

La Paz. Deep Learning. 2021
De acuerdo con las Naciones Unidas, el discurso de odio se define como “Todas las formas de expresión que comparten, alienten, justifiquen o promueven la humillación, el menosprecio, la estigmatización o amenaza contra una persona o grupo como las mujeres y las niñas”.
Actualmente, estamos experimentando una oleada de discurso de odio en varios ámbitos y hacia diferentes minorías. Por ejemplo, después de la final de la Eurocopa 2020 se desató una ola de ataques racistas en redes sociales contra jugadores de la sección inglesa después de haber fallado penales. En particular, se destaca el uso de Internet para la propagación de este tipo de agresiones gracias a que éste proporciona anonimidad, distanciamiento, ausencia de normativa de los contenidos, entre otros.
Las redes sociales y otras plataformas en Internet cuentan con algunos mecanismos automáticos para detectar discursos de odio. Estas herramientas han adquirido mayor relevancia ante diversos sucesos que han disparado la proliferación de contenido con discurso de odio. La siguiente gráfica muestra cómo el discurso de odio aumentó durante el año de pandemia, según los mensajes de odio eliminados por Facebook:
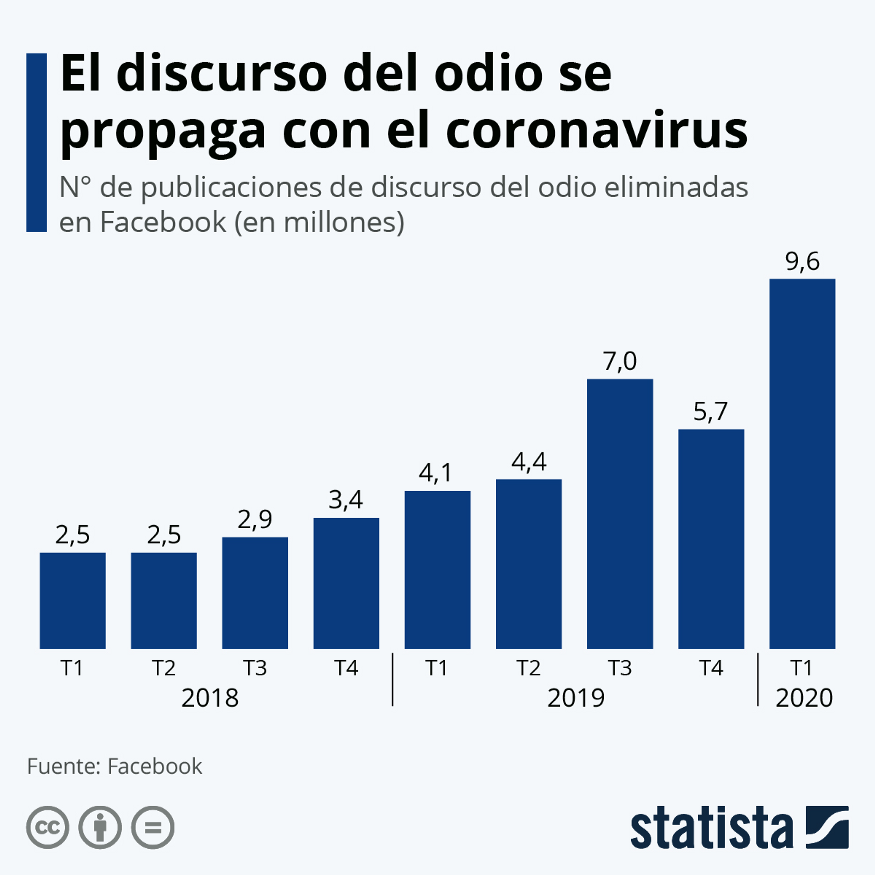
Figura 1:Número de publicaciones con discurso de odio eliminadas en Twitter. Fuente: https://es.statista.com/grafico/21710/publicaciones-de-discurso-del-odio-eliminadas-por-facebook/
Sin embargo, estas herramientas no se encuentran disponibles para cualquier ciudadano que quisiera analizar contenidos para determinar la existencia de discurso de odio. Es por esta razón que decidimos construir un método que sirviera como herramienta o base para la construcción de tecnologías que pudieran ayudar en la detección de este tipo de comentarios y así poder detener su propagación.
En este artículo, describimos cómo aplicamos métodos de Deep Learning y Procesamiento de Lenguaje Natural (NLP, por sus siglas en inglés) para la detección de discurso de odio en comentarios de Twitter en idioma español. Este trabajo es una continuación del proyecto Violentómetro Online. En dicho proyecto tuvimos un primer acercamiento al problema de detección de discurso de odio contra mujeres mediante el uso de técnicas clásicas de Machine Learning.
Solución
En esta sección, describimos la metodología (Transformers y Data Augmentation), así como los datos que utilizamos durante la realización de este proyecto. También detallamos los parámetros del modelo y las técnicas de interpretación que empleamos para entender sus predicciones.
Conjunto de Datos
MEX-A3T: Fake News and Aggressiveness Analysis es un evento organizado por la comunidad de NLP en México para detectar noticias falsas y textos con discurso de odio. Los organizadores compartieron con el equipo el conjunto de datos de entrenamiento que consiste en Tweets en el idioma español. El conjunto tiene las siguientes características:
- 7 mil 332 registros
- 2 columnas:
- Text: Texto del Tweet (no contiene handlers).
- Category:
- 1: Contiene odio en general (2110 registros)
- 0: No contiene odio (5222 registros)
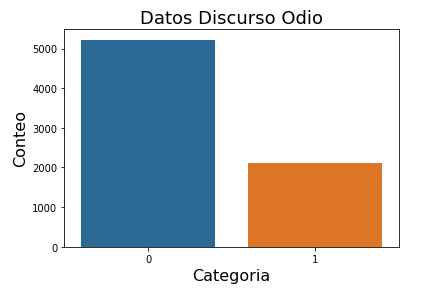
Data Augmentation
La distribución del conjunto de datos (Figura 2) muestra que se tienen menos registros de la categoría 1 (discurso de odio). Este problema afecta en particular a los modelos de Deep Learning por lo que fue necesario aplicar técnicas que nos permitieran generar nuevos ejemplos (sintéticos) para tener una cantidad de registros cercana a la de la categoría 2.
Las operaciones de data augmentation que se aplicaron al 50% de mensajes de discurso de odio del dataset para obtener más ejemplos son las siguientes:
- Synonym Replacement: Reemplazo de algunas palabras por su sinónimo.
- Random Deletion: Borrado de algunas palabras de manera aleatoria con probabilidad p.
- Random Swap: Intercambio de palabras de manera aleatoria.
- Random Insertion: Inserción de un sinónimo en una posición aleatoria n.
Modelo
Para crear el modelo utilizamos la librería de Transformers de Hugging Face (Figura 4) que contiene modelos de Deep Learning pre entrenados para varios propósitos como clasificación de texto, extracción de información, traducción, entre otros. En particular utilizamos el modelo BETO, el cual es un modelo con la arquitectura BERT entrenado con un corpus en español, para obtener la representación vectorial del texto (embeddings). Además se utilizaron dos capas adicionales: multi-layer bi-directional GRU y otra lineal que obtiene las predicciones. Es posible utilizar otras arquitecturas en lugar de multi-layer bi-directional GRU, pero para este proyecto decidimos utilizar ésta ya que es más eficiente computacionalmente que LSTM.
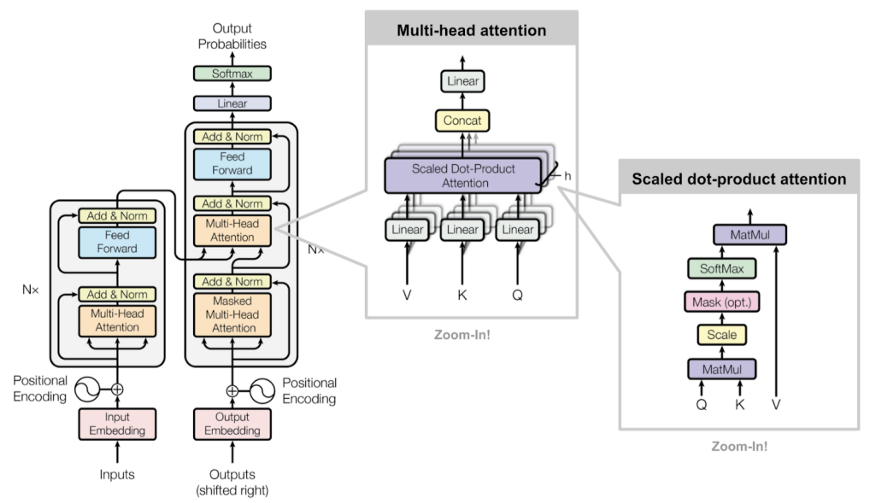
Figura 3: Arquitectura de Transformers. Fuente: https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html#transformer
Nota: El código completo se puede consultar en el repositorio del proyecto violentometro-online.
Mejores Parámetros
Probamos diferentes variaciones de BETO para obtener los mejores parámetros de entrenamiento para el modelo final. Evaluamos cada modelo utilizando la métrica F1 ya que ésta es comúnmente utilizada en problemas de clasificación de textos además de tomar en cuenta las siguientes variaciones:
- Model: Variación de BETO (cased y uncased).
- Epochs: Número de iteraciones en el entrenamiento.
- Preprocessed: Preprocesamiento del texto que incluye operaciones como remover emojis, dígitos, stopwords, entre otros.
- Sample frac: Proporción de ejemplos sintéticos en el conjunto de datos.
La siguiente tabla muestra los modelos con los que obtuvimos los mejores resultados:
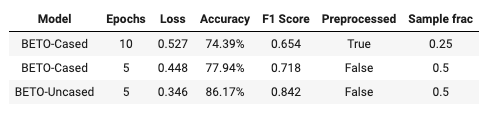
Como podemos observar, el mejor modelo (BETO-Uncased) no requirió un preprocesamiento del texto además de que fue necesario generar una importante cantidad de datos sintéticos. Dicho modelo obtuvo el mejor valor (0.842) de la métrica F1. Queremos resaltar que dicho resultado es mucho mejor al que habíamos obtenido anteriormente utilizando el modelo de Random Forest..
Explicación de las Predicciones
Utilizamos la API Lime para obtener una explicación detallada de las predicciones del modelo. Lime es capaz de explicar cualquier modelo de clasificación que haga predicciones de una o más clases. Para poder utilizar Lime es necesario crear una función que regrese un arreglo de Numpy con las probabilidades de cada una de las clases. Lime muestra los pesos de cada una de las palabras del texto en la predicción. La Figura 4 contiene la explicación de la predicción de un texto:
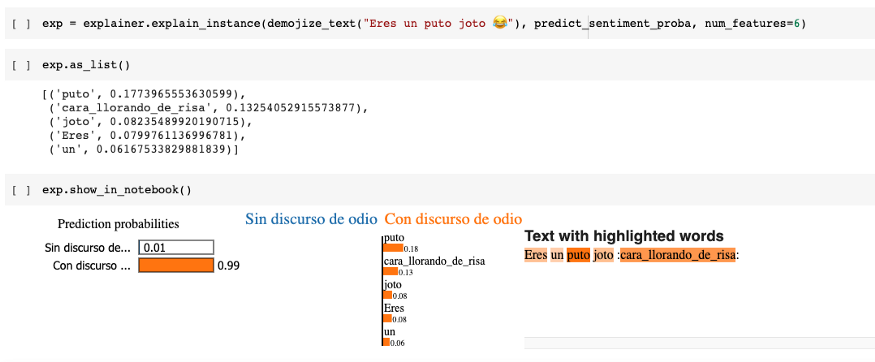
Se puede observar que en la predicción del modelo, se le dio más peso a la palabra que aparece primero en la lista además de la representación en texto del emoji.
Aplicación Web
Desarrollamos el prototipo de una aplicación web con el modelo que obtuvo los mejores resultados. Dicha aplicación web se puede consultar aquí. El prototipo fue desarrollado con el framework Streamlit y se utilizó GitHub Actions para desplegarlo (integración continua) en AWS. La siguiente imágen muestra el prototipo:
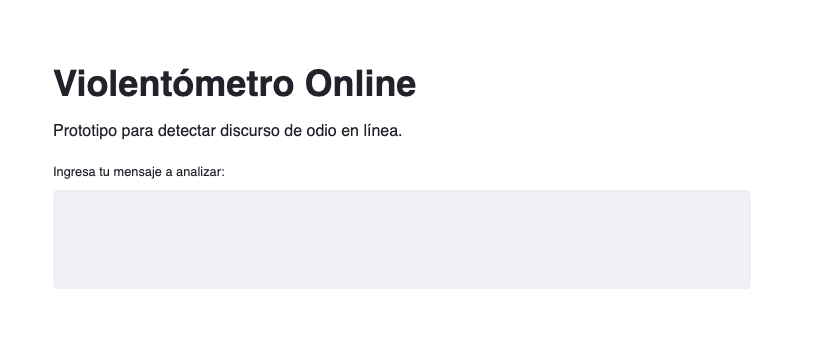
Los usuarios pueden introducir cualquier texto en la aplicación. Cuando los usuarios pulsan las teclas Ctrl+Enter, la aplicación (modelo) devuelve como resultado las siguientes categorías:
- 1 = Contiene discurso de odio
- 0 = No contiene discurso de odio
Conclusiones
El objetivo de nuestro proyecto es desarrollar un método efectivo para detectar automáticamente la violencia verbal en idioma español que ocurre en discursos en línea. Con este proyecto pudimos crear un método que tiene una efectividad bastante razonable utilizando técnicas avanzadas como Deep Learning y data augmentation, además de estar construido con herramientas gratuitas y de código abierto. También se utilizó una API que nos permitió entender las predicciones del modelo.
Entre los siguientes pasos de nuestro proyecto podemos destacar lo siguiente:
- Utilizar otras variantes del idioma español.
- Recolectar más ejemplos de discurso de odio que se encuentren dirigidos a diferentes minorías (mujeres, religiones, opiniones, entre otros) para obtener un modelo más robusto.
- Incorporar un mecanismo de feedback para los usuarios de la aplicación web.
Agradecimientos
Queremos agradecer a María José Díaz-Torres, Paulina Alejandra Morán-Méndez, Luis Villasenor-Pineda, Manuel Montes-y-Gómez, Juan Aguilera, Luis Meneses-Lerín, autores del Dataset MEX-A3T y del artículo Automatic Detection of Offensive Language in Social Media: Defining Linguistic Criteria to build a Mexican Spanish Dataset. También queremos agradecer al equipo que hizo posible Saturdays.AI La Paz por todo su trabajo y dedicación en la organización del programa.
Fuentes
- LA ESTRATEGIA Y PLAN DE ACCIÓN DE LAS NACIONES UNIDAS PARA LA LUCHA CONTRA EL DISCURSO DE ODIO: https://www.un.org/en/genocideprevention/documents/advising-and-mobilizing/Action_plan_on_hate_speech_ES.pdf
- Detecting gender-based hate speech in Spanish with Natural Language Processing: https://becominghuman.ai/detecting-gender-based-hate-speech-in-spanish-with-natural-language-processing-cdbba6ec2f8b
- EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. Jason Wei, Kai Zou. EMNLP-IJCNLP 2019
- BETO: Spanish BERT: https://github.com/dccuchile/beto
- Lime project: https://github.com/marcotcr/lime
Integrantes
Presentación del proyecto: DemoDay
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) a la vez que se realizan proyectos para el bien (#ai4good). Los talleres que realizamos forman parte del programa AI 4 Schools para que cualquier persona “aprenda haciendo” IA sin importar su especialidad o nivel de partida.
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en este link o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
