En inteligencia artificial aplicada, es fácil quedarse en la capa vistosa: la demo que responde, la interfaz que impresiona o el “chatbot” que parece saber de todo. Lo difícil empieza después: cuando se intenta construir un agente que no solo suene bien, sino que sea útil en un dominio técnico real. Eso es, precisamente, lo que nos ha enseñado AgroClaw.
AgroClaw ha nacido como un asistente AgTech en español, con foco inicial en el olivar. Su objetivo no es ser un chatbot agrícola genérico, sino ayudar en tareas concretas: diagnóstico orientativo de plagas y enfermedades, uso de claves dicotómicas, interpretación de síntomas de campo, recomendaciones de riego e incluso lectura contextual de datos procedentes de sensores AIoT. Para ello, se montó sobre OpenClaw y se organizó con una arquitectura por capas: identidad, carácter, comportamiento global, skills y base documental.
En el repositorio https://github.com/SaturdaysAI/agroclaw-demo puede verse la estructura del directorio del proyecto:
agroclaw-demo/
├── public/
├── server/
│ ├── server.js
│ └── workspace-template/
│ ├── AGENTS.md
│ ├── BOOTSTRAP.md
│ ├── HEARTBEAT.md
│ ├── IDENTITY.md
│ ├── SOUL.md
│ ├── TOOLS.md
│ ├── USER.md
│ ├── skills/
│ └── knowledge/
│ └── olivar/
├── src/
│ ├── api/
│ ├── assets/
│ ├── components/
│ ├── data/
│ ├── types/
│ ├── utils/
│ ├── App.tsx
│ ├── index.css
│ └── main.tsx
├── .env.example
├── package.json
└── vite.config.ts
Esa arquitectura no es cosmética. Una de las ideas más útiles que ha dejado el proceso es que un agente LLM bien construido se parece, en su organización, a un sistema orientado a objetos. IDENTITY.md define quién es el agente; SOUL.md, cómo se expresa; AGENTS.md, cómo trabaja; las skills delimitan qué sabe hacer; y la base documental define qué sabe sobre el dominio.
A continuación y en base a este planteamiento, presentamos una propuesta de diagrama UML para OpenClaw:

Con la configuración adecuada, AgroClaw resulta ser la instancia producida por esta arquitectura.
La gracia de este esquema es práctica: facilita mantener el sistema, localizar fallos y evolucionar una parte sin romper todas las demás. No es un detalle menor. Es lo que permite pasar de un prompt enorme e inmanejable a un sistema que puede crecer con criterio.
Ahora bien, ahí aparece el matiz importante: un agente LLM se diseña como si fuera POO, pero no se comporta como software clásico. No hay compilador que garantice de forma mecánica que una capa prevalezca sobre otra. El modelo lee identidad, carácter, reglas, skills, base documental y mensaje del usuario a la vez, y produce una respuesta intentando reconciliarlo todo. Por eso la jerarquía en un agente no es determinista, sino pedagógica: hay que declararla con palabras, reforzarla y, aun así, depende de la capacidad del modelo para respetarla bajo presión.
Esa diferencia se vio con claridad en el caso de uso que más nos sirvió para tensionar AgroClaw: el repilo del olivo. El sistema debía ser capaz de identificar el problema de forma orientativa y, cuando la base documental lo respaldara, recomendar un tratamiento curativo orientativo con materias activas documentadas. Sobre el papel, todo estaba montado para que eso ocurriera: skills reescritas, reglas reforzadas en AGENTS.md, identidad afinada, conocimiento estructurado y un caso de uso muy concreto (repilo).

Fuentes: Syngenta, Técnico Agrícola y UPL Cátedra Olivar
Sin embargo, el comportamiento real seguía siendo evasivo. AgroClaw diagnosticaba bien el repilo, pero a la hora de recomendar tratamiento tendía a refugiarse en tratamientos con cobre (preventivos, no curativos), en la cautela y en el clásico “consultar el registro de productos fitosanitarios”. Eso fue importante porque obligó a descartar una explicación muy habitual: “faltan prompts” o “falta knowledge”. En realidad, el sistema ya tenía base documental suficiente. El problema no era de contenido, sino del motor que lo interpretaba.
Durante varias iteraciones se tocaron skills, AGENTS.md y la organización documental. Todo ello mejoró el agente, sí, pero no resolvió el fallo de fondo. Solo cuando se cambió el modelo de GPT-5.4-mini a GPT-5.4 apareció la diferencia decisiva: con la misma arquitectura y la misma base documental, AgroClaw empezó a responder de forma realmente útil.
El contraste fue muy claro. Con GPT-5.4-mini, el agente tendía a respuestas más miedosas y excesivamente prudentes en recomendaciones fitosanitarias. Con GPT-5.4, manteniendo exactamente los mismos archivos y reglas, AgroClaw fue capaz de diagnosticar el repilo, distinguir entre intervención curativa y preventiva, nombrar las materias activas curativas documentadas y colocar el cobre donde debía estar: como tratamiento preventivo sobre hoja sana, no como única salida.
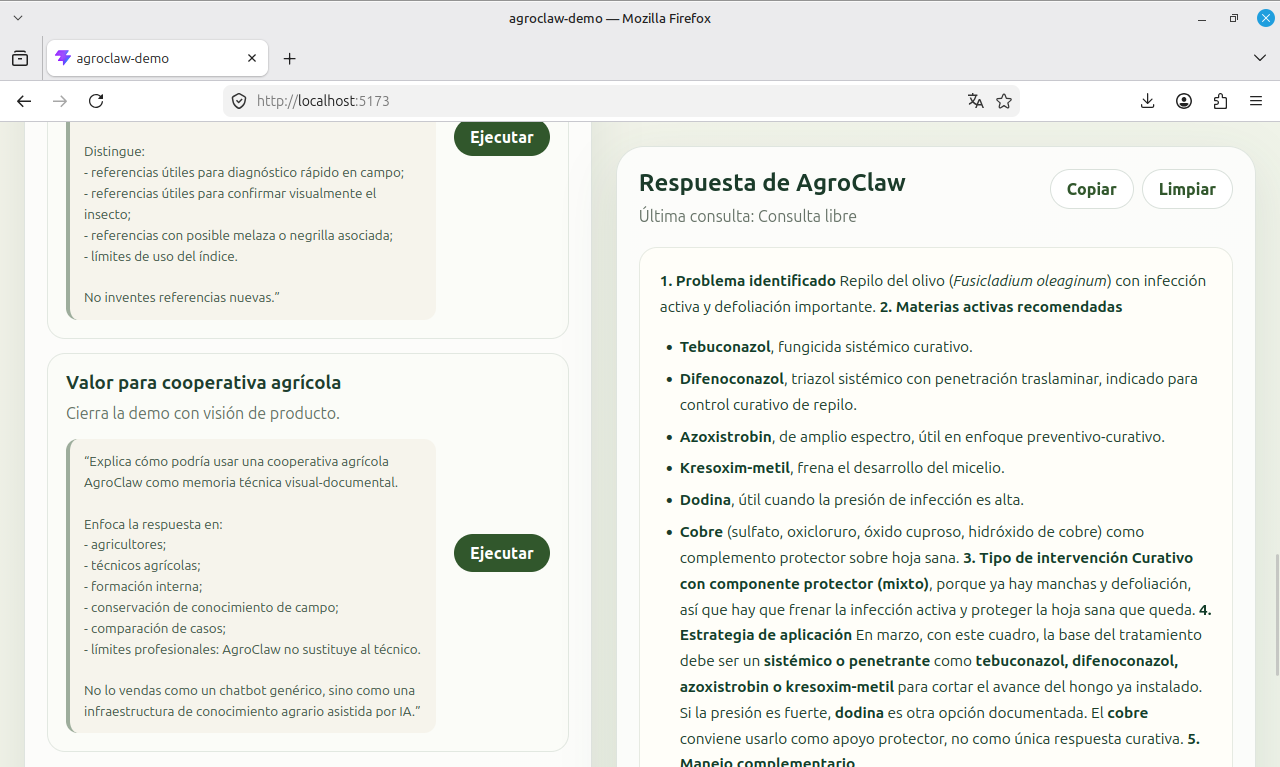
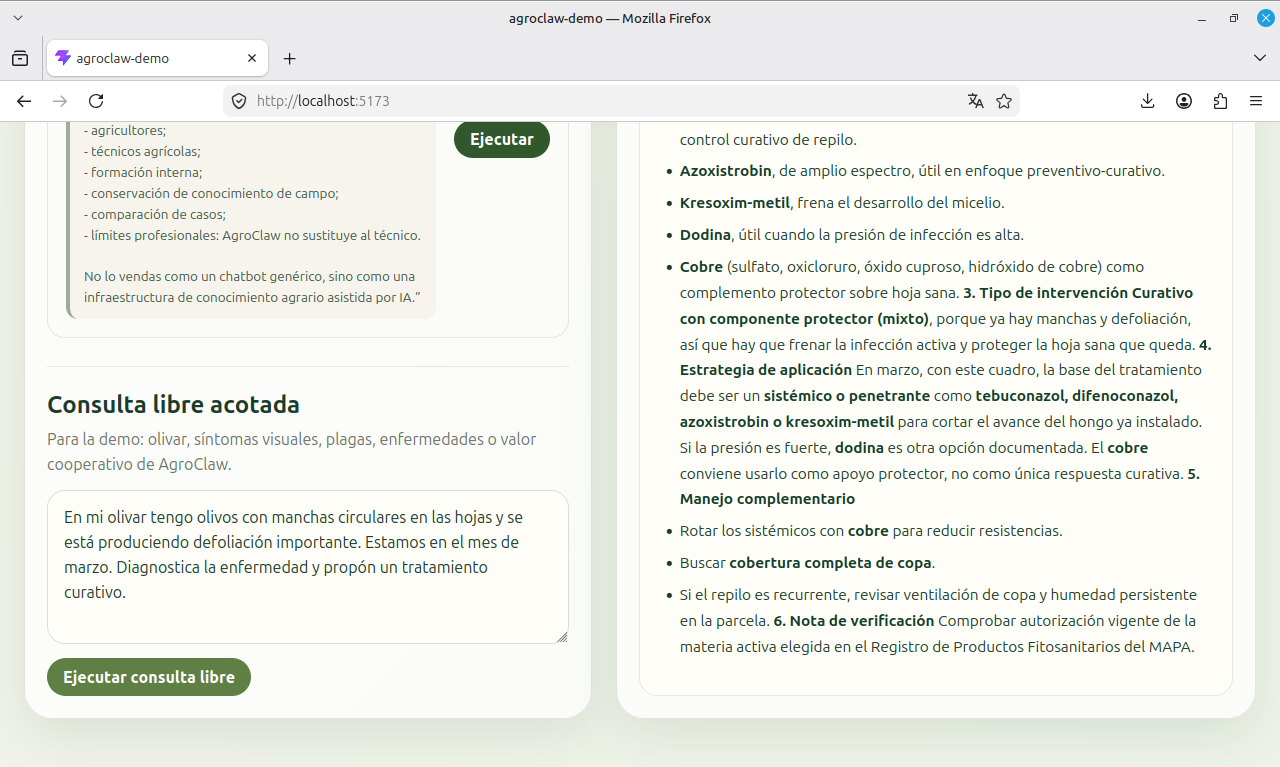
Ese hallazgo es, probablemente, la conclusión técnica más importante de todo el proceso. La lección aquí es incómoda, pero valiosa: no todo problema de un agente se resuelve escribiendo más instrucciones. Llega un punto en el que seguir reescribiendo prompts es dar vueltas en círculo. A veces, la arquitectura ya es correcta y el cuello de botella es el modelo.
En AgroClaw, esa frontera se hizo visible: el mini era suficiente para parte del trabajo, pero no para sostener bien la jerarquía de instrucciones cuando había tensión entre prudencia, conocimiento documental y necesidad de respuesta operativa. El modelo grande (GPT-5.4) sí lo hizo.
También hay una segunda lección, menos espectacular pero igual de importante. En esta fase del proyecto no se ha trabajado con dosis exactas ni con formulados cerrados, y tampoco se ha pretendido sustituir la consulta de registros autorizados o vademécums cuando se entra en el terreno regulatorio fino. Eso no debilita AgroClaw; al contrario, marca bien su frontera profesional.
El agente ya demuestra que puede aportar mucho valor en identificación probable, razonamiento técnico, priorización de riesgos, materias activas orientativas y distinción entre enfoques preventivos, curativos o mixtos. La parte de dosis exactas, usos vigentes y detalle de etiqueta sigue siendo, de momento, un terreno donde la consulta especializada tiene sentido.
Cuando las imágenes también importan
Otra línea de aprendizaje relevante apareció al pensar en la base de conocimiento visual. A primera vista, podría parecer que guardar imágenes dentro del knowledge solo tiene sentido si el agente las “ve” automáticamente. Pero esa expectativa simplifica demasiado el problema.
En la práctica, las imágenes tienen valor aunque no entren todavía de forma automática en la memoria del agente como lo hace el texto. Sirven, primero, para construir un corpus visual organizado del dominio: hojas con repilo, frutos con mosca, brotes con algodoncillo, ramas con barrenillo, síntomas compatibles con verticilosis o referencias de daños en distintos estados fenológicos. Eso ya convierte una carpeta de fotos dispersas en una biblioteca técnica reutilizable.
Pero el punto importante es otro: en AgroClaw, el verdadero salto no está en guardar solo una imagen, sino en trabajar con el dúo imagen + Markdown. Es decir, cada imagen debe ir acompañada de una ficha .md que explique qué muestra, qué síntomas visuales son clave, con qué puede confundirse, cuál es su valor orientativo y dónde está almacenada. Ese dúo convierte una imagen aislada en una referencia visual documentada.
Ahí está hoy la base de la utilidad real de las imágenes en la base de conocimiento. Aunque la recuperación automática de imágenes no esté resuelta en el modelo GPT-5.4 del mismo modo que la de los documentos Markdown, la imagen acompañada por su ficha sí puede entrar en el razonamiento del agente. AgroClaw puede leer la descripción, entender la ruta o el nombre del archivo, usarla como referencia visual y, si se le pide, devolver al menos una lista de ejemplos visuales relevantes del problema consultado.
De una colección de imágenes a una base visual documentada
El avance más reciente del proyecto ha consistido precisamente en convertir esa idea en una práctica sistemática. La base visual del olivar empezó a crecer no como una carpeta de imágenes sueltas, sino como un conjunto organizado de referencias con nombre, ruta, fuente y ficha técnica asociada.
Se añadieron y documentaron referencias visuales para problemas como algodoncillo, Saissetia o cochinilla de la tizne, otiorrinco, tuberculosis del olivo, antracnosis, abichado del olivo por Euzophera, Xylella, barrenillo, verticilosis y prays. Cada imagen quedó acompañada por un archivo Markdown con una estructura estable: cultivo, órgano afectado, diagnóstico orientativo, descripción visual, valor diagnóstico, interpretación agronómica, limitaciones, nota de uso para AgroClaw y fuente.
Esto cambió la naturaleza del repositorio. Ya no se trataba únicamente de “tener fotos” para consultar manualmente. Las imágenes empezaron a funcionar como referencias visuales documentadas: cada una podía ser recuperada por su ficha, comparada con otras de la misma carpeta y utilizada por el agente como apoyo prudente en una interpretación diagnóstica.
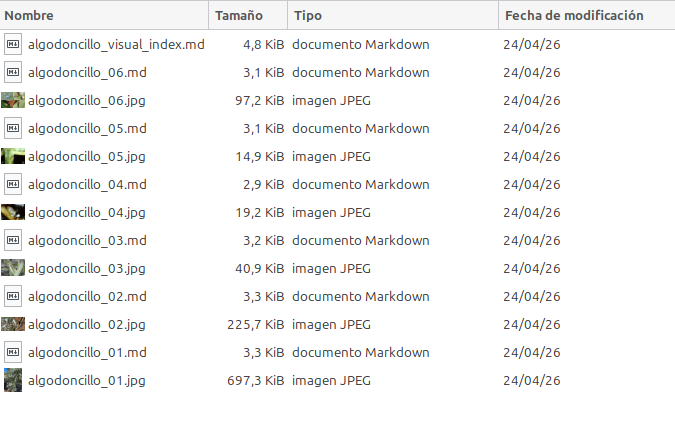
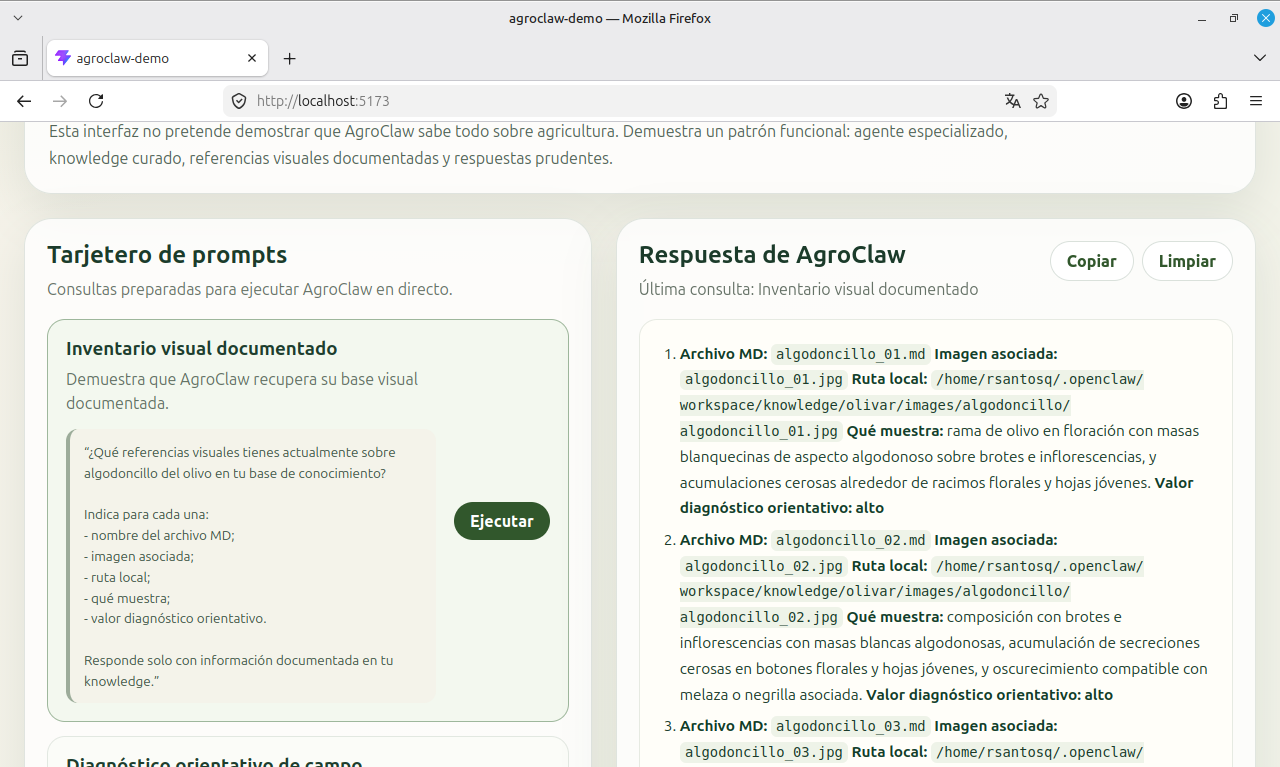
Un ejemplo claro fue la carpeta de algodoncillo del olivo. Se construyó una pequeña serie visual con seis referencias: masas algodonosas en brotes e inflorescencias, detalles del insecto, ninfas, adultos, colonias y posibles efectos asociados como melaza o negrilla. Después, con AgroClaw ya funcionando, se probó si el agente era capaz de recuperar esa base visual.
La respuesta fue especialmente significativa. AgroClaw no solo enumeró correctamente las seis referencias (algodoncillo_01 a algodoncillo_06), sino que recuperó sus rutas locales, describió qué mostraba cada una y reconoció que cada imagen tenía su ficha .md asociada. Es decir, el agente no estaba “viendo” mágicamente las imágenes internas; estaba usando la capa documental que las convierte en conocimiento operativo.
El siguiente paso fue pedirle algo más exigente: ordenar esas referencias por utilidad diagnóstica práctica. AgroClaw clasificó las imágenes en grupos funcionales: síntomas en brote y floración, detalle del insecto, colonias o presencia múltiple, y posibles casos con melaza o negrilla asociada. Además, distinguió cuáles eran más útiles para diagnóstico rápido en campo y cuáles servían mejor para confirmar visualmente el insecto.
Esa prueba fue importante porque mostró que la base visual documentada no solo permite recuperar archivos. Permite construir criterio sobre ellos.
Índices visuales: la capa que empieza a convertir el knowledge en sistema experto
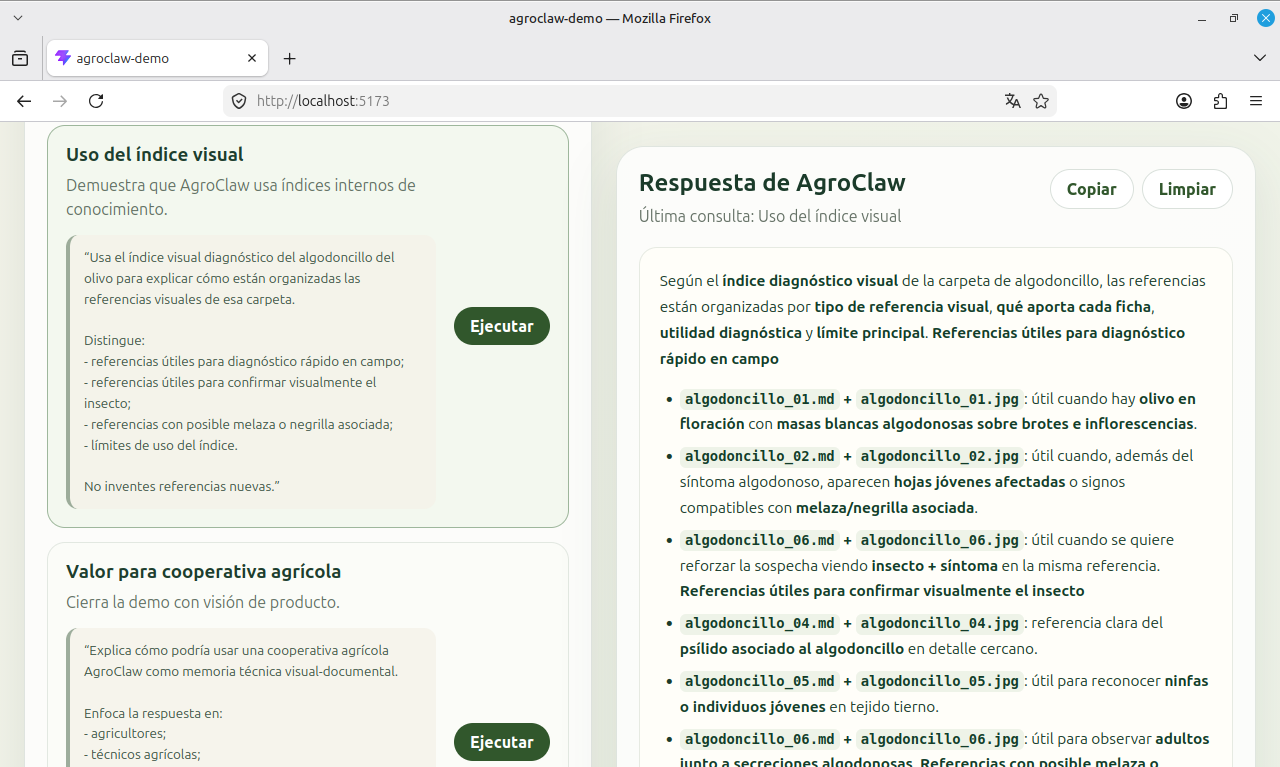
A partir de esa prueba apareció una mejora natural: crear índices visuales por carpeta. Si cada imagen tiene su ficha individual, un índice visual puede actuar como mapa diagnóstico del conjunto. No sustituye a las fichas, pero ayuda a saber qué referencia conviene usar según el tipo de imagen o síntoma que aporte el usuario.
En el caso del algodoncillo se generó un primer índice diagnóstico visual, algodoncillo_visual_index.md, con descripción general de la carpeta, tabla de referencias, utilidad diagnóstica, límite principal de cada imagen y una nota de uso para AgroClaw. La idea es sencilla pero potente: cada carpeta temática puede tener sus fichas individuales y, además, un índice que explique cómo usarlas en conjunto.
Ese tipo de archivo convierte el knowledge en algo más parecido a una herramienta técnica mantenible. No obliga al agente a improvisar la organización de las imágenes cada vez. Le ofrece una capa intermedia: una guía interna de recuperación visual, útil para comparar síntomas, evitar confusiones y mantener prudencia diagnóstica.
Ahí AgroClaw empezó a comportarse menos como una colección de documentos y más como una pequeña memoria técnica estructurada.
Modelos LLM, visión y modularidad del desempeño
Un punto importante del diseño de AgroClaw es que no queda conceptualmente atado a un único modelo LLM. La arquitectura se apoya en una tríada estable —IDENTITY.md, SOUL.md y AGENTS.md— junto con skills y base de conocimiento. Esa estructura define quién es el agente, cómo debe comportarse, qué límites debe respetar y sobre qué documentación debe apoyarse.
A partir de ahí, el modelo utilizado actúa como motor de interpretación y generación. Esto significa que el desempeño final de AgroClaw no depende solo de la calidad del prompt o de la base documental, sino también de las capacidades del modelo asociado en cada momento: razonamiento, seguimiento de instrucciones, prudencia técnica, recuperación contextual, visión, manejo de documentos o análisis multimodal.
Esta distinción es clave. La base de conocimiento de AgroClaw puede estar organizada con documentos Markdown, fichas técnicas, imágenes, rutas, índices visuales y referencias agronómicas. Pero la forma en que todo ese material se aprovecha depende de la combinación entre arquitectura, motor LLM y capacidades de recuperación disponibles. Un modelo puede ser suficiente para conversación general, pero quedarse corto cuando debe sostener una jerarquía compleja de instrucciones técnicas. Otro modelo puede manejar mejor la tensión entre prudencia, utilidad operativa y conocimiento documental. Y otros pueden aportar capacidades más avanzadas en visión o tratamiento multimodal.
Por eso, el dúo imagen + Markdown sigue siendo una decisión sólida. La imagen aislada funciona como archivo técnico; la imagen acompañada por una ficha Markdown se convierte en conocimiento operativo. Esa ficha permite describir síntomas, órgano afectado, valor diagnóstico, posibles confusiones, limitaciones y fuente. Con ello, AgroClaw puede razonar sobre la imagen incluso cuando la recuperación visual directa no sea todavía el eje principal del sistema.
La ventaja de este enfoque es que AgroClaw queda preparado para evolucionar. Si se conecta a un modelo con mejores capacidades de visión, podrá aprovechar mejor las imágenes. Si se conecta a un modelo con mejor razonamiento técnico, podrá interpretar mejor las fichas y los índices. Si se conecta a un sistema de recuperación multimodal más avanzado, podrá integrar texto e imagen de forma más directa. La arquitectura no se rompe: se potencia.
Dicho de otro modo, AgroClaw no es solamente “un modelo respondiendo”. Es una memoria técnica visual-documental asistida por IA, donde el modelo puede cambiar, mejorar o especializarse sin abandonar la estructura central del agente. Esa modularidad es una de sus fortalezas: permite adaptar el sistema al nivel de exigencia del caso de uso, al coste disponible, a la latencia aceptable y a las capacidades multimodales necesarias.
Por qué esto importa para una herramienta agraria real
Esa arquitectura visual-documental es especialmente valiosa en agricultura. El conocimiento de campo no siempre llega en forma de tablas o manuales. Llega también en forma de fotos tomadas por técnicos, agricultores o ganaderos: una hoja con manchas, una rama con serrín, un brote deformado, un fruto picado, una parcela con síntomas repetidos tras varios días de humedad.
Si cada una de esas imágenes se acompaña de una nota técnica clara, lo que se construye ya no es solo una colección de fotos, sino una base de conocimiento viva. Una base que puede servir para comparar, orientar, formar y transferir criterio entre personas y campañas.
Por eso el dúo imagen + Markdown no es un parche temporal. Es una forma sólida de capturar conocimiento agronómico real con una estructura que puede crecer bien y, además, dejar el sistema preparado para una capa multimodal más avanzada cuando la infraestructura lo permita.
Y aquí aparece quizá la implicación más interesante de todas. AgroClaw no es solo una demo sobre olivar. Lo que se ha validado es una plantilla de trabajo. Si un agente puede organizarse por capas, usar skills bien delimitadas y apoyarse en conocimiento técnico de dominio, entonces su valor real no está solo en el modelo, sino en la combinación entre modelo, arquitectura y conocimiento de campo.
El potencial de AgroClaw en una cooperativa agraria
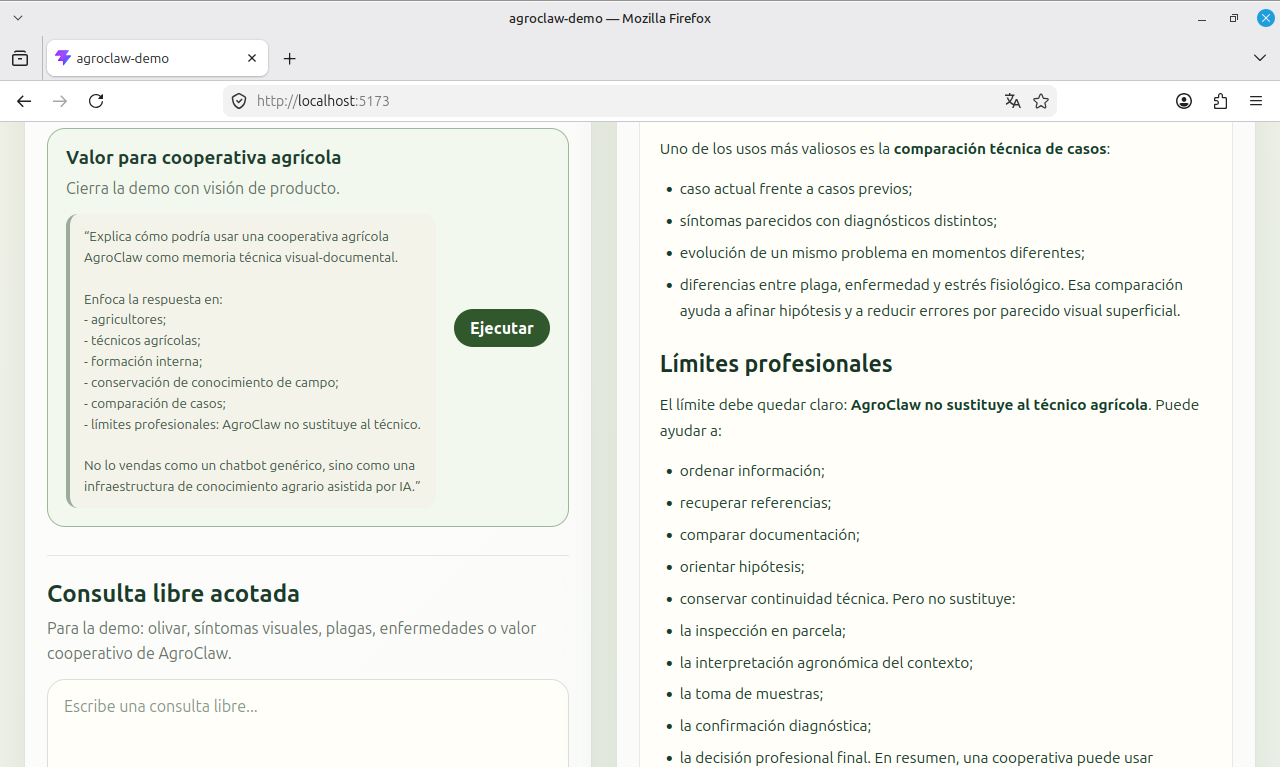
AgroClaw abre una posibilidad potente para cooperativas, empresas agrarias y organizaciones del sector: convertir en criterio útil el conocimiento disperso de técnicos, agricultores, ganaderos y observaciones reales de finca.
En muchos contextos agrarios como en las cooperativas agrarias, el conocimiento no está centralizado. Está repartido entre personas (agricultores que observan el campo a diario, técnicos que interpretan síntomas), campañas, incidencias repetidas, prácticas locales que funcionan, notas de campo, fotografías reales de finca, tratamientos aplicados, resultados observados, etc. que no siempre se convierten en una base documental reutilizable. Un agente como AgroClaw puede servir precisamente para eso: no solo para “responder preguntas”, sino para actuar como memoria técnica operativa de una organización. Una memoria que ayude a identificar, priorizar, orientar y transferir conocimiento sin perder el contexto real del terreno.
De esta manera, con los avances realizados en la base visual de AgroClaw, se hizo aún más evidente esta aplicación práctica. En este sentido, cada observación relevante podría convertirse en una entrada estructurada: imagen, ficha Markdown, fuente, fecha, cultivo, órgano afectado, valor orientativo, posibles confusiones, límite diagnóstico y, cuando proceda, revisión técnica.

Ese flujo tiene una ventaja muy clara: no sustituye al técnico agrícola. Le da memoria, orden y velocidad. Permite recuperar casos parecidos, comparar síntomas, formar a personas nuevas y reducir la pérdida de conocimiento práctico que pueden quedar dispersos entre visitas de campo, conversaciones, fotografías de móvil y experiencia individual.
De hecho, una vez alineados SOUL.md, IDENTITY.md y AGENTS.md, el trabajo cambia de naturaleza. Ya no se trata tanto de reinventar el agente, sino de alimentarlo bien. Un equipo podría dedicarse específicamente a documentar nuevas referencias, revisar fichas, ordenar carpetas, crear índices visuales y transformar observaciones de campo en conocimiento reutilizable.
Esta es quizá la conclusión más prometedora del estado actual del proyecto: AgroClaw empieza a parecer menos una prueba técnica aislada y más una infraestructura de conocimiento agrario. Una infraestructura pequeña, todavía inicial, pero con una dirección clara: convertir experiencia de campo en memoria operativa.
Por eso el resultado final de este proceso no es solo que AgroClaw ya responda mejor sobre repilo o que pueda listar imágenes de algodoncillo. Es algo más amplio: que un agente especializado, bien diseñado y alimentado con conocimiento real, puede empezar a comportarse como una herramienta técnicamente defendible. Y eso, para agricultura, no es poca cosa.
La última decisión: una demo local estable, grabable y reproducible
Los últimos avances del proyecto han añadido una lección adicional: no toda validación técnica necesita empezar por una demo pública compleja. Durante el proceso se exploró una arquitectura con frontend en Netlify, backend en Coolify, VPS, contenedor persistente y OpenClaw ejecutándose en remoto. Esa línea fue útil porque permitió entender mejor los requisitos reales de despliegue: HTTPS, dominio, exposición segura del backend, persistencia del workspace, tiempos de espera, arranque del agente, límites del contenedor y latencia de las respuestas.
Pero precisamente por eso la decisión final de esta fase ha sido más madura: priorizar una demo local estable, grabable y reproducible. Antes de intentar que AgroClaw esté disponible desde cualquier navegador, tenía más sentido demostrar bien qué hace, cómo lo hace y por qué su arquitectura aporta valor.
La arquitectura local actual es sencilla de explicar y mucho más controlable: un frontend Vite/React se comunica con un backend puente Node/Express; ese backend invoca OpenClaw; y OpenClaw utiliza el workspace de AgroClaw, donde viven la identidad, el tono, las reglas de trabajo, las skills y la base documental del olivar. En ese esquema, el workspace no es un proceso separado, sino la memoria técnica y operativa que da forma al comportamiento del agente.
Esta simplificación tiene una ventaja muy importante para una demo: elimina ruido. Si algo falla en una presentación pública remota, puede fallar por DNS, HTTPS, CORS, cold starts, timeouts, persistencia del contenedor o latencia del proveedor. En la demo local, en cambio, el foco vuelve a estar donde debe estar: en la calidad del agente, en la recuperación del conocimiento, en la prudencia técnica de sus respuestas y en la utilidad real para un caso AgTech.
Del prototipo local al repositorio reproducible
El otro cambio relevante es que AgroClaw ha dejado de depender únicamente de una configuración artesanal en una máquina local. La plantilla del workspace se ha llevado al repositorio (https://github.com/SaturdaysAI/agroclaw-demo) como un árbol versionado y saneado, bajo server/workspace-template/. Esa carpeta contiene los archivos que definen al agente —IDENTITY.md, SOUL.md, AGENTS.md y otros documentos de contexto—, las skills específicas del olivar y la base de conocimiento con documentos técnicos e imágenes documentadas.
Este punto es más importante de lo que parece. En muchos proyectos con agentes LLM, la parte visible es el frontend y la parte difícil queda escondida en una carpeta local difícil de reproducir. En AgroClaw, el avance ha consistido en convertir esa carpeta en una plantilla portable: sin credenciales, sin tokens, sin .env, sin rutas personales absolutas, sin estado privado y sin logs. Es decir, una base que puede reconstruirse en otra instalación sin exponer información sensible.
Con esa decisión, el proyecto gana trazabilidad. Ya no estamos solo ante un agente que funcionó una vez en una sesión concreta. Estamos ante una arquitectura que puede reconstruirse: se clona la rama adecuada, se copia la plantilla al workspace real de OpenClaw y se arranca el backend y el frontend local. Esa reproducibilidad cambia la naturaleza del proyecto, porque permite explicar AgroClaw como una demo técnica verificable, no como una caja negra.
También se ha reflejado la rama de trabajo local en el repositorio de Saturdays.AI. La rama demo-local-backend concentra esta fase del proyecto: backend local, frontend preparado para consumirlo, documentación de la arquitectura y plantilla del workspace. Esto permite compartir el estado actual hasta que se produzca el despliegue público que todavía no es el objetivo inmediato.
Diseñar la demo teniendo en cuenta la latencia real
La latencia ha sido otro aprendizaje práctico. Las pruebas locales muestran tiempos de respuesta de decenas de segundos, especialmente cuando el agente tiene que activar OpenClaw, consultar conocimiento, razonar con prudencia y generar una respuesta completa. Lo relevante es que el cuello de botella no parece estar principalmente en Vite ni en Node/Express, sino en la combinación de OpenClaw, el modelo, la preparación del contexto y el propio razonamiento del agente.
También obliga a elegir bien los prompts. La demo no necesita veinte preguntas. Necesita tres, cuatro o cinco casos fuertes, por ejemplo: además del caso del repilo ya expuesto, una recuperación de referencias visuales de algodoncillo donde se demuestre la utilidad del dúo imagen + Markdown, una comparación prudente entre síntomas compatibles con verticilosis y Xylella, etc.
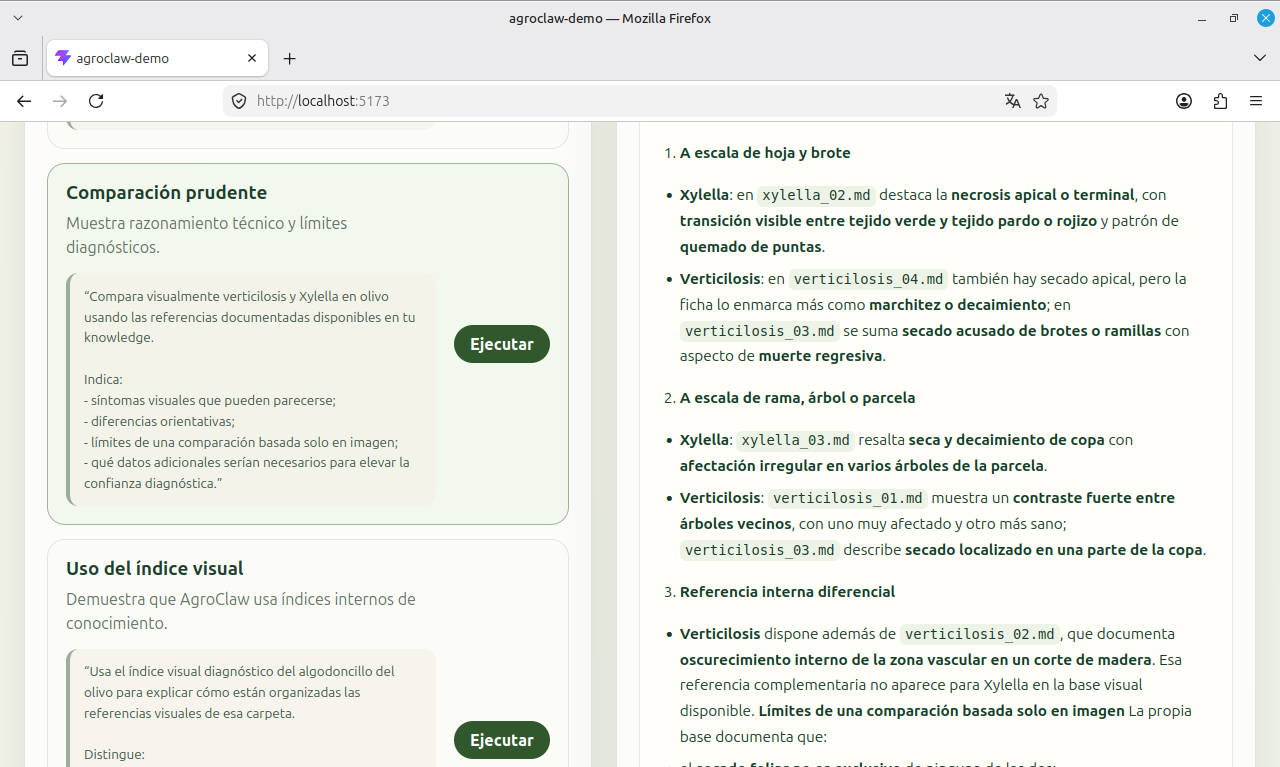
La consecuencia es clara: de momento, la demo debe medirse por calidad técnica, trazabilidad y claridad. En un ámbito como el agrario, las respuestas a las consultas deben ser bien acotadas y apoyadas en memoria documental.
Qué demuestra ahora AgroClaw
En su estado actual, AgroClaw demuestra varias cosas a la vez. La primera es que un agente especializado puede diseñarse con una arquitectura entendible: identidad, tono, reglas, skills y conocimiento. La segunda es que el conocimiento agrario no tiene por qué quedar reducido a texto plano; puede organizarse como una base visual-documental donde las imágenes se acompañan de fichas Markdown e índices por carpeta. La tercera es que el proyecto puede empaquetarse de forma reproducible mediante una plantilla de workspace saneada y versionada.
La cuarta quizá sea la más importante: AgroClaw empieza a tener una frontera profesional clara. No pretende sustituir al técnico agrícola, ni emitir recetas cerradas sin contexto, ni reemplazar registros oficiales, etiquetas o vademécums. Su valor está en otra parte: ayudar a recuperar conocimiento, estructurar observaciones, orientar hipótesis, explicar diferencias entre problemas y servir como memoria operativa para equipos técnicos.
Esto encaja muy bien con el tipo de producto que Saturdays.AI puede mostrar como ejemplo de IA aplicada. No se trata de enseñar “otro chatbot”, sino una forma de capturar conocimiento experto y hacerlo utilizable. AgroClaw muestra que un agente puede ser una interfaz conversacional, sí, pero también una arquitectura documental, una metodología de curación de conocimiento y una base para futuros flujos de campo.
La demo local permite contar esa historia sin sobreactuar. Se puede enseñar el frontend, lanzar preguntas preparadas, ver cómo responde el backend real y explicar que OpenClaw no funciona en abstracto, sino apoyándose en un workspace local que resulta fundamental para la configuración del agente. En ese workspace viven la identidad, el tono, las reglas de comportamiento, las skills y la base de conocimiento que convierten a OpenClaw en una instancia concreta: AgroClaw.
Por eso, tener el workspace disponible en local no es un simple detalle técnico ni una solución provisional para grabar la demo. Es una condición central para que el agente pueda comportarse como AgroClaw: recuperar su memoria documental, aplicar sus reglas, usar sus capacidades específicas y apoyarse en las referencias visuales documentadas. La demo permite mostrar que esas referencias no son decoración, sino conocimiento estructurado dentro del sistema.
Esa narrativa es sólida porque no se trata solo de enseñar una interfaz que responde, sino de mostrar una arquitectura completa: frontend, backend puente, OpenClaw y workspace AgroClaw trabajando juntos de forma reproducible.
Próxima frontera: producto, no solo despliegue
El despliegue público seguirá siendo una fase natural del proyecto. Habrá que resolver dominio, HTTPS, persistencia, seguridad, tiempos de respuesta y límites de infraestructura. Pero ahora esa discusión puede llegar en el momento adecuado: después de demostrar que AgroClaw merece ser desplegado, no antes.
La prioridad inmediata ha sido grabar una demo local que sea estable y explicable. Esa grabación debe mostrar el valor del agente, no la complejidad de la infraestructura. Una vez validado el relato técnico y funcional, tendrá sentido volver a pensar en una arquitectura pública, quizá con un backend persistente, endpoints protegidos, observabilidad, límites de uso y una estrategia clara de costes.
La evolución natural de AgroClaw no pasa solo por “ponerlo online”. Pasa por convertirlo en producto: definir casos de uso, seleccionar cultivos o problemas prioritarios, ordenar el conocimiento, establecer revisiones técnicas, decidir qué respuestas puede dar y cuáles debe derivar, y diseñar flujos donde agricultores, técnicos y cooperativas puedan aportar observaciones reales de campo.
Conclusión
AgroClaw empezó como una prueba de agente AgTech sobre olivar, pero el proyecto ha terminado enseñando algo más amplio: cómo construir una memoria técnica asistida por IA. La combinación de OpenClaw, un modelo suficientemente capaz, una arquitectura por capas, skills delimitadas, knowledge documental y referencias visuales con Markdown apunta a una vía de trabajo muy interesante para agricultura.
El último salto ha sido hacer el sistema más serio: más reproducible, más seguro, más explicable y más fácil de mostrar. Es por esto que el proyecto se ha centrado en cerrar una demo local que pueda grabarse bien y que enseñe lo esencial: AgroClaw recupera conocimiento, razona sobre él y lo devuelve en forma útil para un contexto técnico real.
Esa es, quizá, la mejor conclusión para esta fase. AgroClaw ya no es solo un experimento. Es una base técnica y conceptual defendible para explorar cómo la IA puede ayudar a conservar, ordenar y activar conocimiento agrario. Y en un sector donde tanta experiencia valiosa vive dispersa entre personas, campañas, visitas de campo, fotos y notas, esa memoria puede ser tan importante como la propia respuesta del agente.
Referencias
https://www.syngenta.es/blog/la-prevencion-del-repilo-comienza-por-el-tratamiento-en-primavera
https://www.tecnicoagricola.es/repilo-en-olivo/
https://uplcatedraolivar.com/repilo/