Latam online. Primera Edición. 2020
¿Cómo adelantarnos al enemigo invisible?
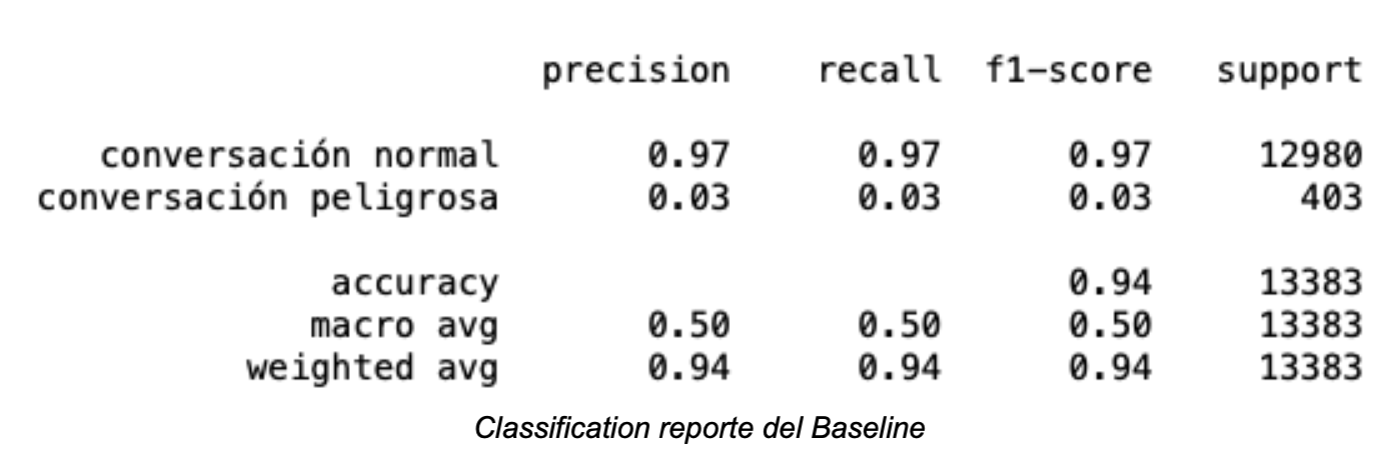
Según la Organización Mundial de la Salud, la contaminación del aire representa uno de los mayores riesgos para la salud, mostrando una relación directa con la carga de morbilidad derivada de accidentes cerebrovasculares, diferentes cánceres de pulmón y neumopatías crónicas e incluso agudas, entre ellas el asma.
Existen estudios que confirman que alinearse a las directrices recomendadas por la OMS derivan en un impacto de hasta 22 meses más en el aumento de la esperanza de vida en la población (WHO, 2016).
Radiografía del aire
En 2016, el 91% de la población vivía en lugares donde no se respetaban las Directrices de la OMS sobre la calidad del aire. Según estimaciones de 2016, la contaminación atmosférica en las ciudades y zonas rurales provoca cada año 4.2 millones de defunciones prematuras. Un 91% de esas defunciones prematuras se producen en países de bajos y medianos ingresos, y las mayores tasas de morbilidad se registran en las regiones del Sudeste de Asia y el Pacífico Occidental.
En los países de bajos y medianos ingresos, la exposición a contaminantes en el interior y alrededor de las viviendas como consecuencia del uso de combustibles en estufas abiertas o cocinas tradicionales incrementa el riesgo de infecciones agudas de las vías respiratorias inferiores, así como el riesgo de cardiopatías, neumopatía obstructiva crónica y cáncer de pulmón en los adultos.
Existen graves riesgos sanitarios no solo por exposición a las partículas (PM10 y PM2.5, es decir, partículas menores que 10 y 2.5 micrómetros respectivamente), sino también al ozono (O3), el dióxido de nitrógeno (NO2) y el dióxido de azufre (SO2). Como en el caso de las partículas, las concentraciones más elevadas suelen encontrarse en las zonas urbanas. El ozono es un importante factor de mortalidad y morbilidad por asma, mientras que el dióxido de nitrógeno y el dióxido de azufre pueden tener influencia en el asma, los síntomas bronquiales, las alveolitis y la insuficiencia respiratoria.
Las industrias, los hogares, los automóviles y los camiones emiten mezclas complejas de contaminantes atmosféricos, muchos de los cuales son perjudiciales para la salud. De todos estos contaminantes, el material particulado fino tiene el mayor efecto sobre la salud humana. La mayor parte del material particulado fino proviene de la quema de combustible, tanto de fuentes móviles como vehículos, como de fuentes estacionarias como centrales eléctricas, industria, hogares o quema de biomasa.
Y esto… ¿cómo se mide?
La calidad del aire se mide a partir de las concetraciones de los contaminantes que están presentes en la atmósfera, en particular en el caso de las partículas finas se representa por la concentración media anual.
Aunque las partículas finas se mide en muchos lugares a lo largo del mundo, la cantidad de monitores en diferentes áreas geográficas varía, y algunas áreas tienen poco o ningún monitoreo. Para producir estimaciones globales de alta resolución, se requieren datos adicionales. La concentración media urbana anual de PM2.5 se estima con modelos mejorados utilizando la integración de datos de sensores remotos por satélite, estimaciones de población, topografía y mediciones terrestres.
Es aquí que nace AIreySalud
Con la finalidad de poder entender a nuestro amenazante enemigo, nos dimos a la tarea de hacerlo nuestro mejor amigo. Conocer hasta el más microscópico detalle para que con la ayuda de la Inteligencia Artificial nos pudiéramos adelantar a sus pasos.
Hipótesis
La concentración promedio diaria de PM2.5 se puede predecir a partir de los contaminantes y parámetros meteorológicos que se monitorean de manera rutinaria en la Ciudad de México.
Metodología de trabajo
En la literatura se recomienda seguir el siguiente plan de modelación:
- Análisis exploratorio de datos (identificar si hay valores faltantes y valores extremos, definir el tratamiento que se les dará)
- Si es necesario, transformar los datos
- Ajustar modelos (definir el conjunto de entrenamiento y de prueba)
- Ajustar un modelo univariado y validarlo.
- Ajustar un modelo agregando fechas especiales (días de asueto y festivos) y validarlo.
- Ajustar un modelo agregando fechas especiales y regresores adicionales y validarlo.
- Ajustar los hiperparámetros del modelo y validarlo.
- Seleccionar el mejor modelo de acuerdo a los criterios de minimizar errores
A estos pasos se agregaría un paso previo: seleccionar los datos para responder al problema a modelar.
Seleccionar los datos
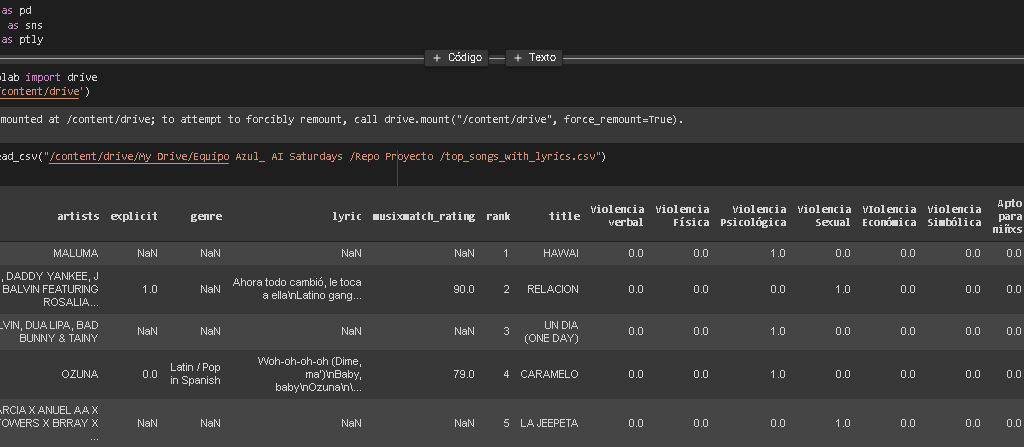
En el tema de calidad del aire los gobiernos locales cuentan en la mayoría de las veces con información de este tipo, sin embargo, a veces llega a presentar un alto porcentaje de datos faltantes. Por otro lado, no toda la información se encuentra disponible de manera frecuente o pasa por un proceso de validación, por lo tanto se determinó emplear datos de una zona metropolitana, que cada mes publica la información validada, es el caso de la información del Sistema de Monitoreo Atmosférico de la Ciudad de México — SIMAT-).
Periodo de análisis: se consideró 5 años completos (2015 a 2019) y lo que va del año 2020.
Se descargaron los datos de contaminantes y parámetros meteorológicos de los sitios de monitoreo del SIMAT (monóxido de carbono -CO-, dióxido de nitrógeno -NO2-, óxidos de nitógeno -NOx-, óxido nitrico -NO-, ozono -O3-, partículas menorea a 10 micrómetros -PM10-, partículas PM coarse que corresponde a la diferencia entre PM10 y PM2.5 -PMCO-, partículas menores a 2.52 micrómetros -PM2.5-, dióxido de azufre -SO2-, temperatura ambiente -TMP-, humedad relativa -RH-, presión atmosférica -PA-, presión barométrica -PBa-, velocidad del viento -WSP- y dirección del viento -WDR-) y se generó una base única. La información inicial representa los registros horarios de 39 sitios (ACO, SUR, TAH, TLA, TLI, SJA, PED, SAG, SFE, TPN, XAL, CCA, MGH, AJM, VIF, UAX, UIZ, CAM, MON, CHO, COY, CUA, MER, INN, HGM, CUT, AJU, ATI, LLA, LPR, NEZ, FAC, IZT, BJU, GAM, LAA, MPA, FAR y SAC) de monitoreo automático, sin embargo, por la construcción propia de un sistema de monitoreo de calidad del aire, no todos los sitios monitorean todos los contaminantes y parámetros meteorológicos. Aunado a esto, en el año 2017 se registró un sismo en la Ciudad de México que dañó la infraestructura de algunas instituciones en las que se localizaba estaciones de monitoreo, lo cual derivó en retirar los equipos de medición de esos lugares. Otra característica que presenta este tipo de fenómenos es la dependencia de sus registros con los ciclos temporales ya que su comportamiento se ve influenciado por la época del año y la hora del día (efecto de inversiones térmicas, época de lluvias, estabilidad atmosférica, horas pico del día, ubicación de fuentes de contaminación, entre otras).
Tabla.1. Listado de los sitios de monitoreo de calidad del aire del SIMAT.
Todo esto implicó que se realizaran varios pasos para determinar la inclusión de los sitios para este análisis.
Preprocesamiento de datos
Selección de sitios:
- Aquellos que monitorean PM2.5 (a saber: TLA, SJA, PED, SAG, SFE, XAL, CCA, MGH, UAX, UIZ, CAM, COY, MER, NEZ, HGM, AJM, BJU, INN, AJU, GAM, MPA, MON, SAC y FAR)
- Aquellos que presentan registros en el año 2019 y cuentan con al menos el 75% de registros de ese año (a saber: TLA, PED, SFE, XAL, CCA, AJM, MON, MER, HGM, NEZ y GAM).
El registro continuo de este tipo de datos requiere un programa de aseguramiento y control de calidad de las mediciones, el cual implica la pérdida de registros, por ejemplo, cuando se realizan calibraciones y revisión del correcto funcionamiento de los equipos automáticos; así como, por la falta de insumo de energía eléctrica que conlleva la reactivación de los equipos. Esto se refleja en tener valores faltantes (missing values) en las bases de datos, por lo tanto, se debe plantear un tratamiento para el relleno de datos faltantes.
Análisis exploratorio de datos
- Se realizó la exploración de los sitios para identificar posibles asociaciones entre ellos por cada parámetro.
- Se revisó si existe alguna dependencia con rezago en las horas para cada parámetro.
- Se realizó la exploración asociada a la dirección del viento, para identificar alguna dependencia relacionada con la dirección de donde proviene el viento.
Para el análisis exploratorio se empleó la librería Open air de r-project.
Relleno de datos faltantes
- Se considera emplear modelos que permitan el ajuste aún con datos faltantes en la variable objetivo o respuesta (PM.2.5).
- De igual manera se considera emplear modelos que requieren que la variable respuesta no contenga faltantes, por lo que se emplearán varios métodos de imputación de valores faltantes para PM2.5 (cabe comentar que por la naturaleza de este tipo de datos rellenar con la media, mediana o alguna otra constante no es recomendable). Previamente se realizará una comparación de los métodos con un conjunto de datos completo en el que se simulan los faltantes y se evalúa el error de la imputación para seleccionar el mejor modelo de relleno de faltantes (se identifica el tipo de datos faltantes que rige a este fenómeno (MCAR, MAR o NMAR por sus siglas en inglés), que se refieren a un comportamiento completamente aleatorio, de forma aleatoria o bien no sigue un proceso aleatorio, respectivamente.
- En el caso de los modelos de pronóstico en el tiempo, se requiere que las variables regresoras no tengan faltantes en el período de entrenamiento ni en el periodo de prueba. Además, se requiere datos futuros para el pronóstico de PM2.5; por lo tanto, también se debe realizar imputación de datos faltantes.
Para el proceso de relleno de datos faltantes se exploraron varias técnicas sin llegar a buenos resultados ya que generaban valores constantes para el relleno (por ejemplo las opciones que tiene implementada la rutina Fancyimpute de Python), entre ellas:
- SimpleFill: reemplaza las entradas que faltan con la media o mediana de cada columna.
- KNN: imputación de vecinos más cercanos a través de la ponderación de registros usando la diferencia cuadrática media de las variables en las que dos filas tienen datos observados.
- SoftImpute: compleción de la matriz mediante umbral suavizado iterativo de las descomposiciones de la SVD. Inspirado en el paquete SoftImpute para R, que se basa en algoritmos de regularización espectral para el aprendizaje de grandes matrices incompletas de Mazumder et. al.
- IterativeImputer: una estrategia para imputar valores faltantes al modelar cada característica con valores perdidos como una función de otras características en forma rotativa. Un código auxiliar que se vincula al IterativeImputer de scikit-learn.
- IterativeSVD: Compleción de la matriz mediante descomposición iterativa de SVD de bajo rango. Debería ser similar a SVDimpute de los métodos de estimación de valores perdidos para microarreglos de ADN de Troyanskaya et. al.
- MatrixFactorization: factorización directa de la matriz incompleta en U y V de rango bajo, con una penalización por escasez de L1 en los elementos de U y una penalización de L2 en los elementos de V.
- NuclearNormMinimization: implementación simple de Compleción de la matriz exacta a través de Optimización convexa por Emmanuel Candes y Benjamin Recht usando cvxpy. Demasiado lento para matrices grandes.
- BiScaler: estimación iterativa de la media por fila/columna y desviación estándar para obtener una matriz doblemente normalizada. No se garantiza que converja, pero funciona bien en la práctica. Tomado de Completar matriz y SVD de bajo rango a través de mínimos cuadrados alternativos rápidos.
Por lo que se decidió rellenar a partir del perfil horario de la serie de datos, es decir considerando el promedio de registros para la misma hora a lo largo de la serie, esto asegura que se cuente con un valor diferenciado por hora y no se generan datos constantes para todos los registros faltantes.
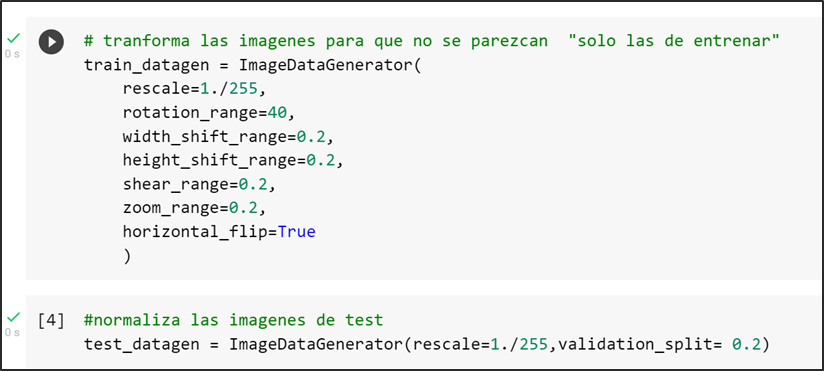
Transformar los datos
En algunas ocasiones es recomendable transformar los datos para obtener un mejor ajuste, sin embargo algunas transformaciones pueden ocasionar falta de interpretación de los resultados, por lo cual se recomienda emplear transformaciones sencillas y fácil de revertir al momento de la interpretación.
En el caso de la variable respuesta (PM2.5) se transformará con el logaritmo natural para contar con un mejor comportamiento de los datos.
Y=ln(PM2.5)
En el caso de los regresores (o covariables) se estandarizan los datos en cada variable, debido a que cada una por su naturaleza está en unidades y escalas variadas.

Ajustar modelos
La librería Prophet de facebook (fbprophet),permite pronosticar datos de series de tiempo basado en un modelo aditivo donde las tendencias no lineales se ajustan a la estacionalidad anual, semanal y diaria, más los efectos de los días festivos. Funciona mejor con series de tiempo que tienen marcados efectos estacionales y varias temporadas de datos históricos. Prophet es robusto ante los datos faltantes y los cambios de tendencia, y normalmente maneja bien los valores atípicos.
Para modelar la serie temporal Prophet, separamos la señal en los siguientes componentes aditivos:
y(t)= g(t) + s(t) + h(t) + εt
Dónde:
- y(t) es la variable a pronosticar
- g(t) es la función de tendencia que modela cambios no periódicos usando un modelo de crecimiento de saturación no lineal o un modelo de regresión lineal por partes. Puede configurar esto usando parámetros.
- s(t) es el funcional estacional (anual, semanal y diario) que modela los cambios periódicos en el valor de la serie temporal. Este componente se modela mediante una transformada de Fourier y, si lo desea, puede agregar sus propias estacionalidades.
- h(t) representa la función para modelar días festivos y eventos de impacto especial. Puede agregar su propio conjunto de feriados personalizados y eventos especiales.
- εt es el error/ruido de los modelos que se supone que tiene una distribución
Para un descripción más detallada del algoritmo consultar https://peerj.com/preprints/3190/
El algoritmo funciona mejor con series de tiempo que tienen fuertes efectos estacionales y varias temporadas de datos históricos. Prophet es robusto ante los datos faltantes en la variable de salida y a los cambios de tendencia, y normalmente maneja bien los valores atípicos (outliers).
Se establecieron los grupos de entrenamiento y prueba para evaluar los modelos considerando la secuencia de la información y a diferencia de tomarlos al azar, se estableció dejar los primeros cuatro años como periodo de entrenamiento y el último año como periodo de prueba.
Resultados
Seleccionar los datos
Se seleccionaron los datos de calidad del aire de las estaciones localizadas en la Zona Metropolitana de la Ciudad de México, que presentan registros entre los años 2015 y 2020, de estas estacione se realizó un filtro para tener las estaciones que contaban con registros de PM2.5, a estas estaciones se les realizó un segundo filtro para contar con las estaciones que registraron dato en el año 2019 y que contaron con suficiencia anual (al menos el 75% de registros horarios en el año) de esta manera se contó con un conjunto de once estaciones (ver Mapa 2).
Análisis exploratorio de datos
El análisis exploratorio permitió conocer el comportamiento de cada variables, en el caso de PM2.5 (Figura 1) se observó que hay diferencias entre las estaciones, ya que algunas presentan mayor cantidad de eventos atípicos, esto se debe principalmente al lugar en el que se localiza cada estación y las fuentes de contaminación asociadas a ellas.

Para ejemplificar el resto de los resultados se presenta el caso de la estación Ajusco Medio (AJM), para su localización consulte el Mapa 2.
El análisis por variable deja ver que son frecuentes los periodos de ausencia de datos, la diferencia en el comportamiento de cada parámetro (algunos presentan distribuciones sesgadas a la derecha, otros a la izquierda y algunos su distribución es simétrica, algunos presentan más de una moda y suele haber datos atípicos) (Figura 2).
El comportamiento de PM2.5 con respecto a la dirección del viento, muestra una clara asociación en meses de invierno (enero y diciembre) en la dirección noreste y con una franja de influencia del norte al este, y en los meses de abril y mayo se repite con un ligero corrimiento hacia el sur (colores rojos en la Figura 3), también se identifica la dilución de este contaminante en los meses de lluvias, ya que predominan los colores azules, verdes y amarilos en todas las direcciones del viento.

La desagregación por época climática para cada año permite apreciar los cambios a lo largo del periodo, (cabe comentar que la época invernal considera el diciembre de un año y el enero y febrero del siguiente año), se identifica el cambio de rojos a naranjas a lo largo de los años en la época invernal y en 2020 no registró esos colores (presenta concentraciones menores). También se marca la influencia de la primavera (marzo a mayo) con concentraciones altas principalmente en 2016, 2017 y 2019 (Figura 4).


La serie de tiempo de los registros horarios de PM2.5 se representa en la Figura 5, se puede apreciar los espacios en blanco correspondientes a los valores faltantes en esos días, así como la variación del fenómeno y los valores extremos.
La modelación se realizará con registros promedios diarios de PM2.5 por lo que se visualizó el comportamiento de estos en la Figura 6.
La variación de PM2.5 a partir de registros diarios permite identificar la presencia de ciclos asociados a los meses y años (Figura 7).
Transformar los datos
En el caso de PM2.5 la transformación fue con el logaritmo natural, la Figura 8 muestra el comportamiento original y la transformación, donde se busca tener una distribución más apegada a la simetría.

En el caso de los regresores se realizó la transformación por separado para el conjunto de datos de entrenamiento y de prueba (Figura 9).
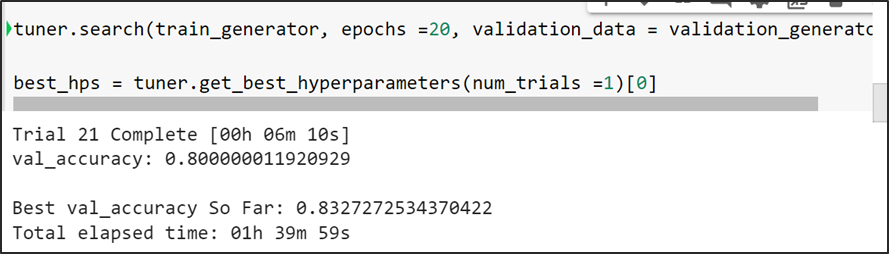
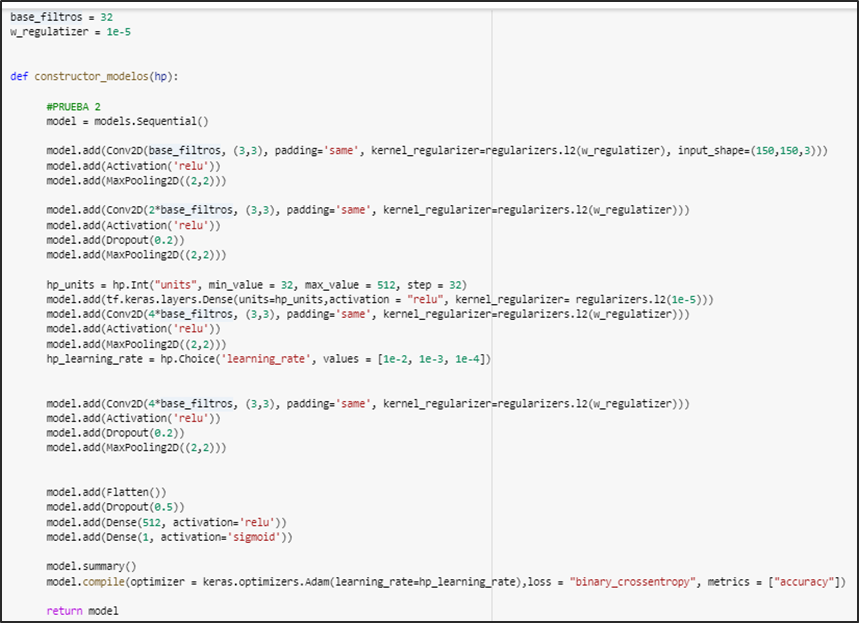
Ajustar modelos
Comenzamos modelando la serie univariada de PM2.5 sin imputar faltantes ya que el modelo maneja la falta de información en la variable de salida.
Generamos el conjunto de entrenamiento desde el 2015–01–01 hasta el 2018–12–31 y el conjunto de prueba a partir del 2019–01–01 y hasta el 2020–09–30 para entrenar y evaluar el modelo respectivamente. Se incorporan los días festivos de México al modelo para lograr un mejor ajuste.
Fragmento de código con los valores de los hiperparametros utilizados para entrenar el algoritmo:
pro_change=Prophet(changepoint_range=0.9,yearly_seasonality=True,
holidays=holidays)
pro_change.add_country_holidays(country_name=’MX’)
forecast = pro_change.fit(train).predict(future)
fig= pro_change.plot(forecast);
a = add_changepoints_to_plot(fig.gca(), pro_change, forecast)
El modelo genera un valor predictivo llamado yhat, y un intervalo de confianza con límite inferior yhat_lower y límite superior yhat_upper para la concentración de PM2.5, fijamos el nivel de confianza del 95%.
Fragmento de código para hacer el cross validation
from fbprophet.diagnostics import cross_validation
cv_results = cross_validation( model = pro_change, initial = ‘731 days’, horizon = ‘365 days’)
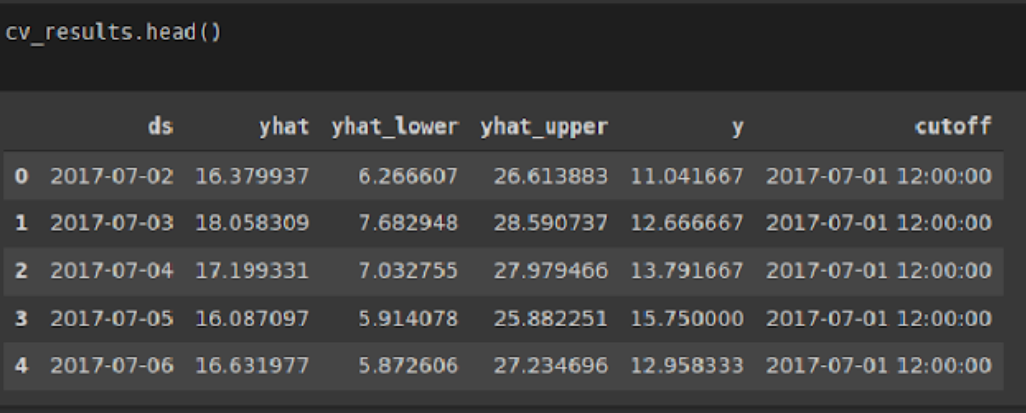
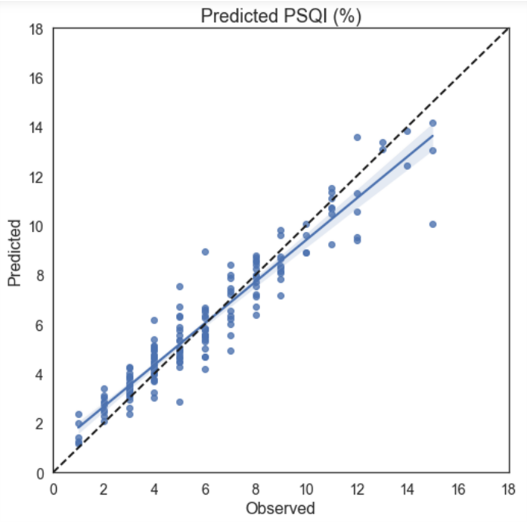
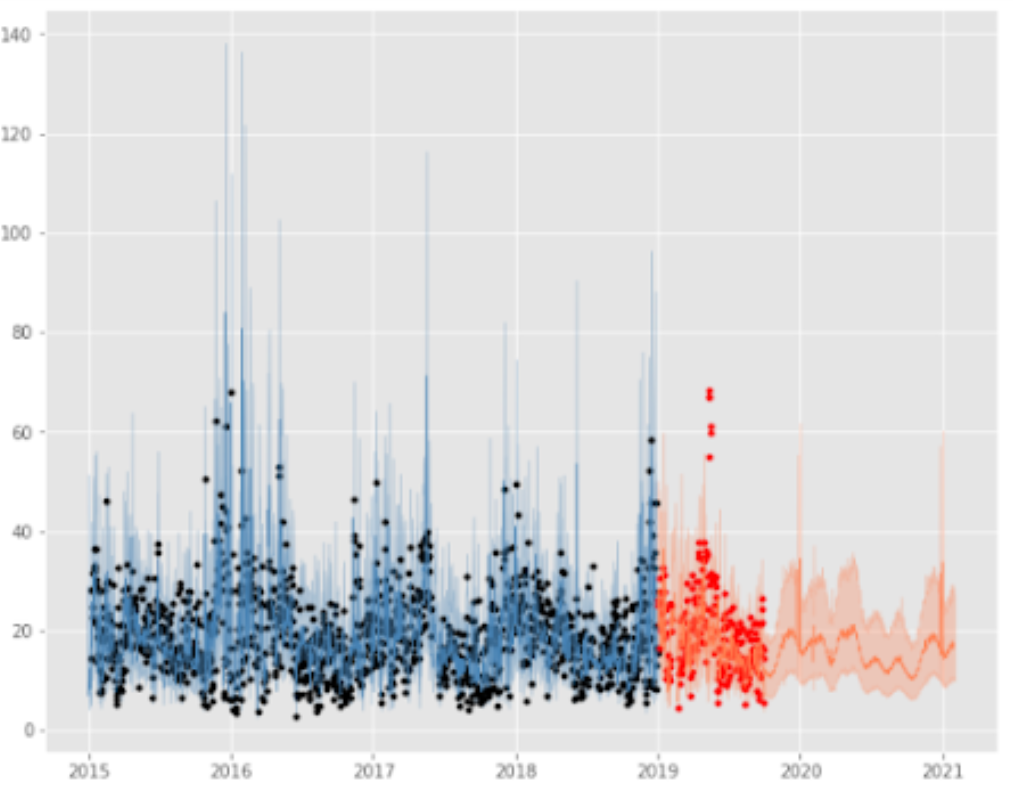
En la Figura 10 los puntos negros representan los valores de concentración promedio diaria de PM2.5, la curva en azul oscuro es el pronóstico generado por el modelo y la zona azul celeste es el intervalo de confianza al 95 %.
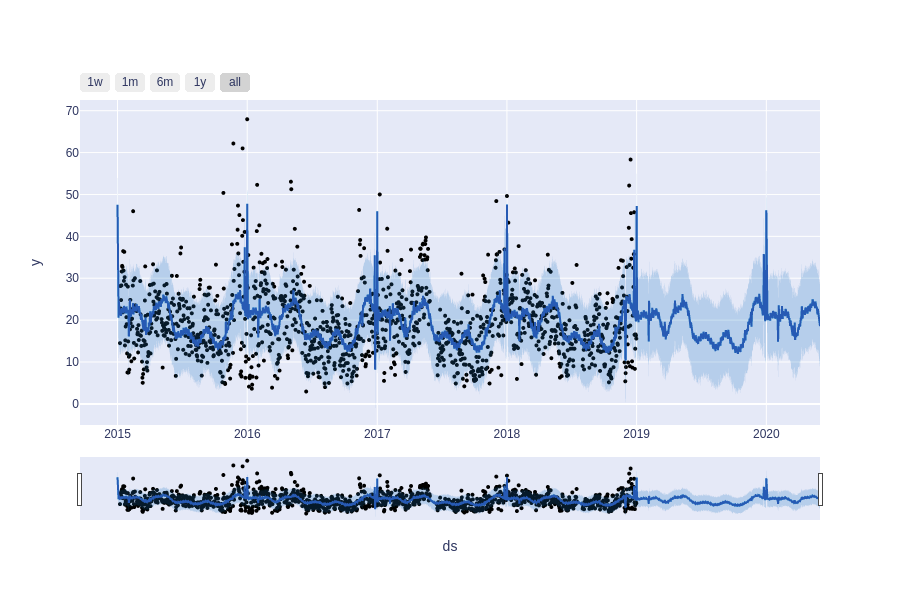
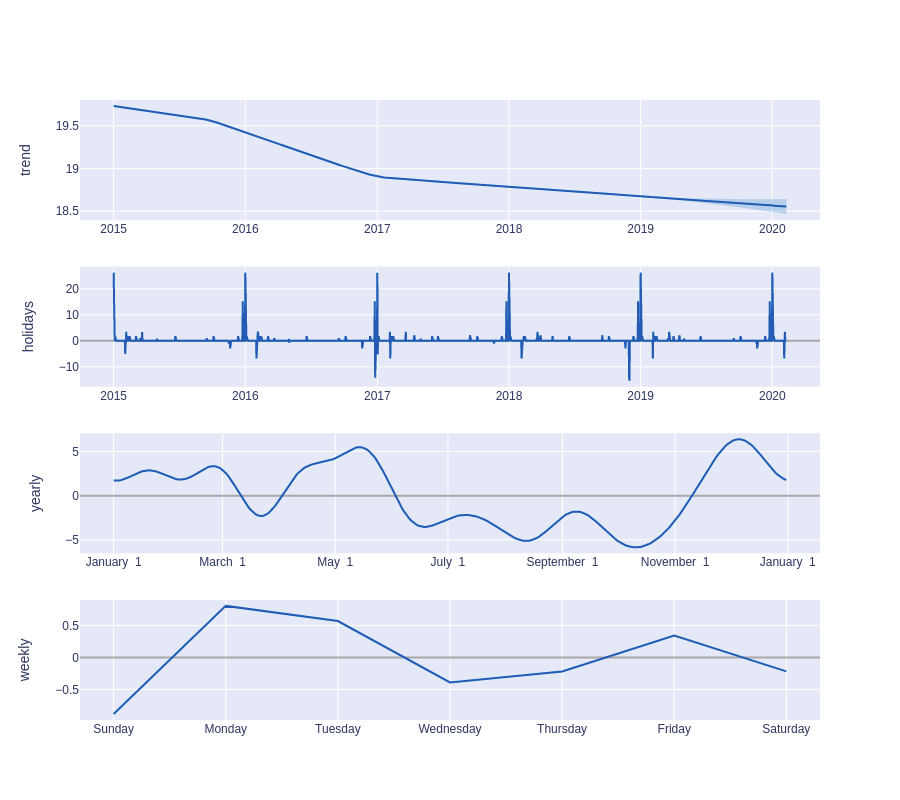
En la Figura 11 se muestra la descomposición de la serie en su tendencia, los días festivos, la estacionalidad semanal y anual.
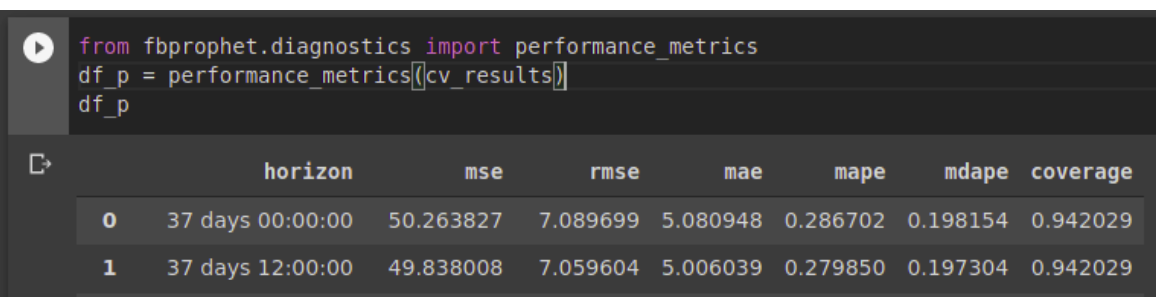
La función performance_metrics se puede utilizar para calcular algunas estadísticas útiles para medir el desempeño de la predicción (yhat, yhat_lower y yhat_upper versus y), en función de la distancia desde el límite (qué tan lejos en el futuro estaba la predicción). Las estadísticas calculadas son el error cuadrático medio (MSE), la raíz cuadrada del error cuadrático medio (RMSE), el error absoluto medio (MAE), el error porcentual absoluto medio (MAPE), el error porcentual absoluto medio (MDAPE) y la cobertura de las estimaciones yhat_lower y yhat_upper. Estos se calculan en una ventana móvil de las predicciones en el dataframe después de clasificar por horizonte (ds menos cutoff). Por defecto, el 10% de las predicciones se incluirán en cada ventana, pero esto se puede cambiar con el argumento rolling_window.
Fragmento de código para la obtención de las métricas
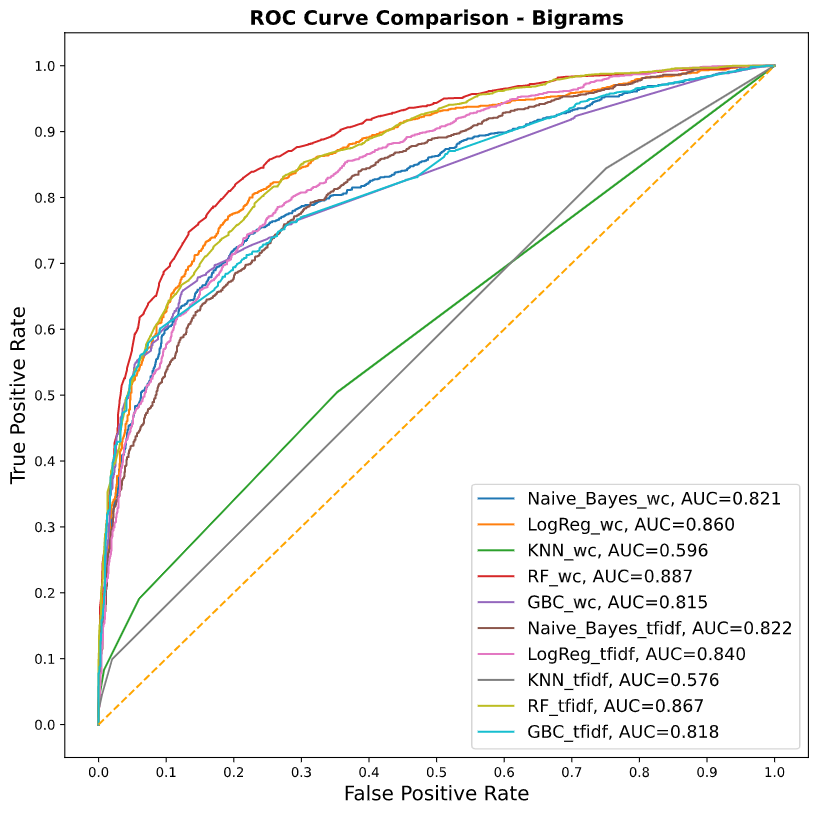
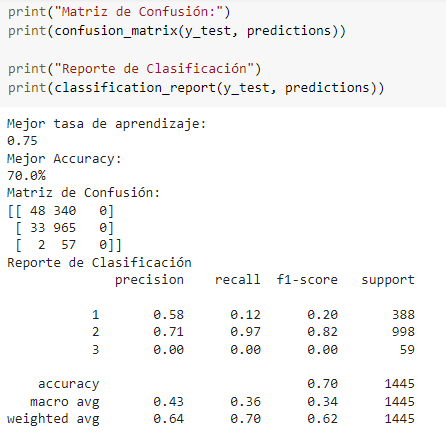
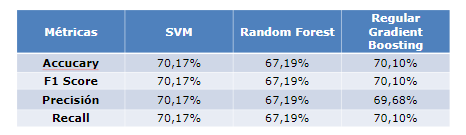
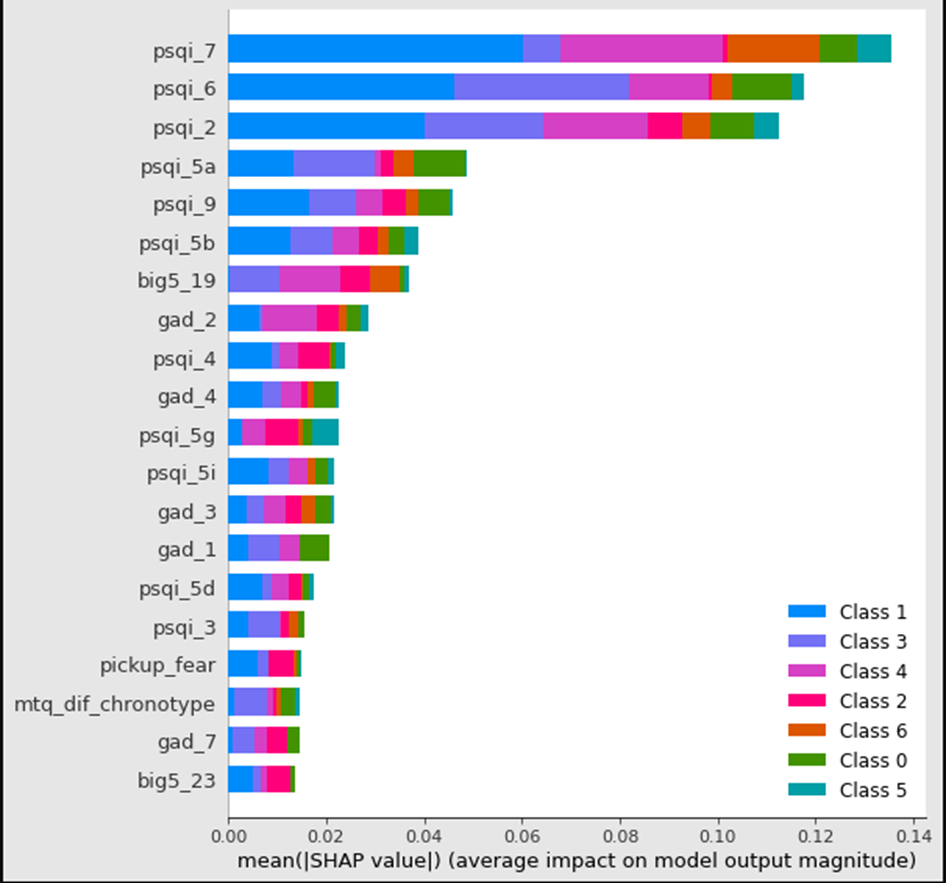
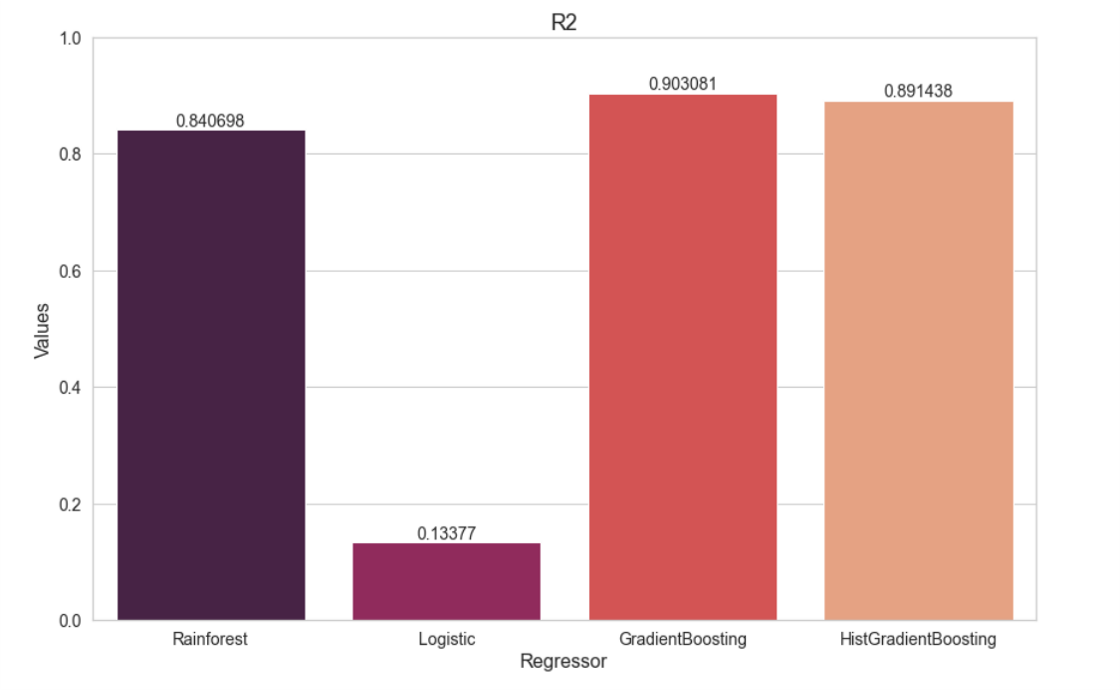
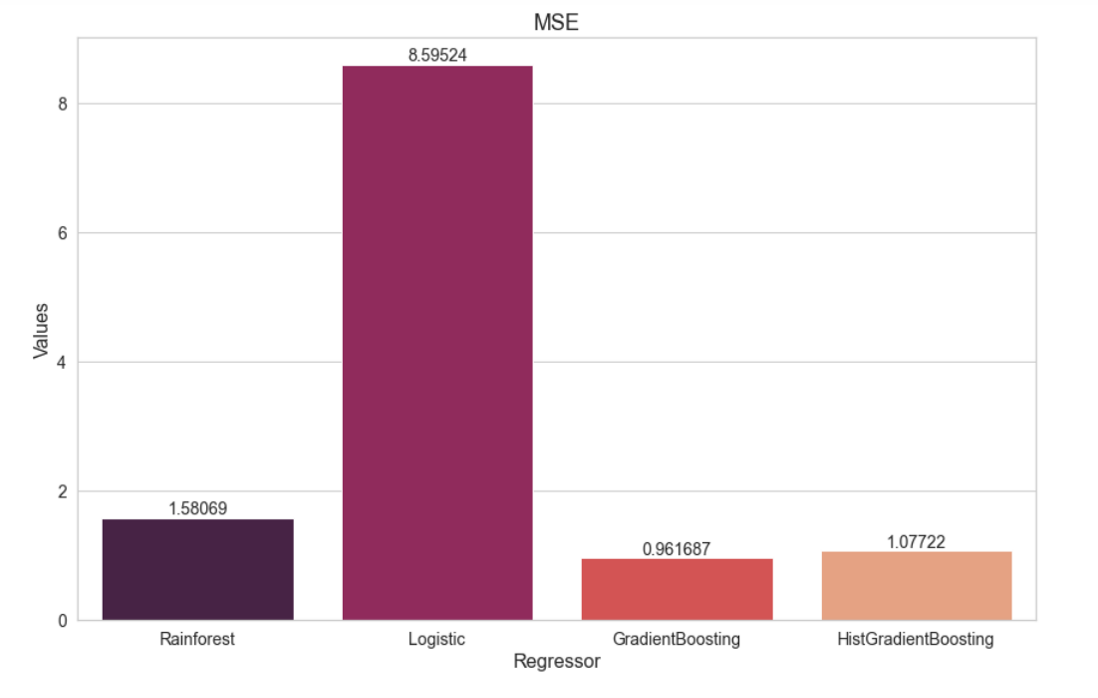
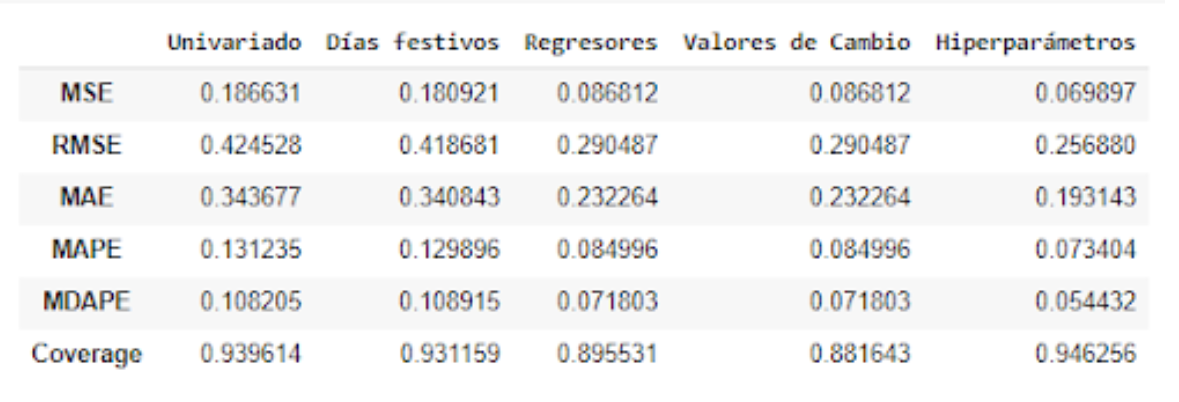
Una vez que se corrieron los diferentes modelos, se realizó la comparación de las métricas para determinar el mejor modelo. En el caso de AJM, el mejor modelo a partir de RMSE fue el ajuste con hiperparámetros, seguido del modelo con regresores en general. Para todas las métricas, el modelo con menor error fue el de los hiperparámetros.
Tabla 2. Comparativa de las métricas de los modelos ajustados (AJM, 2015–2020)
A continuación se presenta la representación gráfica del mejor modelo ajustado, distinguiendo el periodo de entrenamiento, el de prueba y el pronóstico (Figura 12).
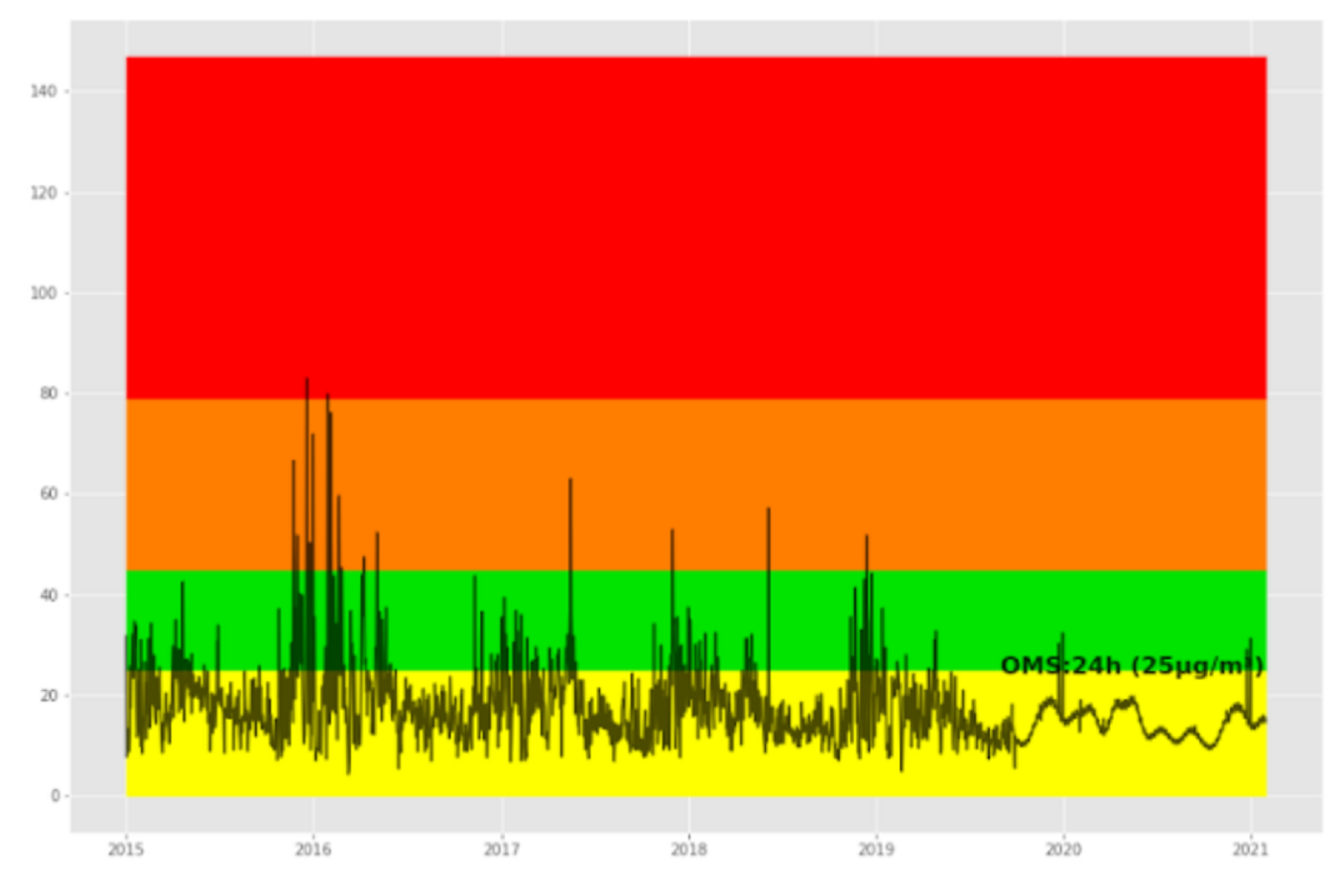
Como resultado agregado al modelar estos datos, podemos detectar si en días futuros se puede presentar algún riesgo para la salud, con referencia a las Directrices de la Organización Mundial de la Salud para el promedio de 24 horas de PM2.5 (25 g/m³) y los rangos establecidos en el Índice AIRE y SALUD de México (NOM-172-SEMARNAT-2019).
Tabla 3. Niveles de riesgo de la calidad del aire (2020)

Fuente:Comisión Ambiental de la Megalópolis (CAMe)
En el caso de Ajusco Medio el pronóstico identifica registros posibles entre las bandas de calidad del aire buena y aceptable, y al considerar el intervalo de confianza del modelo (Figura 13) se identifica que los registros podrían llegar hasta la banda de calidad el aire mala, lo que podría presentar algún riesgo para la población.
Qué sigue
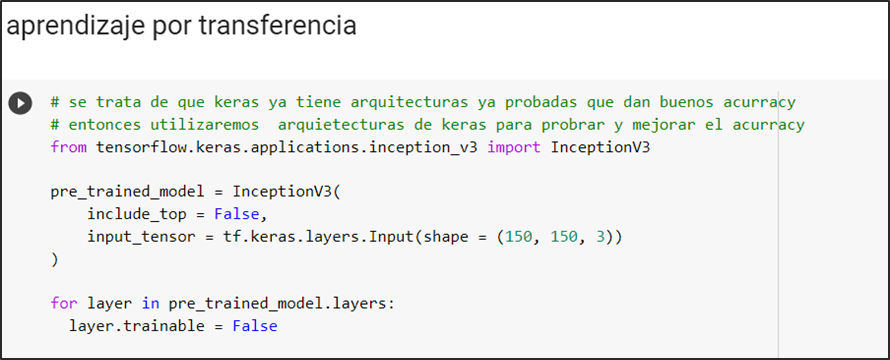
Se abre un mar de oportunidades para mejorar este primer acercamiento a modelar la calidad del aire por medio de inteligencia artificial. Los modelos se aplicaron a cada una de las estaciones, pero se puede desarrollar un modelo multiseries. De igual manera se estableció el total de variables contra las que se realizó el ajuste, pero se puede realizar una búsqueda entre los regresores que mayor aportación presentan al modelado de PM2.5.
Desarrollar una aplicación para dar difusión de los resultados.
Probar otros conjuntos de datos de diferentes ciudades.
y mucho más…
Referencias
Medina F. y Galván M. Imputación de datos: teoría y práctica. CEPAL, 2007.
Shaadan N. and RahimN A M. 2019 J. Phys.: Conf. Ser. 1366 012107.
Taylor SJ, Letham B. 2017. Forecasting at scale. PeerJ Preprints 5:e3190v2
Librerías o paquetes
Carslaw, D. C. and K. Ropkins, (2012) openair — — an R package for air quality data analysis. Environmental Modelling & Software. Volume 27–28, 52–61.
Facebook Open Source, Prophet. https://facebook.github.io/prophet/
Fancyimpute https://github.com/iskandr/fancyimpute
Integrantes
Presentación del proyecto: DemoDay
Repositorio
En el siguiente repositorio se encuentra el código usado para desarrollar esa aplicación: https://github.com/SaturdaysAI/Projects/tree/master/LATAM_remote/SaturdaysAI-LATAM_AIreySalud_2020-main
¡Más Inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!