Latam online. Segunda Edición. 2021
A mucha gente le motiva los retos en el trabajo, en los estudios y en la vida en general, pero pregunto, puedes imaginar una vida en donde cada día existen retos diferentes, iniciando desde la mañana cuando al levantarte y tomar un refrescante baño en la mañana, debes hacer lo necesario para no tropezar en el camino para encontrar tu ropa y combinarla adecuadamente para la ocasión, pues hoy debes ir al centro de la ciudad a cumplir con unos trámites burocráticos que requieres, además de hacer las compras del supermercado para la semana. Luego de prepararte un café y conseguir que no se te riegue del borde de la taza, estás listo para empezar tu día, sales de tu casa y esperas no tener que tropezar con obstáculos que son comunes en la calle: basura que no llegó a su respectivo tacho, las mejoras de la ciudad caracterizadas por sus constantes cambios de planificación a costa de dejar trabajos inconclusos en las calles, los no tan amigables perros en la calle que podrían poner a prueba tu instinto y la razón, pero bueno es algo que uno ya sabe y lo que debe hacer es llegar hasta la estación del bus y esperar que algún transeúnte de buen corazón te ayude a identificar la línea de bus que te acerque a tu destino. Ya habrá tiempo para ir luego al supermercado, conseguir lo necesario y confiar en recibir lo justo como cambio o tener la seguridad de pagar lo que corresponda.
Estas situaciones describen una vida llena de retos que deben afrontar las personas no videntes cotidianamente, y que muchas veces les impide integrarse socialmente en entornos laborales, comerciales, de ocio e incluso incrementan su dependencia de terceros, lo cual supone, además, un impacto psicológico que eventualmente y de a poco va minando su autoestima.
Dependiendo de la edad en que las personas no-videntes pierden el sentido de la vista puede llegar a ser una experiencia más o menos traumática que podrá ser llevadera si se cuenta con apoyo emocional sobre todo en la etapa inicial y se trabaja fuertemente para educarse y adaptarse a su nueva condición y calidad de vida, que demandará pasar por un tortuoso camino de duelo por la pérdida de la vista.
A pesar de estas situaciones nada alentadoras, existen muchas personas que no se dejan vencer por la adversidad y logran con éxito adaptarse tanto emocional y socialmente para llevar una vida digna y con razones para continuar retando la adversidad día a día.
De acuerdo a la OMS [1] “A nivel mundial, se estima que aproximadamente 1300 millones de personas viven con alguna forma de deficiencia visual.
A nivel mundial, las principales causas de la visión deficiente son los errores de refracción no corregidos y las cataratas.
La mayoría de las personas con visión deficiente tienen más de 50 años.”
Además, El deterioro de la vista o su pérdida, tiene impactos en la calidad de vida de las personas que lo padecen, de acuerdo a OMS, “Los niños pequeños con deterioro grave de la visión a edad temprana pueden sufrir retrasos en el desarrollo motor, lingüístico, emocional, social y cognitivo”.
“En el caso de los adultos mayores, el deterioro de la visión puede contribuir al aislamiento social, a la dificultad para caminar, a un mayor riesgo de caídas y fracturas, y a una mayor probabilidad de ingreso temprano en residencias de ancianos.”
The Lancet Global Health [ 2] afirma que:
“En 2020, un estimado de 596 millones de personas a nivel mundial, tienen deficiencia de visión a distancia, y de estos 43 millones son ciegos.”
“Una proporción grande de estos (90%), viven en países de ingresos bajos o medios”.
“Para 2050, el envejecimiento de la población, el crecimiento y la urbanización conllevarán un estimado de 895 millones de personas con deficiencia visual a distancia y 61 millones de ciegos.”
Ante esta problemática, y como parte de la aplicación práctica de un curso de Machine Learning [ 3] e Inteligencia Artificial (IA) [4], nace la idea de usar la tecnología para identificar ideas que puedan abordar la problemática de las personas con discapacidad visual y diseñar una herramienta que les apoye en la consecución de sus actividades cotidianas. La idea del grupo fue pensar en un proyecto que pueda aportar socialmente y que tenga un impacto en la comunidad. Desde el punto de vista de los Objetivos de Desarrollo Sostenible (ODS) [5] estarían relacionados: Salud y bienestar, Industria, innovación e infraestructura, reducción de las desigualdades y alianzas para lograr los objetivos.
El proyecto Ciclope.IA, como lo hemos llamado, busca integrar en una aplicación para celular, diferentes opciones (skills) orientadas a solucionar limitaciones que experimentan personas con discapacidad visual en sus actividades cotidianas tales como: Reconocimiento de billetes y monedas de manera rápida y efectiva, identificación de la línea de autobús, identificación de colores, conocer el nivel de llenado de un recipiente, encontrar objetos perdidos, etc.
Como se puede observar las opciones que se pretenden integrar son ambiciosas y demandarán un trabajo extenso, sin embargo, es necesario empezar por algo, se suele decir que una “torta se la come en pedazos” y es por ello que la aplicación inicialmente dispone de la funcionalidad que permite al usuario reconocer la cantidad de dinero en efectivo en dólares (billetes), haciendo uso de la cámara de su celular. Posterior a la detección, la app reproduce un mensaje de voz con el resultado del monto reconocido. El uso de Ciclope.IA brinda al usuario seguridad y autonomía al momento de realizar transacciones en efectivo y disminuye el riesgo de ser víctima de engaño. La interacción con la aplicación se puede realizar en idioma español bajo el sistema operativo Android.
Alcance inicial del proyecto
Cuando iniciamos el proyecto y luego de un acercamiento con un grupo de no-videntes identificamos algunas opciones (skills) que deberíamos incluir en la aplicación, así que para tomamos la opción más frecuentemente demandada que es la de identificación de billetes al momento de realizar transacciones monetarias con terceros. Adicionalmente se conoció que la mejor forma de interacción con personas no-videntes es a través de audio, por lo que decidimos que la interacción del usuario con la aplicación se debía hacer a través de voz tanto de entrada como de salida.
Para soportar nuestra configuración revisamos en algunas estadísticas en el sitio yiminshum.com, “actualmente hay 5.190 millones de usuarios únicos en dispositivos móviles, donde no divide el tipo de teléfono, esto cubre el 67% de la población.”
“El 73% de las personas están conectadas y comparten su tiempo desde un teléfono inteligente o smartphone. El 23,5% está asociado en un teléfono común, donde sus funciones son las básicas y limitadas que debe cumplir un teléfono que es llamar y enviar mensajes y el 3,6% está asociado a un router, tablet o PC móvil.”
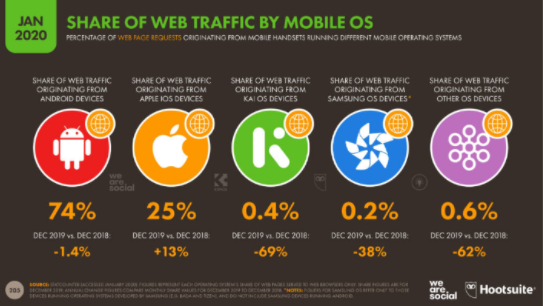
“OS mejor conocido como sistema operativo, son importantes para el funcionamiento de los equipos en el mundo, el 74% de los usuarios son en equipos Android, 25% es iOS, 0,4% es KAI, 0,2% Samsung OS y 0,6% otros sistemas operativos.”
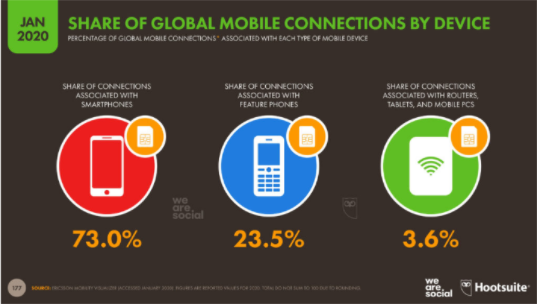
Con esta información se limitó el alcance del proyecto a teléfonos inteligentes Android que cubre una gran parte del mercado sobre todo en lugares diferentes a los Estados Unidos, a países hispanohablantes y que tengan su moneda de uso corriente el Dólar.
IA Aplicada
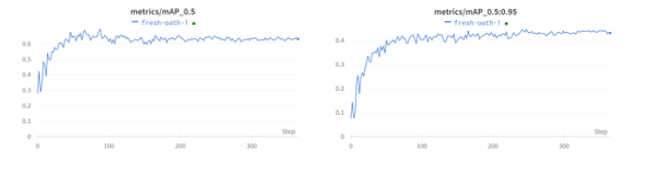
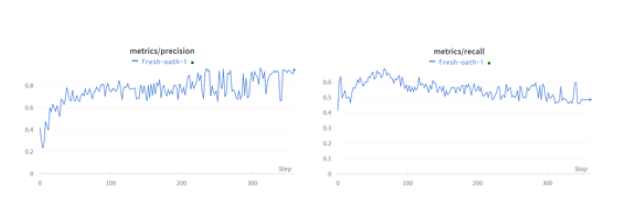
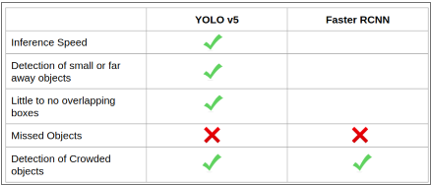
Frente a la problemática identificada se determinó que la mejor manera de apoyar a personas no-videntes es desarrollar una aplicación para celular que haga las veces de sus ojos en situaciones que se requieran, para ello desde el punto de vista técnico se exploraron diferentes modelos de reconocimiento de imágenes que podrían aplicarse, y al final se decidió usar YoloV5 por la versatilidad al momento de identificar objetos y basados en pruebas realizadas por Towards Data Science [6] que recomiendan el modelo frente a otro también muy conocido, otros elementos que consideramos fue la posibilidad de usar el modelo sin necesidad de tener una conexión de internet activa sino un modelo pre-entrenado que se copia en el celular en una versión Pytorch Lite que ocupe menos tamaño y recursos.
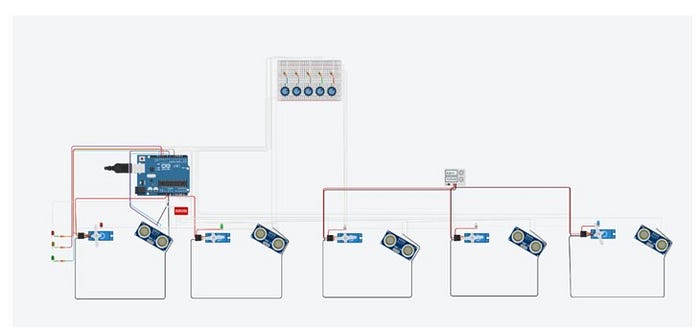
Para entrenar el modelo, se exploró opciones de dataset disponibles, desafortunadamente no se consiguió uno por lo que se optó por crear un dataset propio.
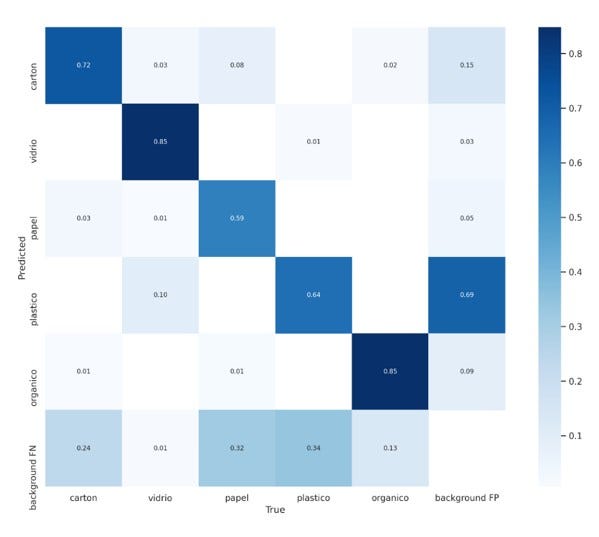
Unos de los grandes retos, justamente fue afinar el dataset para que incluya las imágenes adecuadas, considerando diferentes escenarios en los que podrían estar los billetes, considerar el reverso y adverso, y la cantidad suficientes de imágenes. Para conseguir las imágenes se usó una herramienta de Web scrapping y posteriormente con la herramienta online https://labelflow.ai/ se asignó a cada imagen las etiquetas para identificar a cada billete en las diferentes imágenes.
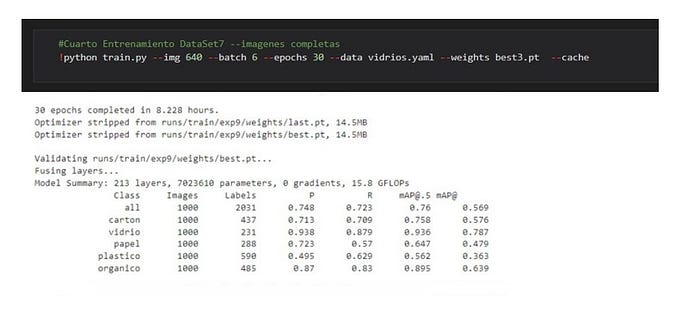
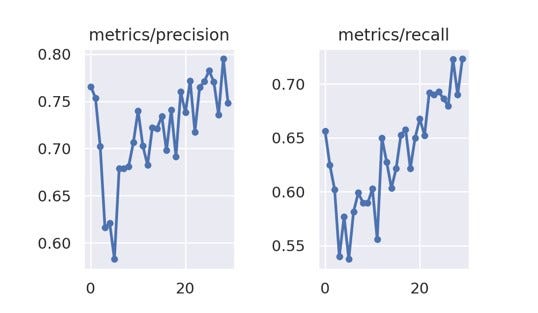
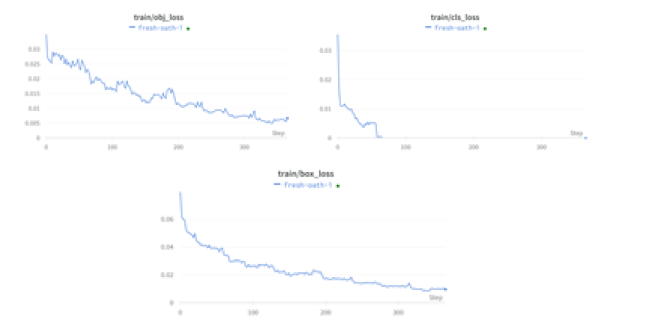
Luego de entrenar el modelo en la herramienta colab de Google se obtuvo un archivo con el mejor modelo generado y se lo uso en la aplicación de celular.
Sin lugar a dudas la IA dará solución a muchas problemáticas del día de hoy y permitirá que su aplicación se extienda masivamente en diferentes áreas del conocimiento y de la vida cotidiana. Nuestro trabajo es una pequeña muestra del potencial a explotar con IA y un aporte para aquellos interesados en apoyar a grupos como los no-videntes que deben superar la adversidad con poco o limitado apoyo de la sociedad.
Conclusiones
Las herramientas de Inteligencia Artificial pueden ser usadas para múltiples propósitos, sin embargo, desarrollar productos que permitan dar solución a necesidades de carácter social, representan una oportunidad enorme que reditúa en bienestar y mejora de la calidad de vida de grupos minoritarios de la sociedad.
Desde el punto de vista técnico el proyecto representó una oportunidad para continuar aprendiendo de este apasionante mundo de la IA y entender entre otras cosas que para crear modelos efectivos es importante trabajar de manera exhaustiva en:
- Crear o disponer de datasets de calidad.
- Aplicar diferentes modelos para evaluar el desempeño.
- Hacer a los usuarios participes del desarrollo de productos.
- Trabajar con equipos multidisciplinarios.
- Mantener una permanente búsqueda de nuevas soluciones.
Video de demostración
Refererencias
[1] Organización Mundial De La Salud. (2021). Ceguera y discapacidad visual. Retrieved January 12, 2022, from https://www.who.int/es/news-room/fact-sheets/detail/blindness-and-visual-impairment. [2] The Lancet Global Health. (2021). The Lancet Global Health Commission On Global Eye Health: Vision Beyond 2020. Retrieved January 12, 2022, from https://www.thelancet.com/journals/langlo/article/PIIS2214-109X(20)30488-5/fulltext [3] BBVA (2019). ¿Machine Learning que es y cómo funciona? Retrieved February 4, 2022 from https://www.bbva.com/es/machine-learning-que-es-y-como-funciona/ [4] Juan Antonio Pascual Estapé(2019). Inteligencia artificial: qué es, cómo funciona y para qué se utiliza en la actualidad. Retrieved February 4, 2022 from https://computerhoy.com/reportajes/tecnologia/inteligencia-artificial-469917 [5] Naciones Unidades (2021). La agenda para el desarrollo sostenible. Retrieved February 4, 2022. https://www.un.org/sustainabledevelopment/es/development-agenda/ [6] Towards Data Science (2020). YOLOv5 compared to Faster RCNN. Who wins?. Retrieved February 4, 2022. https://towardsdatascience.com/yolov5-compared-to-faster-rcnn-who-wins-a771cd6c9fb4Integrantes
- Alexander Cortes
- Ariosto Olmedo Cabrera
- Antonio Paucar
- Carlos Sesma
- Miriam Quimi
- Santiago Yunes
- Viviana Márquez
Presentación del proyecto: DemoDay
Repositorio
En el siguiente repositorio se encuentra el código usado para desarrollar esta aplicación: https://github.com/SaturdaysAI/Projects/tree/master/LATAM_remote/Ciclopeia
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!