«Aprendí que nunca somos demasiado pequeños para hacer la diferencia»
Greta Thunberg
Latam online. Segunda Edición. 2021
Es una de las frases celebres de Greta Thunberg, haciendo alusión al poder de los jóvenes de cambiarlo todo, en particular su forma de ver el mundo y las oportunidades de hacer cosas nuevas en pro de su futuro.
Pero… y sí ese futuro se ve gris y contaminado ¿Entonces cómo pueden hacer la diferencia hoy?
Actualmente, muchos jóvenes se preocupan por los problemas ambientales, volviéndose actores proactivos en la búsqueda de soluciones, esta urgencia de cambio nos motivó a crear ConciencIA Ecológica para enseñar a los niños la forma correcta de clasificar sus residuos de una manera divertida, promoviendo las prácticas de las (4R), Reducir, Reutilizar, Reciclar y Recuperar, utilizando tecnología e inteligencia artificial.
Este equipo conformado por siete (07) apasionados de la inteligencia artificial ha unido tres países como: Ecuador, México y Venezuela, participando en la 2da edición de Saturdays.AI LATAM y a través de su método build to learn elaboró un proyecto basado en Deep Learning llamado ConciencIA Ecológica, enfocado en estudiantes de educación básica de la ciudad de Guayaquil — Ecuador.
Si quieres saber más te invito a seguir leyendo.

El problema
De acuerdo al Instituto Nacional de Estadísticas y Censo (INEC), en el año 2017 cada ecuatoriano produjo 860 gramos de residuos sólidos en un día, a pesar de que este número se encontró por debajo del kilogramo de basura por día en América Latina y el Caribe, ese año se tuvo un crecimiento de 48% con respecto al año anterior, por lo que no es sorprendente imaginar, que si no se tomaron medidas a tiempo, estos números sean mayores hoy en día.
De la basura recolectada el 96% se entierra en rellenos sanitarios, celdas emergentes o botaderos a cielo abierto y solo el 4% se recicla. Para tener una idea de las razones por la que el reciclaje es bajo, en el 2016 el INEC realizó una encuesta de hogares detectando que el 59% de los hogares no clasificaron residuos.
Cuando se le preguntó las razones por las cuales no clasificaban, el 43% respondió por la falta de contenedores específicos. Sin embargo, el 57% restante se debió a problemas culturales: “no saben clasificar” (18%), “no le interesa” la clasificación de residuos (16%), dicen “no conocer los beneficios” (15%) o el restante (8%) no confía en los sistemas de recolección de basura.
De esta realidad, Guayaquil es la primera ciudad que produce basura generando el 28% del total de desechos diarios del país, y la más elevada a nivel de porcentaje de desinterés: el 29% de los ciudadanos no le interesa clasificar, el 15% no conoce los beneficios y el 6% no sabe clasificar, este desinterés es seguido por Ambato (20%), Machala (14%), Quito (11%), Cuenca (9%).
Por esta razón nuestro proyecto centra sus esfuerzos en esta ciudad y abre su primer capítulo llamado Guayaquil.

Los niños no sólo son el futuro, también son el presente del mundo
Los niños de hoy serán los adultos del mañana, si queremos cambiar la forma como las personas interactúan con nuestro planeta, debemos empezar desde edades tempranas creando hábitos amigables con el ambiente, y estos pueden estimularse en la escuela a través de la educación y la creación de espacios destinados a las buenas prácticas ambientales.
Conscientes de los anterior nace la idea de ConciencIA Ecológica el cual busca enseñar a los niños a clasificar sus residuos de forma divertida.
Este proyecto se enfoca en disminuir el desinterés y el desconocimiento en la clasificación de residuos de estudiantes de educación básica en la ciudad de Guayaquil, a través de contenedores con visión inteligente que oriente a niños desde los 5 años hasta los 14 años, en la correcta clasificación y gestión de residuos, promoviendo las prácticas de Reducir, Reutilizar, Reciclar y Recuperar (4R).
La propuesta une varios conceptos, primero buscando que el niño desde la edad escolar se familiarice con la gestión de residuos, orientándose a través de audio y luces hacia el contenedor correcto, también que gestione correctamente el residuo en su contenedor contribuyendo a la clasificación desde el origen, y creando conciencia en el niño a través de mensajes educativos.
Los contenedores están pensados para poder medir el volumen de residuos y emitir una señal al encontrarse el recipiente lleno, esto permitirá a la escuela vaciarlo a tiempo y evitar daños en la compuerta del recipiente.
Génesis de conciencia ecológica
En este punto existía dos decisiones para el módulo central de ConciencIA Ecológica, la primera ubicar un Jason Nano Nvidia, que condensa en su interior la cámara, la capacidad de cómputo y la posibilidad de conectar el micro controlador, o ubicar una Tablet reciclada, utilizar su cámara y alojar la capacidad de cómputo en la Tablet y que esta coordine la clasificación con las señales a los contenedores, las bocinas y las luces.
La decisión se tomó considerando la base del presupuesto que puede tener una escuela, por lo que la segunda opción parece ser la más viable, ya que por menos presupuesto se podrían llevar ConciencIA Ecológica a más escuelas. El equipo estimo 70$ considerando la donación de una Tablet reciclada.
Luego de decidir cómo realizar la clasificación, se pensó en qué se quería clasificar y utilizando la Norma Ecuatoriana INEN 2841, 2014, referente a la estandarización de colores para recipientes de depósito y almacenamiento temporal de residuos sólidos, se establecieron 5 clases: vidrio, papel, cartón, plástico, orgánico.
Que finalmente se agruparon en:
- En un contenedor de color verde: Orgánicos.
- En un contenedor de color azul: Plástico.
- En un contenedor de color blanco. Vidrio.
- En un contenedor de color gris: Cartón y Papel.
- En un contenedor negro: Desechos, el cual lo establecimientos como los porcentajes de predicción más bajo que presente el modelo.
Pasos para seguir
1. Dataset
Los datos fueron seleccionados de tres fuentes: Un repositorio abierto de imágenes de desechos llamado “Waste datasets review”, en particular con el data set Trashnet, que contiene 2527 imágenes; fotos en páginas web especializadas de fotografías y fotos captadas desde el celular relacionadas con productos que se consideró etiquetar relacionadas al ámbito escolar.
El dataset se construyó con un total de 5000 imágenes en 5 clases: vidrio, papel, cartón, plástico, orgánico. Para el proyecto no se consideró la clase metal. El dataset se dividió en 80% entrenamiento y 20% para validar.
2. Procesamiento: el ABC
Esta fue la fase más larga por el tiempo invertido para hacer los cuadros delimitadores (bounding box). Para el procesamiento se utilizó LabelImg, el cual es una herramienta gratuita de anotación de imágenes gráficas disponible en pip para python3.0 o superior.
Para cada etiquetado se cuidó encerrar el objeto dentro del cuadro delimitador, lo más ajustado posible a la imagen y haciendo tantos cuadros como objetos existieran.

Las imágenes fueron guardadas en formato Yolo (*.txt). Este formato establece la clase y las coordenadas de los cuadros delimitadores con la siguiente estructura:(c, xn, yn, wn, hn)

Donde:
- c : es el número de la clase, en este proyecto hay 5 clases, donde c puede tomar el valor 0 para cartón, 1 papel, 2 vidrio, 3 plástico y 4 orgánico.
- xn: centro del cuadro delimitador normalizado en la dirección x.
- yn: centro del cuadro delimitador normalizado en la dirección y.
- wn: ancho normalizado del cuadro delimitador (x).
- hn: alto normalizado del cuadro delimitador (y).
3. El modelo
El modelo seleccionado fue el YOLOv5 (You Only Look Once). Este es un sistema de código abierto para la detección de objetos en tiempo real pre-entrenado con el dataset COCO, el cual hace uso de una única red neuronal convolucional (CNN) para detectar objetos en imágenes.
De acuerdo con la revisión bibliográfica, Yolo en su quinta versión es un buen algoritmo para detectar objetos en el campo de la alimentación, robótica, salud, entre otros, logrando un buen posicionamiento y reconocimiento de objetos, más precisos que otros algoritmos, incluso versiones anteriores de Yolo. Este equipo seleccionó YoloV5, por considerarlo un algoritmo robusto con buenos resultados en investigaciones recientes relacionadas con detección.
4. Resultados:
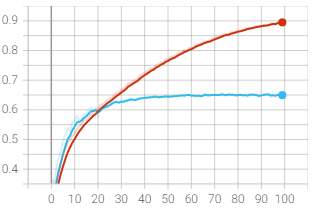
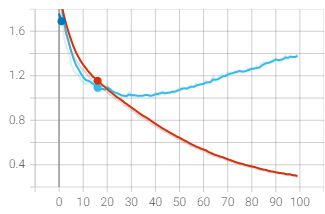
El modelo se entrenó 4 veces utilizando la técnica de “Transferencia de aprendizaje, llegando a obtener una mejora del 50% en el último entrenamiento con respecto al primero. En el modelo se usaron las siguientes variables:
- Modelo: Se usó la versión Small (Yolov5s) ya que es el más rápido de entrenar y permitió tener una buena idea del comportamiento de la base de dato y del modelo frente al problema. Sin embargo, la desventaja de la rapidez es que se sacrifica precisión en comparación con otras versiones como la Extra Large (Yolov5x)
- Pesos (weights): para el primer entrenamiento se utilizó los pesos predeterminados en Yolo, los cuales provienen del entrenamiento del data set COCO, llamado “yolov5.pt. Durante cada entrenamiento se generó un archivo con el mejor peso encontrado, el cual se utilizó para el siguiente entrenamiento.
- Épocas: Se inició el entrenamiento con 10 épocas, llegando hasta 30 épocas.
- Batch, se mantuvo fijo en 6 para todo el entrenamiento.
- Tamaño de imágenes: El data set se configuro para que cada imagen tuviera un tamaño de 640 x 640.
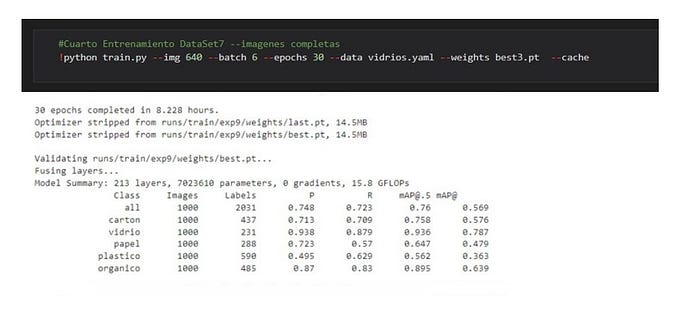
Los resultados de
- Matriz de confusión
- Precisión y Sensibilidad (Recall)
La matriz de confusión indica que tipo de error está cometiendo el modelo, en el caso de Yolo para el cálculo utiliza una confianza de 0,25 y un límite de IoU (Intersection over Union) de 0,45. Esto quiere decir que para clasificar un objeto este debe tener un 50% de probabilidad de estar en una clase.

Yolo presenta su matriz en valores relativos, donde cada elemento de la matriz está normalizado al total de la columna, por lo que la suma de los valores de cada columna es igual a 1.
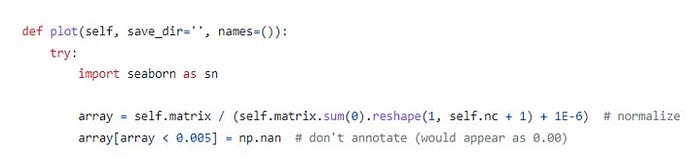
Para el data set, tenemos que el cartón lo clasifica relativamente bien, en el 72% de los casos reconoció esta clase, mientras el restante 24% lo clasificó como background. El vidrio lo reconoció en el 85% de los casos, mientras un 10% lo confundió con plástico quizás por la similitud de la transparencia. El papel un 59%, siendo este el valor más bajo, compartiendo un 8% con cartón, y un 32% con el background. Para el caso del plástico se obtuvo un 64% de asertividad, y el restante 34% con el background. Por último, en orgánico se obtuvo un 85% de verdaderos positivos y apenas un 13% de background.
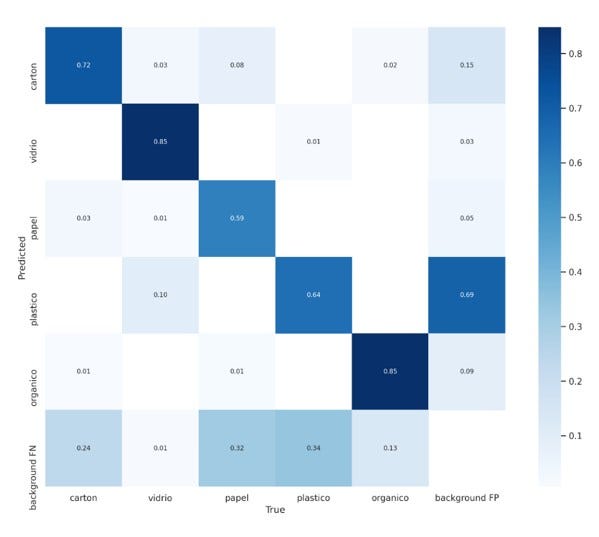
La precisión promedio de todas las clases del modelo fue 0.748, la cual para este tipo de algoritmo es buena, nos indica que de cada 10 imágenes, aproximadamente 7 la clasifica correctamente. Su sensibilidad (Recall) fue 0.723, lo que es una buena medida de la cantidad de objetos por clase clasificados correctamente, en una clase determinada de cada 10 imágenes 7 son correctas, apenas 3 son falsos positivos.
5. El prototipio: su crecimiento
Es importante mencionar que el alcance del proyecto se limitó a realizar el prototipado de ConciencIA Ecológica que consistió en el despliegue, la simulación de los componentes del hardware y un bosquejo de una aplicación que conecta la predicción del modelo con el hardware para clasificar imágenes de seis (6) tipos de residuos: orgánicos, vidrio, plástico, papel, cartón, desechos.
A continuación se explicará el funcionamiento del prototipo.
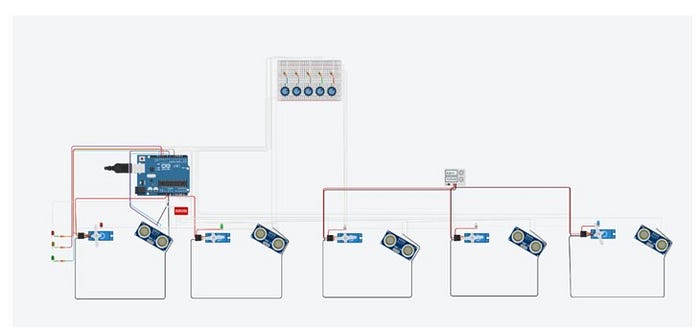
ConciencIA Ecológica consistirá en cinco (05) contenedores de diferentes colores y un módulo central donde se encontrará una Tablet con cámara. Los contenedores se diseñaron pensando en el tamaño de los niños y la forma más fácil de depositar el residuo en estos.

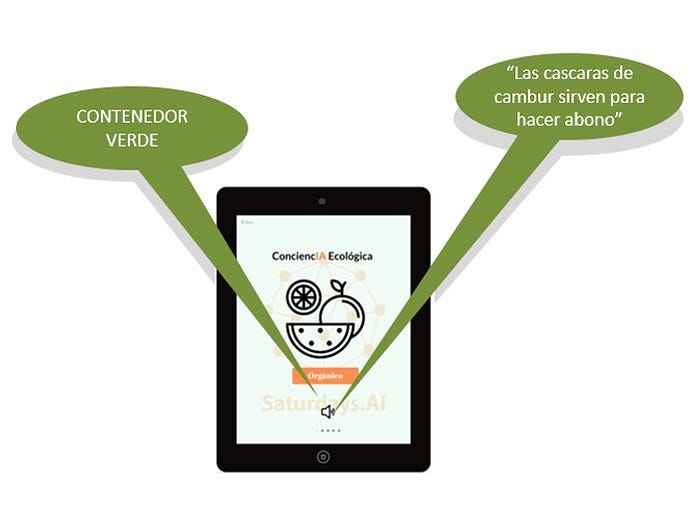
Se buscará que el aprendizaje se realice a través de la interacción del niño con los contenedores, para ello el niño presentará un residuo a la cámara de la Tablet y a través de un modelo, se podrá reconocer hasta seis (6) tipos de residuos: orgánicos, vidrio, plástico, papel, cartón y desechos en general. Luego de reconocer el residuo, se enviará la predicción a una App alojada en la Tablet en el módulo central, la cual mostrará en pantalla lo reconocido y emitirá un sonido con el nombre del material categorizado y el color del contenedor.

Al mismo tiempo, la Tablet enviará una señal a un micro controlador para abrir el contenedor destinado a recolectar el residuo y se enviará una señal que encenderá una luz ubicada en el contenedor. La App emitirá información sobre la práctica de las 4R para promover su uso. El niño finalmente se dirigirá al contenedor señalado y deposita el residuo.

En cada contenedor se instalará un sensor ultrasónico para medir el volumen de residuos acumulados, el sensor enviará una señal a tres led´s que indicarán tres niveles: Disponible (verde), Intermedio (amarillo) y Lleno (rojo). Esto con el fin de evitar que los contenedores rebasen su capacidad, ya que, de producirse, pueden obstaculizar la apertura de la puerta con la entrada de residuos produciendo daños a los servomotores.

6. Despliegue
Por otro lado, la aplicación en esta fase no tendrá interacción física con el niño, por el momento servirá como centralizador de la información que viene del modelo y que dirige la acción de la apertura de los contenedores, mostrar en pantalla el resultado, emitir sonido y prender las luces de los contenedores.
La App debe ser iniciada por el administrador, el cual podrá comenzar a ejecutar Conciencia Ecológica a través de su usuario y contraseña.
Inmediatamente, se despliega un menú el cual mostrará un botón de “comenzar a reciclar” que pondrá a Conciencia Ecológica en modo de reconocimiento de residuos. Al darle al botón se enciende el sensor de aproximación y el sensor óptico (cámara); a futuro se tiene pensado implementar un módulo de estadísticas visible en el menú, a los efectos de esta idea de proyecto se colocará como deshabilitado.

En el modo reconocimiento, cuando el sensor de aproximación se activa, se mostrará un mensaje para que el niño presente el objeto a la cámara, cuando detecte el objeto se realizará la predicción.

Una vez realizada, se mostrará en la pantalla la clase identificada y emitirá un sonido con el nombre del contenedor, luego emitirá un corto mensaje educativo.
Al mismo tiempo la App enviará la información por bluetooth al micro controlador, el cual se encargará de abrir la compuerta correcta y emitir la señal para encender los led´s. Abajo se muestra un diagrama simulado en Tinkercad.
Su futuro: Próximos pasos
Hasta este punto, tenemos una idea de cómo Conciencia Ecológica de una forma sencilla puede orientar a los niños en la creación de hábitos para Reducir, Reutilizar, Reciclar y Recuperar. Pero…
¿hasta aquí llegamos?
A corto plazo, lo primero sería llevar esta conceptualización a la realidad, mejorando cada uno de los aspectos técnicos contemplados en el prototipo. El financiamiento de la Municipalidad de Guayaquil o una institución interesada seria la chispa para propulsar el proyecto.
A mediano plazo, aumentar la base datos e incluir otros materiales para la clasificación, como por ejemplo metal e incluso escalarse el proyecto a empresas para materiales peligrosos como baterías, bombillos ahorradores, bombillo fluorescentes, que están ocasionando un grave problema al ambiente.
En principio, el diseño de los contenedores educativos esta ajustados a las necesidades de cada región e incluso país, ya que actualmente no existe una regulación internacional que dicte las normas de los colores de los contenedores o qué tipo de material se recicla, se puede adaptar Conciencia Ecológica a las necesidades del usuario.
¿Por qué no buscamos que la inteligencia artificial le responda al niño sus inquietudes y dudas?. La App puede ser mejorada para incluir la interacción con el niño y se podría tener una conversación de reciclaje y de aspectos de interés para la educación de los niños de acuerdo a los programas educativos de cada región o país.
Pensando en el futuro de la información. El sensor ultrasónico, podría generar datos a través de la estimación de volumen de cada contenedor. Estos datos ayudarán a llevar la estadística acumulada en el tiempo, sea por contenedor y en sus 5 categorías; así como también por escuelas.
Esta información se alojará en una base de datos para posteriormente alimentar un dashboard de indicadores que permitirá su monitoreo, así como otras funcionalidades como: el control de dispositivos que no estén en funcionando; las escuelas que no están siendo proactivas; tiempo de contenedores llenos sin gestionar; entre otros. En fin una serie de indicadores primordiales, que permita a través de los entes encargados llevar un control de unidades “contenedores” por escuela e incentivar a estas para que su alumnado aprenda jugando.
Integrantes:
- Luis Reyes
- Lady Sangacha
- Jostin Maldonado
- Karely Mayorquín
- Jorge Chiquito
- Verónica Abad
- Carlos González
Presentación del proyecto: DemoDay
Repositorio:
GitHub: https://github.com/SaturdaysAI/Projects/tree/master/LATAM_remote/ConcienciaEcologica
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!