Zaragoza. Primera Edición. 2022
El mercado laboral que todos conocemos se desarrolla sobre un esquema a modo de dos grandes tablones de anuncios, uno frente al otro: el primero con los que ofrecen puestos de trabajo y el segundo con quienes los demandan. Y en muchas ocasiones es el segundo el que se adapta al primero.
Pero creemos que esto tiene que cambiar. Más que un encuentro en el que la mayor parte de las veces se elige por eliminación, las relaciones laborales deberían de parecerse un poco más a las personales, al menos en sus planteamientos iniciales. En las apps de contactos, hay que aportar muchos datos acerca de quiénes somos y también de lo que buscamos. De allí surgen candidatos y con eso se busca el MATCH por ambas partes.
No es cuestión de enamorarse a primera vista, pero sí creemos que es bueno conocer más en profundidad en qué consisten las ofertas de trabajo. Son datos públicos que nos pueden contar aspectos importantísimos tanto de la empresa, como del territorio donde están asentadas. Los requisitos que piden a sus futuros trabajadores y su análisis pueden ayudar tanto a las personas que buscan empleo, como al sector de la educación o a los gobiernos e instituciones de cara a prever situaciones de déficit o superávit en alguno de ellos. En una economía interdependiente y globalizada como la que vivimos, ofrecer un excelente comportamiento del flujo de la mano de obra puede ayudar a asentar empresas, y ser un buen apoyo para la economía y la toma de decisiones.
En el caso de Aragón, la situación se complica en lugares como Teruel, al aplicarse el factor de la despoblación en muchas zonas. Insistiendo en la misma idea que el objetivo de nuestro trabajo, la consejera de Presidencia de Aragón, Mayte Pérez en una reunión en Teruel comentó hace unos días la importancia de generar “foros y sinergias para adelantarnos a las necesidades de empleo que van a surgir. Debemos analizar el mercado laboral hoy, pero ver también las expectativas de futuro que tiene la provincia para acompañarlas de una oferta formativa cualificada” [1].
Las empresas de construcción, tanto de obra pública como civil, ya alertaron en otoño de la carencia de mano de obra para su sector, lo que podría ocasionar problemas.
Y no sólo la construcción.
Se cifra ya en 30.000 millones de euros anuales las pérdidas por la falta de mano de obra en Europa [2].
Frente a estos datos, los del paro. En Aragón hay más de 61.000 personas en desempleo. La mayor parte, más de 42.000, son del sector servicios. Pero en el sector de la construcción hay 3.871 trabajadores en paro, en industria 7.000 y en agricultura y ganadería, 3.624. A todos ellos se suman más de 4.500 personas sin empleo anterior.
¿Por qué hay desempleo en un sector cuando hay más demanda? ¿las personas que están en el paro en ese sector no cumplen los requisitos? ¿no acceden a las ofertas por no estar en la misma población en la que se publican?
Se plantean muchos interrogantes, y muchos más cuando las empresas e instituciones planifican la actividad de aquí a los próximos diez años, para recuperar el parón que ha supuesto el COVID y ya marcan las necesidades de mano de obra que van a tener.
Problema
Nos enfocamos en el siguiente problema: ¿Cómo podríamos facilitar el análisis de las ofertas de empleo en Aragón para brindar a sus ciudadanos conclusiones relevantes?¿Cómo podemos ayudar a las empresas a encontrar mano de obra que se ajuste a sus necesidades?¿Pueden las instituciones planificar oferta y demanda de empleo conociendo mucho más el mercado laboral?
Tanto el problema identificado como el proyecto desarrollado están enmarcados en el ODS 8 (Objetivo de Desarrollo Sostenible) de trabajo decente y crecimiento económico [3], y está motivado por la carencia de herramientas que faciliten a los aragoneses estudiar en términos globales la situación actual de las ofertas de empleo en Aragón.
Objetivo general
Para resolver el problema identificado nos planteamos como objetivo general: Desarrollar una herramienta basada en técnicas de Procesamiento del Lenguaje Natural que facilite analizar las ofertas de empleo disponibles en Aragón a partir de diferentes criterios (sector, provincia, ciudad, oficina del INAEM, fechas, etc.) Su utilidad puede ser de interés para empresas, instituciones, planificación educativa, estudiantes, desempleados, empresas de formación, etc…
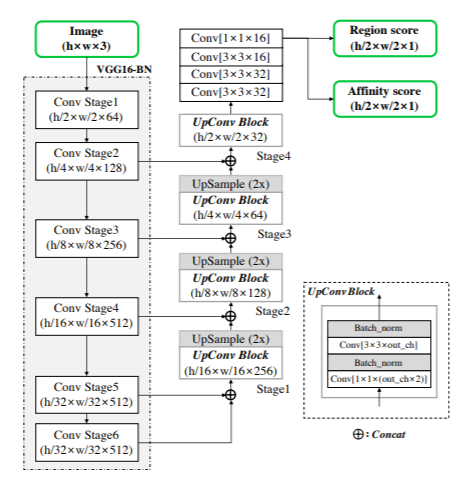
Con el propósito de cumplir con el objetivo planteado y llevar a cabo el proyecto de manera organizada, seguimos la metodología CRISP-DM (Cross-Industry Standard Process for Data Mining) [4], orientada a trabajos de Minería de Datos, que en nuestro caso se enfoca específicamente en técnicas básicas de Procesamiento del Lenguaje Natural (PLN) [11]. En la siguiente figura se presentan las diferentes fases que abarca la metodología.
Conjunto de datos
Al iniciar el planteamiento de nuestra propuesta, consideramos estudiar el ámbito laboral en Aragón al completo, oferta y demanda. Para la oferta vimos que podíamos contar con el Instituto Aragonés de Empleo, INAEM [5], que de lunes a viernes facilita un PDF con las ofertas de empleo disponibles esa jornada en todo el territorio, distribuídas en 28 sectores productivos.
También planteamos usar Infojobs, pero la información que se facilita allí no se encuentra tan bien clasificada. Además, Infojobs aporta unos tipos de trabajo determinados. No suelen ser empleos de alta formación y sueldos elevados, lo que sesgaría las características del estudio.
Para la demanda pensamos en LinkedIn, que sí ofrece mucha información y buena indexación. Pero no todos los miembros de la comunidad LinkedIn buscan trabajo. Con lo cual quedaba descartado. Lo mismo sucedió con los demandantes de trabajo en Infojobs u otras páginas similares como Milanuncios.com. Suelen ser perfiles con urgencia en trabajar, que daría para otro estudio, quizá de carácter social, pero no en la línea que nosotras planteamos.
Por este motivo, decidimos acudir a la base, y crear un sistema capaz de interpretar la oferta diaria de puestos de trabajo en la comunidad autónoma de Aragón, e intentar sacar de allí el máximo partido al modelo de ficha con los datos básicos que encontramos en cada uno de los empleos que allí se anuncian. Hay también que tener en cuenta que el INAEM gestiona buena parte de los puestos de trabajo que salen al mercado laboral en Aragón, pero no el 100%. Por ello nuestras conclusiones, no podrán ser en ningún caso estrechamente ajustadas a la realidad, sino que se convierten en tendencias, aproximaciones y evoluciones cercanas a la oferta de empleo real.
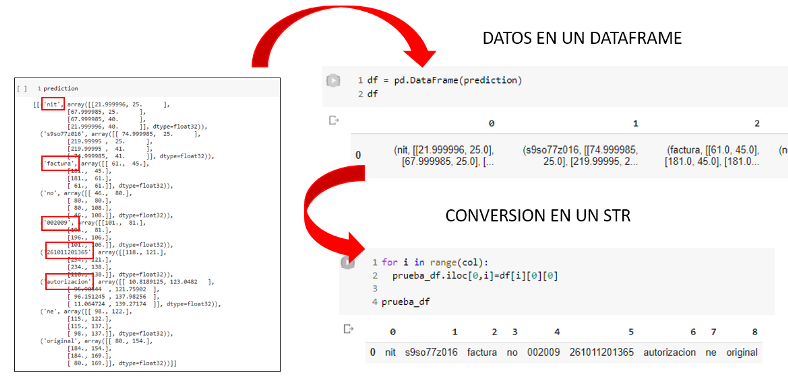
El conjunto de datos que se obtuvo fue el resultado de analizar, extraer y preprocesar un conjunto de esos documentos PDF disponibles en el portal de INAEM [5], y también incorporando la información que aparece en la propia página web del INAEM, en el rango de fechas del 2021 hasta principios de marzo de 2022. En total 1152 ofertas de trabajo. Se distribuyen por sectores profesionales en Aragón (ver Figura 8). Cada oferta de empleo se divide en dos bloques. Uno más breve y esquemático con el título, provincia, ciudad, código, fecha de publicación y oficina. El segundo bloque es el de la descripción. Dentro de ella se obtiene información sobre las tareas a desempeñar, requisitos solicitados por la empresa, condiciones de trabajo, trámites y plazos, entre otras.
Durante el proceso de extracción de la información textual desde los documentos de PDF se utilizó la librería de Python Tika [6]. El texto resultante de la extracción por cada documento PDF fue separado por sectores profesionales y luego por ofertas de empleo. De cada oferta, se extrajeron los textos de mayor interés a analizar (“sector”, “identificador de la oferta”, “fecha de publicación”, “título de la oferta”, “ciudad”, “provincia”, “oficina del INAEM”, “descripción global”, “descripción específica”, “tareas a desempeñar”, “requisitos solicitados por la empresa”, y “condiciones de trabajo”). Para ello, aplicamos expresiones regulares [7], también conocidas como regex por su contracción de las palabras inglesas regular expression, que no es más que una secuencia de caracteres que conforma un patrón de búsqueda sobre los textos. En la siguiente figura se puede ver un ejemplo para encontrar las “fechas de publicación” dentro de los textos de las ofertas.
A primera vista parecen tablas de datos con una pauta similar y un orden concreto. Pero lo cierto es que en la práctica se constata que no es así. Cada oficina tiene sus usos y costumbres, lo que dificulta el tratamiento de los datos. Por ejemplo, unas escriben las poblaciones con mayúsculas, y otras sólo la inicial va en mayúscula. Eso hace que se identifique como dos poblaciones distintas si vemos una oferta en BARBASTRO y otra en Barbastro, también se pueden diferenciar por los acentos (por ejemplo, Sabiñánigo y Sabiñanigo) o porque simplemente están mal escritas (por ejemplo, concinero en vez de cocinero, grú para referirse a grúa, etc.). También hay ofertas de trabajo duplicadas, y en cuanto a las características de la descripción global de la oferta, en algunas oficinas las detallan como “Requisitos” y en otras como “Tareas”,entre otras diferencias. Incluso algunas oficinas no ponen etiquetas que separen los distintos conceptos dentro de la descripción, lo que impide aplicar el modelo.
Ejemplo 1.- Lleva las etiquetas de TAREAS, REQUISITOS, CONDICIONES
Ejemplo 2.- Sin etiquetas ni separación. Únicamente aparece “Funciones” sin mayúscula ni negrita
En la fase de análisis y verificación de la calidad de los datos extraídos, identificamos este conjunto de problemas, que fueron tratados para su posterior explotación desde el dashboard: eliminamos ofertas de trabajo duplicadas (asegurando tener un identificador único por oferta), corrigiendo nombre de ofertas, ciudades, provincias, oficinas de empleo, y descripciones mal escritas a partir de diccionarios. También hemos tenido que unificar los textos que significan lo mismo para diferentes características.
Con el propósito de extraer información complementaria a la obtenida desde los documentos PDF, aplicamos en paralelo la técnica de web scraping al buscador de ofertas de empleo en Aragón de INAEM [5], como es el caso del “nivel profesional”, “requerimientos” y “duración del contrato” de las ofertas de empleo, que sólamente aparecían en la web. Adicionalmente, el web scraping permitió completar valores vacíos que no se consiguieron extraer desde los documentos PDF, tales como las “descripciones generales”, “condiciones de trabajo”, nombres de “ciudades” y “provincias”, al estar tanto en la web como en los documentos PDF. Tal vez el web scraping hubiera sido suficiente para tener una primera versión de los datos relacionados con las ofertas de empleo de INAEM, pero los campos “sector” y “oficina de empleo” de cada una de las ofertas sólo estaban presentes en los documentos PDF, los cuales considerábamos muy importantes para estudiar desde el dashboard. Por todo lo anterior, hay que resaltar que una gran parte del proyecto fue dedicada a la fase de extracción, análisis, limpieza y homogeneización de la información.
Dashboard de ofertas de empleo en Aragón
Con el propósito de facilitar el análisis de la situación actual de las ofertas de empleo en Aragón, desarrollamos un dashboard haciendo uso de la librería Streamlit [8]. Esta librería de python ofrece una plataforma de código abierto que permite crear y compartir fácilmente aplicaciones web personalizadas para ciencias de datos y aprendizaje automático. El código fuente del dashboard y de la extracción y preprocesamiento textual está disponible en nuestro repositorio de GitHub [9].
El dashboard cuenta con 4 apartados principales que vamos a desarrollar a continuación. Aunque hay más de una veintena de sectores, hemos querido fijarnos sobre todo en el turismo, por ser importante en la economía aragonesa y con requisitos y términos más conocidos para la sociedad:
- 1.- Estudio de ofertas por criterio:
En este apartado conocemos el número de ofertas que hay según los siguientes criterios de búsqueda: sector, oficina y provincia.
Según el criterio seleccionado se genera una gráfica de barras.
Análisis:
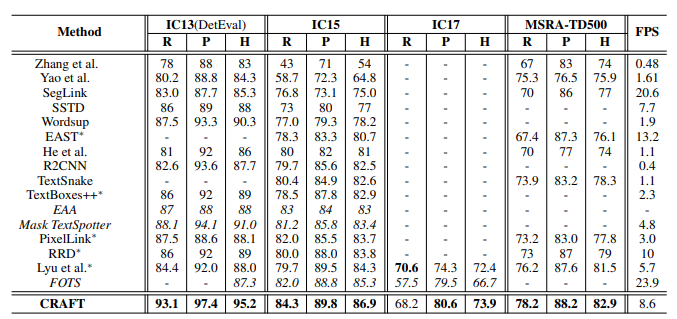
Con el criterio “Sector” analizamos 24 de los 28 sectores que contempla la página web del Servicio nacional de empleo. Hay 4 sectores que el INAEM o bien no contempla, o bien no existen ofertas de trabajo para ellos. Esos 4 sectores son Información y Manifestaciones artísticas, Minería y primeras transformaciones, Pesca y acuicultura y Piel y cuero. Vemos que los tres ámbitos que más ofertas han presentado desde noviembre a aquí son Turismo y Hostelería (en plena temporada de nieve y con las vacaciones de Navidad), Administración y Oficinas y Edificación y Obras Públicas. Las que menos personal han solicitado en este tiempo son Producción, Transformación y Distribución de Energía, Seguros y finanzas y Artesanía. En esta gráfica en este periodo podemos observar la temporalidad, con mucha demanda en Hostelería (una de las temporadas altas del turismo en Aragón) y con una oferta contenida por ejemplo en Agricultura, ya que en invierno disminuyen las labores del campo.
Con el criterio “Oficina” observamos que con mucha diferencia, la de Zaragoza Ranillas es la que más ofertas de empleo gestiona en toda la comunidad. Le sigue la oficina de Huesca Capital. Zaragoza acumula cinco oficinas de empleo, dos de las cuales, Zaragoza Centro y Zaragoza Compromiso de Caspe, se sitúan las siguientes en el ránking de las cinco primeras, que cerraría la oficina de Teruel Capital. Fuera de las tres capitales provinciales, destaca Sabiñánigo en número de ofertas de trabajo. En esa sucursal se une la oferta industrial de la capital del Alto Gállego, al abundante sector hostelero y turístico del Valle de Tena, que se complementa con construcción y ganadería. En el listado hay una oficina que no corresponde con Aragón. Ello es debido a que desde las oficinas de Castellón y Castelldefels (Barcelona) han lanzado a Aragón unas ofertas buscando esquiladores.
Con el criterio “Provincia” observamos la proporción actual de ofertas que se reparten entre los tres territorios provinciales de Aragón.
- 2.- Estudio de ofertas por fecha: En este apartado cruzamos varios de los datos que encontramos en las ofertas, para lograr conclusiones más específicas o perfiles más ajustados. Se genera una gráfica de temporalidad, que facilita el análisis del número de ofertas de trabajo combinando diversos criterios, tales como año, sector laboral y provincia.
Análisis:
Si seleccionamos el criterio “AÑO” podemos obtener sólo uno en concreto, como esta gráfica, correspondiente a 2021 para todo Aragón. Es evidente un pico en las ofertas de trabajo a mediados de diciembre, tras el puente, justo antes de las contrataciones de cara a la campaña navideña.
Para el año 2022 en todo Aragón, vemos escasa oferta en los primeros días, que aún son festivos, y un pico destacado al final del mes de enero. Llama la atención la caída en las ofertas llegado mitad del mes de febrero, que luego se recupera con un nuevo pico demanda de trabajadores a final de mes.
Y podemos unir los dos periodos que tenemos actualmente, 2021 y 2022. En esta gráfica, añadimos el criterio “PROVINCIA” seleccionando la de Zaragoza. Encontramos unas conclusiones similares en estos parámetros, con picos a mitad de diciembre y finales de enero, y una caída de ofertas a mitad de febrero, para encontrar una importante subida a final de este mes.
Analizamos ahora el número de ofertas aplicando el criterio “PROVINCIA” en este caso en la de Huesca para el año 2021 y 2022. Es muy llamativo el pico de ofertas a finales de enero, de cara parece a una contratación a más largo plazo. Destaca también el descenso de empleos propuestos a mitad de febrero.
En cuanto al número de ofertas en Teruel para el año 2021 y 2022, es también muy llamativo el pico a final del mes de enero, y también una caída significativa a mitad de mes de febrero:
Y también se puede analizar aplicando los tres criterios, es decir por cada uno de los sectores/años/provincia.
Por ejemplo, estudiamos aquí el sector TURISMO Y HOSTELERÍA y provincia ZARAGOZA para todos los años. Hay una subida a final del mes de enero, quizá preparando el puente festivo de San Valero o ante la previsión de la eliminación de algunas restricciones de hostelería, que se efectuó a principios de febrero.
En esta otra gráfica, hemos seleccionado el sector de la EDIFICACIÓN Y OBRA PÚBLICA, también en la provincia de Zaragoza, con demanda de trabajadores muy desigual en estos días.
- 3.-Nube de palabras: Generamos una nube de palabras a partir de los textos que contienen los títulos y descripciones globales de las ofertas laborales, las cuales se pueden filtrar por sector profesional. Adicionalmente, se puede ajustar diferentes parámetros de configuración de la nube de palabras, tales como el color del fondo de la imagen, el color de las palabras más frecuentes, el número máximo de palabras a generar, el tamaño máximo del fondo, y el estado aleatorio para que muestre palabras diferentes por cada valor definido. Por otra parte, permite subir una imagen (de tipo “silhouette”) para generar la nube de palabras con la forma de la figura dibujada en la imagen. Nuestra idea de “conocer es amar” aplicada a este proyecto nos ha animado a darle forma de corazón. Es una herramienta muy valiosa, porque más allá del dato, permite identificar otros conceptos no detectables en un primer análisis sobre las ofertas de empleo. Lo explicamos a continuación.
Para realizar el análisis de los datos exploratorios del PLN [11], utilizamos la librería de Python WordCloud [10]. A partir de esta librería pudimos hacer una representación visual de las palabras (también conocido como nube de palabras) que conforman los textos de los títulos y descripciones globales de las ofertas de trabajo, en donde el tamaño es mayor para aquellas palabras que aparecen con más frecuencia. Las gráficas de nube de palabras, nos permitieron visualizar las palabras claves contenidas en los textos para su posterior estudio. Previo a la representación visual y como parte del procesamiento de datos en lenguaje natural, eliminamos del texto un conjunto de palabras vacías (conocidas como stop words), que son palabras sin significado como artículos, pronombres, preposiciones, etc.
Análisis:
Para la primera nube de palabras que analizamos, hemos seleccionado, por ejemplo, los criterios Oferta + Sector TURISMO Y HOSTELERÍA. Es decir, esta nube de palabras es con el encabezamiento de la Oferta.
En las nubes de palabras, aparecen los términos más usados o habituales dentro del texto. Era de esperar encontrar ‘Camarero’, ‘Cocinero’ o ‘Barra’. Pero encontramos otros términos que nos dan pistas de tendencias. Por ejemplo, aparecen varios municipios donde hay especial demanda de Hostelería (Rubielos, Garrapinillos, Montañana, Cariñena), y otros servicios de Hostelería que no son los mayoritarios (Residencia, planchistas, marmitones, ancianos o discapacidad). Ello nos permite analizar, por ejemplo, una tendencia emergente dentro de este sector dando servicio residencial, y varias especializaciones que se necesitan en Aragón, como por ejemplo Barrancos. Observamos el sesgo de género ya que se solicita mucho más los Camareros (muy grande) que las Camareras (muy pequeño), o Cocinero un poco más grande que Cocineras. Es llamativo que las demandas especifican el género.
Si nos vamos a otro criterio, podemos analizar el texto de la Descripción global de la oferta, también en el mismo sector de TURISMO Y HOSTELERÍA. Buena parte de esta nube se la llevan palabras que indican trámites administrativos derivados de la gestión laboral. Pero hay varios términos que nos ofrecen características del sector. Entre las palabras destacadas, por ejemplo se encuentra ‘Experiencia’ y también ‘jornada completa’ que se lee bastante grande, frente a ‘jornada parcial’ que también se encuentra en la nube pero mucho más pequeña. Por contra, aparece con más tamaño ‘contrato temporal’ que ‘contrato indefinido’. Entre los requisitos que se solicitan se encuentra también carnet de conducir o posibilidad de conducción para el trabajo.
Analizamos ahora otro sector muy distinto. Seleccionamos OFERTAS y sector SERVICIOS A LA EMPRESA. En un sector tan genérico, los términos que aparecen nos ofrecen valiosa información sobre los perfiles que se buscan. Entre los que más, Técnico, Riesgos Laborales, Prevención, Teleoperadores, Seguridad o Informático. Una manera muy sencilla de definir perfiles en este sector.
Aportamos un ejemplo más de OFERTA en este caso, el de INDUSTRIA ALIMENTARIA. En un sector tan diverso, las características del mercado aragonés se definen en su vertiente de carnicería. Despiece, Cárnica, Carnicero, Tripería, Cárnicos, Aviar, Animal, Matadero, Carnicería constituyen las mayoría de las palabras de la nube.
- 4.- Mapa de ofertas: Con esta opción se genera un mapa donde se puede visualizar el número de ofertas por cada provincia, oficina de desempleo en Aragón y población donde se ofrece el puesto de trabajo, con círculos que amplían su radio proporcionalmente al número de empleos.
MAPA 1.- Con el propósito de obtener automáticamente la latitud y longitud de las provincias, ciudades y oficinas de empleo en Aragón, usamos la librería GeoPy [12]. Por otra parte, la librería de Python pydeck [13] fue utilizada para visualizar los datos en el mapa de una manera interactiva. En la Figura 13, se muestra un ejemplo de visualización del mapa geográfico con el número de ofertas de empleo por cada una de las provincias de Aragón.
Análisis:
Con esta primera imagen en mapa, de un simple vistazo nos hacemos una idea de cómo se reparte el volumen de ofertas del INAEM en Aragón entre sus tres provincias. Las proporciones mayores están en Zaragoza y Huesca, y se nota mayor distancia con las de la provincia de Teruel.
MAPA 2.- La siguiente posibilidad que ofrece nuestro modelo refleja las poblaciones donde se ofrecen los puestos de trabajo. Este mapa puede convertirse en una herramienta valiosa para la ordenación del territorio. Observando la evolución a lo largo de días o meses puede dar información, por ejemplo, de las necesidades de vivienda, educación o servicios, o al contrario, advertir del riesgo de despoblación o de que se inicien movimientos migratorios de los habitantes de una zona buscando trabajo en otro lugar.
MAPA 3.- La tercera posibilidad es conocer el volumen de ofertas de empleo de cada oficina del INAEM en Aragón. Podemos observarlo de manera general, incluyendo las de toda la comunidad autónoma como en este gráfico.
O bien acercarnos y descubrir las opciones de las distintas oficinas dentro de una misma ciudad, como ocurre en Zaragoza.
Conclusiones
En este artículo, hemos presentado el proyecto desarrollado en Saturdays.AI-Zaragoza, un primer paso para contribuir con la sociedad, ante la carencia de herramientas que faciliten a los aragoneses estudiar en términos globales la situación actual de las ofertas de empleo en su comunidad.
Tal y como hemos explicado, entre los problemas que nos hemos encontrado se encuentra la distinta indexación según cada oficina del INAEM. Si todas ellas rellenaran una misma plantilla online exactamente con los mismos criterios el tratamiento de los datos sería mucho más sencillo e inmediato. ¿De qué sirven los datos si no están semi-estructurados? ¿si no hay un patrón que facilite la extracción de la información? Si además nuestro enfoque se implementara y recopilara con esos datos día a día, sería una valiosa arma para la gestión del empleo en la comunidad de Aragón, permitiendo conocer puntualmente la evolución de los distintos sectores, de los lugares donde se ofrece trabajo, de los requisitos que solicitan las empresas para sus futuros empleados. Mucho de nuestro trabajo se ha invertido en solucionar detalles que no tendrían que estar allí. De no habernos encontrado esas diferencias en las formas de clasificación de datos, nuestro estudio nos permitiría hablar de otros análisis más profundos y precisos e incluso modelos de aprendizaje automático avanzados.
Simplemente continuar añadiendo los datos a diario a este trabajo, permitiría un estudio muy detallado de cómo se comporta el mercado laboral en un año, analizando así la evolución de sectores tan temporales como pueden ser el agrícola o el turismo, ambos con un peso muy relevante en la economía aragonesa e incluso pudiendo llegar a predecir las necesidades futuras del mercado laboral aragonés.
Además de todo ello, algunas de las principales aportaciones que realiza este trabajo son las siguientes:
- Es una herramienta que aumenta el conocimiento sobre las ofertas de empleo en Aragón.
- Consigue organizar los datos del INAEM a pesar de las dificultades.
- Crea un sistema de interpretación del lenguaje natural del que obtenemos los datos deseados.
- Generación automática de gráficas de barras según los datos por sectores, oficina y provincia.
- Generación automática de gráficas según criterios independientes o combinados con año, sector y provincia.
- Generación automática de nubes de palabras, que además de analizar la oferta, nos ofrece nuevas ideas o criterios, conceptos emergentes que son muy interesantes para analizar las ofertas.
- Generación automática de mapas que permiten tener una visión de las ofertas directamente sobre el territorio, lo que ofrece una valiosa herramienta de comprensión sobre la evolución del empleo y su impacto en las distintas comarcas.
Para qué se puede aplicar:
- Marcar líneas de formación para empresas o gobiernos.
- Dar indicación a los jóvenes que buscan un horizonte laboral para tomar decisiones en cuanto a su formación de cara a futuro.
- Dar información a las empresas de los requisitos que hay en el mercado para un puesto concreto, y conocer las condiciones medias de contratación.
- Conocer el tiempo qué tarda en cubrirse una plaza en un sector.
- Saber los lugares de Aragón dónde se demanda el empleo y dónde no.
- Demanda de empleo según la época del año. Evolución de la temporalidad.
- Planificación de la ordenación del territorio y de la sociedad según las necesidades de la población que pueda desplazarse buscando el empleo.
Como líneas de trabajo a seguir partiendo de lo que ya tenemos, se puede continuar con el desarrollo y mejora del dashboard.
Y de cara al futuro
- Se podría desarrollar para que el programa se enriqueciera con más información que incorporara a diario de manera automática.
- Se podría convertir en una aplicación web real y consultable por autoridades relacionadas con la gestión económica y social, empresas, trabajadores, sindicatos, estudiantes, etc.
- Incorporar otras plataformas de empleo, puesto que la del INAEM no representa toda la oferta existente. Requeriría de un complejo estudio para encontrar en esas otras plataformas el modo de homogeneizar la información, es decir, unificar en un única característica aquellos textos que significan lo mismo pero se categorizan bajo etiquetas diferentes. Esto incluso podría pasar dentro de una misma plataforma, como tenemos en el INAEM.
Agradecimientos
Agradecemos la oportunidad que nos ha brindado Saturdays.AI para aprender los fundamentos básicos de Inteligencia Artificial, a pesar de no ser expertos en el ámbito. Y sobre todo a María del Carmen Rodríguez Hernández, por toda la ayuda que nos ha prestado y todas las horas de apoyo, sin las cuales, esto no sería una realidad.
Referencias
[1] Periódico La Comarca “Preocupación por la falta de mano de obra en Teruel” 27/01/2022 https://www.lacomarca.net/preocupacion-falta-mano-obra-teruel/ (Consultado el 25 de febrero de 2022) [2] C. Porteiro, Diario La Voz de Galicia “Europa pierde 30.000 millones de euros anuales por la falta de mano de obra” 16/10/2021 https://www.lavozdegalicia.es/noticia/economia/2021/10/16/europa-pierde-30000-millones-euros-anuales-falta-mano-obra/0003_202110G16P28991.htm (Consultado el 3 de marzo de 2022) [3] Objetivos de Desarrollo Sostenible. PNUD. https://www.undp.org/es/sustainable-development-goals (Consultado el 24 Febrero, 2022) [4] P. Haya. La metodología CRIP-DM en ciencia de datos. https://www.iic.uam.es/innovacion/metodologia-crisp-dm-ciencia-de-datos (Consultado el 24 Febrero, 2022) [5] INAEM: Ofertas de Empleo en Aragón. https://inaem.aragon.es/ofertas-de-empleo (Consultado el 2 de marzo 2022) [6] C. Mattmann. Librería de Python Tika. https://github.com/chrismattmann/tika-python (Consultado el 24 Febrero 2022) [7] López, F., & Romero, V. (2014). Dominar las expresiones regulares de Python. Publicación de paquetes. págs. 110. ISBN 978–1–78328–315–6. [8] A. Treuille, A. Kelly y T. Teixeira. Streamlit. https://streamlit.io (Consultado el 25 Febrero 2022) [9] M. Morao y E. P. Nogarol. Dashboard de Ofertas de Empleo en Aragón.https://github.com/marianamorao/eq_1_demanda_empleo (Consultado el 4 Marzo, 2022) [10] A. Mueller y et al. Librería de Python WordCloud. https://github.com/amueller/word_cloud (Consultado el 25 Febrero, 2022) [11] H. Suresh. WordClouds: Basics of NLP. Medium. 03/06/2020 https://medium.com/@harinisureshla/wordclouds-basics-of-nlp-5b60be226414 (Consultado el 4 Marzo, 2022) [12] K. Esmukov y et al. Librería de Python GeoPy. https://geopy.readthedocs.io (Consultado el 25 Febrero, 2022) [13] X. Chen y et al. Librería de Python Pydeck. https://github.com/visgl/deck.gl/tree/master/bindings/pydeck (Consultado el 25 Febrero, 2022)
Integrantes
- Mariana Morao Santos
- Esther P. Nogarol
Presentación del proyecto: Demoday
Repositorio
En el siguiente repositorio se encuentra el código usado para desarrollar esta aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Zaragoza/eq_1_demanda_empleo-main/eq_1_demanda_empleo-main
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!