
Registrar lo que comemos es útil, pero aburrido. Abrir una app, buscar “arroz”, comparar marcas, ajustar gramos… ¿Y si hiciéramos una foto y la IA reconociera el plato para darnos una estimación nutricional? Sin cuentas, sin subir nuestros datos a servidores misteriosos.
Así nace FoodCheck, una web app estática desplegada en GitHub Pages que detecta alimentos en fotos, estima porciones y calcula nutrientes usando OpenFoodFacts. La “magia” de visión no va en el navegador ni en un backend tradicional, sino que la delegamos a un Cloudflare Worker que usa Workers AI (modelo LLaVA).
La idea detrás de FoodCheck
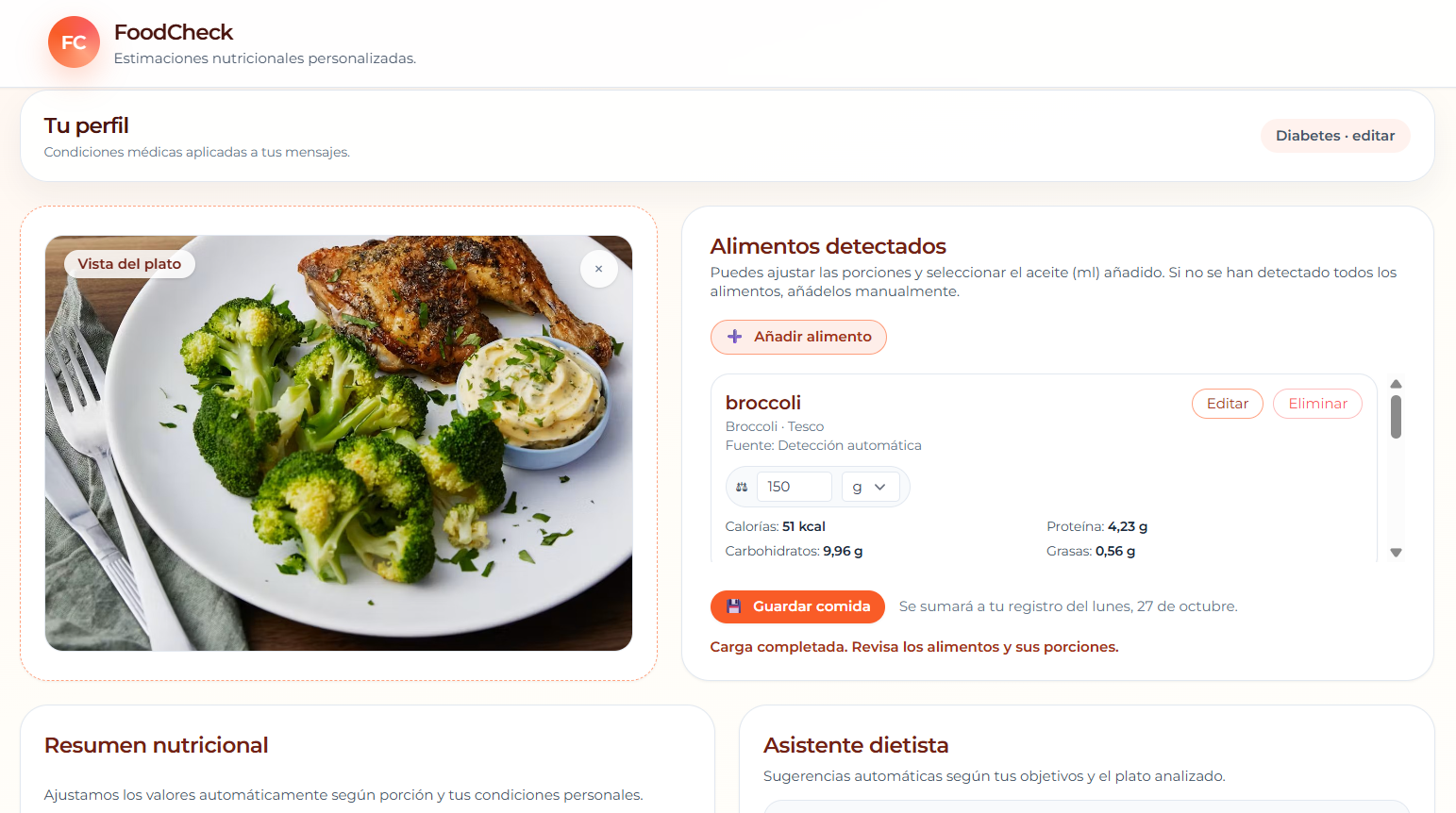
El usuario abre la app, selecciona si tiene alguna enfermedad y arrastra una foto de la comida que quiere analizar. La aplicación detecta entonces los alimentos, estima cantidades y muestra la información nutricional. Luego puede ajustar gramos, añadir nuevos alimentos y guardar la comida del día.
Todo se almacena en local, sin servidores externos.
Herramientas
- Visual Studio Code
- HTML, Tailwind CSS y Javascript
- Google Fonts (Montserrat)
- OpenFoodFacts (API pública, sin API key)
- Cloudflare Workers AI (modelo @cf/llava-hf/llava-1.5-7b-hf)
- Despliegue: GitHub Pages (frontend) + Cloudflare Workers (proxy e IA)
Un frontend minimalista
Cuando queremos prototipar una idea rápidamente, a menudo menos es más. En el caso de FoodCheck, el frontend puede ser tan simple como un único archivo index.html. No necesitas frameworks pesados ni configuraciones complejas para empezar a experimentar.
Para conseguir una interfaz simple pero funcional que permita al usuario subir una imagen y obtener resultados de análisis visual, usamos:
- Tailwind CSS para estilos rápidos.
- Montserrat, una fuente elegante que mejora la estética general.
- Un pequeño script que gestiona el flujo de interacción con el backend (en este caso, un Worker de Cloudflare).
Como guía, esta podría ser la estructura de tu index.html:
<!DOCTYPE html>
<html lang="es">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<title>FoodCheck</title>
<meta name="description" />
<link rel="preconnect" href="https://fonts.googleapis.com" />
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin />
<link href="https://fonts.googleapis.com/css2?family=Montserrat:wght@400;500;600;700&display=swap"
rel="stylesheet" />
<script src="https://cdn.tailwindcss.com?plugins=forms,typography,aspect-ratio"></script>
<script type="application/json" id="foodcheck-config">
{ "visionEndpoint": "https://TU-WORKER-NAME.tu-cuenta.workers.dev/" }
</script>
<style>
body {
background: linear-gradient(160deg, #fff6f0 0%, #fffdf8 35%, #ffffff 100%);
color: #1f2937;
font-family: "Montserrat", system-ui, -apple-system, BlinkMacSystemFont, "Segoe UI",
sans-serif;
}
<!-- Resto de código -->
</style>
</head>
<body data-rsssl=1 class="bg-gray-50 flex flex-col items-center p-6">
<h1 class="text-2xl font-semibold mb-4">FoodCheck</h1>
<!-- Resto de código -->
</body>
</html>
Qué hay detrás de la foto (el pipeline real)
Cuando el usuario arrastra una foto al frontend de FoodCheck, el proceso real es el que es muestra en el siguiente diagrama:
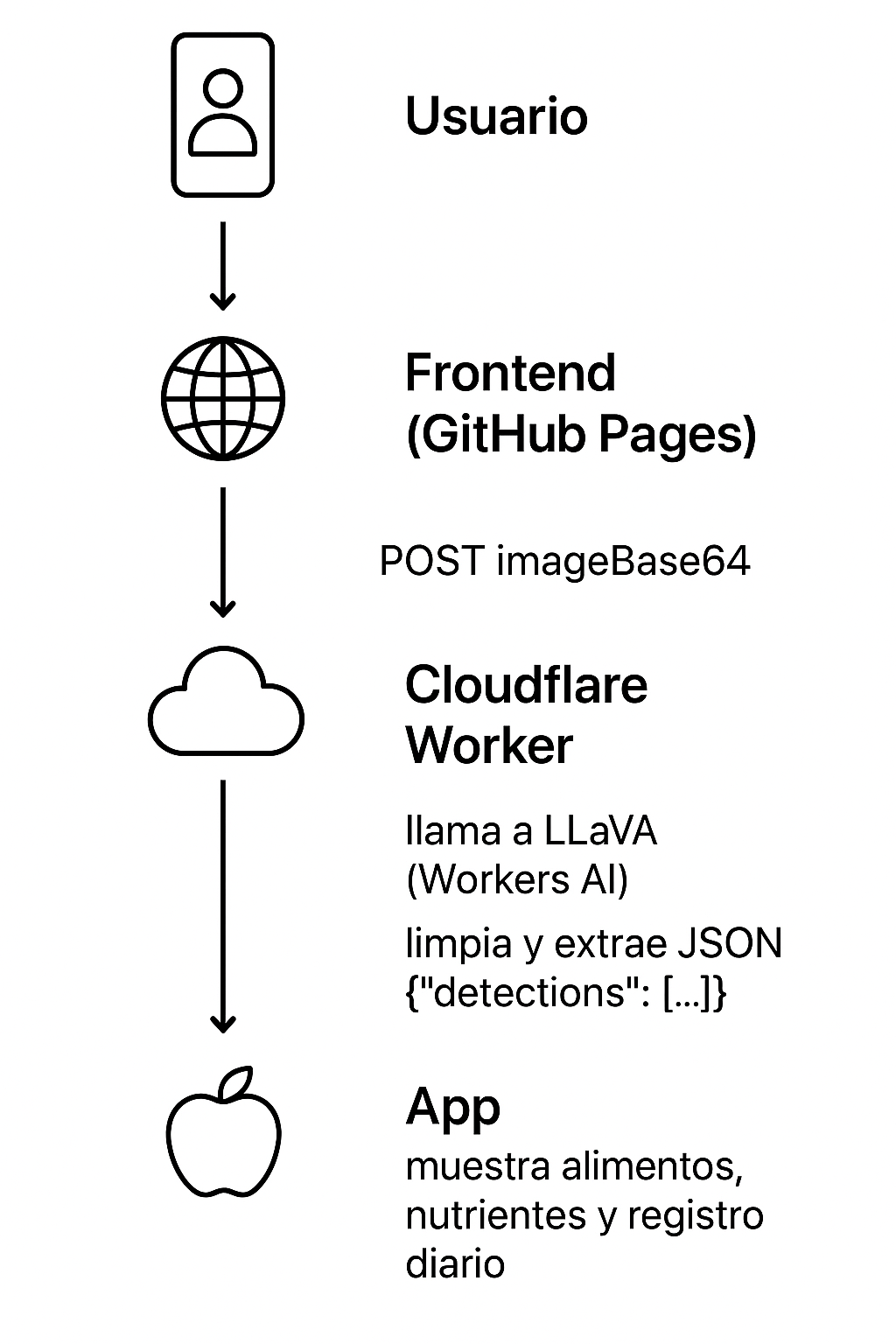
1. Detección del alimento
El frontend obtiene la URL del Worker desde el bloque de configuración JSON que ya incluimos en el <head> del index.html y que hace de puente entre el navegador y el backend en Cloudflare Workers.
Cuando el usuario añade una imagen, la convertimos en Data URL con FileReader.readAsDataURL (formato data:image/…;base64,…):
function processFile(file) {
// Leemos como Data URL para poder mostrar y enviar como texto
const reader = new FileReader();
reader.onload = (e) => {
const src = e.target?.result; // "data:image/...;base64,AAAA..."
if (!src) return;
// Guardamos en estado y mostramos la previsualización
state.image = { src, name: file.name, lastModified: file.lastModified };
loadImagePreview(src); // muestra la imagen en la UI
};
reader.readAsDataURL(file);
}
Enviamos ese string como JSON al Worker mediante POST, junto con un prompt, y el Worker responde con un JSON que incluye las detecciones. Esas detecciones serán un JSON estructurado, ya que el Worker prepara previamente un prompt en español que le indica al modelo cómo responder, por ejemplo:
{
"detections": [
{
"name": "manzana roja",
"confidence": 0.92,
"portion_estimate_grams": 120
}
]
}
Así garantizamos que la respuesta sea estructurada, fácil de interpretar y lista para ser usada por el frontend.
A su vez, la llamada al modelo es directa:
const result = await env.AI.run('@cf/llava-hf/llava-1.5-7b-hf', {
image: Array.from(imageBytes),
prompt: systemInstructions,
max_tokens: 1024
});
Y LLaVA devuelve texto en result.description, de donde hay que extraer el bloque JSON aplicando, por ejemplo:
const cleaned = jsonString.replace(/\\_/g, '_');
const json = JSON.parse(cleaned);
…
return json?.detections ? json : { detections: [] };
El frontend recibe entonces la respuesta limpia con {detections»:[…]}.
2. Estimación de la porción
Antes de usar los resultados, se validan nombres y se normaliza la confianza (0–1). Si el modelo de visión no devuelve una cantidad de porción, se asigna un valor por defecto:
const portionAmount = detection.portionGrams ?? 120;
Además, el usuario puede editar la cantidad y unidad (gramos, ml, pieza, taza) con conversiones predefinidas en el código (por ejemplo, 1 pieza ≈ 80 g, 1 taza ≈ 150 g):
const UNIT_CONVERSIONS = { g: 1, ml: 1, pieza: 80, taza: 150 };
function convertToGrams(amount, unit) {
const factor = UNIT_CONVERSIONS[(unit || "g").toLowerCase()] ?? 1;
return (Number(amount) || 0) * factor;
}
3. De nombres a nutrientes
Cada alimento detectado se consulta en OpenFoodFacts para saber su composición nutricional. Se busca por nombre y nos quedamos únicamente con productos que tienen información completa sobre sus nutrientes. Para evitar problemas de CORS y tener un único punto de control, la app no llama a OpenFoodFacts directamente, sino a nuestro Worker (Cloudflare).
Para llamar al Worker y hacer así las consultas, primero construimos una URL con parámetros de interés (texto que escribe el usuario, número de resultados…). Esta URL la llamamos a través del endpoint configurado en el <head> (id foodcheck-config), reutilizando el mismo dominio del Worker de visión:
async function queryOpenFoodFacts(query, limit = 50, options = {}) {
if (!query || !query.trim()) return [];
const params = new URLSearchParams({
search_terms: query,
search_simple: "1",
json: "1",
page_size: String(limit),
lc: "es",
});
const externalSignal = options.signal;
const controller = externalSignal ? null : new AbortController();
const signal = externalSignal ?? controller.signal;
const timeout = externalSignal ? null : setTimeout(() => controller.abort(), 7000);
try {
const cfg = JSON.parse(document.getElementById("foodcheck-config").textContent);
const endpointBase = cfg.visionEndpoint.replace(/\/$/, "");
const proxyUrl = `${endpointBase}/api/nutrition?${params.toString()}`;
const response = await fetch(proxyUrl, { signal });
if (!response.ok) throw new Error(`El proxy de nutrición falló: ${response.status}`);
const data = await response.json();
if (!Array.isArray(data.products)) return [];
return data.products.filter((product) => product?.nutriments);
} finally {
if (!externalSignal && timeout) clearTimeout(timeout);
}
}
El Worker recibe así los parámetros de búsqueda y hace la petición servidor a servidor a OpenFoodFacts:
async function handleNutritionRequest(request, env) {
const url = new URL(request.url);
const params = url.searchParams;
try {
const offUrl = `https://world.openfoodfacts.org/cgi/search.pl?${params.toString()}`;
// El worker llama a OFF (de servidor a servidor, sin CORS)
const response = await fetch(offUrl, {
headers: {
'User-Agent': 'FoodCheckApp-Proxy/1.0' }
});
const data = await response.json();
// Devolvemos la respuesta de OFF al navegador
return new Response(JSON.stringify(data), {
status: 200,
headers: { ...corsHeaders(), "Content-Type": "application/json" }
});
} catch (err) {
return new Response(JSON.stringify({ error: "Error al contactar OpenFoodFacts", details: err.message }), {
status: 500,
headers: { ...corsHeaders(), "Content-Type": "application/json" }
});
}
}
La respuesta devuelta al navegador es un producto con nutrientes por 100 gramos. La app ajusta los valores nutricionales a la porción estimada previamente calculada siguiendo esta fórmula:
nutriente_por_porción = (nutriente_por_100g * gramos_porción) / 100
3. Visualización y registro local
Los valores obtenidos en el paso anterior se muestran al usuario en un anillo de macronutrientes (kcal y % de energía) y en una tabla de nutrientes. Además, la interfaz muestra también la lista editable de alimentos detectados junto con su cantidad y un mensaje tipo “dietista virtual” con observaciones simples basadas en umbrales fijados:
if (totals.fiber < 12) suggestions.push("Añade verduras, legumbres o fruta para aumentar la fibra.");
if (totals.sodium > 800) suggestions.push("Controla el sodio: limita sal añadida y productos procesados.");
…
El usuario puede guardar cada comida. El registro diario suma automáticamente las comidas y muestra la información nutricional completa, y esto se logra mediante un guardado persistente de datos como el que mostramos aquí:
// Guardado persistente
function persistState() {
localStorage.setItem("foodcheck:preferences", JSON.stringify({ conditions: state.userConditions }));
localStorage.setItem("foodcheck:dailyLog", JSON.stringify(state.dailyLog));
}
// Guardar una comida
function saveCurrentMealToHistory() {
const totals = calculateTotalsFromItems(state.foodItems);
const entry = { timestamp: Date.now(), items: structuredClone(state.foodItems), totals };
const day = state.currentDate; // "YYYY-MM-DD"
const dayEntry = state.dailyLog[day] ?? { items: [], totals: null };
dayEntry.items.push(entry);
dayEntry.totals = dayEntry.items.reduce((acc, it) => sumTotals(acc, it.totals), emptyTotals());
state.dailyLog[day] = dayEntry;
persistState();
}
Desplegando en GitHub Pages y Cloudflare
El despliegue es doble:
- Frontend: repositorio estático en GitHub Pages.
- Worker: publicado en Cloudflare con binding env.AI. La URL generada al desplegar es la que usamos en el bloque de Javascript del HTML.
Problemas reales y cómo los resolví
Al principio, intenté conectar FoodCheck con OpenRouter para usar modelos de visión gratuitos. Sobre el papel sonaba bien, pero en la práctica no detectaba alimentos o devolvía respuestas vacías.
Fui intentando solucionar los principales problemas que surgían:
- El modelo no veía la imagen, así que hice que le llegaran mensajes multimodales (texto e imagen).
- Errores de CORS, por lo que creé un Worker como proxy para gestionarlo.
- JSON mal formado, teniendo que implementar un parseo defensivo en el frontend (limpiar el texto, extraer las llaves {} y reintentar JSON.parse()).
- Imágenes grandes o HEIC, así que las formateé a JPEG y limité su tamaño (ej.: <canvas>.toDataURL(‘image/jpeg’, 0.85)).
A pesar de esos ajustes, el sistema seguía sin funcionar. El motivo probable es que los modelos gratuitos de baja prioridad quedaran en cola o expiraran sin respuesta si la red estaba saturada, especialmente sin cuenta de facturación asociada.
Así que busqué otra alternativa que no implicara pagos ni registro sensible, y la encontré justo en Cloudflare Workers AI. Como ya tenía el proyecto desplegado en Workers, probé el modelo LLaVA de Workers AI y funcionó a la primera.
Y es aquí donde Codex juega un papel importante. Lo utilicé como asistente para generar funciones, depurar errores y ajustar prompts. Fue un gran compañero de aprendizaje por su gran precisión y rapidez. Pero con él también aprendí una lección clave, y es que si no defines tú bien la arquitectura de la aplicación, la IA lo va a hacer por ti y es posible que no acierte.
En mi caso, necesitaba una app 100% estática para GitHub Pages y, aunque le di las condiciones exactas, en algún momento propuso crear un servidor Node o usar variables de entorno (.env), lo cual no es posible ahí.
Ahí comprendí que la clave es decidir primero la arquitectura y mantener los prompts coherentes con esa decisión para así usar la IA dentro de ese marco. Por tanto, mejor utiliza la IA para acelerar el trabajo, no para que decida por ti.
Reflexión final
FoodCheck no pretende sustituir a un dietista, pero demuestra algo importante: con un poco de código y una IA bien usada, podemos crear herramientas útiles, privadas y educativas.
Por tanto, el futuro de la IA aplicada a la salud quizás no esté en los grandes servidores, sino en las manos de los desarrolladores curiosos.