Latam online. Primera Edición. 2020
¿Te has puesto a pensar, qué escuchan tus hijos?
¿Alguna vez has pensado cómo influye la música en nuestra sociedad y viceversa?
Actualmente estamos rodeados de una gran cantidad de música que, aunque tiene ciertos filtros y criterios para su publicación, en ocasiones llega a oídos de cierta población que resulta afectada por el mensaje que se transmite. Hoy en día ya no es necesario contar con una disquera para promocionar una canción, ya que el acceso a las redes sociales permite que cualquier persona con un celular y acceso a internet se grabe y publique su canción llegando a miles de personas en el mundo, entre ellos menores de edad, como tus hijos.
Para que una canción llegue a ser escuchada existen varios canales de distribución como televisión, radio y las redes sociales, y si no se cuenta con un filtro adecuado, todo tipo de canciones con diferente contenido puede estar llegando a los oídos de menores de edad.
Nuestra propuesta se basa en identificar las canciones en las que, en su letra, exista contenido violento. De acuerdo al artículo “La violencia contra las mujeres en la música: Una aproximación metodológica”[1], dónde se habla sobre la violencia contra las mujeres en la música, indica que:
“en los casos más negativos se proyecta estereotipos que sitúan al hombre y a la mujer en posiciones sociales distintas, incluso llegando a justificar y potenciar la violencia contra las mujeres“.
Es por ello que este proyecto tiene como ambición contribuir al cumplimento de uno de los diecisiete Objetivos de Desarrollo Sostenible, planteados por las Naciones Unidas y aceptados por varios países en Latinoamérica, específicamente el objetivo cinco referente a la equidad de género. Para identificar y concientizar a la población sobre el mensaje que transmite la música y, de esta manera, empoderar a la población que tiene acceso a plataformas digitales de música, sobre los mensajes en las canciones que escucha.
Al inicio de este proyecto, se planteó una lluvia de ideas, se pensó en crear una app que al escuchar o ingresar una canción indique si esta contiene diversos tipos de violencia en sus letras, mediante el uso de Procesamiento Natural de Lenguaje (NLP), para lo cual se propuso el siguiente etiquetado:
Apto para menores de edad
No contiene ningún tipo de violencia, el mensaje y contexto de la canción debe ser revisado por un adulto.
Extracción de datos
Para ello, se empezó a analizar una muestra de 500 canciones, las cuales se seleccionaron de listas de popularidad de música latina, ya que el proyecto se plantea para la población hispanoparlante de América Latina, por lo que el flujo de trabajo quedó de la siguiente manera:
1) Se buscó en los rankings de Billboard y de Scanner Sound, la lista de canciones más tocadas con un web scraper, con lo que se obtuvo artista y título.
2) Mediante las herramientas de desarrollador de musixmatch se obtuvo la api el género musical de cada canción y si estas tienen lenguaje ‘explícito’, sin embargo solo nos proporcionaba el 40% de las letras.
3) De Google se obtuvo la letra de las canciones el cual se nutre de dos proveedores: Musixmatch y LyricFind, con lo que, finalmente, se obtuvieron los siguientes campos:
- Artista
- Género
- Título
- Si es explícita o no (lenguaje inapropiado)
Luego, se realizó la extracción de las letras de las canciones mediante API’s que ofrecen los sitios más populares de música (Musixmatch y el Billboard) mediante sus herramientas para desarrolladores.
Una vez que se obtuvieron las letras de las canciones se procedió al etiquetado manual, el cual se realizó de acuerdo a los tipos de violencia anteriormente expuestos. El equipo desarrollador de este proyecto, etiquetó las categorías de entrenamiento, con lo que se obtuvo una siguiente fuente de datos, su representación se puede ver a continuación:

Resulta importante destacar que, debido a que el etiquetado de cada categoría está sujeto a los criterios de cada integrante del equipo, el conjunto de datos podría tener un sesgo. Vale la pena mencionar, que esta etapa del proyecto es una prueba de concepto que nos servirá para validar la factibilidad de realizar un etiquetado automático de acuerdo al objetivo planteado. Además, al observar que el número de positivos en cada categoría no era suficiente para que el algoritmo pudiese tener un buen aprendizaje, se decidió agregar una categoría adicional, llamada ‘clase’, la cual indica si tiene contenido violento. Este cambio dentro del alcance se abordará más adelante.
EDA
Luego se procedió a realizar el Análisis Expiatorio de Datos (EDA). Para preparar los datos utilizando la librería ‘pandas’ para Python, así como matplotlib, seaborn y plotly para este primer análisis que nos permitiera tomar decisiones previas al preprocesamiento de los datos y tener un panorama de cómo se distribuían las clases en nuestra ‘data set’. y obtener un corpus que nos sirviera de base para iniciar con el análisis utilizando NLP.
Del conjunto de datos generado se obtuvieron algunos ‘insights’ interesantes mediante un primer Análisis Expiatorio de Datos (EDA):
Análisis/distribución de tipos de violencia
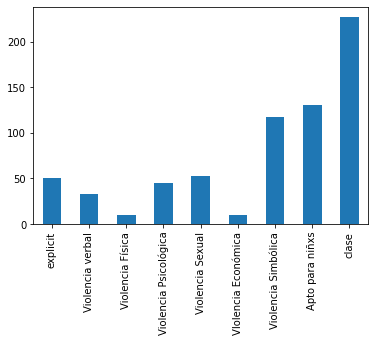
Gráfica de Barras que muestra el número de incidencias en cada clase del ‘data set’
En esta gráfica de barras podemos observar la distribución de los tipos de violencia que contiene la música seleccionada, en este caso, la mayor predominancia son géneros musicales de reggaeton, regional mexicano y pop en español debido a que se obtuvieron las canciones más escuchadas del momento, sin embargo, esta información no se utilizará para el algoritmo ya que podría crear un sesgo importante, como se puede observar en el histograma de acuerdo a los géneros. Vale la pena mencionar que este análisis se hizo antes de normalizar los datos para tener un panorama de cómo están distribuidos los datos.
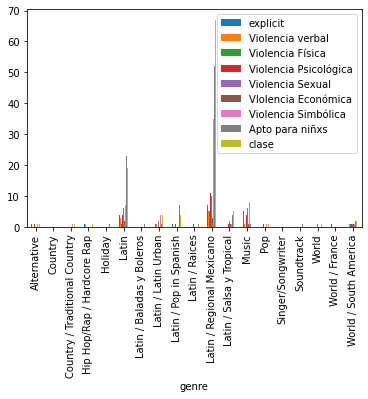
Gráfica de barras que muestra cómo se distribuyen los tipos de violencia por género musical.
Se realizó un mapa de calor para descubrir cómo se relacionan los tipos de violencia dentro de las canciones que se consideraron.

Después del análisis de los tipos violencia, consideramos que separar la cantidad de canciones en las siete categorías seleccionadas no sería suficiente para hacer una buena clasificación ya que tenemos relativamente pocos positivos en cada categoría. Con base en esta observación, para una primera fase, se realizará la separación solo en 2 categorías: “violento” y “no violento”. Algo muy importante de destacar es, que aunque una canción no contenga violencia, no quiere decir que sea apto para infantes, debido a que podría tocar temas no aptos para ciertas edades.
Análisis con mapas de palabras con y sin la etiqueta de violencia
En una segunda aproximación, durante el preprocesamiento de los datos se obtuvieron mapas de palabras, como un segundo EDA, con el fin de identificar las palabras más frecuentes en contenido violento y no violento y reconocer algunas “stopwords” que debemos considerar o, en dado caso, palabras que deban lematizarse.
El preprocesamiento de los datos, en este caso, se realizó de la siguiente manera:
1) Normalización datos/letras de canciones (acentos, mayúsculas, signos de puntuación y eliminación de palabras como ‘oh’, ‘yeah’, ‘ma’, etc.)
2) Tokenizado de palabras
3) Remoción de ‘stopwords’
4) Lematización (en una siguiente etapa se considera ver si ‘stemming’ podría ayudar a obtener mejores resultados)
5) Vectorización de las canciones (en esta etapa del proyecto se emplea Bag of Words).
Posterior a que se hizo el preprocesamiento, se emplearon nuevamente mapas de palabras para observar qué palabras podrían ser más recurrentes en una canción con violencia y sin violencia. Sin embargo, al obtener los mapas de palabras, se observó que en ambos casos predominan palabras como: haber, querer, hacer y tener. Por lo que se incluyeron a la lista de ‘stopwords’ y se volvió a hacer un análisis con una nube de palabras.




Como se puede observar, ambas clasificaciones siguen teniendo algunas palabras en común como “decir” y “saber”. Sin embargo, se pueden observar diferentes palabras en el mapa de las canciones ‘con violencia’, como “olvidar”, “morir”, “perder”, “dejar”, etc.
Una vez que se tuvo la ‘corpora’ preparada y se aplicó la vectorización Bag of Words, se trabajó con la etiqueta de “violento” o “no Violento”, que va a representar si la canción tiene cualquier tipo de violencia en su contenido.
Entrenamiento y selección del modelo
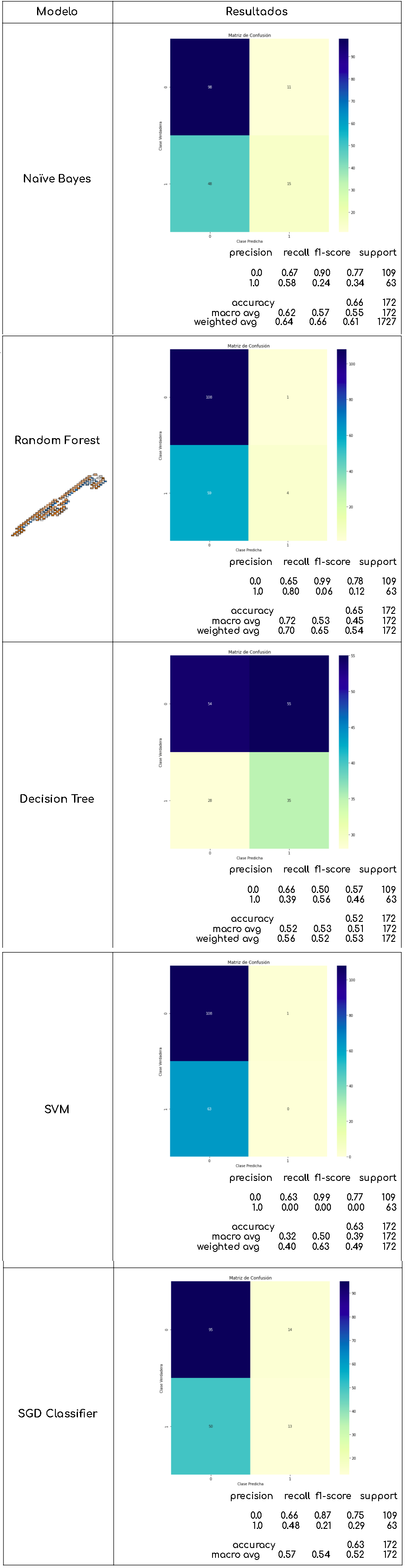
Se probó con diferentes algoritmos, después de aplicar la representación ‘bag of words’ y usando la técnica de lematización con las herramientas de nltk, para los modelos se ocuparon las librerías de sklearn como Naive Bayes, Random Forest, Decision Tree, SVM y SGD.
Por cada modelo, se presentó un reporte de clasificación para visualizar su precisión ‘accuracy’ , pero también se consideró el f1-score para evaluarlos junto con un mapa de calor de la matriz de confusión.
Para poder comparar mejor el desempeño de los modelos, también se emplearon las curvas ROC. Lo cual nos muestra de una forma más visual el comportamiento de los modelos entre sí
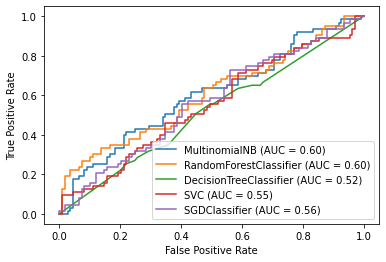
Curvas ROC de los modelos
Como se observa en la gráfica de curvas ROC, los modelos que tuvieron mejor desempeño fueron ‘Random Forest’ y ‘Naïve Bayes’, que tienen resultados muy similares. Sin embargo, si observamos las matrices de confusión y el ‘F1 Score’ podemos concluir que con los datos que se tienen, ‘Naïve Bayes’ es el modelo que mejor comportamiento tiene en esta etapa del proyecto. Ya que para nosotros es mejor tener una etiqueta de violencia aunque no la tenga, a que una canción con violencia sea erróneamente clasificada y llegue a menores de edad. Es decir, en términos técnicos es mejor para nosotros tener un error tipo I (falsos positivos), a un error tipo II (Falsos negativos).
Escalabilidad del proyecto
Con base en los datos generados, se hizo el aprendizaje considerando sólo 2 categorías ‘con violencia’ y ‘sin violencia’, debido a que la cantidad de canciones utilizadas no serían suficientes para que el algoritmo pueda diferenciar entre 6 clases diferentes, incluso se piensa que en un futuro, con mayor cantidad de datos de aprendizaje, se pueda hace la clasificación en 3 o 4 categorías, dependiendo del número de positivos que podamos obtener.
De obtener buenos resultados, se podría crear una API para uso en aplicaciones móviles o como plug in, con el fin de facilitar el reconocimiento de una canción y saber si dicha canción tiene o no contenido violento.
El conocer de antemano si una canción tiene o no contenido violento, será de ayuda para empoderar a los usuarios y reflexionar sobre el impacto que tiene lo que se escucha en la cultura popular sobre nuestras vidas y la cultura de la población.
Un caso particular de una aplicación podría ser como herramienta de detección de ‘violencia mediática’, en una ley recientemente aprobada en México: la ley ‘Olimpia’, en la cual se integró este término, que como se puede leer en el periódico Excélsior[2], se define como:
Todo acto que a través de cualquier medio de comunicación:
-Promueva estereotipos sexistas.
-Haga apología de la violencia contra mujeres y niñas.
-Produzca o permita la producción y difusión de discursos de odio sexista.
-Promueva la discriminación de género o desigualdad entre mujeres y hombres.
-Cause daño a las mujeres y niñas de tipo psicológico, sexual, físico, económico, patrimonial o feminicida.

Glosario:
NLP: Procesamiento Natural del Lenguaje, por sus siglas en inglés (Natural Language Processing) es la rama de la Inteligencia Artificial que estudia la interacción del lenguaje humano con las computadoras.
Corpus (pl. corpora): Un corpus lingüístico es un conjunto amplio y estructurado de ejemplos reales de uso de la lengua. Estos ejemplos pueden ser textos (los más comunes), o muestras orales (generalmente transcritas). [3]
Lematización: Relaciona una palabra flexionada o derivada con su forma canónica o lema. Y un lema no es otra cosa que la forma que tienen las palabras cuando las buscas en el diccionario. [4]
Stopword: Palabras muy comunes y poco informativas desde el punto de vista léxico, tales como conjunciones (y, o, ni, qué), preposiciones (a, en, para, por, entre otras) y verbos muy comunes (ser, ir, y otros más).[4]
Referencias:
- Gómez Escarda, María., Pérez Redondo, Rubuén J. (2016) “La violencia contra las mujeres en la música: Una aproximación metodológica”. Universidad Rey Juan Carlos, España.
- Robles De la Rosa, Leticia (Noviembre 2020). Aprueban ‘Ley Olimpia’ para todo el país; establecen delito en el Código Penal Federal. Excélsior. https://m.excelsior.com.mx/nacional/aprueban-ley-olimpia-para-todo-el-pais-establecen-delito-en-el-codigo-penal-federal/1415366
- Werner, Welte; Meno Blanco, Francisco (1985). Lingüística Moderna: Terminología y Bibliografía. Madrid: Gredos.
- Urdaneta Fernández, Lino Alberto (4 Mayo 2019). Reducir el número de palabras de un texto: lematización y radicalización (stemming) con Python. Medium. https://medium.com/qu4nt/reducir-el-n%C3%BAmero-de-palabras-de-un-texto-lematizaci%C3%B3n-y-radicalizaci%C3%B3n-stemming-con-python-965bfd0c69fa
Integrantes
- Álvarez Leandro
- Cuadros Alejandra
- Morales Leobardo
- Ramírez Héctor
- Samaniego Luis
Presentación del proyecto: DemoDay
Repositorio
En el siguiente repositorio se encuentra el código usado para desarrollar esta aplicación:https://github.com/SaturdaysAI/Projects/tree/master/LATAM_remote/NLP_Violencia-en-musica–master
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!