Reconocimiento de emociones mediante el estudio de expresiones faciales con deep learning y computer vision.
FindPet: Identificación de mascotas perdidas con Inteligencia Artificial
La Paz. Deep Learning. 2021
En este artículo utilizaremos técnicas de Inteligencia Artificial para encontrar mascotas perdidas. Aquellas personas que han perdido a una mascota por diferentes motivos saben que aunque muchas regresan a sus dueños un gran porcentaje no logra el reencuentro. Unas 420,000 mascotas, entre perros y gatos principalmente, se pierden anualmente en el Perú y son muy pocas las que son encontradas o devueltas a sus dueños, debido a que es muy difícil identificarlas.
La identificación de mascotas por lo general se hace a través de plaquitas metálicas colgadas en su cuello, con su nombre y el teléfono del propietario. Otros optan por insertarles un chip bajo la piel y algunos pocos, por lo costoso, prefieren los GPS e, incluso, tatuarlas. Ante la pérdida de sus mascotas, las personas optan por buscarlas mediante carteles pegados en postes, a través de redes sociales, anuncios en medios de comunicación u ofreciendo recompensas en dinero o con entradas a conciertos o partidos de fútbol. Es por ello, que el objetivo de este proyecto es poder ayudar a las personas a encontrar a sus mascotas perdidas mediante Inteligencia Artificial y Deep Learning para la identificación de sus mascotas de manera rápida, precisa y económica.
Problemática
Diariamente, se calcula que se extravían aproximadamente entre 30 y 40 animales domésticos, entre perros y gatos, solamente en Lima. Sin embargo, se estima que esta cifra puede ser mayor, no solo al contabilizar el resto de las ciudades de Perú, sino también porque muchas personas no saben cómo o dónde pueden reportar la pérdida o extravío de su mascota. Muy pocas mascotas son encontradas o retornadas con sus dueños, debido a que es difícil poder identificarlas y hacer el rastreo correcto. Como consecuencia de ello, muchas de las mascotas terminan como animales callejeros causando sobrepoblación que terminan contaminando la ciudad con sus heces y los parásitos que son expulsados a través de estas.
Objetivo
Desarrollar una aplicación que ayude a las personas a reportar y encontrar mascotas perdidas de manera rápida usando Inteligencia Artificial con técnicas de Deep Learning.
Datasets
Se utilizaron datasets existentes y de acceso libre, para la clasificación de razas se utilizaron los datasets de Stanford que contiene imágenes de 120 razas de perros de todo el mundo y Thudogs que contiene 130 razas de perros junto con los bounding boxes de todo el cuerpo y la cabeza del perro en cada imagen; mientras que para la identificación de mascotas se utilizó Flickr que contiene sólo los rostros del perro y está dividido por nombre del perro perteneciendo solo a dos tipos de raza: pugs y huskies.

Proceso de Identificación de Mascotas
El proceso de identificación de mascotas perdidas mediante Inteligencia Artificial consta de cuatro fases como se muestra en la siguiente figura, a continuación se detalla cada una de ellas.
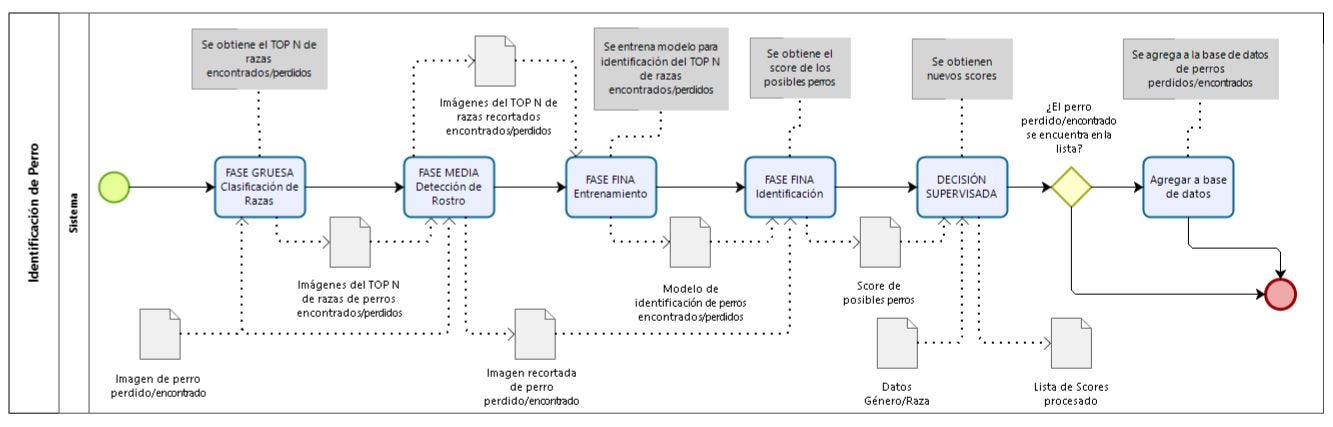
- FASE GRUESA: Clasificación de Razas
En esta fase, ingresa la imagen de un perro perdido o encontrado y se evalúa con el modelo de clasificación de razas y como output se obtiene el top N de razas a la que pertenece el perro, esto sirve como input para la fase media donde solo ingresarán las imágenes que se tenga en base de perros encontrados o perdidos que se tenga de estas “N” razas.
- FASE MEDIA: Detección de Rostro
En esta fase, se tiene como input la imagen del perro encontrado y el resultado de la clasificación de esta imagen obteniendo las imágenes de top N de las razas, para ser evaluados por el modelo de detección de rostros, en este caso yolo v5, obteniendo como output los bounding boxes del rostro del perro para cada imagen.
- FASE FINA: Identificación de la mascota
En esta fase, ingresa como input las imágenes del perro encontrado o perdido junto con las imágenes del top N ya recortadas el rostro utilizando los bounding boxes obtenidos de la fase media, para hacer el entrenamiento del modelo de identificación de rostro.
- DECISIÓN SUPERVISADA
Finalmente, para hacer una decisión más precisa utilizamos decisión supervisada con parámetros como la edad y el género del perro, para poder acotar y tener más precisión para identificar al perro correcto.
Modelos
Para la construcción del modelo de clasificación de razas e identificación de mascotas se utilizó Redes Neuronales Convolucionales, específicamene Inception v3 y Xception, ya que que se trata de un problema de clasificación de imágenes con N posibles salidas, donde N es el número de razas o número de nombres de perros, en el caso del dataset de Stanford N tiene un valor de 120 , para Thudogs 130 y Flickr 42. Para la construcción del modelo de detección de rostro de la mascota se usó Yolo v5.
- Inception v3
Inception-v3 es una arquitectura de red neuronal convolucional de la familia Inception que realiza varias mejoras, incluido el uso de Label Smoothing, convoluciones factorizadas 7 x 7 y el uso de un clasificador auxiliar para propagar información de etiquetas en la parte inferior de la red, junto con el uso de batch normalización para capas en la cabecera lateral.
A continuación, se muestra el diagrama de arquitectura de Inception v3:
- Xception
Xception significa “xtreme inception”. Esta arquitectura replantea la forma en que vemos las redes neuronales, en particular las redes convolucionales. Y, como sugiere el nombre, lleva los principios de Inception al extremo.
En una red convolucional tradicional, las capas convolucionales buscan correlaciones tanto en el espacio como en la profundidad. En Inception, comenzamos a separar los dos ligeramente. Usamos convoluciones 1×1 para proyectar la entrada original en varios espacios de entrada más pequeños y separados, y de cada uno de esos espacios de entrada usamos un tipo diferente de filtro para transformar esos bloques de datos 3D más pequeños. Xception lleva esto un paso más allá. En lugar de dividir los datos de entrada en varios fragmentos comprimidos, asigna las correlaciones espaciales para cada canal de salida por separado y luego realiza una convolución en profundidad 1×1 para capturar la correlación entre canales.
A continuación, se presenta el diagrama de arquitectura de Xception, donde los datos pasan primero por el flujo de entrada, luego por el flujo medio que se repite ocho veces y finalmente por el flujo de salida. Tenga en cuenta que todas las capas de convolución y convolución separable van seguidas de la normalización por lotes.
- Yolo v5
Yolo v5 es un modelo de detección de objetos, y su primera versión oficial fue lanzada por Ultralytics. Como YOLO v5 es un detector de objetos de una sola etapa, tiene tres partes importantes como cualquier otro detector de objetos de una sola etapa.
- Model Backbone: se utiliza principalmente para extraer características importantes de la imagen de entrada dada. En YOLO v5, las CSP — Cross Stage Partial Networks se utilizan como backbone para extraer una gran cantidad de características informativas de una imagen de entrada.
- Model Neck: se utiliza principalmente para generar pirámides de características. Las pirámides de características ayudan a los modelos a generalizarse bien en la escala de objetos. Ayuda a identificar el mismo objeto con diferentes tamaños y escalas. Las pirámides de características son muy útiles y ayudan a los modelos a funcionar bien con datos invisibles. Hay otros modelos que utilizan diferentes tipos de técnicas de pirámide de características como FPN, BiFPN, PANet, etc.
- Model Head: se utiliza principalmente para realizar la parte de detección final. Aplicó anchor boxes en features y genera vectores de salida finales con probabilidades de clase, objectness scores, y bounding boxes.
A continuación se muestra el diagrama de arquitectura de Yolo v5:
Resultados
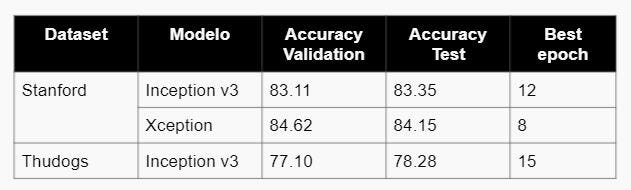
- FASE GRUESA: Clasificación de Razas
- FASE MEDIA: Detección de Rostro

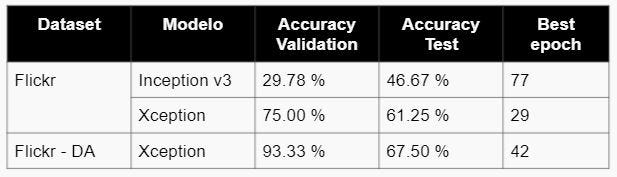
- FASE FINA: Identificación de la mascota
Conclusiones y Recomendaciones
- En la fase gruesa de clasificación de razas, se concluye que el modelo más óptimo es Inception v3 con un accuracy de 83.35% usando el dataset de Stanford y 78.28% para el de Thudogs.
- En la fase media de detección de rostros, se probó únicamente el modelo Yolo v5 obteniendo un MAP de 98.5%.
- En la fase fina de identificación de rostros, se concluye que el modelo más óptimo es Xception con un accuracy de 67.5% para el dataset de Flickr una vez realizado el data augmentation.
- El uso de modelos de deep learning en la identificación de mascotas perdidas disminuirá el tiempo de retorno de la mascota a su hogar, permitiendo hacer el rastreo correcto.
- En la fase fina se recomienda probar GAN’s para data augmentation.
- En la fase gruesa, se sugiere combinar los datasets de Stanford y Thudogs, y probar los modelos desarrollados.
- En la fase gruesa, se recomienda crear un dataset propio para identificación.
- En la fase media, se sugiere probar nuevos modelos adicionales a yolo v5.
Referencias
- Dog Identification using Biometrics and Neural Networks
https://arxiv.org/pdf/2007.11986v1.pdf
- Dog Breed Identification Using Deep Learning
https://www.researchgate.net/publication/328834665_Dog_Breed_Identification_Using_Deep_Learning
- Yolo v5
Presentación del proyecto: DemoDay
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!Saturdays.AI
WRITTEN BY
Mishel Carrion Lopez

Saturdays.AI
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.

Detección de terrenos en renovación con Inteligencia Artificial
La Paz. 2021
En este artículo, veremos cómo llevar a cabo la detección de terrenos con Inteligencia Artificial con el objetivo identificar los terrenos (lotes) disponibles para producción (en renovación). De esta manera pretendemos mejorar los costes y la eficiencia que se asocian a su detección y explotación.
Entendemos por loteo de terrenos el proceso de división del suelo, cualquiera sea el número de predios resultantes, cuyo proyecto contempla la apertura de nuevas vías públicas, y su correspondiente urbanización. No obstante, analizaremos los terrenos de cara a su producción agrícola.
Los datos son extraídos de la base de datos geográficos de monitoreo de producción de los cañeros de la zona norte de Santa Cruz. Todo esto se maneja en un CATASTRO.
Esta información geográfica tiene relaciona información tabulada:
Entonces se puede tener una visualización del estado de los lotes, si están en producción (con cobertura) o en renovación (sin cobertura) a través de los polígonos que limitan los lotes y las imágenes satelitales.
Son estas imágenes en diferentes épocas del año las que permiten analizar visualmente si los lotes están en renovación o no.
Descripción del problema:
La determinación de si un lote está o no en renovación es importante ya que es una variable a la hora de calcular la producción y rendimiento de las propiedades de cada cañero, y para ello se presentan los siguientes inconvenientes:
- Las inspecciones de campo y a través de imágenes satelitales son morosas.
- Susceptible a errores.
- Demasiado tiempo invertido.
Objetivo:
Determinar si un lote de cultivo de caña está en renovación a través del cambio de cobertura a partir de los datos estadísticos de NDVI de los últimos 12 meses con Machine Learning.
Propuesta de solución.
Las imágenes satelitales pueden ser procesadas para obtener ciertos índices. El índice de interés para observar si un lote está en renovación se llama NDVI (Normalized Difference Vegetation Index):
Se puede observar los lotes con cobertura en color verde, y los que están sin cobertura en rojo, esto de los colores es solo simbología. Lo que en verdad se tiene con el NDVI es una matriz de píxeles:
Cada pixel tiene valores entre -1 y 1; siendo -1 suelos completamente descubiertos, y 1 suelos con cobertura vegetal.
Entonces, se puede obtener la estadística descriptiva de cada lote, y a través de su media y desviación estándar determinar si un lote está en renovación o no.
Como se puede apreciar, lotes con cobertura tiene una media cercana a 1 y una desviación estándar baja, y los que están sin cobertura una media cercana a 0 y también una desviación estándar baja, la desviación estándar es importante ya que determina que las uniforme son los valores de los píxeles en cada lote.
Ingeniería de características.
- Se identificó como target el campo Variedad el cual se almacena la variedad sembrada en ese lote, pero si el lote está en renovación, tiene la etiqueta “Renovación”, también cambiamos de nombre de la columna a Renovación.
- Convertimos el campo Renovación de categórico a booleano.
- Unimos los 13 dataset (1 de catastro y 12 de los valores estadísticos del último año) en uno solo dataset para mejor uso.
Visualización de Datos
- Cantidad de registros por Renovación.
- Cantidad de registros por gestión.
- Cantidad de registros por hectareaje.
- Matriz de correlación.
- Visualización del balanceo del target.
Reducción de dimensiones a través de PCA.
Se realizó la reducción de dimensiones a través de PCA a dos componentes principales, y se puede apreciar una diferencia entre los registros:
Entrenamiento de modelos
Se probaron tres tipos de modelos, también se implementó Cross Validation. Los resultados fueron los siguientes:
- Regresión Logística
- Random Forest
- SVM
Elección del mejor modelo
En base a los resultados obtenidos, elegiremos ahora el modelo de Inteligencia Artificial más adecuado para la detección de terrenos en renovación:
Se observa que los 3 modelos seleccionados se aproximan a la misma probabilidad 0.93, sin embargo, SVM tiene un mejor score.
También se decidió aplicar la Curva de ROC, y dio el dio el siguiente resultando:
En este caso Random Forest es quien presenta mayor área bajo la curva, por lo tanto, SVM y Random Forest son los mejores modelos a considerar para la clasificación de lotes en renovación.
Autores del proyecto.
- Bismark Socompi.
- Ruth Paola Vedia
- Cristian Vargas
WRITTEN BY
Bismark Socompi Rodriguez
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Diagnósticos de X-Rays con Neumonía en Niños entre 0 a 5 años con Machine Learning
La Paz. Machine Learning. 2021
(La Paz 2021) Alrededor de todo el mundo, existe un problema bastante común en la mayoría de los hospitales y es que al existir diariamente, una cantidad bastante grande de personas que buscan atención médica, el sistema de atención tiende a colapsar y una gran cantidad de personas no llegan a recibir atención médica que puede llegar a ser urgente. Tenemos que tener en cuenta que la variedad de pacientes y la variedad de casos a tratar dentro de un hospital es enorme. Sin embargo, una de las enfermedades más importantes que hay que tratar de forma rápida tras su diagnóstico es la neumonía en niños de 0 a 5 años de edad. En el presente, el Machine Learning nos permite hacer un diagnóstico de neumonía automático y rápido.
La neumonía infantil es la enfermedad infecciosa que más muertes de niños ocasiona día a día en todo el mundo. En promedio, más de 800 000 niños menores de 5 años mueren de neumonía cada año, es decir que cada 39 segundos muere un niño a causa de la neumonía. Lo más impactante en esta situación es que según el artículo realizado por la UNICEF el 20 de enero de 2020, casi todas esas muertes son prevenibles. El número abismal de muertes infantiles a causa de la neumonía es debido a que esta enfermedad se puede transmitir a la hora de respirar partículas suspendidas en el aire.
Problemática:
Teniendo en cuenta la cantidad enorme de casos de neumonía en niños menores de 5 años, ¿cómo podemos implementar una Inteligencia Artificial para que el diagnóstico de la neumonía infantil sea más eficiente?
Objetivo:
El objetivo principal de este proyecto es desarrollar una Inteligencia Artificial capaz de analizar radiografías de infantes que tengan 3 años de edad o menos. De esta forma, todo infante que tenga radiografías de sus pulmones podrá ser diagnosticado en cuestión de segundos y podrá ser llevado a un área de atención en lugar de tener que pasar primero por un doctor general que deba hacer el diagnóstico si el infante tiene o no neumonía.
Datasets:
Se utilizó el dataset “Chest X-Ray Images (Pneumonia)” encontrado en la plataforma de Kaggle. Este dataset contiene 5 863 imágenes divididas en 2 categorías: train (89.4% del dataset total), test (10.6% del dataset total). Estas dos categorías serán utilizadas respectivamente para entrenar y testear nuestro modelo. Así mismo, es importante mencionar que cada categoría del dataset está dividida en dos partes, la primera está compuesta de radiografías de infantes sin pneumonia, esta división está denominada como: “NORMAL”
La segunda parte está denominada como: “PNEUMONIA” y es donde se encuentran las radiografías de los infantes que tienen neumonía:
Proceso de identificación de la neumonía:
Para poder realizar una buena identificación de neumonía hemos decidido utilizar el filtro un filtro de escala de grises que se encuentra en la librería de cv2. Este filtro nos permite resaltar las diferentes áreas importantes del cuerpo humano. De esta forma el análisis es más certero y el accuracy del modelo más alto. Así mismo es importante tener en cuenta que si no pasaramos las imágenes por un filtro sería peligroso ya que el modelo se basaría únicamente en la imágen original y no existiría ninguna opción para eliminar el ruido de la imágen.
En la imágen previa se puede apreciar como los pulmones se ven más resaltados aplicando el filtro ya mencionado.
Subsecuentemente se realizó una normalización a todos los píxeles de cada imagen para que todo valor vaya de 0 a 1.
Así mismo, hemos utilizado la librería de Keras para incluir DataAugmentation dentro de nuestro DataSet. Esta añadidura le permite a nuestro modelo aumentar levemente el accuracy ya obtenido con el filtro de la escala de grises ya que realiza rotaciones, zoom y mueve la imagen de forma horizontal y vertical.
Una vez añadido el filtro se analiza cada imágen y se busca una opacidad homogénea presente al nivel de los pulmones, este es el principal efecto de la neumonía.
Modelos:
El modelo que hemos implementado es el CNN (Convolutional Neural Network). En resumen es un tipo de Red neuronal artificial con un aprendizaje supervisado el cual puede identificar distintas características de entrada, por así decirlo, que en algunos casos no se puede intuir.
Las convoluciones consisten en tomar toda la imagen en pixeles y aplicar cada cierto número de píxeles un kernel (una matriz pequeña) el cual altera la imagen original dependiendo el kernel que estamos aplicando.
Resultados
- Training & Validation Accuracy + Testing Accuracy & Loss
- Matriz de confusión
Se intentó una implementación de la métrica de la matriz de confusion pero por un problema de versiones no se pudo obtener los datos buscados
- Accuracy:
- User tests:
Teniendo en cuenta que si la predicción se acerca a 1 significa que la imagen es la de pulmones sanos y si se acerca a 0 significa que la imagen corresponde a pulmones con síntomas de neumonía, las predicciones realizadas por nuestro modelo son correctas.
Conclusiones y Recomendaciones
En conclusión se pudo ver que:
- Se recomienda utilizar los filtros grises para mejorar la calidad de las imágenes
- Para que no sobrecargue la máquina virtual, si es que se la programa en colab, es necesario cambiar el tamaño de la imagen para que pueda leer todas las imágenes del dataset.
- En el Data Augmentation implementado se recomienda que se aplique para mejorar el accuracy.
- Se recomienda implementar la normalización para que la predicción sea más precisa.
Referencias:
https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia
http://acodigo.blogspot.com/2013/05/procesamiento-de-imagenes-en-opencv.htmlHow to Configure Image Data Augmentation in Keras – Machine Learning MasteryImage data augmentation is a technique that can be used to artificially expand the size of a training dataset by…machinelearningmastery.com
SyDoJa
Neumonía
“Diagnósticos de X-Rays con Neumonía en Niños entre 0 a 5 años con Machine Learning”
INTEGRANTES:
Dylan Chambi Frontanilla
Joseph Anthony Meneses Salguero
Samuel Matias Escobar Bejarano
CURSO:
Machine Learning
LA PAZ 10/09 — BOLIVIA-2021
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!