Conclusión
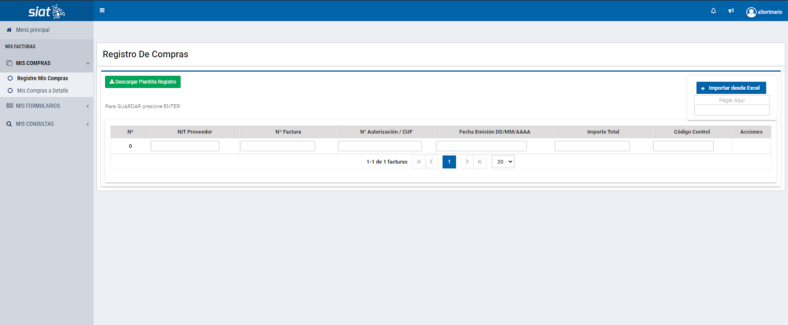
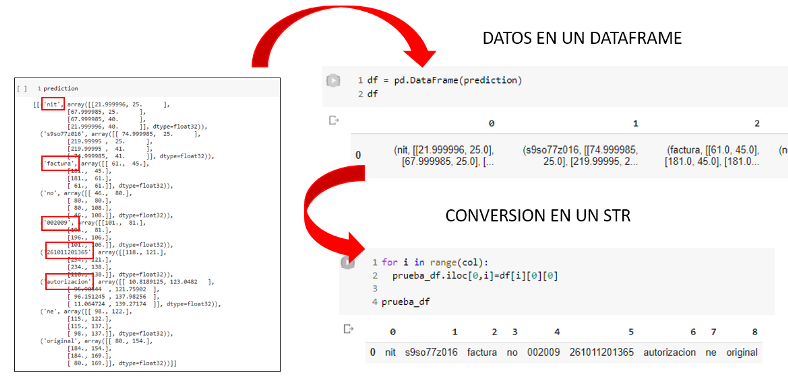
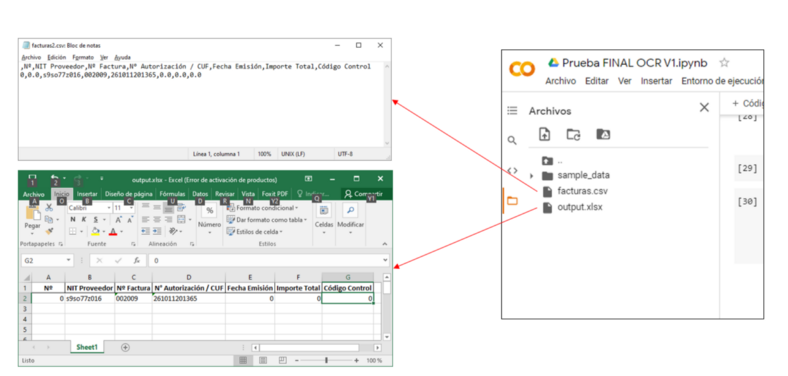
Por medio de este prototipo, se puede identificar los valores más relevantes y complicados de transcribir para la mayoría de las personas que realizan su declaración de facturas. Además, que el importarlos desde una foto o imagen escaneada reduce drásticamente el tiempo de transcripción de datos. Lo que sería de mucha ayuda para personas no muy familiarizadas con las computadoras, como un buen porcentaje de adultos mayores en el país.
Si bien, muchos datos son identificados. El mayor problema reside en la calidad de la imagen tomada, ya que si esta no tiene una buena nitidez o tamaño llega a tener problemas con la identificación de algunos caracteres. Y que para trabajos futuros se podría intentar solventar con un entrenamiento más personalizado y no basándose en uno pre entrenado.
A su vez, el realizar una GUI (Interfaz gráfica de usuario), ayudaría bastante en poder llevar a este prototipo a ser más amigable con el usuario. Y por ende, facilita la importación de imágenes o facturas escaneadas para su reconocimiento de caracteres y exportación final.
Código
https://github.com/albmarale/SaturdaysAIDeepLearning
Bibliografía
[1] “PyTorch: Scene Text Detection and Recognition by CRAFT and a Four-Stage Network | by Nikita Saxena | Towards Data Science.” https://towardsdatascience.com/pytorch-scene-text-detection-and-recognition-by-craft-and-a-four-stage-network-ec814d39db05 (accessed Jul. 13, 2021).
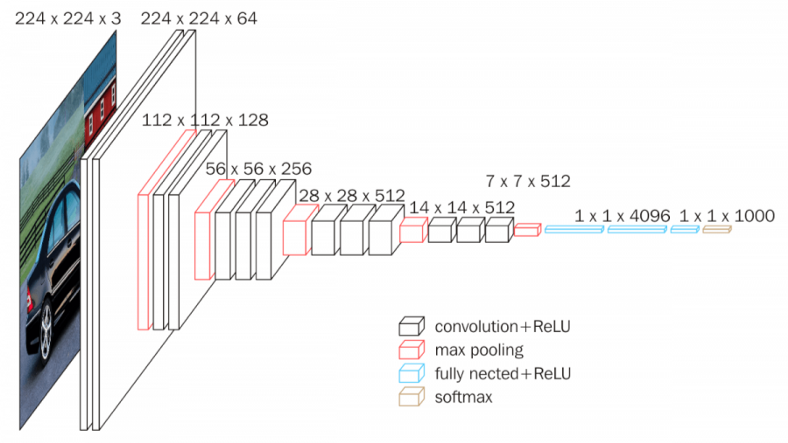
[2] M. ul Hassan, “VGG16-Convolutional Network for Classification and Detection,” en l{\’\i}nea].[consulta 10 abril 2019]. Dispon. en https//neurohive. io/en/popular-networks/vgg16, 2018.
[3] F. Morales, “keras-ocr — keras_ocr documentation,” 2021, Accessed: 13-Jul-2021. [Online]. Available: https://keras-ocr.readthedocs.io/en/latest/.
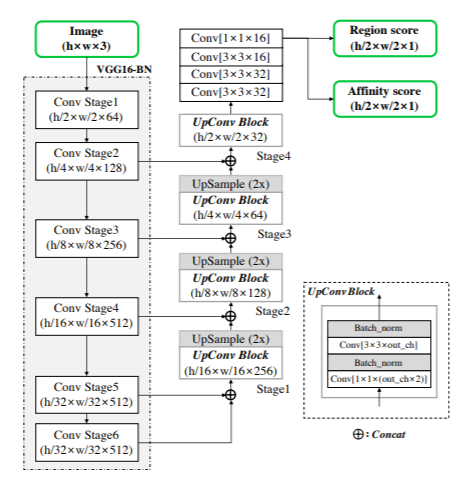
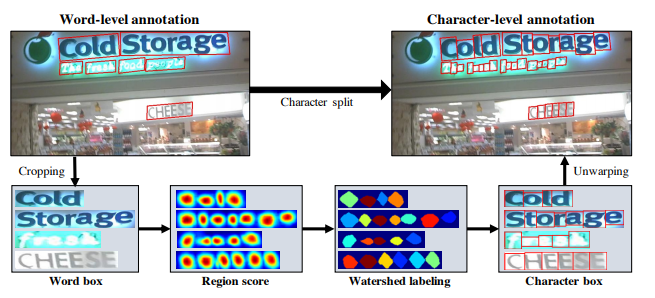
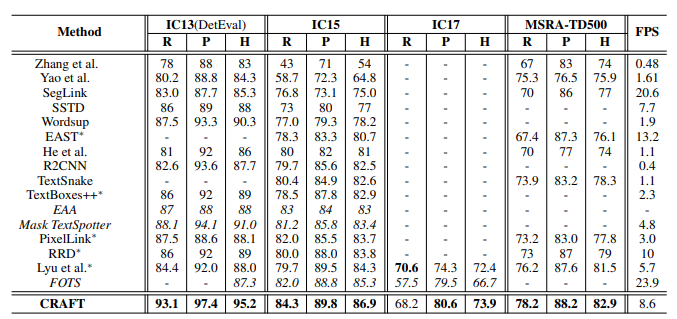
[4] Y. Baek, B. Lee, D. Han, S. Yun, and H. Lee, “Character region awareness for text detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 9365–9374.




Add a Comment
You must be logged in to post a comment