De la navegación segura al miedo a perderlo.
Cuando tus hijos navegan en internet, ¿aplicas o configuras algún filtro de control parental?

Latam online. Segunda Edición. 2021
En la actualidad, el hostigamiento u acoso sexual online es conocido en el lenguaje anglosajón como grooming online; donde un adulto logra tener contacto a través de un medio tecnológico contra un menor de edad, siendo el objetivo del abusador atacar a través de interacciones como: acoso a su moral, hablar de sexo, conseguir material íntimo o acordar un encuentro sexual.
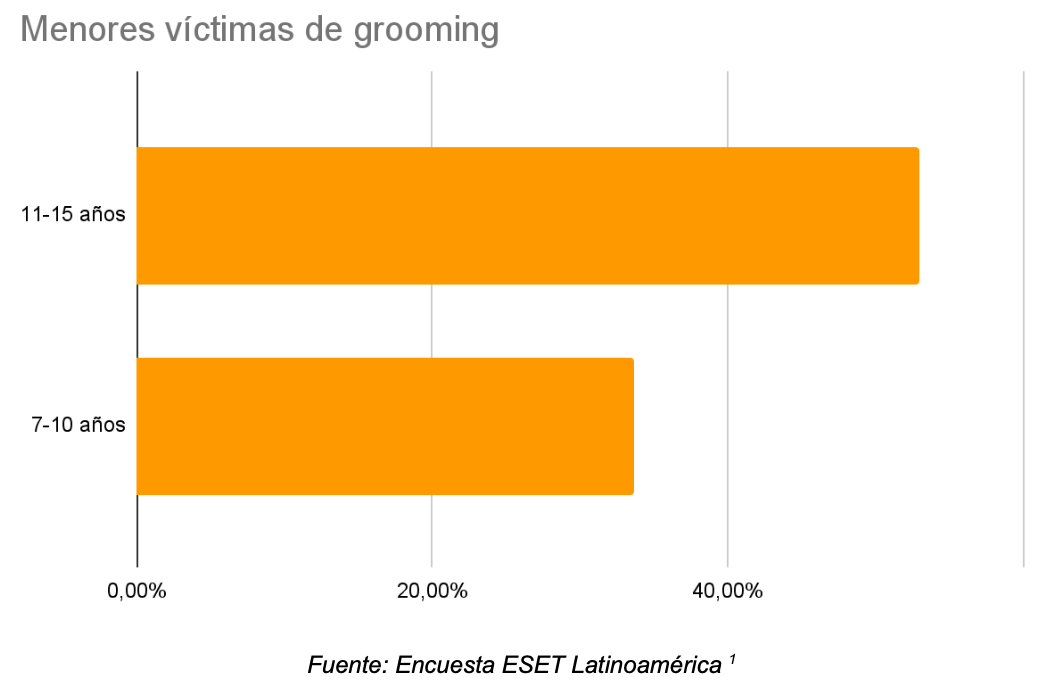
El grooming online se ha incrementado a raíz del confinamiento por el COVID-19. En Argentina aumentó más del 30% en el 2020(2), en datos del INEGI del 2019 arrojan que en México creció el 27%(3) , mientras que el diario ABC de España, reportó un incremento del 410% en los últimos años (4).
Contexto… please!
Los aplicativos actuales para el control parental recurren a bloqueos de aplicaciones, algunos sitios inapropiados, evitar compras online o el acceso de algún virus a los dispositivos como celulares, tablets o computadoras de niños y adolescentes. Sin embargo ninguno analiza conversaciones en redes sociales y tampoco clasifica las que puedan ser catalogadas como peligrosas.
Derivado del confinamiento por el COVID-19 los niños y adolescentes se han visto más vulnerables debido a la necesidad de utilizar los dispositivos móviles como parte de sus actividades diarias, gran parte de eso fue para tomar clases virtuales, realizar tareas y en otras ocasiones como medio de entretenimiento y comunicación, al verse limitados por no poder salir y compartir tiempo con familiares y amigos.
La nula supervisión ha permitido que menores de edad hayan experimentado situaciones indeseadas sin el conocimiento de los adultos.
De acuerdo al sitio salud con lupa, el 39% de los acosos se han experimentado por Facebook, seguida por el 23% en Instagram y un 14% por WhatsApp (5).
La propuesta

Tótem significa protector
Tótem = “Déjalo Navegar sin Preocupaciones”
Sin tanto rollo, esto es lo que hicimos.
Actualmente contamos con un dataset de conversaciones en inglés, las cuales son analizadas y catalogadas como normales o peligrosas, una vez obtenido esté resultado se enviará una notificación al padre o tutor si se detecta una conversación inapropiada.
¡¿Cómo hicieron eso?!
Aquí te explicamos qué fue lo que aplicamos para obtener los resultados que te mostraremos más adelante…
Fase 1 (Aquí vamos…)
Obtención de los datos
Los datos fueron adquiridos del proyecto PAN Lab 20126. La carpeta con los datos fue solicitada y se nos concedió el permiso para usarla. Revisando la data nos encontramos con conversaciones de diversa duración, en las que los participantes tenían diferentes formas de escribir y el archivo del corpus que tenía un formato .xml. Por lo que se procedió con la conversión de la data a un formato .csv, “Comma Separated Values”, para poder proceder con la siguiente fase.
Fase 2 (Analicemos esto…)
Limpieza de datos
La segunda tarea presentó un grado de dificultad alto, debido al ruido de la data. Por lo tanto se siguieron los siguientes pasos.
- Se eliminó cualquier tipo de puntuación.
- Se convirtieron los números a palabras usando la librería num2words.
- Se buscaron abreviaturas y textos con jergas cibernéticas como: “u” para “you”, “ur” para “your”, “what ‘s” para “what is”, entre otras. Además se creó un diccionario con estas palabras nuevas.
- Se eliminaron las stopwords como: the, and, that, a, any, an, be, with. Entre otras.
- Se eliminaron emojis, URL, hashtags y cualquier tipo de valor alfanumérico.
- Se empleó la técnica de lematización, para llevar todos los verbos a su forma en infinitivo. Para así crear incrustaciones a partir de palabras más simples.
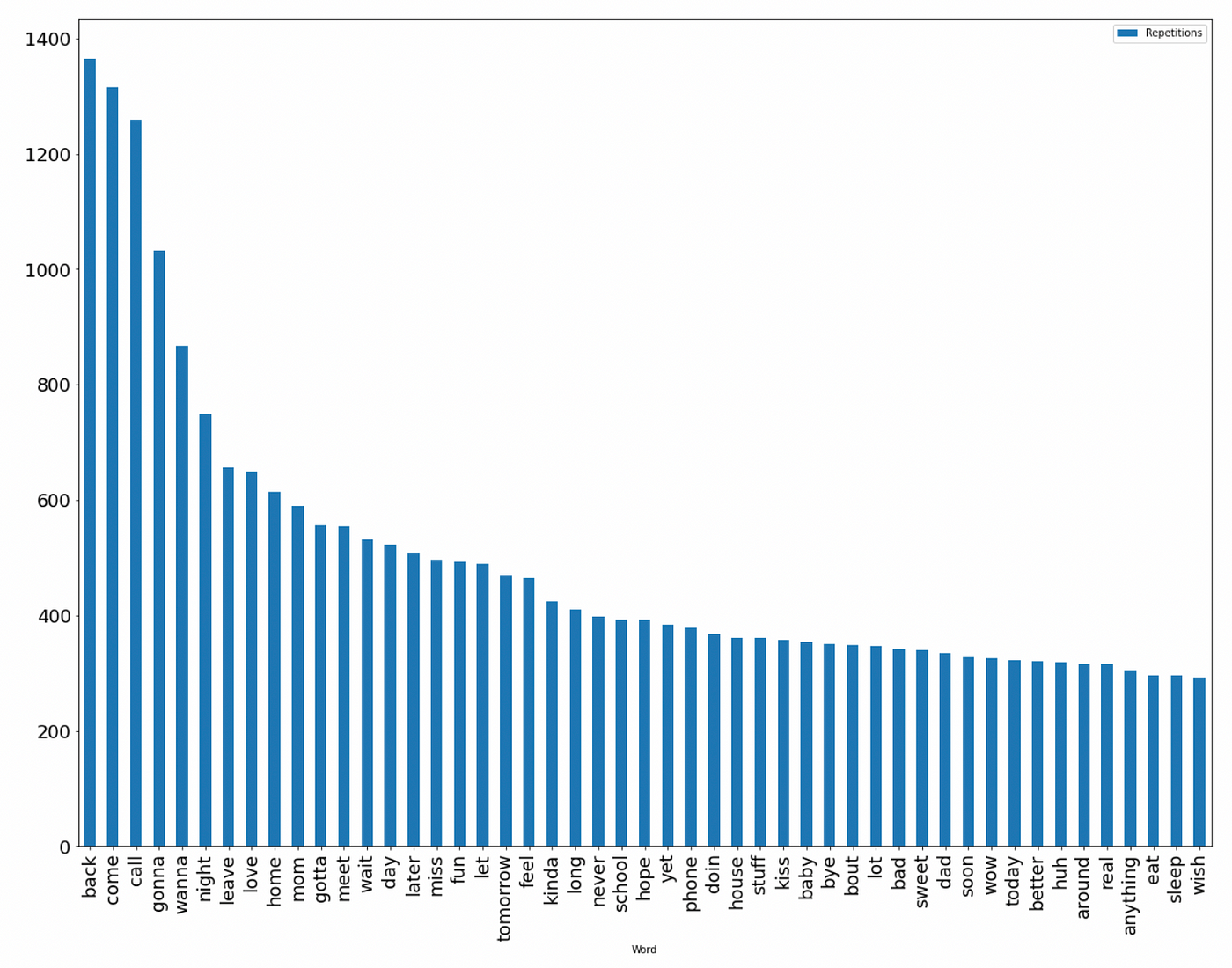
- Se exploraron los datos, analizando las 100 palabras más comunes en las conversaciones de los predadores.
Fase 3 (Entrenemos esto…)
Vectorización
La extracción de características representó un desafío particular, en primera instancia se optó realizarlo con base a las palabras más frecuentes presentes en las conversaciones de depredadores; no obstante, varias de estas eran de uso común, por lo que fue necesario analizar alternativas para lograr un óptimo desempeño. Es así que se optó por el uso del método TF-IDF (Term Frequency — Inverse Document Frequency), siendo una de sus características el resaltar la importancia de una palabra en un conjunto de documentos (corpus). En ese sentido, para transformar la secuencia de palabras (provenientes de las conversaciones) a vectores de características con representaciones numéricas se usó el vectorizador TF-IDF (TfidfVectorizer) de la librería de scikit-learn. Este transformador permitió generar una matriz de características, con una representación adecuada para realizar el entrenamiento del modelo. Para dicho propósito, se dividió el dataset en:
- Datos de entrenamiento: 80%
- Datos de testeo: 20%
Entrenamiento
Para el entrenamiento del modelo se usó la librería scikit-learn y se escogió el modelo Support Vector Machines (SVM) para emplear un clasificador binario.
Los hiper parámetros fueron:
- Parámetro de regularización ©: 10
- Kernel: RBF
- Coeficiente de kernel (gamma): Scale
Evaluación
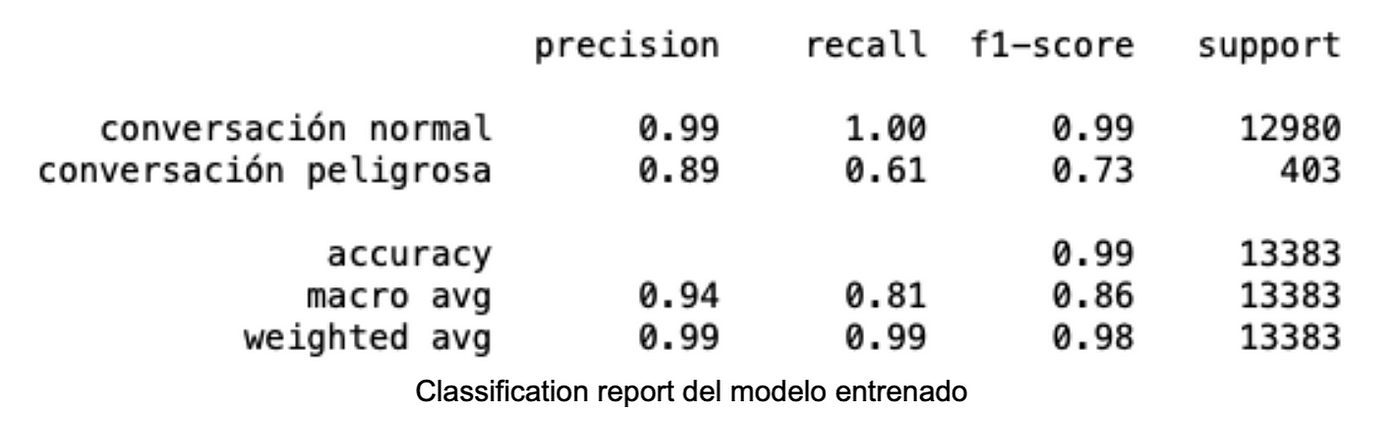
Durante la evaluación del modelo se obtuvieron los siguientes resultados:
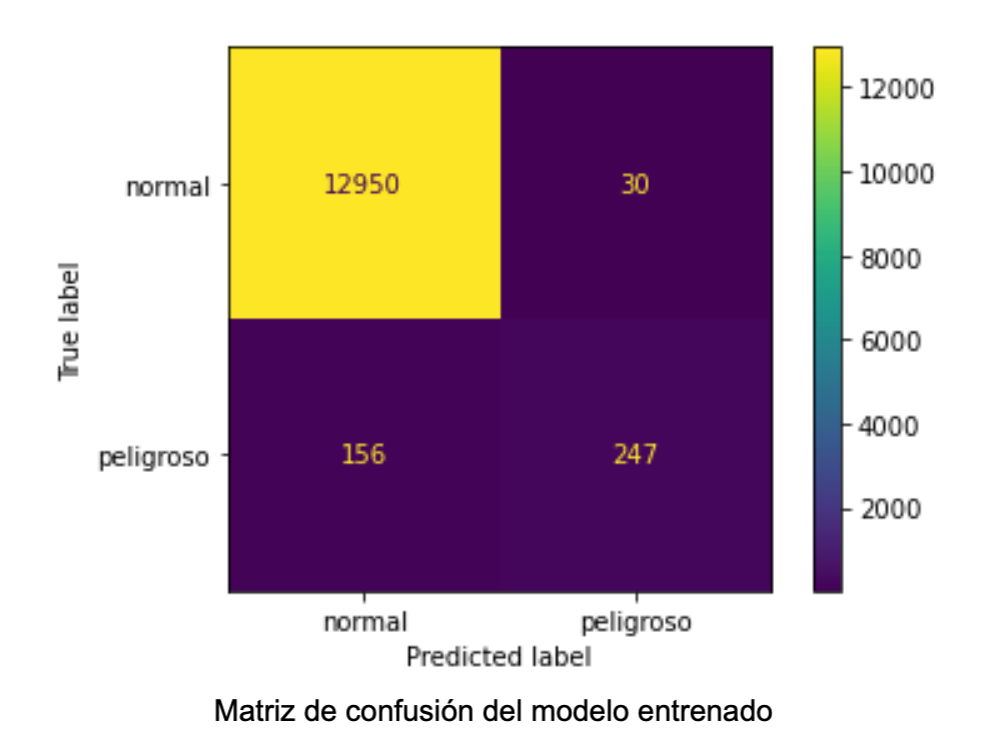
Siendo la matriz de confusión la siguiente:
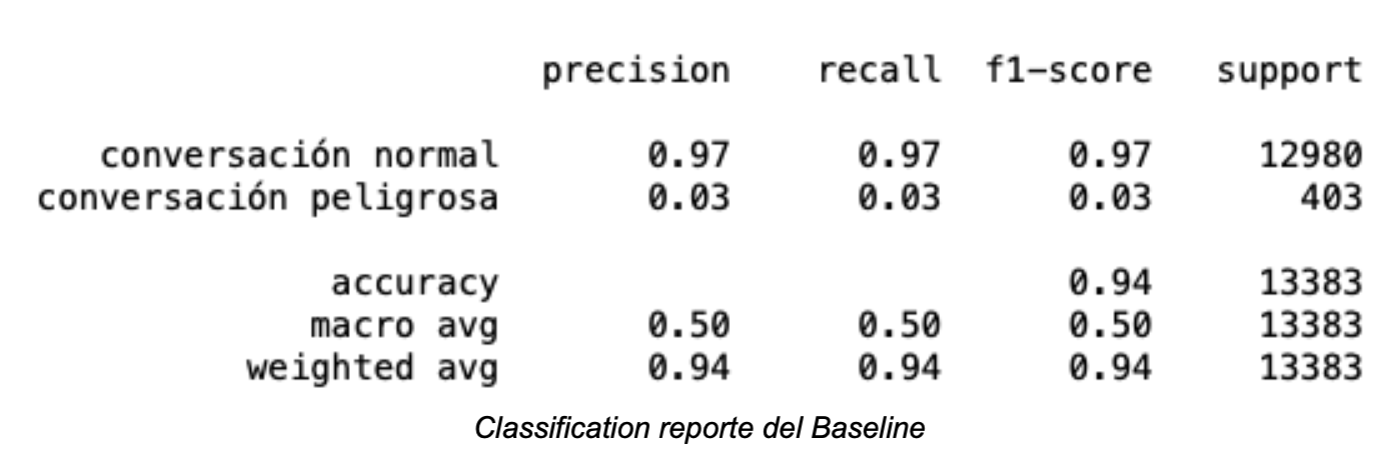
Los resultados del modelo muestran una notable mejora en comparación a aquellos correspondientes al Baseline:
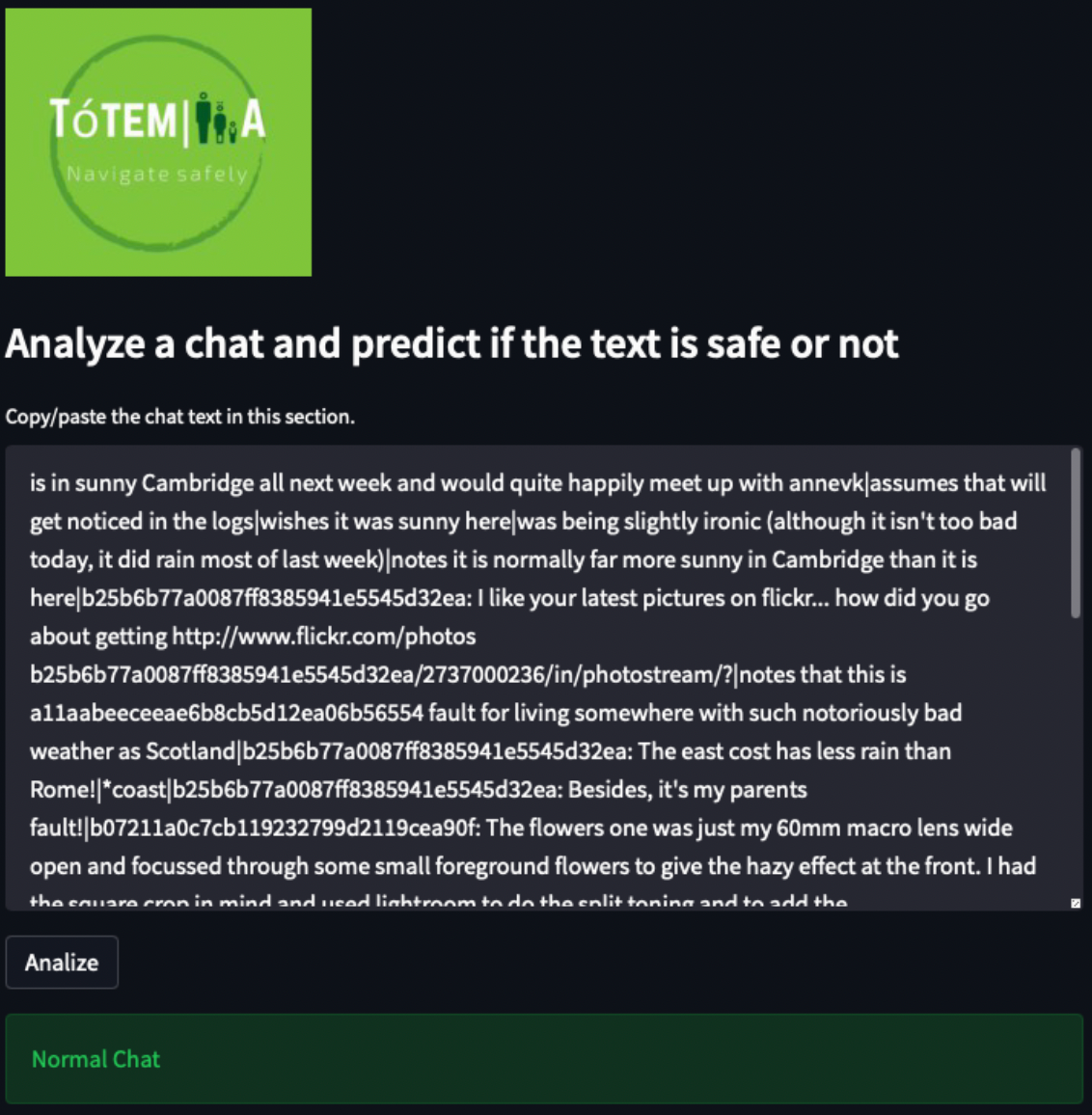
El modelo desarrollado se desplegó en una aplicación web haciendo uso de la herramienta Streamlit, en la cual a través de la interfaz se proporciona la conversación a ser analizada y la aplicación muestra la alerta si es una aplicación normal o peligrosa, a continuación se observa algunos ejemplos del funcionamiento:

¿Te hace sentido nuestra propuesta?
Hasta ahora hemos podido analizar y clasificar conversaciones inapropiadas que se pueden reportar y de está forma proporcionar herramientas a los padres para el monitoreo de aplicaciones cuya función no es interferir con la privacidad sino prever situaciones peligrosas en conversaciones online.
En el futuro, sería genial desarrollar estas alertas al alcance de padres de familia como parte de las restricciones de algunas aplicaciones, que se preocupan por aplicar reglas de control parental para los usuarios vulnerables que hacen uso de sus servicios, tales como: https://www.facebook.com, https://www.instagram.com, https://www.tiktok.com, https://www.whatsapp.com, etc.
Referencias
- http://www.eset-la.com/micrositios/proteccion-infantil/descargar/grooming_chicos_eset.pdf
- https://www.unidiversidad.com.ar/por-la-hiperconectividad-en-cuarentena-el-grooming-aumento-un-30-en-argentina
- https://alumbramx.org/ciberacoso-y-grooming-contra-ninas-ninos-y-adolescentes-en-aumento-por-covid-19/
- https://www.abc.es/familia/padres-hijos/abci-grooming-y-aumentado-410-por-ciento-ultimos-anos-201903081632_noticia.html?ref=https%3A%2F%2Fwww.google.com%2F
- https://saludconlupa.com/la-vida-de-nosotras/ninas-y-mujeres-hablan-del-acoso-en-linea/
- http://pan.webis.de
- https://www.welivesecurity.com/la-es/2020/05/20/grooming-crece-durante-cuarentena/
Aquí puedes ver un video que describe nuestra propuesta
Integrantes
- Aarón Arguello
- Edson Segales
- Ingrid Velecela
- Karla Avilés
- Viridiana Vergara
Presentación del proyecto: DemoDay
Repositorio
Y si quieres ver la fuente de datos y el código que aplicamos, lo puedes encontrar en GitHub:
https://github.com/SaturdaysAI/Projects/tree/master/LATAM_remote/TotemIA
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!