Los eventos tech no tienen por qué tener lugar siempre dentro de una sala de conferencias. Durante cuatro días, PyCamp España 2026 llevó Python a plena naturaleza: un campamento donde programar, debatir, compartir proyectos, convivir y hacer comunidad formaron parte de una misma experiencia. En un entorno rural, la tecnología también se vivió alrededor de una mesa, una conversación y un paseo por el monte.
AgroClaw es un agente AgTech experimental aplicado al olivar que ha evolucionado hacia una memoria técnica visual-documental asistida por IA. A través de OpenClaw, una arquitectura por capas, skills especializadas, knowledge en Markdown y referencias visuales documentadas, el proyecto explora cómo recuperar conocimiento agrario, orientar diagnósticos y conservar experiencia de campo en una estructura reutilizable.
Todo empezó como empiezan muchas obsesiones en Minecraft: en una isla de SkyBlock, solo, con recursos limitados y una sensación constante de que el verdadero cuello de botella no era el juego… sino la información. Horas saltando entre wikis desactualizadas, foros enterrados y vídeos inconexos para entender una sola mecánica. En ese momento surge la pregunta: ¿y si la wiki no fuera un archivo muerto, sino un sistema vivo que aprende al ritmo del juego?
SkyBlockCodexAPI nace de esa fricción, pero también de esa intuición: convertir el caos de conocimiento de SkyBlock en una infraestructura dinámica donde comunidad, datos y modelos de IA no solo documentan lo que pasa, sino que lo entienden, lo actualizan y lo anticipan.
La primera fase fue bastante directa en apariencia: conectar con la API pública de Hypixel y empezar a mostrar información de:
ítems
colecciones
skills
elecciones
bingo
museum
Sobre el papel, la idea era simple: pedir datos y enseñarlos. En la práctica, no tardamos en descubrir el problema real: la información no llega siempre con el mismo formato ni con el mismo nivel de limpieza.
Algunas descripciones venían en texto plano.
Otras traían listas.
Otras mezclaban lore, perks, unlocks y campos especiales.
Y muchas incluían códigos de formato de Minecraft como §7, §a, §d o incluso formatos alternativos como %%light_purple%%.
Ese fue uno de los primeros momentos en los que la IA empezó a aportar valor de verdad. Nos ayudó a:
detectar estructuras repetidas dentro del caos
proponer normalizaciones sin perder información
transformar formatos pensados para el juego en algo legible para web
acelerar iteraciones pequeñas sin perder coherencia visual
No se trataba solo de “traducir JSON”. Se trataba de interpretar el lenguaje visual del juego y llevarlo a un entorno web sin que perdiera personalidad.
El reto de hacerlo estático sin que se sintiera estático
Uno de los condicionantes más importantes del proyecto fue decidir que la aplicación debía vivir en GitHub Pages.
Eso imponía una restricción muy clara: sin backend tradicional. Sin servidor persistente. Sin lógica privada en el lado del servidor.
Lejos de verlo como un límite, lo tratamos como una restricción creativa. Si queríamos una web estática, entonces teníamos que conseguir que pareciera dinámica usando únicamente:
HTML
CSS
JavaScript
llamadas a endpoints públicos
una arquitectura ligera pero flexible
La IA fue especialmente útil aquí porque nos ayudó a repensar el proyecto varias veces sin tener que rehacerlo entero. A medida que descubríamos qué endpoints eran públicos, cuáles no, qué cosas se podían consultar directamente y cuáles convenía simplificar, fuimos ajustando la arquitectura con rapidez.
El resultado fue una decisión importante: apostar por una web muy viva, pero sin backend propio, aprovechando solo lo que podía resolverse de forma segura y pública. Eso nos permitió mantener el despliegue simple y el proyecto muy fácil de compartir.
Una dificultad real: el formato visual de Minecraft no existe en la web
Uno de los problemas más curiosos —y más entretenidos— fue el tratamiento del texto.
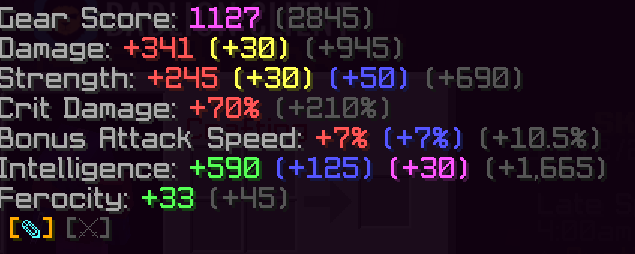
En SkyBlock, una enorme parte del significado visual está en el color. Un perk no solo dice algo: cómo lo dice también importa. Un texto dorado, una línea en azul claro, un stat en rojo o una rareza en morado no son adornos; son parte de la experiencia del juego.
Ejemplos típicos:
+0.5% ☣ Crit Chance
+1 ❈ Defense
+5 SkyBlock XP
perks con colores embebidos
nombres de ítems con formato especial
Para mostrar eso bien en una web tuvimos que resolver muchas pequeñas dificultades:
interpretar códigos §
interpretar formatos
alternativos como %%light_purple%% diferenciar entre símbolo, número y texto
respetar el “+” sin romper el color del stat
aplicar colores distintos según el atributo
mantener la legibilidad visual sin perder el estilo del juego Aquí la IA fue especialmente útil como herramienta de iteración rápida. Nos ayudó a convertir reglas visuales informales en reglas concretas de renderizado. Y, quizás más importante, a corregir decenas de bugs pequeños que aparecen cuando se trabaja con texto muy irregular.
Muchos de esos errores habrían costado bastante tiempo si hubiéramos ido caso por caso. Con IA, fue mucho más fácil detectar patrones, revisar excepciones y ajustar el resultado hasta que se sintiera bien.
Más allá del buscador: convertir datos en experiencia
Una vez que el renderizado básico funcionaba, el siguiente paso fue dejar de pensar solo en “mostrar datos” y empezar a pensar en cómo se navega una wiki.
Ahí empezaron a aparecer las decisiones que más personalidad le dieron al proyecto:
Búsqueda y sugerencias
No queríamos un buscador muerto. Queríamos una búsqueda ágil, con autocompletado y sugerencias que dieran sensación de inmediatez.
Se añadieron:
sugerencias en tiempo real
búsqueda por items, collections y skills
ejemplos visuales en la landing
una animación de búsqueda para hacer la home más llamativa
Además, trabajamos para que esas sugerencias no fueran solo texto plano, sino que respetaran colores, rarezas y formatos especiales. Así la experiencia del buscador encajaba con la del resto de la aplicación.
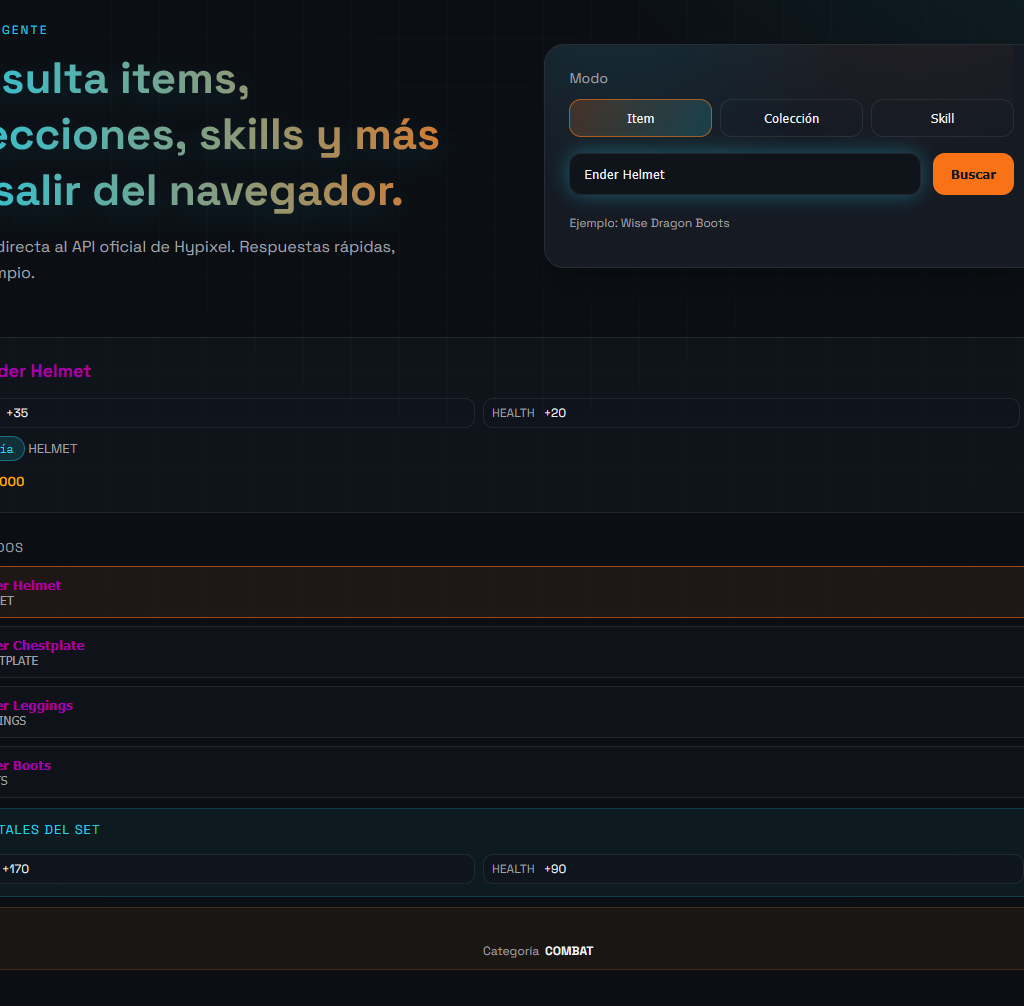
Ítems: de una ficha plana a una ficha realmente útil
La sección de items fue probablemente una de las más trabajadas.
No bastaba con enseñar nombre, categoría e ID. Eso se parecía demasiado a imprimir un JSON en pantalla. Queríamos algo que hablara el idioma del jugador.
Por eso se fue refinando la ficha hasta incluir:
nombre con color según rareza
soporte para nombres con formato especial
imagen del item según su material
soporte para cabezas con skin.value
soporte para iconos 3D en skull items
manejo de imágenes que fallan sin mostrar el icono roto del navegador
stats visuales, ordenados y coloreados
información del Museum
items relacionados dentro del mismo set
suma de stats totales del set
También tuvimos que resolver casos muy concretos y muy “SkyBlock”:
materiales legacy como gold_boots que en assets reales son golden_boots
armaduras tintadas de cuero con campo color
sets con nombres poco uniformes como:
Wise Dragon Boots
Boots of the Pack
Perfect Boots – Tier XII
Aquí la IA volvió a ser muy útil no por “inventar” la solución, sino por ayudarnos a generalizar reglas. Cuando detectábamos un caso raro, podíamos iterar rápido sobre la lógica y convertir excepciones en patrones reutilizables. Llegando al resultado final
Collections: no solo tiers, sino contexto
La parte de collections también evolucionó bastante.
Al principio bastaba con enseñar categoría y tiers. Pero una vez que empezamos a usar la web como una herramienta real, quedó claro que eso se quedaba corto.
Terminamos añadiendo:
iconos por categoría
visualización horizontal de tiers
unlocks dentro de cada tier
resaltado de SkyBlock XP
unlocks clicables cuando apuntan a items reales
soporte para recipes y minion recipes
Eso permitió que una colección no fuera solo una lista de requisitos, sino una pequeña ruta navegable dentro de la propia wiki. Desde una colección puedes saltar a un item, y desde el item seguir explorando otras partes del contenido.
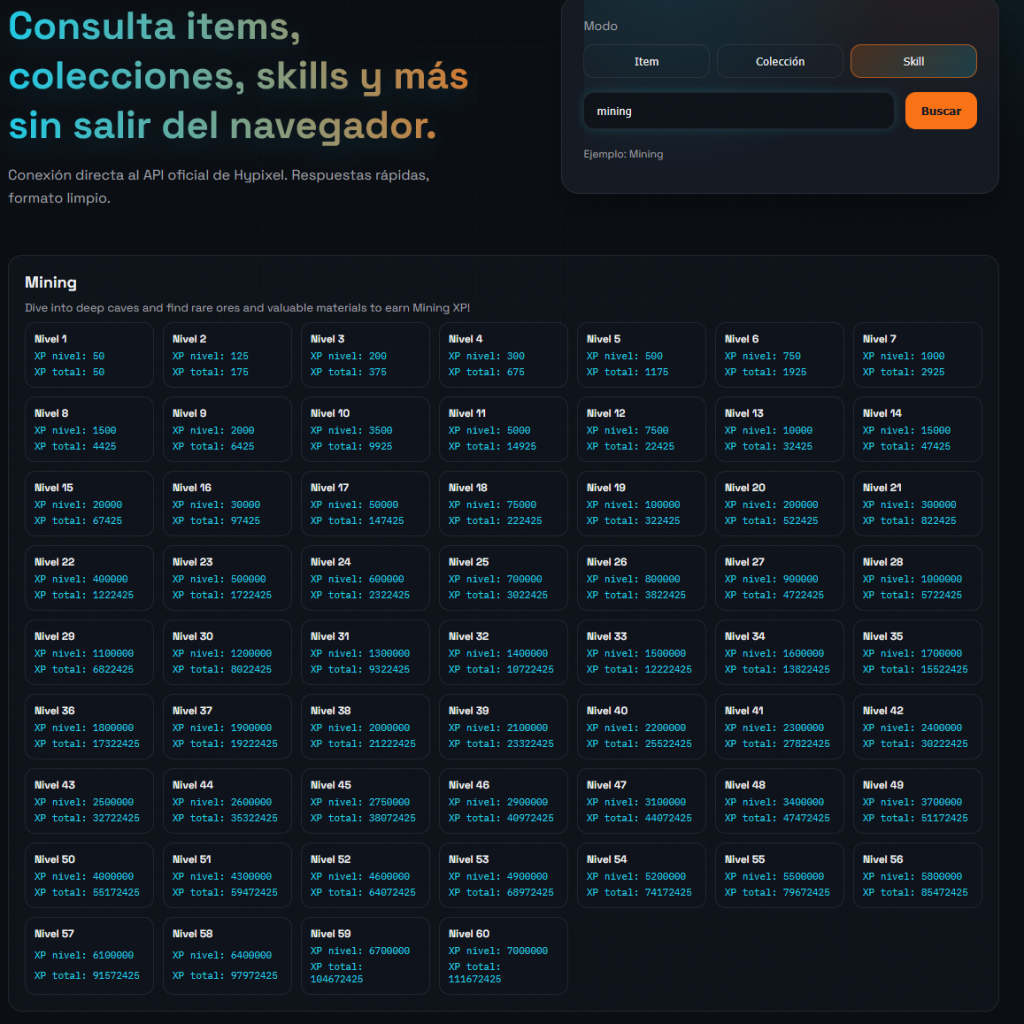
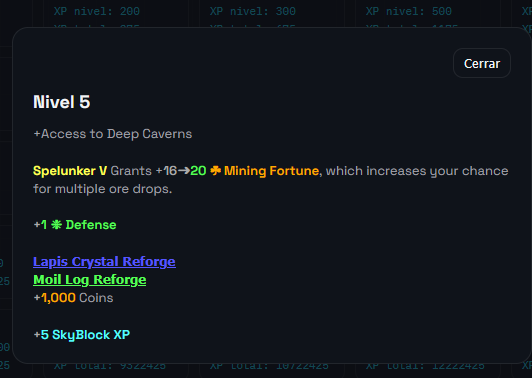
Skills: niveles, XP y recompensas con contexto
La sección de skills también requirió una buena cantidad de trabajo. No solo por la estructura de datos, sino porque había que interpretar correctamente la información del API.
La API no daba la experiencia “por nivel”, sino la experiencia total acumulada. Así que hubo que recalcular y representar:
nivel
XP necesaria para ese nivel
XP total
unlocks por nivel
Después añadimos un modal de detalle para cada nivel, donde se muestran los unlocks con formato visual mejorado. Y ahí se volvió a repetir la misma idea que ya habíamos aprendido: no basta con mostrar texto; hay que respetar el lenguaje visual del juego.
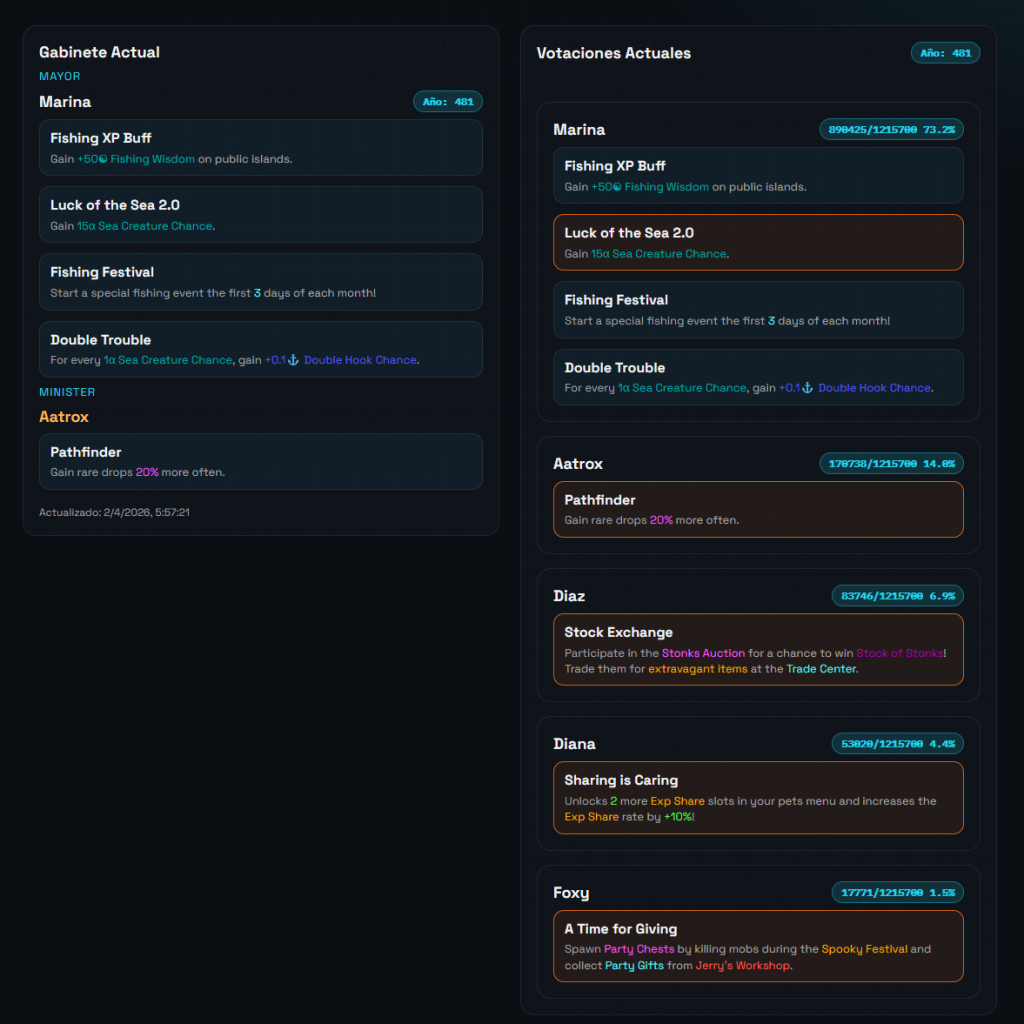
Mayor y elecciones: cuando el modelo de datos cambia según el contexto
La parte de Mayor fue especialmente interesante porque no solo había que mostrar información, sino también interpretar situaciones distintas:
mayor actual
minister
perks
elecciones activas
candidatos
porcentajes de votos
posibles special mayors
A nivel de interfaz, acabamos separando la página en dos columnas:
a la izquierda, el gabinete actual
a la derecha, las votaciones actuales
Después fuimos refinando la presentación:
perks con título y descripción
colores de Minecraft en descripciones
detección de minister perks
años visibles
votos mostrados como x / y z%
orden de candidatos de mayor a menor voto
Y, como suele pasar en proyectos reales, aparecieron casos especiales. Por ejemplo, cuando la estructura de election no estaba exactamente donde esperábamos o cuando se estaba mostrando la elección anterior en vez de la actual.
Ese tipo de problemas son justamente donde la IA ahorra tiempo de verdad: no porque “adivine” la respuesta, sino porque permite probar rápidamente estrategias de parsing más robustas hasta dar con una solución consistente.
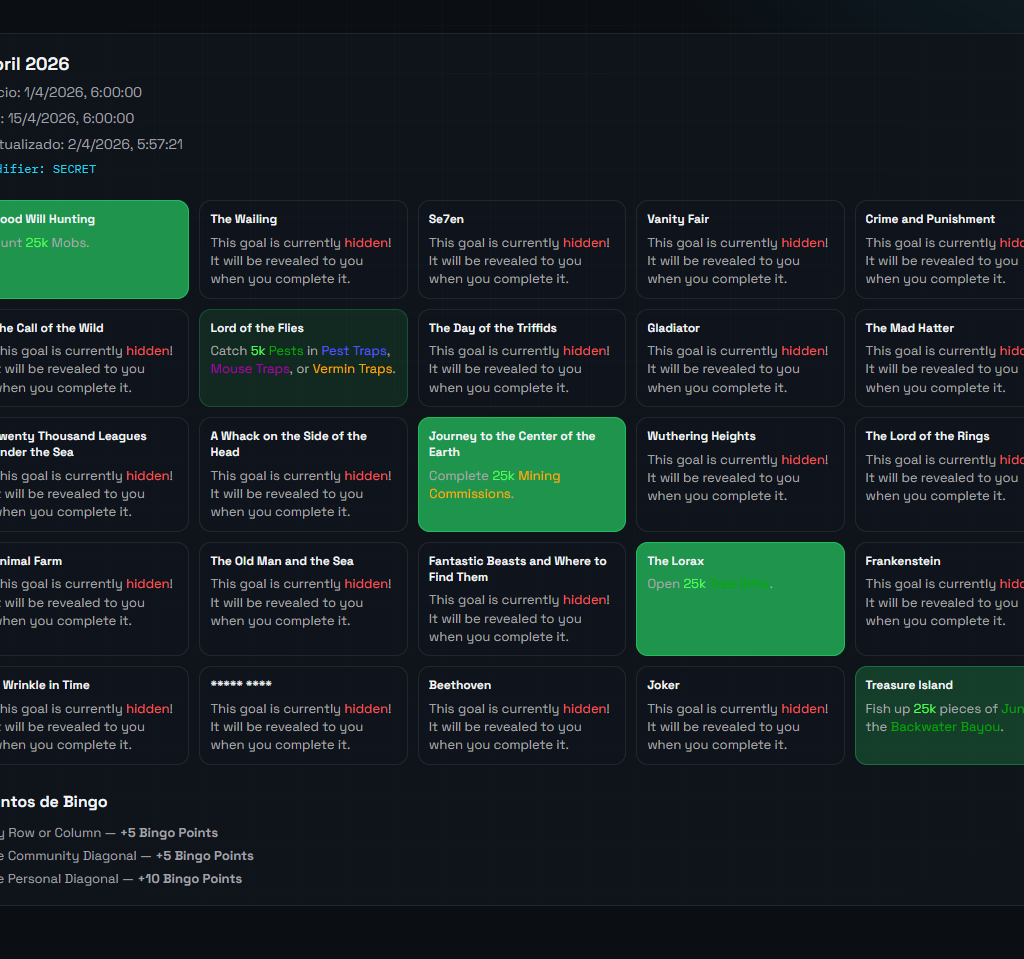
Bingo: convertir una API en una carta jugable
La subpágina de Bingo fue otra de las partes más divertidas de construir.
No queríamos listar objetivos en vertical. Eso no se parecía en nada a la experiencia real del juego. Así que lo convertimos en una carta 5×5, visual y navegable.
Se añadieron:
grid 5×5
modal por objetivo
full lore dentro del modal
hover interactivo
detección de goals comunitarias
coloreado progresivo según tier alcanzado
información de puntos contextual
navegación separada en su propia subpágina
Con Bingo, más que en ningún otro módulo, se vio claramente la diferencia entre “mostrar datos” y “diseñar una experiencia”. Ese cambio de mentalidad fue una de las mejores decisiones del proyecto.
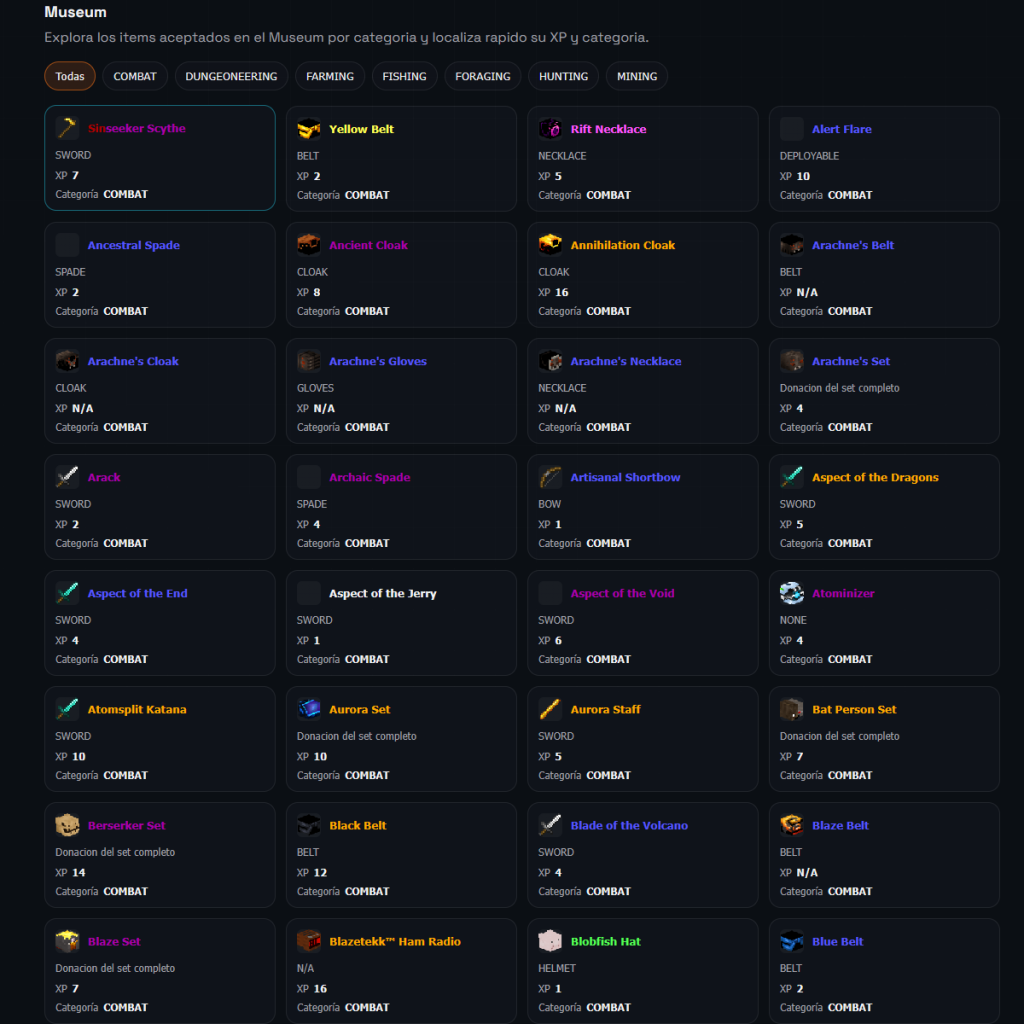
Museum: organizar sin saturar
La sección de Museum nació como una necesidad natural del proyecto. Una vez que ya teníamos items bien renderizados, tenía todo el sentido construir un navegador dedicado que permitiera explorar:
qué items acepta el Museum
cuánta XP da cada uno
a qué categoría pertenece
Además, se trabajó específicamente para evitar ruido innecesario:
deduplicación de armor sets
visualización limpia por categorías
iconos representativos
navegación desde Museum al item correspondiente
Y también aquí aparecieron los matices: sets completos, icono principal del helmet en Museum, distintas formas de extraer la XP de donación, etc.
Lo que Codex aportó de verdad
A estas alturas, la contribución de la IA se puede resumir muy bien: menos fricción, más iteración, más consistencia.
No sustituyó criterio.
No diseñó por sí sola.
No tomó decisiones importantes sin supervisión.
Pero sí hizo posible trabajar mucho más rápido en tareas como:
detectar patrones en datos inconsistentes
proponer estructuras de render más limpias
mantener coherencia entre páginas
depurar bugs visuales pequeños pero molestos
ajustar casos especiales sin frenar el ritmo del proyecto
Y eso tiene un valor enorme, porque en proyectos así el enemigo real no suele ser la complejidad técnica pura, sino el desgaste acumulado de cien pequeños detalles.
La IA ayudó precisamente ahí: en mantener el proyecto en movimiento.
Resultado actual
SkyBlockCodexAPI hoy ya no es una idea, sino una base sólida y funcional.
Actualmente incluye:
buscador rápido
sugerencias inteligentes
renderizado fiel al lenguaje visual de SkyBlock
fichas de items mucho más orientadas al jugador
páginas separadas para Mayor, Bingo y Museum
soporte para colores, perks, rarezas y formatos especiales
navegación clara entre secciones
despliegue en GitHub Pages
Todo ello sin backend tradicional, manteniendo una arquitectura ligera y fácil de compartir.
En una explotación agrícola, una decisión tan antigua como regar ya no depende solo del calendario, del tacto de la tierra o de mirar al cielo. En algunos campos, esa decisión empieza en una pantalla. Múltiples sensores captan datos relevantes para la explotación, y se toman decisiones potenciadas con IA, que van a llegar desde la tierra al plato.
La web app de Energía en Acción nace para dar una estructura digital a un proyecto que ya existía y necesitaba un espacio propio para organizar mejor su funcionamiento. La plataforma conecta estudiantes, mentores y organizaciones en un mismo entorno, facilitando la exploración de proyectos, la participación, el seguimiento y la comunicación desde un solo lugar.
Comparar dos IAs programando no consiste solo en ver quién escribe mejor código. En la práctica, la diferencia más relevante aparece en cómo entienden una tarea abierta, cuánto contexto necesitan, qué decisiones toman cuando algo no está completamente especificado y cómo reaccionan a las correcciones.
Para demostrarlo, he realizado un experimento: he clonado FoodCheck, una app publicada en GitHub Pages, manteniendo la misma lógica de negocio y la misma interfaz. Este es el resultado.
El reto tenía la condición de que la app tenía que ser 100% estática. GitHub Pages no ejecuta servidores, no maneja variables de entorno del lado del servidor ni permite un backend tradicional.
La misma aplicación, dos IAs:
Codex (modelo gpt-5.1-codex-max), mi anterior asistente para desarrollar la app original.
MiniMax M2.1 (Chat-Agent), con quien he intentado replicarla simplemente dándole la URL para que la analizara.
El contraste entre ambos estilos fue más interesante de lo que esperaba.
FoodCheck como caso de estudio
FoodCheck no es solo una interfaz donde subes una foto y salen números. Por debajo hay decisiones de arquitectura críticas:
Visión artificial avanzada capaz de interpretar platos complejos, no solo objetos aislados.
Datos nutricionales y reglas que dependen del perfil de salud del usuario.
Persistencia local (registro diario) sin base de datos.
Despliegue estático obligatorio en GitHub Pages.
Estas restricciones no son detalles técnicos, son el producto. Y aquí es donde la forma de trabajar de cada IA marca la diferencia.
Codex como copiloto: muy potente, pero necesita tareas bien acotadas
Con Codex (gpt-5.1-codex-max) la sensación general fue la de tener un copiloto sólido. Con un matiz: si no divides el trabajo en tareas muy específicas, tiende a dar más rodeos. Y además, cuando la app crece, a veces se olvida de lo que hizo varios mensajes atrás y hay que volver a explicarle el contexto.
No es que se equivoque, sino que tiende a dispersarse si no le guías: necesita que dividas el problema en pasos más concretos, puede proponer soluciones intermedias que no encajan del todo con el despliegue final, y a veces insiste en patrones estándar del desarrollo web aunque choquen con las restricciones previas.
En mi caso, esto se notó especialmente en dos puntos: la detección de alimentos y la adaptación a una app estática.
La detección simulada como punto de partida
Igual que me ocurrió después con MiniMax, el punto de partida fue una detección ficticia simplificada, suficiente para que la UI y el flujo funcionen pero no aceptable si el objetivo es un análisis real de platos.
Aprendí que, si no insistes, la IA prefiere cerrar primero el producto visible y ya luego afinar el corazón técnico.
Llegar a una solución viable para GitHub Pages llevó iteraciones
Codex fue proponiendo ideas que en un entorno general de desarrollo web son normales (por ejemplo, configuraciones estilo .env o piezas propias de un backend). Pero en GitHub Pages eso es inviable.
Hizo falta iterar hasta aterrizar en una solución compatible con una app estática, donde la parte inteligente vive fuera del frontend (por ejemplo, vía servicios externos).
Iniciativa conservadora
Al no haberle dado una indicación explícita sobre la base de datos nutricional a utilizar, Codex optó por una base de datos local muy reducida, con valores nutricionales introducidos manualmente para unos pocos alimentos. Desde el punto de vista del desarrollo incremental, esta decisión tiene sentido, ya que permite avanzar sin dependencias externas y validar el flujo completo de la aplicación.
Sin embargo, también muestra el patrón de Codex como copiloto, tendiendo a elegir soluciones seguras si no se le fuerza a ampliar el alcance. La integración con una base de datos real como OpenFoodFacts no surgió por inferencia de dominio, sino solo cuando se le indicó de forma explícita. Codex no se equivoca, pero tampoco asume contexto de producto si no se le pide.
MiniMax M2.1 como agente: rapidez, foco y buena inferencia de contexto
Con MiniMax M2.1 el enfoque fue distinto desde el principio. Lo utilicé directamente para replicar FoodCheck.
La diferencia se vio enseguida, ya que en apenas unos minutos fue capaz de:
Hacer una primera lectura visual y lógica del producto original.
Crear la carpeta y los archivos (index.html, styles.css, app.js, README.md).
Desplegar una versión inicial funcional.
Y él solo se corregía sin que yo llegara a ver el error, solo veía el resultado final funcionando.
Base de datos nutricional sin instrucciones explícitas
Un detalle clave es que no tuve que mencionar OpenFoodFacts. El agente lo incluyó por iniciativa propia como fuente de datos nutricionales, demostrando una capacidad de inferencia superior sobre “qué necesita una app de este tipo”.
Del token en el frontend al diseño correcto del sistema
Al integrar LLaVA vía Cloudflare, MiniMax propuso inicialmente que el usuario introdujera su API token en la app. Es una solución rápida, pero muy mala desde el punto de vista de experiencia de usuario.
Cuando se le pidió una alternativa, el agente dio un salto importante: propuso un Cloudflare Worker como proxy para guardar el token de forma segura y mantener el frontend completamente estático.
En la práctica, este fue el punto donde MiniMax mostró más instinto de sistema y mayor capacidad para cerrar una solución completa de producto, no solo de código.
El punto débil de MiniMax: la fidelidad de la interfaz
Sin embargo, esta autonomía que brilló en el backend, fracasó en el frontend. Donde MiniMax M2.1 no consiguió cerrar el objetivo fue en la replicación exacta de la interfaz.
Aunque intentó replicar exactamente el diseño y llegó a desplegar versiones afirmando que lo había conseguido, seguía habiendo diferencias. Y esto conecta con una realidad práctica, y es que “parecido” es fácil, pero “idéntico” es más complejo.
Un agente puede aproximar estilos, pero para clonar una interfaz de forma fiable suele necesitar acceso directo al CSS original, assets y una validación visual metódica (capturas comparativas, inspección de estilos, etc.). Sin eso, se queda en “muy similar” rellenando los huecos de diseño con su propia imaginación.
El tropiezo compartido con el «mínimo viable»
A pesar de sus diferencias, ambas IAs cayeron en la misma trampa al inicio: la detección simulada o simplificada. Pero esto no es un error raro, es un patrón. Se construye el “cascarón” del producto, y luego se conecta el motor real.
Tanto Codex en su momento como MiniMax después propusieron por defecto usar TensorFlow.js + COCO-SSD. El problema es que COCO-SSD detecta tan solo ciertos alimentos concretos, pero no detecta alimentos de un plato de comida normal. Para una app de comida, eso es inútil.
Esto nos enseña una lección, y es que la IA tiende al camino de menor resistencia técnica. Prefiere cerrar el producto visible con una librería estándar antes que buscar la solución compleja (modelos multimodales) que realmente se necesita. Tuve que intervenir en ambos casos para forzar el uso de visión real.
Qué aporta Codex que MiniMax no
La principal fortaleza de Codex no es la velocidad ni la autonomía, sino el control. Cuando el desarrollador tiene claro el diseño, las restricciones y el resultado esperado, Codex se comporta de forma más predecible y menos creativa en el mal sentido. Rara vez inventa arquitectura, fuentes de datos o flujos no solicitados si se le han dado las órdenes correctas.
Esto reduce el riesgo de soluciones elegantes pero incorrectas desde el punto de vista del producto. El coste es que exige más trabajo previo: descomponer el problema, anticipar restricciones y guiar activamente el camino. Codex no suele cerrar el sistema por ti, pero respeta mejor lo que tú defines como correcto.
Qué aporta MiniMax que Codex no
MiniMax M2.1 destaca cuando el problema es abierto y el objetivo es tener algo completo funcionando lo antes posible. Toma la iniciativa para que el código sea una solución de mercado y no una estándar basada en lo que la mayoría de desarrolladores hace. Su capacidad para inferir contexto (como elegir OpenFoodFacts sin indicación explícita o proponer un Worker como proxy seguro) demuestra un mayor instinto de producto y de sistema.
Esta autonomía acelera enormemente las primeras fases, pero introduce un riesgo. El modelo tiende a decidir qué es suficientemente bueno si no se le dan métricas claras. MiniMax no espera a que definas todos los detalles, los asume. Eso lo convierte en un generador de soluciones, pero en un asistente que necesita auditoría constante cuando la fidelidad importa.
Además, MiniMax parece ser mejor detective. Si el código falla, MiniMax suele mirar el error y proponer una solución que arregla el problema actual e incluso problemas futuros que uno aún no ha visto. Codex suele limitarse a arreglar solo lo que le pides.
Conclusión: dos estilos de IA, una misma responsabilidad humana
Este experimento deja una reflexión clara, y es que hoy en día, con IAs, hacer que una app exista es barato. En minutos puedes tener archivos, pantallas, incluso un flujo completo desplegado. Lo complejo empieza cuando tu objetivo no es simplemente que funcione, sino que sea exactamente lo que tú quieres.
Las dos IAs, de maneras distintas, rellenaron huecos. Si no defines con precisión cómo debe ser la arquitectura, proponen una. Si no delimitas qué significa “visión de platos complejos”, te ofrecen el modelo más a mano. Y si no instrumentas la fidelidad visual, te entregan una interfaz “bastante parecida” y la dan por buena.
Por eso, la IA es el motor de aproximación, pero el desarrollador es el sistema de medida. Y medir no es solo pasar tests unitarios. En productos como FoodCheck también significa comprobar que el despliegue cumple restricciones (GitHub Pages, sin backend), validar integración (tokens, CORS, endpoints, “Failed to fetch”), y tener un criterio tangible para lo subjetivo (qué es “idéntico” en una interfaz).
Si hay que destacar alguna diferencia práctica entre ambos modelos, podría decir que con Codex el trabajo humano se concentra al inicio, definiendo bien tareas, restricciones y arquitectura. Con MiniMax, el esfuerzo se desplaza al final revisando decisiones, detectando supuestos incorrectos y validando que tienes realmente lo que querías.
Ninguno elimina el trabajo del desarrollador; simplemente lo mueve de sitio. Elegir uno u otro no es tanto una cuestión de potencia del modelo como de en qué fase prefieres invertir tu atención. Pero en ambos casos, el resultado final depende menos del modelo que de la claridad con la que el desarrollador define qué cuenta como éxito.
En cualquier caso, quizá la enseñanza más interesante de todas es que cuando tienes un asistente que programa rápido, el trabajo se desplaza. Ya no es tanto escribir código, sino definir con precisión qué cuenta como correcto. Porque, si no lo defines tú, lo definirá la IA… y lo hará a su manera.
En este tutorial aprenderás a crear una app web que analiza fotos de comida usando IA con el modelo LLaVA 1.5 de Cloudflare Workers AI. Montarás un frontend estático en GitHub Pages, un Worker sin servidor como backend y conectarás con OpenFoodFacts para obtener los nutrientes.
Descubre paso a paso cómo desarrollé la webapp de Barranquismo que no encontraba, con ChatGPT, Codex e IA.
Código, guía, ejemplos y consejos de este aprendizaje para que tú lo puedas aplicar.
¿Alguna vez has querido crear una wiki y no sabías por dónde empezar? Piensa en ella como un museo temático: eliges la colección (el tema), diseñas el recorrido (la navegación) y curas cada pieza (las páginas de detalle). De la idea al sitio vivo, paso a paso con un ejemplo real basado en el videojuego: Hollow Knight.
La Inteligencia Artificial está transformando la industria alimentaria. Sistemas de visión automática, control predictivo y análisis en tiempo real permiten reducir errores, mejorar la trazabilidad y optimizar cada etapa de la cadena de frío. La fábrica 4.0 ya es una realidad.