Pablo Talavante es un reconocido experto en inteligencia artificial y aprendizaje automático, especializado en la vanguardia de la tecnología de IA. Su perfil como científico de datos e ingeniero destaca en áreas como visión por computadora y procesamiento del lenguaje natural, utilizando herramientas avanzadas como Python, TensorFlow y PyTorch. Además, su enfoque innovador hacia la aplicación de la IA en el arte lo posiciona como un visionario en la intersección entre la tecnología y la creatividad.
Fue mentor de Saturdays en el grupo de deep learning
Definición del Arte y el Impacto Innovador de la IA
Pablo Talavante contempla el arte como una forma de expresión creativa que ofrece una visión personal del mundo. En cuanto al papel de la IA en el arte, Talavante la compara con herramientas revolucionarias del pasado como los óleos en pintura o la cámara fotográfica. Aunque estas herramientas fueron en su momento novedosas y transformadoras, ahora son completamente normalizadas. Talavante sugiere que la IA está siguiendo un camino similar, proporcionando nuevas técnicas y procesos artísticos que antes no estaban disponibles. Él espera que, al igual que la fotografía cambió la percepción de lo figurativo, la IA fomente la exploración de nuevas formas de expresión artística.
La Legitimidad y Ética de la IA en la Creación Artística
Talavante aborda la legitimidad de la IA en el arte desde una perspectiva crítica. Reconoce la democratización que las herramientas de IA están trayendo al arte, pero está preocupado por la falta de transparencia y legislación en cuanto a los datos utilizados para entrenar estos modelos. Plantea un dilema ético: ¿es legítimo usar imágenes con derechos de autor para entrenar modelos de IA? Mientras reconoce que los artistas históricamente se han basado en obras anteriores, también plantea la cuestión de los derechos de autor y la originalidad en la era digital. Talavante sugiere que la fase de entrenamiento de un modelo de IA podría ser comparable a la fase de estudio y exploración de un artista, aunque reconoce que la cuestión de los derechos de autor sigue siendo un desafío.
Evaluando el Arte Generado por IA: Un Nuevo Paradigma
En cuanto a la evaluación del arte generado por IA, Talavante opina que no debería ser valorado de manera diferente al arte creado por humanos. Argumenta que, aunque la IA pueda parecer avanzada ahora, con el tiempo se normalizará y se integrará en el proceso creativo como cualquier otra herramienta. Critica el uso del término «arte con IA», señalando que se aplica a menudo de manera indiscriminada. Para Talavante, es crucial la intencionalidad detrás de la obra para poder clasificarla como arte, independientemente de si se ha utilizado IA o no. Resalta la importancia de ir más allá de la generación de imágenes y busca contar historias o transmitir mensajes, como lo hacen artistas que utilizan la IA de manera innovadora, como Mario Klingemann, Robbie Barrat, dadabots y Sofía Crespo.
Mario Klingemann. Appropriate Response, 2020
Información acerca de Saturdays.ai
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible #ai4all mediante cursos y programas intensivos donde se realizan proyectos para el bien #ai4good.
Hazte miembro premium de Saturdays y podrás aprovechar todos los beneficios de una comunidad líder en Inteligencia Artificial: https://saturdays.ai/become-a-member
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Today, thanks to deep learning algorithms of artificial intelligence, we have the possibility to automate the classification of images, so this tool can help medical personnel in the classification and early detection of breast cancer. In this way, women suffering from this disease could be diagnosed automatically, in time to start treatment.
Breast cancer is the most common type of cancer in women and is also one of the main causes of death according to the WHO (WHO, 2020). Early detection is the single most important factor in lowering cancer treatment costs and mortality. To make it possible it is necessary to have medical ultrasound images and specialists who can explain them. However, the lack of these creates a gap in access to early treatment in countries with little or not enough access to specialized diagnostic services and whose population receives low and middle income.
Description of the problem
Our project consists of the detection and classification of breast cancer in women between 25 and 75 years old. This is possible from the development of an deep learning model trained with images obtained using ultrasound scanners that result in the segmentation of the type of cancer that could be suffered.
Objective
Allow women suffering from breast cancer to be automatically diagnosed using a deep learning model so that they can start treatment early and safely, reducing costs and the mortality rate. To meet this objective, we have proposed a tool that uses artificial intelligence to provide greater agility to the process through self-diagnosis with ultrasound images.
Model selection
The breast cancer detection and classification project works with ultrasound images of three types, labeled as benign, malignant and neutral, so the deep learning model selected for its execution is convolutional networks with TensorFlow Keras.
Datasets
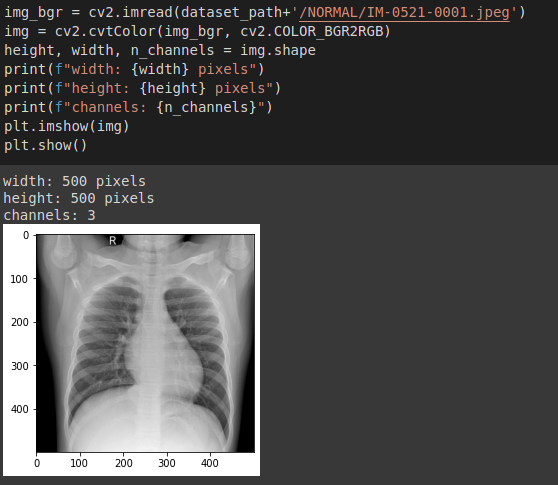
The dataset was collected from Baheya Hospital for Early Detection and Treatment of Women’s Cancer, Cairo, Egypt. It contains 780 breast ultrasound images, in women between 25 and 75 years old (133 normal, 437 benign and 210 malignant) with an average image size of 500 x 500 pixels, some of which are seen below,
Fig. 1. Samples of images
The images from the original dataset contain mask images that do not provide meaningful information to the model we developed, for this reason Shell statements were used to remove them from the dataset we are using.
Implemented techniques
We must emphasize that until now there is a shortage of public data sets of breast cancer ultrasound images and it prevents the good performance of the algorithms. Because of this, the authors who made public the dataset we used, recommend augmenting data using GANs.
Our project developed GAN networks for each class in order to obtain more accurate results and 150 epochs were used.
However, it failed to create usable images, for this reason we declined the use of this technique. The challenge is to develop the GAN with a greater number of epochs and with a better neural network configuration to obtain more realistic images.
Fig. 2. MALIGNANTSource: Compiled by authors using MatplotlibFig. 3. BENIGNSource: Compiled by authors using MatplotlibFig.4. NORMALSource: Compiled by authors using Matplotlib
Network definition
Within the possible design patterns in Keras, subclassing has been implemented to use the low-level APIs of Keras. You can consult more information about this in the following article:
Preprocessing layer: Resizing, Rescaling and Normalization
Conv2D: 32 filters, 4 strides, ‘same’ padding and ReLU activation
MaxPooling2D: pool_size of (3,3), ‘same’ padding and 2 strides
Flatten
Dense: 512 neurons and ReLU activation
Dropout (0.4)
Dense: 3 neurons and SoftMax activation
We are based on AlexNet architecture, on which we made some adjustments like number of neurons, fully connected layers and dropout values.
We use Adam optimizer with learning rate of 0.0001, the Sparse Categorical Crossentropy loss function and Sparse Categorical Accuracy function.
Fig. 5. Model summary — Source: Compiled by authors
Training
TensorBoard was used to observe the real-time behavior of the accuracy and loss values, which provides useful graphs to analyze results and many controls for their manipulation.
Fig. 6. Dashboard TensorBoard — Source: Compiled by authors
Earlystopping
We use EarlyStopping as a form of regularization to avoid overfitting when training the model. For example, if the loss value stops decreasing, the training will stop even though all iterations have not been completed.
Conclusions and future works
WomanLife is intended to be an easy-to-access, low-cost medical diagnostic tool.
This AI is not only beneficial for women who use it but also has the potential to become a medical assistant. We want to clarify that WomanLife does not intend to replace medical specialists but to provide a tool that facilitates their work.
From now on we intend to optimize the model using a GAN network to obtain greater precision and use techniques that find the correct parameters for training the model (Hyperparameter tuning).
Our project also developed an application that, given an image scanned with the camera or selected from the gallery, goes through the developed network and returns a series of probabilities related to the type of cancer suffered.
The model was developed in pure TensorFlow, converted, saved and exported to TensorFlow Lite.
Fig. 7. Sample of the operation of the application prototype — Source: Own elaborationFig. 8. Conversion from TensorFlow to TensorFlow Lite architecture — Source: Own elaboration
Sources
You can access to notebook and mobile application through my GitHub repositories bellow:
Here, you will can find more projects related to Data Science and Machine Learning. In summary, it contains all my work so far. Any reply or comment is always welcome.
About the authors
Erick Calderin Morales
Systems engineer with experience in software development, master’s student in systems engineering and master’s degree in data science with an affinity for artificial intelligence.
Al-Dhabyani, W., Gomaa, M., Khaled, H., & Aly, F. (2019). Deep learning approaches for data augmentation and classification of breast masses using ultrasound images. Int. J. Adv. Comput. Sci. Appl, 10(5), 1–11.
Al-Dhabyani, W., Gomaa, M., Khaled, H., & Fahmy, A. (2020). Dataset of breast ultrasound images. Data in brief, 28, 104863.
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of rogramas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
La COVID-19 es la enfermedad causada por el nuevo coronavirus conocido como SARS-CoV-2. La OMS tuvo noticia por primera vez de la existencia de este nuevo virus el 31 de diciembre de 2019, al ser informada de un grupo de casos de «neumonía vírica» que se habían declarado en Wuhan (República Popular China).
Se llama SARS-CoV-2, por las siglas:
“SARS” porque puede producir un “Síndrome Respiratorio Agudo Grave” (siglas en inglés: Severe Acute Respiratory Syndrome, SARS).
“CoV” porque es un coronavirus.
“2” porque ya existió un virus parecido en 2002–2003 que producía también SARS.
¿QUÉ PRUEBAS SE UTILIZAN PARA DIAGNOSTICAR EL COVID-19?
PCR
Las PCR (siglas en inglés de “Reacción en Cadena de la Polimersa”), son un tipo de pruebas de diagnóstico que se llevan utilizando durante años en diferentes crisis de salud pública relacionadas con enfermedades infecciosas. Estas pruebas se están usando desde los primeros días del estallido de la pandemia de coronavirus en España. Sin embargo, los test rápidos se han incorporado recientemente y, como su nombre indica, son más rápidos y sencillos. Ambos sirven para comprobar si una persona está infectada o no por el Covid-19.
ANTÍGENO
Prueba de antígeno. Esta prueba para la COVID-19 detecta ciertas proteínas en el virus. Se usa un hisopo para tomar una muestra de fluido de la nariz, y las pruebas de antígeno pueden dar resultados en minutos.
RADIOGRAFIA DE TORAX
Los escáneres o las radiografías producen una imagen de los órganos y estructuras (corazón, pulmones y vías respiratorias) del tórax. Pueden detectar bloqueos, inflamación y exceso de líquido.
Las radiografías utilizan una pequeña cantidad de radiación para producir una imagen en dos dimensiones. Por lo general, las realiza un radiólogo en el hospital mediante un equipo fijo, pero también se pueden hacer con una máquina portátil.
La tomografía computarizada (TC) utiliza una computadora para fusionar varias radiografías tomadas desde diferentes ángulos y producir así una imagen bidimensional que se puede convertir en una imagen tridimensional. Requiere de un equipo muy especializado y la realiza en el hospital un radiólogo especialista.
Se pueden realizar en un hospital o en otros centros sanitarios, como la consulta de un médico o una clínica.
PROBLEMATICA
Dado que hay kits de prueba de COVID-19 son de acceso limitado para la población en general, debemos confiar en otras medidas de diagnóstico.
IMÁGENES DE RAYOS X
En el campo de la medicina se utilizan con frecuencia radiografías y tomografías computarizadas para diagnosticar neumonía, inflamación pulmonar, abscesos y / o ganglios linfáticos agrandados. Dado que COVID-19 ataca las células epiteliales que recubren nuestro tracto respiratorio, podemos usar rayos X para analizar la salud de los pulmones de un paciente.
Una gran mayoría de los hospitales tienen máquinas de imágenes de rayos X, se plantea la siguiente pregunta: ¿Cómo se podría detectar COVID-19 en imágenes de rayos X?, sin los kits de prueba dedicados.
OBJETIVOS
Recopilar las entradas del modelo en datasets para el entrenamiento, pruebas y validación.
Desarrollar un modelo de diagnóstico del covid a través de imágenes de rayos X usando deep learning, con un porcentaje de confiabilidad aceptable.
Evaluar los resultados del modelo a través de la matriz de confusión.
DESARROLLO DEL MODELO
Para el desarrollo del modelo se ha utilizado un dataset del repositorio de kaggle que tiene un total de 5.856 imágenes, se ha usado radiografías de pacientes que tenían neumonía porque estos pacientes tienen una alta probabilidad de tener covid-19.
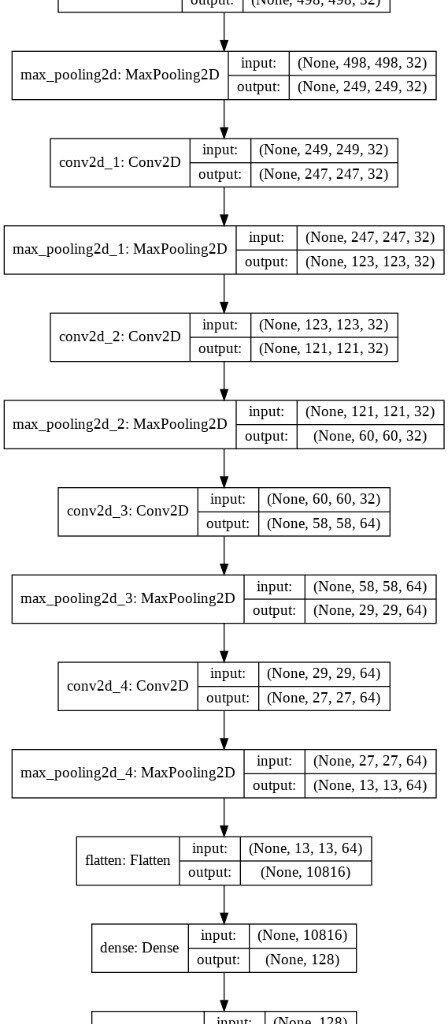
Para la construcción del modelo se utilizó Redes Neuronales Convolucionales, porque son redes neuronales diseñadas y ampliamente usadas para trabajar con imágenes.
Las redes convolucionales contienen varias hidden layers, las cuales se encargan de detectar líneas, curvas y así con las convoluciones se permitirá detectar formas más complejas como siluetas, rostros, etc.
Las herramientas utilizadas son: Tensorflow y keras. Tensorflow es una plataforma de código abierto usada para aprendizaje automático compuesta por un conjunto de herramientas, librerías y recursos que facilitan el trabajo en el desarrollo e implementación de soluciones con inteligencia artificial (IA). Keras es una librería, actualmente es API de alto nivel que proporcionan interfaces que simplifican el trabajo en el desarrollo de aplicaciones con IA, a partir de la versión 2.0 keras ya viene integrada dentro de Tensorflow.
DESARROLLO DEL PROYECTO
Debido a que es una pequeña prueba de concepto de clasificación de imágenes para un curso introductorio a Deep Learning, se ha subido las imágenes del dataset a una carpeta de google drive y el desarrollo del modelo se utilizó los servicios de colab.research de Google.
Las imágenes fueron ajustadas a un tamaño de 500×500, para poder entrenar, en la siguiente imagen se observa una radiografía de un paciente normal.
Con la integración de Keras con Tensorflow, se tienen nuevas clases como “ImageDataGenerator” que facilitan la carga de imágenes:
Las imágenes fueron divididas en 3 grupos: entrenamiento, pruebas y validación.
El modelo de clasificación se puede observar en la siguiente gráfica:
EVALUACION DEL MODELO
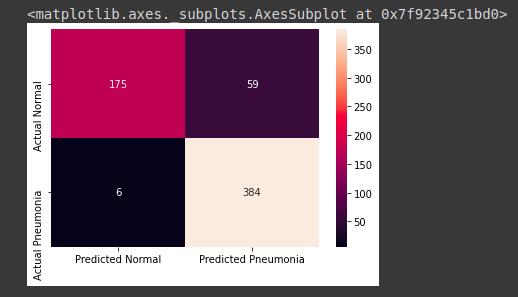
Para realizar la evaluación se ha utilizado la matriz de confusión:
Donde se puede observar que el modelo ha identificado:
Para personas que estaban sanas y que el modelo predijo como personas sanas fueron 175 casos de verdaderos negativos (VN).
Para personas que estaban enfermas y que el modelo predijo como personas enfermas fueron 384 casos de verdaderos positivos (VP).
Para personas que estaban enfermas y que el modelo predijo como personas sanas fueron 59 casos de falsos negativos (FN).
Para personas que estaban sanas y que el modelo predijo como personas enfermas fueron 6 casos de falsos positivos (FP).
Con estos datos podemos calcular los siguientes indicadores:
Exactitud = (VP + VN) / (VP + VN + FN + FP)
Exactitud = (175 + 384) / (175 + 384 + 59 + 6)
Exactitud = 0,8958
La exactitud es la cantidad de predicciones que fueron positivas que fueron correctas y se llegó a un valor de 89,58%
Precisión = VP / (VP + FP)
Precisión = 384 / (384 + 6)
Precisión = 0,9846
La precisión es el porcentaje de casos positivos detectados llegó a un valor de 98,46%
Sensibilidad = VP / (VP + FN)
Sensibilidad = 384 / (384 + 59)
Sensibilidad = 0,8668
La sensibilidad es la proporción de casos positivos correctamente identificados llegó a un valor de 86,68%
Especificidad = VN / (VN + FN)
Especificidad = 175 / (175 + 59)
Especificidad = 0,7478
La especificidad trata de la cantidad de casos negativos correctamente identificados llegó a un valor de 74,78%.
ANALISIS DE RESULTADOS
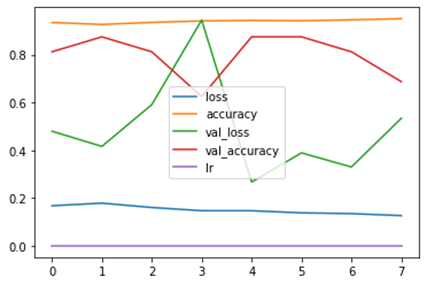
Del proceso de desarrollo del modelo, de acuerdo a las librerías de Keras y Tensorflow pudimos llegar a una precisión del 89,59 %.
Con los resultados obtenidos podemos observar en la figura que el valor de la precisión se mantuvo por encima del 80%, el valor de la pérdida fue inferior al 20 %.
CONCLUSION
De acuerdo a los resultados obtenidos se tiene:
El valor de confiabilidad del modelo es aceptable, representado por el 89%.
El modelo de diagnóstico del covid a través de imágenes de rayos X usando deep learning, podría aplicarse en nuestro medio como otra alternativa de diagnóstico.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) a la vez que se realizan proyectos de impacto social (#ai4good). Si quieres aprender más sobre este proyecto (y otros) únete a nuestra comunidad en o aprende a crear los tuyos en nuestro programa AI Saturdays.
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Utilizamos la Inteligencia Artificial para ayudarnos a realizar el diagnóstico presuntivo de trastornos en niños en edad escolar.
Saturdays.AI es una iniciativa a nivel global, cuyo principio es promover escenarios para la democratización del aprendizaje de la Inteligencia Artificial para todos y de forma ubicua. Democratizar, significa facilitar el acceso a todos los ciudadanos que deseen alcanzar una formación pertinente, relevante y de calidad, en cualquiera de los niveles educativos o profesionales. Por ese motivo, el equipo de investigación y desarrollo, conformado por: {Andrea Mariana Escobar, Danny Aguirre, Luis Chamba Eras, Marco Chiluiza, Paúl Quezada}, decidió participar en la Tercera Edición del Saturdays AI Quito, que de manera inédita, ubicua y flexible, se desarrolló de manera virtual.
En la primera sesión, se desarrolló la lluvia de ideas, con el objetivo de identificar la línea de investigación base, sobre el cual se desarrollaría el proyecto, sobre todo que tenga un impacto social y relacionado con los objetivos-metas de la Agenda 2030.
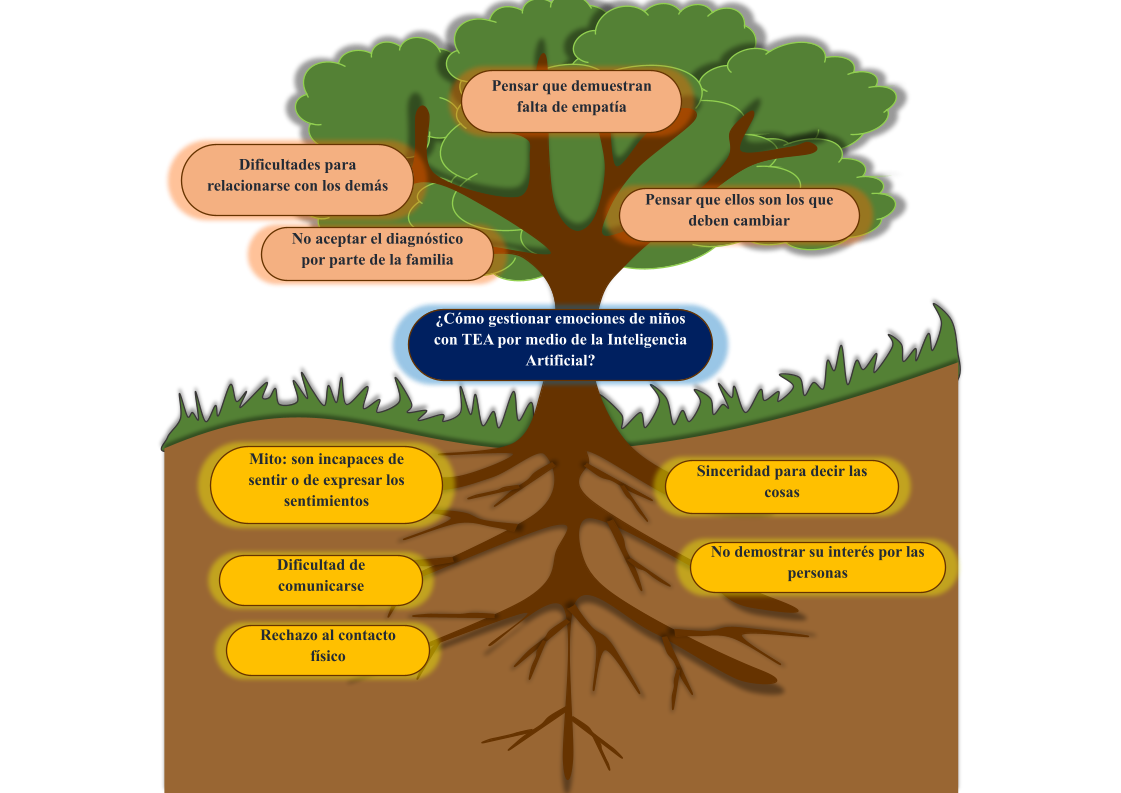
Originalmente se propuso el tema “Chatbot para la gestión de emociones de niños autistas”, obteniendo el primer árbol de problemas (Fig. 1), luego, se puso en marcha la estrategia de búsqueda de literatura que permita definir el alcance a la propuesta, se encontró 27 artículos científicos vinculados a esa línea base (ver Tabla 1).
Figura 1. Árbol de problemas inicial.
La literatura científica permitió conocer y comprender lo que se ha hecho y lo que se puede hacer en temas con el autismo, con ello se concluyó que el tema es muy amplio y con mucho futuro de trabajo para proyectos vinculados a la parte informática con un fin social. Además, se identificó que no existe un conjunto de datos de acceso libre que sirva como punto de partida para el tema planteado.
Otro punto clave, fue hacer búsquedas en grupos afines al tema del autismo, tanto en redes sociales como en la Web, con ello se observó que es un tema muy delicado y complejo, desde el punto de vista de los que conviven con el autismo, o los que no lo hacemos. Posiblemente es un tema que no ha tenido una visibilidad y democratización que permita, definir políticas para apoyar y educar a todos los que nos relacionamos con personas con autismo, sea de manera directa o indirecta. Con esto, se necesitó acudir con los profesionales o especialistas en campo, para despejar muchas dudas surgidas por la exploración preliminar, y con ello ver la viabilidad de la propuesta.
En el camino surgieron nuevas pistas, se encontró un conjunto de datos en Kaggle (https://www.kaggle.com/gpiosenka/autistic-children-data-set-traintestvalidate), relacionado con el autismo, que ha sido utilizado para construir algunos modelos que permiten por medio de la visión por computador predecir por medio de una fotografía si un niño tiene o no autismo. Con ello, cambió la perspectiva del proyecto, de pasar de las emociones (sin un conjunto de datos) al reconocimiento facial (con un conjunto de datos) en el mismo ámbito del autismo.
Para seguir en línea de conocer la opinión profesional sobre la propuesta, se realizó dos entrevistas, la primera con la especialista Amparito Morales, a la cual, se le presentó nuestra nueva idea, de que por medio de la tecnología se podía ayudar a mejorar en los diagnósticos en el área del autismo, inicialmente, se tuvo resistencia en el uso de la tecnología, pero eso fue bueno, porque permitió como equipo, convencer a la profesional de la utilidad real en escenario como en los grandes colegios o escuelas, en dónde el trabajo de los pocos especialistas (Departamento de Consejería Estudiantil (DECE)) puede ser apoyado por una herramienta que apoye en las tareas de automatización, en este caso, reconociendo cuáles de los niños por medio de una fotografía podría tener su atención prioritaria en la detección temprana del autismo.
De la primera entrevista surgió la segunda, con la reconocida investigadora Catalina López, pionera en el Ecuador por su enfoque senso-perceptivo para identificar los perfiles de autismo de acuerdo a la idiosincrasia de un país.
Actualmente, se encuentra terminando una herramienta de tamizaje orientado para niños y adolescentes de 4 a 17 años (características para alerta al diagnóstico clínico), además, durante la entrevista, Catalina López, validó la idea del proyecto, agregándole nuevas ideas vinculadas con las tecnologías, y que han surgido de sus investigaciones, como por ejemplo, realidad virtual para aplicar las herramientas de tamizaje, automatización de la herramienta de tamizaje considerando la protección de datos, privacidad, anonimato, confidencialidad, código de ética bajo principios mundiales, consentimiento informado, entre otros.
Finalmente, la investigadora propuso que un chatbot mediante la interacción sea por voz o texto, permitiría identificar patrones de comportamiento y el tema de emociones. Esta entrevista, fijó el trabajo o líneas futuras que se derivan del proyecto, centrándo el tema de reconocimiento fácil y una herramienta de tamizaje (Fig. 3), como el límite para la propuesta final del proyecto DETECTAA-AI, con la que se trabajó en el Saturdays AI.
Figura 2. Entrevista con Catalina López, Especialista en Perturbaciones de la Comunicación Humana de la Universidad Andina Simón Bolívar.Figura 3. Lluvia de ideas del modelo inicial del proyecto DETECTAA-AI.
Contexto
Los trastornos del desarrollo, técnicamente conocidos como trastornos del neurodesarrollo, son trastornos con base neurológica que pueden afectar la adquisición, retención o aplicación de habilidades específicas o conjuntos de información. Consisten en alteraciones en la atención, la memoria, la percepción, el lenguaje, la resolución de problemas o la interacción social. Estos trastornos pueden ser leves y fácilmente abordables con intervenciones conductuales y educativas o más graves, de modo que los niños afectados requieran un apoyo educativo particular. Entre los trastornos del neurodesarrollo tenemos: trastorno de déficit de atención/hiperactividad, trastornos del espectro autista, dificultades del aprendizaje, como la dislexia y las deficiencias en otras áreas académicas, discapacidad intelectual, síndrome de Rett.
“El autismo es un trastorno neurológico complejo que generalmente dura toda la vida. Es parte de un grupo de trastornos conocidos como trastornos del espectro autista (TEA). Actualmente se diagnostica con autismo a 1 de cada 68 individuos y a 1 de cada 42 niños varones, haciéndolo más común que los casos de cáncer, diabetes y SIDA pediátricos combinados. Se presenta en cualquier grupo racial, étnico y social, y es cuatro veces más frecuente en los niños que en las niñas. El autismo daña la capacidad de una persona para comunicarse y relacionarse con otros. También, está asociado con rutinas y comportamientos repetitivos, tales como arreglar objetos obsesivamente o seguir rutinas muy específicas. Los síntomas pueden oscilar desde leves hasta muy severos” [1].
El autismo en Ecuador
De acuerdo a la especialista Catalina López, se tiene los siguientes avances:
El personal que labora en los departamentos de consejería estudiantil de las unidades educativas (DECE) debe realizar evaluaciones para determinar los alumnos que pudiesen presentar problemas de comportamiento. Debido a la gran cantidad de estudiantes asignados a cada profesional de estos departamentos, el proceso de evaluación consume la mayor cantidad de tiempo disponible por este personal, dejando muy pocos recursos para profundizar el diagnóstico y apoyo a los niños que realmente presentan trastornos del desarrollo. En la Fig. 4 se observa el árbol de problemas, que se lo obtuvo, previa lluvia de ideas, lectura de la literatura y luego de las entrevistas.
Figura 4. Árbol de problemas relacionados con el proyecto DETECTAA-AI.
¿Cómo lo pensamos resolver?
Se desarrollará una aplicación Web formada por dos componentes (Fig. 3).
El primer componente ayudará a predecir qué estudiantes pueden o no tener el TEA basado en una imagen fotográfica (tipo tamaño carné) por medio de visión por computador. Los rasgos que se determinen dependen de las bases de datos disponibles. En una primera fase se utilizará la base de datos disponible en Kaggle (https://www.kaggle.com/gpiosenka/autistic-children-data-set-traintestvalidate) para detección facial de TEA, considerando definir un proceso de entrenamiento del sistema que permita detectar nuevos factores de comportamiento a medida que se disponga de bases de imágenes adicionales.
Técnicamente, el tamizaje corresponde a la aplicación de un test o procedimiento a personas “asintomáticas”, con el objetivo de separarlos en dos grupos; aquellos que tienen una condición que podría beneficiarse de una intervención temprana; y aquellos que no.
El segundo componente realizará un tamizaje, usando el test MCHAT, y que sea la base para en el futuro implementar el procesamiento de lenguaje natural (chatbot de preguntas y respuestas).
¿Cómo se vincula el proyecto con los objetivos de desarrollo sustentables?
Se vincula con dos objetivos:
Primero, con el de Salud y bienestar (ODS 3), meta: reforzar la capacidad de todos los países, en particular los países en desarrollo, en materia de alerta temprana, reducción de riesgos y gestión de los riesgos para la salud nacional y mundial.
Segundo, con la Reducción de las desigualdades (ODS 10), meta: el avance en la reducción de la desigualdad, tanto dentro de los países como entre ellos, ha sido desigual. Todavía se debe dar más peso a la opinión de los países en desarrollo en los foros decisorios de las instituciones económicas y financieras internacionales. Además, si bien las remesas pueden ser un medio de supervivencia para las familias y las comunidades de los trabajadores migrantes internacionales en sus países de origen, el elevado costo de transferir dinero sigue reduciendo los beneficios.
¿Cuál es la hipótesis del proyecto?
El uso de la Inteligencia Artificial permitirá crear un prototipo que permita apoyar al diagnóstico presuntivo de trastornos del desarrollo en niños de edad escolar.
¿Cuál es la población objetivo?
Niños de 0 a 12 años
Padres, madres, cuidadores
Educadores
Especialistas de los DECE
Investigadores
¿Qué nos dice la literatura científica sobre proyectos relacionados con el reconocimiento facial?
La literatura científica que soporta nuestro proyecto se resume en la Tabla 2.
¿Qué es la visión por computador?
Es un campo de la Inteligencia Artificial enfocado a que las computadoras puedan extraer información a partir de imágenes, ofreciendo soluciones a problemas del mundo real (Fig. 5).
Figura 5. El reconocimiento facial puede ayudar a mejorar los diagnósticos, foto derecha, niño sin TEA, niño de la izquierda niño con TEA.
¿Qué áreas del conocimiento se vinculan?
Ciencias de la Salud (Salud Mental).
Ciencias de la Computación (Inteligencia Artificial, Visión por Computador).
Metodología
La metodología que se utilizó fue Desing Thinking, en la Fig. 6 se observa un resumen de cada una de las etapas desarrolladas.
Figura 6. Descripción de cada una de las etapas de la metodología de acuerdo con el proyecto DETECTAA-AI.
En la Fig. 7, se tiene un lienzo de trabajo proporcionado por https://www.analogolab.co/, para poner en marcha los principios de la metodología Desing Thinking. En este enlace Web, se observa el diseño completo del proyecto.
Figura 7. Idea general del proyecto, Mapeo de actores vinculados con el proyecto, definir los clientes o interesados en el proyecto, futuros beneficiarios, Declaración de la idea, Factores positivos, oportunidades, problemas y soluciones.
Resultados
Arquitectura
La arquitectura del proyecto está dividida en una aplicación de Frontend y una aplicación de Backend (ver Fig. 8). El Frontend, desarrollado con Flask (Framework de Python), contiene todas las interfaces con las cuales el usuario final interactúa. Esta, a su vez, se conecta mediante un endpoint al Backend. En el Backend se encuentra una API, desarrollada con Flask, que contiene un modelo de Deep Learning entrenado con librerías de TensorFlow y un conjunto de imágenes obtenidas desde Kaggle. El Frontend también interactúa con un modelo entrenado en Teachable Machine (una plataforma de Google para entrenar modelos de machine learning de forma rápida y fácil).
Figura 8. Arquitectura propuesta para DETECTAA-AI.
Enlaces Web a las API y a la aplicación de DETECTAA-AI:
Los resultados obtenidos para el primer caso (niño con TEA) son bastante favorables, ya que tanto los modelos como el cuestionario dan un porcentaje alto de detección de TEA en la persona evaluada, tal como se muestra en la Fig. 9.
Figura 9. Flujo de trabajo, caso 1.
Los resultados del segundo caso (niña sin TEA), presentan porcentajes aceptables en el diagnóstico de TEA. Tal como muestra la Fig. 10, los resultados obtenidos fueron: Teachable Machine: 100%, TensorFlow: 85.28% y M-Chat: Riesgo Bajo.
Figura 10. Flujo de trabajo, caso 2.
En el tercer caso (niño sin TEA) los resultados obtenidos de los modelos y M-chat reflejan resultados diferentes, ya que los modelos de machine learning devuelven diagnósticos acertados en cuanto a la prueba realizada, sin embargo, el M-chat retorna un Riesgo alto de tener un diagnóstico de TEA, como se muestra en la Fig. 11.
Figura 11. Flujo de trabajo, caso 3.
Conclusiones
Con el desarrollo del proyecto DETECTAA-AI se llegó a las siguientes conclusiones:
Es posible detectar indicios de TEA en las personas mediante el uso de modelos de inteligencia artificial.
Para que un modelo tenga una tasa de confiabilidad más alta, es necesario una mayor cantidad de imágenes de entrenamiento y mejor procesamiento de esa información.
Los algoritmos de inteligencia artificial sirven como un apoyo a los profesionales de la salud, más no como un reemplazo.
Es necesario un vínculo entre la academia, estado, empresas, gremios, sociedades, para que estas iniciativas se puedan poner en marcha de acuerdo al contexto Ecuatoriano.
Combinar la investigación científica a procesos profesionales, permite construir prototipos escalables en el tiempo.
El prototipo DETECTAA-AI, debe usarse con fines académicos y de investigación, como ejemplo de prueba de concepto, y no para ofrecerla como herramienta de diagnóstico final, ya que se necesita un equipo de profesionales que aporten en la detección del TEA.
Líneas futuras
Implementar la herramienta de tamizaje con NLP, de tipo de preguntas y respuestas, utilizando el cuestionario propuesto por la Dra. Catalina López en el contexto Ecuatoriano, considerando la privacidad, protección de datos, entre otros.
Obtener una base de datos propia de imágenes en el contexto de Ecuador, para realizar pruebas al prototipo DETECTAA-AI.
Es recomendable aumentar una tercera herramienta de detección de TEA por NLP, el cual permita detectar presencia de tea mediante el análisis de patrones en la voz de la persona que se requiera diagnosticar.
Concientizar a la población que la tecnología puede ser un apoyo muy importante en el contexto de la Salud.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.