
Donostia. Segunda Edición. 2021
Introducción
Según la Dirección General de Tráfico (DGT), la distracción en la conducción es una de las principales causas de los accidentes de tráfico, siendo la causa de 1 de cada 3 accidentes mortales (33%), por delante de la velocidad (29%) y del alcohol (26%).
Tras un minuto y medio de hablar por el móvil (incluso con manos libres), el conductor no percibe el 40% de las señales, su velocidad media baja un 12%, el ritmo cardíaco se acelera bruscamente durante la llamada y se tarda más en reaccionar.
La peligrosidad por un uso inadecuado del móvil puede llegar a ser equiparable a la conducción con exceso de alcohol.
Más de 1 de cada 3 españoles reconoce haber hablado por teléfono, leído o escrito mensajes durante la conducción en los últimos años.
Un conductor que habla mientras conduce:
· Pierde la capacidad de mantener una velocidad constante.
· No guarda la distancia de seguridad suficiente con el vehículo que circula delante.
· El tiempo de reacción aumenta considerablemente: entre medio a dos segundos, dependiendo de los reflejos de cada conductor.

Esto hace que la detección de estas distracciones sea esencial para mejorar la seguridad vial. Si se pudiera “detectarlas” con el fin de avisar al conductor de que algo va mal, el número de accidentes podría disminuirse radicalmente.
En este proyecto estaremos enfocados en detectar algunas distracciones más comunes, como utilizar el móvil, mirarse al espejo o beber algo mientras conducimos, bien como identificarlas.
Objetivo
El objetivo de este proyecto es ajustar un modelo de Machine Learning capaz de identificar y clasificar las diferentes distracciones a que estamos expuestos siempre que conducimos.
Para ello, trabajaremos con una técnica de Deep Learning conocida como “Redes Neuronales Convolucionales” (CNN o “Convolutional Neural Network”).
Probaremos algunas arquitecturas de redes neuronales, todas ellas mejoradas con redes pre-entrenadas para la clasificación de imágenes (transfer learning).
Conjunto de Imágenes
El conjunto de imágenes que hemos utilizado en el marco de este proyecto proviene de un concurso lanzado en la plataforma Kaggle hace aproximadamente 5 años (pulse aquí para verlo).
Todas las imágenes han sido obtenidas por medio de una cámara instalada dentro del coche, siempre con un conductor dentro y en diversas situaciones cotidianas.
Las fotos han sido tomadas en un ambiente controlado: un camión arrastraba el coche por las calles, de tal manera que los conductores no tuviesen que conducir de verdad.
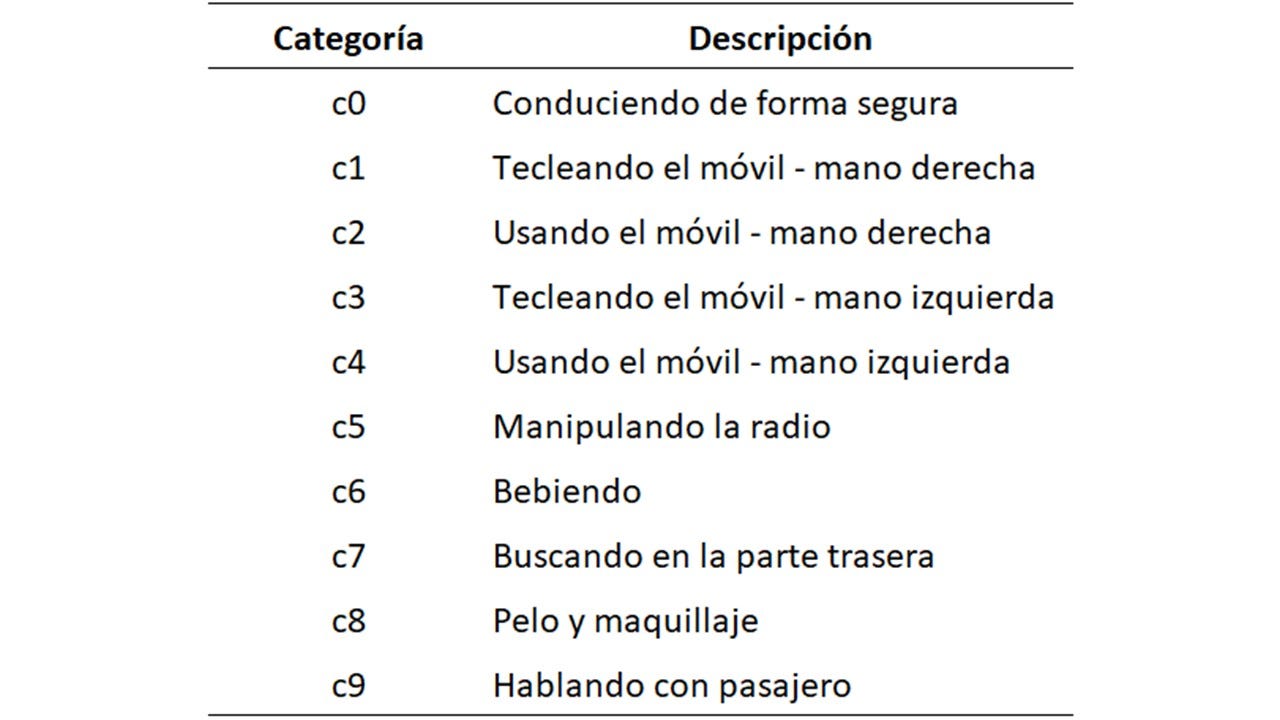
Para el entrenamiento de los modelos, hemos contado con un total de 22.424 imágenes, clasificadas en 10 categorías:
Exploratory Data Analysis
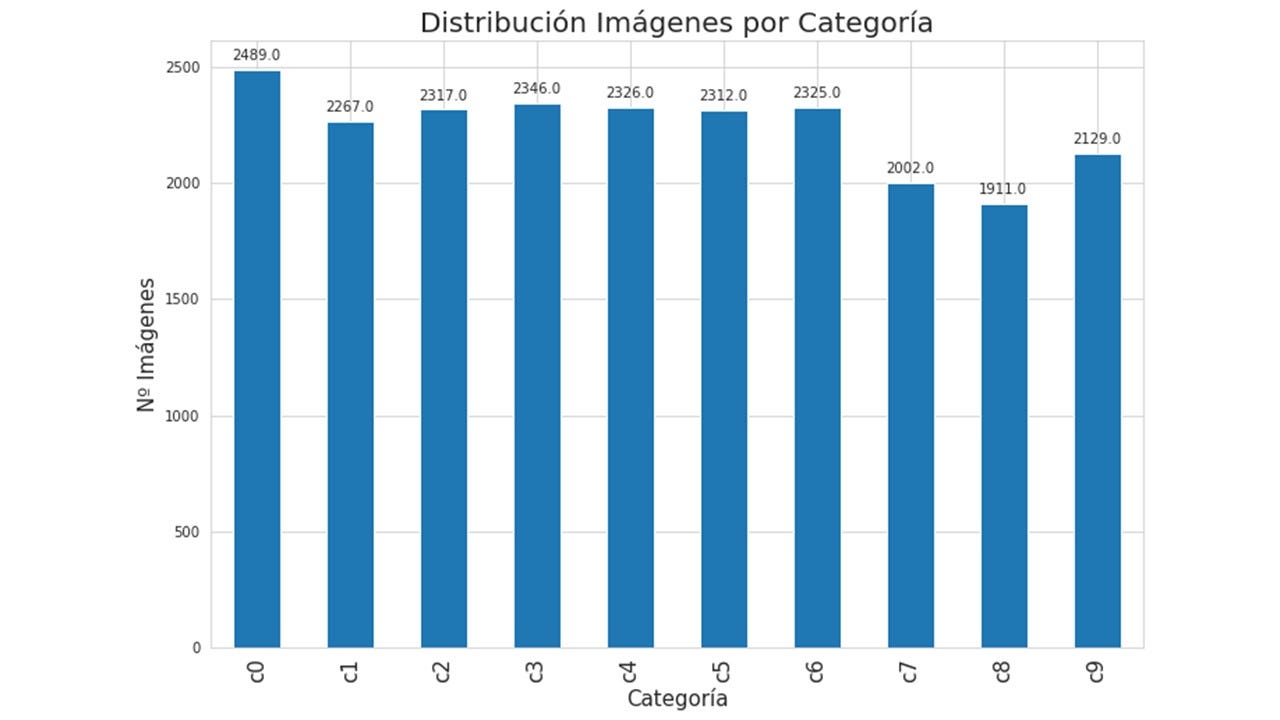
Como parte de la etapa de “Exploratory Data Analysis”, hemos comprobado que todas las imágenes tenían la misma dimensión: (480, 640, 3).
Tras un muestreo aleatorio, podríamos afirmar que las imágenes estaban bien clasificadas a lo largo de las 10 categorías del experimento. Esto se debe seguramente por tratarse de un conjunto de imágenes proveniente de un experimento controlado y que fue a concurso en la plataforma Kaggle.
Además, las imágenes estaban distribuidas de una forma razonablemente equilibrada entre las 10 categorías, por lo que prácticamente hemos podido “saltarnos” a la etapa de “EDA” para irnos directamente a la fase de entrenamiento de los modelos de CNN.
También estaban disponibles en la plataforma Kaggle 79.725 imágenes para testeo, sin ningún tipo de clasificación o etiqueta.
Es importante mencionar que las imágenes de entrenamiento y testeo estaban divididas en Kaggle de tal manera que un mismo conductor no podría aparecer en los 2 grupos (entrenamiento y testeo).
En general, las 10 categorías podrían ser consideradas “excluyentes”, a excepción de las categorías “c0” (conduciendo de forma segura) y “c9” (hablando con pasajero), que se parecen más entre ellas y podrían ser consideradas “no excluyentes”, ya que, en algunas situaciones, tienen en común las 2 manos colocadas en el volante.

Implementación
En líneas generales, hemos seguido los siguientes pasos para el ajuste de las Redes Neuronales Convolucionales presentadas en este proyecto:
- Bajar y pre-procesar las imágenes de los conductores.
- Construir y entrenar un modelo para clasificar las imágenes de los conductores.
- Chequear el ajuste del modelo y mejorarlo usando diferentes técnicas.
Transfer Learning
Normalmente, no hace falta entrenar una Red Neuronal Convolucional empezando de cero.
Redes Convolucionales modernas, entrenadas con enormes conjuntos de datos como ImageNet, pueden tardar semanas en múltiples GPU’s.
En cambio, una práctica cada vez más habitual es el uso de redes pre-entrenadas como un extractor de características fijas, o como una red inicial para ajustes más finos.
La red pre-entrenada VGG es interesante para el objetivo de este proyecto porque, aparte de su sencillez, genera excelentes resultados. La idea es mantener todas las capas de la red VGG, conectando su capa final a nuestro propio clasificador.
De esta forma, podríamos usar la red VGG como un extractor de características fijas para nuestras imágenes, quedando pendiente el entrenamiento de un clasificador más sencillo al final de todo (top model).
En este proyecto, utilizaremos la red pre-entrenada “VGG16”, como punto de partida. Para el ajuste más fino, utilizaremos 3 capas finales, propuestas en este link (“Hands-on Transfer Learning with Keras and the VGG16 Model”).
A partir del resultado de este primer ajuste, construiremos nuevos modelos, con más capas. También utilizaremos el recurso de Data Augmentation, e incluso nos atreveremos a cambiar la “VGG16” por la “VGG19”, red neuronal pre-entrenada más compleja, ya que cuenta con 3 capas más que la “VGG16”.
Amazon Web Services
Los ajustes de este primer modelo y de todos los demás presentados en este artículo han sido realizados en SageMaker de Amazon Web Services. Para ello, hemos contado con el crédito de 1.000$ que Amazon nos concedió por formar parte de la familia Saturdays.AI.
Hemos elegido el centro computacional ubicado en ‘EE.UU. Este (Ohio)us-east-2’, ya que este centro disponía de máquinas con GPU. La máquina elegida para abrir la instancia de nuestro notebook en SageMaker ha sido: ‘ml.p3.2xlarge’.
Parámetros y Evaluación de los Modelos
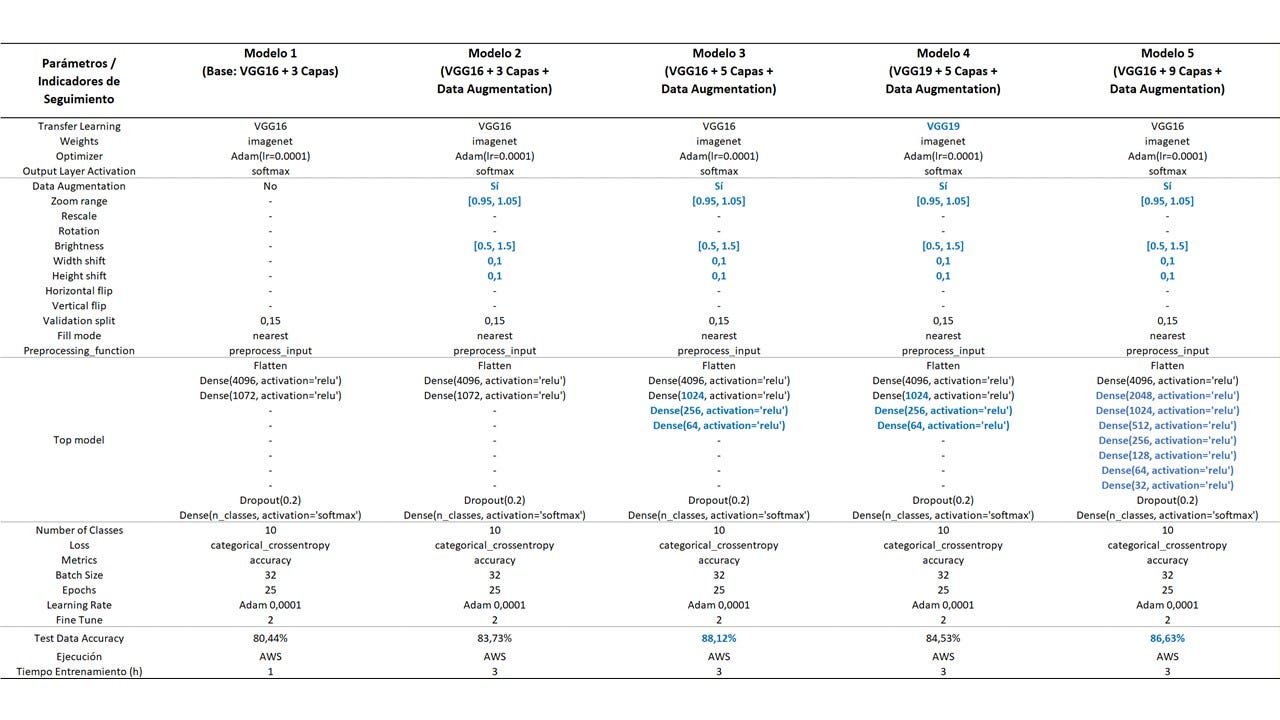
Un resumen de los parámetros de los modelos ajustados será presentado a continuación en modo de tabla.
De todas formas, no está de más comentar que, en todos los modelos, hemos fijado Batch = 32 y Epochs = 25, para que hubiese una base de comparabilidad entre los ajustes de los modelos.
Para hacer la evaluación de los modelos ajustados, además de las gráficas de accuracy y de loss generadas por el algoritmo, hemos clasificado 1.002 imágenes, que a partir de ahora llamaremos ‘Test Data’.
Esta imágenes han sido elegidas aleatoriamente de las 79.725 imágenes no clasificadas para testeo, con el objetivo de tener una medida de accuracy en un conjunto de imágenes totalmente ajeno a los datos utilizados para los entrenamientos (‘Test Data’ Accuracy).
También hemos preparado un código en Google Colab (“model_test.ipynb”), para poder visualizar el resultado del modelo en cada imagen, como se puede ver en el GIF de abajo.

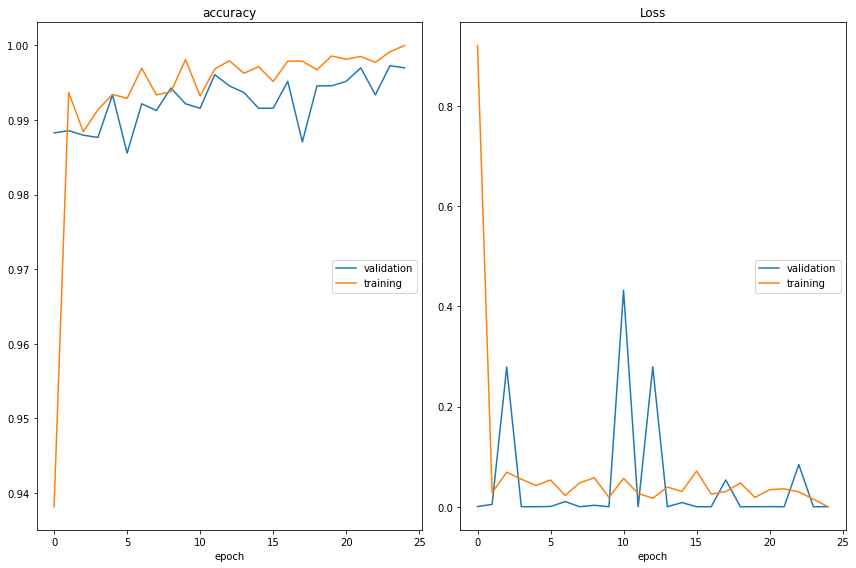
Modelo 1: VGG16 + 3 Capas
Como comentado anteriormente, para el primer modelo (“base”) hemos utilizado la red pre-entrenada “VGG16”, y para el ajuste más fino, hemos utilizado 3 capas finales.
El resultado del ajuste de este modelo podría ser considerado satisfactorio, teniendo en cuenta que este ha sido el primer intento de modelización del proyecto:
· ‘Test Data’ Accuracy: 80,44%
Modelo 2: VGG16 + 3 Capas + Data Augmentation
Para mejorar el modelo anterior, nos hemos planteado utilizar el recurso de “Data Augmentation”.
En principio, no sabíamos a que se referían algunos de los diversos parámetros disponibles para hacer el Data Augmentation, tampoco qué significaban sus rangos.
Para solventarlo, hicimos una serie de pruebas, para poder decidir qué parámetros de Data Augmentation queríamos emplear en nuestro conjunto de imágenes y sus respectivos rangos.
Al tratarse de un experimento controlado, el conjunto de imágenes utilizado requería un Data Augmentation controlado y discreto, teniendo en cuenta que cambios exagerados aplicados a las imágenes originales podrían ser contraproducentes.
Por ejemplo, hemos decidido no hacer “rotaciones”, ya que corríamos el riesgo de generar imágenes “antinaturales”.
Los parámetros de Data Augmentation que hemos utilizado han sido: “zoom”, “width”, “height” y “brightness”. A continuación, algunos ejemplos.


Nota: las imágenes tienen ese tono debido al preprocesamiento de RGB.
El resultado del ajuste de este modelo ha mejorado considerablemente con relación al anterior (Modelo 1), por lo que hemos decidido continuar utilizando Data Augmentation en los siguientes modelos ajustados en el marco de este proyecto.
· ‘Test Data’ Accuracy: 83,73%

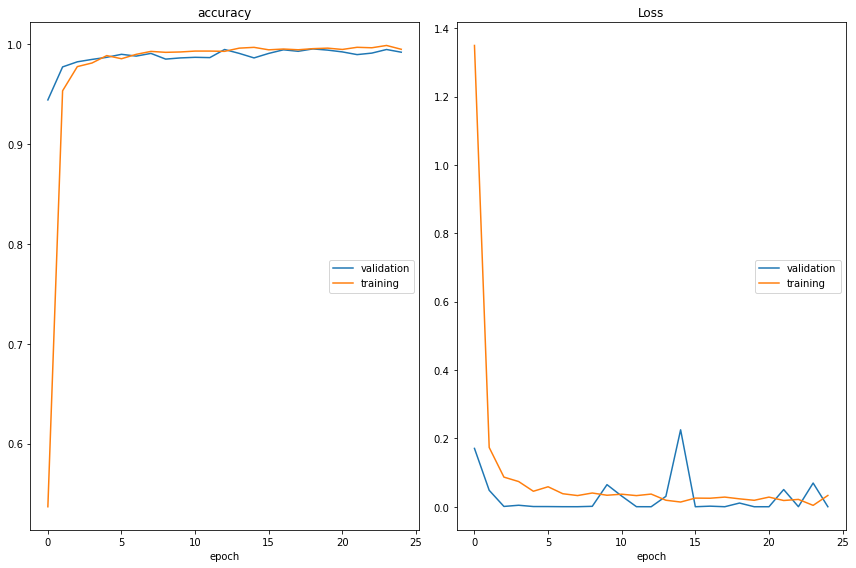
Modelo 3: VGG16 + 5 Capas + Data Augmentation
De cara a seguir mejorando el ajuste anterior, hemos incrementado 2 capas a la red neuronal final (top model), manteniendo los mismos parámetros de Data Augmentation del modelo anterior.
Se observa una mejora importante en el accuracy del modelo en ‘Test Data’:
· ‘Test Data’ Accuracy: 88,12%
Modelo 4: VGG19 + 5 Capas + Data Augmentation
A esta altura, ya que los resultados habían mejorado considerablemente, hemos decidido hacer algo diferente, como un cambio de la red pre-entrenada, para seguir explorando nuevos caminos hacia la mejora.
Hemos utilizado la red “VGG19”, que contiene 3 capas más que la red “VGG16”.
En este caso, los resultados de accuracy no han mejorado respecto al Modelo 3:
· ‘Test Data’ Accuracy: 84,53%
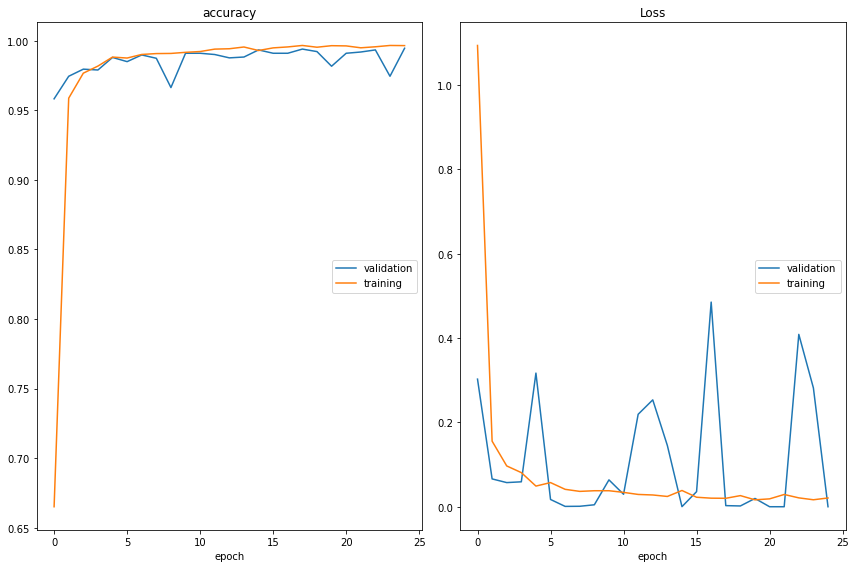
Por lo que hemos decidido volver a utilizar la red “VGG16” para el ajuste del siguiente modelo.
Modelo 5: VGG16 + 9 Capas + Data Augmentation
Para seguir explorando otras posibles mejoras en lo que concierne al accuracy del modelo, hemos decidido aumentar considerablemente el número de capas, de 5 a 9, manteniendo el Data Augmentation anterior.
En este caso, tampoco hemos mejorado el accuracy respecto al Modelo 3, aunque el resultado haya sido bastante aceptable:
· ‘Test Data’ Accuracy: 86,63%
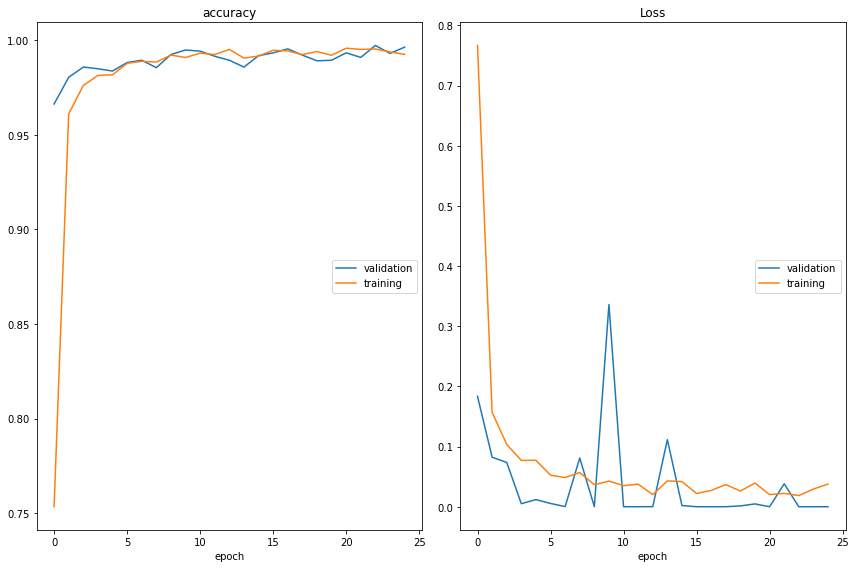
Tabla Resumen
La tabla a continuación detalla los 5 modelos ajustados y la línea de razonamiento seguida para ir ajustándolos, paso a paso.
En azul, los cambios implementados a partir del primer modelo (“base”), y los mejores resultados de accuracy (> 85%).
Matriz de Confusión: Modelo 3
Los porcentajes de acierto por categoría provenientes del ajuste del Modelo 3 son en general bastante satisfactorios.
Esto se refleja en la Matriz de Confusión del modelo.

Se destacan las siguientes categorías por su alto porcentaje de acierto (>95%): “c3” (tecleando el móvil -mano izquierda), “c5” (manipulando la radio) y “c7” (buscando en la parte trasera).
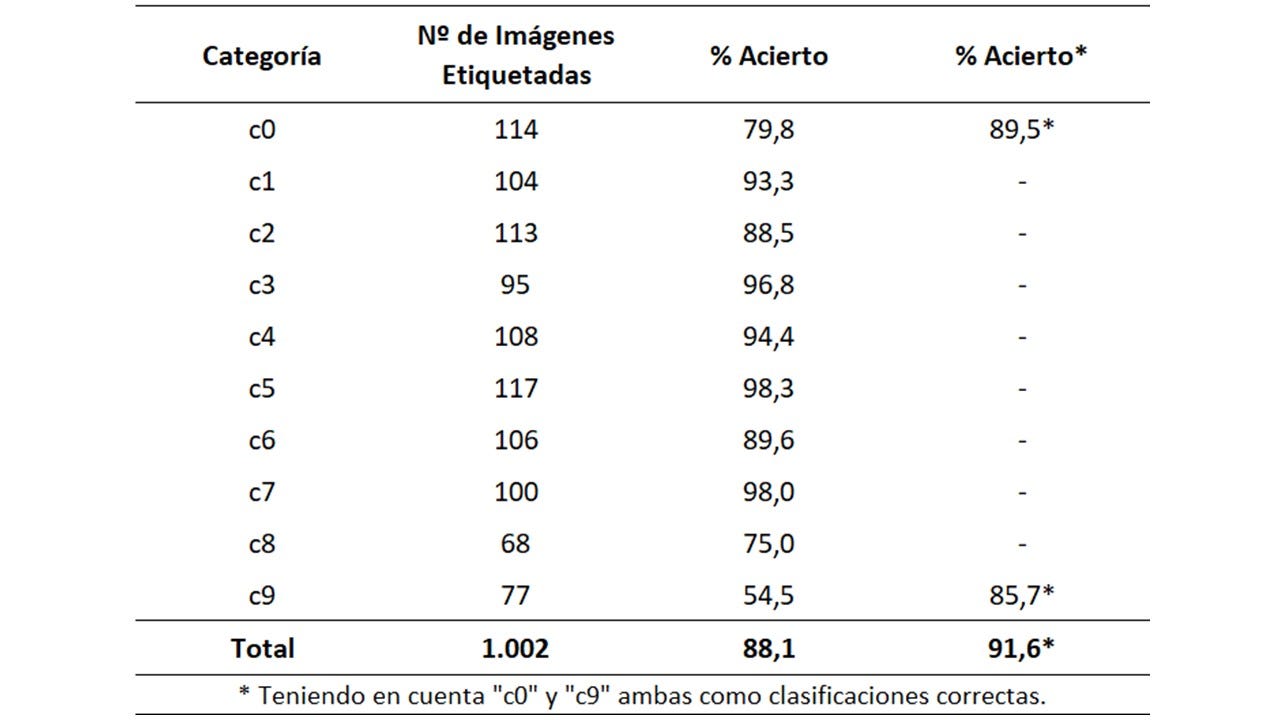
Es notable la disminución del porcentaje de acierto en la categoría “c9” (hablando con pasajero). Esto pasa debido a que las categorías “c0” y “c9” podrían ser consideradas las “menos excluyentes”, según comentado anteriormente.
Si tenemos en cuenta “c9” y “c0” ambas como clasificaciones correctas para “c9”, este porcentaje de acierto para “c9” se incrementa un 30,2% (de 54,5% a 85,7%), acercándose a los porcentajes de acierto de las demás categorías.
Hemos realizado este cálculo para intentar cuantificar el impacto en accuracy por el hecho de haber trabajado con un par de categorías “algo menos excluyentes”.
Si las categorías “c0” y “c9” hubiesen sido definidas de una forma “más excluyente”, seguramente hubiésemos conseguido unos ajustes con mejor accuracy desde el principio.
Por otro lado, entendemos que el estudio tiene que reflejar situaciones cotidianas, ya que serán la realidad a ser afrontada en el momento de desplegar cualquier modelo en la vida real.
Conclusiones
La gran capacidad computacional que requiere este tipo de técnica ha hecho que tuviéramos que dedicar una parte importante del recurso del proyecto para solventar problemas de ejecución de los códigos utilizados.
Hemos tenido que aprender a utilizar los servicios de Amazon Web Services para hacerlo viable, y los modelos de este proyecto han podido ser entrenados gracias a las GPU’s disponibles de esta plataforma.
A continuación, se presentan algunas conclusiones y lecciones aprendidas tras desarrollar este proyecto:
- No siempre un incremento de capas a la Red Neuronal va a mejorar el accuracy del ajuste del modelo. Este hecho se ha podido ver en los ajustes de los Modelos 3 y 5.
- El recurso de Data Augmentation debe ser utilizado con criterio, tras un análisis del conjunto de imágenes inicial, ya que su uso indiscriminado puede ser contraproducente.
- El trabajo en equipo ha sido fundamental para el éxito de este proyecto. Los perfiles diferentes entre los miembros del equipo del proyecto y del equipo coordinador de Saturdays.AI Donostia ha sido clave para sumar una visión amplia y enriquecedora.
El camino no ha sido fácil y ha requerido muchas horas de entrenamientos. Pero créenos: ¡ha merecido la pena!
Próximos Pasos
Como próximos pasos, nos planteamos lo siguiente:
· Ajustar un segundo modelo más específico que aprenda a detectar las diferencias entre las categorías “c0” y “c9”.
· Volver a entrenar el Modelo 4 (VGG19 + 5 capas + Data Augmentation), pero ahora con más “epochs”. La idea es observar si con más entrenamientos la red “VGG19” converge a los mismos resultados observados con la red “VGG16”.
· Ejecutar el Modelo 3 en una Jetson Nano Nvidia, y por medio de una cámara instalada en el coche, comprobar la eficacia del modelo en la detección de comportamientos inadecuados.
Equipo de Trabajo
Y para despedirnos, nos gustaría presentarnos.
Hola. Me llamo Imanol Areizaga y soy Ingeniero Industrial. Desde mis primeras experiencias laborales estoy trabajando en procesos de digitalización en el ámbito industrial. En el camino de Data Science vas descubriendo paso a paso nuevos horizontes y en este paso que estoy dando junto a Saturdays.AI estoy interesado en cómo aplicar Deep Learning en el ámbito Industrial. Un ámbito muy exigente, en el que la eficiencia de los modelos tiene que ser muy cercana al 100%.
Hola a tod@s. Me llamo Henry Corazza Sef y soy estadístico. Aunque me haya decantado por trabajar en la implementación de la Metodología 6 Sigma en el área industrial, sigo muy interesado en Data Science en general. Tras este curso, he descubierto otra pasión: ¡el enigmático universo de las Redes Neuronales! ?
Agradecemos a los mentores y organizadores de Saturdays.AI Donostia, especialmente a Beñat Galdós, Joxemari Gallastegi e Imanol Echeverria, por su profesionalidad, dedicación y entusiasmo.
Repositorio
En el siguiente repositorio se encuentra el código usado para desarrollar esta aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Donostia/Donostia2021/focusondriving-main
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master de inteligencia artificial en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!