Quito. 2021
Ing. Benjamin Villegas Mendez, Ing. Mauricio Oroza Herbas
INTRODUCCIÓN
Ante la pandemia del covid 19, todas las instituciones que se dedican al aprendizaje se vieron afectadas ya que dar clases no sería lo mismo por un buen tiempo. Fue así que la migración a clases virtuales ahora es un hecho. Esta migración trae consigo muchas ventajas y desventajas. El presente proyecto se enfoca en el gran problema de pérdida de atención e interés por parte de los estudiantes resultando en que solo el 40% de estudiantes realmente mantiene la atención y es capaz de aprovechar la clase impartida, ya sea a nivel de colegio, pregrado e incluso hasta postgrado. Este proyecto sugiere la solución de proveer de feedback al docente por medio de reconocimiento emocional de los rostros de los estudiantes en tiempo real. Teniendo este tipo de información a la mano, el docente puede modificar el contenido de su clase o utilizar técnicas que puedan recuperar la atención de la mayoría de sus estudiantes para hacer efectiva su clase. La solución propuesta consiste en una red neuronal convolucional recurrente con ResNet (residual network) que, mediante la webcam, reconoce que emoción está teniendo el estudiante. Se hizo una integración de 3 diferentes partes de datasets para el entrenamiento y se utilizaron técnicas para poder mejorar el desempeño del sistema. El resultado apunta a un sistema de reconocimiento facial de emociones utilizable que podría implementarse posteriormente en softwares de clases y reuniones virtuales.
DESCRIPCIÓN DEL PROBLEMA
El problema radica en la dificultad por parte de estudiantes de mantener atención en clases virtuales resultando en que 6 de cada 10 estudiantes pierden la atención en la clase impartida. A diferencia de las clases presenciales, los docentes tienen poco o ningún feedback sobre el estado de atención de sus alumnos dificultando que el docente pueda tomar acciones para mantener la atención de dichos.
OBJETIVOS
El objetivo general es la creación de un modelo de deep learning que pueda predecir en tiempo real las emociones de una persona frente a su webcam, dentro de un entorno de programación.
En los objetivos particulares, se cita seleccionar un dataset que pueda ser adecuado para el fin perseguido, implementar un sistema de reconocimiento facial solamente, y seleccionar un modelo de clasificación adecuado para poder crear el modelo general de reconocimiento de emociones.
SELECCIÓN DEL DATASET
Se hizo una búsqueda de datasets relacionados a emociones y se encontró una lista de los datasets más utilizados como se muestra en la figura a continuación:

El principal criterio para la selección fue buscar datasets que estén disponibles de forma gratuita que estén dentro de la lista presentada anteriormente, los cuales son FER2013 y CK+. Para el presente proyecto se utilizó una mezcla de ambos datasets incluyendo un dataset propio creado. Los 2 primeros datasets son bastante utilizados para reconocimiento facial actualmente y tienen bastante cantidad de datos relevantes para el proyecto en curso. Por tema de costo, se buscó fragmentos de dichos datasets que estén disponibles de forma gratuita y se los integró en uno solo. Se revisaron los dataset manualmente para eliminar posibles imágenes que no correspondan con la emoción, se agregaron datos y se utilizó data augmentation.
SELECCIÓN DE LOS MODELOS
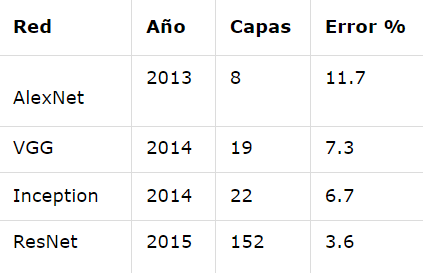
Dado que se trata de un problema de clasificación de imágenes con 7 posibles salidas (correspondientes a 6 emociones faciales detectables básicas y una neutral) se estudiaron varias posibles arquitecturas de computer vision y clasificación de imágenes entre las que se pueden mencionar: AlexNet, VGG, inception y ResNet. Siendo esta última la escogida para el modelo propuesto dada su versatilidad en el entrenamiento de redes profundas sin presentar el problema de desvanecimiento de gradiente (vanishing gradient).
En la siguiente tabla se puede observar su porcentaje de error frente al dataset de clasificación de imágenes de la competencia ImageNet de 2015.
El principio de funcionamiento de las redes residuales (ResNet) puede entenderse analizando lo que sus autores denominan bloque residual convolucional.
Si suponemos que la salida del bloque F(x) tiene la misma dimensión que su entrada x, se conoce a este bloque como bloque residual identidad que puede resumirse bajo la siguiente fórmula:
x = x + F(x)
Donde por simplicidad la salida del bloque también se llamará x.
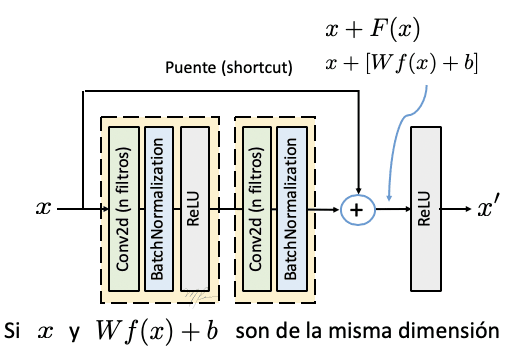
Los datos resultantes del bloque residual Identidad no son modificados, esto es porque el tensor que resulta de las etapas convolucionales F(x) es de las mismas dimensiones que los datos originales, por lo que no es necesario ajustar las dimensiones para sumarlos.
En el caso que las dimensiones de salida y el tensor de entrada sean diferentes porque se incrementen el número de canales o se modifiquen las dimensiones del tensor será necesario aplicar operaciones a x para hacer congruentes las dimensiones.
Por ello, para poder hacer la suma de la liga residual con los datos procesados, se agrega una capa convolucional (sin activación) en la liga puente con paso de dos y con el número de canales requeridos.
X = [Vx + b] + F(x)
A este bloque se le conoce como bloque residual convolucional.

Para el caso del modelo implementado para reconocimiento de emociones se implementó una red ResNet de 9 bloques para que el entrenamiento no sea demasiado extenso ni consuma demasiados recursos del GPU y memoria asignados en el notebook diseñado.
TÉCNICAS IMPLEMENTADAS
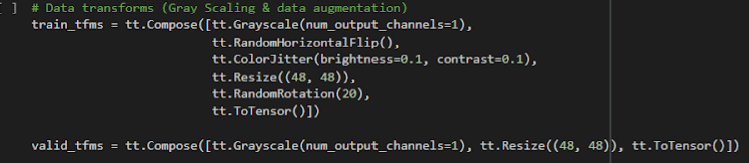
Dada la naturaleza del dataset compuesto utilizado, cuyas imágenes contienen variación de tamaños, imágenes a color y en escala de grises además de para algunas de las emociones detectadas se tienen menos imágenes para la etapa de entrenamiento que otras, se utilizaron las siguientes técnicas de data augmentation:
- Random horizontal flip: Utilizada para aleatoriamente espejar imágenes en sentido horizontal.
- Color Jitter: Para aleatoriamente ajustar el brillo y contraste de las imágenes.
- Resize: Para parametrizar el tamaño de las imágenes antes de la entrada al entrenamiento
- Random rotation: Para aleatoriamente girar imágenes en 20 grados de su posición original.
- Grayscale: para que todas las imágenes de entrada sean en escala de grises.
- To Tensor: Para convertir las imágenes en tensores previamente al entrenamiento
También se utilizaron algunas técnicas para hacer el entrenamiento más óptimo:
- Learning Rate Scheduling: Para tener un learning rate variable a medida que avanza el entrenamiento en cada epoch, siendo así que alrededor del 30 por ciento de las epochs se tenga el máximo valor del learning rate.
- Weight Decay: Previene que los pesos sean demasiado grandes.
- Gradient Clipping: limita los valores de los gradientes a un rango pequeño para evitar cambios no deseados en los parámetros debido a grandes valores de gradiente.
Cabe mencionar que en la construcción del modelo ResNet se utilizaron también técnicas conocidas de optimización como ser: batch normalization, maxpool y dropout.
En el caso de la detección de rostros para su posterior clasificación, se utilizó el modelo pre entrenado de Open CV “Haar cascade frontal face” cuya llamada a dicho modelo se hace dentro de un script de JavaScript para el manejo de Webcam dentro de Colab en tiempo real.
EVALUACIÓN DE LOS MODELOS
Dentro de la función desarrollada en JavaScript para el acceso a Webcam en tiempo real, se encuentran tanto el modelo pre entrenado de detección de rostros como el modelo entrenado para la clasificación de emociones, ambos funcionan en tiempo real logrando de esa manera detectar emociones en cuestión de segundos mientras se van guardando las predicciones obtenidas para realizar gráficas al finalizar la ejecución de la función como en la siguiente gráfica
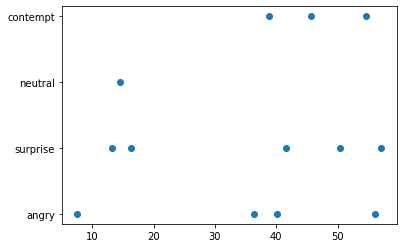
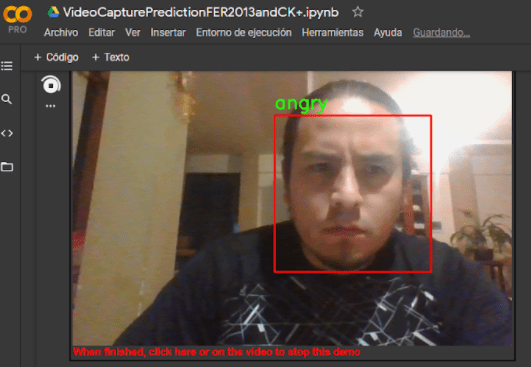
La siguiente imagen muestra una captura de pantalla del modelo en pleno funcionamiento detectando la emoción de enojo (angry).
ANÁLISIS DE LOS RESULTADOS
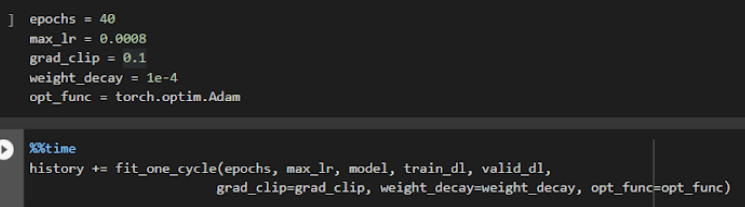
Se utilizaron 40 epochs para el entrenamiento del modelo diseñado logrando una precisión del 70% en un tiempo de entrenamiento de aproximadamente 40 minutos. Cabe mencionar que el accuracy a lo largo de las epoch no fluctúa demasiado, esto después de haber modificado el dataset de forma manual eliminando imágenes consideradas ruido.

Es posible ver el cambio del learning rate durante el entrenamiento en la siguiente imagen.

Las predicciones del modelo en general son acertadas tomando en cuenta que Google Colab tiene recursos limitados de GPU y memoria asignada a cada notebook.
CONCLUSIONES
-Un buen dataset es imprescindible para una buena detección, al conseguir fragmentos de datasets de forma gratuita, se evidencio que tenían imágenes erróneas que no correspondian con la emoción a detectar, es por eso que se tuvo que analizar cada imagen del dataset, limpiar y agregar datos para poder tener un resultado certero. Se recomienda acceder a dataset elaborados por universidades o instituciones dedicadas a la investigación.
-Se utilizó un modelo pre-entrenado para el reconocimiento de rostros, y posteriormente se creó un modelo propio capaz de detectar emociones en tiempo real con un accuracy de 70%.
-La utilización de redes neuronales residuales que beneficiaron en un tiempo de entrenamiento más corto con resultados aceptables.
-Se implementó el sistema de reconocimiento de emociones en tiempo real dentro del entorno de colab con funciones de javaScript, de otra forma no sería posible el manejo de una webCam dentro de colab.
-Se guardan los datos y se presentan distintas gráficas al final de la detección con el fin de que el docente pueda tener visualización de los datos obtenidos durante toda su clase.
- Las aplicaciones posteriores de este modelo pueden ser utilizadas en detección de emociones en marketing, creación de contenidos y desarrollo de productos.
El código completo tanto del notebook usado para el entrenamiento como el notebook usado para la ejecución misma del modelo pueden encontrarlos en:
https://github.com/benjorocker94/Face-emotion-recognition-with-cola
BIBLIOGRAFÍA
- Mellouck & Handouzi. (2020). Facial emotion recognition using deep learning: review and insights. Procedia Computer Science. https://www.sciencedirect.com/science/article/pii/S1877050920318019
- Minae et al. (2019). Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional Network
- Rivera. (2019). La Red Residual (Residual Network, ResNet).http://personal.cimat.mx:8181/~mrivera/cursos/aprendizaje_profundo/resnet/resnet.html#par%C3%A1metros-del-modelo-vs-la-exactitud-accuracy
- Bok. (2020). Getting Started with Albumentation: Winning Deep Learning Image Augmentation Technique in PyTorch example. https://towardsdatascience.com/getting-started-with-albumentation-winning-deep-learning-image-augmentation-technique-in-pytorch-47aaba0ee3f8
- Rohan Singh. (2020). Emotion Detection Using Pytorch. https://medium.com/swlh/emotion-detection-using-pytorch-4f6fbfd14b2e
Repositorio
En el siguiente repositorio se encuentra el código usado para desarrollar esa aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Quito/2021/Face-emotion-recognition-with-colab-main
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) a la vez que se realizan proyectos para el bien (#ai4good). Los talleres que realizamos forman parte del programa AI 4 Schools para que cualquier persona “aprenda haciendo” IA sin importar su especialidad o nivel de partida.
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en este link o visítanos en nuestra web www.saturdays.ai ¡te esperamos!