Redes Neuronales aplicadas a la seguridad vial, proyecto «Focus on Driving» – inteligencia artificial para conducir mejor

Redes Neuronales aplicadas a la seguridad vial, proyecto «Focus on Driving» – inteligencia artificial para conducir mejor
ANÁLISIS DE DEPRESIÓN EN REDES SOCIALES: UNA APLICACIÓN EN BIOESTADÍSTICA

Donostia. Primera edición. 2020
En la vida cotidiana, ¿Cuántas veces nos ocurre que preguntamos a una persona qué tal está, y la respuesta es positiva mientras que su rostro indica lo contrario? ¿Cuántas veces has ido a la peluquería y has pretendido salir contenta cuando realmente, no te gustaba el resultado final? ¿Alguna vez has querido recibir el feedback de miles de personas en una conferencia o en el transcurso de ella?

Si nos ponemos a reflexionar sobre las cuestiones mencionadas, probablemente nos daremos cuenta de que muchas veces se miente cuando se tratan las emociones, ¿pero nuestra cara también miente?
Muchas veces se da más importancia a lo que se dice con la voz, que a lo que se dice con la expresión facial, siendo más fácil mentir o esconder la realidad con la primera de ellas. Con este proyecto queríamos, además de desplegar un proyecto real de inteligencia artificial, hacer algo que pudiese ser útil, pudiese detectar las emociones de las personas según su cara, mediante una imagen o la detección de la cara con una webcam. Las emociones surgen cuando ocurre algo relevante. Aparecen rápidamente, de forma automática, y hacen cambiar nuestro foco de atención.
La inteligencia emocional es algo que ha ido adquiriendo mucha relevancia los últimos años, la importancia en percibir, usar, comprender y manejar las emociones, tanto las correspondientes a uno mismo como a las del resto. Para ello, es evidente que necesitamos emociones reales, por lo que queríamos facilitar la forma en la que se pueden percibir las emociones. ¿Será una máquina capaz de detectar y clasificar las emociones mejor que el ser humano?
Facial Expression Recogniser será una aplicación encargada de detectar las emociones a tiempo real. En esta primera versión se utilizarán las imágenes y, a continuación, su función será clasificar las emociones en cuanto la cámara pueda detectar caras.
El dataset utilizado para el desarrollo de este proyecto, que se obtuvo en Kaggle, consistía en una serie de imágenes divididas en carpetas en función de la expresión de rostro. Las etiquetas de las carpetas se dividían según la siguiente clasificación:
0 — Angry
1 — Disgust
2 — Fear
3 — Happy emotions
4 — Sad
5 — Surprise
6 — Neutral
El objetivo principal del proyecto era detectar y clasificar las emociones según estas etiquetas. Para dicha predicción, se usaría imágenes obtenidas mediante la webcam.

Tal y como ha sido mencionado con anterioridad, a la hora de describir el dataset utilizado, se ha visto que se contaba con imágenes y con las etiquetas de las emociones correspondientes. Esto ha hecho que el proceso de EDA haya restado importancia en este proyecto.
Sin embargo, si ha sido necesario cierto análisis y transformación de los datos. Para empezar, se ha tenido que crear dataframes partiendo del dataset. Para ello, se ha pasado de las fotos que se tenían a pixeles, y se han creado dos columnas en dicha tabla, una la relacionada con la emoción y la otra con los píxeles.

Además, cabe destacar que desde un inicio se contaba con una clasificación del dataset entre train y test, por lo que la transformación de imágenes a pixels se hizo dos veces, terminando así con dos dataframes: train_data y test_data

El proyecto realizado se basa en Deep Learning, por lo que ha sido necesario el uso de redes neuronales. En nuestro caso, se han utilizado redes neuronales convolucionales, las cuales se utilizan sobre todo para tareas de visión artificial, pues son muy efectivas en la clasificación y segmentación de imágenes, entre otras aplicaciones.
Para ello, se ha presentado un modelo secuencial, lo que permite apilar capas secuenciales en orden de entrada a salida.


Las capas añadidas al modelo han sido:
– Conv2D
– Batch Normalization
– MaxPooling2D
– Flatten
– Dense
– Activation
– Dropout
Para crear el modelo anteriormente mencionado, se ha utilizado Tensorflow y Keras. Este último es una biblioteca de Redes Neuronales escrita en Python. Es capaz de ejecutarse sobre TensorFlow. Este último satisface las necesidades de los sistemas capaces de construir y entrenar redes neuronales para detectar y descifrar patrones y correlaciones.
Después de crear el modelo se inició el entrenamiento del modelo. Al principio, se entrenó el modelo con un solo epoch, lo que además de tardar mucho tiempo, solo obtuvo un accuracy del 0,29. Es por esto por lo que se tuvo que modificar el entrenamiento del modelo, aumentando los epochs, cambiando los pasos a dar en cada epoch, etc.
Además, debido a un problema de guardado se tuvo que crear un callback al ModelCheckpoint, para que almacenará un checkpoint cada vez que un epoch finalizara, así, se pudo obtener un modelo final con más epochs.
Al final, el modelo obtenido ha conseguido un accuracy final del 0.9602. Esto indica la precisión de lo que se entrenó. Sin embargo, si analizamos el val_accuracy, el cual se refiere a cuánto funciona su modelo en general para casos fuera del conjunto de entrenamiento, el valor obtenido ha sido del 0.6035.

Sin embargo, si calculamos la precisión del modelo con el dataset utilizado para el testeo, veremos que el accuracy es bastante bajo, del 0,1733, lo que implica tener mucho margen de mejora este modelo.

Una vez tuviésemos el modelo listo, había que predecir y probarlo. Para ello, se codificó de forma que nos indicase aquellas emociones que se podían considerar en la expresión facial de la imagen introducida, y según el porcentaje, concluir con el sentimiento más significativo. Por ejemplo:

Introducimos esta primera imagen, donde es evidente que el chico está mostrando cierto enfado. De esta forma, nuestro modelo lo ha clasificado de la siguiente manera:


Recalcando que el enfado es el sentimiento que predomina en la imagen. Si utilizamos nuestro modelo, con el fin de detectar alguna otra emoción, veremos que también funciona.

Tal y como se mencionara en las conclusiones, la intención era incorporar la detección de caras mediante las webcam y así, poder detectar las emociones de una forma más real.
Una vez finalizado el proyecto, en una reflexión grupal, se comentó lo mucho que se ha aprendido en el desarrollo de este mismo, además de habernos dado cuenta de lo lejos que puede llegar la tecnología, y para ser más precisos la inteligencia artificial.
Hemos visto que en este ámbito de reconocimiento facial se están dando grandes avances, existen modelos que reconocen rostros incluso llevando la mascarilla puesta, y las aplicaciones de esta tecnología sólo están limitadas por nuestra imaginación. Desde el punto de vista de marketing, recoger el feedback de los usuarios y clientes es un proceso muy importante, pero obtener esta información suele costar, casi nadie nos paramos a rellenar un formulario para decir cómo ha sido nuestra experiencia a menos que haya sido negativa.
Es por ello que si somos capaces de detectar puntos rojos en la experiencia de los usuarios sin que suponga para ellos un esfuerzo más se podría mejorar el servicio, y gracias a esta tecnología esto sí es posible.
Los próximos pasos que se darán con este proyecto están directamente relacionados con los problemas que se han tenido en la culminación del proyecto. La primera dificultad sufrida por el equipo fue la correspondiente al despliegue en Amazon Web Services, lo que debía facilitar el entrenamiento, hizo que el proyecto quedase parado dada la inexperiencia de los integrantes del equipo con dicha herramienta. Esto ha hecho que el entrenamiento no se pudiese hacer en los servidores de Amazon, lo que ha tardado mucho tiempo y dificulta cualquier modificación y ejecución en el modelo. Es por esto por lo que, próximamente, se intentará realizar dicho despliegue para poder trabajar de una manera más eficiente y eficaz.
Este problema hizo que la desviación sufrida en el tiempo fuese muy elevada, lo que dificultó la culminación de toda la funcionalidad que previmos en primera instancia. Además, esto también estaba directamente relacionado con el pequeño margen que nos quedaba para entrenar el modelo, lo que implica que la eficacia y precisión del modelo no sea la óptima, y aun quede un margen bastante amplio de mejora. Es por esto por lo que se podría, mediante más entrenamientos, obtener un modelo de mayor calidad.
No considerábamos tener tantos problemas cuando definimos el proyecto que queríamos realizar, debido a la inexperiencia que teníamos en este ámbito. Una de las funcionalidades que planteamos al principio era la incorporación de una Web Cam que nos permitiera sacar fotos al instante y poder clasificar las emociones de dicha imagen, para poder hacerlo más real. Sin embargo, debido a la falta de tiempo, es un aspecto que no se ha podido desarrollar pero que sería lo primero que realizaríamos en el futuro.
Sería muy útil integrar nuestro modelo con webcams en las entradas/salidas de todos aquellos lugares que quieran valorar la satisfacción o experiencia del cliente en dicho lugar. Por ejemplo, restaurantes, tiendas, conferencias, etc.
Además, en el futuro sería genial programar que la aplicación fuese capaz de reconocer una imagen tomada en la salida de un lugar con aquella imagen tomada en la entrada a la misma persona. Eso haría que se pudiese comparar eficientemente los resultados de todos los usuarios, y sería un paso adelante enorme ya que dotaríamos a la empresa/institución que lo utilice de inteligencia empresarial. Si a eso le sumásemos una serie de gráficos que visualicen los resultados en una especie de dashboard, podría ayudar a los directivos a tomar diversas decisiones en base a la satisfacción del cliente.
En el siguiente repositorio se encuentra el código usuado para desarrollar esta aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Donostia/Donostia2020/Facial_Expression_Saturdays
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!

Donostia. Primera Edición. 2020
El fatídico 11 de marzo del 2020, la OMS declaró la pandemia mundial por COVID-19. Más de 300 días después, hemos decidido hacer público y accesible para el mundo entero el trabajo que hemos venido desarrollando durante más de 8 semanas.

Prepárense, gobiernos e instituciones sanitarias del planeta, pues lo que van a ver en este artículo establecerá los cimientos de un nuevo sistema de vigilancia que permitirá asegurar el cumplimiento de una de las medidas que más se ha repetido durante estos fatídicos 300 días: la distancia de seguridad interpersonal de metro y medio.
Nuestro incombustible grupo, formado por 3 “locos” ingenieros (alguno de ellos en proceso) ha trabajado día y noche para traer la mejor solución posible a este problema.
El proyecto, que comenzó bajo el nombre de WATCHDOG (perro guardián) por la misión inicial que teníamos en mente (un robot con autonomía de movimientos que vigilase el cumplimiento de la distancia de seguridad y que ladrase cada vez que esta fuera quebrantada) iba a ofrecer, más allá del obvio beneficio de un constante recordatorio a las personas de la necesidad de cumplir con la medida de la distancia interpersonal, una herramienta para el mapeo y creación de “puntos calientes” en los que la distancia se incumpliese más a menudo.
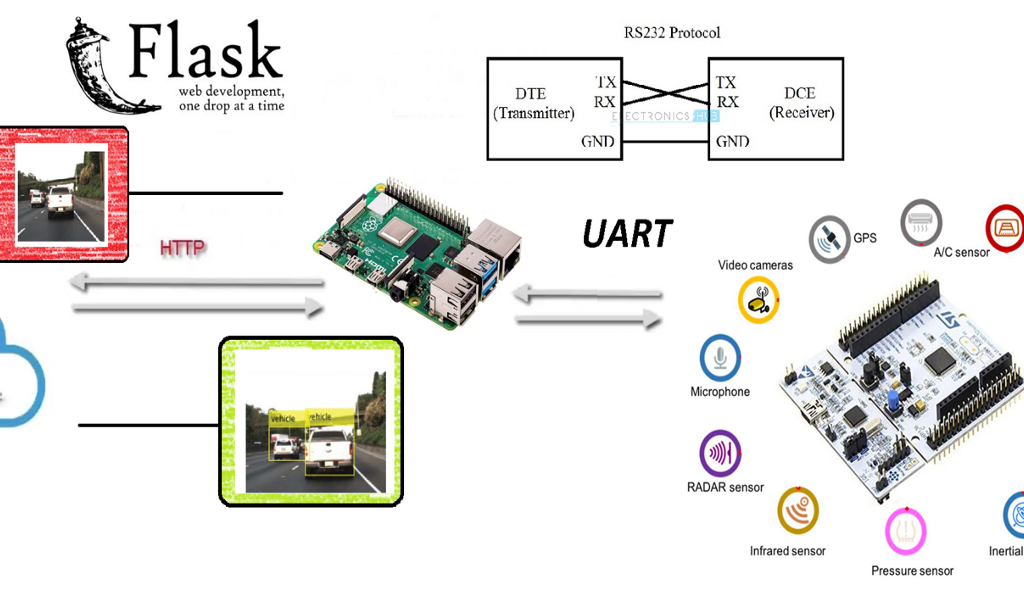
Para todo ello, el equipo ha tratado de crear una convergencia entre los mundos de la electrónica y la Inteligencia Artificial, haciendo uso de los medios más innovadores que tenía a su mano. Con una Raspberry Pi 3, un microcontrolador de bajo nivel equivalente a Arduino Mega, diferentes medios para la comunicación, algoritmos, librerías y redes neuronales convolucionales se ha tratado de alcanzar la solución con la mayor satisfacción posible.
Para el proyecto de Saturdays.AI se ha pensado en desarrollar un proyecto Watchdog (perro guardián) que vigila la distancia mínima recomendada por los protocolos Anti-COVID.
El planteamiento inicial ha sido el de programar un robot capaz de emitir un ladrido cuando la distancia de seguridad (requerido por los protocolos Anti-COVID) fuera quebrantada, enviando los datos adquiridos a un servidor y realizar un mapeo (mapa de calor) en tiempo real.
El objetivo básico del proyecto es converger el mundo OT con el mundo IT, es decir, la convergencia de la electrónica con el de la IA (inteligencia artificial) muy de moda en el mundo IT, utilizando técnicas de Deep Learning, que es una de las ramas del Machine Learning. De hecho, a pesar de que esta primera edición de AI Saturdays Euskadi se haya orientado al Machine Learning en general, hemos decidido profundizar en el Deep Learning por voluntad propia.
Poco a poco se están desarrollando tarjetas electrónicas autónomas que funcionan At The Edge (es decir que la misma tarjeta de control aplica los algoritmos) sin utilizar el Cloud para ello, o sin utilizar una unidad PC más potente para su procesado. Este fenómeno, conocido como Edge Computing, permite aliviar la carga de procesamiento a servidores centrales delegando tareas que puedan ser sencillas pero repetitivas a los nodos externos.
Cuando se detectan 2 personas, manda la posición de la detección y la imagen de violación de la distancia a un servidor Web, creado con Flask.
En lo que al mapeo respecta, la idea inicial era realizar un mapeo SLAM (simultaneous localization and mapping) utilizando un sensor LIDAR o una cámara 3D, pero nos hemos encontrado con limitaciones para hacer un Point Cloud que nos permitiera ejecutar el mapeo. Se describe esta limitación en los Trabajos a Futuro.
El objetivo inicial era plasmar todo el código dentro de una tarjeta Raspberry PI 3 (de aquí en adelante RPi3), pero a pesar de existen librerías para controlar los módulos de entradas y salidas (GPIO), el dispositivo no es lo suficientemente potente para poder procesar todo en tiempo real. Para ello existen módulos dedicados y deterministas que facilitan estas tareas.
Para tratar de cumplir con el objetivo aquí propuesto se ha utilizado un microcontrolador STM32F411RET. Se trata de un microcontrolador de gama baja equivalente a un Arduino Mega, pero con un sistema operativo de tiempo real (Real Time Operating System o RTOS), al ser determinista se tiene el control del timing y tareas, pudiendo tener un mayor control para la adquisición de datos y respuesta de los actuadores.
Se decidió utilizar esta tecnología por la gran cantidad de librerías robustas que existen para controlar los periféricos.
El algoritmo final que se ha usado ha sido por goleada YOLO (para nuestro caso), respecto a otros conocidos como SSD (Single Shot Detection) o la más precisa de todas las tecnologías RESNET.
El reto en este apartado ha sido buscar la tecnología que mejor se adapta al tiempo real y nos basamos en las reglas de oro que dijo uno de los mentores:
1. ¿Qué pasa en el mercado? ¿Cuál es la tendencia del mismo? ¿Qué tipo de arquitectura es más viable con las restricciones presupuestarias y de tiempo que tenéis?
2. Mirad lo que hacen los grandes. ¿Podemos pensar igual a ellos? Es decir, ¿tenemos que plantearnos entrenar redes extremadamente complejas, o tenemos que poner los pies en la tierra y plantear ejemplos más rápidos para construir un Producto Mínimo Viable (MVP)?
3. ¡Adáptate!
En esta fórmula, el resultado de 1+1 en ingeniería sería determinista pero en la vida real el resultado es estocástico, así que depende. ?
Este proyecto está acotado para capacidad computacional de gama media y se ha querido estrujar al máximo desde ese punto de vista. Por ello, el mejor algoritmo que encontramos, el cual estaba puramente escrito en C (siendo un terrible reto el aplicar funciones matemáticas a pelo; aprovechamos para agradecer a Joseph Redmon) es lo más rápido comparado con librerías escritas a mayor alto nivel (TensorFlow, pyTorch).
Como curiosidad, usando la versión para embebidos de SSD se llega a unos 18 Frames por Segundo (FPS) comparado con YOLO, que llega a 24 FPS. Sin haber añadido telecomunicaciones nos dimos cuenta cuál era el camino a seguir, pero se encontraron todo tipo de resoluciones de las distintas tecnologías.
“Cabe destacar que para el equipo, el algoritmo o tecnología más completo y adaptado si se tuviera un poco más de capacidad computacional serían RNN o FAST-RNN, ya que de una tirada no solo tendríamos la posición de los objetos, sino cada pixel de la imagen estaría vinculado a una clase y con esto se podría dotar al proyecto de la capacidad de contextualizarse en el entorno. Y esto nos llevaría a más poder de adaptación, teniendo en particular un efecto positivo para el ámbito del Machine Learning, donde se dispondría de más DATO al que poder darle valor sacado del entorno.”
Si se tiene aún más curiosidad al respecto, os dejamos este link.
Como esto se extendería hasta el infinito, no se van a explicar los detalles del funcionamiento a fondo; se adjunta un link donde se explica detalladamente el algoritmo en su versión v3. La diferencia está en que en la versión v4 aumenta la precisión pero en su versión tiny la velocidad se mantiene constante.
La analogía del “EDA” realizado en nuestro proyecto de Deep Learning tendría que ver, entre otros, con limpieza y preprocesamientos hechos de las imágenes obtenidas. El primer preprocesamiento ejecutado sería el que ofrece la función BLOB de OpenCV que reduce la escala de 8 bits (255 RGB) a escala porcentual unitaria.
Este detalle es muy importante ya que pasa el resultado de cualquier cámara a la que el algoritmo necesita de entrada. ¿Lo malo? Que se vuelen datos de coma flotante y eso requiere más gasto computacional pero de ese problema ya se encargaron sus autores.
El “tuning” de los parámetros en este aspecto que hemos hecho ha sido pasar la imagen de entrada a la escala más pequeña (316 x 316 píxeles).
Habiendo hecho este primer paso, la imagen pasará por múltiples filtros internos cambiando la dimensionalidad de la entrada y readaptando al mejor estilo de Nolan con películas del calibre de Tenet o Inception. ¿El resultado?
El algoritmo YOLOv4 entrega los datos de la imagen en una matriz compuesta de 13x13x (A x ((B+P) + C)), siendo:
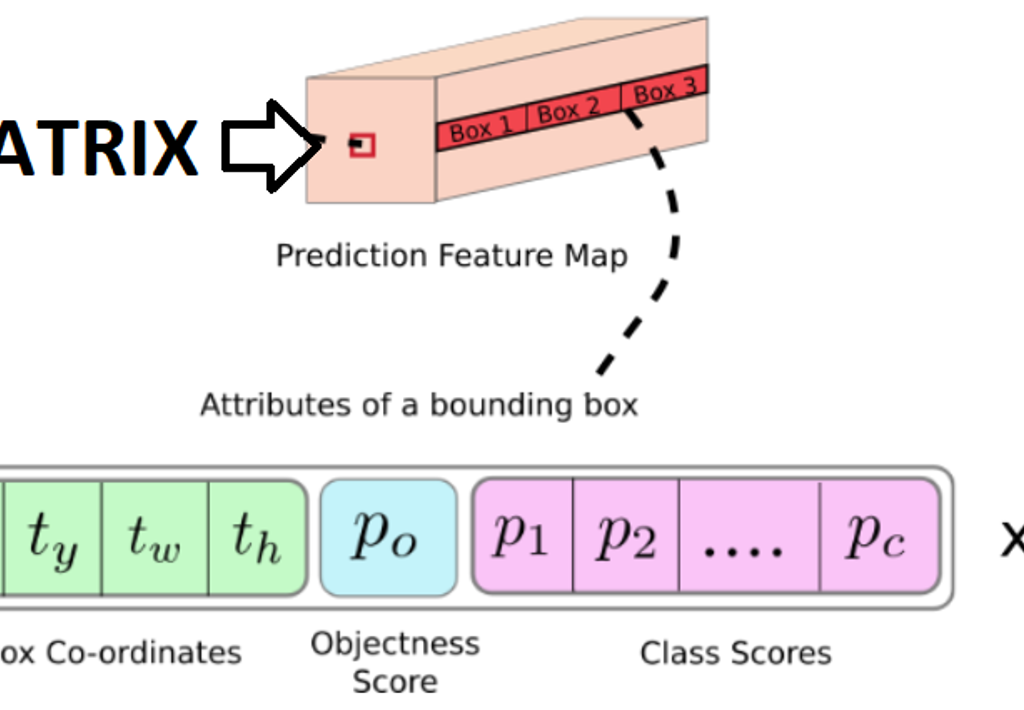
? ¿Y por qué no reentrenar la red aplicando transfer learning?
Mucho ojo, ya que nuestro equipo se peleó para mejorar la respuesta de este algoritmo para aumentar y darle más valor a la matriz de salida de la versión tiny.
Los resultados, por desgracia, no fueron los esperados. El mapa de características que se crea en estos modelos se basa en cantidades muy grandes de datos y de mucha variedad en el tema de la visión, donde son necesarias grandes cantidades (10.000 imágenes) para que el procesamiento pueda ser fluido. Y es cierto, si se reentrenara partiendo de transfer learning nos ahorraríamos muchas imágenes de entrada, pero también hay que tener en cuenta las clases de objetos que se quieran reconocer. Mientras más clases de objetos haya el mapa de características aprende mejor a separar cada clase.
Por ello, se han usado los pesos de la versión COCO para el algoritmo YOLO, ya que era la más similar para nuestro caso.
A continuación, se aplica un segundo filtro, usado para aplicar el BBOX de los distintos anchor boxes para ver cuál es el mejor.
Estos pasos anteriores formarían el proceso EDA como tal. Sin embargo, y en comparación con un proceso de ML, el filtro que se aplicaría dependería del grado de confianza que se tenga de la detección de un objeto, mientras que en un proceso de ML la “manipulación” se suele hacer sobre el mismo dato.
Todo esto se ensambla en una función llamada “Impure Detector” que nos va a devolver los datos que más nos interesan en una lista de Python de la siguiente forma:
La Raspberry 3B+ cuenta con el sistema operativo Raspbian y librerías OpenCV (4.1.0.22).
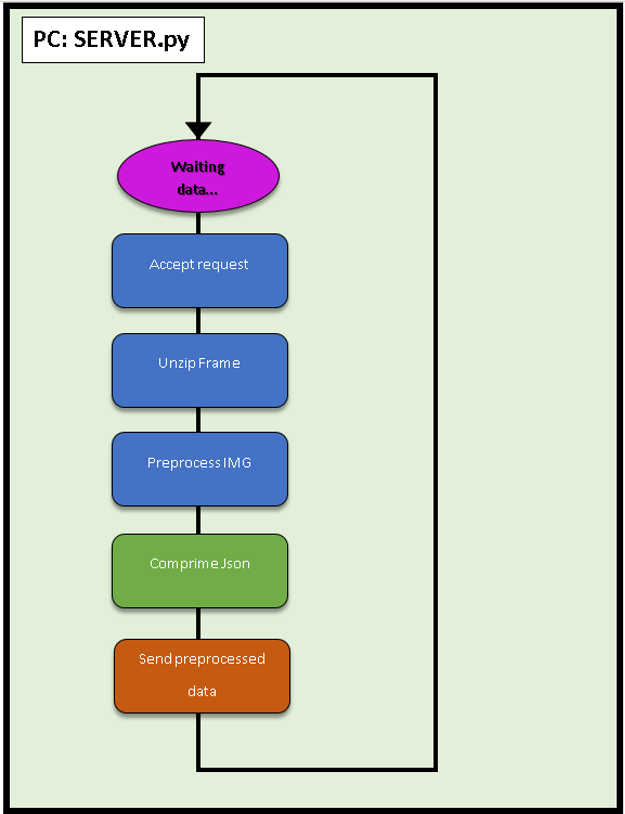
El funcionamiento de manera general es sencillo: Se procesan los datos de la imagen y se reenvían a un servidor Web Flask instalado en un PC.
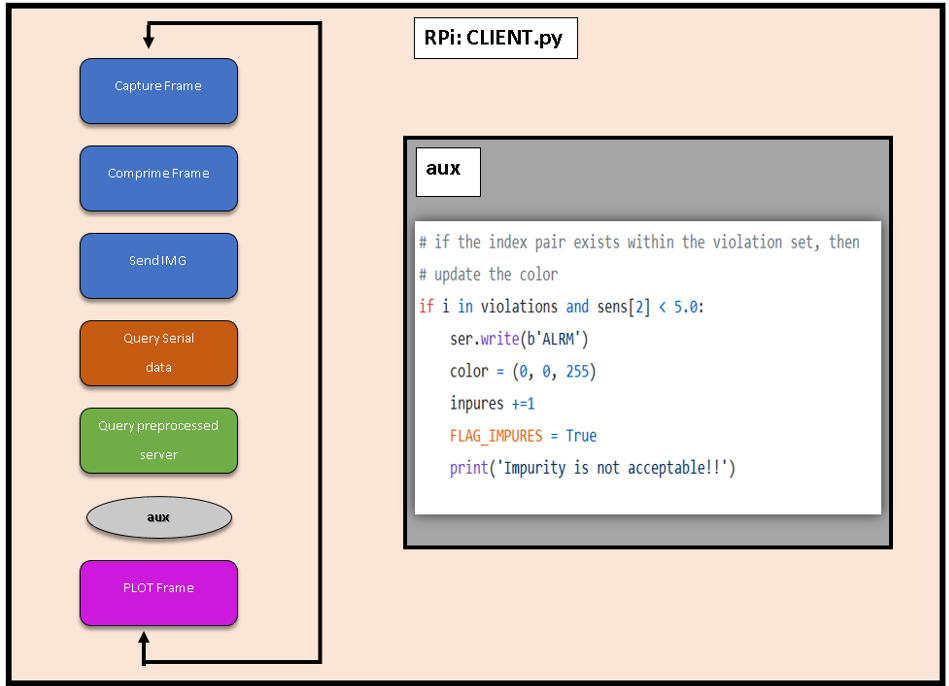
Podemos ver más detalles sobre el código de la RPi en CLIENT.py:
● Comunicación Serie
Tenemos una comunicación serie con el microcontrolador. Después de unas cuantas pruebas nos hemos dado cuenta de que, a la velocidad máxima con la que puede trabajar la RPi con python es con un BaudRate 115200 Bits/s, lo que limita la capacidad de mejorar el tiempo de espera entre Cliente-Servidor. Anotamos este aspecto como Trabajo futuro.
● MQTT
También se ha usado MQTT para enviar los datos respecto a la “violación” de la distancia de seguridad” a otro servidor. Sin embargo, como se ha mencionado antes, no se ha llegado a hacer un mapa de calor con el área de los “delitos de distancia de seguridad” a tiempo real, pero conseguimos enviar los datos e insertarlos en un archivo remoto, guardándolos en un fichero CSV dentro del servidor.
Un trabajo a futuro al que, por desgracia no pudimos llegar, era el de generar un pequeño script para graficar o plotear esos datos.
Las imágenes son bastante problemáticas ya que enviar los paquetes de información tan largos y en la que la que el orden influya es complicado, es necesario indexarlos. Se han probado muchas, pero muchas metodologías distintas y la que mejores resultados ha dado ha sido usando una REST API del servidor.
En Internet se encuentra de todo excepto lo que realmente se quiere, por lo tanto hemos tenido que desarrollar el sistema de envío de imágenes comprimidas por HTTP.
Para ello se han utilizado las funciones de imágenes por excelencia, recogidas en el paquete Open Source OpenCV utilizando un buffer dinámico, evitando la escritura en el disco. Esto se debe ya que por experiencia se ha visto que, a la larga, si no se cuidan, los servidores “envejecen” o “degeneran”. Esto evita por ejemplo forzar los soportes de memoria flash y controlar los ciclos de lectura/escritura aplicados.
Después de emplear OpenCV, nuestro sistema crea la captura en un buffer, lo comprime y se envía al servidor, quien lo descomprime y escribe a disco, dejándolo preparado para su almacenamiento y/o post procesamiento. Este envío se hace en formato JSON ya que se tenían errores al enviarlos en otros formatos.
? ¿Cómo enviar datos que son variables en el tiempo de forma constante?
Normalmente, para que dos personas y/o máquinas se comuniquen tienen que hablar el mismo idioma. En Machine Learning, además, los datos suelen enviarse en bloques constantes de información y de tamaño reducido. En nuestro caso, los pasos que va a ejecutar nuestro cliente son secuenciales y si se tropieza en algún punto todo se va al traste.
Por tanto, se han creado datos “ficticios” para enviarlos como mínimo para que todas las piezas del proyecto puedan funcionar sincronizadamente y en armonía.
Los “impuros” nos van a marcar el index del objeto al que esté pecando pero en los negativos no se va a fijar. Por tanto, esa es la razón por la que el proyecto consigue funcionar sin que se note este pequeño bug.
Se ha elegido este microcontrolador (STM32F411RET) por una opción que un Arduino no ofrecía:
La programación de distintas subtareas para que se ejecuten de manera concurrente además de las interrupciones.
Programar en el STMCubeIde nos da la opción de tener la facilidad de programación de Arduino, así como librerías de entornos más industriales.
A diferencia del Arduino en el que el uso de multitareas metiéndolas en un proceso Round Robin es muy complejo, sumado a la limitación de la cantidad de temporizadores o timers que ofrece Arduino Uno 3, con el STM32F404RE estos problemas para insertarlos en la industria se mitigan.
Por tanto, una vez que el micro haya ejecutado la configuración inicial (tareas, interrupciones, timers…) el programa empezará a ejecutar las tareas aplicando un Round Robin, las cuales se agrupan en el siguiente esquema:
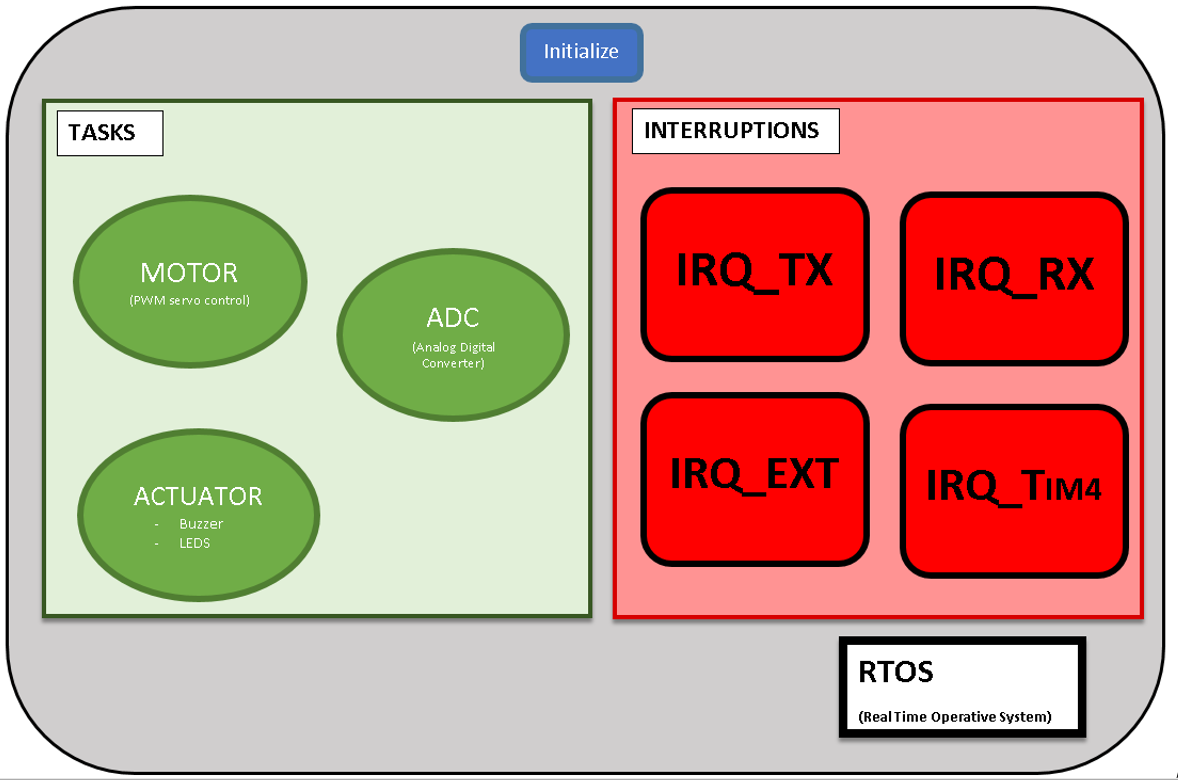
Dentro de las tareas o programas concurrentes existentes existen tres:
1. ADC
Este subprograma se encarga de leer las entradas digitales y procesarlas en 10–12 bits; aspecto que en una lectura por Arduino solo ofrecerá 8 bits de conversión.
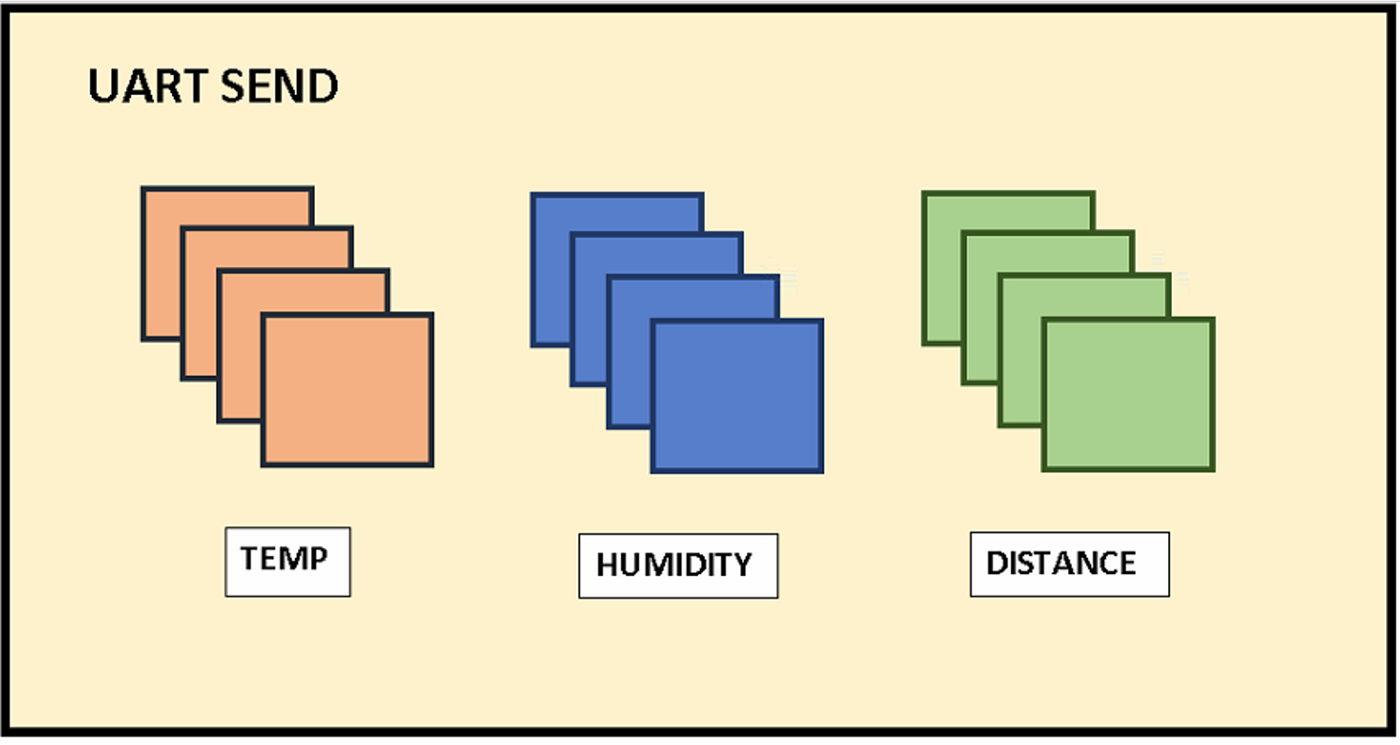
Una vez acabadas una por una en orden secuencial, insertará los datos aplicando sus respectivas conversiones en un vector global int32, siendo el motivo para guardarlos como int y no en float que la cantidad de espacio que ocupan se duplicaría (de 32 a 64 bits, por la coma flotante).
Como se puede apreciar en la imagen del envío del Transmisor-Receptor Asíncrono Universal (UART), se envían 4 datos por cada sensor. El último dato es el que quedaría detrás de la coma flotante para su posterior preprocesamiento sencillo en la RPi.
Ejemplo de esto sería recibir del sensor de distancia un valor de 1004 y transformarlo a 100, 4 en este caso simulando metros de profundidad.
2. ACTUATORS
Dentro de los actuadores podemos encontrar que se conmutarán los estados de las salidas digitales pertenecientes al Buzzer y LED_EXT encargados de dotar al robot de notificar al entorno de manera acústica y visual.
No se ha añadido el actuador del motor porque se cree que separado se entiende mejor a la hora de distribuir el código.
3. MOTOR
Los servomotores trabajan entre 500 y 2500 ticks por lo que nuestra tarea TASK_MOTOR se aprovechará de las interrupciones del timer_4 para cambiar su valor ON/OFF.
Además, se ha añadido un acumulador, de tal manera que si mientras se detecta una violación de la distancia de seguridad y antes de que la función se apague se vuelve a recibir una interrupción por la violación de distancia, aumentará el tiempo de espera 5 segundos más en esa posición. Con esto nos aseguramos de que hay un mayor control de las presencias detectadas.
Las interrupciones son peticiones síncronas o asíncronas al reloj en la que el procesador va a dejar de lado la tarea que esté realizando para centrarse en la interrupción.
Nosotros hemos definido 4 tipos de interrupciones.
1. IRQ_EXT:
Es la interrupción externa por botón a la que se va a acceder en caso de que haya un error tanto de comunicación o de cualquier otro tipo para resetear la configuración del microcontrolador sin que resetee todo. Reenviará la información y nos avisará enviando un “DONE” por el puerto serial.
2. IRQ_TIM4
Se ha configurado el timer_4 del microcontrolador para que se ejecute cada 1 MHz.
En resumen, para que tardemos 50 Hz que es la velocidad del servomotor tenemos que añadir un registro contador de 0–2000 unidades para que entre en la interrupción cada 50 Hz.
Es decir, que en cada 200 ms recibiremos 20000 ticks. O dicho de otra manera, cada 200 milisegundos nuestro micro interrumpirá la interrupción de ese timer.
3. IRQ_TX:
Esta interrupción únicamente va a encender un LED interno del microcontrolador para saber de manera rápida que todo está funcionando correctamente.
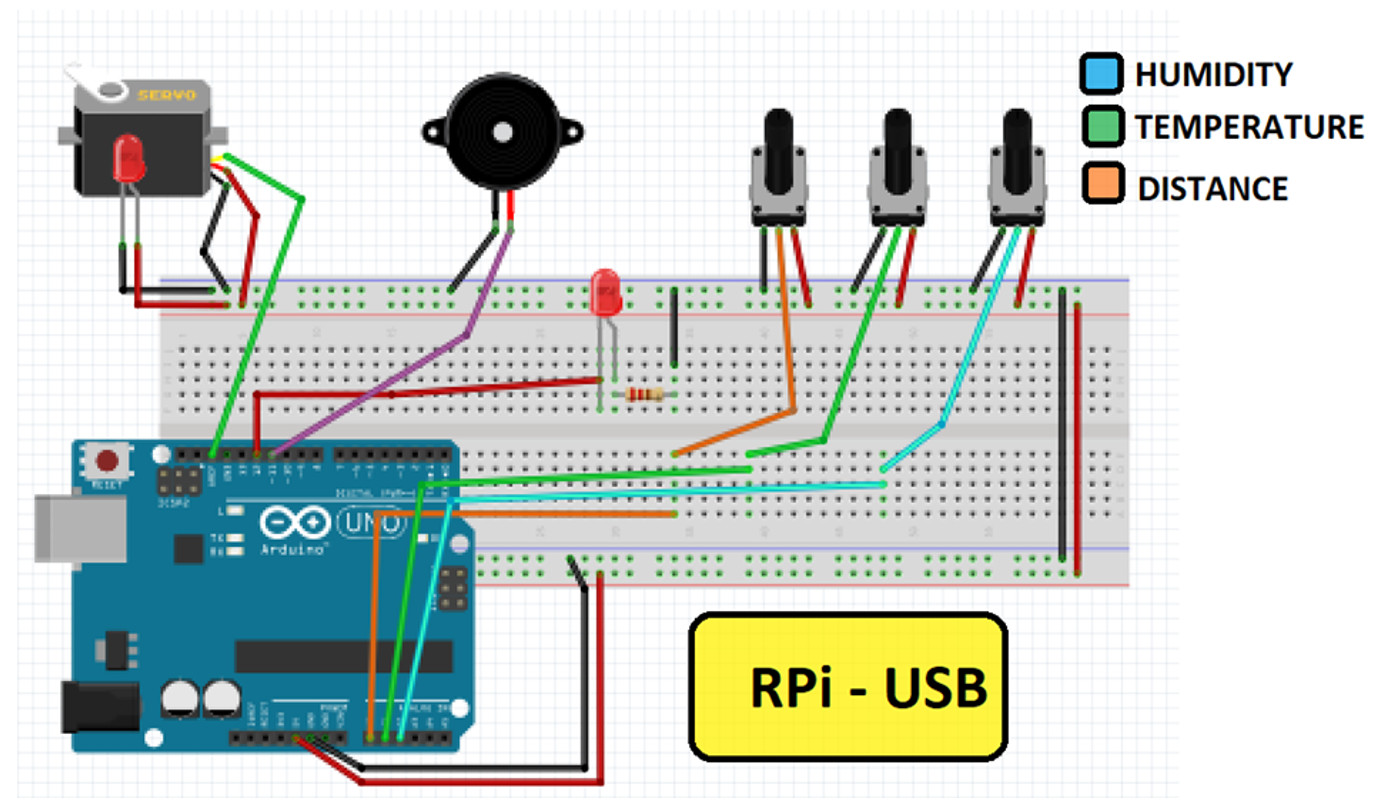
En la figura inferior, además de ver la distribución de los pines se puede ver el pin del LED interno así como el pulsador interno del microcontrolador.
4. IRQ_RX:
A pesar de estar la última en la lista, es la interrupción más importante. Para que la RPi actúe como “cabeza pensante”, es necesaria una interrupción que esté atenta a cualquier señal asíncrona que reciba del microPC y que alerte a la RPi.
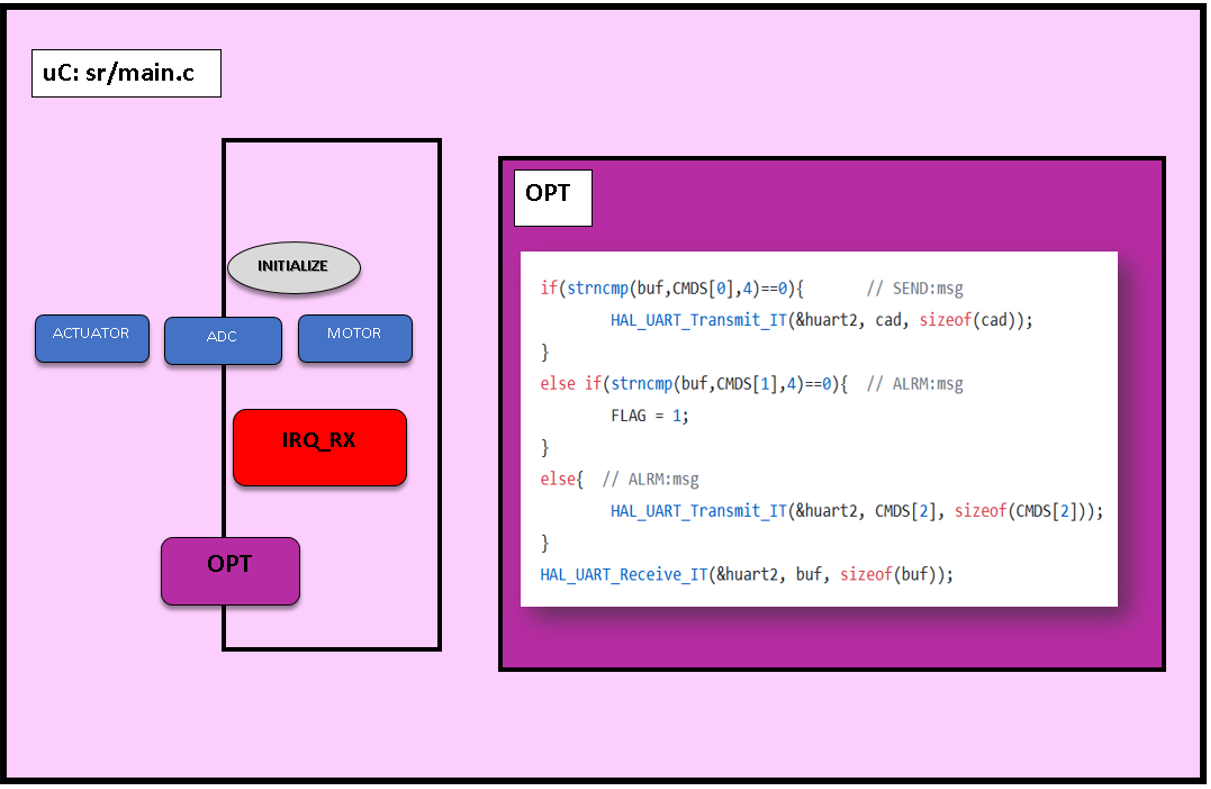
Los comandos que se van a enviar desde la RPi son dos:
Cuando recibamos SEND el microcontrolador enviará los datos que tenga en ese momento en el vector “sens”.
Si recibe ALRM ejecutará los actuadores y si antes de que se acabe vuelve a recibir una entrada ALRM, aumentará el tiempo del mismo.
Se trata de un proyecto aparentemente simple, pero que detrás de todo existe un ecosistema muy complejo al que se le quería meter mano. Solo hay que ver la arquitectura de la infraestructura que ha quedado:
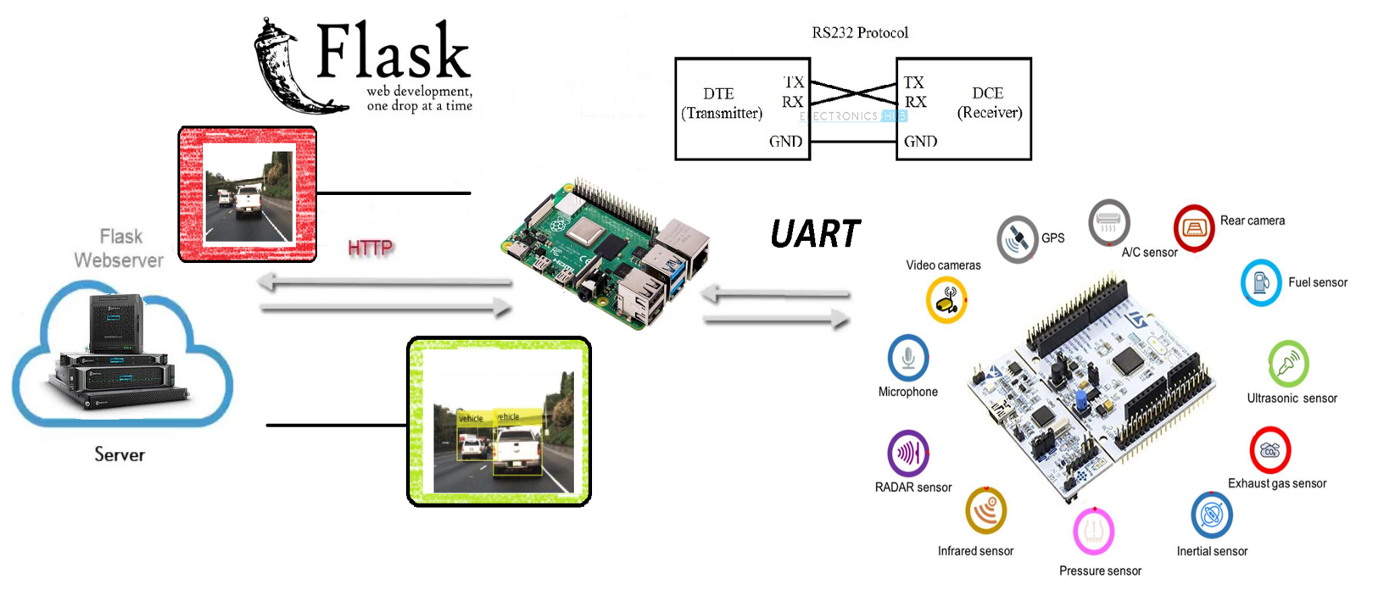
Aunque el objetivo era aplicar temas de Machine Learning, estos temas requieren de una determinada arquitectura y funciones para comunicaciones, tratamiento de imágenes etc. El tema de SLAM + ML se ha quedado a las puertas pero sí se han dado pasos para poder continuar con la misma.
Y a la larga, el objetivo que se había planteado que era aplicar esta tecnología al mundo real aparte de la IT y darle una aplicación más industrial, creemos que aunque no se haya logrado, se está un paso más cerca con el uso de estas “herramientas caseras”.
Como reflexión obtenido, hemos detectado que si se va a empezar a usar el Cloud Computing, para las próximas generaciones hará falta un cifrado de la información muy densa que se envíe (aunque se sacrifique la latencia), ya que es un tema muy serio al que poca importancia se le está dando actualmente.
Hemos detectado diferentes tareas como trabajo futuro de cara a este proyecto:
En el siguiente repositorio se encuentra el código usado para desarrollar esta aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Donostia/Donostia2020/Impure_Detector-main
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Donostia. 2021
Bilbao 2021. Pablo Martín García (pablo) y Omar Calderón (Omar Calderon). Las técnicas de inteligencia artificial aplicadas a empleados cubren una creciente necesidad dado lo costoso en tiempo y dinero que es conseguir buenos colaboradores para las empresas, además de eso la formación que tienen que darles para su buen desempeño dentro de la organización. Por ello, retener estos talentos se ha vuelto un gran reto y a la vez una necesidad, que no esta siendo nada fácil de enfrentar, las personas hoy en día ya no tienden a quedarse donde no están cómodas y no se sientan valoradas.
Las altas rotaciones de empleados se han vuelto normales en muchas empresas. Como ejemplo, en los sectores tecnológico y turístico, 75% de sus empleados a pesar de tener un puesto fijo, están en búsqueda activa de nuevas ofertas. Lo que representa un gran problema en términos de costes, ambiente laboral y eficiencia. Cuando se tiene un entorno laboral así, los otros empleados tienden a hacer lo mismo, ya que eso da sensación de inestabilidad y provoca atrasos en el trabajo.
Actualmente, uno de los problemas más graves a los que se enfrentan las empresas es la fuga de talento. Y, aunque esta migración de talento humano afecta a todas las empresas y todos los sectores, a día de hoy, en nuestro país, los sectores que se ven más perjudicados por este motivo son el tecnológico y el turístico. Según varias encuestas realizadas a lo largo de 2020, más del 75% de los empleados de estos sectores afirma que, a pesar de tener un puesto de trabajo, sigue buscando activamente otras ofertas de empleo, problema que intentaremos abordar con técnicas de inteligencia artificial.(https://interimgrouphr.com/blog/gestion-talento/fuga-talento-causas-soluciones/)
Actualmente en España 9 de cada 10 empleados no se sienten cómodos en su actual puesto de trabajo y esto hace que las organizaciones tengan que replantearse estrategias para mejorar las condiciones de sus colaboradores, pero los criterios para mejorar las mismas no deben ser elegidos por intuición, como se ha hecho toda la vida, lo que ha llevado a estos resultados actuales.
Uno de los motivos por los que las organizaciones pierden a sus empleados es la insatisfacción laboral. Por desgracia y según los datos que maneja Bizneo HR, casi 9 de cada 10 españoles son infelices en su puesto de trabajo. Y, ¿cuáles son las razones de este descontento? Entre otros, la imposibilidad de prosperar en la compañía y la dificultad para conciliar entre vida laboral y familiar. Principalmente.(https://www.bizneo.com/blog/como-evitar-la-fuga-de-talentos-en-tu-empresa/)
IBM HR Analytics Employee Attrition & Performance
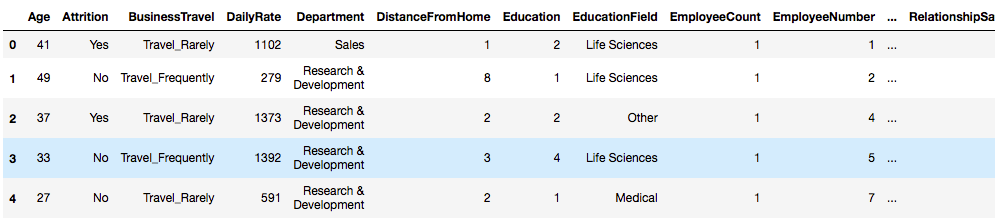
Es un dataset de IBM en el cual recopilaron datos de 1470 de sus empleados ideal para aplicar técnicas de Inteligencia Artificial. En este dataset existen diferentes tipos de columnas, que van desde su edad, salario, satisfacción, etc.
Vistazo a las primeras filas:
Descripción de columnas:
AGE: Valor numérco
ATTRITION: Empleado dejando la empresa (desgaste) (0=no, 1=yes)
BUSINESS TRAVEL: (1=No viaje, 2=Viaja frecuentemente, 3=Viaja ocacionalmente)
DAILY RATE: Valor numérico — Nivel salarial
DEPARTMENT: (1=RRHH, 2=I&D, 3=Ventas)
DISTANCE FROM HOME: Valor numérico — Distancia desde casa
EDUCATION: Valor numérico
EDUCATION FIELD: (1=RRHH, 2=Ciencias, 3=Marketing, 4=Ciencias Médicas, 5=Otros, 6=Técnico)
EMPLOYEE COUNT: Valor numérico
EMPLOYEE NUMBER: Valor numérico — ID del Empleado
ENVIROMENT SATISFACTION: Valor numérico — Satisfacción con el ambiente
GENDER: (1=Femenino, 2=Masculino)
HOURLY RATE: Valor numérico — Salario por hora
JOB INVOLVEMENT: Valor numérico — Involucramiento en el trabajo
JOB LEVEL: Valor numérico — Nivel de trabajo
JOB ROLE: (1=Recepción, 2=RRHH, 3=LAB Técnico, 4=Manager, 5= Director de Gerencia, 6= Director de Investigación, 7= Científico de Investigación, 8=Ejecutivo de Ventas, 9= Representante de Ventas)
JOB SATISFACTION: Valor numérico — Satisfacción con el Trabajo
MARITAL STATUS: (1=Divorciado, 2=Casado, 3=Soltero)
MONTHLY INCOME: Valor numérico — Salario Mensual
MONTHY RATE: Valor numérico — Ratio Mensual
NUMCOMPANIES WORKED: Valor numérico — Número de Empresas Trabajadas
OVER 18: (1=Si, 2=No)
OVERTIME: (1=No, 2=Si)
PERCENT SALARY HIKE: Valor numérico — Porcentaje de Incremento Salarial
PERFORMANCE RATING: Valor numérico — Ratio de Desempeño
RELATIONS SATISFACTION: Valor numérico — Satisfacción de Relaciones
STANDARD HOURS: Valor numérico — Horas Estándar
STOCK OPTIONS LEVEL: Valor numérico — Opciones de Participaciones
TOTAL WORKING YEARS: Valor numérico — Total de Años Trabajados
TRAINING TIMES LAST YEAR: Valor numérico — Horas de Entrenamiento
WORK LIFE BALANCE: Valor numérico — Equilibrio Vida Laboral — Personal
YEARS AT COMPANY: Valor numérico — Total de Años en la Empresa
YEARS IN CURRENT ROLE: Valor numérico — Años en el Puesto Actual
YEARS SINCE LAST PROMOTION: Valor numérico — Última Promoción
YEARS WITH CURRENT MANAGER: Valor numérico — Años con el Gerente Actual
No existen valores nulos en el dataset:

Matriz de correlaciones:
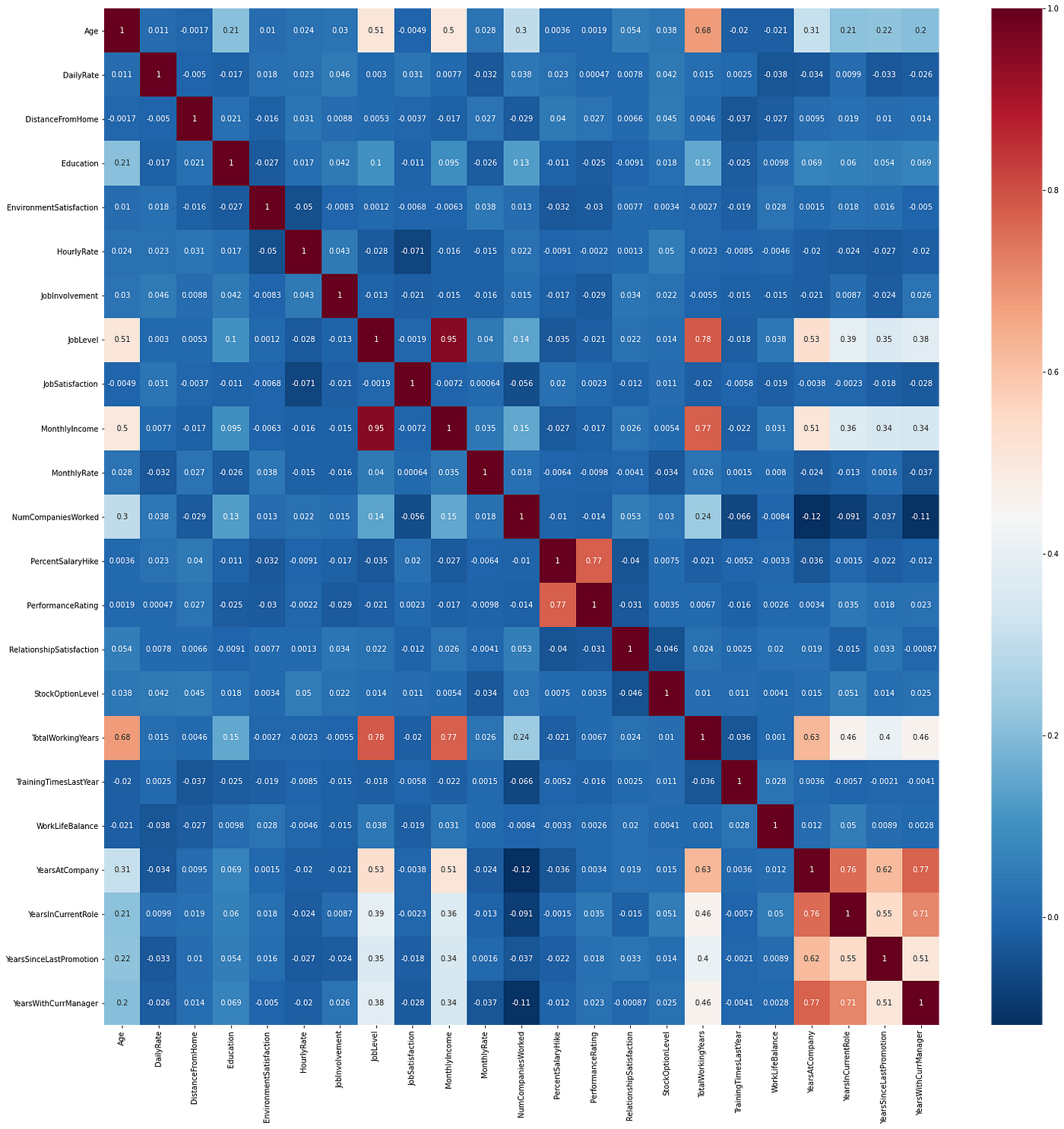
Como podemos ver, dentro de la matriz, las variables que más correlacionas tienen entre sí son las variables relacionadas con tiempo, como la cantidad de años de experiencia, edad, etc. Entre sí y con variables como salario y nivel del puesto de trabajo.
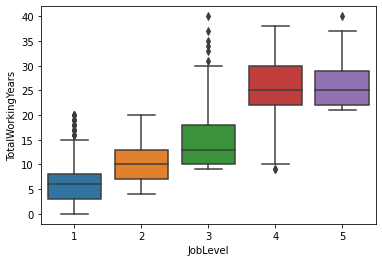
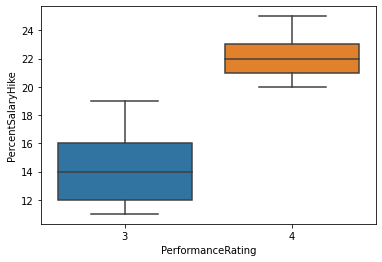
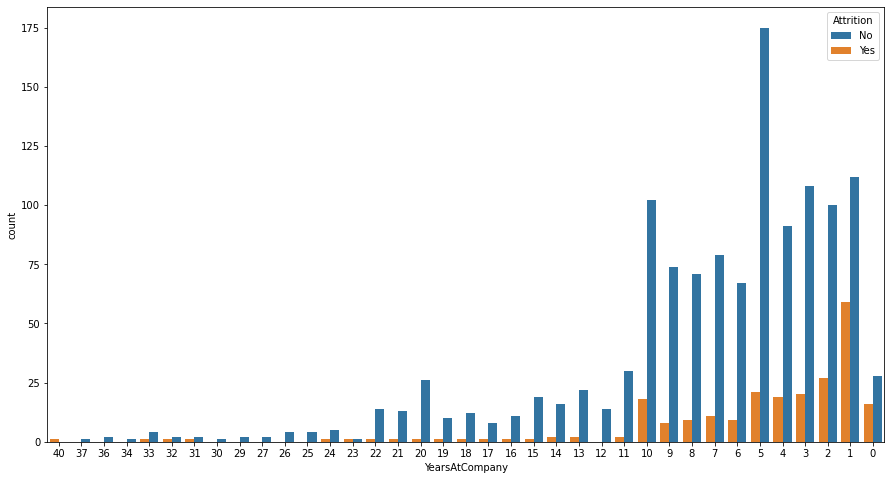
En el siguiente plot podemos observar la evolución del desgaste de los empleados dentro de la organización, viendo desde el que tiene 40 años en la empresa (que es el más antiguo) hasta los que acaban de entrar que tienen 0 años.
Vamos a trabajar profundamente con nuestra variable dependiente que en este caso sería Attrition. Esta variable es binaria, consta con dos valores que son YES y NO. Para lo que queremos hacer nosotros que es medir y predecir el verdadero nivel de desgaste de un empleado no nos sirve, esto debemos transformalo a probabilidades. Sabemos de algunos modelos de clasificación que se ajustan a nuestras necesacidades, pero vamos a hacer la comparación entre ellos a ver cual nos da mejor rendimiento con este tipo de datos.
RandomForestClassifier {0: {'train_time': 0.4280989170074463, 'pred_time': 0.05773425102233887, 'acc_train': 1.0, 'acc_test': 0.9271255060728745, 'f_train': 1.0, 'f_test': 0.923076923076923}}
AdaBoostClassifier {0: {'train_time': 0.36793017387390137, 'pred_time': 0.08242297172546387, 'acc_train': 0.9259634888438134, 'acc_test': 0.9109311740890689, 'f_train': 0.9255102040816326, 'f_test': 0.9083333333333333}}
GaussianNB {0: {'train_time': 0.008366107940673828, 'pred_time': 0.025140047073364258, 'acc_train': 0.8078093306288032, 'acc_test': 0.771255060728745, 'f_train': 0.8265446224256293, 'f_test': 0.7911275415896488}}
Basándonos en el resultado del accuracy_test, vamos a continuar trabajando con Random Forest Classifier, que además de haber tenido mejor rendimiento, consta con las características de Feature Importances y Predict Proba.
Utilizando Feature Importances podemos apreciar cuales son las variables que según el modelo son las que más influyen en su predicción.
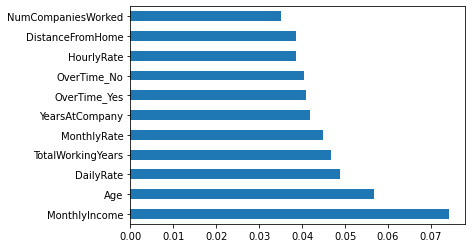
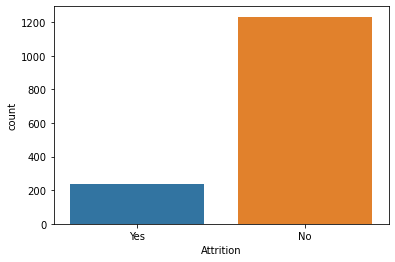
El dataset esta desbalanceado, 16% de los 1470 rows son para personas con desgaste (Attrition), para que el modelo de aún mejor predicciones y no este sesgado, vamos a ampliar el dataset utilizando el método SMOTE.
Shape of X before SMOTE: (1470, 51)
Shape of X after SMOTE: (2466, 51)
Balance of positive and negative classes (%):
No 50.0
Yes 50.0
Después de entrenar el modelo Random Forest Classifier con el dataset ampliado, vamos a ver cuales son sus predicciones en probabilidades para cada columna de nuestro dataset.
0 0.72
1 0.03
2 0.93
3 0.20
4 0.08
...
2461 0.99
2462 1.00
2463 0.99
2464 0.99
2465 0.95
Con la columna de Attrition transformada a probabilidades podemos ver con exactitud el desgaste en cada fila y asi medir con precisión que tanto afecta en el desgaste los cambios y ajustes que la empresa haga en las condiciones de sus empleados.
En esta parte estamos tomando en cuenta las variables en las cuales la empresa puede intervenir directamente, como salario, sobretiempos, etc. Las que son personales no, porque ya requeriría de consentimientos de terceros o gestiones más complejas.
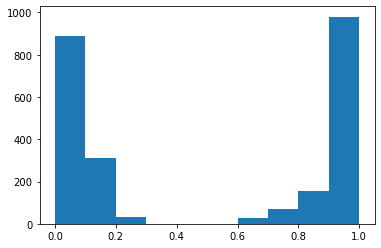
Como primer experimento, hemos decidido medir como cambiaría el nivel de desgaste dentro de la empresa efectuando ajustes salariales de 10, 20, 30, 40, 50, 60, 70, 80 y 90%.
Para compartir los cambios en el nivel de desgaste a medida que se va aumentando el salario, hemos hecho los siguientes histogramas.
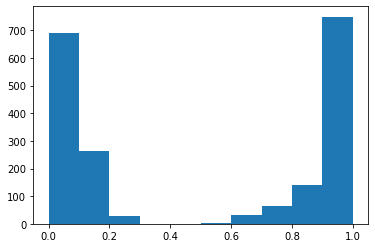
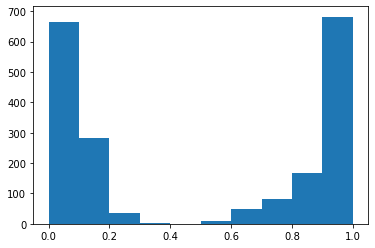
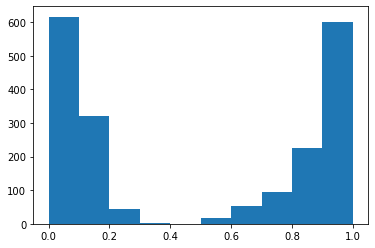
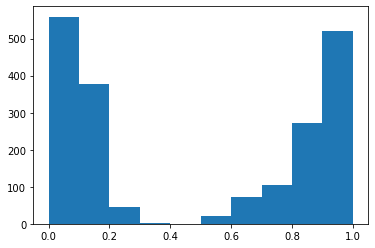
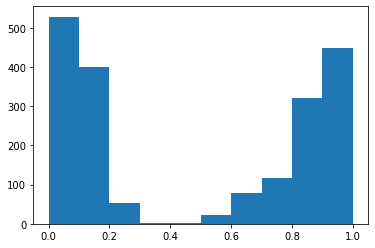
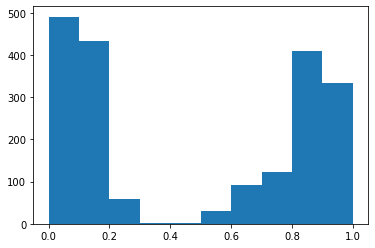
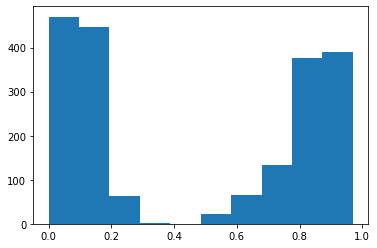
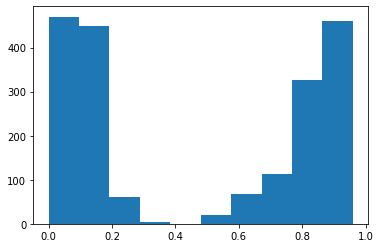
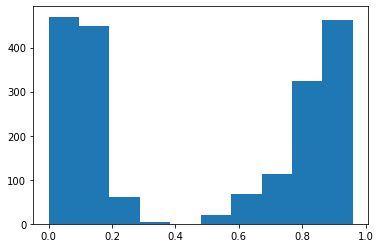
Hemos podido ver que la cantidad de personas sin desgaste aumenta, el punto es que aumenta muy poco para la gran inversión que esta haciendo la empresa, lo que en la práctica no sería factible.
Por eso hemos escogido otra forma de experimentar, en vez de trabajar con todos los empleados, vamos a trabajar de forma individual, con dos casos que tienen desgaste y dependiendo de su condición específica, vamos a realizar los ajustes necesarios.
Como primer candidato hemos tomado un row con Attrition alto y le hemos puesto candidate_1
candidate_1['Attrition']0.76
Hemos realizado unos cambios en algunos valores para ver como cambia su nivel de desgaste, hemos elegido MonthlyIncome y OverTime. En este caso hemos aumentado su salario mensual un 10% y le hemos quitado que tenga que hacer sobretiempos.
candidate_1['MonthlyIncome'] = candidate_1['MonthlyIncome'] * 1.1
2230.8candidate_1[‘OverTime_No’] = 1
candidate_1['OverTime_Yes'] = 0
Cambiando estos valores y pasandolo como input por el Random Forest Classifier, podemos ver la nueva probabilidad de Attrition que nos da.
prob_candidate_1 = clf.predict_proba(candidate_1)[:,1]0.47
Considerablemente ha bajado mucho su nivel de desgaste, haciéndolo ya estar en un nivel sano.
Realizaremos un segundo ejemplo, esta vez con un empleado que no esté haciendo horas extra.
Ejemplo con el candidato 2
candidate_2['Attrition']0.76
Para este segundo ejemplo, hemos elegido MonthlyIncome y StockOptionLevel. En este caso hemos aumentado su salario mensual un 10% y le hemos dado una opción de participación de nivel 2 dentro de la empresa, para que se sienta partícipe.
candidate_2['MonthlyIncome'] = candidate_2['MonthlyIncome'] * 1.1
3256.00candidate_2['StockOptionLevel'] = 2
Cambiando estos valores y pasandolo como input por el Random Forest Classifier, podemos ver la nueva probabilidad de Attrition que nos da.
prob_candidate_2 = clf.predict_proba(candidate_2)[:,1]0.49
También ha dejado de estar en la zona de desgaste con estos ajustes que están dentro de las manos de la empresa.
Trabajando este caso nos hemos dado cuenta que solamente predecir Si y No en el desgaste no es suficiente, ya que no se estaría midiendo que tan desgastada está una persona, ni las cosas que podrían cambiar su estado y en que medida.
Por eso hemos elegido abordar el proyecto de una forma más proactiva y que pueda ayudar a cambiar la situación de las personas antes de que sea tarde y también ayudar a tomar estas decisiones de forma informada.
Con esta forma de abordar el proyecto hemos validado nuestra hipótesis de que es si es posible combatir el desgaste y reducir la fuga de talento si se aplican los cambios necesarios y que estos mismos están dentro de las manos de la empresa. Dentro de lo que hemos podido ver en los resultados, el salario cambia un poco el nivel de desgaste, pero no es definitivo, hay que analizar la situación de cada colaborador de forma individual.
Los siguientes pasos serían medir de forma más eficiente cuales variables afectan en medida exacta a los empleados y volver a aplicar Inteligencia Artificial para obtener una predicción más precisa.
Aquí en repositorio del proyecto.
Gracias.Saturdays.AI
En el siguiente repositorio se encuentra el código usado para desarrollar esa aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Donostia/Donostia2021/HUMANDS-master
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Tradition, from latin tradere, to transmit, is the act of sharing a behavior or belief from generation to generation. And as such, this heritage becomes part of our ourselves, our identity.
Innovation, in contrast, is the introduction of new ideas, of new ways or approaches that change how things were done before. This new approaches are often seen as a threat to tradition, as the adoption of new methods or behaviors tends to change the way that things were done, the tradition.
However, do things always need to be this way? Can innovation be used to leverage and spread tradition among society?
Donostia. 2021
Among the various treasures basque culture has manged to keep alive are bertsoak, improvised verses with rhyme that are sung following a doinu, a melody, that has to match with certain neurri, or verse length.
This bertsos are typically sung in front of an audience, and, the bertsolaris, the basque rhyme singers, sing about different topics which are provided by the moderator, gaijartzaile, while they interact with the rest of bertsolaris (in a rather acid way) in pursue of the public’s applause.
How does this look like? Well lets take a look of how a modern bertso saio looks like lets take a look to the following video.

Did you notice that the base used by both of the bertsolari is the same? This base is called doinu(a). Doinus are transmitted from generation to generation, and it is very important for bertsolaris to know them well, because they need to use the doinu suggested by the gaijartzaile (moderator) or the other bertsolaris to sing their bertsoz.
Bertsos are like rap, and rap battles happen on the fly, there is no script to follow. This means the abbility of the bertsolari to improvise becomes the cornerstone of the bertso. However, the base, the doinu, is already known by everyone, it is something fixed, rigid.
Which is a pity, isn’t it? If improvisation is part of the great art of the bertsolari… Why not provide an improvised doinu so that the bertso experience becomes even more challenging and unique?
With these thoughts in mind, and with the newly adquiered Deep Learning skillset, @jperezvisaires and @klopetx had an instant match in our mind. If there was anything that could create doinus by itself… that would be a Generative Adversarial Network.
Could bertsolarism be revolutionized with the use of AI?
Well… maybe not that much, but it was worth a try.
With the insightful courses we had during our SaturdayAI lessons, we learned about the latest innovations on the field of Deep Learning, such as the different architectures, (convolutional, recurrent, autoencoder…) as well as the different uses such as reinforcement learning and generative adversarial networks. The question at this point was, could the magic of generative adversarial networks be used to create new doinus? If so, what did we need for that purpose?
Data! Of course.
Fortunately for us (and for the basque culture) there exists an entity, Bertsozale Elkartea, who has a webpage that includes all the known doinus, around 3000, with their meta-data included. It is in basque, but just in case you wanted to give it a look.
And well… you know what they say right?
It’s easier to ask for forgiveness than to get permission…
So… We scrapped the web (thank you bertsozale for your work, and sorry for overloading your servers and getting your data wihout formally asking permission).
First we downloaded the metadata of the doinus. We made a selection of the most used ones considering the number of syllables and type, and we donwloaded the ‘Zortziko/Txiki’ ones that had 7 syllables in the first berse followed by 6 in the second which decreased the list of doinus to around 200.
«But wait a minute, donwload what exactly?»
Fortunately for us, we had the chance to download the doinus in either mp3 or midi formats.
«Midi? What’s that? I know about mp3 but midi reminds me of how french people names the mid day…»
MIDI (Musical Instrument Digital Interface) is a technological standard used to transfer up to 16 information channels. It transfers messages of events that include musical notation, tone and speed among other things. Basically, this files explain what notes are played, when, for how long and how loud.

Example of a midi.
Once the data was ready, we just needed to feed the GAN.
And our experience of using midi directly for the GAN is perfectly summarized by the following poem:
We used the midi as input
Well, at least we tried
we faced some problems
and hence, gave up.
You know, everyone uses Deep Learning with images, why should we do otherwise?
So, instead of using midis directly, we created images with them, cause, due to the nature of the midi files, it is quite simple to visualize/represent them as images.
Once at the more comfortable image domain it was easier to work with the problem, as there is much more content dealing with images and convolutional neural networks.
Let’s take a breath for a second. We started talking about how well GANs are supposed to work in the creation of new unheared soinus, but what are GANs exactly?
GANs were introduced by Goodfellow et. al. and are essentially two separate models that are trained together with an opposed purpose. One of the models, the generator, generates new data samples from a random seed; the second model, the discriminator, tries to tell whether the data is original (real) or if it was created by the generative model (fake). Due to their behavior, they are typicall compared to a counterfeiter and a cop. The counterfeiter keeps improving the quality of the works while the cop gets better at detecting which ones are real or faked.
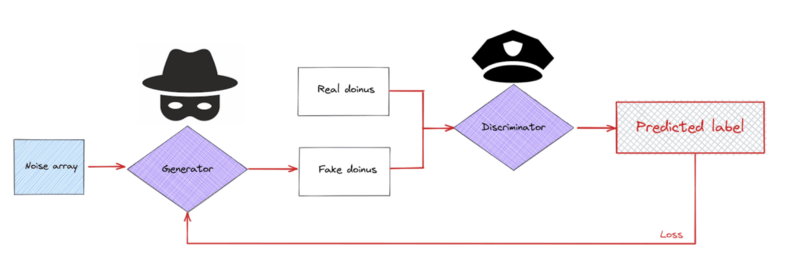
The structure of a GAN fed with doinus.
Basically, during the training process, the counterfeiter should get much better at creating new data (in this case images of new possible doinus) while the cop should improve at the detection of fake doinus, forcing the improvement of the counterfeiter. At some point, the generative model should be good enough at creating doinus that it would become absolutely impossible for the discriminative model to discern among real or fake doinus, meaning we have a model capable of creating good enough doinus.
MiliaGAN, the generator part of the GAN.
Easy peasy lemon squeezy isn’t it?
SPOILER: Nothing went as expected.
We started to feed our monster (well, monsters actually).
We waited until the training converged.
And we freaked out with the resulting doinus.

Yep, this is not a mistakenly black image, its a “shy” midi with no notes.
Yes, an empty midi. Apparently our GAN was so smart that it preferred to remain silent instead of saying something worse than silence… It went full Simon & Garfunkel and published its own version of the Sound of Silence.
Why?
The images we were trying to create were really sparse, with lots of zeroes and only some ones on the notes being played. The generator initially learnt that by switching all the pixels off, it could trick the dumb discriminator at the beginning. However, during training, at some point, even the dumbest of discriminators was able to detect that a blank image was not a real doinu, which meant that all the efforts made by the generator to produce blank images from noise were now worthless. The generator was not able to adapt fast enough to trick the new discriminator and the training diverged.
To solve the problem of sparse images, we took the argmax of all the columns, esentially turning a 128×1024 image into a a 1×1024 vector. This was possible because the doinus only play one note at a time.
Lesson: Ensure you synthesize your data as much as possible, make life easy for your neural network.
Initially, we wanted the generator to focus on creating one type of doinu only; the most popular doinu: zortziko txikia. We only had about 180 usable samples of this kind of doinu, and it soon became apparent that training GANs requires a substantial amount of data just to get barely passable results. So instead of focusing on a small fraction of the doinus, we decided to take all the database in the end. This meant jumbling all kind of different doinus together, but got us a dataset of around 2700 samples; still really small for GAN training, but worth a shot.
Yeap, the whole database with the different neurris, rhymes etc.
Everything.
Goes.
In.
In addition, we reduced the resolution of the images so that they were less sparse, in order to avoid the problem of the shy gan.
And we reduced the midi resolution even more. We needed to simplify if we wanted to make some kind of progress.
And, surprisingly, the magic happened.
So, what have we learned after the creation of our little monster, the MiliaGAN?
The MiliaGAN project has been a great chance to learn DeepLearning techniques, and Generative Adversarial Networks in particular. It has only been possible thanks to the help from the AI Saturdays crew, who have created an ideal environment to learn about AI, boost the creation of a great community and the development of new projects and ideas. And, of course, to the rest of Fellows, that have helped and shared their thoughts. We are very grateful to all of you for making MiliaGAN possible. Thank you for creating this great community!
On the personal side, this project has been both challenging and a great source of fun. It combines two key aspects of our identity, our culture and our geekness. It is, additionally, the first time that Jon and Kerman join forces in a crazy technological project (not first time for crazy projects, but this is not the place for this discussion).
Will MiliaGAN revolutionize the world of bertsolarism? We frankly doubt it, but hey, if someone ever asks, we had fun and we learned.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) a la vez que se realizan proyectos de impacto social (#ai4good). Si quieres aprender más sobre este proyecto (y otros) únete a nuestra comunidad en o aprende a crear los tuyos en nuestro programa AI Saturdays.
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!

Donostia. 2021
¿Cómo calificarías la experiencia de aprendizaje que viviste/estás viviendo en la universidad? ¿Sabrías decir qué es lo que hace que estás más satisfecho/a con un profesor?
Cuando hablamos de experiencias, es complicado poner nombres y apellidos a nuestras sensaciones. Además, estas sensaciones de una persona pueden ser muy diferentes a las de otra, y no es fácil encontrar patrones comunes. Sin embargo, todos/as somos capaces de recordar con cariño a algún/a profesor/a de nuestra etapa preuniversitaria, una persona que nos transmitió algo diferente al resto.
¿No sería ideal tener claro qué es lo que hace que ese profesor/a nos haya generado una experiencia positiva? ¿No sería útil que ese/a profesor/a (y el equipo de coordinación) tuviera esto en cuenta como un factor crítico para medir su desempeño?
Y, seamos claros. Además de la experiencia, valoramos mucho el resultado final del proceso. La motivación extrínseca de la evaluación final es un factor muy relevante, por lo que, ¿no sería importante conocer qué es lo que hace que un/a profesor/a mejore los resultados académicos de un grupo? De esta forma, no solo tener un grupo contento, sino un grupo que ofrece su mayor potencial. Y, estando la universidad tan cerca del mercado laboral, esto es si cabe más importante que en otras etapas formativas.
Cuando empezamos a pensar sobre estas preguntas, creíamos que ya estarían respondidas la mayoría de ellas. Pero, al parecer la medición de la experiencia universitaria no es un tema de debate nacional. Y los ranking están casi más dedicados a lo bien clasificados que están los MBAs que a la satisfacción del alumnado.
Así que desde Saturdays.AI Bilbao un equipo formado por dos estudiantes universitarios (Gorka Legarreta Ibarra y Rubén García Pedrejón) y un servidor, profesor universitario, (Iñaki Fernández López-Zuazo) nos pusimos manos a la obra. Los 3, por motivos obvios, tenemos interés en hacer que la experiencia y los resultados académicos sean los mejores posibles. Y, desde una visión muy personal como profesor, si algo me irrita es que todo el mundo crea que tenga la razón sobre cuál es la mejor forma de enseñar/educar. Así que, citando a Deming “para no ser una persona más con una opinión” vamos a trabajar para llegar a conclusiones basadas en datos.
Ninguno de los 3 teníamos experiencia en programación, pero a fuerza de practicar, practicar, y practicar (y un poquito de controlC+controlV, todo hay que decirlo) hemos llegado a alguna conclusión interesante.
Si eres estudiante, ¿preparado/a para saber qué es lo que tienes pedir a tu universidad para tener la mejor experiencia y notas posibles?
Si eres profesor/a universitario/a ¿preparado/a para conocer los elementos en los que más tienes que enfocarte para mejorar tu desempeño profesional?
Sin datos no hay paraíso, y ha sido complicado hacerse con una buena base de datos, que contuviera información suficiente para llegar a conclusiones de interés. Una universidad ha cedido amablemente un dataset, anonimizando cualquier atributo de caracterización, e introduciendo multiplicadores a algunos atributos para evitar su identificación. Estos cambios no han afectado en ningún caso al resultado del proyecto, pues ambos dataset (el original y el modificado) arrojan las mismas conclusiones. Por último, aunque en este análisis se han utilizado los comentarios aportados por los alumnos/as en el dataset, se han borrado posteriormente, pues contenían información que hacía fácil identificar a profesores/as y situaciones concretas.
Este dataset contiene información sobre más de 20.000 encuestas de satisfacción realizadas al alumnado desde febrero 2015 a diciembre 2020. Se ha completado la información de la encuesta con datos identificativos del profesor/a que impartía la asignatura y de la nota media del grupo.
Entrando al detalle, la información que más se trabajará a lo largo del dataset es:
Respuestas a las preguntas concretas de satisfacción: Se evalúa el conocimiento del/a profesor/a, su manera de explicar, la metodología que utiliza en el aula y el feed-back que da. Por último, se le da una nota general.
Nota media: Se ha realizado una media de todo el grupo que responde a la encuesta. Es decir, un registro no contiene la nota que ha sacado el alumno/a en la evaluación, sino la nota media de todo el grupo al que pertenece
Datos identificativos del profesor/a y su asignatura: Sexo, edad, campus donde trabaja habitualmente, tipo de asignatura que imparte…
En las primeras sesiones de Saturdays.AI siempre se menciona la importancia de la limpieza de datos, y que es una tarea que lleva más del 80% del tiempo de casi cualquier proyecto. Sinceramente, parecía una exageración, pero quizás hemos llegado al 90% 🙂
Para no liarnos demasiado en este punto, estas han sido las mayores transformaciones:
Con el dataset preparadito para trabajar en él, empezamos con un Heatmap para conocer la correlación entre todas las variables:
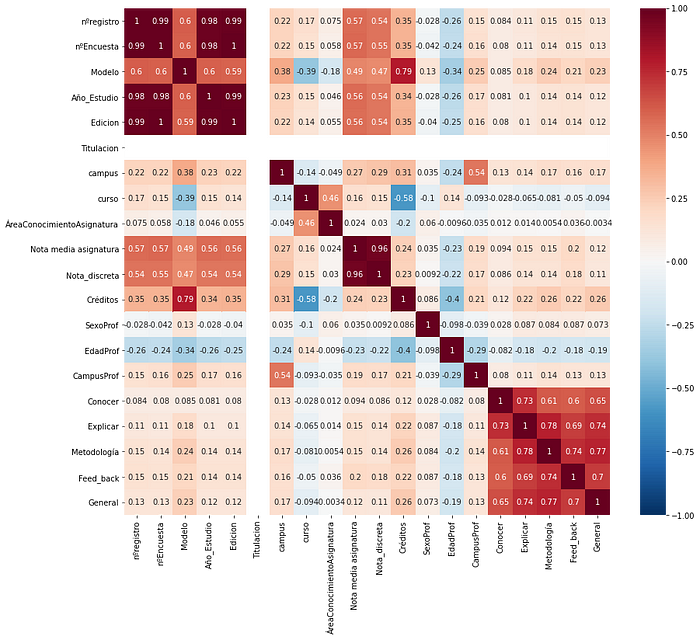
Si nos fijamos en las variables relacionadas con la satisfacción, podemos comprobar que la metodología es lo que más correlaciona con la nota general del profesor/a (aunque explicar y feed_back están muy cerca) y el conocimiento del/a profesor/a, lo que menos. Vamos, que empezamos a reafirmar algo que ya imaginábamos: por mucho que sepa una persona, como no cuenta con la metodología adecuada, puede no llegar a satisfacer lo suficiente al alumnado. Pero ojo, conocer también se correlaciona con explicar, por tanto, para poder explicar bien hay que conocer bien lo que se imparte. Condición necesaria, pero no suficiente.
También nos pareció interesante conocer si el sexo y la edad influyen en la satisfacción del alumnado, así que pasamos a agrupar con estos criterios:

Pues parece que los/as más jóvenes obtienen generalmente mejor puntuación. Sin diferencias destacables entre sexos, aunque es cierto que las mujeres más adultas (>55) parecen ofrecer una mejor experiencia que los hombres de su edad.
Por último, queríamos saber si, más allá de la edad, lo relevante era la antigüedad del/a profesor/a en la universidad. El profesorado está ordenado según su entrada en la facultad, por lo que bastaba con plotear este orden respecto a la nota de satisfacción.

Pues sí, parece que los nuevos fichajes tienen menos puntuaciones negativas que los/as veteranos/as del lugar. Eso sí, les cuesta más llegar al 10.
Ahora que tenemos ya algunas ideas sobre el dataset, pasamos a los modelos.
Hemos trabajado 4 modelos, cada uno con un objetivo.
-Regresión lineal: Para poder predecir la satisfacción general si contamos con los 4 ítems de satisfacción, y conocer la importancia de cada uno de ellos.
-Asociación: Para conocer qué atributos se “mezclan” más con otros.
-Decision Trees: Para clasificar de forma sencilla a promotores/detractores/neutros.
-Clustering: Para identificar la relación entre nota y satisfacción, y lo más importante, describir los grupos de profesores/as que se forman.
-NLP: Para conocer qué comentarios se repiten más según la satisfacción y la nota del grupo.
Regresión lineal
Escogimos las 4 variables de satisfacción como variables independientes, y la satisfacción general como la variable dependiente del modelo. Suponíamos, vistas las correlaciones, que íbamos a tener buenos resultados.
Y así fue, utilizando la técnica Ridge de regresión obtenemos un accuracy del… ¡67%! Seguro que jugando con los datos train y test podemos llegar a un resultado mejor, pero nos dimos por satisfechos. Para contextualizar mejor este dato, medimos la importancia relativa de cada variable.

Es decir, podemos predecir el resultado, y comprobamos que explicar es el elemento que más hace variar este resultado. Así que ya sabéis profesores/as, si os parece que os está yendo mal con un grupo, ¡a explicar mejor!
Asociación
Ya tenemos varias pistas sobre qué afecta más a la satisfacción, pero todavía no sabemos si hay relación entre un grupo con buenas notas y un buen profesor/a. Para comprobarlo, implementamos el algoritmo “a priori” para visualizar las asociaciones entre variables. A continuación, adjuntamos las asociaciones con un lift>1 (ocurren más de lo esperado).

Aunque hay un poco de todo, la asociación con mayor lift y confianza es “sobresaliente” con “promotor” Por lo tanto, podemos intuir que aquellos grupos que tienen una media sobresaliente, tienen un/a profesor/a que han valorado muy positivamente, pero no al contrario. Y tampoco podemos concluir que malas notas llevan mayoritariamente aparejadas malos/as profesores/as.
Para profundizar más en qué es lo que hace que ese profesor/a tenga promotores o detractores, empezamos con los decision trees.
Decision Trees
La primera prueba que hicimos fue con una profundidad de 2, para empezar a visualizar los primeros resultados.

Conclusiones similares a lo anterior para el profesorado: Explicar es lo que más diferencia a promotores de detractores/neutros. Pero para asegurar un mayor número de alumnos/as promotores, mejor tener una buena metodología en las sesiones. Y, si explicar no es tu fuerte, céntrate en dar un buen feedback para no tener detractores.
Pero bueno, el score del árbol es de 0.35, así que hay que coger el resultado con cierto escepticismo.
Si ampliamos la profundidad a 5, ya vemos que entran nuevos atributos, y sube el score a 0.45. Un insight que descubrimos con este árbol es que, si el feedback no es lo suficientemente bueno, pero el conocimiento percibido por el alumno/a es alto, la posibilidad de tener promotores sube.
Visto todo esto, vamos a centrarnos en cómo son los/as profesores/as según la satisfacción de los/as alumnos/as y las notas que ponen.
Clustering
Antes que nada, aplicamos el algoritmo K-Means para identificar el número óptimo de clústeres: 6. Pasamos a plottear esta relación entre notas y satisfacción:
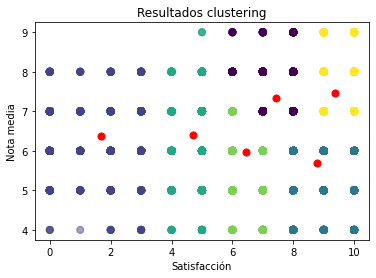
Tenemos 6 grupos diferenciados, pero vamos a poner el foco en 3 de ellos:
Para profundizar algo más en cómo clasificar a estos profesores, vamos a darle un poco al NLP.
NLP
Como todo proyecto, en las fases finales quedan pocas energías. Y si lo último es NLP, que no es precisamente el algoritmo más sencillo, cuesta llegar a conclusiones reveladores. Sin embargo, con un simple counts de cuáles son las frases más repetidas (cuando se les pregunta aspectos a mantener) de los/as alumnos/as en función de la nota que dan al profesorado y las notas que reciben, obtenemos los siguientes insights.
En el caso de los detractores, los comentarios giran en torno al trabajo en equipo. Vamos, que lo positivo de la asignatura han sido sus compañeros/as de clase más que la propia clase. En cambio, los comentarios más repetidos con los promotores ensalzan al profesor/a: su conocimiento, formas diferentes de dar clase, buen feedback a todos los trabajos…
Si analizamos las respuestas según la nota obtenida, los comentarios más repetidos en el caso de los suspensos hacen referencia al material aportado. Es decir, lo único bueno que tiene que decir es que la asignatura o los PPTs son buenos. Y en el caso de los sobresalientes, ya aparecen (por primera vez) muchos comentarios sobre la disposición del profesor/a: atención, actitud, motivación, ganas de ayudar…
No son conclusiones reveladoras que nos hagan ganar el nobel de educación, y puede que no sean extrapolables a otras universidades y contextos. Pero al menos ya hay una base por dónde empezar, y aunque ahora lo complicado sea precisamente cómo mejorar esas explicaciones o la actitud, los profesores/as ya sabemos dónde incidir, y los alumnos/as qué exigir 😉
Si tuviéramos que cerrar con una conclusión final, sería precisamente la importancia de la actitud. Es el comentario más repetido, con diferencia, en el caso de los grupos con notas sobresalientes. Ya no es cuestión de que estén más o menos satisfechos, sino de que obtienen mejores resultados. Y aunque mejores calificaciones no equivalen necesariamente a un mejor desarrollo futuro, nos surgen dos preguntas de cierre.
Como profesores/as, o desde la coordinación: ¿Se hacen los esfuerzos suficientes para mejorar la actitud y disposición del profesorado hacia los/as alumnos/as? ¿Puede más la burocracia o la experiencia del estudiante?
Como alumnos/as: ¿Hasta qué punto existe actitud hacia el aprendizaje? ¿Cuánta responsabilidad tiene el profesor en motivarnos? ¿No sería más lógico venir motivados/as de casa?
Todavía queda mucho por hacer…
En el siguiente enlace de GitHub encontrarás el dataset y los diferentes notebooks utilizados en el proyecto.
Si quieres ver la presentación que se hizo del proyecto, la tienes por aquí.
Y para acabar, un agradecimiento a todo el equipo de Saturdays.AI Bilbo. De estar contando filas en un Excel hemos pasado a un proyecto presentable, nada habría sido posible sin la comunidad. Mila esker denoi!
Thanks to Rubén García Pedrejón.
En el siguiente repositorio se encuentra el código usuado para desarrollar esta aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Donostia/Donostia2021/StudentExperience-ResultsAI-main
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) a la vez que se realizan proyectos para el bien (#ai4good). Los talleres que realizamos forman parte del programa AI 4 Schools para que cualquier persona “aprenda haciendo” IA sin importar su especialidad o nivel de partida.
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en este link o visítanos en nuestra web www.saturdays.ai ¡te esperamos!