La Paz. Deep Learning. 2021
Las herramientas de visión artificial han demostrado vez tras vez el gran potencial que posee en sus distintas áreas de aplicación. Una de estas está justamente relacionada con los vehículos y sus conductores. Abarcando desde movilidades autónomas hasta herramientas de uso personal el espectro es muy amplio. Por ello, en este texto se explica la implementación de un detector de fatiga en conductores mediante Inteligencia Artificial utilizando OpenCV y Dlib.
DESCRIPCIÓN DEL PROBLEMA
Los accidentes de tránsito son una de las principales causas de muerte en ciudadanos de todos los países. Estos se pueden clasificar de acuerdo a sus causas. Se calcula que entre un 20% y un 30% de los accidentes se deben a conductores que conducen con fatiga. Si bien la fatiga al conducir es un riesgo evitable, lastimosamente, muchos conductores no toman las precauciones necesarias cuando conducen por periodos prolongados de tiempo. Por lo tanto, los conductores con fatiga pueden beneficiarse de un sistema de Inteligencia Artificial que los alerte al momento de perder la atención.
OBJETIVO
Diseñar un sistema para detectar la fatiga en conductores.
SELECCIÓN DEL MODELO
Se seleccionó un modelo de visión artificial pre entrenado basado en la librería cv2 de OpenCV y dlib para detección facial.
TÉCNICAS IMPLEMENTADAS
- OpenCV: La biblioteca libre de visión artificial que se está usando para obtener la imagen del conductor.
- Dlib face landmarks: Son 68 puntos que se colocan sobre el rostro detectado para la identificación de facciones faciales, en este caso los ojos.
- NumPy: Esta biblioteca se está usando para el cálculo de la proporción de abertura de los ojos, mediante álgebra lineal y el posicionamiento de los puntos faciales de los ojos.
EVALUACIÓN DE MODELOS
El sistema construido hace uso de un modelo pre entrenado de detección facial. Con ayuda de las bibliotecas previamente mencionadas se realiza un procedimiento como sigue:
- Se carga el modelo detector y predictor que son los que detectan el rostro del conductor así como los 68 puntos faciales.
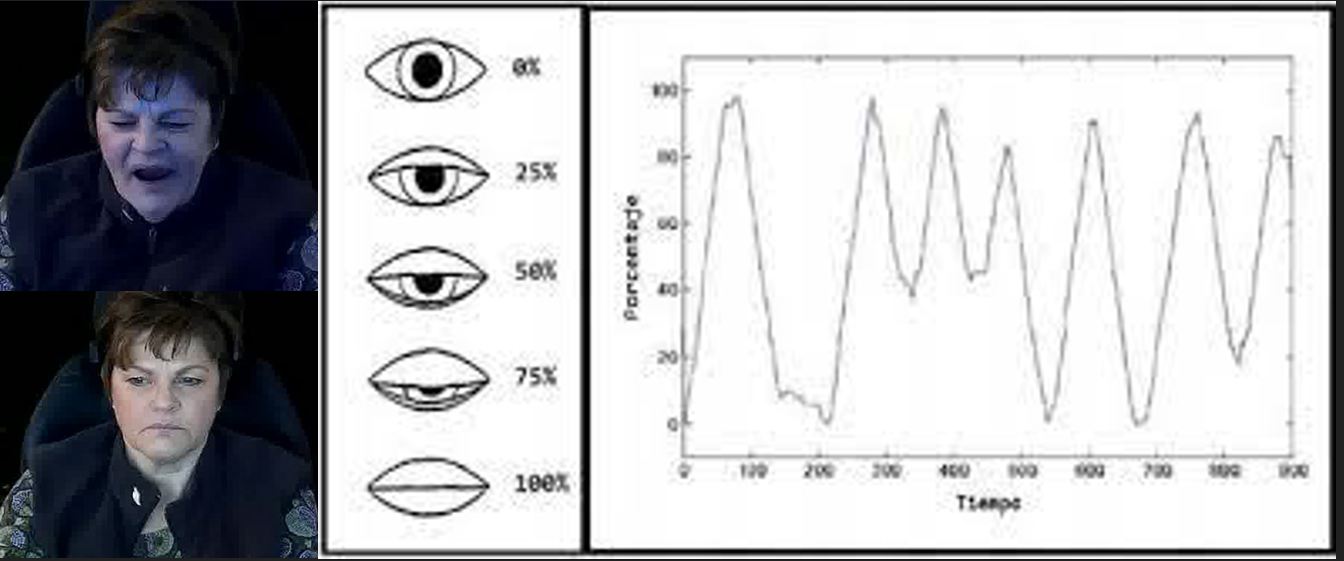
- Una función lineal detecta la proporción de aspecto en los ojos midiendo distancias entre los puntos oculares.
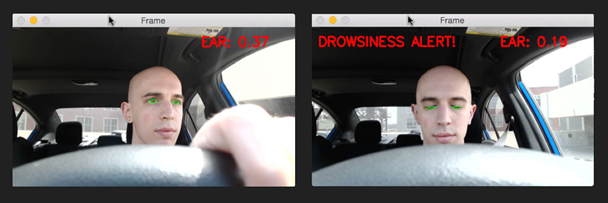
- Según el valor que se obtenga en esta proporción el programa se ramifica según el estado que considere correspondiente (despierto, cansado o dormido). Para que se considere la transición de un estado a otro debe haber una permanencia en ese estado durante un periodo de tiempo.
- El sistema indica en pantalla el estado identificado, este es el paso donde podría activarse o no una alarma.
- Este procedimiento se realiza fotograma a fotograma para tener una predicción constante del estado de fatiga de la persona.
ANÁLISIS DE RESULTADOS
Como se utilizó un modelo pre entrenado los resultados obtenidos por el detector facial y de los puntos de referencia del rostro son buenos.

Sin embargo, los resultados que obtuvimos en la detección del estado de fatiga son más bien fluctuantes. En ocasiones el sistema es poco sensible y no detecta estados con los ojos cerrados o, por el contrario, el sistema es pronto para indicar un estado posiblemente falso. Las razones que podrían causar este problema incluyen la calidad del video y el enfoque exclusivo en los ojos del conductor (cuando podrían tomarse en consideración otros factores como la boca).

CONCLUSIÓN
El proyecto ha desarrollado un sistema funcional capaz de detectar la fatiga en conductores de vehículos. La consistencia en estas detecciones no es buena así que se proponen algunas sugerencias: Aplicar operaciones de erosión y dilatación para reducir el ruido en la captura de video, implementar un sistema que detecte la proporción de abertura de la boca para aumentar la consistencia, y modificar los umbrales de detección para ajustarse a las necesidades de cada conductor.
INTEGRANTES
Carlos Claure –https://www.linkedin.com/in/carlos-manuel-claure-vargas-475226212
Raquel Calle –https://www.linkedin.com/in/raquel-veranda-calle-zapata-460226212
Liders Limpias –https://www.linkedin.com/in/limpiaslider/
Alejandro Carrasco. –https://www.linkedin.com/in/miguel-alejandro-carrasco-c%C3%A9spedes-785717215/
REFERENCIAS
Presentación del proyecto: DemoDay
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!Saturdays.AI

WRITTEN BY
Raquel Calle

Saturdays.AI
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.