El proyecto comenzó con esta pregunta: ¿Será posible mejorar la toma de decisiones en al Industria textil con Machine Learning? Después de decidir que queríamos responder a la incógnita decidimos la industria y como sabemos en Bolivia y encontramos a la industria textilera que hasta el 2015, tuvo una contribución de la industria textil boliviana al Producto Interno Bruto (PIB) era del 0,9%, equivalente a 451 millones de dólares,sin embargo este sector se ve severamente afectado por varios problemas tales como:
Mercadería Ilegal que ingresa al País
Ropa usada
Prendas chinas
Porque vimos estos problemas y creemos que Bolivia puede mejorar su competitividad escogimos al sector de la industria textil para aplicarle Machine Learning.
DESARROLLO
Encontramos el dataset en Kaggle, este tenía las siguientes variables (están traducidas al español al lado):
date – Fecha ()
smv – valor promedio por trabajo
day – Dia (Lun-Dom)
wip – trabajos en cola
quarter – 5 periodos / mes
over time – sobrehora
department – departamento
incentive – incentivo
teamno – # de equipo
idle time – tiempos ociosos
no of workers – # de trabajadores
idleman – # de trabajadores ociosos
no of style change – # de cambios
actual productivity – productividad actual
targeted_productivity – productividad esperada
Nuestro dataset obtenido de Kaggle tenía esas características, después de ver las variables vimos que la variable SMV valor (promedio de trabajo) tenía algunos huecos,por lo que viendo su distribución decidimos rellenarla con la tendencia de la media y así ya obtuvimos todos los datos listos para trabajar.
Comenzamos con la idea de regresión pero los métodos parecían no servir o nos daban unos resultados muy bajos por lo cual tuvimos que cambiar de aproach, después se procedió a un problema de clasificación, realizamos una normalización de los datos y ya con los datos trabajados comenzamos a trabajar,acá un ejemplo de la matriz de correlación que logramos obtener una vez pasamos a la parte de clasificación de datos con datos ya normalizados.
Después se comenzó a probar modelos,el con mejores resultados predictivos fue ADAboost(insertamos imagen referencial)
Logramos un 0.82 de accuracy lo cual fue simplemente increible despues de ver como otros métodos no llegaban ni al 0.50, decidimos probar con varios modelos adicionales como Random Forest, pero la precisión era menor (no por mucho)
Al final nos quedamos con Adaboost y logramos un trabajo excelente.
CONCLUSIONES
Con los modelos de regresión de acuerdo al rendimiento (scores de 0.5) calculado, no se acomodan al dataset propuesto, se realizó un tratamiento al target para volver un problema de clasificación.
Los modelos de clasificación aplicados al dataset dieron resultados favorables en especial Adaboost con un score de 0.82
Los mecanismos y procesos de machine learning permitieron en el problema reutilizar el modelo como uno de clasificación.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Todos sabemos la importancia de las plantas y a muchas personas les gustaría tener plantas en casa, pero existen varios problemas que lo impiden como por ejemplo el tiempo disponible para cuidarlas. El presente proyecto plantea resolver estos problemas por medio del Machine Learning creando un huerto inteligente que reconoce que planta va a cuidar y aplica un protocolo de cuidado adecuado. Las tecnologías usadas son redes neurales convolucionales, visión artificial, python y arduino.
Las plantas son una parte importante de nuestro diario vivir y no nos damos cuenta de su importancia. Las plantas en casa vienen con muchas ventajas como es la reducción de contaminación del aire, la reducción de estrés, y la reducción de la contaminación acústica. Pero, con tantas ventajas ¿porque no´ todos tenemos plantas en casa?
Esto pasa porque existen algunos problemas a la hora de tener plantas en casa. Los tres principales problemas son: La falta de conocimiento, descuido y falta de tiempo. El proyecto consiste en un huerto inteligente para los hogares de personas que quieren tener plantas en casa. El huerto reconocería la planta que va a cuidar por medio de visión artificial y redes neurales convolucionales y aplicaría un protocolo adecuado para la planta. Gracias a esto cualquier persona podrá tener plantas en casa sin tener el tiempo o el conocimiento que esto conlleva.
TECNOLOGÍA USADA
· CNN
· Visión artificial Python
· Arduino
· Dataset propio
El modelo utilizado para la creacion del huerto inteligente aplicando Machine Learning es una red YOLOv5 la cual se modifica para aceptar las clases de nuestro dataset. Por ahora el dataset solo cuenta con siete clases (tipos de plantas) por el tiempo que implica crear un dataset, aun así, se logró un funcionamiento aceptable. El código se realizó en Jypiter y el dataset en la web Roboflow.
FUNCIONAMIENTO
El huerto, por medio de una cámara, recoge la imagen de la planta que se procesa por medio de redes neurales convolucionales y visión artificial para así obtener una predicción de que planta está en el huerto. Después, esa predicción hace que se mande una señal, dependiendo de la planta que se identificó, a un arduino el cual al recibir esta señal selecciona el protocolo de cuidado dependiendo el tipo de planta y así controla los tiempos de regado y la cantidad de agua.
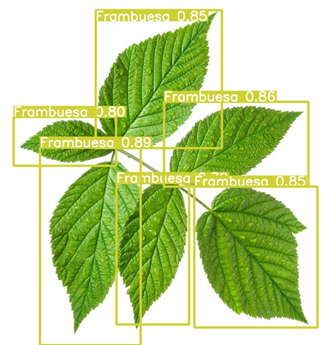
Figura 2. Detección de Frambuesa
OBSERVACIONES
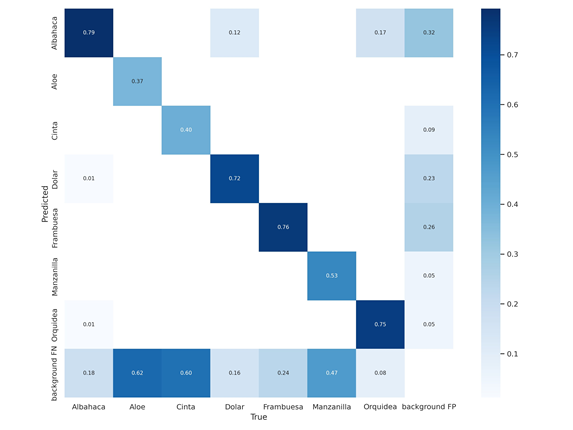
Figura 3. Matriz de confusiónFigura 4. Resultados
Como se puede observar en los resultados, después del entrenamiento, se logró una precisión de 0.52 sin llegar a un overfeating. Esto se debe a la falta de datos en el dataset. También se puede observar que hay una gran confusión entre las plantas de Aloe y Cinta, posiblemente el error se debe al parecido de las hojas y la falta de imágenes en el dataset. Aun así, en las pruebas realizadas en otras plantas como la orquídea y la frambuesa son satisfactorias.
PROXIMOS AVANCES
Actualmente se continua la mejora del dataset para obtener más imágenes y de esta manera el huerto pueda reconocer mayor cantidad de plantas y con mayor precisión. También se está experimentando con diferentes modelos de deep learning para mejorar el funcionamiento del huerto.
Se planea mejorar mucho la estructura para tener un diseño más estético y cómodo para los hogares de personas en el área urbana. Además, se planea mejorar la parte del hardware para minimizar costos de producción y controlar más factores externos como la temperatura y la luz.
Finalmente se espera poder implementar una versión del huerto para cultivos a gran escala.
Presentación del proyecto: DemoDay
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.
Durante la última década, la explosión de la cantidad de datos disponibles, la optimización de algoritmos y la evolución constante de la potencia informática han permitido que la inteligencia artificial (IA) realice cada vez más tareas humanas [1]. Y desde hace un tiempo la inteligencia artificial se ha convertido en una poderosa herramienta para devolvernos al pasado. Lo demuestran la cada vez mayor cantidad de imágenes y videos restaurados a través de diferentes técnicas de inteligencia artificial, como por ejemplo la capacidad de colorear videos en blanco y negro.
En términos de coloración de imágenes y videos la Inteligencia artificial ha evolucionado y durante los últimos años se ha observado una mejora significativa. Ya que la coloración manual requiere una gran cantidad de tiempo y es un proceso costoso, la aplicación de técnicas de inteligencia artificial es una gran opción para este tipo de tareas porque es capaz de trabajar por sí misma y colorear automáticamente en un corto periodo de tiempo [2].
Problemática
Existen pocos registros filmográficos que capturen la vida cotidiana de antaño de nuestro país es por ello que quisimos tener otra perspectiva de estos videos añadiendo color a los pocos que encontramos.
Objetivo
Extraer imágenes de videos antiguos para darles color haciendo uso de una red GAN, para posteriormente generar un video a color.
Dataset
El dataset se pudo obtener a partir de videos encontrados en youtube, de tipo documental y grabaciones de los distintos paisajes de Bolivia, se usaron 10 videos distintos ya que se tienen videos antiguos a color, que tienen un color más opaco, otros videos de los paisajes con un color más definido pero con una calidad no mayor a 480p, y otro con una calidad mayor. No se tomaron todos los frames de estos ya que se optó por usar los frames significativos y asi no tener varios frames de una misma escena.
Selección del modelo y técnicas usadas
La arquitectura usada para colorear mediante Inteligencia Artificial fue la de Unet-GAN por su gran capacidad para sintetizar las características de las imágenes lo que mejora ampliamente los resultados finales.
Una red generativa antagonica (GAN) tiene dos redes. Una es el discriminador que intentará discriminar entre imágenes reales y falsas. Y la segunda red de la GAN es el generador que se encargará de generar imágenes falsas pero muy cercanas a las imágenes originales más bien podemos decir que las imágenes falsas estarán en la misma distribución de las imágenes originales.
UNET se utiliza básicamente en problemas de segmentación de imágenes donde las dimensiones de entrada y salida son las mismas. GAN intenta generar nuevas imágenes a partir de un ruido aleatorio. Entonces, el generador de GAN tiene muy pocas dimensiones en la entrada, pero la salida es en gran dimensión. Puede usar UNET como generador en el GAN (pix2pix usa esto).
En este caso, generará imágenes falsas no a partir de ruido aleatorio sino de otra imagen de referencia. Tiene otras opciones como red deconvolución, codificador automático, etc.
Al inicio se realizó la obtención de videos, se segmentó los videos en frames que se usaron como ground truths, se estandarizó las imágenes a un tamaño y se hizo la conversión de los frames RGB a grayscale para usarlos como inputs. Al finalizar con el proceso de colorización se unió los frames resultantes para convertirlos de nuevo en video.
Análisis de resultados
En la gráfica 1 podemos observar la pérdida del discriminador y la del generador y se puede ver que existe una tendencia exponencial y que la pérdida es estacionaria en el valor 0.4 para el discriminador y 0 para el generador.
Gráfica 1. Pérdida del discriminador y del generador
Se puede apreciar en las imágenes de entrenamiento con 600 épocas que se llega a tener un color correcto, pero no tan intenso como en las imágenes RGB reales, también se puede ver que llega a tener errores cuando se tiene una sección con mayor brillo en la imagen, como ser rayos del sol o secciones de blanco.
Con las imágenes de testeo se puede ver que las imágenes se llegan a colorear pero se sigue teniendo el problema con las secciones de brillo y que tiene una mayor predisposición a la gama de rojos y azules.
En las imagenes del video en blanco y negro elegido para poner a prueba nuestro modelo se tiene una buena coloracion siendo que al ser una grabacion de la ciudad de La Paz-Bolivia se tiene más imagenes de edificios no se necesita tener una gran variedad de colores, el color más intenso que se ve es en el cielo.
Conclusión y recomendaciones
Se logró implementar un modelo con arquitectura Unet-GAN capaz de colorear imágenes en blanco y negro y con el conjunto de las imagenes coloreadas se obtuvo un video a color, todo este proceso nos permitio familiarizarnos con modelos de Inteligencia Artificial del tipo Deep Unsupervised Learning, preparación de datasets, lenguaje Python, librerias especializadas en Deep learning y Colab como herramienta para la implementacion de nuestro modelo. Los resultados son aceptables sin embargo quedan algunas falencias que subsanar como que ciertas imágenes con brillo que forman parte de nuestro dataset de entrenamiento presentan error al momento de ser reproducidas por la GAN, además algunas colorizaciones no son completas, esto debido a que el dataset no contaba con muchas variaciones de color, por lo tanto es recomendable ampliar la paleta de colores con las que se realiza el entrenamiento.project_color.mp4Edit descriptiondrive.google.com
[2] film colorization, colorize video, colorize black and white videos, colorize video software, film colorization software, colorization of film. (n.d.). Retrieved December 4, 2021, from https://pixbim.com/film-colorization
Códigos
Código para la recoleccion del dataset a partir de videos descargados de youtube
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.
La Paz 2021. Las técnicas de Inteligencia Artificial tienen muchas aplicaciones actuales en el campo de las fotografías. Una de ellas tiene que ver con la manipulación de imágenes, campo en el cual se inscribe nuestro proyecto.
En particular, la restauración de imágenes (image restoration) es el proceso de recuperar una imagen a partir de una versión degradada. Image restoration es un caso de estudio que normalmente es tratado con procesamiento de imágenes. Se parte de la idea de que la imagen ha pasado a través de una función de degradación y se le ha añadido ruido; la restauración entonces consistirá en revertir el proceso y recuperar la imagen original.
El propósito de este proceso es “compensar” o “deshacer” aquellos defectos que generaron la degradación de la imagen, obteniendo un estimado de la imagen original.
La degradación puede provenir de diferentes fuentes, como la difuminación de movimiento (motion blur), ruido, desenfoque de la cámara o una combinación de todas éstas. También hablaremos de degradación al referirnos a aquellas fotografías impresas o negativos que sufrieron cualquier tipo de desgaste debido al envejecimiento del papel, polvo, manchas, etc.
De manera tradicional, una vez identificado el tipo de degradación, es posible procesar la imagen con un tratamiento de procesamiento de imágenes. Existen diferentes estudios y especializaciones con respecto a estos procesos, especialmente para revertir el ruido agregado a la función de degradación. Cada caso es único, por lo cual el tiempo de procesamiento puede llegar a ser muy largo. Al mismo tiempo, podemos encontrar estudios de fotografía que ofrecen el servicio de restauración aplicando técnicas de edición digital, lo cual resulta costoso.
Ejemplo de restauración de imágenes
Por otro lado, tenemos los films negativos fotográficos producidos por las cámaras analógicas que son preservados por varios tipos de usuarios, desde historiadores y bibliotecarios hasta quienes simplemente desean conservar recuerdos familiares. Estas películas normalmente deben pasar por un proceso químico (revelado) para la obtención de la fotografía física que describe la escena que fue capturada con la cámara analógica.
Revelado digital de negativo
Existen técnicas de manipulación de la imagen digital de un negativo para obtener la imagen que correspondería a la revelada en el proceso tradicional. Estas técnicas siguen una secuencia de pasos que consisten en ajustar ciertos parámetros de la imagen que van más allá de la inversión de colores, algo que también se debe hacer imagen por imagen.
DESCRIPCIÓN DEL PROBLEMA y OBJETIVO
La selección de la técnica de procesamiento de imágenes que debe aplicarse a la imagen degradada proviene de una apreciación visual y resulta subjetiva. Muchas veces debemos aplicar varias técnicas en cascada para obtener un resultado óptimo. Este proceso consume tiempo, es específico a cada caso que se presente y en la mayoría de los casos no se puede paralelizar.
¿Y si pudiéramos utilizar la inteligencia artificial para crear un solo modelo que sea capaz de restaurar la imagen degradada sin necesidad de categorizar el tipo de degradación, cómo también realizar el revelado de las fotografías a partir de los negativos en film?
Éste es precisamente nuestro objetivo. Utilizaremos técnicas de Inteligencia Artificial para construir un modelo de restauración de fotografías que podrá recuperar la imagen original a partir de las degradaciones descritas y/o a partir de los negativos fotográficos. Para hacer el desafío más interesante incluiremos además imágenes en formato blanco y negro que deberán ser coloreadas; y también imágenes con regiones suprimidas, es decir taparemos regiones de la escena simulando manchas o rasguños que pudieran haber eliminado por completo estas regiones. Por más que existen modelos que hacen ciertas funciones que describimos, una de las dificultades será el de combinar todas estas restauraciones (colorización, revelado, restauración e incluso generación creativa) en un sólo modelo.
SELECCIÓN DE LOS MODELOS
El proyecto presentado está basado en varias librerías de Fast.ai, que proporcionan herramientas de manipulación de fotografías mediante inteligencia artificial, de datasets para entrenamientos e incluso de modelos pre entrenados que son un buen punto de partida. La arquitectura general escogida es la de trabajar con una GAN (Generative Adversarial Network), que es apropiada para resolver nuestra problemática.
La estructura general utilizada consiste en un generador de imágenes, que intenta crear imágenes con la mejor calidad posible, ya sea en el color, la resolución, la textura… Por otra parte se entrena un discriminador que debe distinguir entre las imágenes reales dadas cómo input y las imágenes generadas por el generador. Finalmente se hace un tercer entrenamiento donde se combinan los dos modelos anteriores, lo que crea la GAN: en este proceso ambos modelos compiten y obligan a mejorarse el uno al otro.
Nuestro modelo generador ya viene pre entrenado y consta de dos partes. La primera son las convoluciones que llevan una imagen de input hacia dimensiones cada vez más pequeñas, y la otra parte es cuando se hace el camino inverso para recuperar una nueva imagen de las mismas dimensiones que la que se tiene como input. La arquitectura total es UNET, que tiene como particularidad que cierta información del proceso de reducción de la imagen se le envía directamente a su contraparte (cuando las dimensiones son equivalentes). Este proceso se puede ver en la siguiente imagen.
Unet
De igual manera, las diferentes operaciones y convoluciones utilizadas están basadas en una arquitectura CNN (Convolutional Neural Network) Resnet34 (34 capas de profundidad), que utiliza bloques residuales o de identidad durante las operaciones de convolución. Cuando cargamos este modelo, se puede entrenar solo la parte de la derecha (aproximadamente 20 millones de parámetros) utilizando la opción freeze(), o se puede entrenar el modelo entero (aprox. 40 millones de parámetros) con la opción unfreeze(). En este momento del proceso, y viendo que se utiliza una loss function de Mean Squared Error (MSELossFlat()), el generador solo intenta acercarse lo más posible a los valores de los píxeles de la imagen original. Sin embargo, esto no es suficiente para capturar, por ejemplo, el entorno de los píxeles, en específico ciertas texturas que son muy importantes para obtener una imagen correcta y de buena resolución. Es por eso que se utiliza el generador junto al discriminador en una estructura GAN.
El discriminador (también llamado critic) utiliza una loss function de cross-entropy con logits permitiendo una clasificación binaria (BCEWithLogitsLoss()), que está bien adaptada a su objetivo. Antes de entrenar la GAN, el discriminador se puede entrenar entre imágenes creadas por el generador y los input reales. Sin embargo, lo que más nos interesa es el entrenamiento de la GAN.
En esta etapa, los dos modelos generador y discriminador se entrenan juntos. La idea es utilizar un switcher que decidirá si es momento de entrenar el generador para mejorar las imágenes creadas y confundir al discriminador, o al contrario entrenar el discriminador cuando un cierto umbral de imágenes están siendo clasificadas como reales cuando en realidad son creadas por el generador.
Este proceso se lo puede realizar iterativamente cambiando el tamaño de las imágenes con las cuales va trabajando el modelo, yendo de dimensiones más pequeñas a las más grandes. De esta manera, el modelo va mejorando progresivamente. Esta técnica se utiliza por ejemplo para mejorar la resolución de las imágenes que se le da al modelo de Inteligencia Artificial y mejorar así las fotografías.
PREPARACIÓN Y CONSTRUCCIÓN DEL DATA SET
Es bien sabido que uno de los aspectos más importantes en la construcción de cualquier modelo inteligente son los datos. Es así que pusimos énfasis en la obtención, preparación y construcción de un dataset que nos pudiera proporcionar todo el espectro de degradaciones que requerimos que nuestro modelo sea capaz de reconstruir y que contemos con la cantidad y variedad necesaria.
Trabajamos con el dataset VOC2012 y ColorizationDataSet como datos iniciales (imágenes variadas a color y sin defectos). Decidimos utilizar 9895 imágenes en total. A una mitad se le aplicó un proceso de negativización artificial gracias a un preprocesamiento de imagenes y para la otra mitad se tomó en cuenta las imágenes en blanco y negro. A todas éstas imágenes se le aplicó un segundo procesamiento de imágenes dónde a un 65% se le aplicó algún tipo de degradación como ser compresión jpeg, ruido sal y pimienta, difuminado (blur), entre otros; y a un 25% se aplicó una degradación más importante cómo son unos huecos o manchas en varios sectores de las imágenes. A continuación podemos ver varios ejemplos de este tratamiento.
Imágenes degradadas generadas artificialmente
Para el entrenamiento del modelo, se dividió el dataset en un train set de 8906 imágenes y un test set de 989 imágenes.
EVALUACIÓN DE MODELOS
Para entrenar nuestro modelo, utilizamos la GPU proporcionada por Google Colab. Antes del entrenamiento de la GAN, se puede entrenar el generador y el discriminador con sus respectivas loss function detalladas en el punto 4.
Para el generador, vemos que existe una cierta mejora al avanzar el número de épocas, tanto para el train set como para el test set. Hay que tener en cuenta que esto es sólo una parte del entrenamiento del generado,que en realidad se hará durante el entrenamiento de la GAN.
Curva de Loss function en uno de los entrenamientos del Generador
Para el discriminador, de igual manera se lo puede entrenar solo, y en esta etapa podemos llegar a un accuracy de hasta 95 %, lo que demuestra que antes de entrenar la GAN, le es muy fácil distinguir las imágenes reales de aquellas producidas por el generador.
Durante el entrenamiento de la GAN, se utilizan otras loss function un tanto modificadas tanto para el generador como discriminador. Sin embargo, para evaluar el modelo final, se necesita hacer una verificación visual ya que las loss function de ambos no nos proporcionan información relevante porque ambas funciones irán mejorando y empeorando en función de qué modelo se esté entrenando.
ANÁLISIS DE RESULTADOS
Para el entrenamiento del modelo de Inteligencia Artificial especializado en las fotografías se preparó un conjunto de datos de 9895 imágenes de negativos fotográficos (artificiales) y 9895 imágenes a color, cada uno de los negativos tiene una imagen a color relacionada..
El conjunto de datos se dividió en 2 grupos uno de entrenamiento y otro de validación, bajo el siguiente detalle:
– Train (8906 imágenes)
– Valid (989 imágenes)
Para el entrenamiento se consideraron los siguientes grupos de imágenes:
a) Imágenes en blanco y negro.
b) Imágenes sin degradación.
c) Imágenes con ruido gaussiano.
d) Imágenes con degradación y supresión de regiones
Resultados Train:
– Imágenes en blanco y negro
Imagen: image2669.jpg
De izquierda a derecha: Imagen Original, Imagen degradada blanco y negro, predicción en el entrenamiento
– Imágenes en negativo sin degradación
Imagen: 2007_000039.jpg
De izquierda a derecha: Imagen Original, Imagen en negativo, predicción en el entrenamiento
Podemos ver que el modelo hace un buen trabajo al colorear ciertas imágenes negativas, encontrando el color correcto en la mayoría de los objetos de la imagen.
– Imágenes en negativo con ruido gaussiano.
Imagen: 2007_003118.jpg
De izquierda a derecha: Imagen Original, Imagen en negativo con ruido, predicción en el entrenamiento
La restauración de ruido hacia una mejor resolución no está completamente realizada, incluso para el train set. Podemos concluir que hace falta más tiempo de entrenamiento para continuar con el proceso.
– Imágenes en negativo con regiones suprimidas
Imagen: 2007_000033.jpg
De izquierda a derecha: Imagen Original, Imagen en negativo con supresión de regiones, predicción en el entrenamiento
Imagen: 2007_000027.jpg
De izquierda a derecha: Imagen Original, Imagen en negativo con supresión de regiones, predicción en el entrenamiento
Para las imágenes degradadas con partes enteras faltantes, el modelo reconoce el color que le debe dar a la zona oscura. Por el momento, la resolución es mala, pero con más entrenamiento, esto puede ir mejorando.
Resultados Test Set:
– Imágenes en blanco y negro.
Imagen: image0476.jpg
De izquierda a derecha: Imagen Original, Imagen degradada blanco y negro, predicción en el testing
– Imágenes en negativo sin degradación.
Imagen: image1027.jpg
De izquierda a derecha: Imagen Original, Imagen en negativo, predicción en el testing
– Imágenes con ruido gaussiano.
Imagen: image0850.jpg
De izquierda a derecha: Imagen Original, Imagen con ruido, predicción en el testing
– Imágenes con Degradación
Imagen: image4988.jpg
De izquierda a derecha: Imagen Original, Imagen en negativo con supresión de regiones, predicción en el entrenamiento
Resultados de imágenes que no forman parte del dataset:
A continuación presentamos resultados de predicción del modelo en imágenes completamente nuevas que no se utilizaron durante el entrenamiento. Podemos observar que dependiendo la imagen en blanco y negro, la colorización se hace de manera aceptable en algunas pero casi nada en otras. De igual manera en la segunda imagen se observa que la imagen del resultado ha mejorado la calidad de la imagen en cuanto al ruido que presenta la original. En cuanto a la imágenes en negativo, el modelo hace un buen trabajo en detectar los objetos de la imagen y colorearlos acorde a lo detectado.
CONCLUSIÓN
Este proyecto de Deep Learning nos permitió familiarizarnos con ciertas técnicas de manipulación de imágenes, código en Python, librerías especializadas en Deep Learning así como técnicas de entrenamientos de modelos en ciencia de datos, usando la Inteligencia Artificial aplicándola a las fotografías. Los resultados son aceptables considerando las limitaciones en tiempo de entrenamiento así como en GPU que se tuvieron. Vimos que el modelo puede trabajar tanto con negativos fotográficos como con fotografías antiguas en blanco y negro que pudieran presentar degradaciones leves o fuertes. Sin embargo, queda mucho margen de mejora como por ejemplo vimos que algunas restauraciones de negativos tienen un tinte azul de fondo, probablemente debido al hecho de haber utilizado negativos solo creados artificialmente y no “reales”. Estos negativos pueden presentar diferentes calidades químicas, de material… que pueden variar por modelo o marca. De igual manera es probable que utilizar imágenes degradadas reales aumente el poder del modelo.
Ziyu Wan, Bo Zhang, Dongdong Chen, Pan Zhang, Dong Chen, Jing Liao, and Fang Wen. Old photo restoration via deep latent space translation. arXiv preprint arXiv:2009.07047, 2020.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
En este artículo, veremos cómo llevar a cabo la detección de terrenos con Inteligencia Artificial con el objetivo identificar los terrenos (lotes) disponibles para producción (en renovación). De esta manera pretendemos mejorar los costes y la eficiencia que se asocian a su detección y explotación.
Entendemos por loteo de terrenos el proceso de división del suelo, cualquiera sea el número de predios resultantes, cuyo proyecto contempla la apertura de nuevas vías públicas, y su correspondiente urbanización. No obstante, analizaremos los terrenos de cara a su producción agrícola.
Los datos son extraídos de la base de datos geográficos de monitoreo de producción de los cañeros de la zona norte de Santa Cruz. Todo esto se maneja en un CATASTRO.
Esta información geográfica tiene relaciona información tabulada:
Entonces se puede tener una visualización del estado de los lotes, si están en producción (con cobertura) o en renovación (sin cobertura) a través de los polígonos que limitan los lotes y las imágenes satelitales.
Son estas imágenes en diferentes épocas del año las que permiten analizar visualmente si los lotes están en renovación o no.
Descripción del problema:
La determinación de si un lote está o no en renovación es importante ya que es una variable a la hora de calcular la producción y rendimiento de las propiedades de cada cañero, y para ello se presentan los siguientes inconvenientes:
Las inspecciones de campo y a través de imágenes satelitales son morosas.
Susceptible a errores.
Demasiado tiempo invertido.
Objetivo:
Determinar si un lote de cultivo de caña está en renovación a través del cambio de cobertura a partir de los datos estadísticos de NDVI de los últimos 12 meses con Machine Learning.
Propuesta de solución.
Las imágenes satelitales pueden ser procesadas para obtener ciertos índices. El índice de interés para observar si un lote está en renovación se llama NDVI (Normalized Difference Vegetation Index):
Se puede observar los lotes con cobertura en color verde, y los que están sin cobertura en rojo, esto de los colores es solo simbología. Lo que en verdad se tiene con el NDVI es una matriz de píxeles:
Cada pixel tiene valores entre -1 y 1; siendo -1 suelos completamente descubiertos, y 1 suelos con cobertura vegetal.
Entonces, se puede obtener la estadística descriptiva de cada lote, y a través de su media y desviación estándar determinar si un lote está en renovación o no.
Como se puede apreciar, lotes con cobertura tiene una media cercana a 1 y una desviación estándar baja, y los que están sin cobertura una media cercana a 0 y también una desviación estándar baja, la desviación estándar es importante ya que determina que las uniforme son los valores de los píxeles en cada lote.
Ingeniería de características.
Se identificó como target el campo Variedad el cual se almacena la variedad sembrada en ese lote, pero si el lote está en renovación, tiene la etiqueta “Renovación”, también cambiamos de nombre de la columna a Renovación.
Convertimos el campo Renovación de categórico a booleano.
Unimos los 13 dataset (1 de catastro y 12 de los valores estadísticos del último año) en uno solo dataset para mejor uso.
Visualización de Datos
Cantidad de registros por Renovación.
Cantidad de registros por gestión.
Cantidad de registros por hectareaje.
Matriz de correlación.
Visualización del balanceo del target.
Reducción de dimensiones a través de PCA.
Se realizó la reducción de dimensiones a través de PCA a dos componentes principales, y se puede apreciar una diferencia entre los registros:
Entrenamiento de modelos
Se probaron tres tipos de modelos, también se implementó Cross Validation. Los resultados fueron los siguientes:
Regresión Logística
Random Forest
SVM
Elección del mejor modelo
En base a los resultados obtenidos, elegiremos ahora el modelo de Inteligencia Artificial más adecuado para la detección de terrenos en renovación:
Se observa que los 3 modelos seleccionados se aproximan a la misma probabilidad 0.93, sin embargo, SVM tiene un mejor score.
También se decidió aplicar la Curva de ROC, y dio el dio el siguiente resultando:
En este caso Random Forest es quien presenta mayor área bajo la curva, por lo tanto, SVM y Random Forest son los mejores modelos a considerar para la clasificación de lotes en renovación.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
En este artículo, utilizaremos técnicas de Machine Learning para optimizar la compactación del suelo.
El suelo es un material compuesto por una parte sólida, líquida y gaseosa, que se formó durante cientos de millones de años de meteorización y sedimentación. Entendemos por compactación el eliminar la mayor cantidad de masa gaseosa (comúnmente aire) del suelo mediante carga.
La curva de compactación consiste en una curva que se construye después de marcar los puntos pares de densidad seca y la humedad de la muestra. Con un mínimo de 5 puntos se traza a mano una curva que pueda correlacionar todos estos puntos y se obtienen la densidad seca máxima y la humedad óptima a la que se puede compactar este suelo.
Estos parámetros son linealmente independientes y no existe una relación entre el ensayo de compactación y la clasificación de suelos, por lo que se realizan dos ensayos diferentes para la obtención del mismo.
Descripción del problema
Para cada kilómetro de carretera se requieren 5 pozos de ensayo de los cuales es requisito presentar dos ensayos:
Clasificación de suelos
Compactación
En la práctica, debido a los recursos económicos y la logística que representa solo se realizan 5 ensayos de clasificación y 2 de compactación y los resultados se interpolan.
Objetivo
Determinar usando técnicas de Machine Learning una correlación entre la clasificación de suelos y la compactación de suelos, refiriéndose al valor de densidad seca máxima y humedad óptima, para calcular la humedad a la que se compactará un determinado tramo de carretera.
Selección del modelo
Debido a que se conoce el resultado y el problema es numérico, los modelos que se usaron fueron:
Regresión lineal
Regresión multi-lineal
Regresión polinómica
Técnicas implementadas
Reducción de dimensiones
Se redujeron todas las columnas que no aportan una información relevante: ‘Pozo’, ‘Lado’, ‘Prf o (m)’, ‘Prf f (m)’, ‘% Hum’, ‘ST >3’, ‘3’, ‘AASTHO’, ‘#’, ‘SUCS’, ‘100%’, ‘97%’, ‘95%’, ‘100%.1’, ‘97%.1’, ‘95%.1’
Valores faltantes
En la columna de LL se encontró que faltaban 30 datos, se utilizó un histograma y se determinó que la curva normal que describe a sus datos estaba desfasada del medio, por lo que se rellenó los datos faltantes con la mediana, que es 32.2
Gráficas
Se realizaron todas las gráficas necesarias para entender e interpretar el problema.
Relación lineal (con sklearn)
Relación polinómica de 2do grado (con numpy)
Relación polinómica de 3er grado (con numpy)
Relación multi-lineal (con sklearn)
Relación multi-lineal (con sns) donde se relacionan los 14 parámetros entre sí y su relación con la Humedad óptima.
Evaluación del modelo
D max vs H opt
Regresión lineal:
Regresión polinómica de 2do grado:
Regresión polinómica de 3er grado:
Feature vs H opt
Regresión lineal:
Análisis de resultados
D max vs H opt
Se puede observar que es la regresión polinómica la que tiene un coeficiente de correlación más cercano a 1 y en gráfica la que mejor se ajusta por lo que será la regresión adoptada
Feature vs H opt
Se puede observar un valor de coeficiente de correlación cercano a 1 y en las gráficas de sns la gran mayoría son relaciones lineales por lo que se acepta el modelo multi-lineal conseguido.
Conclusión
Se determinó una correlación entre la clasificación de suelos y la compactación de suelos, para calcular la humedad a la que se compactará un determinado tramo de carretera:
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Aplicamos Machine Learning (un tipo de red neuronal recurrente (RNN) llamado LSTM (Long short-term memory)) para realizar una predicción de fallas en motores y ayudar así a reducir uno de los mayores problemas a nivel industrial, como es el mantenimiento correctivo (debido a sus elevados costes tanto de reparación como de producción). Por otra parte el mantenimiento preventivo está planificado por medio de una agenda para realizar un paro programado, donde no interesa si el equipo aún puede trabajar o si sus piezas siguen bien; se realiza el mantenimiento porque así fue programado.
Es por ello que, con el pasar de los años la tecnología permite que podamos invertir en nuevas soluciones que nos permita saber cuándo fallará un equipo, esto es llamado mantenimiento predictivo (PdM). Que actualmente, por medio de diferentes sensores podemos tener un dataset completo de muchas variables, como ser: vibración, temperatura, análisis de aceites o grasas, etc.
Fig. 1. Diferencia de ganancia por producción entre el mantenimiento preventivo tradicional y el mantenimiento predictivo, donde solamente se detiene la producción basado en condiciones.
DESCRIPCIÓN DEL PROBLEMA
El problema es el tiempo y los recursos económicos invertidos para poder solventar una falla de mantenimiento correctivo en el menor tiempo posible. A la vez que un mantenimiento preventivo podría optimizarse al hacerlo en base a condiciones de los equipos. Ambos ocupan tiempo en su mantenimiento y también en la producción del producto.
DATASET
Los datasets utilizados, son de la degradación de motores de turbo-ventiladores de la NASA generados por C-MAPSS, lo cual es aplicable a cualquier otra máquina rotativa, como ser: motores de transportes industriales, bombas hidraulicas, etc.
Fig. 2. Imagen del turboventilador simulado por C-MAPSS.Tabla 1. Detalle de las columnas de los datasets de prueba y entrenamiento.
SOLUCIÓN PROPUESTA
Por tal motivo el proyecto ayudará a estimar el tiempo en el cual unos turboventiladores llegarán a fallar. Dando el tiempo suficiente para poder programar una parada de mantenimiento y buscar los repuestos necesarios al mejor precio.
SELECCIÓN DEL MODELO
Para la detección de fallas en motores veremos los siguientes modelos de Machine Learning:
RNN
Son un tipo de red neuronal recurrente (RNN) y estas tienen conexiones recurrentes entre estados ocultos, con un retraso de tiempo. Idealmente, las RNN son capaces de descubrir correlaciones temporales entre los eventos secuenciales que están muy lejos unos de otros
Fig. 3. Arquitectura de una Red neuronal recurrente (RNN)Fig. 4. Arquitectura de una Long Short-Term Memory (LSTM)
LSTM
Sin embargo, en la práctica, es difícil entrenar RNN debido al Vanishing Gradient y los problemas de Exploding Gradient. Por lo que las RNN se enfrentan a dificultades para manejar dependencias en secuencias de largo plazo. Por lo que, el modelo basado en RNN más efectivo se llama LSTM. De manera resumida, su estructura consiste en celdas de memoria. La cual su principal función es la de almacenar un valor y determinar el tiempo que debe almacenarse. Además, estas celdas seleccionan qué entradas se almacenan y también deciden si estas serán recordadas, eliminadas o si serán enviadas como salida de una red.
Fig. 5. Programación de la RNN con LSTM
La red tiene dos capas de LSTM, la primera de 100 unidades y la segunda de 50 unidades. A la salida de cada una se tiene un DropOut para evitar el overfitting, y finalmente se tiene la Dense, que es activada por una sigmoid, que nos da la probabilidad final.
PCA
El análisis de componentes principales (PCA) es uno de los algoritmos de machine learning no supervisados más utilizados. Para la reducción de dimensiones y el pre procesamiento de datos.
Fig. 6. PCA aplicado a tres dimensiones para poder graficarlo.Fig. 7. Datos del dataset completo, con los 21 sensores, y las 3 configuraciones de los usuarios.Fig. 7. Datos del dataset con PCA aplicado. Se reducen a 8 componentes principales.
MÉTRICAS
A continuación se observarán las métricas analizadas. Donde podemos observar que el accuracy es del 95.11%, y que las F1-Score son muy buenas, la que menor valor tiene es la macro. Además que comparando los datos predecidos con los de prueba, tenemos un accuracy del 97%.
Los resultados que analizamos son la matriz de confusión, que nos muestra que su accuracy es del 92.77%, y por otra parte la ROC Curve, donde podemos observar un buen umbral de discriminación del modelo.
Fig. 9. Matriz de ConfusiónFig. 10. ROC CURVE
RESULTADO
Por ende, podemos predecir la probabilidad con la que llegaría a fallar el motor del turbo ventilador en 30 días. Escogiendo el ID de la máquina, tendríamos el siguiente resultado; donde podemos ver que la probabilidad en la que el Motor 16 falle, es del 1.8%, por lo que podemos seguir usando este motor de manera tranquila.
Lo ideal es que este análisis se lo haga de manera periódica, al ser implementado. Debido a que da un buen sondeo del estado de las máquinas a los supervisores de mantenimiento para ir planificando lo más crítico en la siguiente parada.
Fig. 11. Pantalla final, donde el programa nos dice la probabilidad que tiene el motor seleccionado de fallar dentro de 30 días.
CONCLUSIÓN
Por medio de esta aplicación de Machine Learning podemos determinar el tiempo de fallas en motores rotativos, gracias al análisis de datos de dicho equipo. Por ende, se tiene el tiempo suficiente para comprar repuestos y planificar un mantenimiento programado, mitigando los costes de mantenimiento de la empresa.
La precisión del modelo implementado es del 95%, por lo que llega a ser fiable a la hora de analizar las máquinas. Este programa puede ser implementado en multiples plantas industriales, y por medio de Internet Of Things, podemos ir recabando información de todos los sensores necesarios, los cuales serán registrados en la nube para su posterior análisis.
Implementando este tipo de tecnología también llega a repercutir en el area medio ambiental, ya que se cambiarían menos repuestos industrial o maximizar el uso de aceites o grasas de acuerdo a su degradación; se traduce en menos basura industrial para el medio ambiente.
[1] D. Bruneo and F. De Vita, “On the use of LSTM networks for predictive maintenance in smart industries,” in Proceedings — 2019 IEEE International Conference on Smart Computing, SMARTCOMP 2019, 2019, pp. 241–248, doi: 10.1109/SMARTCOMP.2019.00059.
[2] S. Guldamlasioglu, O. Aydin, and D. Scientist, “Using LSTM networks to predict engine condition on large scale data processing framework,” 2017, doi: 10.1109/ICEEE2.2017.7935834.
[3] L. Swanson, “Linking maintenance strategies to performance,” Int. J. Prod. Econ., vol. 70, no. 3, pp. 237–244, Apr. 2001, doi: 10.1016/S0925–5273(00)00067–0
[4] A. Martínez, “Redes Neuronales Recurrentes con LSTM aplicado al Mantenimiento Predictivo, Caso: Degradación de motores de turboventiladores”, 2020, Universidad Católica Boliviana “San Pablo”.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!