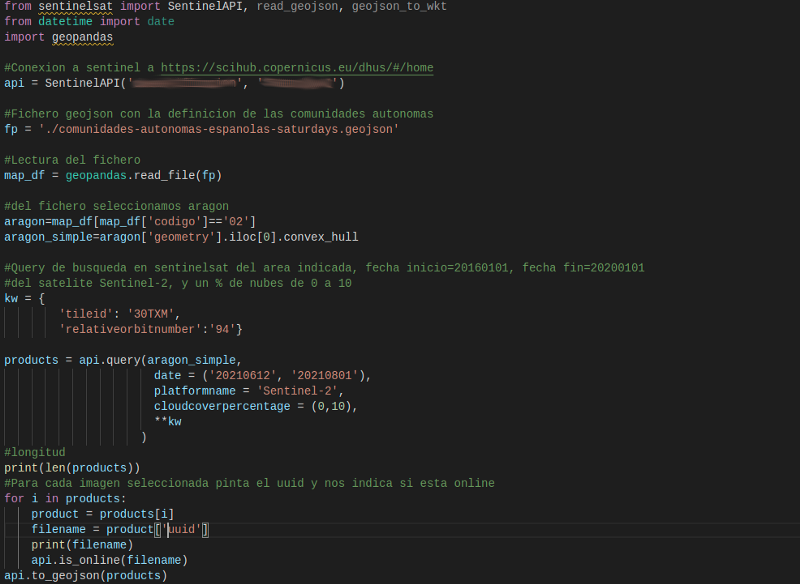
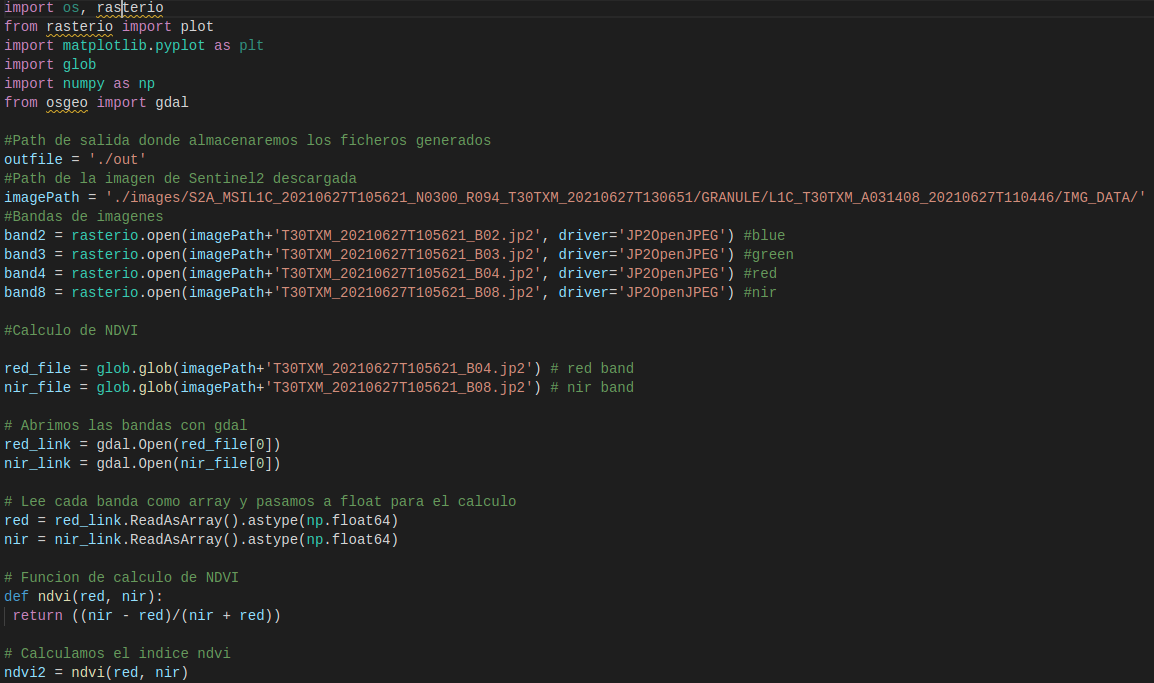
Ya que se hará un análisis sobre cambios en la superficie terrestre, las imágenes satelitales que se eligieron fueron del instrumento Sentinel 2A. Para la obtención de datos usamos la librería de Python SentinelSat para la descarga de imágenes en el área que nos interesa. Es de anotar que las imágenes se han tomado con los siguientes condicionantes: para un área específica detallada en un fichero .json, para la misma tesela (zona de captura de imagen del satélite) y sección de órbita para garantizar que se está tomando la misma zona de estudio para diferentes momentos de tiempo.
Fragmento de código para la descarga de imágenes sentinel del sitio scihub.copernicus.eu Fuente: Propia
NOTA: Para la obtención y captura de los datos se han descargado las imágenes de Sentinel con un porcentaje de nubes máximo de 10%.
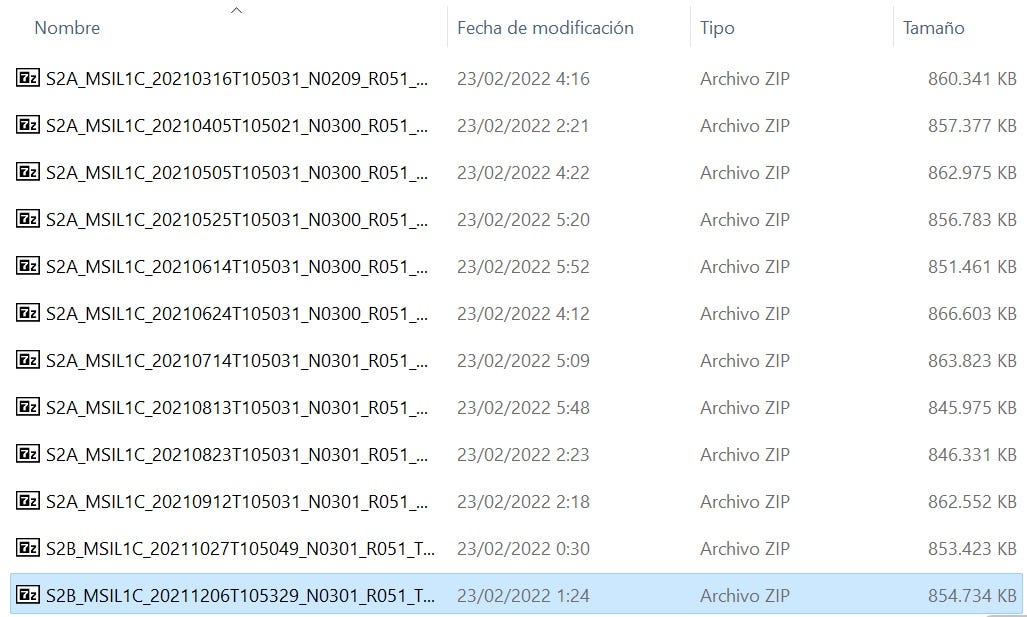
Una vez ejecutado el script para la descarga de imágenes del satélite, se descarga una serie de ficheros zip que contienen cada uno la siguiente estructura al momento de descomprimirlos:
Estructura de fichero descargado del sitio scihub.copernicus.eu Fuente: propia
Cada una de las imágenes Sentinel vienen dadas con un consecutivo de nombre de imagen con la siguiente estructura:
MS2_MSILLL_YYYYMMDD
Donde:
MS2: identifica la misión de Sentinel 2, pudiendo encontrar S2A (para Sentinel 2A) o S2B (para Sentinel 2B)
MSI: indica el instrumento de operación (MultiSpectral instrument)
LLL: indica el nivel de procesado del producto pudiendo encontrar los niveles L0, L1C, L1B o L2A
YYYY: designa el momento temporal UTC (año) en el que fue tomada la imagen
MM: designa el momento temporal UTC (mes) en el que fue tomada la imagen
DD: designa el momento temporal UTC (día) en el que fue tomada la imagen
Las descargas de Sentinel para el proyecto fueron:
Relación de imágenes. Fuente: Propia
Preparación
Una vez obtenidas las imágenes, sobre ellas calcularemos los índices NDVI mediante Script en Python.
Fragmento de código para el cálculo del NDVI para las imágenes descargadas
Para entender la salida de este script, las imágenes con el NDVI calculado (nuevos ficheros tif), se debe tener en cuenta que esta transformación imágenes nos da lugar a una imagen compuesta por una matriz de valores donde cada valor corresponde a un pixel (representación en la imagen) y este valor oscila entre -1 y 1. Recordando el apartado de Índice de Vegetación, a partir de 0.3 entendemos que hay vegetación para ese píxel (valor de matriz).
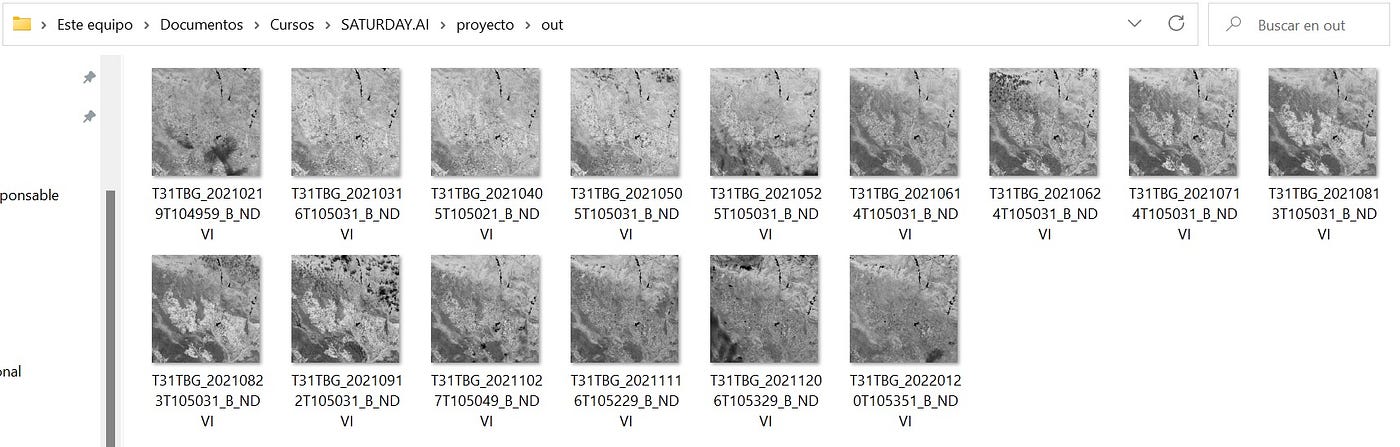
Captura de pantalla de las imágenes NDVI generadas por el script. Fuente: Propia
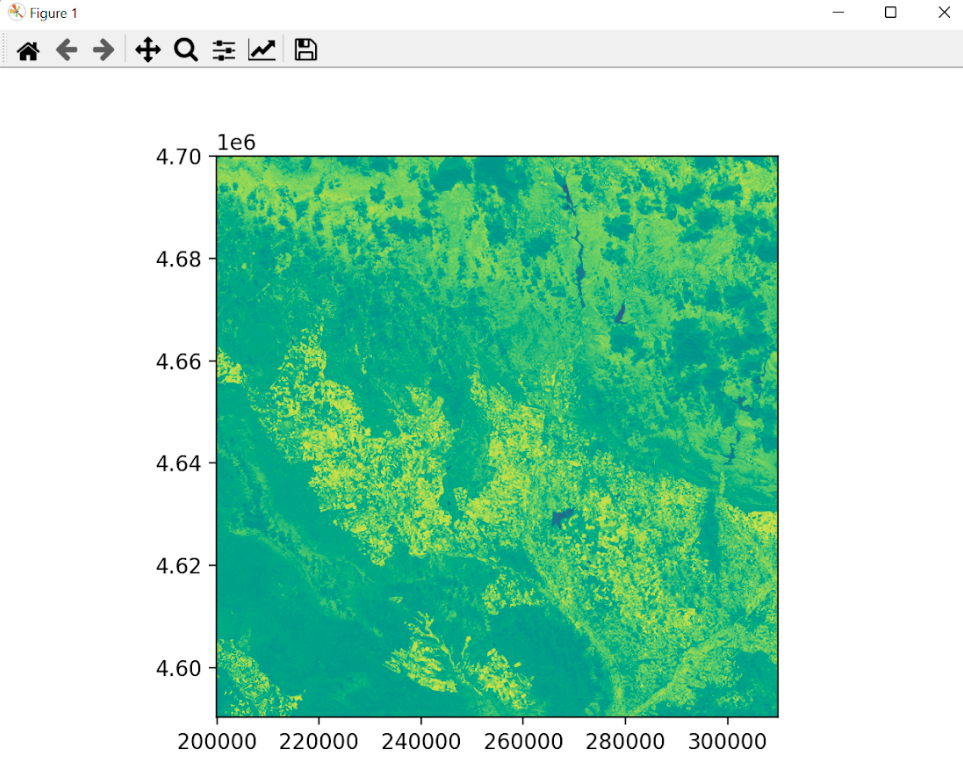
Detalle de una de las imágenes NDVI generadas por el script de Python. Fuente: Propia
¿Y la predicción de valores de desertificación?
Ya estamos en el punto en donde, hemos identificado la zona sobre la que trabajaremos, hemos hallado los índices de vegetación para estas zonas en diferentes momentos de tiempo, ahora continuaremos con el establecimiento de una relación entre los valores medidos y cómo estos cambian en el tiempo (nuestra variable continua) para anticipar un conjunto de nuevos valores.
Deseamos construir un modelo que describa la relación entre las variables de estudio, con el fin, principalmente, de predecir los valores de una variable a partir de los valores de la otra. Elegiremos Random Forest Regressor ya que tenemos un conjunto de valores numéricos que hemos considerado como categorías (cada imagen con su matriz específica) y luego promediamos la salida de cada árbol de decisión usando este algoritmo ( Definición de Random Forest regressor. Material Saturdays AI. Zaragoza. Edición I. 2021–2022. Sesión Regresores).
Breve resumen del funcionamiento de Random Forest Regressor
Como este es un modelo de Machine Learning Supervisado, tomaremos las imágenes con el NDVI calculado, solo una zona de las misma para el aprendizaje del modelo y la zona siguiente de las imágenes para la predicción futura de índices NDVI.
Evaluación
Entrenamiento
Para el entrenamiento del algoritmo, se tomaron 5 imágenes con NDVI calculado y una imagen adicional como salida conocida. De cada una de las imágenes se ha elegido un subset de igual tamaño para añadirlos a un vector en Python. Lo anterior se realiza por capacidad de procesamiento de las máquinas disponibles, las imágenes originales tienen dimensiones de 10.000×10.000 píxeles que no es posible procesar de forma ágil y eficiente con los recursos disponibles en el grupo de trabajo.
Imágenes con NDVI calculado. Fuente: propia.
Nota Aclaratoria: Cada imagen de NDVI calculado tiene un tamaño de 470MB aproximadamente, por lo que 6 de ellas nos da un estimado de 2,8GB para hacer el procesamiento de este dataset.
Fragmento de código para la elección del subset de datos para el Random Forest de entrenamiento. Fuente: propia
Con ayuda de la librería sklearn establecemos un set de entrenamiento para el algoritmo con el que poder “enseñarle” cómo puede intentar predecir los siguientes valores y ejecutar la siguiente fase de prueba (testing).
Prueba
Para probar el algoritmo, se tomaron las mismas 5imágenes con el NDVI calculado pero esta vez, el subset elegido corresponde a otra porción de la imagen. En el entrenamiento hemos elegido una sección, para la prueba (test) elegimos una sección distinta.
Fragmento de código para la elección de los datos de test para el algoritmo. Fuente: Propia
El margen de error para la imagen predicha es el siguiente:
Margen de error resultante de la predicción. Fuente: Propia.
Es necesario saber si el algoritmo es capaz de predecir correctamente una imagen. Utilizaremos una imagen que ya se tiene para validar la efectividad del algoritmo a la hora de predecir el resultado.
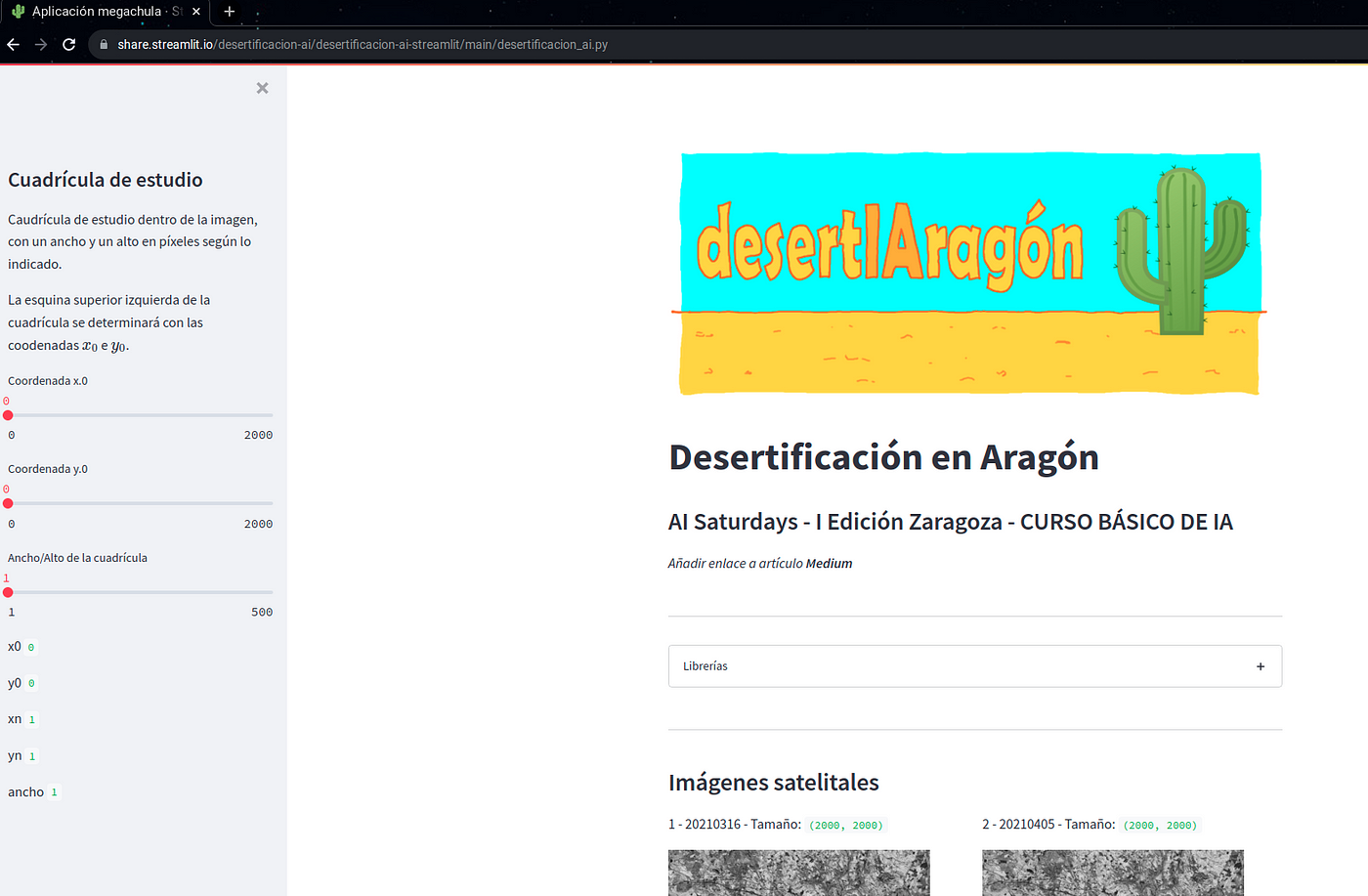
En la página desertIAragon se encuentra desplegada la aplicación de Streamlit para visualizar los cambios en NDVI calculados
Captura de pantalla del sitio web de Streamlit para mostrar imágenes calculadas. Fuente : Propia
En la sección Imágenes Satelitales, encontramos un subset de 2000×2000 píxeles de las imágenes extraídas del sitio web de Sentinel:
Imágenes satelitales de 2000 x 2000 px. Fuente: propia
La sección de cuadrículas de estudio, nos permite elegir la coordenada deseada para mostrar los cambios en el NDVI calculado y sus valores. Elegir la coordenada en las opciones disponibles en el panel izquierdo:
Elección de coordenada para la cuadrícula de estudio. Fuente: propia
Valor de NDVI calculado para la imagen 1. Fuente: Propia.
Predicción
El sistema se entrena con una porción igual de cada una de las imágenes 1 a 5. Esta porción es un recuadro de coordenadas aleatorias y dimensiones igual al ancho/alto de la cuadrícula indicado en la banda lateral (en Streamlit).
La razón de elegir un recuadro reducido es el elevado coste computacional que tiene el entrenamiento del sistema. Este coste puede estar rondando aproximadamente 5 minutos de procesamiento para un fragmento inferior a 250 píxeles de dimensión, en un ordenador con una RAM de 8GB y un procesador: Intel Core I5 2,67 Ghz.
De esta forma la aplicación puede mostrar unos resultados de una forma relativamente ágil. Para el test se ha elegido las imágenes de las cuadrículas 1 a 5 con las que se ha obtenido el índice NDVI.
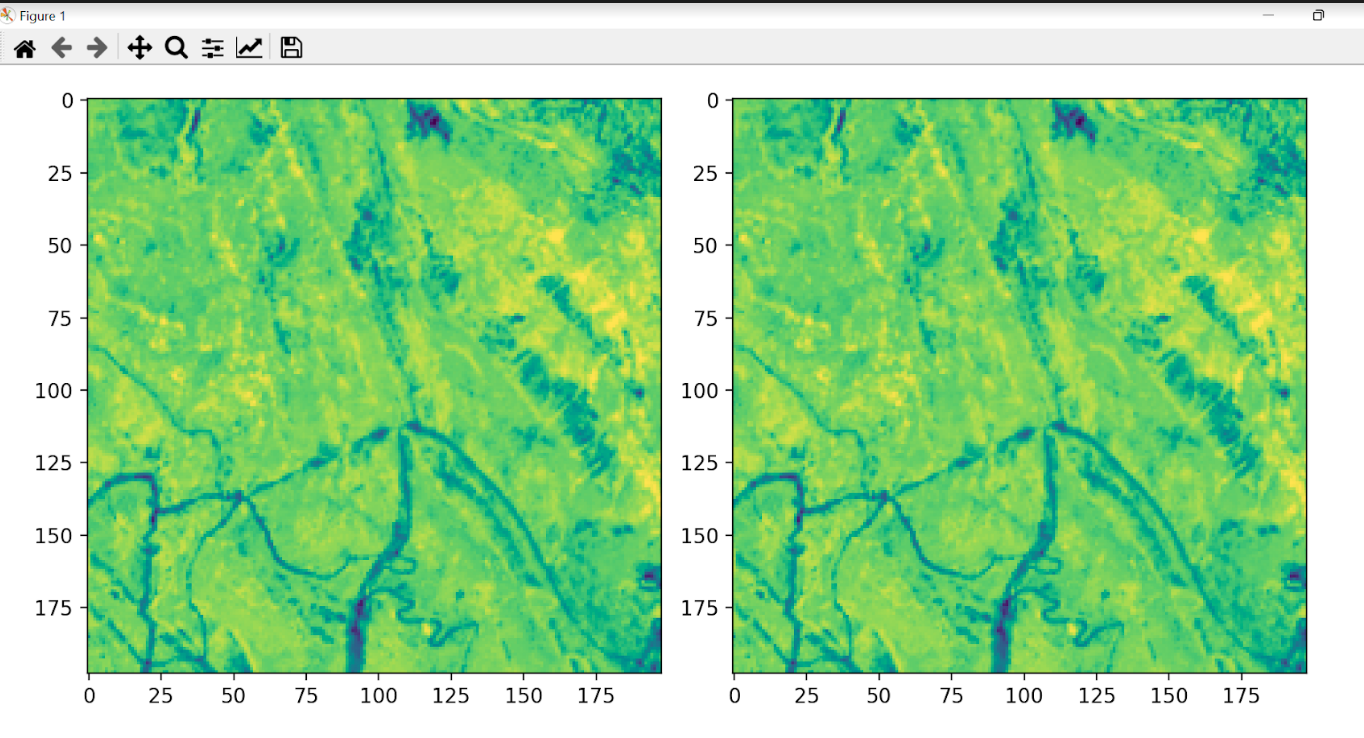
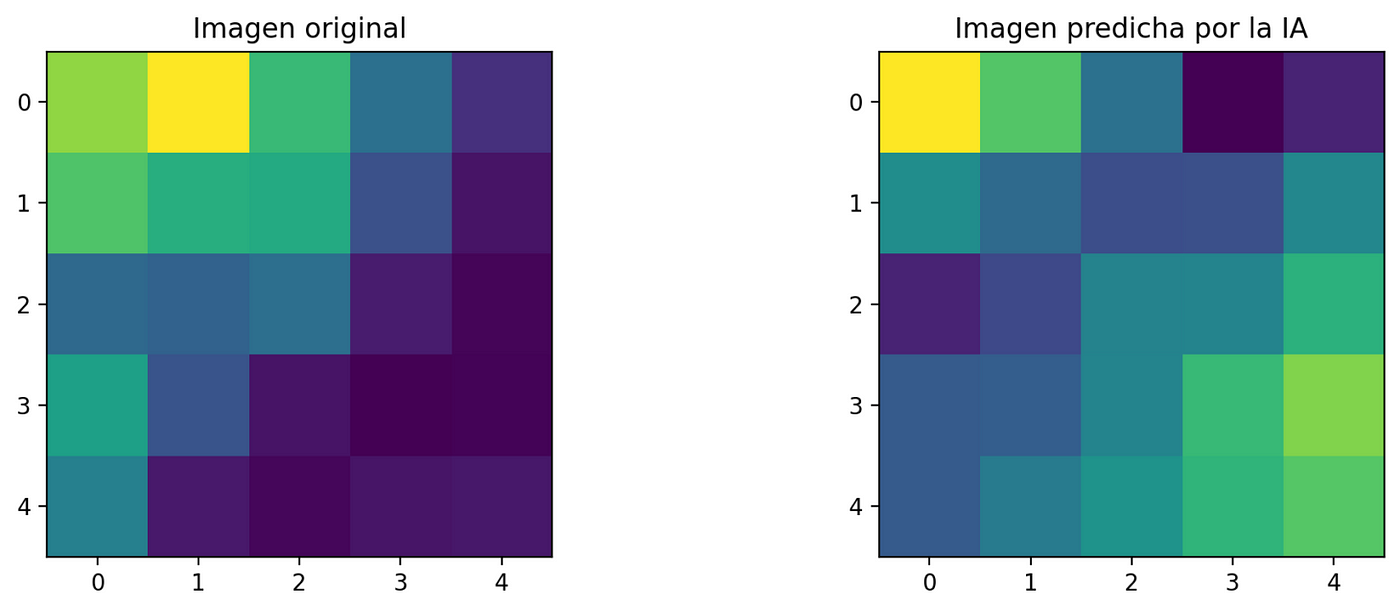
La predicción se hace con la cuadrícula 6. Se compara la imagen original con la predicha por la IA.
Comparación fragmento de la imagen original vs. imagen predicha por la IA
Datos generales de las imágenes:
Coordenadas de la esquina superior izquierda: i_0i0 * j_0j0 = 0 * 0 px Coordenadas de la esquina superior derecha: i_nin * j_njn = 5 * 5 px
Error cuadrático promedio: 0.03719
Conclusiones
Existe software propietario como ERDAS para facilitar el cálculo de NDVI y algoritmos de regresión para predecir comportamientos, sin embargo, alineados con los principios de Saturdays.AI: acercar la IA a todos los ciudadanos y aplicarla a problemas sociales, hemos optado por una solución basada en herramientas de código abierto y disponibles para todo público.
Este proyecto tiene la potencialidad de explorar como una fase siguiente la capacidad de procesamiento de datos para imágenes de dimensiones más grandes, ya sea en resolución espacial o temporal, de forma más eficiente en la nube. Tomando ventajas como procesamiento en paralelo o distribuido se podrán añadir más entradas al algoritmo y procesamientos más complejos que no se pueden suplir con los recursos actuales
La desertificación sobre las zonas evaluadas se puede predecir de forma eficiente, con un margen de error bastante reducido para la primera fase de evaluación. A nivel numérico es posible establecer dónde la vegetación se ha ido perdiendo a lo largo del tiempo y predecir sus valores futuros para tomar acciones a tiempo sobre estas zonas y evitar así, nuevas zonas de desertificación.
Se puede encontrar el código de este proyecto en GitHub
Adicionalmente, el código de visualización se puede encontrar en : GitHub Streamlit
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
El mercado laboral que todos conocemos se desarrolla sobre un esquema a modo de dos grandes tablones de anuncios, uno frente al otro: el primero con los que ofrecen puestos de trabajo y el segundo con quienes los demandan. Y en muchas ocasiones es el segundo el que se adapta al primero.
Pero creemos que esto tiene que cambiar. Más que un encuentro en el que la mayor parte de las veces se elige por eliminación, las relaciones laborales deberían de parecerse un poco más a las personales, al menos en sus planteamientos iniciales. En las apps de contactos, hay que aportar muchos datos acerca de quiénes somos y también de lo que buscamos. De allí surgen candidatos y con eso se busca el MATCH por ambas partes.
No es cuestión de enamorarse a primera vista, pero sí creemos que es bueno conocer más en profundidad en qué consisten las ofertas de trabajo. Son datos públicos que nos pueden contar aspectos importantísimos tanto de la empresa, como del territorio donde están asentadas. Los requisitos que piden a sus futuros trabajadores y su análisis pueden ayudar tanto a las personas que buscan empleo, como al sector de la educación o a los gobiernos e instituciones de cara a prever situaciones de déficit o superávit en alguno de ellos. En una economía interdependiente y globalizada como la que vivimos, ofrecer un excelente comportamiento del flujo de la mano de obra puede ayudar a asentar empresas, y ser un buen apoyo para la economía y la toma de decisiones.
En el caso de Aragón, la situación se complica en lugares como Teruel, al aplicarse el factor de la despoblación en muchas zonas. Insistiendo en la misma idea que el objetivo de nuestro trabajo, la consejera de Presidencia de Aragón, Mayte Pérez en una reunión en Teruel comentó hace unos días la importancia de generar “foros y sinergias para adelantarnos a las necesidades de empleo que van a surgir. Debemos analizar el mercado laboral hoy, pero ver también las expectativas de futuro que tiene la provincia para acompañarlas de una oferta formativa cualificada” [1].
Figura 1: Elconfidencial.com 15/12/2021.
Figura 2: La Comarca 27/01/2022.
Las empresas de construcción, tanto de obra pública como civil, ya alertaron en otoño de la carencia de mano de obra para su sector, lo que podría ocasionar problemas.
Figura 3: El Periódico de Aragón 11/09/2021.
Figura 4: Heraldo de Aragón 05/07/2021.
Y no sólo la construcción.
Figura 5: Heraldo de Aragón 10/10/2021.
Se cifra ya en 30.000 millones de euros anuales las pérdidas por la falta de mano de obra en Europa [2].
Frente a estos datos, los del paro. En Aragón hay más de 61.000 personas en desempleo. La mayor parte, más de 42.000, son del sector servicios. Pero en el sector de la construcción hay 3.871 trabajadores en paro, en industria 7.000 y en agricultura y ganadería, 3.624. A todos ellos se suman más de 4.500 personas sin empleo anterior.
¿Por qué hay desempleo en un sector cuando hay más demanda? ¿las personas que están en el paro en ese sector no cumplen los requisitos? ¿no acceden a las ofertas por no estar en la misma población en la que se publican?
Se plantean muchos interrogantes, y muchos más cuando las empresas e instituciones planifican la actividad de aquí a los próximos diez años, para recuperar el parón que ha supuesto el COVID y ya marcan las necesidades de mano de obra que van a tener.
Figura 6: La Voz de Galicia 16/10/2021.
Problema
Nos enfocamos en el siguiente problema: ¿Cómo podríamos facilitar el análisis de las ofertas de empleo en Aragón para brindar a sus ciudadanos conclusiones relevantes?¿Cómo podemos ayudar a las empresas a encontrar mano de obra que se ajuste a sus necesidades?¿Pueden las instituciones planificar oferta y demanda de empleo conociendo mucho más el mercado laboral?
Tanto el problema identificado como el proyecto desarrollado están enmarcados en el ODS 8 (Objetivo de Desarrollo Sostenible) de trabajo decente y crecimiento económico [3], y está motivado por la carencia de herramientas que faciliten a los aragoneses estudiar en términos globales la situación actual de las ofertas de empleo en Aragón.
Objetivo general
Para resolver el problema identificado nos planteamos como objetivo general: Desarrollar una herramienta basada en técnicas de Procesamiento del Lenguaje Natural que facilite analizar las ofertas de empleo disponibles en Aragón a partir de diferentes criterios (sector, provincia, ciudad, oficina del INAEM, fechas, etc.) Su utilidad puede ser de interés para empresas, instituciones, planificación educativa, estudiantes, desempleados, empresas de formación, etc…
Con el propósito de cumplir con el objetivo planteado y llevar a cabo el proyecto de manera organizada, seguimos la metodología CRISP-DM (Cross-Industry Standard Process for Data Mining) [4], orientada a trabajos de Minería de Datos, que en nuestro caso se enfoca específicamente en técnicas básicas de Procesamiento del Lenguaje Natural (PLN) [11]. En la siguiente figura se presentan las diferentes fases que abarca la metodología.
Al iniciar el planteamiento de nuestra propuesta, consideramos estudiar el ámbito laboral en Aragón al completo, oferta y demanda. Para la oferta vimos que podíamos contar con el Instituto Aragonés de Empleo, INAEM [5], que de lunes a viernes facilita un PDF con las ofertas de empleo disponibles esa jornada en todo el territorio, distribuídas en 28 sectores productivos.
También planteamos usar Infojobs, pero la información que se facilita allí no se encuentra tan bien clasificada. Además, Infojobs aporta unos tipos de trabajo determinados. No suelen ser empleos de alta formación y sueldos elevados, lo que sesgaría las características del estudio.
Para la demanda pensamos en LinkedIn, que sí ofrece mucha información y buena indexación. Pero no todos los miembros de la comunidad LinkedIn buscan trabajo. Con lo cual quedaba descartado. Lo mismo sucedió con los demandantes de trabajo en Infojobs u otras páginas similares como Milanuncios.com. Suelen ser perfiles con urgencia en trabajar, que daría para otro estudio, quizá de carácter social, pero no en la línea que nosotras planteamos.
Por este motivo, decidimos acudir a la base, y crear un sistema capaz de interpretar la oferta diaria de puestos de trabajo en la comunidad autónoma de Aragón, e intentar sacar de allí el máximo partido al modelo de ficha con los datos básicos que encontramos en cada uno de los empleos que allí se anuncian. Hay también que tener en cuenta que el INAEM gestiona buena parte de los puestos de trabajo que salen al mercado laboral en Aragón, pero no el 100%. Por ello nuestras conclusiones, no podrán ser en ningún caso estrechamente ajustadas a la realidad, sino que se convierten en tendencias, aproximaciones y evoluciones cercanas a la oferta de empleo real.
El conjunto de datos que se obtuvo fue el resultado de analizar, extraer y preprocesar un conjunto de esos documentos PDF disponibles en el portal de INAEM [5], y también incorporando la información que aparece en la propia página web del INAEM, en el rango de fechas del 2021 hasta principios de marzo de 2022. En total 1152 ofertas de trabajo. Se distribuyen por sectores profesionales en Aragón (ver Figura 8). Cada oferta de empleo se divide en dos bloques. Uno más breve y esquemático con el título, provincia, ciudad, código, fecha de publicación y oficina. El segundo bloque es el de la descripción. Dentro de ella se obtiene información sobre las tareas a desempeñar, requisitos solicitados por la empresa, condiciones de trabajo, trámites y plazos, entre otras.
Figura 8: Ejemplo de una oferta de trabajo que encontramos en el documento PDF del INAEM.
Durante el proceso de extracción de la información textual desde los documentos de PDF se utilizó la librería de Python Tika [6]. El texto resultante de la extracción por cada documento PDF fue separado por sectores profesionales y luego por ofertas de empleo. De cada oferta, se extrajeron los textos de mayor interés a analizar (“sector”, “identificador de la oferta”, “fecha de publicación”, “título de la oferta”, “ciudad”, “provincia”, “oficina del INAEM”, “descripción global”, “descripción específica”, “tareas a desempeñar”, “requisitos solicitados por la empresa”, y “condiciones de trabajo”). Para ello, aplicamos expresiones regulares [7], también conocidas como regex por su contracción de las palabras inglesas regular expression, que no es más que una secuencia de caracteres que conforma un patrón de búsqueda sobre los textos. En la siguiente figura se puede ver un ejemplo para encontrar las “fechas de publicación” dentro de los textos de las ofertas.
A primera vista parecen tablas de datos con una pauta similar y un orden concreto. Pero lo cierto es que en la práctica se constata que no es así. Cada oficina tiene sus usos y costumbres, lo que dificulta el tratamiento de los datos. Por ejemplo, unas escriben las poblaciones con mayúsculas, y otras sólo la inicial va en mayúscula. Eso hace que se identifique como dos poblaciones distintas si vemos una oferta en BARBASTRO y otra en Barbastro, también se pueden diferenciar por los acentos (por ejemplo, Sabiñánigo y Sabiñanigo) o porque simplemente están mal escritas (por ejemplo, concinero en vez de cocinero, grú para referirse a grúa, etc.). También hay ofertas de trabajo duplicadas, y en cuanto a las características de la descripción global de la oferta, en algunas oficinas las detallan como “Requisitos” y en otras como “Tareas”,entre otras diferencias. Incluso algunas oficinas no ponen etiquetas que separen los distintos conceptos dentro de la descripción, lo que impide aplicar el modelo.
Ejemplo 1.- Lleva las etiquetas de TAREAS, REQUISITOS, CONDICIONES
Ejemplo 2.- Sin etiquetas ni separación. Únicamente aparece “Funciones” sin mayúscula ni negrita
En la fase de análisis y verificación de la calidad de los datos extraídos, identificamos este conjunto de problemas, que fueron tratados para su posterior explotación desde el dashboard: eliminamos ofertas de trabajo duplicadas (asegurando tener un identificador único por oferta), corrigiendo nombre de ofertas, ciudades, provincias, oficinas de empleo, y descripciones mal escritas a partir de diccionarios. También hemos tenido que unificar los textos que significan lo mismo para diferentes características.
Con el propósito de extraer información complementaria a la obtenida desde los documentos PDF, aplicamos en paralelo la técnica de web scraping al buscador de ofertas de empleo en Aragón de INAEM [5], como es el caso del “nivel profesional”, “requerimientos” y “duración del contrato” de las ofertas de empleo, que sólamente aparecían en la web. Adicionalmente, el web scraping permitió completar valores vacíos que no se consiguieron extraer desde los documentos PDF, tales como las “descripciones generales”, “condiciones de trabajo”, nombres de “ciudades” y “provincias”, al estar tanto en la web como en los documentos PDF. Tal vez el web scraping hubiera sido suficiente para tener una primera versión de los datos relacionados con las ofertas de empleo de INAEM, pero los campos “sector” y “oficina de empleo” de cada una de las ofertas sólo estaban presentes en los documentos PDF, los cuales considerábamos muy importantes para estudiar desde el dashboard. Por todo lo anterior, hay que resaltar que una gran parte del proyecto fue dedicada a la fase de extracción, análisis, limpieza y homogeneización de la información.
Dashboard de ofertas de empleo en Aragón
Con el propósito de facilitar el análisis de la situación actual de las ofertas de empleo en Aragón, desarrollamos un dashboard haciendo uso de la librería Streamlit [8]. Esta librería de python ofrece una plataforma de código abierto que permite crear y compartir fácilmente aplicaciones web personalizadas para ciencias de datos y aprendizaje automático. El código fuente del dashboard y de la extracción y preprocesamiento textual está disponible en nuestro repositorio de GitHub [9].
El dashboard cuenta con 4 apartados principales que vamos a desarrollar a continuación. Aunque hay más de una veintena de sectores, hemos querido fijarnos sobre todo en el turismo, por ser importante en la economía aragonesa y con requisitos y términos más conocidos para la sociedad:
1.- Estudio de ofertas por criterio:
En este apartado conocemos el número de ofertas que hay según los siguientes criterios de búsqueda: sector, oficina y provincia.
Según el criterio seleccionado se genera una gráfica de barras.
Figura 9: Captura de pantalla de estudio de ofertas por criterio
Análisis:
Con el criterio “Sector” analizamos 24 de los 28 sectores que contempla la página web del Servicio nacional de empleo. Hay 4 sectores que el INAEM o bien no contempla, o bien no existen ofertas de trabajo para ellos. Esos 4 sectores son Información y Manifestaciones artísticas, Minería y primeras transformaciones, Pesca y acuicultura y Piel y cuero. Vemos que los tres ámbitos que más ofertas han presentado desde noviembre a aquí son Turismo y Hostelería (en plena temporada de nieve y con las vacaciones de Navidad), Administración y Oficinas y Edificación y Obras Públicas. Las que menos personal han solicitado en este tiempo son Producción, Transformación y Distribución de Energía, Seguros y finanzas y Artesanía. En esta gráfica en este periodo podemos observar la temporalidad, con mucha demanda en Hostelería (una de las temporadas altas del turismo en Aragón) y con una oferta contenida por ejemplo en Agricultura, ya que en invierno disminuyen las labores del campo.
Con el criterio “Oficina” observamos que con mucha diferencia, la de Zaragoza Ranillas es la que más ofertas de empleo gestiona en toda la comunidad. Le sigue la oficina de Huesca Capital. Zaragoza acumula cinco oficinas de empleo, dos de las cuales, Zaragoza Centro y Zaragoza Compromiso de Caspe, se sitúan las siguientes en el ránking de las cinco primeras, que cerraría la oficina de Teruel Capital. Fuera de las tres capitales provinciales, destaca Sabiñánigo en número de ofertas de trabajo. En esa sucursal se une la oferta industrial de la capital del Alto Gállego, al abundante sector hostelero y turístico del Valle de Tena, que se complementa con construcción y ganadería. En el listado hay una oficina que no corresponde con Aragón. Ello es debido a que desde las oficinas de Castellón y Castelldefels (Barcelona) han lanzado a Aragón unas ofertas buscando esquiladores.
Con el criterio “Provincia” observamos la proporción actual de ofertas que se reparten entre los tres territorios provinciales de Aragón.
2.- Estudio de ofertas por fecha: En este apartado cruzamos varios de los datos que encontramos en las ofertas, para lograr conclusiones más específicas o perfiles más ajustados. Se genera una gráfica de temporalidad, que facilita el análisis del número de ofertas de trabajo combinando diversos criterios, tales como año, sector laboral y provincia.
Figura 10: Captura de pantalla de estudio de ofertas por fecha
Análisis:
Si seleccionamos el criterio “AÑO” podemos obtener sólo uno en concreto, como esta gráfica, correspondiente a 2021 para todo Aragón. Es evidente un pico en las ofertas de trabajo a mediados de diciembre, tras el puente, justo antes de las contrataciones de cara a la campaña navideña.
Para el año 2022 en todo Aragón, vemos escasa oferta en los primeros días, que aún son festivos, y un pico destacado al final del mes de enero. Llama la atención la caída en las ofertas llegado mitad del mes de febrero, que luego se recupera con un nuevo pico demanda de trabajadores a final de mes.
Y podemos unir los dos periodos que tenemos actualmente, 2021 y 2022. En esta gráfica, añadimos el criterio “PROVINCIA” seleccionando la de Zaragoza. Encontramos unas conclusiones similares en estos parámetros, con picos a mitad de diciembre y finales de enero, y una caída de ofertas a mitad de febrero, para encontrar una importante subida a final de este mes.
Analizamos ahora el número de ofertas aplicando el criterio “PROVINCIA” en este caso en la de Huesca para el año 2021 y 2022. Es muy llamativo el pico de ofertas a finales de enero, de cara parece a una contratación a más largo plazo. Destaca también el descenso de empleos propuestos a mitad de febrero.
En cuanto al número de ofertas en Teruel para el año 2021 y 2022, es también muy llamativo el pico a final del mes de enero, y también una caída significativa a mitad de mes de febrero:
Y también se puede analizar aplicando los tres criterios, es decir por cada uno de los sectores/años/provincia.
Por ejemplo, estudiamos aquí el sector TURISMO Y HOSTELERÍA y provincia ZARAGOZA para todos los años. Hay una subida a final del mes de enero, quizá preparando el puente festivo de San Valero o ante la previsión de la eliminación de algunas restricciones de hostelería, que se efectuó a principios de febrero.
En esta otra gráfica, hemos seleccionado el sector de la EDIFICACIÓN Y OBRA PÚBLICA, también en la provincia de Zaragoza, con demanda de trabajadores muy desigual en estos días.
3.-Nube de palabras: Generamos una nube de palabras a partir de los textos que contienen los títulos y descripciones globales de las ofertas laborales, las cuales se pueden filtrar por sector profesional. Adicionalmente, se puede ajustar diferentes parámetros de configuración de la nube de palabras, tales como el color del fondo de la imagen, el color de las palabras más frecuentes, el número máximo de palabras a generar, el tamaño máximo del fondo, y el estado aleatorio para que muestre palabras diferentes por cada valor definido. Por otra parte, permite subir una imagen (de tipo “silhouette”) para generar la nube de palabras con la forma de la figura dibujada en la imagen. Nuestra idea de “conocer es amar” aplicada a este proyecto nos ha animado a darle forma de corazón. Es una herramienta muy valiosa, porque más allá del dato, permite identificar otros conceptos no detectables en un primer análisis sobre las ofertas de empleo. Lo explicamos a continuación.
Figura 11: Captura de pantalla de la nube de palabras.
Para realizar el análisis de los datos exploratorios del PLN [11], utilizamos la librería de Python WordCloud [10]. A partir de esta librería pudimos hacer una representación visual de las palabras (también conocido como nube de palabras) que conforman los textos de los títulos y descripciones globales de las ofertas de trabajo, en donde el tamaño es mayor para aquellas palabras que aparecen con más frecuencia. Las gráficas de nube de palabras, nos permitieron visualizar las palabras claves contenidas en los textos para su posterior estudio. Previo a la representación visual y como parte del procesamiento de datos en lenguaje natural, eliminamos del texto un conjunto de palabras vacías (conocidas como stop words), que son palabras sin significado como artículos, pronombres, preposiciones, etc.
Análisis:
Para la primera nube de palabras que analizamos, hemos seleccionado, por ejemplo, los criterios Oferta + Sector TURISMO Y HOSTELERÍA. Es decir, esta nube de palabras es con el encabezamiento de la Oferta.
En las nubes de palabras, aparecen los términos más usados o habituales dentro del texto. Era de esperar encontrar ‘Camarero’, ‘Cocinero’ o ‘Barra’. Pero encontramos otros términos que nos dan pistas de tendencias. Por ejemplo, aparecen varios municipios donde hay especial demanda de Hostelería (Rubielos, Garrapinillos, Montañana, Cariñena), y otros servicios de Hostelería que no son los mayoritarios (Residencia, planchistas, marmitones, ancianos o discapacidad). Ello nos permite analizar, por ejemplo, una tendencia emergente dentro de este sector dando servicio residencial, y varias especializaciones que se necesitan en Aragón, como por ejemplo Barrancos. Observamos el sesgo de género ya que se solicita mucho más los Camareros (muy grande) que las Camareras (muy pequeño), o Cocinero un poco más grande que Cocineras. Es llamativo que las demandas especifican el género.
Si nos vamos a otro criterio, podemos analizar el texto de la Descripción global de la oferta, también en el mismo sector de TURISMO Y HOSTELERÍA. Buena parte de esta nube se la llevan palabras que indican trámites administrativos derivados de la gestión laboral. Pero hay varios términos que nos ofrecen características del sector. Entre las palabras destacadas, por ejemplo se encuentra ‘Experiencia’ y también ‘jornada completa’ que se lee bastante grande, frente a ‘jornada parcial’ que también se encuentra en la nube pero mucho más pequeña. Por contra, aparece con más tamaño ‘contrato temporal’ que ‘contrato indefinido’. Entre los requisitos que se solicitan se encuentra también carnet de conducir o posibilidad de conducción para el trabajo.
Analizamos ahora otro sector muy distinto. Seleccionamos OFERTAS y sector SERVICIOS A LA EMPRESA. En un sector tan genérico, los términos que aparecen nos ofrecen valiosa información sobre los perfiles que se buscan. Entre los que más, Técnico, Riesgos Laborales, Prevención, Teleoperadores, Seguridad o Informático. Una manera muy sencilla de definir perfiles en este sector.
Aportamos un ejemplo más de OFERTA en este caso, el de INDUSTRIA ALIMENTARIA. En un sector tan diverso, las características del mercado aragonés se definen en su vertiente de carnicería. Despiece, Cárnica, Carnicero, Tripería, Cárnicos, Aviar, Animal, Matadero, Carnicería constituyen las mayoría de las palabras de la nube.
4.- Mapa de ofertas: Con esta opción segenera un mapa donde se puede visualizar el número de ofertas por cada provincia, oficina de desempleo en Aragón y población donde se ofrece el puesto de trabajo, con círculos que amplían su radio proporcionalmente al número de empleos.
Figura 12: Captura de pantalla del mapa de ofertas.
MAPA 1.- Con el propósito de obtener automáticamente la latitud y longitud de las provincias, ciudades y oficinas de empleo en Aragón, usamos la librería GeoPy [12]. Por otra parte, la librería de Python pydeck [13] fue utilizada para visualizar los datos en el mapa de una manera interactiva. En la Figura 13, se muestra un ejemplo de visualización del mapa geográfico con el número de ofertas de empleo por cada una de las provincias de Aragón.
Figura 13: Ejemplo de mapa geográfico de ofertas por cada una de las provincias de Aragón.
Análisis:
Con esta primera imagen en mapa, de un simple vistazo nos hacemos una idea de cómo se reparte el volumen de ofertas del INAEM en Aragón entre sus tres provincias. Las proporciones mayores están en Zaragoza y Huesca, y se nota mayor distancia con las de la provincia de Teruel.
MAPA 2.- La siguiente posibilidad que ofrece nuestro modelo refleja las poblaciones donde se ofrecen los puestos de trabajo. Este mapa puede convertirse en una herramienta valiosa para la ordenación del territorio. Observando la evolución a lo largo de días o meses puede dar información, por ejemplo, de las necesidades de vivienda, educación o servicios, o al contrario, advertir del riesgo de despoblación o de que se inicien movimientos migratorios de los habitantes de una zona buscando trabajo en otro lugar.
MAPA 3.- La tercera posibilidad es conocer el volumen de ofertas de empleo de cada oficina del INAEM en Aragón. Podemos observarlo de manera general, incluyendo las de toda la comunidad autónoma como en este gráfico.
O bien acercarnos y descubrir las opciones de las distintas oficinas dentro de una misma ciudad, como ocurre en Zaragoza.
Conclusiones
En este artículo, hemos presentado el proyecto desarrollado en Saturdays.AI-Zaragoza, un primer paso para contribuir con la sociedad, ante la carencia de herramientas que faciliten a los aragoneses estudiar en términos globales la situación actual de las ofertas de empleo en su comunidad.
Tal y como hemos explicado, entre los problemas que nos hemos encontrado se encuentra la distinta indexación según cada oficina del INAEM. Si todas ellas rellenaran una misma plantilla online exactamente con los mismos criterios el tratamiento de los datos sería mucho más sencillo e inmediato. ¿De qué sirven los datos si no están semi-estructurados? ¿si no hay un patrón que facilite la extracción de la información? Si además nuestro enfoque se implementara y recopilara con esos datos día a día, sería una valiosa arma para la gestión del empleo en la comunidad de Aragón, permitiendo conocer puntualmente la evolución de los distintos sectores, de los lugares donde se ofrece trabajo, de los requisitos que solicitan las empresas para sus futuros empleados. Mucho de nuestro trabajo se ha invertido en solucionar detalles que no tendrían que estar allí. De no habernos encontrado esas diferencias en las formas de clasificación de datos, nuestro estudio nos permitiría hablar de otros análisis más profundos y precisos e incluso modelos de aprendizaje automático avanzados.
Simplemente continuar añadiendo los datos a diario a este trabajo, permitiría un estudio muy detallado de cómo se comporta el mercado laboral en un año, analizando así la evolución de sectores tan temporales como pueden ser el agrícola o el turismo, ambos con un peso muy relevante en la economía aragonesa e incluso pudiendo llegar a predecir las necesidades futuras del mercado laboral aragonés.
Además de todo ello, algunas de las principales aportaciones que realiza este trabajo son las siguientes:
Es una herramienta que aumenta el conocimiento sobre las ofertas de empleo en Aragón.
Consigue organizar los datos del INAEM a pesar de las dificultades.
Crea un sistema de interpretación del lenguaje natural del que obtenemos los datos deseados.
Generación automática de gráficas de barras según los datos por sectores, oficina y provincia.
Generación automática de gráficas según criterios independientes o combinados con año, sector y provincia.
Generación automática de nubes de palabras, que además de analizar la oferta, nos ofrece nuevas ideas o criterios, conceptos emergentes que son muy interesantes para analizar las ofertas.
Generación automática de mapas que permiten tener una visión de las ofertas directamente sobre el territorio, lo que ofrece una valiosa herramienta de comprensión sobre la evolución del empleo y su impacto en las distintas comarcas.
Para qué se puede aplicar:
Marcar líneas de formación para empresas o gobiernos.
Dar indicación a los jóvenes que buscan un horizonte laboral para tomar decisiones en cuanto a su formación de cara a futuro.
Dar información a las empresas de los requisitos que hay en el mercado para un puesto concreto, y conocer las condiciones medias de contratación.
Conocer el tiempo qué tarda en cubrirse una plaza en un sector.
Saber los lugares de Aragón dónde se demanda el empleo y dónde no.
Demanda de empleo según la época del año. Evolución de la temporalidad.
Planificación de la ordenación del territorio y de la sociedad según las necesidades de la población que pueda desplazarse buscando el empleo.
Como líneas de trabajo a seguir partiendo de lo que ya tenemos, se puede continuar con el desarrollo y mejora del dashboard.
Y de cara al futuro
Se podría desarrollar para que el programa se enriqueciera con más información que incorporara a diario de manera automática.
Se podría convertir en una aplicación web real y consultable por autoridades relacionadas con la gestión económica y social, empresas, trabajadores, sindicatos, estudiantes, etc.
Incorporar otras plataformas de empleo, puesto que la del INAEM no representa toda la oferta existente. Requeriría de un complejo estudio para encontrar en esas otras plataformas el modo de homogeneizar la información, es decir, unificar en un única característica aquellos textos que significan lo mismo pero se categorizan bajo etiquetas diferentes. Esto incluso podría pasar dentro de una misma plataforma, como tenemos en el INAEM.
Agradecimientos
Agradecemos la oportunidad que nos ha brindado Saturdays.AI para aprender los fundamentos básicos de Inteligencia Artificial, a pesar de no ser expertos en el ámbito. Y sobre todo a María del Carmen Rodríguez Hernández, por toda la ayuda que nos ha prestado y todas las horas de apoyo, sin las cuales, esto no sería una realidad.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
¡Ya existe la inteligencia artificial que separa canciones por pistas!
Los amantes de la música están de enhorabuena ya que existe una inteligencia artificial que permite separar una canción en pistas. Es decir, permite añadir una canción en formato mp3 y el programa la separa por instrumentos, puedes obtener las pistas de guitarra, voz, bajo, batería, piano, etc.
¿Cómo funciona?
Para ello, debemos descargarnos un software llamado Anaconda y con él se podrá efectuar dicha separación por instrumentos, lo cual permitirá a aficionados o estudiantes de música poder escuchar los instrumentos por separado de una canción y poder captar mejor las melodías o, practicar dicha canción con el mismo instrumento y quitar de la grabación el que estés tocando.
Así será más sencillo escuchar qué está tocando cada músico y sería como si estuvieras ensayando con el resto de músicos y tú estuvieras tocando tu instrumento. Otro uso a tener en cuenta es el de los samples, ya que de esta forma se podrá samplear solo la guitarra de una canción o la batería y excluir el resto de instrumentos que no se quieran.
Como aspecto negativo, mencionar que el programa no está pulido al 100% y se oyen algunas impurezas en el sonido a la hora de separar los instrumentos y es algo que en el futuro esperemos que esté mejor optimizado. A pesar de esto, no vamos a desmerecer la labor del programa ya que sigue siendo realmente útil.
Por otro lado si alguien es más perezoso o se lo puede permitir, mediante el pago de 13€ mensuales el subscriptor puede acceder a una enorme base de datos de canciones ya separadas por pistas y separadas por géneros musicales.
Dentro música…
¿Qué os parece? Sabemos que es una aplicación de la Inteligencia Artificial muy concreta y que no todo el mundo le va a sacar partido, pero seguramente todos conocemos a algún amigo que está aprendiendo a tocar o toca algún instrumento y puede ayudarlo mucho, o puede que conozcamos a algún músico que también pueda serle útil para crear bases. Además todavía falta por pulirla un poco, pero estamos convencidos que se irá mejorando mucho en el futuro y cada vez será más útil.
No olvides que aprender Inteligencia Artificial es sencillo, consulta muestra página web para ver toda la información sobre nuestros cursos sobre nuestros cursos!
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education