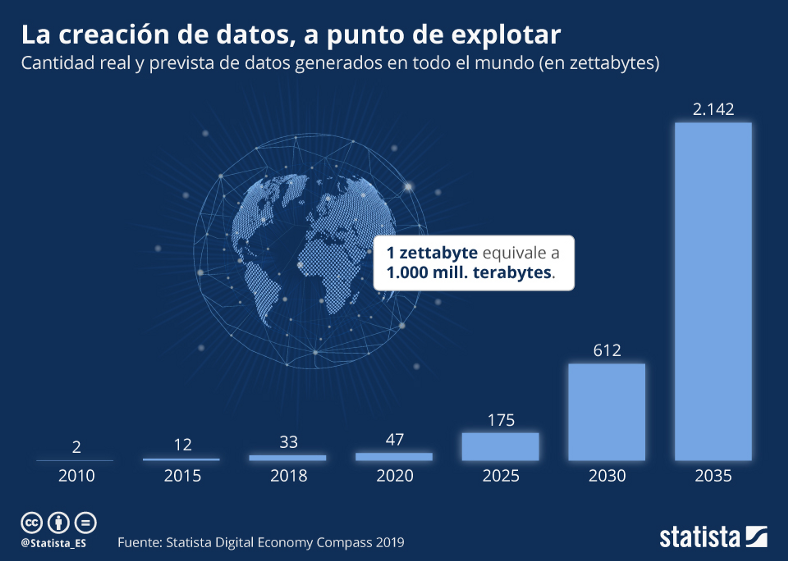
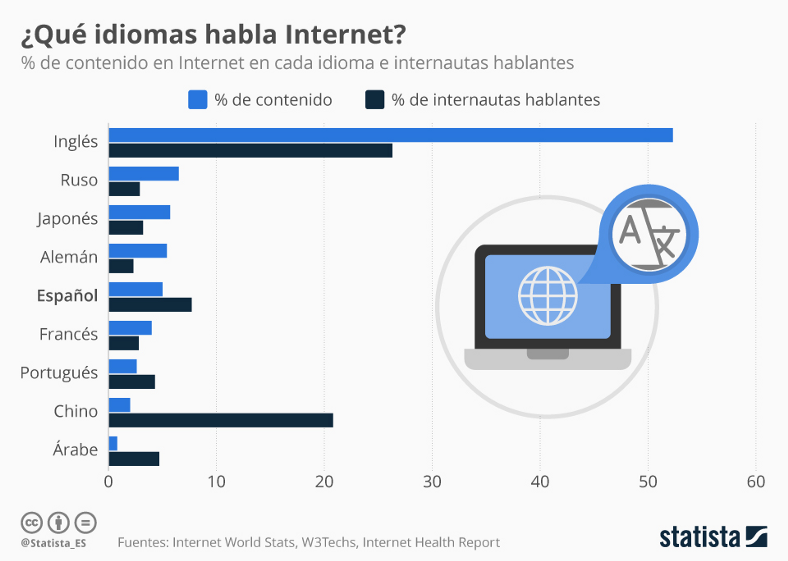
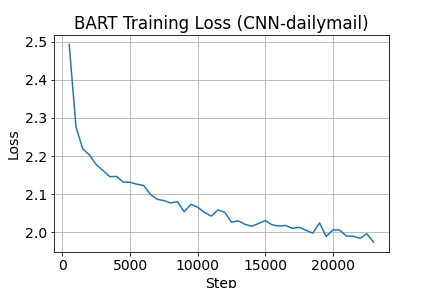
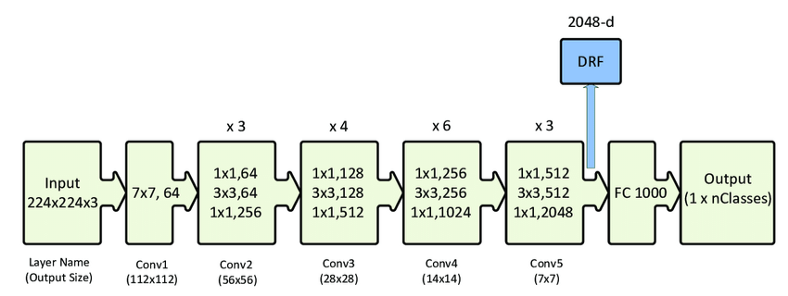
Para realizar el fine tuning se hizo uso del dataset “cnn_dailymail”, para la evaluación se utilizó la métrica “rouge”, y el modelo base que se usó fue “facebook/bart-base”.
raw_datasets = load_dataset(“cnn_dailymail”, “3.0.0”)
metric = load_metric(“rouge”)
model_checkpoint = “facebook/bart-base”
Se cargaron un tokenizer y un modelo haciendo referencia al modelo base seleccionado.
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
Del dataset “cnn_dailymail” se extrajeron los elementos que se encuentran bajo las etiquetas de “article” y “highlights” como datos de entrada y salida respectivamente.
max_input_length = 512
max_target_length = 128def preprocess_function(examples):
inputs = [doc for doc in examples[“article”]] model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(examples[“highlights”], max_length=max_target_length,
truncation=True)model_inputs[“labels”] = labels[“input_ids”] return model_inputstokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
Antes de entrenar el modelo se realiza la configuración de hiperparámetros.
batch_size = 4
args = Seq2SeqTrainingArguments(
“BART_Finetuned_CNN_dailymail”,
evaluation_strategy = “epoch”,
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
gradient_accumulation_steps=2,
weight_decay=0.01,
save_total_limit=2,
num_train_epochs=1,
predict_with_generate=True,
fp16=True,
)
Se crea una función para realizar el cómputo de métricas haciendo uso de rouge score.
def compute_metrics(eval_pred):
predictions, labels = eval_pred
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
# Replace -100 in the labels as we can’t decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Rouge expects a newline after each sentence
decoded_preds = [“\n”.join(nltk.sent_tokenize(pred.strip())) for pred in decoded_preds]decoded_labels = [“\n”.join(nltk.sent_tokenize(label.strip())) for label in decoded_labels]
result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
# Extract a few results
result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
# Add mean generated length
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in predictions]result[“gen_len”] = np.mean(prediction_lens)
return {k: round(v, 4) for k, v in result.items()}
Una vez inicializado el modelo, definidos los hiperparámetros, datasets, tokenizer y métricas creamos un Trainer.
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets[“train”],
eval_dataset=tokenized_datasets[“validation”],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
Descargamos punkt tokenizer que nos permite transformar un texto por oraciones.
nltk.download(‘punkt’)
Finalmente realizamos el entrenamiento y la evaluación
trainer.train()trainer.evaluate()
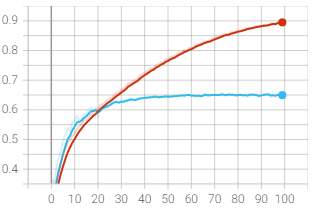
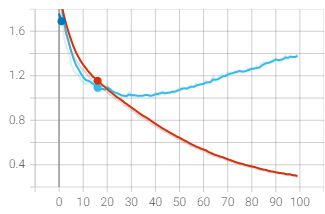
Resultados