Cómo la inteligencia artificial está revolucionando la ingeniería biomédica con una interfaz cerebro-médula espinal entrenada con IA, permitiendo a Gert-Jan Oskam recuperar la movilidad después de 12 años de paraplejia.

Cómo la inteligencia artificial está revolucionando la ingeniería biomédica con una interfaz cerebro-médula espinal entrenada con IA, permitiendo a Gert-Jan Oskam recuperar la movilidad después de 12 años de paraplejia.

Este artículo analiza los desafíos en la regulación de la inteligencia artificial, explorando enfoques regulatorios en diferentes países y la importancia de la cooperación internacional.
El glaucoma es una enfermedad que afecta al nervio óptico. Si este no se trata de manera precoz puede provocar ceguera. Según afirma la OMS, cada año, el glaucoma es la causa que millones de personas pierdan la vista. En el mundo, 2,2 billones de personas padecen discapacidad visual y de estas, un total de 1 billones hubieran podido controlar esta enfermedad a partir de un diagnóstico previo.
El uso de la inteligencia artificial en este campo, nos podría ayudar enormemente a diagnosticar a los pacientes de manera preventiva. Para su uso, a través de imágenes de fondo de ojo tomadas a partir de bases de datos públicos, todas ellas catalogadas por especialistas en el campo de la medicina y tomadas por un tomógrafo de coherencia óptica.
Una vez adquirimos las distintas imágenes de fondo de ojo, estas serán destinadas para el entrenamiento del desarrollo de la red neuronal. La totalidad de éstas, teniendo en cuenta que previamente han sido debidamente analizadas por especialistas y obtenidas de varios centros médicos, se clasifican en:
-Sospecha de enfermedad de glaucoma
-Paciente sano
-Suma total de todas estas
(Descartando previamente por otro lado todas aquellas que habían salido defectuosas)
En el caso del estudio llevado a cabo en la Universidad Politécnica Salesiana, se utilizó Python con el interpretador de Jupyter Notebook que al ser una extensión de Python no necesitaba de otras descargas de programas adicionales en el PC y tampoco de ningún tipo de licencia. Por tanto, una vez conseguido este procedimiento, las imágenes proporcionadas por parte de diversos centros de medicina que conformaron la base de datos fueron separadas en distintas carpetas siendo estas mismas separadas de nuevo en otras dos: una con la clasificación de los pacientes sanos y otros con sospecha de glaucoma.
Las imágenes, extraídas a partir de un tomógrafo de coherencia óptica, fueron debidamente recortadas hasta conseguir aislar el disco óptico ya que esta es la región de interés para el diagnóstico. Para ello se creó un algoritmo con dos objetivos muy marcados: primeramente, que la imagen fuera normalizada a dimensiones parecidas a las de un cuadrado y segundo, que estas también tuvieran centradas la ubicación de región de interés.
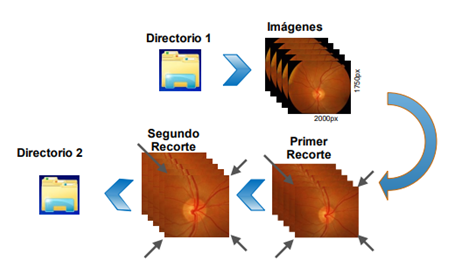
Posteriormente, a fin de poder procesar estas imágenes correctamente se trató que todas fueran del mismo tamaño para agilizar el proceso. Seguidamente, fueron clasificadas en dos carpetas distintas (sospecha y sano) para entrenar correctamente a la red convolucional y reservando por otra parte las que serían usadas para la prueba de la matriz de confusión.
En conclusión, esta propuesta de detección de glaucoma es una de las múltiples que podemos encontrar a día de hoy para el diagnóstico de ésta enfermedad. Desgraciadamente, no tiene una solución óptima, pero sabemos que si la diagnosticamos en una etapa temprana podemos tratarla para paliar algunos de los síntomas. Por otra parte también sabemos que la red neuronal depende de la base de datos que dispongamos. Por tanto, la precisión de los resultados conseguidos dependerá del tamaño del batch, dimensiones de las imágenes, cantidad de capas convulsionales… entre otros siendo necesario el entrenamiento de nuestro modelo.
Si quieres formar parte de la búsqueda de soluciones óptimas, no dudes en comenzar o continuar tu formación en Inteligencia Artificial con nosotros. Consulta los cursos de Saturdays.AI y elige el que más te guste en nuestra web.
1.-Buri Abad, Edison Arturo. Procesamiento de imágenes digitales del fondo de ojo con el uso de inteligencia artificial para brindar una herramienta de soporte de diagnóstico presuntivo del glaucoma humano. Feb-2022.
2.-Mayo Clinic. Glaucoma. Consultar en: https://www.mayoclinic.org/es-es/diseases-conditions/glaucoma/symptoms-causes/syc 20372839#:~:text=El%20glaucoma%20es%20un%20grupo,personas%20mayores%20de%2060%20a%C3%B1os.
Eva Arnall

Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education

Redes Neuronales aplicadas a la seguridad vial, proyecto «Focus on Driving» – inteligencia artificial para conducir mejor

Donostia. Primera edición. 2020
En la vida cotidiana, ¿Cuántas veces nos ocurre que preguntamos a una persona qué tal está, y la respuesta es positiva mientras que su rostro indica lo contrario? ¿Cuántas veces has ido a la peluquería y has pretendido salir contenta cuando realmente, no te gustaba el resultado final? ¿Alguna vez has querido recibir el feedback de miles de personas en una conferencia o en el transcurso de ella?

Si nos ponemos a reflexionar sobre las cuestiones mencionadas, probablemente nos daremos cuenta de que muchas veces se miente cuando se tratan las emociones, ¿pero nuestra cara también miente?
Muchas veces se da más importancia a lo que se dice con la voz, que a lo que se dice con la expresión facial, siendo más fácil mentir o esconder la realidad con la primera de ellas. Con este proyecto queríamos, además de desplegar un proyecto real de inteligencia artificial, hacer algo que pudiese ser útil, pudiese detectar las emociones de las personas según su cara, mediante una imagen o la detección de la cara con una webcam. Las emociones surgen cuando ocurre algo relevante. Aparecen rápidamente, de forma automática, y hacen cambiar nuestro foco de atención.
La inteligencia emocional es algo que ha ido adquiriendo mucha relevancia los últimos años, la importancia en percibir, usar, comprender y manejar las emociones, tanto las correspondientes a uno mismo como a las del resto. Para ello, es evidente que necesitamos emociones reales, por lo que queríamos facilitar la forma en la que se pueden percibir las emociones. ¿Será una máquina capaz de detectar y clasificar las emociones mejor que el ser humano?
Facial Expression Recogniser será una aplicación encargada de detectar las emociones a tiempo real. En esta primera versión se utilizarán las imágenes y, a continuación, su función será clasificar las emociones en cuanto la cámara pueda detectar caras.
El dataset utilizado para el desarrollo de este proyecto, que se obtuvo en Kaggle, consistía en una serie de imágenes divididas en carpetas en función de la expresión de rostro. Las etiquetas de las carpetas se dividían según la siguiente clasificación:
0 — Angry
1 — Disgust
2 — Fear
3 — Happy emotions
4 — Sad
5 — Surprise
6 — Neutral
El objetivo principal del proyecto era detectar y clasificar las emociones según estas etiquetas. Para dicha predicción, se usaría imágenes obtenidas mediante la webcam.

Tal y como ha sido mencionado con anterioridad, a la hora de describir el dataset utilizado, se ha visto que se contaba con imágenes y con las etiquetas de las emociones correspondientes. Esto ha hecho que el proceso de EDA haya restado importancia en este proyecto.
Sin embargo, si ha sido necesario cierto análisis y transformación de los datos. Para empezar, se ha tenido que crear dataframes partiendo del dataset. Para ello, se ha pasado de las fotos que se tenían a pixeles, y se han creado dos columnas en dicha tabla, una la relacionada con la emoción y la otra con los píxeles.

Además, cabe destacar que desde un inicio se contaba con una clasificación del dataset entre train y test, por lo que la transformación de imágenes a pixels se hizo dos veces, terminando así con dos dataframes: train_data y test_data

El proyecto realizado se basa en Deep Learning, por lo que ha sido necesario el uso de redes neuronales. En nuestro caso, se han utilizado redes neuronales convolucionales, las cuales se utilizan sobre todo para tareas de visión artificial, pues son muy efectivas en la clasificación y segmentación de imágenes, entre otras aplicaciones.
Para ello, se ha presentado un modelo secuencial, lo que permite apilar capas secuenciales en orden de entrada a salida.


Las capas añadidas al modelo han sido:
– Conv2D
– Batch Normalization
– MaxPooling2D
– Flatten
– Dense
– Activation
– Dropout
Para crear el modelo anteriormente mencionado, se ha utilizado Tensorflow y Keras. Este último es una biblioteca de Redes Neuronales escrita en Python. Es capaz de ejecutarse sobre TensorFlow. Este último satisface las necesidades de los sistemas capaces de construir y entrenar redes neuronales para detectar y descifrar patrones y correlaciones.
Después de crear el modelo se inició el entrenamiento del modelo. Al principio, se entrenó el modelo con un solo epoch, lo que además de tardar mucho tiempo, solo obtuvo un accuracy del 0,29. Es por esto por lo que se tuvo que modificar el entrenamiento del modelo, aumentando los epochs, cambiando los pasos a dar en cada epoch, etc.
Además, debido a un problema de guardado se tuvo que crear un callback al ModelCheckpoint, para que almacenará un checkpoint cada vez que un epoch finalizara, así, se pudo obtener un modelo final con más epochs.
Al final, el modelo obtenido ha conseguido un accuracy final del 0.9602. Esto indica la precisión de lo que se entrenó. Sin embargo, si analizamos el val_accuracy, el cual se refiere a cuánto funciona su modelo en general para casos fuera del conjunto de entrenamiento, el valor obtenido ha sido del 0.6035.

Sin embargo, si calculamos la precisión del modelo con el dataset utilizado para el testeo, veremos que el accuracy es bastante bajo, del 0,1733, lo que implica tener mucho margen de mejora este modelo.

Una vez tuviésemos el modelo listo, había que predecir y probarlo. Para ello, se codificó de forma que nos indicase aquellas emociones que se podían considerar en la expresión facial de la imagen introducida, y según el porcentaje, concluir con el sentimiento más significativo. Por ejemplo:

Introducimos esta primera imagen, donde es evidente que el chico está mostrando cierto enfado. De esta forma, nuestro modelo lo ha clasificado de la siguiente manera:


Recalcando que el enfado es el sentimiento que predomina en la imagen. Si utilizamos nuestro modelo, con el fin de detectar alguna otra emoción, veremos que también funciona.

Tal y como se mencionara en las conclusiones, la intención era incorporar la detección de caras mediante las webcam y así, poder detectar las emociones de una forma más real.
Una vez finalizado el proyecto, en una reflexión grupal, se comentó lo mucho que se ha aprendido en el desarrollo de este mismo, además de habernos dado cuenta de lo lejos que puede llegar la tecnología, y para ser más precisos la inteligencia artificial.
Hemos visto que en este ámbito de reconocimiento facial se están dando grandes avances, existen modelos que reconocen rostros incluso llevando la mascarilla puesta, y las aplicaciones de esta tecnología sólo están limitadas por nuestra imaginación. Desde el punto de vista de marketing, recoger el feedback de los usuarios y clientes es un proceso muy importante, pero obtener esta información suele costar, casi nadie nos paramos a rellenar un formulario para decir cómo ha sido nuestra experiencia a menos que haya sido negativa.
Es por ello que si somos capaces de detectar puntos rojos en la experiencia de los usuarios sin que suponga para ellos un esfuerzo más se podría mejorar el servicio, y gracias a esta tecnología esto sí es posible.
Los próximos pasos que se darán con este proyecto están directamente relacionados con los problemas que se han tenido en la culminación del proyecto. La primera dificultad sufrida por el equipo fue la correspondiente al despliegue en Amazon Web Services, lo que debía facilitar el entrenamiento, hizo que el proyecto quedase parado dada la inexperiencia de los integrantes del equipo con dicha herramienta. Esto ha hecho que el entrenamiento no se pudiese hacer en los servidores de Amazon, lo que ha tardado mucho tiempo y dificulta cualquier modificación y ejecución en el modelo. Es por esto por lo que, próximamente, se intentará realizar dicho despliegue para poder trabajar de una manera más eficiente y eficaz.
Este problema hizo que la desviación sufrida en el tiempo fuese muy elevada, lo que dificultó la culminación de toda la funcionalidad que previmos en primera instancia. Además, esto también estaba directamente relacionado con el pequeño margen que nos quedaba para entrenar el modelo, lo que implica que la eficacia y precisión del modelo no sea la óptima, y aun quede un margen bastante amplio de mejora. Es por esto por lo que se podría, mediante más entrenamientos, obtener un modelo de mayor calidad.
No considerábamos tener tantos problemas cuando definimos el proyecto que queríamos realizar, debido a la inexperiencia que teníamos en este ámbito. Una de las funcionalidades que planteamos al principio era la incorporación de una Web Cam que nos permitiera sacar fotos al instante y poder clasificar las emociones de dicha imagen, para poder hacerlo más real. Sin embargo, debido a la falta de tiempo, es un aspecto que no se ha podido desarrollar pero que sería lo primero que realizaríamos en el futuro.
Sería muy útil integrar nuestro modelo con webcams en las entradas/salidas de todos aquellos lugares que quieran valorar la satisfacción o experiencia del cliente en dicho lugar. Por ejemplo, restaurantes, tiendas, conferencias, etc.
Además, en el futuro sería genial programar que la aplicación fuese capaz de reconocer una imagen tomada en la salida de un lugar con aquella imagen tomada en la entrada a la misma persona. Eso haría que se pudiese comparar eficientemente los resultados de todos los usuarios, y sería un paso adelante enorme ya que dotaríamos a la empresa/institución que lo utilice de inteligencia empresarial. Si a eso le sumásemos una serie de gráficos que visualicen los resultados en una especie de dashboard, podría ayudar a los directivos a tomar diversas decisiones en base a la satisfacción del cliente.
En el siguiente repositorio se encuentra el código usuado para desarrollar esta aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Donostia/Donostia2020/Facial_Expression_Saturdays
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!



Latam online. Segunda Edición. 2021
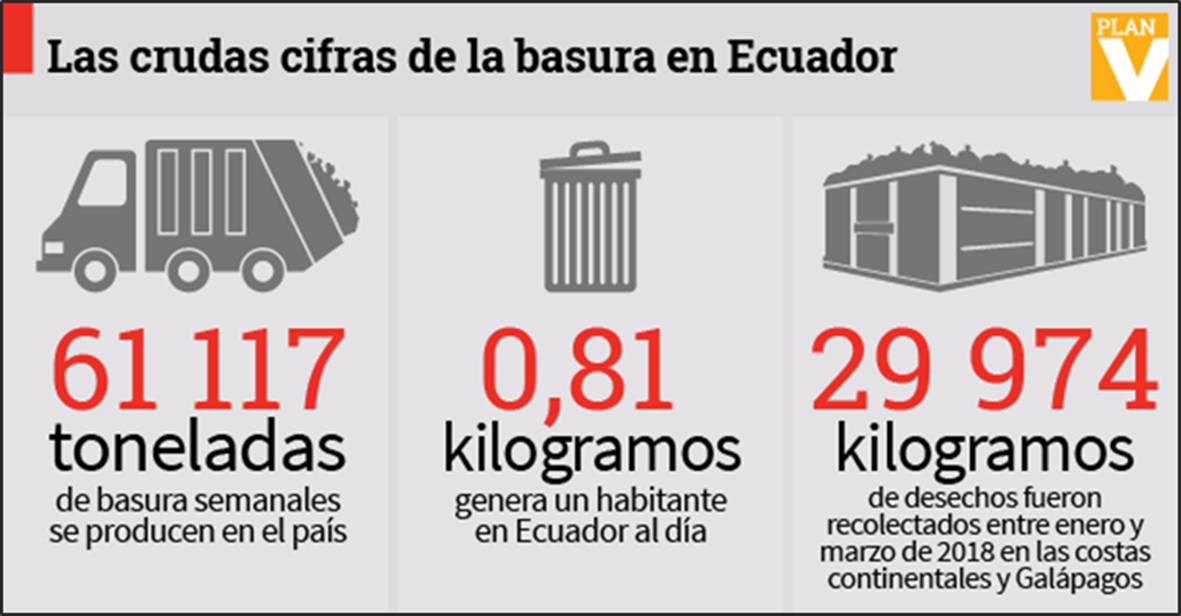
En la actualidad, los desechos municipales a nivel mundial podrían aumentar un 70% en los próximos 30 años, provocando así montones de basura acumulados alrededor del mundo (Banco Mundial, 2019). Es por esto que, si no se toman medidas urgentes, se espera un futuro donde el convivir con basura sea algo normal para la sociedad.
Debido a las consecuencias de las acumulaciones de basura no controladas ni planificadas se deben tomar diferentes estrategias que amortigüen sus ocurrencias en distintos puntos del mundo.
El problema de la acumulación de basura no solo radica en el mal olor que se percibe, sino la imagen de insalubridad, desorden y hasta de inseguridad que la basura se desparrama en las calles genera. En las calles se puede encontrar desde cartones y pañales, hasta cáscaras de frutas, plástico y sábanas viejas. Todo esto al pie del canal de aguas lluvias, en cuyas bases también es común ver flotando todo tipo de desechos.
Según el Ministerio del Ambiente, en el Ecuador la más crítica es la Costa, en donde apenas el 10% de los municipios dispone de un relleno sanitario, manual o mecanizado; en la región Sierra son 25%, y en el Oriente, el 24%. Por lo que las cifras de basura dentro del país aumentan diariamente tal y como se visualiza en la Figura 2.
En la figura 2.1, se visualizan algunas de las consecuencias de la acumulación de basura como lo son: daños en la infraestructura pública, aumento de enfermedades y plagas, inundaciones en las calles, obstrucción en los alcantarillados y entre otros.

En la ciudad de Guayaquil, las penas por desechar desechos sólidos no peligrosos al margen de la frecuencia y horarios establecidos y acumular la basura en parterres y aceras; van desde los $80 a $500 .

Ciudad Limpia se basó en la siguiente pregunta : ¿Cómo identificar de manera oportuna la acumulación de la basura no controlada en la ciudad de Guayaquil para minimizar el impacto en la sociedad? Por tal motivo creamos una aplicación que nos permite contribuir en la recolección de basura. Haciendo participe a la ciudadanía en mejorar la limpieza de la ciudad y que alguna empresa se interese en nuestra herramienta tecnológica basada en Inteligencia artificial.

Manuel Ahumada “Fue una experiencia de aprendizaje práctico: enfocado en el hacer para adquirir los temas y conceptos presentados. Eso refuerza el conocimiento.”.
Patricia Andrade “Mi experiencia fue muy enriquecedora debido a todo el nuevo conocimiento que aprendí. Además, me gustó mucho el compartir ideas con compañeros de distintos campos para solucionar un problema práctico”.
César Villarroel “Fue una experiencia de aprendizaje práctico: enfocado en el hacer para lograr adquirir los temas y conceptos presentados. Eso refuerza el conocimiento.”.
Ingrid León “La experiencia que se obtiene en esta modalidad es buena, El poder compartir conocimientos, desafíos y riesgos hacen que seamos más profesiones. Me quedo con una frase “«Son dos las opciones básicas: aceptar las condiciones como existen o aceptar la responsabilidad de modificarlas»”, entonces podemos mejorar siempre”.
En la siguiente figura 4, se puede visualizar la idea principal del proyecto.
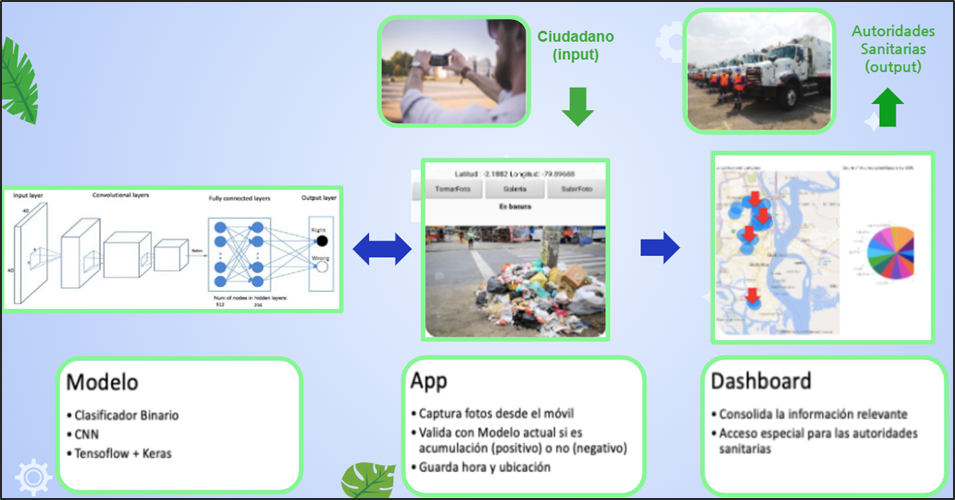
Desarrollar una aplicación basada en Inteligencia Artificial que permita identificar aglomeraciones de basura en la vía pública de zonas urbanas.
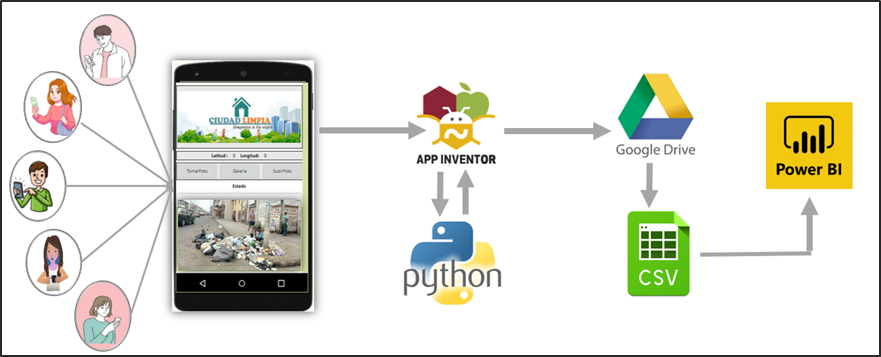
Se proyecta que mediante la colaboración de los ciudadanos se cree una concientización donde formen parte de la limpieza y cuidado de la ciudad. ¿Cómo lo van a hacer? Fácil, a través de la app “Ciudad Limpia” , en donde pueden tomar una foto para identificar y reportar la acumulación de basura de un sector determinado. Además, la aplicación registra la fecha, hora y ubicación del problema. Dicha aplicación estará basada en Inteligencia Artificial que permitirá identificar aglomeraciones de basura en la vía pública de zonas urbanas y fomentar un plan de acción inmediata para las autoridades sanitarias.
El conjunto de datos que se formó fue basado en descarga de imágenes de manera individual desde el Internet, videos transformados en fotogramas. Además, se sacó la plataforma de Kaggle y Google Street view donde se pudo obtener una gran cantidad de dataset de imágenes de aglomeración de basura.

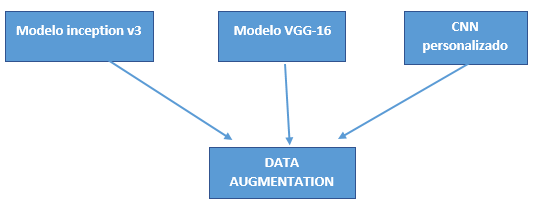
Para la selección de los modelos se obtuvo las siguientes consideraciones:
Estas consideraciones son debido a los recursos que se tienen para realizar el objetivo general. Los modelos a desarrollarse son:
La principal técnica utilizada para compensar el conjunto de datos de tamaño limitado por la limitación de búsqueda de imágenes en Google fue la “aumentación de datos” realizada por la librería de keras “ImageDataGenerator”.
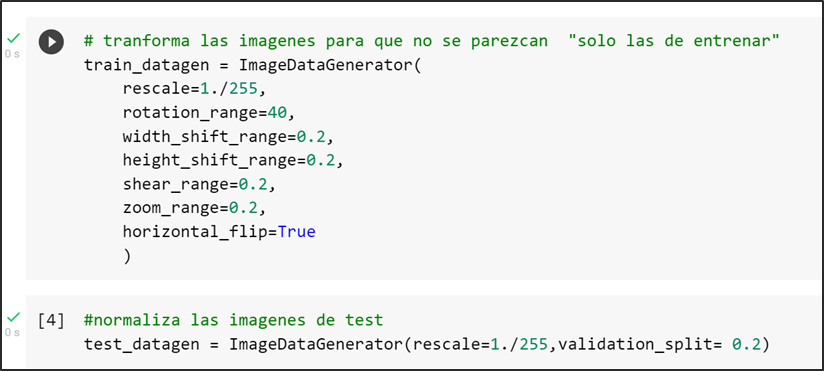
El aumento de datos es la generación artificial de datos por medio de perturbaciones en los datos originales. Esto nos permite aumentar tanto en tamaño como en diversidad nuestro conjunto de datos de entrenamiento. En el computer vision, esta técnica se convirtió en un estándar de regularización, y también para mejorar el rendimiento y combatir el overfitting en CNNs.

En los tres modelos seleccionados se consideraron la técnica de aumento de datos con el objetivo de normalizar o re-escalar los píxeles en un rango de 0 a 1. Además de modificar las imágenes del conjunto tren con el objetivo de que existe una distinción en cada una de las imágenes seleccionadas tanto de ancho, largo, amplitud, rotación y escalamiento. A continuación, se observa el código donde se transforman las imágenes de entrenamiento con los parámetros seleccionados:
En el modelo CNN personalizado se aplicaron técnicas de regulación, callbacks y por último keras tuner.
Keras Tuner es una librería muy sencilla de utilizar que simplifica en gran medida complejidad el proceso de aplicar de optimización de hiper-parámetros sobre redes de neuronas profundas construidas mediante Keras, ofreciéndonos un amplio grado de versatilidad para optimizar tanto la estructura de nuestra red como la configuración de los parámetros de algunos de los algoritmos implicados en el proceso de entrenamiento.
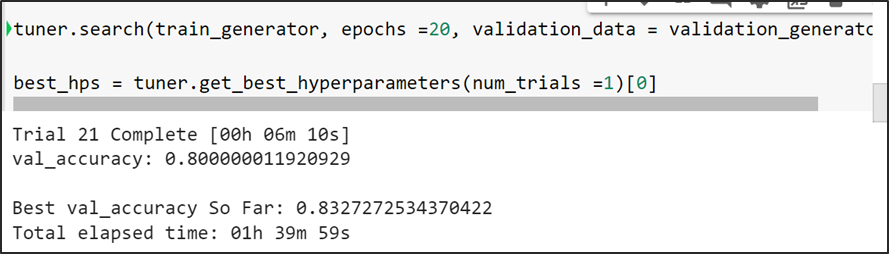
Keras Tuner mientras va analizando cada trial, verifica el mejor valor de val accuracy infiriendo que es la mejor configuración de la arquitectura y la procede a guardar la mejor configuración de la arquitectura del modelo (número de capas) con el cual tiende a lograr la mejor métrico.
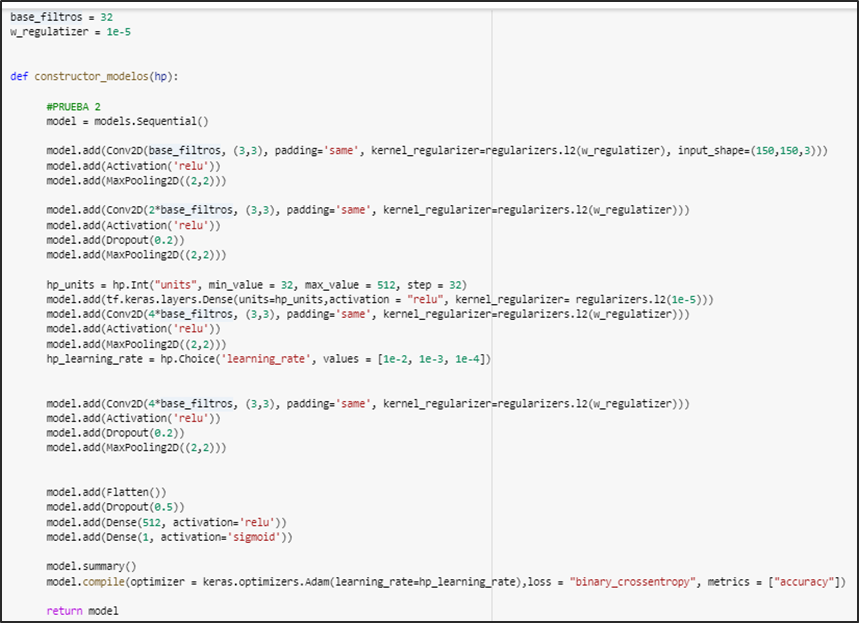
Arquitectura del modelo cnn personalizado cuenta con regularizadores, convolución, keras tuner
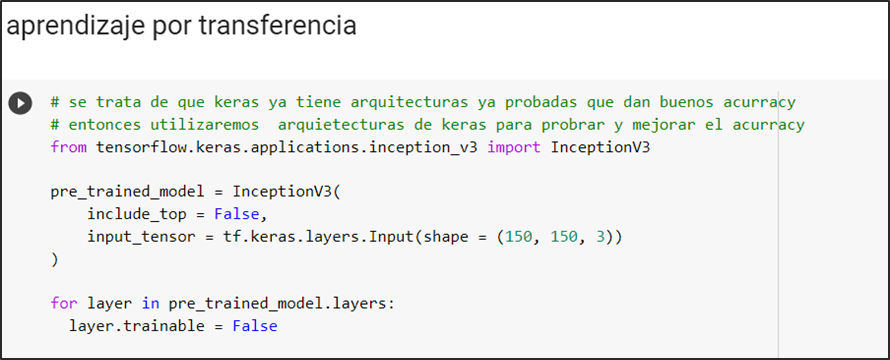
Se define el modelo pre-entrenado inceptionv3, valida el tamaño de las imágenes de input con que se entrena:
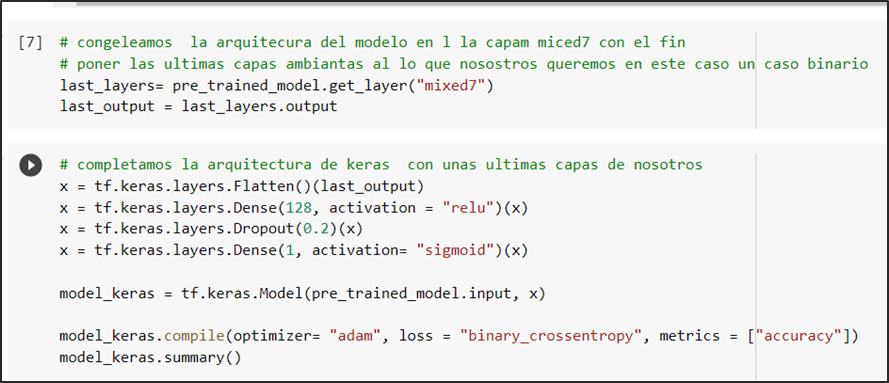
Se congela la arquitectura en la capa “mixed7” para después alterarla añadiendo capas basadas en la predicción de nuestro modelo que es una clasificación binaria por el cual la última capa tiene activación sigmoidal la cual nos ofrece como resultado la probabilidad de que si un caso es positivo o negativo

Se define el modelo pre-entrenado vgg16 y valida el size de las imágenes de input con que se entrena

Se procede a aumentar las capas basadas en la predicción de nuestro modelo que es una clasificación binaria por lo cual la última capa tiene activación sigmoidal la cual nos ofrece como resultado la probabilidad de que si un caso es positivo o negativo
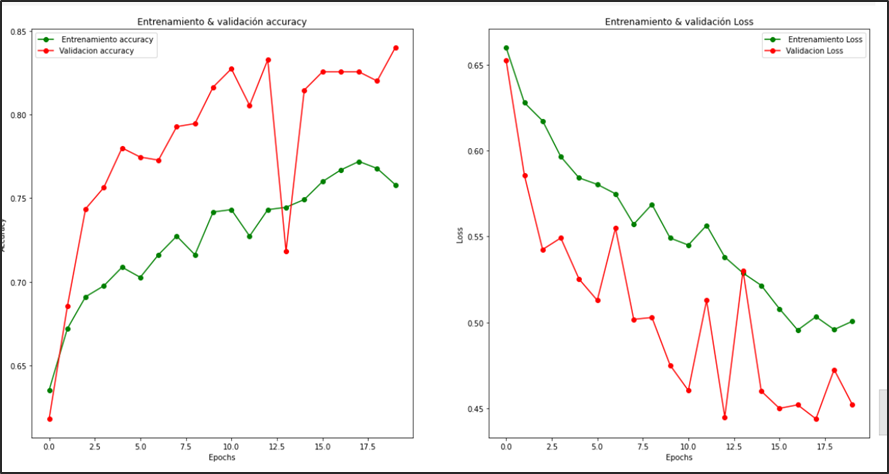
En la evaluación del modelo se entrenó con 20 épocas. Sé puede verificar que no logra converger en su totalidad. Logra una accuracy de la evaluación del conjunto test del 78 %

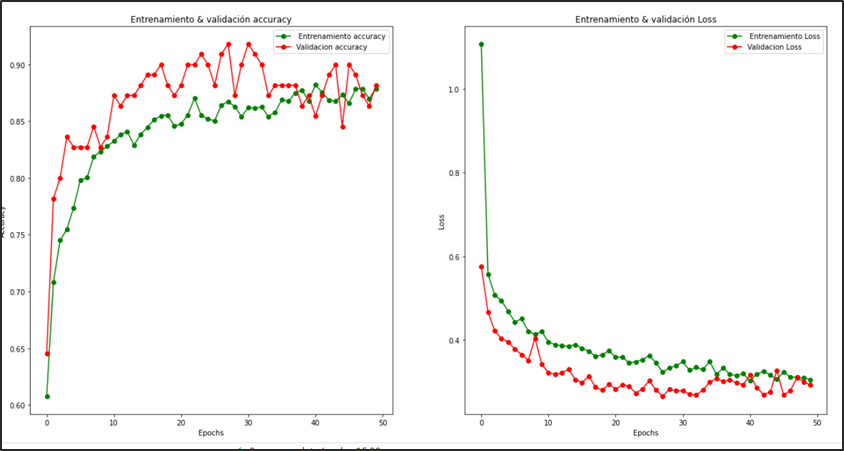
En la evaluación del modelo el cual se entrenó con 50 épocas se puede analizar que logra converger en totalidad a partir de la época 28 en adelante, con una precisión de la evaluación del conjunto test del 85 %

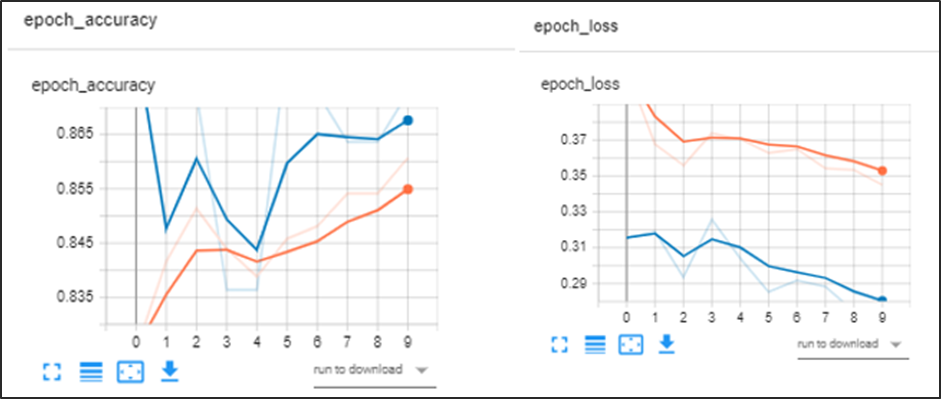
En la evaluación del modelo el cual se entrenó con 10 épocas se puede analizar que logra converger, con una precisión de la evaluación del conjunto test del 84 %

A continuación, mostramos las predicciones de los modelos:
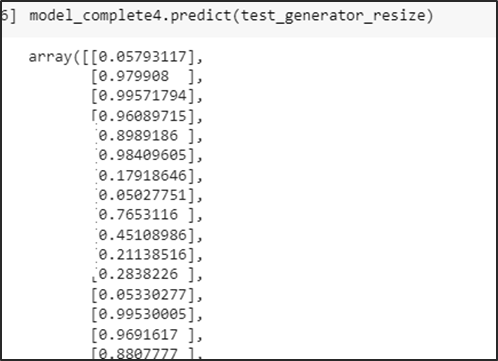
Se obtiene las probabilidades de predicción del conjunto test
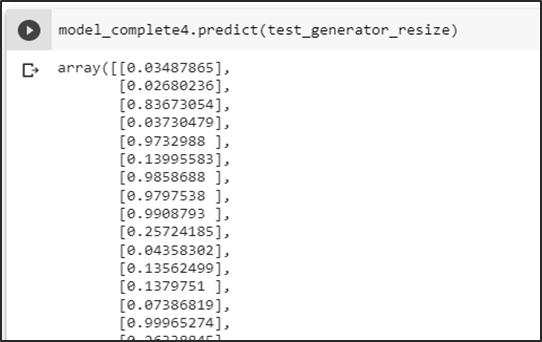
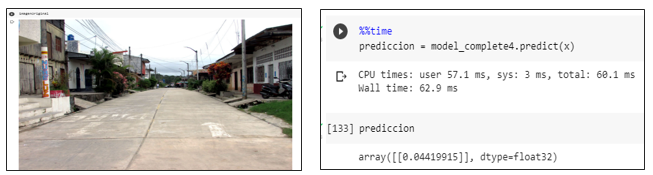
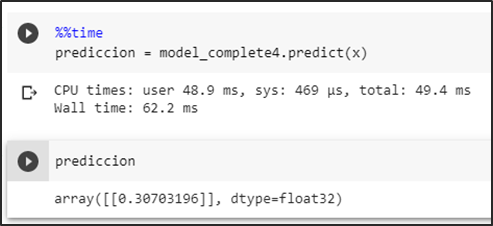
Prueba del modelo prediciendo una imagen sin basura dando como resultado una probabilidad menor a un umbral de 0.5 se la identifica como una no aglomeración.
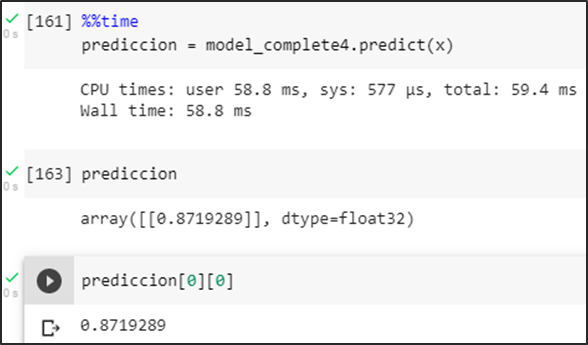
Prueba del modelo prediciendo una imagen con basura generando una probabilidad mayor a un umbral de 0.5 se la identifica como una aglomeración.

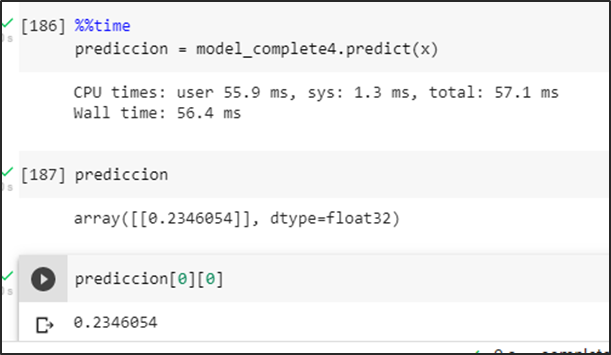
Prueba del modelo prediciendo una imagen falsa positiva intentando romper la predicción en consecuencia se obtiene una probabilidad menor a un umbral de 0.5 se la identifica como una no aglomeración
Se obtienen las probabilidades de predicción del conjunto test

Prueba del modelo prediciendo una imagen sin basura dando como resultado una probabilidad menor a un umbral de 0.5 se la identifica como una no aglomeración
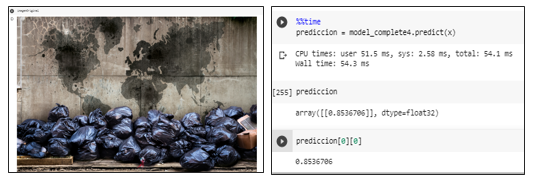
Prueba del modelo prediciendo una imagen con basura mostrando una probabilidad mayor a un umbral de 0.5 se la identifica como una aglomeración
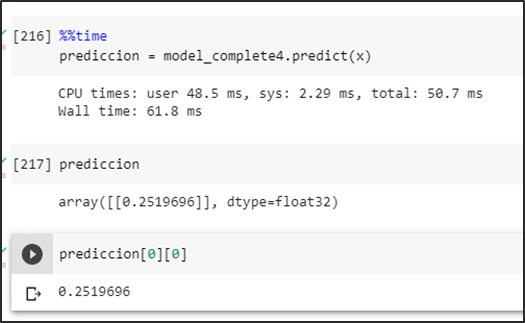
Prueba del modelo prediciendo una imagen falsa positiva intentando romper la predicción en consecuencia se obtiene una probabilidad menor a un umbral de 0.5 se la identifica como una no aglomeración
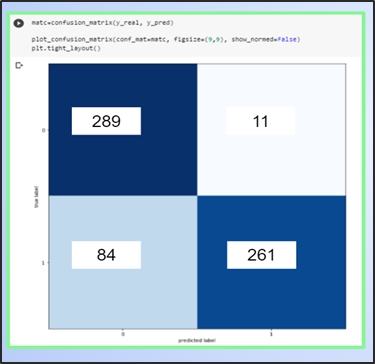
En la matriz de confusión podemos deducir que está prediciendo aceptablemente, pero puede mejorar la predicción de los falsos negativos esto se puede solucionar aumentando imágenes de positivos para que el entrenamiento del modelo mejore los positivos
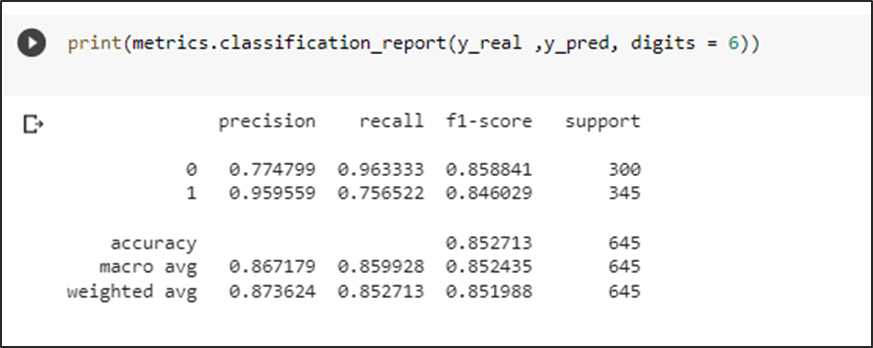
Las métricas obtenidas son aceptables con un f1 score del 85 % de predicción para casos negativos y un 84 % para casos positivos, esto confirmaría la teoría de aumentar los datos en positivos
En la actualidad, existen muchas maneras de desarrollar aplicaciones en dispositivos móviles que cumplen con una función en específico y son compatibles con distintos sistemas operativos.
Es por esto, que se seleccionó como herramienta de programación y desarrollo de nuestra App “Ciudad Limpia” al entorno de App Inventor . Mediante esta plataforma se puede programar en JavaScript de manera fácil y sencilla debido a que utiliza una programación en bloques que permite un mayor entendimiento y uso por parte del usuario.
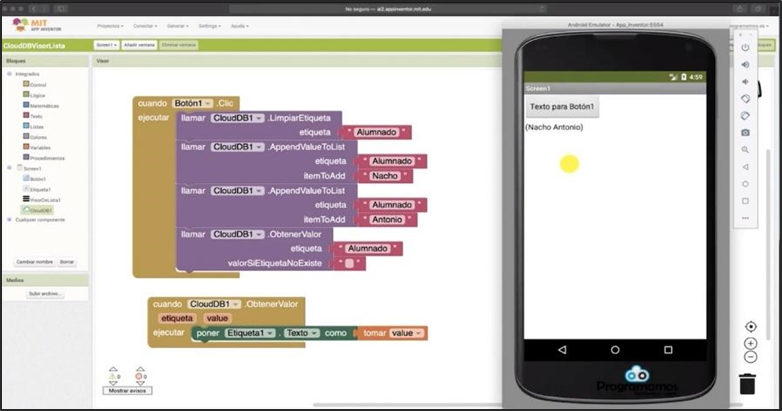
Con respecto a la arquitectura de nuestra aplicación “Ciudad Limpia”, se tiene los siguientes pasos a seguir, tal como se observa en la siguiente ilustración ():
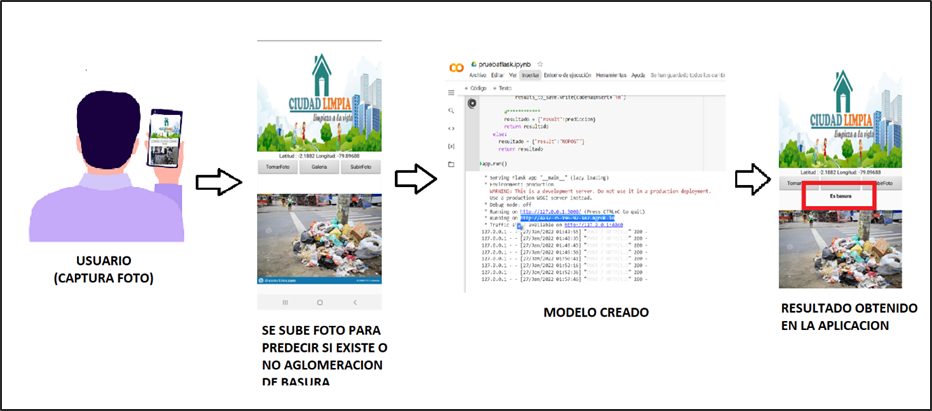
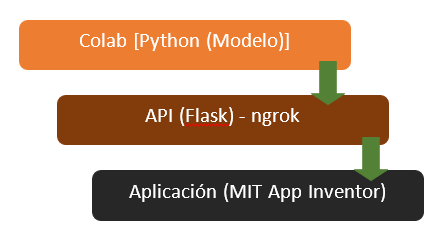
La conexión de la aplicación “Ciudad Limpia” con el modelo creado a través de Google Colab se realiza a través de la creación de un servidor local expuesto al Internet para el acceso de la aplicación móvil utilizando ngrok. Realizando una petición POST desde APP Inventor, se realiza el envío de la imagen codificada en bit64 al servidor el cual ejecuta el modelo y devuelve el resultado obtenido clasificado como aglomeración o no aglomeración de basura.
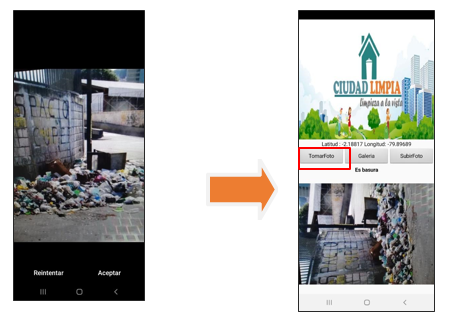
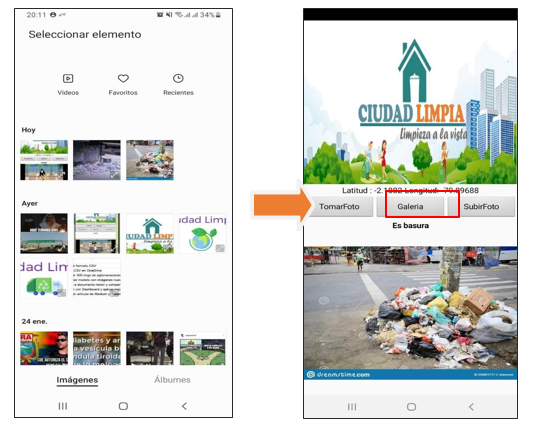
Con respecto al entorno y manejo de la App “Ciudad Limpia” se consideran tres botones dentro de la interfaz con distintas funciones al momento de procesar una fotografía:
· Usuario “toma foto”: En este caso, el usuario utiliza la cámara de su dispositivo para capturar la imagen de la aglomeración de basura en su sector.
· Usuario selecciona “foto de galería”: En este caso, el usuario selecciona una foto que tenga registrado sobre la aglomeración de basura en su sector que encuentre dentro de su galería de imágenes de su celular.
· Usuario “sube foto”: En este caso, el usuario sube la foto de la aglomeración de basura en su sector para que sea registrado y notificado a las autoridades pertinentes y se pueda visualizar dentro de la aplicación el resultado de si existe o no una aglomeración.

Una vez realizada la predicción de la aglomeración de la basura dentro de la aplicación se procede a crear una base de datos a través de la aplicación de Google drive en extensión .csv, en donde se consideran los siguientes parámetros:
– Longitud
– Latitud
– Resultado de la predicción del modelo
– ID de la imagen capturada.
A continuación, se puede observar el archivo final generado con todos los datos que ha recolectado:
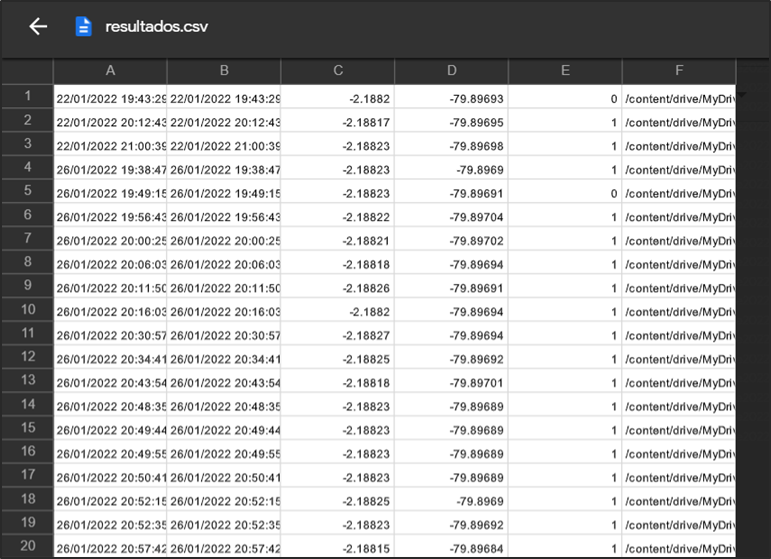
De acuerdo a los resultados que genera el modelo y los datos que guarda la aplicación web. Hemos considerado por uso en el mercado, la facilidad de uso, mejor visualización de objetos y desarrollar el tablero en Power BI.
Power BI es una herramienta que se utiliza principalmente para crear cuadros de mando que facilitan la toma de decisiones.
La información se puede actualizar de manera automatizada o manual y permite la compartición de los informes mediante la propia herramienta.
Por todo lo antes mencionado se procedió en la utilización de dicha herramienta.
Una vez que la aplicación web guardó los datos, realizamos los siguientes pasos que muestra la siguiente gráfica.

Mediante los campos: latitud, longitud, timestamp, aglomeración (1-Si, 0-No). Creamos un tablero que contenga varios objetos como KPI ‘s, gráficos de barras, gráficos pastel y hasta mapas. Así de manera visual tener una mejor comprensión de los resultados.
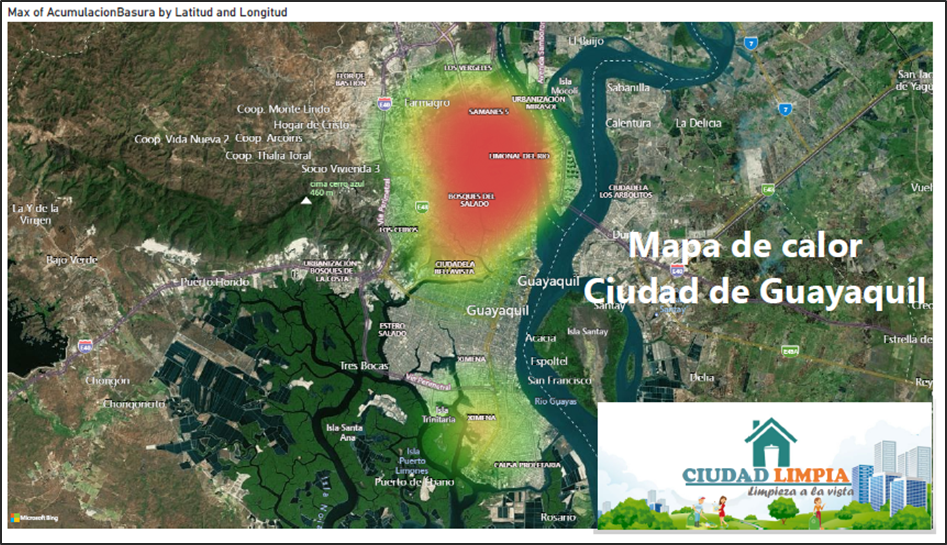
Dicha información nos permite poder identificar a través de un mapa en qué puntos de la ciudad tenemos más aglomeraciones de basura, en qué fechas y día se identificó la mayor cantidad de aglomeración y hacer una mejora en cuanto a la recolección de basura.
· Basura: los números rojos de Ecuador. (2019, 6 marzo). Plan V. https://www.planv.com.ec/historias/sociedad/basura-numeros-rojos-ecuador
· F., & de Franspg, V. T. L. E. (2020, 20 septiembre). Generación de datos artificiales (Data Augmentation).
· World Bank Group. (2019, 6 marzo). Convivir con basura: el futuro que no queremos. World Bank. https://www.bancomundial.org/es/news/feature/2019/03/06/convivir-con-basura-el-futuro-que-no-queremos#:%7E:text=Se%20proyecta%20que%20la%20r%C3%A1pida,podr%C3%ADa%20ser%20la%20nueva%20normalidad.
Toda la explicación en cuanto a implementación, código, entrenamiento del modelo, uso de interfaz y herramienta BI se puede encontrar en el siguiente link:
https://github.com/SaturdaysAI/Projects/tree/master/LATAM_remote/ciudadlimpia
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!

La Paz. Segunda Edición. 2021
En el mundo, los incendios forestales constituyen la causa más importante de destrucción de bosques. En un incendio forestal no sólo se pierden árboles y matorrales, sino también casas, animales, fuentes de trabajo e inclusive vidas humanas.
Como se puede apreciar en la Fig.1 en Bolivia los últimos siete meses este fenómeno se multiplicó de manera alarmante el área afectada debido a múltiples factores la Fig. 2 muestra algunas de las causas estudiadas para los incendios forestales. Otro factor importante identificado es el cambio climático que debido al aumento de temperatura en los lugares afectados, aumenta las áreas afectadas de manera alarmante.
Debido a las consecuencias de los incendios forestales no controlados ni planificados se deben tomar diferentes estrategias que permitan mitigar su ocurrencia en zonas protegidas o prohibidas para esta actividad.
En base a lo mencionado anteriormente se plantea el siguiente problema:
¿Cómo identificar de manera oportuna incendios forestales no controlados para minimizar su impacto?
Se plantea como objetivo general implementar un modelo de Deep Learning para la detección temprana de incendios forestales mediante el reconocimiento de humo en las áreas llanas/boscosas utilizando imágenes del lugar.
El siguiente gráfico muestra la idea central del proyecto.
El dataset para realizar el entrenamiento de los modelos se realizó mediante la descarga de imágenes clasificadas como “incendio forestal” (imágenes tomadas en perspectiva con presencia de humo en zonas forestales) y “no incendio forestal” (imágenes tomadas en perspectiva en zonas forestales sin presencia de humo o fuego).
Las imágenes descargadas (4 grupos de imágenes) fueron llevadas a un repositorio github para su importación sencilla en Google Colab.

Impresión de las 8 primeras imágenes de entrenamiento y 8 primeras imágenes de validación:
La selección de los modelos parte de las siguientes consideraciones:
Estas consideraciones son debido a los recursos que se tienen para realizar el objetivo general. Los modelos a desarrollarse son:
La principal técnica utilizada para compensar el dataset de tamaño limitado por la limitación de búsqueda de imágenes en Google fue la de “data augmentation” realizada por la librería de keras “ImageDataGenerator”.
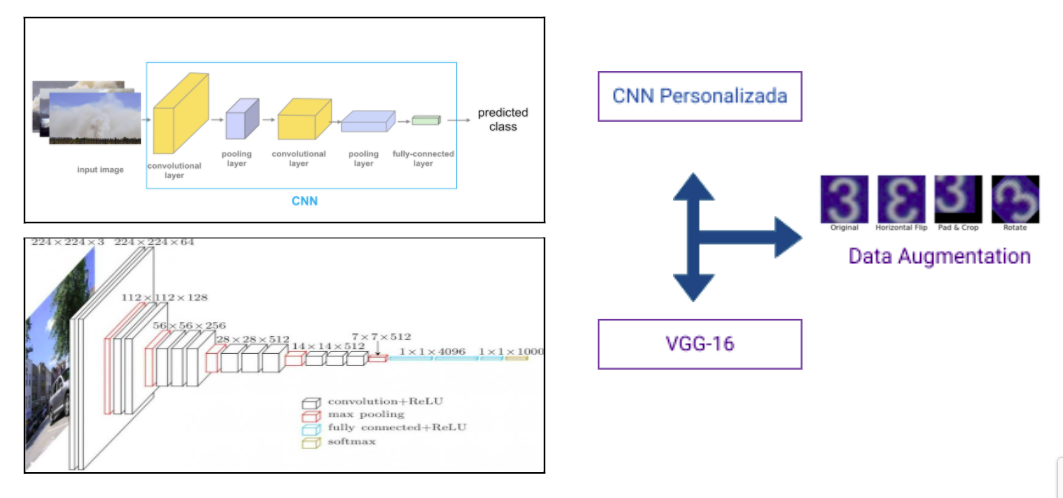
A continuación se muestran los resultados del modelo CNN personalizado y VGG-16.
1. Precisión y Curva de ROC de CNN personalizado:
2. Precisión y Curva de ROC de VGG-16:
Las predicciones de los modelos a continuación:
El modelo CNN personalizado tiene un desempeño adecuado para la detección de incendios forestales. El modelo VGG-16 con el elemento de pre-entrenamiento requiere más elaboración para obtener resultados más precisos. De esta manera un modelo Deep Learning no siempre requiere tener una alta complejidad para realizar la clasificación de manera eficiente.
El modelo desarrollado obtiene muy buenos pronósticos para el problema planteado y es una solución complementaria al problema de incendios forestales.
La utilización de modelos de AI Deep Learning pueden ser mejor explotados como complemento a la solución de problemas coyunturales.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
La Paz. Deep Learning. 2021
La Paz 2021. Las técnicas de Inteligencia Artificial tienen muchas aplicaciones actuales en el campo de las fotografías. Una de ellas tiene que ver con la manipulación de imágenes, campo en el cual se inscribe nuestro proyecto.
En particular, la restauración de imágenes (image restoration) es el proceso de recuperar una imagen a partir de una versión degradada. Image restoration es un caso de estudio que normalmente es tratado con procesamiento de imágenes. Se parte de la idea de que la imagen ha pasado a través de una función de degradación y se le ha añadido ruido; la restauración entonces consistirá en revertir el proceso y recuperar la imagen original.
El propósito de este proceso es “compensar” o “deshacer” aquellos defectos que generaron la degradación de la imagen, obteniendo un estimado de la imagen original.
La degradación puede provenir de diferentes fuentes, como la difuminación de movimiento (motion blur), ruido, desenfoque de la cámara o una combinación de todas éstas. También hablaremos de degradación al referirnos a aquellas fotografías impresas o negativos que sufrieron cualquier tipo de desgaste debido al envejecimiento del papel, polvo, manchas, etc.
De manera tradicional, una vez identificado el tipo de degradación, es posible procesar la imagen con un tratamiento de procesamiento de imágenes. Existen diferentes estudios y especializaciones con respecto a estos procesos, especialmente para revertir el ruido agregado a la función de degradación. Cada caso es único, por lo cual el tiempo de procesamiento puede llegar a ser muy largo. Al mismo tiempo, podemos encontrar estudios de fotografía que ofrecen el servicio de restauración aplicando técnicas de edición digital, lo cual resulta costoso.
Por otro lado, tenemos los films negativos fotográficos producidos por las cámaras analógicas que son preservados por varios tipos de usuarios, desde historiadores y bibliotecarios hasta quienes simplemente desean conservar recuerdos familiares. Estas películas normalmente deben pasar por un proceso químico (revelado) para la obtención de la fotografía física que describe la escena que fue capturada con la cámara analógica.
Existen técnicas de manipulación de la imagen digital de un negativo para obtener la imagen que correspondería a la revelada en el proceso tradicional. Estas técnicas siguen una secuencia de pasos que consisten en ajustar ciertos parámetros de la imagen que van más allá de la inversión de colores, algo que también se debe hacer imagen por imagen.
La selección de la técnica de procesamiento de imágenes que debe aplicarse a la imagen degradada proviene de una apreciación visual y resulta subjetiva. Muchas veces debemos aplicar varias técnicas en cascada para obtener un resultado óptimo. Este proceso consume tiempo, es específico a cada caso que se presente y en la mayoría de los casos no se puede paralelizar.
¿Y si pudiéramos utilizar la inteligencia artificial para crear un solo modelo que sea capaz de restaurar la imagen degradada sin necesidad de categorizar el tipo de degradación, cómo también realizar el revelado de las fotografías a partir de los negativos en film?
Éste es precisamente nuestro objetivo. Utilizaremos técnicas de Inteligencia Artificial para construir un modelo de restauración de fotografías que podrá recuperar la imagen original a partir de las degradaciones descritas y/o a partir de los negativos fotográficos. Para hacer el desafío más interesante incluiremos además imágenes en formato blanco y negro que deberán ser coloreadas; y también imágenes con regiones suprimidas, es decir taparemos regiones de la escena simulando manchas o rasguños que pudieran haber eliminado por completo estas regiones. Por más que existen modelos que hacen ciertas funciones que describimos, una de las dificultades será el de combinar todas estas restauraciones (colorización, revelado, restauración e incluso generación creativa) en un sólo modelo.
El proyecto presentado está basado en varias librerías de Fast.ai, que proporcionan herramientas de manipulación de fotografías mediante inteligencia artificial, de datasets para entrenamientos e incluso de modelos pre entrenados que son un buen punto de partida. La arquitectura general escogida es la de trabajar con una GAN (Generative Adversarial Network), que es apropiada para resolver nuestra problemática.
La estructura general utilizada consiste en un generador de imágenes, que intenta crear imágenes con la mejor calidad posible, ya sea en el color, la resolución, la textura… Por otra parte se entrena un discriminador que debe distinguir entre las imágenes reales dadas cómo input y las imágenes generadas por el generador. Finalmente se hace un tercer entrenamiento donde se combinan los dos modelos anteriores, lo que crea la GAN: en este proceso ambos modelos compiten y obligan a mejorarse el uno al otro.
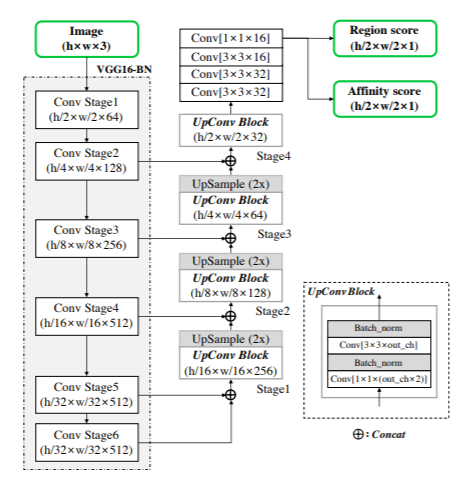
Nuestro modelo generador ya viene pre entrenado y consta de dos partes. La primera son las convoluciones que llevan una imagen de input hacia dimensiones cada vez más pequeñas, y la otra parte es cuando se hace el camino inverso para recuperar una nueva imagen de las mismas dimensiones que la que se tiene como input. La arquitectura total es UNET, que tiene como particularidad que cierta información del proceso de reducción de la imagen se le envía directamente a su contraparte (cuando las dimensiones son equivalentes). Este proceso se puede ver en la siguiente imagen.
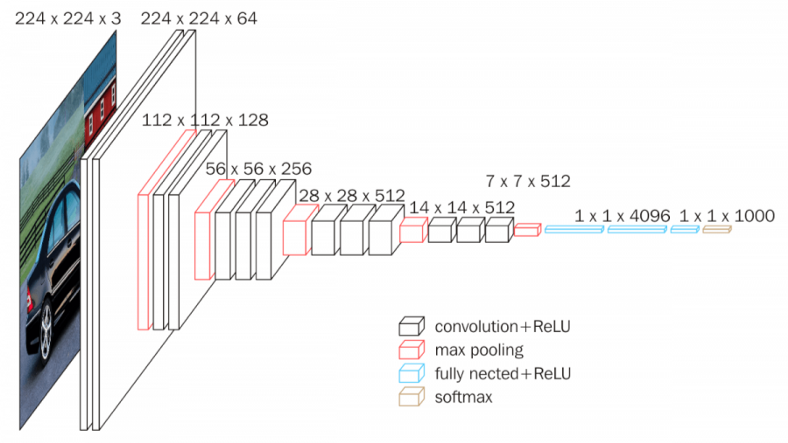
De igual manera, las diferentes operaciones y convoluciones utilizadas están basadas en una arquitectura CNN (Convolutional Neural Network) Resnet34 (34 capas de profundidad), que utiliza bloques residuales o de identidad durante las operaciones de convolución. Cuando cargamos este modelo, se puede entrenar solo la parte de la derecha (aproximadamente 20 millones de parámetros) utilizando la opción freeze(), o se puede entrenar el modelo entero (aprox. 40 millones de parámetros) con la opción unfreeze(). En este momento del proceso, y viendo que se utiliza una loss function de Mean Squared Error (MSELossFlat()), el generador solo intenta acercarse lo más posible a los valores de los píxeles de la imagen original. Sin embargo, esto no es suficiente para capturar, por ejemplo, el entorno de los píxeles, en específico ciertas texturas que son muy importantes para obtener una imagen correcta y de buena resolución. Es por eso que se utiliza el generador junto al discriminador en una estructura GAN.
El discriminador (también llamado critic) utiliza una loss function de cross-entropy con logits permitiendo una clasificación binaria (BCEWithLogitsLoss()), que está bien adaptada a su objetivo. Antes de entrenar la GAN, el discriminador se puede entrenar entre imágenes creadas por el generador y los input reales. Sin embargo, lo que más nos interesa es el entrenamiento de la GAN.
En esta etapa, los dos modelos generador y discriminador se entrenan juntos. La idea es utilizar un switcher que decidirá si es momento de entrenar el generador para mejorar las imágenes creadas y confundir al discriminador, o al contrario entrenar el discriminador cuando un cierto umbral de imágenes están siendo clasificadas como reales cuando en realidad son creadas por el generador.
Este proceso se lo puede realizar iterativamente cambiando el tamaño de las imágenes con las cuales va trabajando el modelo, yendo de dimensiones más pequeñas a las más grandes. De esta manera, el modelo va mejorando progresivamente. Esta técnica se utiliza por ejemplo para mejorar la resolución de las imágenes que se le da al modelo de Inteligencia Artificial y mejorar así las fotografías.
Es bien sabido que uno de los aspectos más importantes en la construcción de cualquier modelo inteligente son los datos. Es así que pusimos énfasis en la obtención, preparación y construcción de un dataset que nos pudiera proporcionar todo el espectro de degradaciones que requerimos que nuestro modelo sea capaz de reconstruir y que contemos con la cantidad y variedad necesaria.
Trabajamos con el dataset VOC2012 y ColorizationDataSet como datos iniciales (imágenes variadas a color y sin defectos). Decidimos utilizar 9895 imágenes en total. A una mitad se le aplicó un proceso de negativización artificial gracias a un preprocesamiento de imagenes y para la otra mitad se tomó en cuenta las imágenes en blanco y negro. A todas éstas imágenes se le aplicó un segundo procesamiento de imágenes dónde a un 65% se le aplicó algún tipo de degradación como ser compresión jpeg, ruido sal y pimienta, difuminado (blur), entre otros; y a un 25% se aplicó una degradación más importante cómo son unos huecos o manchas en varios sectores de las imágenes. A continuación podemos ver varios ejemplos de este tratamiento.
Para el entrenamiento del modelo, se dividió el dataset en un train set de 8906 imágenes y un test set de 989 imágenes.
Para entrenar nuestro modelo, utilizamos la GPU proporcionada por Google Colab. Antes del entrenamiento de la GAN, se puede entrenar el generador y el discriminador con sus respectivas loss function detalladas en el punto 4.
Para el generador, vemos que existe una cierta mejora al avanzar el número de épocas, tanto para el train set como para el test set. Hay que tener en cuenta que esto es sólo una parte del entrenamiento del generado,que en realidad se hará durante el entrenamiento de la GAN.
Para el discriminador, de igual manera se lo puede entrenar solo, y en esta etapa podemos llegar a un accuracy de hasta 95 %, lo que demuestra que antes de entrenar la GAN, le es muy fácil distinguir las imágenes reales de aquellas producidas por el generador.
Durante el entrenamiento de la GAN, se utilizan otras loss function un tanto modificadas tanto para el generador como discriminador. Sin embargo, para evaluar el modelo final, se necesita hacer una verificación visual ya que las loss function de ambos no nos proporcionan información relevante porque ambas funciones irán mejorando y empeorando en función de qué modelo se esté entrenando.
Para el entrenamiento del modelo de Inteligencia Artificial especializado en las fotografías se preparó un conjunto de datos de 9895 imágenes de negativos fotográficos (artificiales) y 9895 imágenes a color, cada uno de los negativos tiene una imagen a color relacionada..
El conjunto de datos se dividió en 2 grupos uno de entrenamiento y otro de validación, bajo el siguiente detalle:
– Train (8906 imágenes)
– Valid (989 imágenes)
Para el entrenamiento se consideraron los siguientes grupos de imágenes:
a) Imágenes en blanco y negro.
b) Imágenes sin degradación.
c) Imágenes con ruido gaussiano.
d) Imágenes con degradación y supresión de regiones
– Imágenes en blanco y negro
Imagen: image2669.jpg
– Imágenes en negativo sin degradación
Imagen: 2007_000039.jpg
Podemos ver que el modelo hace un buen trabajo al colorear ciertas imágenes negativas, encontrando el color correcto en la mayoría de los objetos de la imagen.
– Imágenes en negativo con ruido gaussiano.
Imagen: 2007_003118.jpg
La restauración de ruido hacia una mejor resolución no está completamente realizada, incluso para el train set. Podemos concluir que hace falta más tiempo de entrenamiento para continuar con el proceso.
– Imágenes en negativo con regiones suprimidas
Imagen: 2007_000033.jpg
Imagen: 2007_000027.jpg
Para las imágenes degradadas con partes enteras faltantes, el modelo reconoce el color que le debe dar a la zona oscura. Por el momento, la resolución es mala, pero con más entrenamiento, esto puede ir mejorando.
Resultados Test Set:
– Imágenes en blanco y negro.
Imagen: image0476.jpg
– Imágenes en negativo sin degradación.
Imagen: image1027.jpg
– Imágenes con ruido gaussiano.
Imagen: image0850.jpg
– Imágenes con Degradación
Imagen: image4988.jpg



A continuación presentamos resultados de predicción del modelo en imágenes completamente nuevas que no se utilizaron durante el entrenamiento. Podemos observar que dependiendo la imagen en blanco y negro, la colorización se hace de manera aceptable en algunas pero casi nada en otras. De igual manera en la segunda imagen se observa que la imagen del resultado ha mejorado la calidad de la imagen en cuanto al ruido que presenta la original. En cuanto a la imágenes en negativo, el modelo hace un buen trabajo en detectar los objetos de la imagen y colorearlos acorde a lo detectado.
Este proyecto de Deep Learning nos permitió familiarizarnos con ciertas técnicas de manipulación de imágenes, código en Python, librerías especializadas en Deep Learning así como técnicas de entrenamientos de modelos en ciencia de datos, usando la Inteligencia Artificial aplicándola a las fotografías. Los resultados son aceptables considerando las limitaciones en tiempo de entrenamiento así como en GPU que se tuvieron. Vimos que el modelo puede trabajar tanto con negativos fotográficos como con fotografías antiguas en blanco y negro que pudieran presentar degradaciones leves o fuertes. Sin embargo, queda mucho margen de mejora como por ejemplo vimos que algunas restauraciones de negativos tienen un tinte azul de fondo, probablemente debido al hecho de haber utilizado negativos solo creados artificialmente y no “reales”. Estos negativos pueden presentar diferentes calidades químicas, de material… que pueden variar por modelo o marca. De igual manera es probable que utilizar imágenes degradadas reales aumente el poder del modelo.

La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Reconocimiento de emociones mediante el estudio de expresiones faciales con deep learning y computer vision.