
Latam online. Segunda Edición. 2021
En Ecuador, el uso del celular mientras se conduce un vehículo registró un incremento en los primeros nueve meses del 2021; entre enero y septiembre de 2021 se reportaron 15,393 siniestros de tránsito. De ellos, 3,989 están relacionados con distracciones, ejemplo el uso del celular el cual representa el 26% del total mencionado. Si se compara con igual periodo del 2020 se observa un incremento: 240 siniestros más causados por este tipo de distracciones. (ANT, 2021)
Como se puede apreciar en la Figura 1, solo en Guayaquil, una de las ciudades más importantes del país, registra un total de 1,450 accidentes de tránsito por conducir desatento a las condiciones de tránsito (celular, pantallas de video, comida, maquillaje o cualquier otro elemento distractor) etiquetada como C14; estos tipos de distractores dejaron 1,256 fallecidos en la vía”, siendo una de las primeras causales de esto. El conducir en estado de somnolencia o malas condiciones físicas (C03) solo registra un total de 9 accidentes y 11 fallecidos en el año 2021.
Clasificación de estados y distractores
Existen varios tipos de distracciones al conducir y así lo determina la National Center for Statistics and Analysis (NCSA por sus siglas en inglés) las cuales se clasifican de la siguiente manera: (NHTSA, 2021)
Estado del conductor:
- Atento
- Distraído
- Miró, pero no vio
- Tiene sueño o se quedó dormido
Distracciones relacionadas al conductor:
- Comer o beber
- Persona, objeto o evento externo
- Ajuste de radio, casete o CD
- Otros ocupantes del vehículo
- Objeto en movimiento en el vehículo
Descripción del problema
De acuerdo con los datos estadísticos obtenidos un número importante de personas mueren como resultado de accidentes de tránsitos. De todos ellos, muchos son provocados por lo que se conoce como inatención, cuyos principales factores contribuyentes son tanto la distracción como la somnolencia. Por lo tanto, los conductores con fatiga pueden beneficiarse de un sistema que los alerte al momento de perder la atención.
En base a lo mencionado en líneas anteriores, se plantea el siguiente problema:
¿Cómo evitar que un conductor de vehículo se distraiga o caiga en estado de somnolencia?
Objetivo general
El objetivo fue diseñar una herramienta para entornos vehiculares, la cual, mediante técnicas de Deep Learning detecte tanto la distracción como la somnolencia en los conductores y pueda enviar una alerta sonora directamente al conductor, para que vuelva la atención inmediatamente a la vía y así evitar que ocurra un siniestro de tránsito, además de que se pueda monitorear las alertas mediante una consola de administración, con el fin de controlar al personal que está maniobrando el vehículo.
Estructura de la herramienta
La Figura 2 muestra la estructura de la herramienta, su funcionamiento será de la siguiente manera:
- Cámara web con altavoz implementada en la cabina del conductor de manera frontal directa.
- Servidor Web donde se ejecutará el algoritmo, el cual procesará las imágenes y realizará las detecciones acordes al entrenamiento, sea por distracciones o estado de somnolencia. Luego del procesamiento y la detección, este, enviará una alerta directa al conductor, el tipo de esta alerta será sonora, con el objetivo de que regrese la atención a la vía.
- Panel de administración o control, luego del procesamiento y ejecución del algoritmo, se enviará también una alerta visual o textual al administrador de la herramienta, para que internamente se lleve un control de los actos cometidos por el conductor.
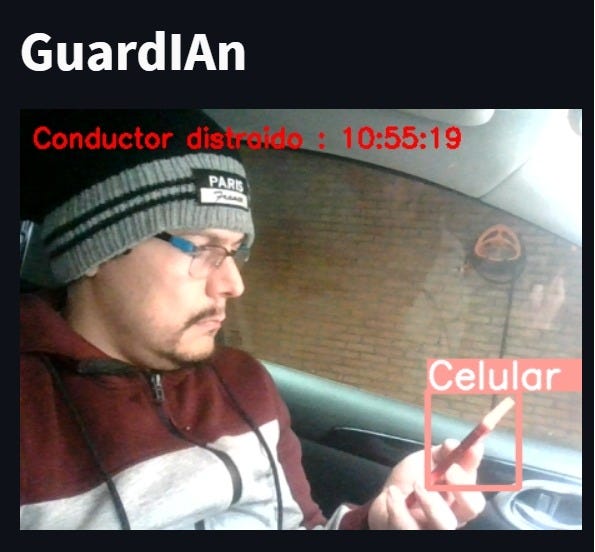
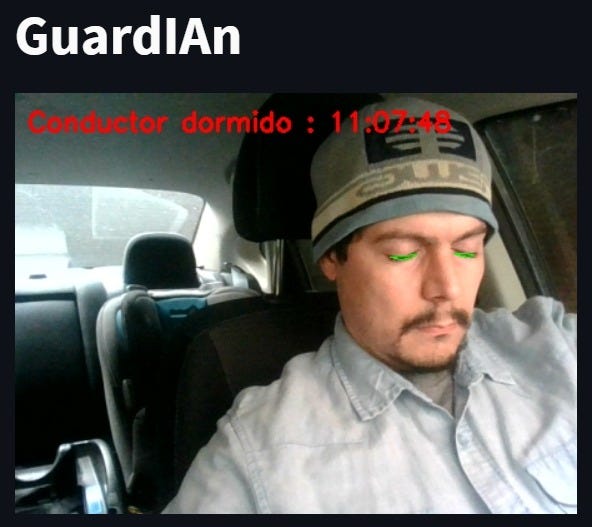
La Figura 3 y 4, muestra la alerta que se mostrará en el panel administrativo de la herramienta en diseño, enviando la imagen del conductor con el objeto distractor o con el estado del conductor.
Técnicas implementadas
A. Detección de inatención
Para detectar las distracciones del conductor necesitamos entrenar un modelo de detección de objetos. La detección de objetos es una tecnología de visión artificial que localiza e identifica objetos en una imagen, debido a su versatilidad, se ha convertido en los últimos años en la tecnología de visión artificial más utilizada.
La tarea de detección de objetos localiza objetos en una imagen y los etiqueta como pertenecientes a una clase objetivo, como se muestra en la imagen a continuación.
Los modelos de detección de objetos logran este objetivo al predecir las coordenadas X1, X2, Y1, Y2 y las etiquetas de clase de objeto.
Para nuestro proyecto utilizamos YOLO V5, YOLO se introdujo inicialmente como el primer modelo de detección de objetos que combinaba la predicción de cuadros delimitadores y la clasificación de objetos en una única red diferenciable de extremo a extremo. Fue escrito y se mantiene en un framework llamado Darknet. YOLO V5 es el primero de los modelos de YOLO escrito en el marco PyTorch y es mucho más liviano y fácil de usar. Dicho esto, YOLO V5 no realizó cambios importantes en la arquitectura de la red en YOLO V4 y no supera a YOLO V4 en un punto de referencia común, el conjunto de datos utilizado fue de COCO dataset.
La Figura 6, nos muestra la arquitectura utilizada de Yolo V5, que está compuesta de la siguiente manera:
Backbone:
Model Backbone actúa como un extractor de características de una imagen de entrada. El extractor de características no es más que el uso de capas convolucionales como kernel, stride, la normalización por lotes se aplica a las imágenes de entrada para extraer características importantes como bordes, formas, etc. CSP (redes parciales de etapa cruzada) se utilizan como columna vertebral en YOLO V5 para extraer características útiles de una imagen de entrada.
Cuello:
En la capa de cuello, la red se diseñó para realizar predicciones de múltiples escalas además de la red de pirámide de características. La predicción multiescalar ayuda a detectar objetos de diferentes tamaños al enviar imágenes a tres valores de cuadrícula diferentes. Entonces, las imágenes de cuadrículas pequeñas detectan objetos grandes y las imágenes de cuadrículas grandes detectan objetos pequeños.
Head:
El modelo Head es el principal responsable del paso final de detección. Utiliza cuadros de anclaje para construir vectores de salida final con probabilidades de clase, puntajes de objetividad y cuadros delimitadores.
B. Detección de sueño y distracción de la visión
Para la detección de los ojos se utilizó la librería Dlib en conjunto con el modelo de referencia de rostros: shape_predictor_68_face_landmarks.dat, el cual utiliza la máscara de detección de puntos (Figura 7) para determinar ubicaciones clave que conforman un rostro.
Utilizando estas herramientas se logró identificar la ubicación de los ojos tomando como referencia desde el punto 36 hasta el 41 para delinear el ojo izquierdo y del 42 al 47 el ojo derecho.
Con esta información se logró determinar si frente a la cámara se encontraba un rostro humano, y en caso afirmativo se utilizó la distancia euclidiana (para determinar la longitud de una línea recta entre dos puntos) y así establecer si los ojos se encuentran abiertos o cerrados.
Posteriormente, si los ojos permanecen cerrados por más de dos segundos entonces se activa una alarma cuya finalidad es despertar al conductor (Figura 3). Por otra parte, si el conductor está viendo en cualquier dirección que no sea el frente, después de cuatro segundos la alarma se activa para alertar respecto a la distracción (Figura 3).
Evaluación del modelo
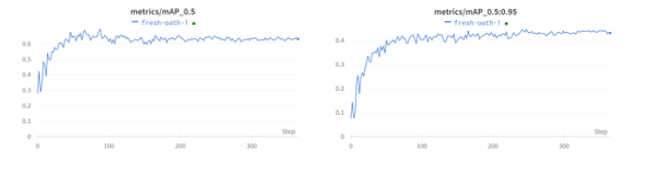
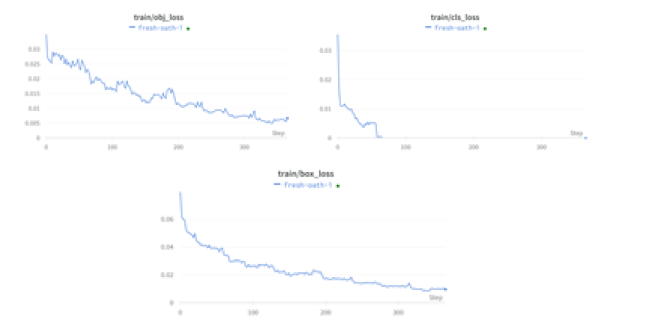
Utilizamos YOLO V5, posterior al entrenamiento, evaluamos las pérdidas de entrenamiento y las métricas de rendimiento en Weights & Biases.
El mAP a 0,5 y el mAP a 0,5:0,95 se trazan para 200 épocas. mAP@[0.5:0.95] significa mAP promedio sobre diferentes umbrales de IoU, de 0.5 a 0.95, paso 0.05 (0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95).
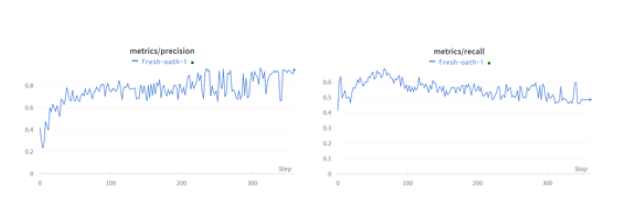
En cuanto a la precisión y la recuperación para 200 épocas se dan a continuación. La precisión fue buena durante las últimas épocas, pero los valores de recuperación fueron más bajos durante las últimas épocas.
Pérdida de entrenamiento y validación:
En detección de objetos, hubo un total de 3 pérdidas para calcular
- Pérdida de caja: que es una pérdida al cuadrado porque detectar las coordenadas de la caja es una tarea de regresión simple
- Pérdida de clase, que es una pérdida de registro porque predice la probabilidad de que un objeto pertenezca a una clase.
- Pérdida de objetos
Generación y preparación del conjunto de datos
Para entrenar nuestro modelo de detección de objetos necesitamos supervisar su aprendizaje con anotaciones de cuadro delimitador. Dibujamos un cuadro alrededor de cada distractor que el detector reconozca: celular, comida, cigarrillo y botellas para identificar cuando el conductor está distraído o realizando alguna actividad ajena a la conducción. Existen muchas herramientas de etiquetado (CVAT , LabelImg , VoTT, Roboflow ) y soluciones a gran escala (Scale, AWS Ground Truth), en nuestro caso utilizamos Roboflow.
Las imágenes para construir nuestro conjunto de datos fueron descargadas de Kaggle y COCO Dataset:
- Dataset containing smoking and not-smoking images (smoker vs non-smoker)
- Mobile Images Dataset
- COCO Dataset
Ventajas de usar guardian
- Innovador, diseñado con Inteligencia Artificial, algoritmo de Deep Learning
- Preciso, algoritmo entrenado con una precisión de 92% de distractores y parpadeos de ojos.
- Accesible, la herramienta se puede implementar en cualquier parte del mundo.
- Adaptable, el algoritmo se puede re-entrenar las veces que haga falta.
- Liviano y fácil de manejar, no necesita de instalación y su uso administración es muy fácil.
- Confiable, herramienta diseñada para la nube, capaz de mantenerse activa 24/7
Conclusión
La inteligencia artificial ha incrementado sus posibilidades, especialmente desde la aparición de tecnologías como las redes neuronales y el aprendizaje automático (machine learning).
Al utilizar Deep Learning, para identificar patrones en fotos o vídeos y llevar a cabo la detección de distractores o estado de somnolencia del conductor, es posible enviarle una alerta sonora que regresaría la atención inmediata y probablemente se evitaría un siniestro de tránsito, reduciendo así la tasa de mortalidad por estas causas.
El proyecto se diseñó como un sistema para entornos vehiculares funcional, capaz de detectar la fatiga y los objetos distractores mientras se conduce un vehículo, además de emitir los dos tipos de alertas (sonora y textual). El modelo logra detectar los distractores correctamente en un 92 %.
El algoritmo podrá seguir entrenando y ampliando los objetos distractores para su detección.
Planes a futuro
El presente proyecto tiene la intención de llevar a las siguientes empresas:
- Empresas de transporte masivo (Terminal terrestre, estación de autobuses)
- Empresas de transporte ejecutivo (Uber, Cabify, Taxi amigo)
Integrantes
- Ing. Carlos Watson (cwatsonm@gmail.com)
- Ing. Josué Huamán (esai.huaman@gmail.com)
- Ing. Yolanda C. Sarmiento (yolitasarmiento@hotmail.com)
- Karyme Rodriguez (karyme.rodriguez@cetys.edu.mx)
- Joanna Araiza (joanna.araiza7829@alumnos.udg.mx)
Presentación del proyecto: DemoDay
Nuestro repositorio en Github
https://github.com/SaturdaysAI/Projects/tree/master/LATAM_remote/GuardIAn
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!








