En este artículo mostraremos como llevar a cabo la detección de fraude por tarjeta de crédito con algoritmos de Machine Learning.
El fraude cibernético hace referencia a aquellas estafas que utilizan la red, para realizar transacciones ilícitas (Condusef, s.f). Dentro de este tipo de fraudes, el fraude con tarjetas de crédito está a la orden del día por la popularidad de las compras en línea. Bastan algunos datos de los usuarios para que un pirata informático pueda cometer el ilícito. El fraude con tarjeta de crédito, implica el uso no autorizado de la información de la tarjeta de crédito de una persona con el propósito de cargar compras en la cuenta de la víctima o extraer fondos de su cuenta (Cornell Law School, s.f). En otras palabras, es un tipo de robo de identidad.
En este escenario, la detección de fraude con Machine Learning para transacciones con tarjeta de crédito es de suma importancia. Actualmente se pierden grandes cantidades de dinero por este tipo de fraude, lo que representa un gran problema para las entidades financieras y para sus usuarios.
Frente a este tipo de situaciones, las empresas suelen reemplazar tarjetas, emprender investigaciones sobre los casos y ofrecer soporte telefónico a los clientes, lo que implica un gasto importante. Incluso con estas atenciones, se puede originar una mala reputación e imagen de la empresa, lo que eventualmente se refleja en una pérdida de clientes y de ingresos.
¿Cómo evitar o minimizar los costos por transacciones fraudulentas?
La inteligencia artificial provee de algoritmos de aprendizaje automático capaces de identificar patrones en las transacciones y detectar si determinada transacción es fraudulenta o no.
Descripción del proyecto
El objetivo general del proyecto es desarrollar un método de detección de fraude utilizando algoritmos de Machine Learning capaz de clasificar efectivamente entre transacciones legítimas y fraudulentas.
Obtención de datos
Por razones de confidencialidad, las transacciones con tarjetas de crédito (reales) no se pueden compartir públicamente. Debido a la escasez de datos, se creará un simulador de datos de transacciones legítimas y fraudulentas.
Las características esenciales que resumen una transacción son: ID de transacción, fecha y hora de transacción, ID del cliente, ID del terminal, monto de la transacción y una etiqueta que muestra si la transacción es fraudulenta o no.
La simulación consta de cinco pasos:
1. Generación de perfiles de clientes: cada cliente es diferente en sus hábitos de gasto. Esto se simulará definiendo algunas propiedades para el cliente como su ubicación geográfica, su frecuencia de gasto y sus montos de gasto.
2. Generación de perfiles de terminal: aquí, la única propiedad que se tomará en cuenta es la ubicación geográfica.
3. Asociación de perfiles de clientes y terminales: se asume que los clientes solo realizan transacciones en terminales que se encuentran dentro de un radio r, de sus ubicaciones geográficas.
4. Generación de transacciones: el simulador recorrerá el conjunto de perfiles de clientes y generará transacciones según sus propiedades.
5. Generación de escenarios de fraude: se etiquetan las transacciones como legítimas o fraudulentas, utilizando los siguientes escenarios de fraude.
a. Escenario 1: cualquier transacción cuyo monto sea superior a 220 se etiqueta como fraudulenta. (Escenario no inspirado en la realidad, se elige el valor según la distribución que sigue la variable montos).
b. Escenario 2: todos los días se extrae al azar dos terminales. Todas las transacciones en estos terminales en los próximos 28 días serán etiquetadas como fraudulentas. (Phishing).
c. Escenario 3: todos los días se extrae al azar 3 clientes. En los próximos 14 días, 1/3 de sus transacciones tienen sus montos multiplicados por 5 y son etiquetadas como fraudulentas. (Fraude sin tarjeta presente).
Así, se tiene el siguiente conjunto de datos:
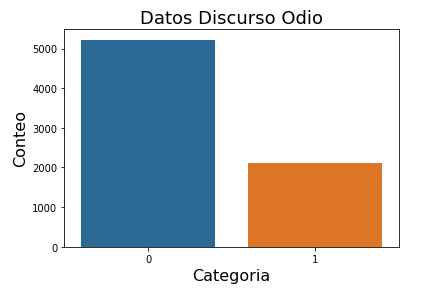
Este simulador generó 1 078 699 transacciones, de las cuales 8 590 (0.796 %) son fraudulentas. Se generan aproximadamente 12 000 transacciones por día, alrededor de 103 transacciones fraudulentas por día y cerca de 88 tarjetas fraudulentas por día.
El dataset presenta un desequilibrio, menos del 1% de transacciones son fraudulentas.
Los montos de transacción tienen una media de 53.69, con una desviación estándar de 42.13 y un monto máximo de 1 248.85.
La primera transacción se realizó el 01–05–2021 a las 00:01:02 horas y la última transacción se registró el 29–07–2021 a las 23:59:43 horas.
Preparación de datos
Para la detección de fraude los algoritmos de Machine Learning generalmente requieren características numéricas y ordenadas, es decir, el tipo de variable debe ser un número entero o real donde el orden de los valores es significativo.
En este dataset, las únicas características numéricas y ordenadas son el monto de transacción y la etiqueta de fraude. La fecha y hora es una marca de tiempo, por lo tanto, no es numérica. Los ID para las transacciones, los clientes y los terminales son numéricos, pero no ordenados. Entonces, se deben diseñar nuevas características a partir de las características mencionadas anteriormente.
La primera transformación consiste en generar dos nuevas características binarias, a partir de la fecha y hora, que caractericen períodos potencialmente relevantes.
1. Si una transacción ocurre durante un día laborable (0) o fin de semana (1).
2. Si una transacción ocurre durante el día o la noche. (La noche comprendida entre las 0 p.m. y las 6 a.m.)
La segunda transformación tiene que ver con el ID del cliente, se calcula dos características en 3 frecuencias. La primera característica es el número de transacciones que ocurren dentro de una frecuencia. La segunda característica es el monto promedio gastado en estas transacciones, en cada frecuencia. La frecuencia se establece en 1, 7 y 30 días. Esto genera 6 nuevas características.
Finalmente, la última transformación se realiza con el ID de terminal. El objetivo es extraer el número de transacciones en el terminal en cada frecuencia y una puntuación de riesgo, que evalúe la exposición de un terminal a transacciones fraudulentas. (El puntaje de riesgo se define como el número promedio de transacciones fraudulentas en un terminal durante un período de tiempo).
Entrenamiento del modelo
Una vez que se tiene el dataset listo, se particiona el dataset en datos de entrenamiento (60 %) para el desarrollo y datos de prueba (40 %) para validación del modelo.
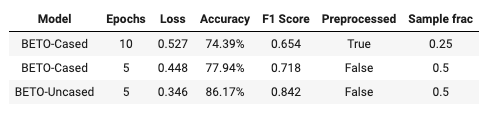
Ya que se está trabajando con un problema de clasificación binaria, se utilizan los siguientes algoritmos: Naive Bayes, Regresión Logísitca, KNN, Decision Tree, Random Forest, XGBoost y AdaBoost.
Evaluación y validación del modelo
Después de entrenar los algoritmos, se evalúan los resultados con distintas métricas y se obtiene la siguiente información:
La métrica que mejor evalúa el rendimiento de los algoritmos, sin causar overfitting, es la ROC AUC Score. Esta métrica indica que el mejor modelo para la predicción de fraudes con tarjeta de crédito es el Decision Tree con una precisión del 83%.
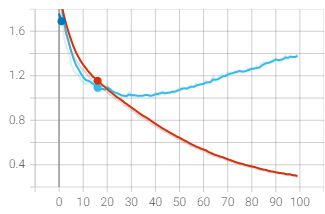
Otra forma de verificar esto es utilizar la curva AUC-ROC, que indica cuánto es capaz el modelo de distinguir entre clases. ROC es una curva de probabilidad y AUC representa el grado o medida de separabilidad. El siguiente gráfico indica las curvas AUC-ROC para todos los algoritmos:
El área bajo la curva ROC es el mejor indicador global de la precisión de una prueba, para el Decision Tree el AUC score es de 0.836.
Los resultados del modelo se pueden expresar mediante una matriz de confusión:
Se puede observar que el modelo ha identificado:
- 426 669 casos de verdaderos negativos, para transacciones NO fraudulentas y que el modelo predijo como NO fraudulentas.
- 2 394 casos de verdaderos positivos, para transacciones fraudulentas y que el modelo predijo como fraudulentas.
- 1 099 casos de falsos negativos, para transacciones fraudulentas y que el modelo predijo como NO fraudulentas.
- 1 318 casos de falsos positivos, para transacciones NO fraudulentas y que el modelo predijo como fraudulentas.
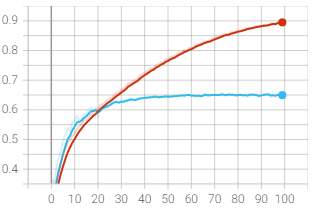
Una curva de aprendizaje muestra la relación entre el puntaje de entrenamiento y el puntaje de prueba con validación cruzada para un estimador con un número variable de muestras de entrenamiento.
Esta curva muestra una alta variabilidad de la prueba (1.00) y una puntuación AUC ROC que converge en alrededor de 0.83.
Conclusiones
- El mejor modelo de Machine Learning para la detección de fraude es el Decision Tree Classifier con una precisión del 83%.
- Por la cantidad de datos de las transacciones, en la fase de entrenamiento es fundamental contar con poder computacional para experimentar con diferentes algoritmos y evaluar sus resultados en un tiempo razonable.
- El método de detección de fraude por tarjeta de crédito desarrollado puede aplicarse de manera efectiva en instituciones financieras, sin embargo, es importante considerar otros escenarios de fraude para optimizar el modelo y no comprometer el poder de predicción.
Referencias
Barrios, J. (2019). La matriz de confusión y sus métricas. Recuperado de: https://bit.ly/3C3ibLE
Condusef (s.f). Tipos de fraude. Recuperado de: https://bit.ly/3kbcmpz
Cornell Law School (s.f). Fraude con Tarjeta de Crédito. Recuperado de: https://bit.ly/3lgOCQ2
Gebejes, A. & Khokhlova, A. (2021). Learning Curve Theory. Data of Learning. VALAMIS. Recuperado de: https://bit.ly/3lhipbp
Le Borgne, Y. & Bontempi, G. (2021). Machine Learning for Credit Card Fraud Detection — Practical Handbook. Université Libre de Bruxelles. Recuperado de: https://bit.ly/3k7tbBH
McKinney, T. (s.f). Fraud Detection in Python. Recuperado de: https://bit.ly/3lb40xiSaturdays.AI
WRITTEN BY
Martin Mercado

Más Inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!