Latam online. Segunda Edición. 2021
En la actualidad, los desechos municipales a nivel mundial podrían aumentar un 70% en los próximos 30 años, provocando así montones de basura acumulados alrededor del mundo (Banco Mundial, 2019). Es por esto que, si no se toman medidas urgentes, se espera un futuro donde el convivir con basura sea algo normal para la sociedad.
Debido a las consecuencias de las acumulaciones de basura no controladas ni planificadas se deben tomar diferentes estrategias que amortigüen sus ocurrencias en distintos puntos del mundo.
Descripción del problema
El problema de la acumulación de basura no solo radica en el mal olor que se percibe, sino la imagen de insalubridad, desorden y hasta de inseguridad que la basura se desparrama en las calles genera. En las calles se puede encontrar desde cartones y pañales, hasta cáscaras de frutas, plástico y sábanas viejas. Todo esto al pie del canal de aguas lluvias, en cuyas bases también es común ver flotando todo tipo de desechos.
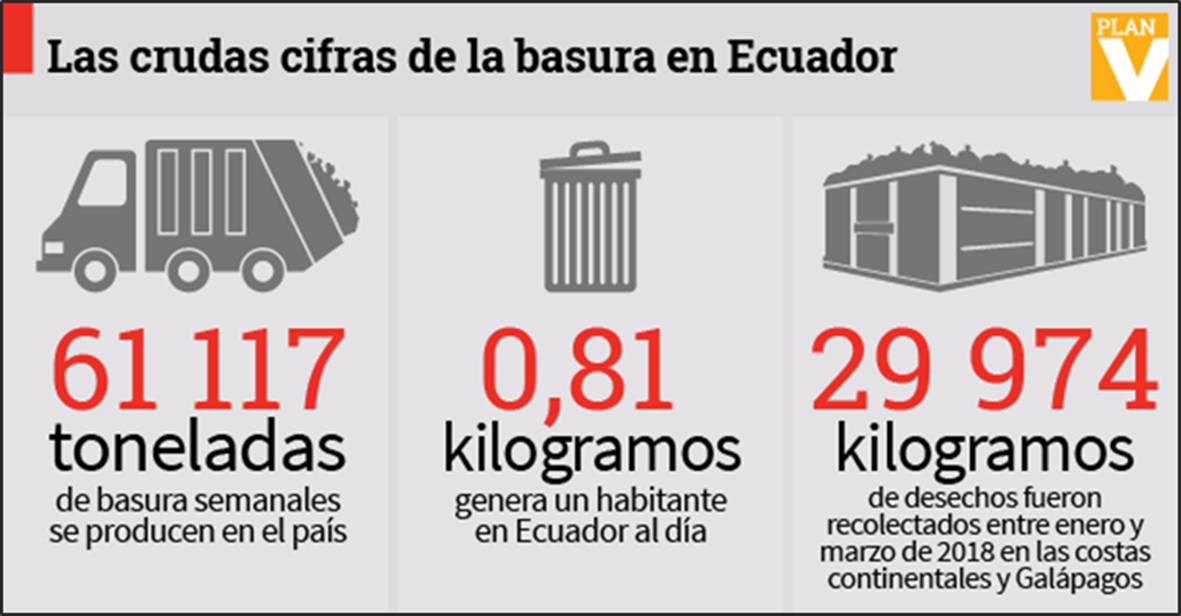
Según el Ministerio del Ambiente, en el Ecuador la más crítica es la Costa, en donde apenas el 10% de los municipios dispone de un relleno sanitario, manual o mecanizado; en la región Sierra son 25%, y en el Oriente, el 24%. Por lo que las cifras de basura dentro del país aumentan diariamente tal y como se visualiza en la Figura 2.
En la figura 2.1, se visualizan algunas de las consecuencias de la acumulación de basura como lo son: daños en la infraestructura pública, aumento de enfermedades y plagas, inundaciones en las calles, obstrucción en los alcantarillados y entre otros.

En la ciudad de Guayaquil, las penas por desechar desechos sólidos no peligrosos al margen de la frecuencia y horarios establecidos y acumular la basura en parterres y aceras; van desde los $80 a $500 .
¿Cómo nace nuestro proyecto?

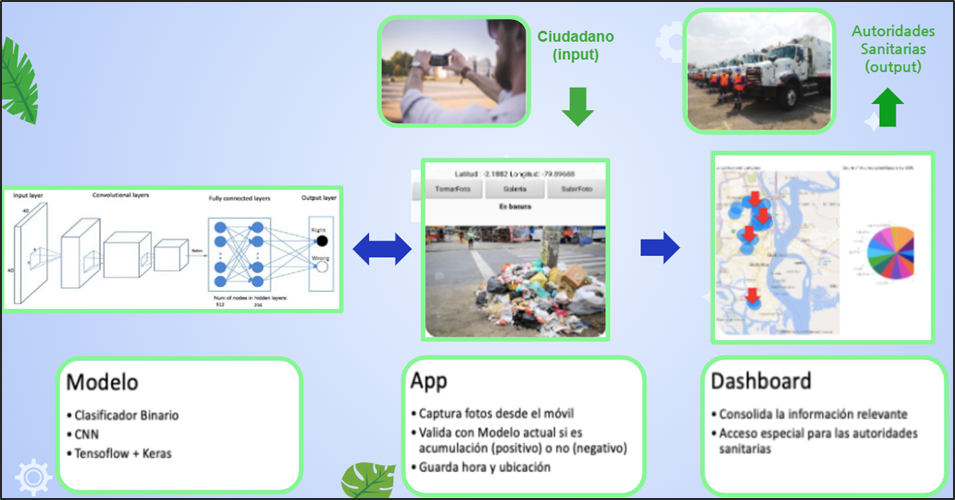
Ciudad Limpia se basó en la siguiente pregunta : ¿Cómo identificar de manera oportuna la acumulación de la basura no controlada en la ciudad de Guayaquil para minimizar el impacto en la sociedad? Por tal motivo creamos una aplicación que nos permite contribuir en la recolección de basura. Haciendo participe a la ciudadanía en mejorar la limpieza de la ciudad y que alguna empresa se interese en nuestra herramienta tecnológica basada en Inteligencia artificial.
Integrantes del proyecto

Experiencia del equipo
Manuel Ahumada “Fue una experiencia de aprendizaje práctico: enfocado en el hacer para adquirir los temas y conceptos presentados. Eso refuerza el conocimiento.”.
Patricia Andrade “Mi experiencia fue muy enriquecedora debido a todo el nuevo conocimiento que aprendí. Además, me gustó mucho el compartir ideas con compañeros de distintos campos para solucionar un problema práctico”.
César Villarroel “Fue una experiencia de aprendizaje práctico: enfocado en el hacer para lograr adquirir los temas y conceptos presentados. Eso refuerza el conocimiento.”.
Ingrid León “La experiencia que se obtiene en esta modalidad es buena, El poder compartir conocimientos, desafíos y riesgos hacen que seamos más profesiones. Me quedo con una frase “«Son dos las opciones básicas: aceptar las condiciones como existen o aceptar la responsabilidad de modificarlas»”, entonces podemos mejorar siempre”.
Objetivo general
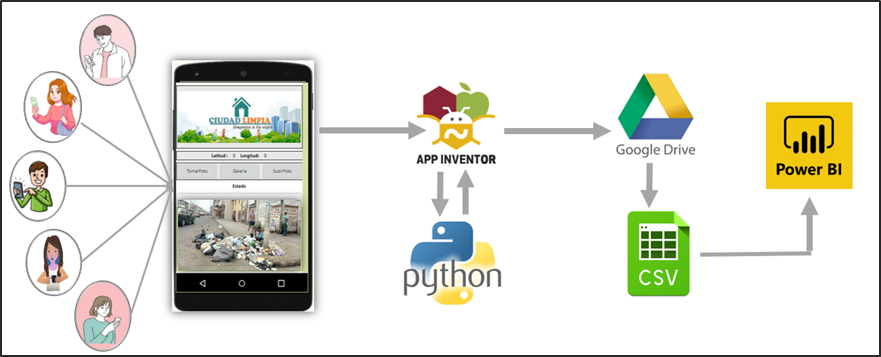
En la siguiente figura 4, se puede visualizar la idea principal del proyecto.
Desarrollar una aplicación basada en Inteligencia Artificial que permita identificar aglomeraciones de basura en la vía pública de zonas urbanas.
Planteamiento de la solución
Se proyecta que mediante la colaboración de los ciudadanos se cree una concientización donde formen parte de la limpieza y cuidado de la ciudad. ¿Cómo lo van a hacer? Fácil, a través de la app “Ciudad Limpia” , en donde pueden tomar una foto para identificar y reportar la acumulación de basura de un sector determinado. Además, la aplicación registra la fecha, hora y ubicación del problema. Dicha aplicación estará basada en Inteligencia Artificial que permitirá identificar aglomeraciones de basura en la vía pública de zonas urbanas y fomentar un plan de acción inmediata para las autoridades sanitarias.
Conjunto de datos
El conjunto de datos que se formó fue basado en descarga de imágenes de manera individual desde el Internet, videos transformados en fotogramas. Además, se sacó la plataforma de Kaggle y Google Street view donde se pudo obtener una gran cantidad de dataset de imágenes de aglomeración de basura.

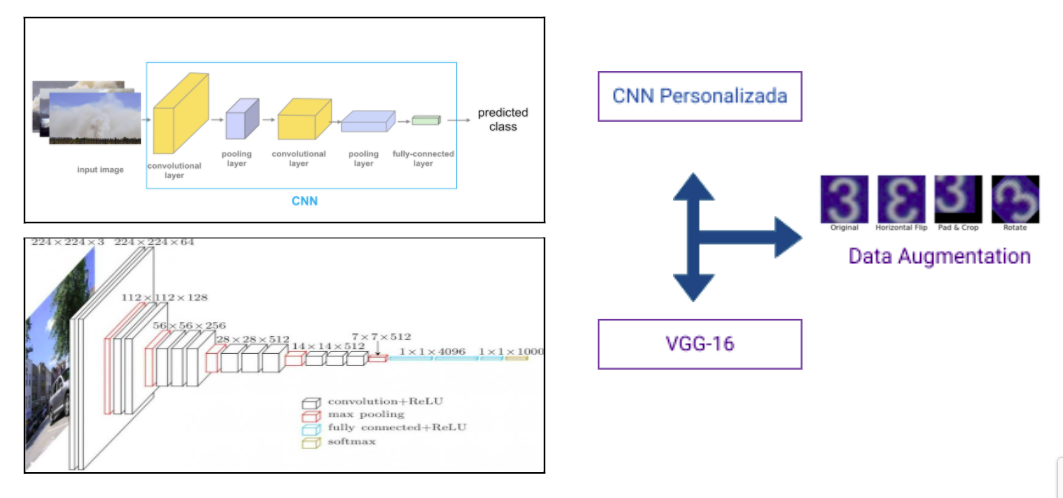
Selección del modelo
Para la selección de los modelos se obtuvo las siguientes consideraciones:
- Fácil implementación.
- Rendimiento del modelo.
- Limitación de cálculo.
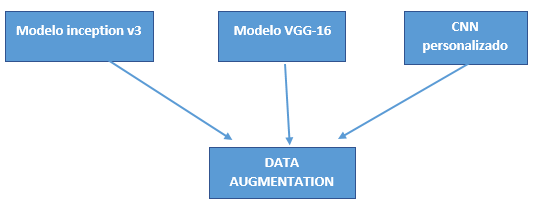
Estas consideraciones son debido a los recursos que se tienen para realizar el objetivo general. Los modelos a desarrollarse son:
- CCN Personalizado.
- VGG-16.
- inicioV3.
Técnicas implementadas
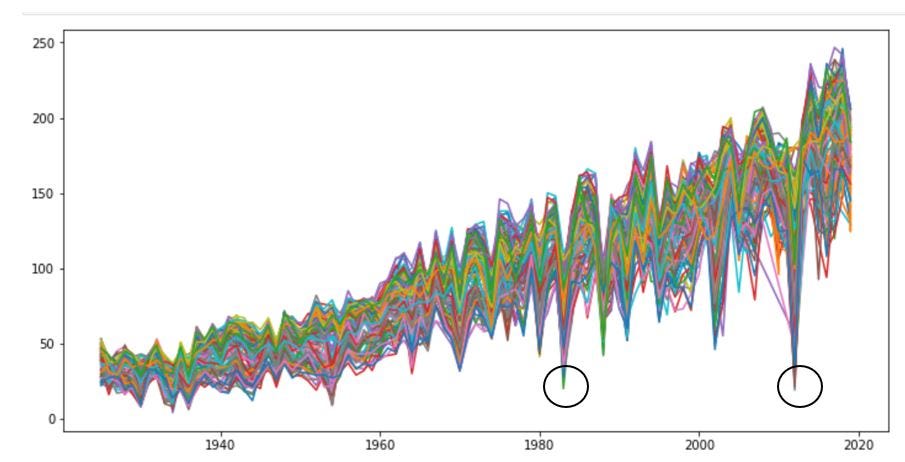
La principal técnica utilizada para compensar el conjunto de datos de tamaño limitado por la limitación de búsqueda de imágenes en Google fue la “aumentación de datos” realizada por la librería de keras “ImageDataGenerator”.
Data augmentation
El aumento de datos es la generación artificial de datos por medio de perturbaciones en los datos originales. Esto nos permite aumentar tanto en tamaño como en diversidad nuestro conjunto de datos de entrenamiento. En el computer vision, esta técnica se convirtió en un estándar de regularización, y también para mejorar el rendimiento y combatir el overfitting en CNNs.

En los tres modelos seleccionados se consideraron la técnica de aumento de datos con el objetivo de normalizar o re-escalar los píxeles en un rango de 0 a 1. Además de modificar las imágenes del conjunto tren con el objetivo de que existe una distinción en cada una de las imágenes seleccionadas tanto de ancho, largo, amplitud, rotación y escalamiento. A continuación, se observa el código donde se transforman las imágenes de entrenamiento con los parámetros seleccionados:
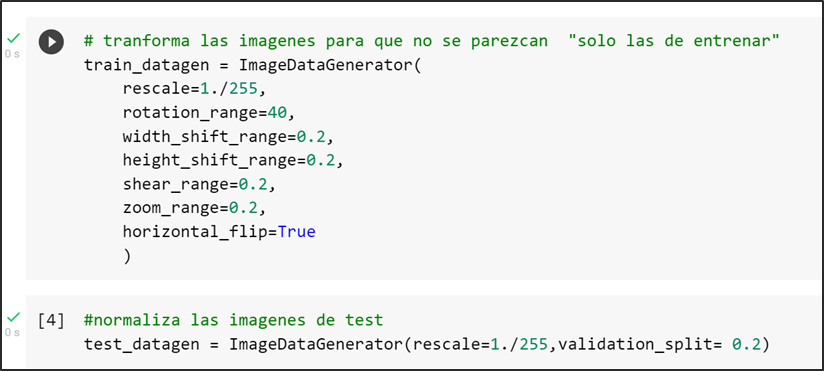
CNN personalizado
En el modelo CNN personalizado se aplicaron técnicas de regulación, callbacks y por último keras tuner.
Keras Tuner
Keras Tuner es una librería muy sencilla de utilizar que simplifica en gran medida complejidad el proceso de aplicar de optimización de hiper-parámetros sobre redes de neuronas profundas construidas mediante Keras, ofreciéndonos un amplio grado de versatilidad para optimizar tanto la estructura de nuestra red como la configuración de los parámetros de algunos de los algoritmos implicados en el proceso de entrenamiento.
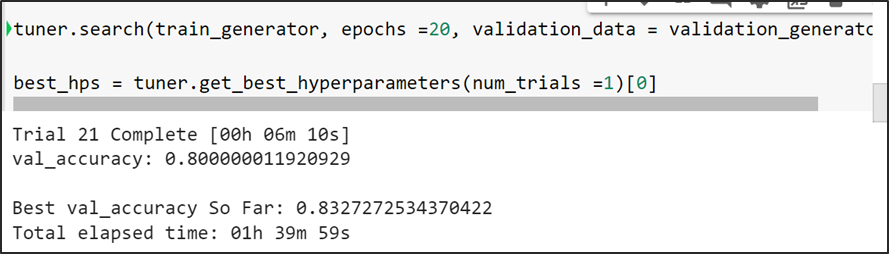
Keras Tuner mientras va analizando cada trial, verifica el mejor valor de val accuracy infiriendo que es la mejor configuración de la arquitectura y la procede a guardar la mejor configuración de la arquitectura del modelo (número de capas) con el cual tiende a lograr la mejor métrico.
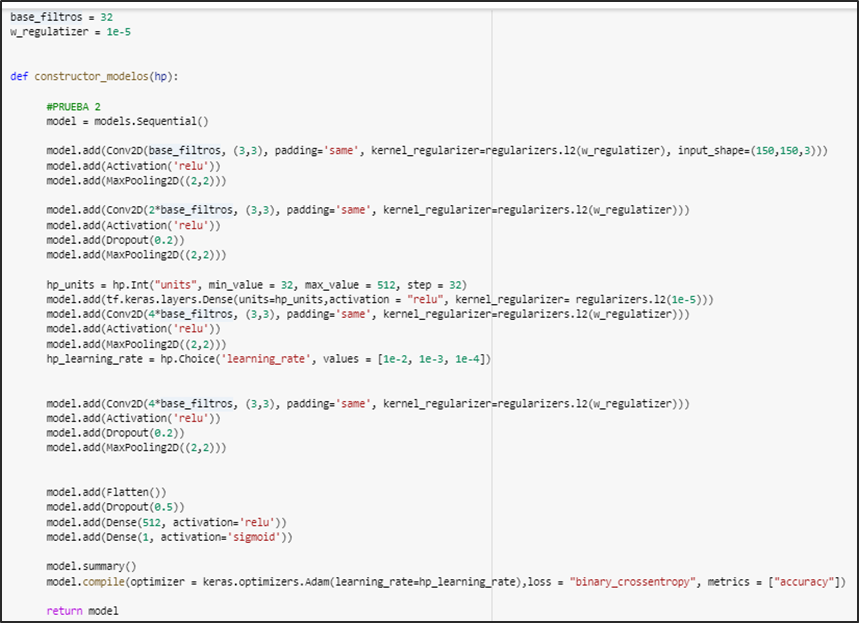
Arquitectura del modelo cnn personalizado cuenta con regularizadores, convolución, keras tuner
InceptionV3
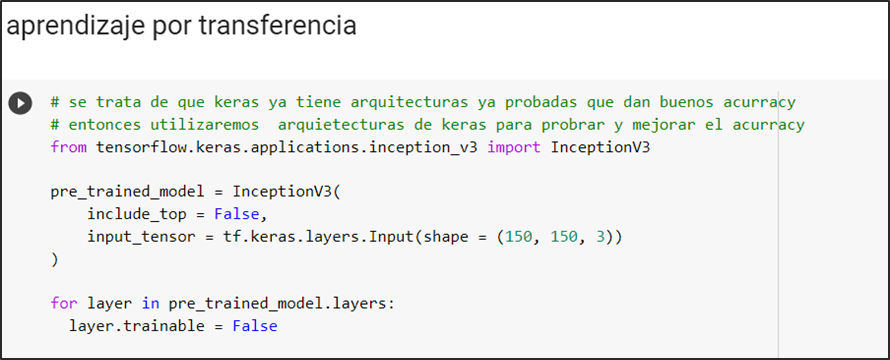
Se define el modelo pre-entrenado inceptionv3, valida el tamaño de las imágenes de input con que se entrena:
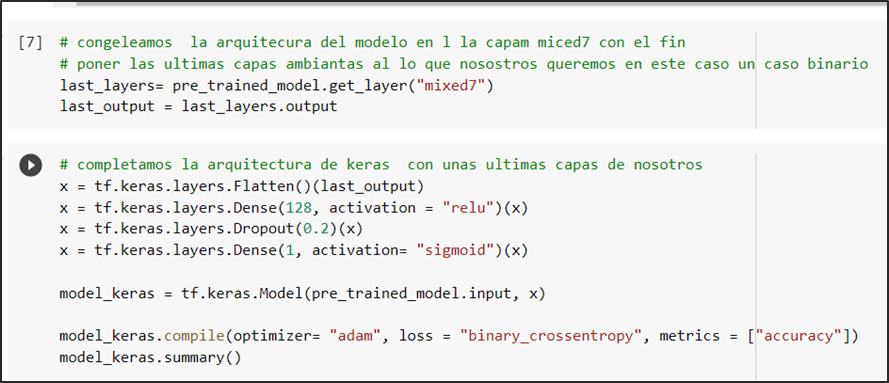
Se congela la arquitectura en la capa “mixed7” para después alterarla añadiendo capas basadas en la predicción de nuestro modelo que es una clasificación binaria por el cual la última capa tiene activación sigmoidal la cual nos ofrece como resultado la probabilidad de que si un caso es positivo o negativo
VGG-16

Se define el modelo pre-entrenado vgg16 y valida el size de las imágenes de input con que se entrena

Se procede a aumentar las capas basadas en la predicción de nuestro modelo que es una clasificación binaria por lo cual la última capa tiene activación sigmoidal la cual nos ofrece como resultado la probabilidad de que si un caso es positivo o negativo
Análisis de resultados
CNN personalizado
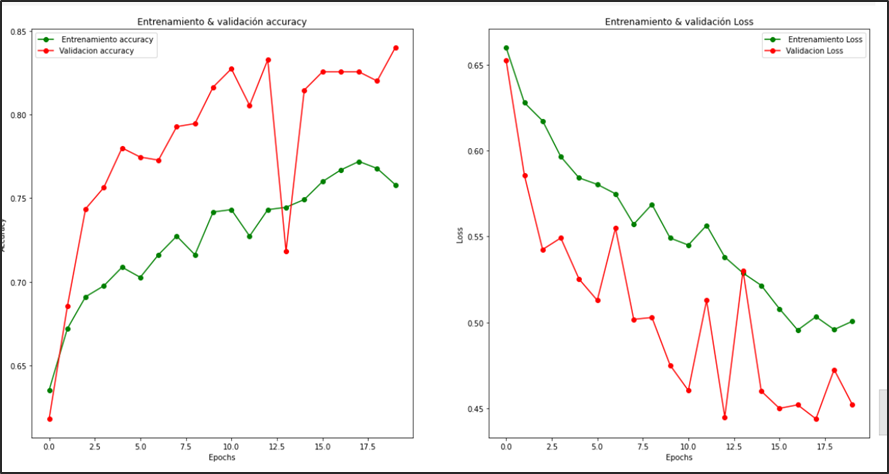
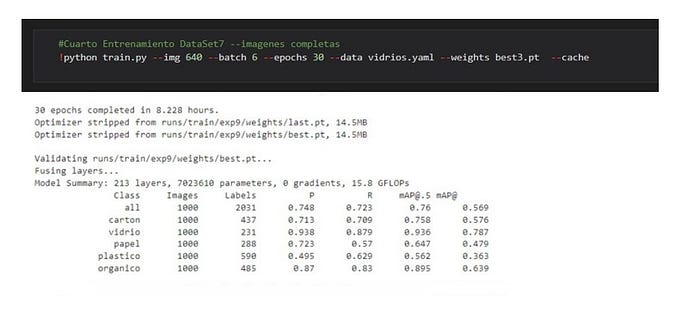
En la evaluación del modelo se entrenó con 20 épocas. Sé puede verificar que no logra converger en su totalidad. Logra una accuracy de la evaluación del conjunto test del 78 %

InceptionV3
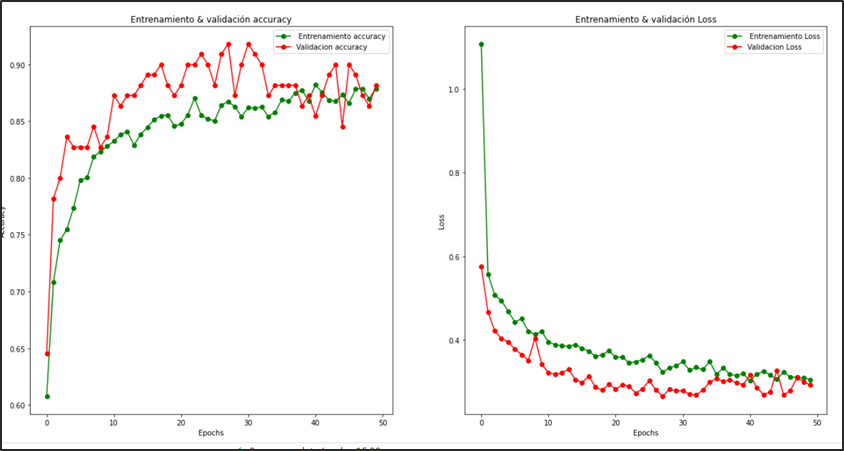
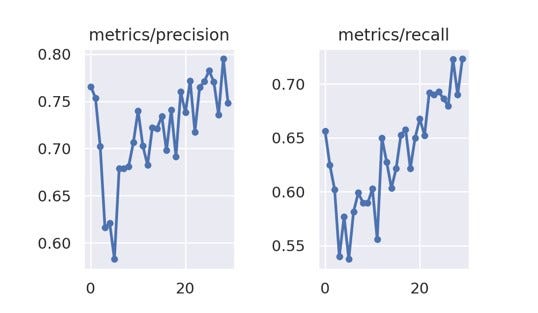
En la evaluación del modelo el cual se entrenó con 50 épocas se puede analizar que logra converger en totalidad a partir de la época 28 en adelante, con una precisión de la evaluación del conjunto test del 85 %

VGG-16
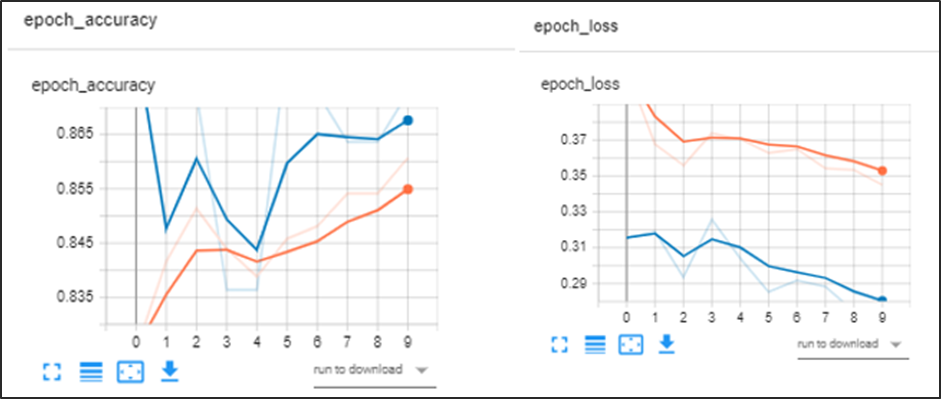
En la evaluación del modelo el cual se entrenó con 10 épocas se puede analizar que logra converger, con una precisión de la evaluación del conjunto test del 84 %

A continuación, mostramos las predicciones de los modelos:
InceptionV3
Predicción de la carpeta test
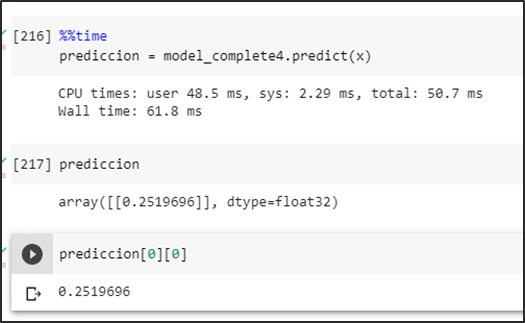
Se obtiene las probabilidades de predicción del conjunto test
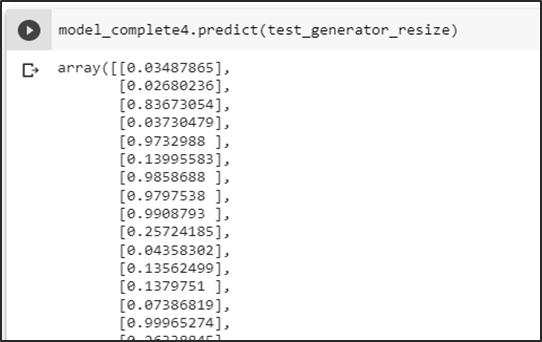
Primera prueba sin basura
Prueba del modelo prediciendo una imagen sin basura dando como resultado una probabilidad menor a un umbral de 0.5 se la identifica como una no aglomeración.
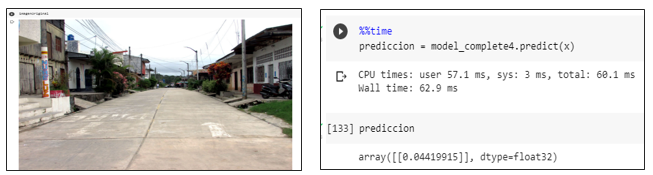
Segunda prueba con basura
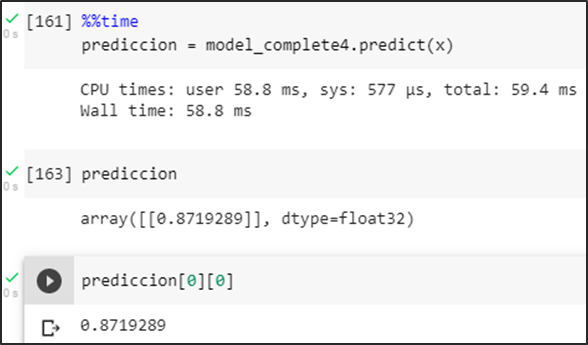
Prueba del modelo prediciendo una imagen con basura generando una probabilidad mayor a un umbral de 0.5 se la identifica como una aglomeración.
Tercera prueba con imagen y muchos colores

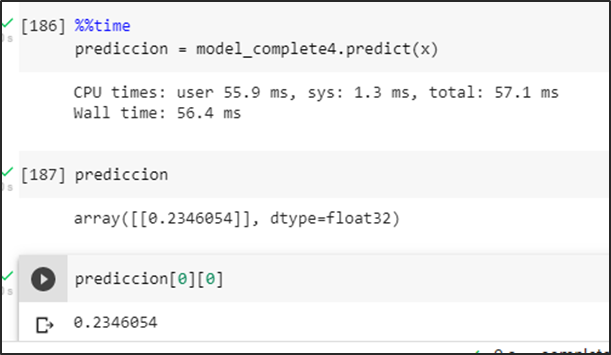
Prueba del modelo prediciendo una imagen falsa positiva intentando romper la predicción en consecuencia se obtiene una probabilidad menor a un umbral de 0.5 se la identifica como una no aglomeración
VGG-16
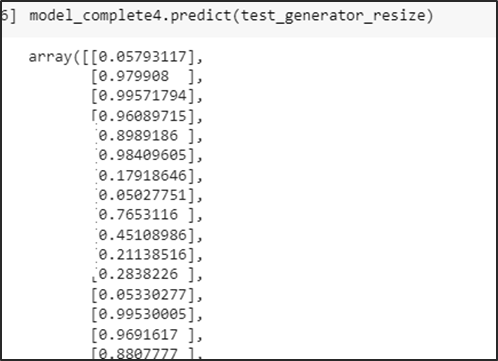
Predicción de la carpeta de test
Se obtienen las probabilidades de predicción del conjunto test
Primera prueba sin basura

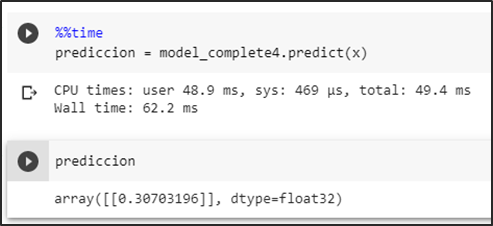
Prueba del modelo prediciendo una imagen sin basura dando como resultado una probabilidad menor a un umbral de 0.5 se la identifica como una no aglomeración
Segunda prueba con basura
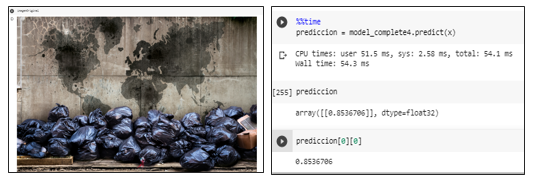
Prueba del modelo prediciendo una imagen con basura mostrando una probabilidad mayor a un umbral de 0.5 se la identifica como una aglomeración
Tercera prueba con imagen de diferentes colores
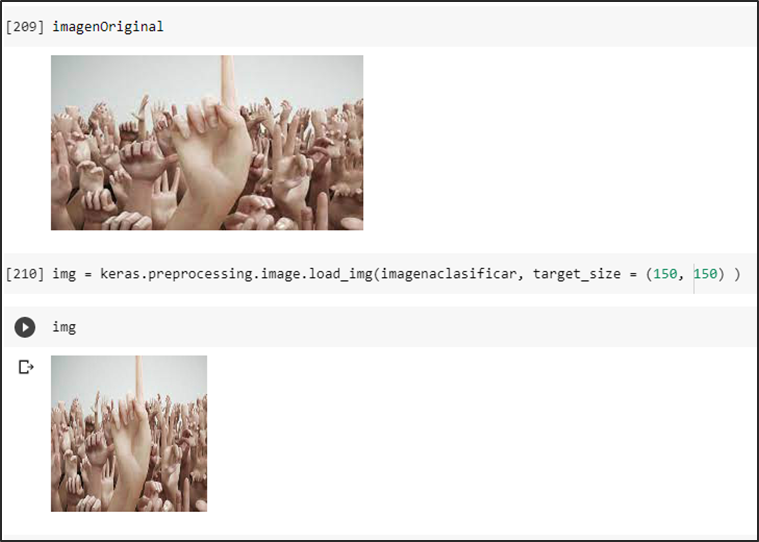
Prueba del modelo prediciendo una imagen falsa positiva intentando romper la predicción en consecuencia se obtiene una probabilidad menor a un umbral de 0.5 se la identifica como una no aglomeración
Métricas del modelo elegido: InceptionV3
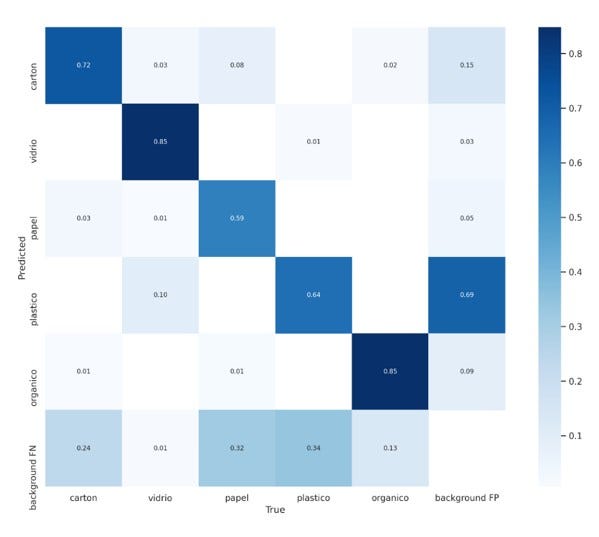
Matriz de confusión
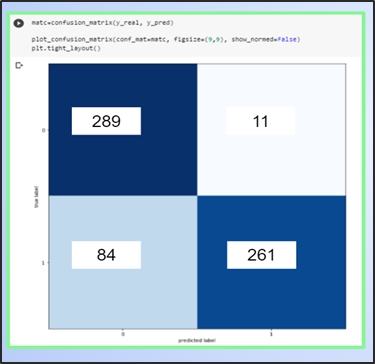
En la matriz de confusión podemos deducir que está prediciendo aceptablemente, pero puede mejorar la predicción de los falsos negativos esto se puede solucionar aumentando imágenes de positivos para que el entrenamiento del modelo mejore los positivos
Métricas
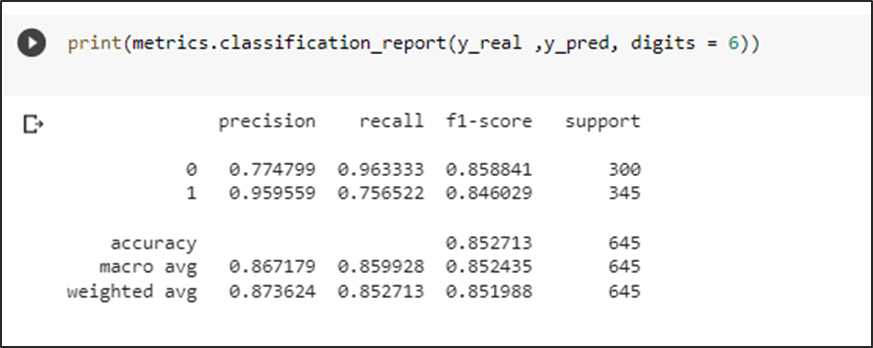
Las métricas obtenidas son aceptables con un f1 score del 85 % de predicción para casos negativos y un 84 % para casos positivos, esto confirmaría la teoría de aumentar los datos en positivos
Aplicación móvil (“Ciudad Limpia”)
Por qué elegimos App Inventor?
En la actualidad, existen muchas maneras de desarrollar aplicaciones en dispositivos móviles que cumplen con una función en específico y son compatibles con distintos sistemas operativos.
Es por esto, que se seleccionó como herramienta de programación y desarrollo de nuestra App “Ciudad Limpia” al entorno de App Inventor . Mediante esta plataforma se puede programar en JavaScript de manera fácil y sencilla debido a que utiliza una programación en bloques que permite un mayor entendimiento y uso por parte del usuario.
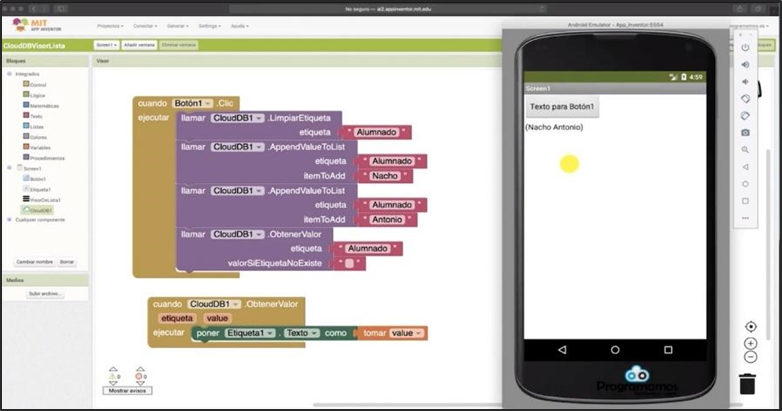
Arquitectura
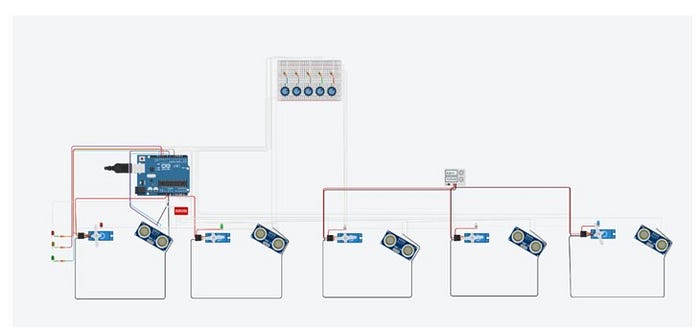
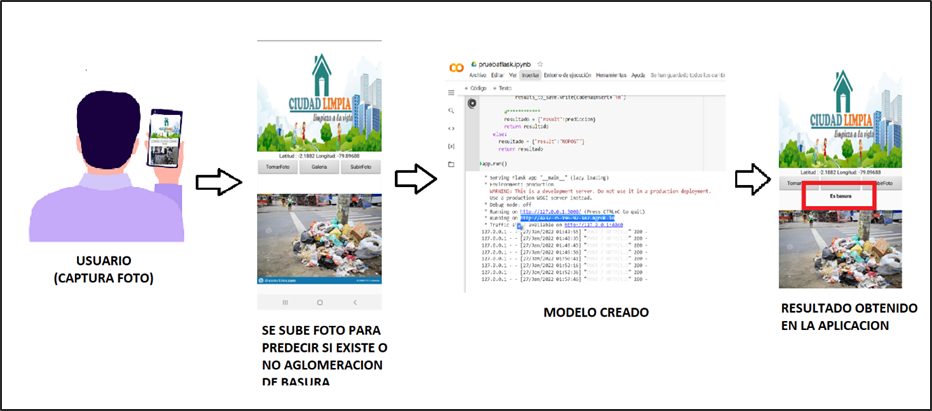
Con respecto a la arquitectura de nuestra aplicación “Ciudad Limpia”, se tiene los siguientes pasos a seguir, tal como se observa en la siguiente ilustración ():
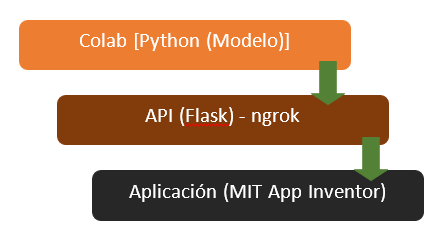
Conexión de App Inventor con Google Colab
La conexión de la aplicación “Ciudad Limpia” con el modelo creado a través de Google Colab se realiza a través de la creación de un servidor local expuesto al Internet para el acceso de la aplicación móvil utilizando ngrok. Realizando una petición POST desde APP Inventor, se realiza el envío de la imagen codificada en bit64 al servidor el cual ejecuta el modelo y devuelve el resultado obtenido clasificado como aglomeración o no aglomeración de basura.
Funcionalidad de la aplicación «Ciudad Limpia»
Con respecto al entorno y manejo de la App “Ciudad Limpia” se consideran tres botones dentro de la interfaz con distintas funciones al momento de procesar una fotografía:
· Usuario “toma foto”: En este caso, el usuario utiliza la cámara de su dispositivo para capturar la imagen de la aglomeración de basura en su sector.
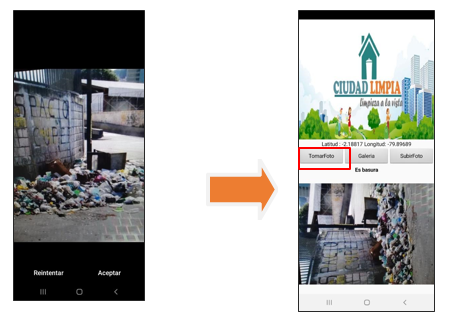
· Usuario selecciona “foto de galería”: En este caso, el usuario selecciona una foto que tenga registrado sobre la aglomeración de basura en su sector que encuentre dentro de su galería de imágenes de su celular.
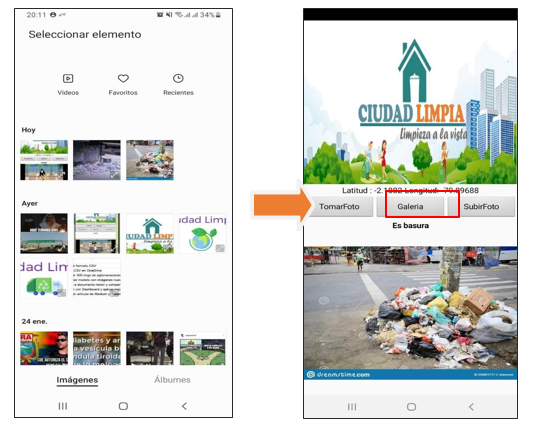
· Usuario “sube foto”: En este caso, el usuario sube la foto de la aglomeración de basura en su sector para que sea registrado y notificado a las autoridades pertinentes y se pueda visualizar dentro de la aplicación el resultado de si existe o no una aglomeración.

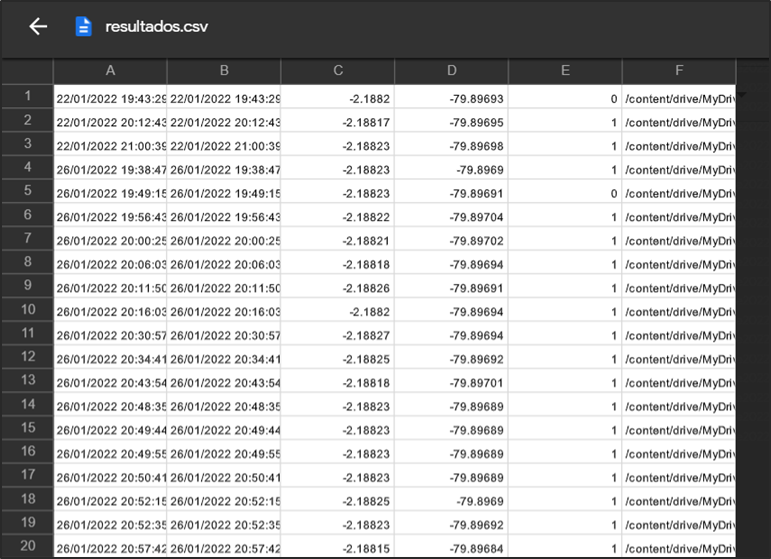
Almacenamiento de datos
Una vez realizada la predicción de la aglomeración de la basura dentro de la aplicación se procede a crear una base de datos a través de la aplicación de Google drive en extensión .csv, en donde se consideran los siguientes parámetros:
– Longitud
– Latitud
– Resultado de la predicción del modelo
– ID de la imagen capturada.
A continuación, se puede observar el archivo final generado con todos los datos que ha recolectado:
Funcionamiento de la interfaz
Herramienta BI
De acuerdo a los resultados que genera el modelo y los datos que guarda la aplicación web. Hemos considerado por uso en el mercado, la facilidad de uso, mejor visualización de objetos y desarrollar el tablero en Power BI.
Power BI es una herramienta que se utiliza principalmente para crear cuadros de mando que facilitan la toma de decisiones.
La información se puede actualizar de manera automatizada o manual y permite la compartición de los informes mediante la propia herramienta.
Por todo lo antes mencionado se procedió en la utilización de dicha herramienta.
Extracción de datos
Una vez que la aplicación web guardó los datos, realizamos los siguientes pasos que muestra la siguiente gráfica.

Mediante los campos: latitud, longitud, timestamp, aglomeración (1-Si, 0-No). Creamos un tablero que contenga varios objetos como KPI ‘s, gráficos de barras, gráficos pastel y hasta mapas. Así de manera visual tener una mejor comprensión de los resultados.
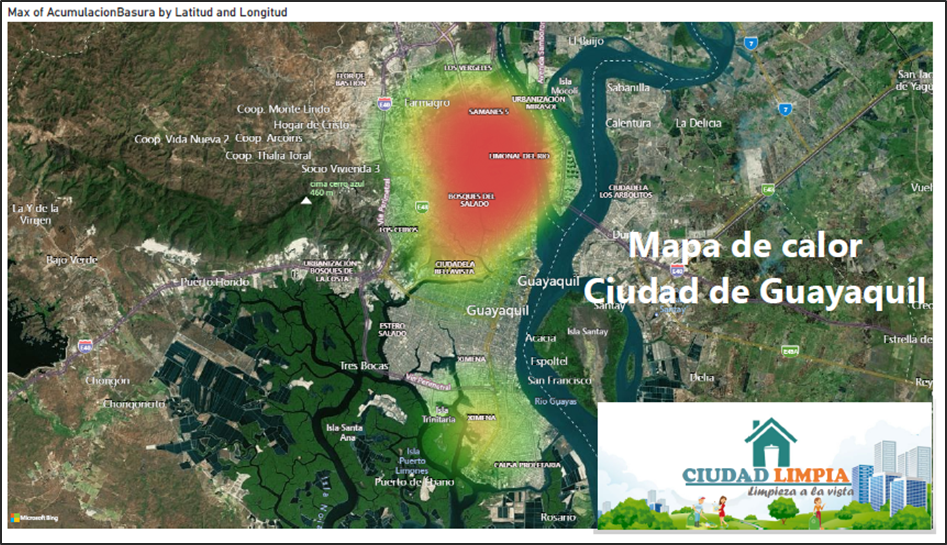
Dicha información nos permite poder identificar a través de un mapa en qué puntos de la ciudad tenemos más aglomeraciones de basura, en qué fechas y día se identificó la mayor cantidad de aglomeración y hacer una mejora en cuanto a la recolección de basura.
Recursos
· Basura: los números rojos de Ecuador. (2019, 6 marzo). Plan V. https://www.planv.com.ec/historias/sociedad/basura-numeros-rojos-ecuador
· F., & de Franspg, V. T. L. E. (2020, 20 septiembre). Generación de datos artificiales (Data Augmentation).
· World Bank Group. (2019, 6 marzo). Convivir con basura: el futuro que no queremos. World Bank. https://www.bancomundial.org/es/news/feature/2019/03/06/convivir-con-basura-el-futuro-que-no-queremos#:%7E:text=Se%20proyecta%20que%20la%20r%C3%A1pida,podr%C3%ADa%20ser%20la%20nueva%20normalidad.
Integrantes
- Ingrid León A.
- Alessandra Palacios
- Manuel Ahumada
- César Villarroet
- Patricia Andrade
- Iván Ortiz
- Diana López
- Diego Sánchez
Presentacion del proyecto: DemoDay
Repositorio
Toda la explicación en cuanto a implementación, código, entrenamiento del modelo, uso de interfaz y herramienta BI se puede encontrar en el siguiente link:
https://github.com/SaturdaysAI/Projects/tree/master/LATAM_remote/ciudadlimpia
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!