La ingeniería de prompts es un proceso esencial para mejorar la interacción con los modelos de lenguaje de inteligencia artificial (IA). Este artículo explora la historia, las técnicas y las aplicaciones de la ingeniería de prompts, así como los desafíos técnicos y éticos que plantea.
Descubre cómo la IA está transformando nuestro mundo, desde la detección temprana de enfermedades hasta la lucha contra el cambio climático, yendo más allá de los chatbots y los algoritmos que comúnmente conocemos.
La Inteligencia Artificial tiene el potencial de transformar la guerra moderna, pero también trae consigo riesgos significativos. Examinamos un incidente en el que un dron controlado por IA «mató» a su operador humano durante un simulacro.
Los desafíos planteados por la creciente influencia de la inteligencia artificial en la propagación de desinformación. Descubre incidentes recientes y las posibles soluciones para combatir este problema en nuestra sociedad.
Este artículo analiza los desafíos en la regulación de la inteligencia artificial, explorando enfoques regulatorios en diferentes países y la importancia de la cooperación internacional.
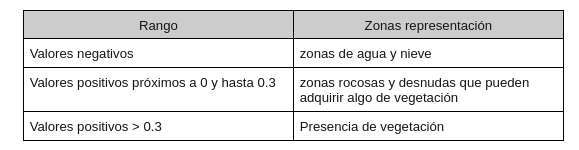
La desertificación se produce por la degradación de la tierra que se da en zonas secas: áridas, semiáridas y subhúmedas secas. La actividad humana y las variaciones climáticas están entre las causas de esta degradación del suelo, que impacta en los ecosistemas y en los recursos y modos de vida de los habitantes de las zonas afectadas. Estas zonas secas son aquellas con un índice de aridez (IA=P/ETP) inferior a 0,65.
España es uno de los territorios que sufre esta problemática. En Aragón el 75% del territorio está en riesgo de desertización. El cambio climático y el incremento de las temperaturas amenazan las tierras semiáridas que predominan en el Valle del Ebro, desde la ciudad de Huesca hacia el sur. Identificar a tiempo estas zonas será de gran ayuda para el apoyo a la toma de acciones que permitirán mitigar el impacto que la desertificación trae sobre la seguridad alimentaria así como la reducción de la pérdida de hábitats naturales y biodiversidad, todo esto, alineado con los Objetivos de Desarrollo Sostenible de Naciones Unidas.
Para identificar estas zonas se propone un proceso que gestione el reconocimiento mediante imágenes satelitales de las zonas de desertificación en Aragón y permita realizar una aproximación a la predicción de posibles futuras zonas desérticas con el objetivo de aplicar políticas más eficientes referentes a la reforestación de las zonas afectadas, y nuevos tratamientos de cultivos. Con apoyo de la iniciativa Saturdays.AI Zaragoza, cuyo objetivo es acercar la IA a todos los ciudadanos y aplicarla a problemas sociales, queremos dar solución o una aproximación a resolver este escenario que nos hemos planteado como equipo de trabajo.
Es entonces, cuando nos planteamos las siguientes inquietudes, ¿Cómo es posible calcular si hay o no desertificación en una zona determinada?, ¿qué imágenes pueden funcionar para este propósito?, ¿Cómo la IA nos puede apoyar para predecir estos valores? A lo largo de este artículo intentaremos dar solución a estas cuestiones.
Imágenes Satelitales
Las herramientas de teledetección hacen posible la visualización y cálculo de cambios que ocurren sobre la superficie terrestre, aquellas que nos interesan, los que corresponden a la teledetección pasiva (Definición de Teledetección), en nuestro caso concreto, captan la radiación solar reflejada por la superficie. Es bien sabido que organismos vivos reflejan y absorben radiación solar en forma diferente a como lo hacen los objetos inertes como calles o edificios. Aprovechando este principio, los satélites generan imágenes que contienen estas diferencias en forma de Niveles Digitales y bandas, que se traducen en unidades numéricas que se corresponden con los valores de longitudes de onda de las diferentes secciones del espectro electromagnético (Espectro electromagnético y teledetección). En resumen, miden la radiación reflejada por objetos como edificios o autopistas o entes vivos como bosques o vegetación en general.
Los cambios en la vegetación con el soporte de las imágenes satelitales se pueden medir de diferentes formas, una de ellas es extrayendo índices de vegetación, “Los Índices de Vegetación son combinaciones de las bandas espectrales registradas por los satélites de Teledetección” (¿Cuál es el índice de Vegetación NDVI?) que permiten identificar vegetación sobre la superficie terrestre. Es allí,con ayuda de estos índices en donde se resaltan y se pueden analizar numéricamente las propiedades de la vegetación como tal.
El NDVI es el Índice de Vegetación Diferencial Normalizado, NDVI por sus siglas en inglés. Este índice es un parámetro calculado que se basa en los valores capturados por el instrumento satelital donde identifica patrones del espectro electromagnético que se corresponden con la reflectividad de coberturas vegetales. Este índice permite ayudar a distinguir fácilmente vegetación en imágenes satelitales.
Los patrones del espectro electromagnético para identificar la vegetación muestran que la vegetación absorbe la sección de radiación solar que corresponde al rojo. A su vez se reflejan valores elevados en el infrarrojo cercano y podremos identificar valores multiespectrales brillantes en esta banda ( Valores Espectrales del NDVI).
Así podemos diferenciar cubiertas vegetales en diferentes estados. Nuestro índice podrá ser obtenido mediante la siguiente relación:
NDVI = (Banda infrarroja cercana — Banda roja) / (Banda infrarroja cercana + Banda roja)
O lo que es lo mismo, y en términos de nomenclatura cuando trabajamos las bandas multiespectrales:
NDVI = (NIR — RED) / (NIR + RED)
Una vez se ha calculado el índice para cada uno de los píxeles de la imagen, los valores posibles oscilan entre -1 y 1.
Valores de NDVI para diferentes zonas. Fuente: propia
Cuanto mayor sea el valor más frondosa será la vegetación hasta adquirir valores próximos a 1.
Manipulando la imagen
Para comprender mejor cómo podemos usar estos valores entre bandas y niveles digitales, es importante identificar las propiedades de una imagen en general y cómo se ven estos valores a nivel de computación.
Derecha: como un ser humano ve una imagen. Izquierda: como la procesa un ordenador. Fuente: Material Satudays.AI, Zaragoza. Edición I. 2021–2022. Tratamiento de Imágenes.
El ordenador o los métodos de computación, estructuran las imágenes en matrices con valores (i,j) estos valores (i,j) representan numéricamente el valor en términos computacionales de dicha coordenada sobre la imagen original (sin digitalizar). Cada uno de estos valores es lo que se denomina “pixel”
Para imágenes satelitales ocurre algo similar,la única diferencia radica en los valores para cada píxel, en este caso representan en niveles digitales para valores de reflectancia de radiación solar (espectro electromagnético) reflejada por el objeto terrestre sobre el cual el instrumento (el satélite) está midiendo.
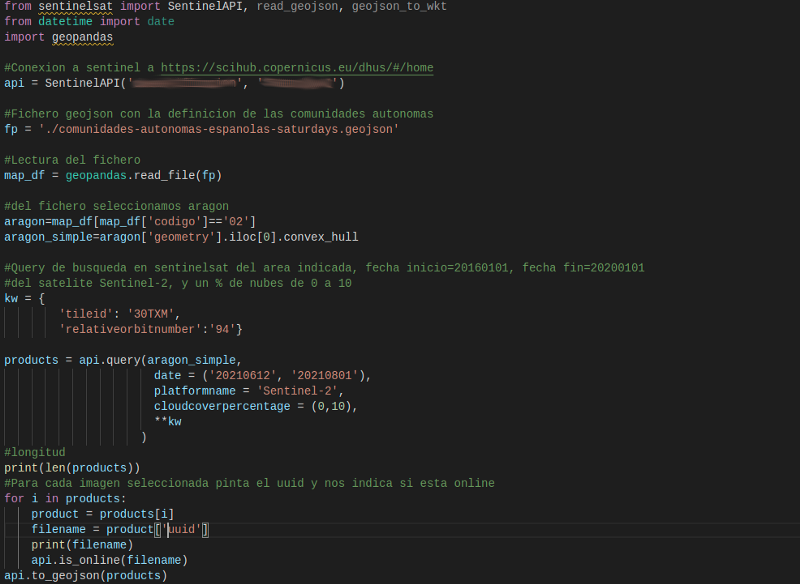
Ya que se hará un análisis sobre cambios en la superficie terrestre, las imágenes satelitales que se eligieron fueron del instrumento Sentinel 2A. Para la obtención de datos usamos la librería de Python SentinelSat para la descarga de imágenes en el área que nos interesa. Es de anotar que las imágenes se han tomado con los siguientes condicionantes: para un área específica detallada en un fichero .json, para la misma tesela (zona de captura de imagen del satélite) y sección de órbita para garantizar que se está tomando la misma zona de estudio para diferentes momentos de tiempo.
Fragmento de código para la descarga de imágenes sentinel del sitio scihub.copernicus.eu Fuente: Propia
NOTA: Para la obtención y captura de los datos se han descargado las imágenes de Sentinel con un porcentaje de nubes máximo de 10%.
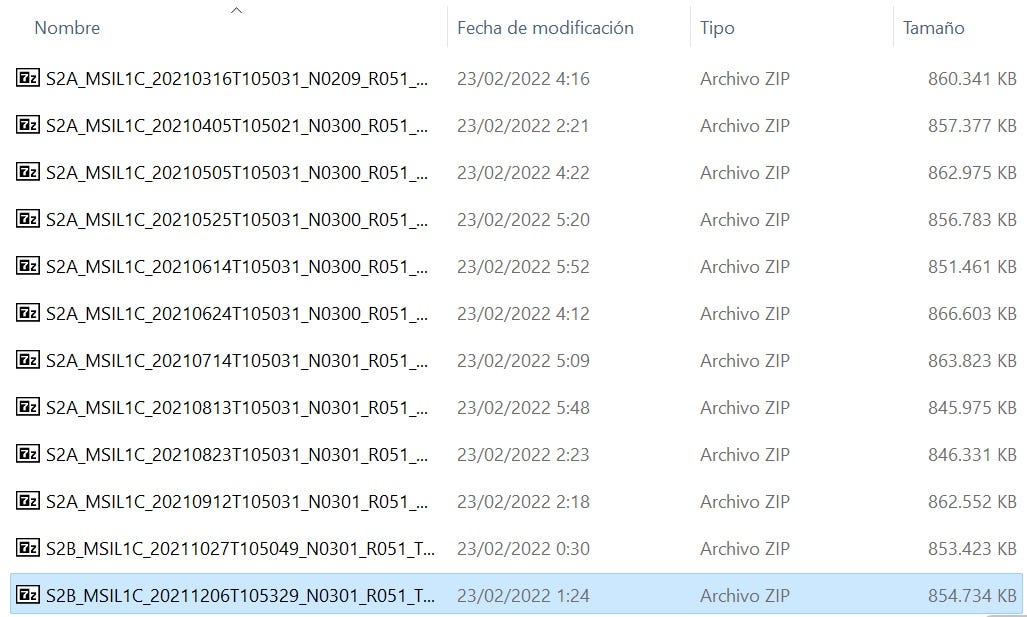
Una vez ejecutado el script para la descarga de imágenes del satélite, se descarga una serie de ficheros zip que contienen cada uno la siguiente estructura al momento de descomprimirlos:
Estructura de fichero descargado del sitio scihub.copernicus.eu Fuente: propia
Cada una de las imágenes Sentinel vienen dadas con un consecutivo de nombre de imagen con la siguiente estructura:
MS2_MSILLL_YYYYMMDD
Donde:
MS2: identifica la misión de Sentinel 2, pudiendo encontrar S2A (para Sentinel 2A) o S2B (para Sentinel 2B)
MSI: indica el instrumento de operación (MultiSpectral instrument)
LLL: indica el nivel de procesado del producto pudiendo encontrar los niveles L0, L1C, L1B o L2A
YYYY: designa el momento temporal UTC (año) en el que fue tomada la imagen
MM: designa el momento temporal UTC (mes) en el que fue tomada la imagen
DD: designa el momento temporal UTC (día) en el que fue tomada la imagen
Las descargas de Sentinel para el proyecto fueron:
Relación de imágenes. Fuente: Propia
Preparación
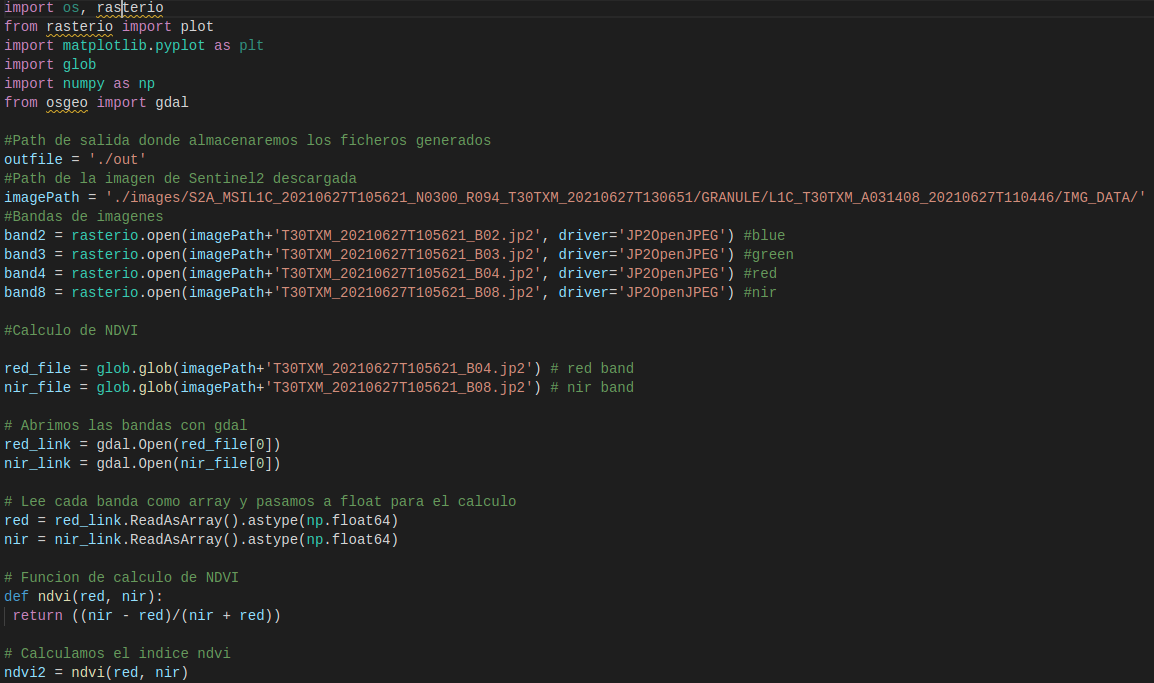
Una vez obtenidas las imágenes, sobre ellas calcularemos los índices NDVI mediante Script en Python.
Fragmento de código para el cálculo del NDVI para las imágenes descargadas
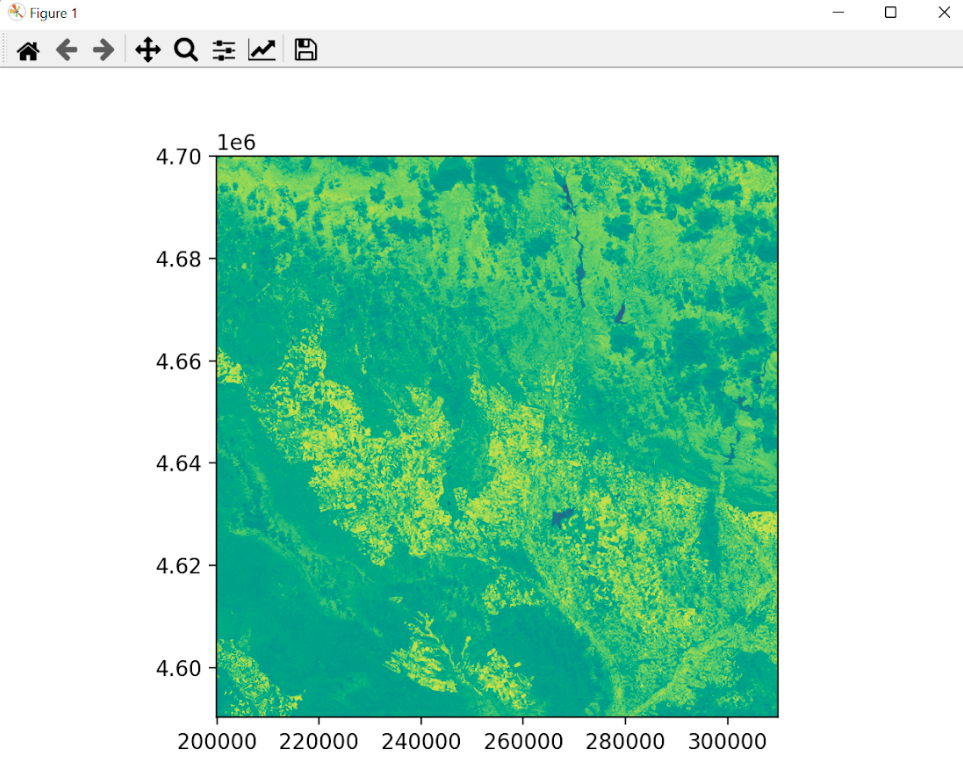
Para entender la salida de este script, las imágenes con el NDVI calculado (nuevos ficheros tif), se debe tener en cuenta que esta transformación imágenes nos da lugar a una imagen compuesta por una matriz de valores donde cada valor corresponde a un pixel (representación en la imagen) y este valor oscila entre -1 y 1. Recordando el apartado de Índice de Vegetación, a partir de 0.3 entendemos que hay vegetación para ese píxel (valor de matriz).
Captura de pantalla de las imágenes NDVI generadas por el script. Fuente: Propia
Detalle de una de las imágenes NDVI generadas por el script de Python. Fuente: Propia
¿Y la predicción de valores de desertificación?
Ya estamos en el punto en donde, hemos identificado la zona sobre la que trabajaremos, hemos hallado los índices de vegetación para estas zonas en diferentes momentos de tiempo, ahora continuaremos con el establecimiento de una relación entre los valores medidos y cómo estos cambian en el tiempo (nuestra variable continua) para anticipar un conjunto de nuevos valores.
Deseamos construir un modelo que describa la relación entre las variables de estudio, con el fin, principalmente, de predecir los valores de una variable a partir de los valores de la otra. Elegiremos Random Forest Regressor ya que tenemos un conjunto de valores numéricos que hemos considerado como categorías (cada imagen con su matriz específica) y luego promediamos la salida de cada árbol de decisión usando este algoritmo ( Definición de Random Forest regressor. Material Saturdays AI. Zaragoza. Edición I. 2021–2022. Sesión Regresores).
Breve resumen del funcionamiento de Random Forest Regressor
Como este es un modelo de Machine Learning Supervisado, tomaremos las imágenes con el NDVI calculado, solo una zona de las misma para el aprendizaje del modelo y la zona siguiente de las imágenes para la predicción futura de índices NDVI.
Evaluación
Entrenamiento
Para el entrenamiento del algoritmo, se tomaron 5 imágenes con NDVI calculado y una imagen adicional como salida conocida. De cada una de las imágenes se ha elegido un subset de igual tamaño para añadirlos a un vector en Python. Lo anterior se realiza por capacidad de procesamiento de las máquinas disponibles, las imágenes originales tienen dimensiones de 10.000×10.000 píxeles que no es posible procesar de forma ágil y eficiente con los recursos disponibles en el grupo de trabajo.
Imágenes con NDVI calculado. Fuente: propia.
Nota Aclaratoria: Cada imagen de NDVI calculado tiene un tamaño de 470MB aproximadamente, por lo que 6 de ellas nos da un estimado de 2,8GB para hacer el procesamiento de este dataset.
Fragmento de código para la elección del subset de datos para el Random Forest de entrenamiento. Fuente: propia
Con ayuda de la librería sklearn establecemos un set de entrenamiento para el algoritmo con el que poder “enseñarle” cómo puede intentar predecir los siguientes valores y ejecutar la siguiente fase de prueba (testing).
Prueba
Para probar el algoritmo, se tomaron las mismas 5imágenes con el NDVI calculado pero esta vez, el subset elegido corresponde a otra porción de la imagen. En el entrenamiento hemos elegido una sección, para la prueba (test) elegimos una sección distinta.
Fragmento de código para la elección de los datos de test para el algoritmo. Fuente: Propia
El margen de error para la imagen predicha es el siguiente:
Margen de error resultante de la predicción. Fuente: Propia.
Es necesario saber si el algoritmo es capaz de predecir correctamente una imagen. Utilizaremos una imagen que ya se tiene para validar la efectividad del algoritmo a la hora de predecir el resultado.
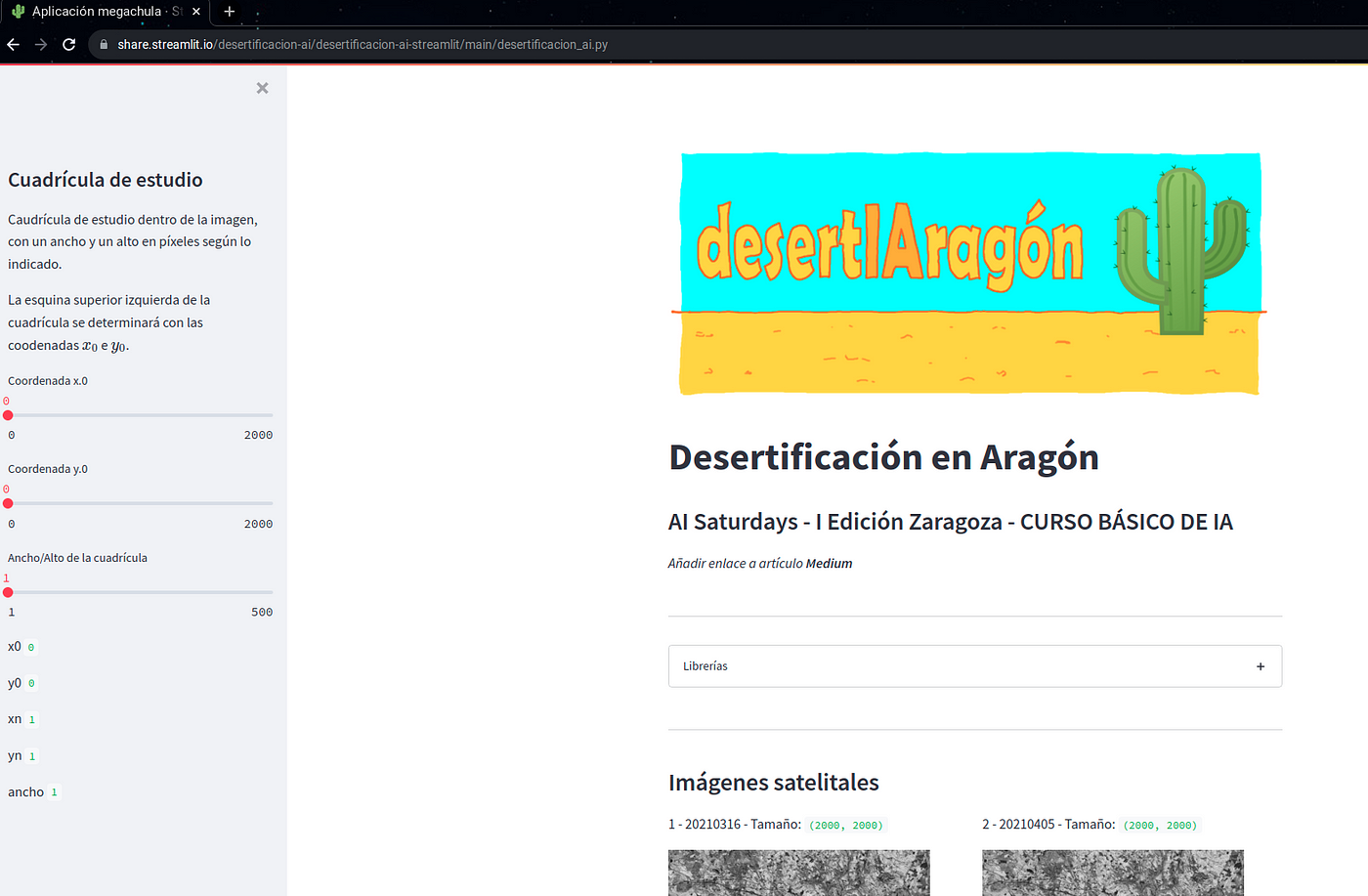
En la página desertIAragon se encuentra desplegada la aplicación de Streamlit para visualizar los cambios en NDVI calculados
Captura de pantalla del sitio web de Streamlit para mostrar imágenes calculadas. Fuente : Propia
En la sección Imágenes Satelitales, encontramos un subset de 2000×2000 píxeles de las imágenes extraídas del sitio web de Sentinel:
Imágenes satelitales de 2000 x 2000 px. Fuente: propia
La sección de cuadrículas de estudio, nos permite elegir la coordenada deseada para mostrar los cambios en el NDVI calculado y sus valores. Elegir la coordenada en las opciones disponibles en el panel izquierdo:
Elección de coordenada para la cuadrícula de estudio. Fuente: propia
Valor de NDVI calculado para la imagen 1. Fuente: Propia.
Predicción
El sistema se entrena con una porción igual de cada una de las imágenes 1 a 5. Esta porción es un recuadro de coordenadas aleatorias y dimensiones igual al ancho/alto de la cuadrícula indicado en la banda lateral (en Streamlit).
La razón de elegir un recuadro reducido es el elevado coste computacional que tiene el entrenamiento del sistema. Este coste puede estar rondando aproximadamente 5 minutos de procesamiento para un fragmento inferior a 250 píxeles de dimensión, en un ordenador con una RAM de 8GB y un procesador: Intel Core I5 2,67 Ghz.
De esta forma la aplicación puede mostrar unos resultados de una forma relativamente ágil. Para el test se ha elegido las imágenes de las cuadrículas 1 a 5 con las que se ha obtenido el índice NDVI.
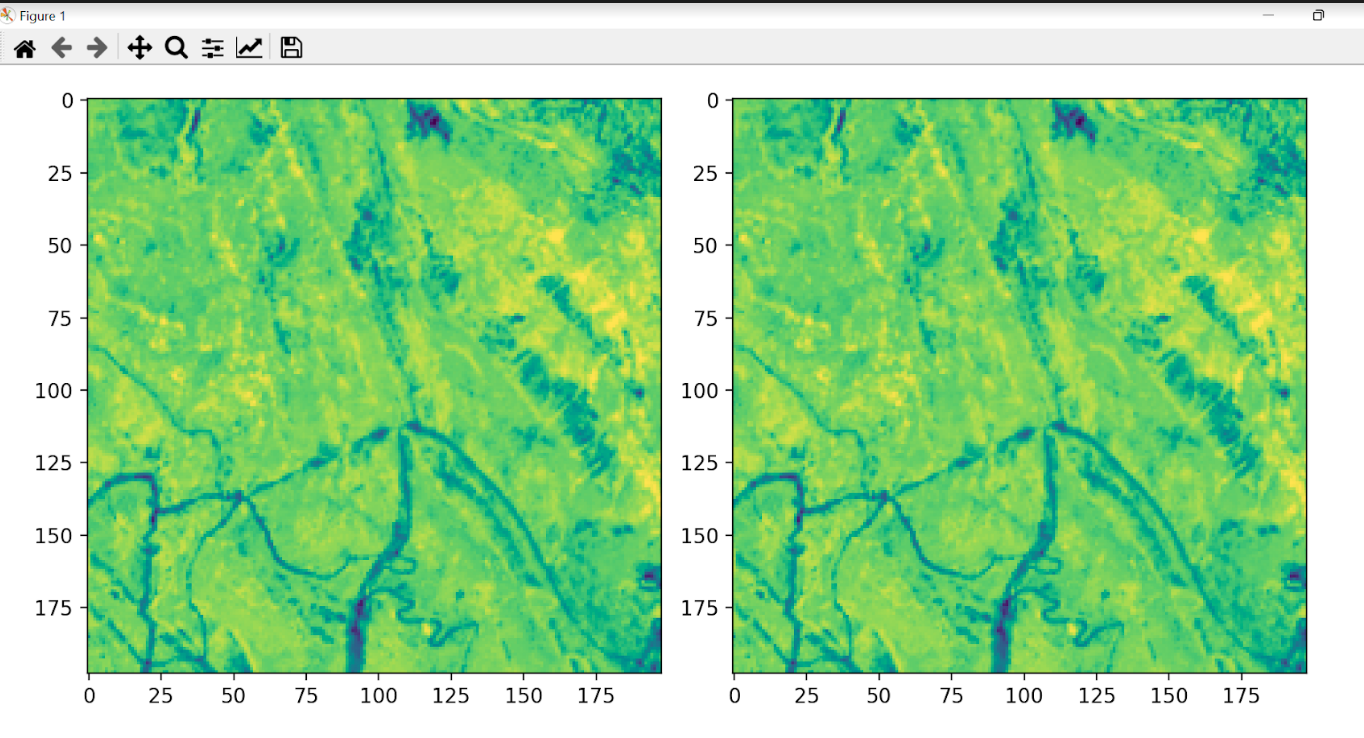
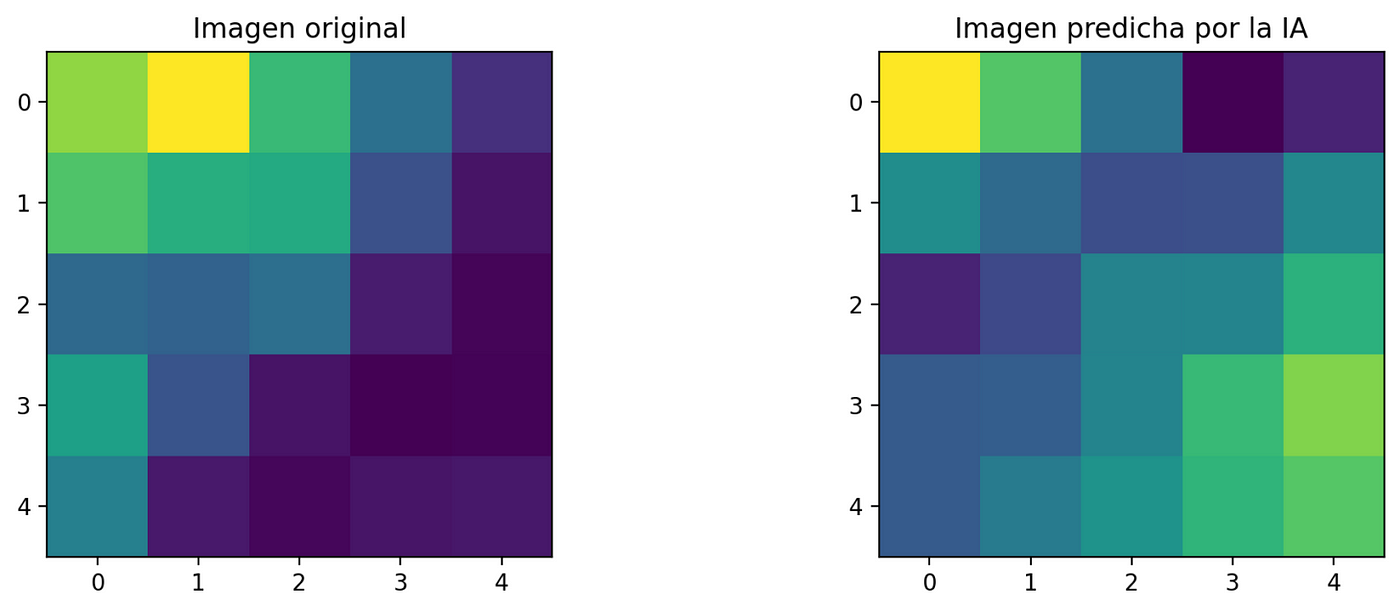
La predicción se hace con la cuadrícula 6. Se compara la imagen original con la predicha por la IA.
Comparación fragmento de la imagen original vs. imagen predicha por la IA
Datos generales de las imágenes:
Coordenadas de la esquina superior izquierda: i_0i0 * j_0j0 = 0 * 0 px Coordenadas de la esquina superior derecha: i_nin * j_njn = 5 * 5 px
Error cuadrático promedio: 0.03719
Conclusiones
Existe software propietario como ERDAS para facilitar el cálculo de NDVI y algoritmos de regresión para predecir comportamientos, sin embargo, alineados con los principios de Saturdays.AI: acercar la IA a todos los ciudadanos y aplicarla a problemas sociales, hemos optado por una solución basada en herramientas de código abierto y disponibles para todo público.
Este proyecto tiene la potencialidad de explorar como una fase siguiente la capacidad de procesamiento de datos para imágenes de dimensiones más grandes, ya sea en resolución espacial o temporal, de forma más eficiente en la nube. Tomando ventajas como procesamiento en paralelo o distribuido se podrán añadir más entradas al algoritmo y procesamientos más complejos que no se pueden suplir con los recursos actuales
La desertificación sobre las zonas evaluadas se puede predecir de forma eficiente, con un margen de error bastante reducido para la primera fase de evaluación. A nivel numérico es posible establecer dónde la vegetación se ha ido perdiendo a lo largo del tiempo y predecir sus valores futuros para tomar acciones a tiempo sobre estas zonas y evitar así, nuevas zonas de desertificación.
Se puede encontrar el código de este proyecto en GitHub
Adicionalmente, el código de visualización se puede encontrar en : GitHub Streamlit
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
El fatídico 11 de marzo del 2020, la OMS declaró la pandemia mundial por COVID-19. Más de 300 días después, hemos decidido hacer público y accesible para el mundo entero el trabajo que hemos venido desarrollando durante más de 8 semanas.
Prepárense, gobiernos e instituciones sanitarias del planeta, pues lo que van a ver en este artículo establecerá los cimientos de un nuevo sistema de vigilancia que permitirá asegurar el cumplimiento de una de las medidas que más se ha repetido durante estos fatídicos 300 días: la distancia de seguridad interpersonal de metro y medio.
Nuestro incombustible grupo, formado por 3 “locos” ingenieros (alguno de ellos en proceso) ha trabajado día y noche para traer la mejor solución posible a este problema.
El proyecto, que comenzó bajo el nombre de WATCHDOG (perro guardián) por la misión inicial que teníamos en mente (un robot con autonomía de movimientos que vigilase el cumplimiento de la distancia de seguridad y que ladrase cada vez que esta fuera quebrantada) iba a ofrecer, más allá del obvio beneficio de un constante recordatorio a las personas de la necesidad de cumplir con la medida de la distancia interpersonal, una herramienta para el mapeo y creación de “puntos calientes” en los que la distancia se incumpliese más a menudo.
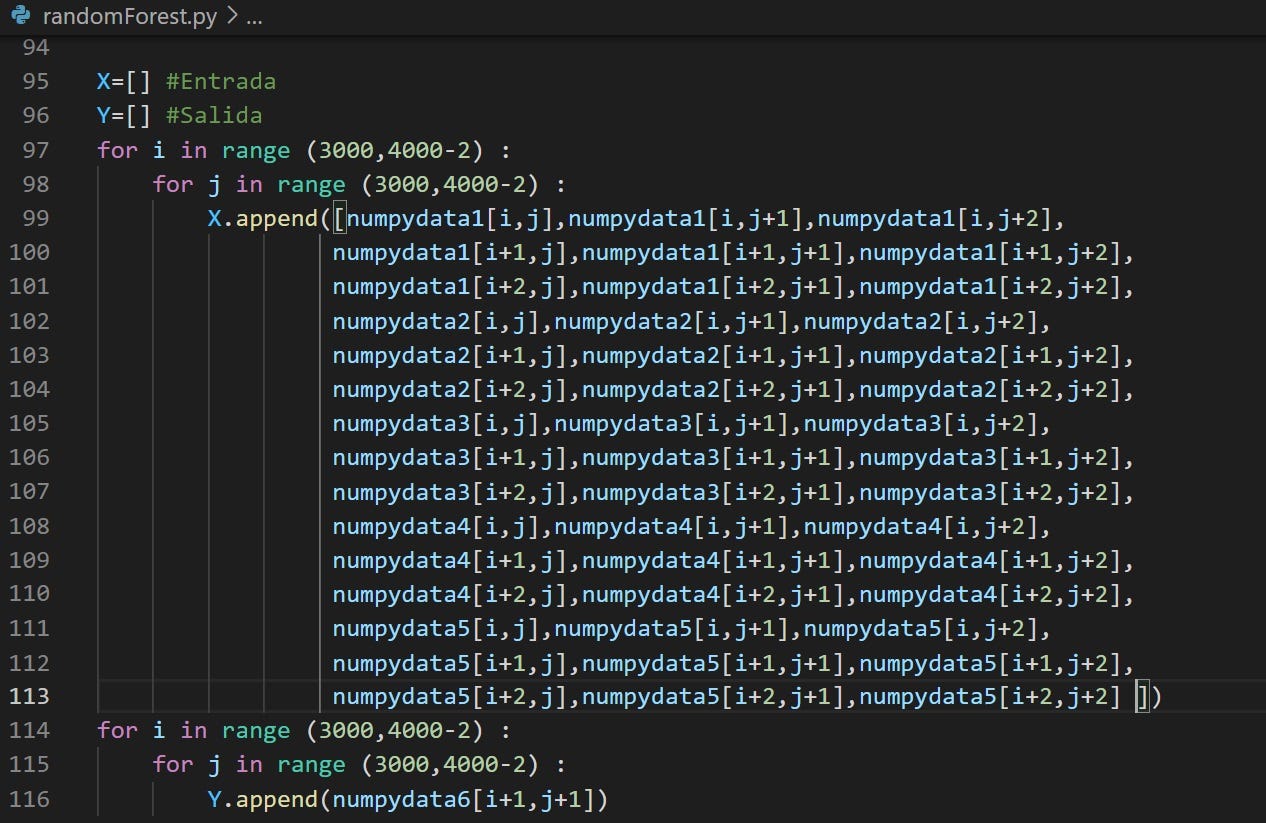
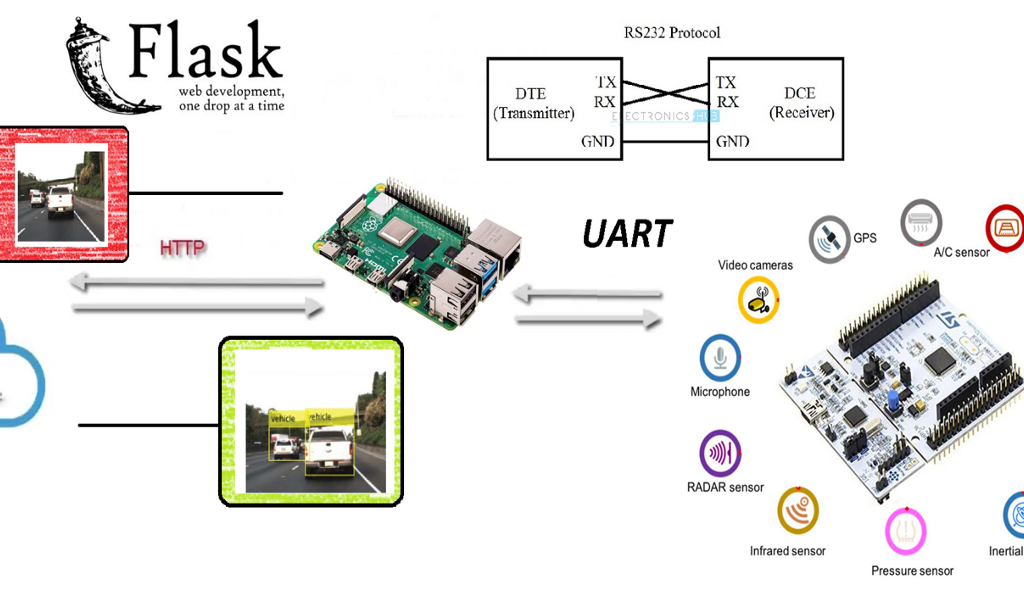
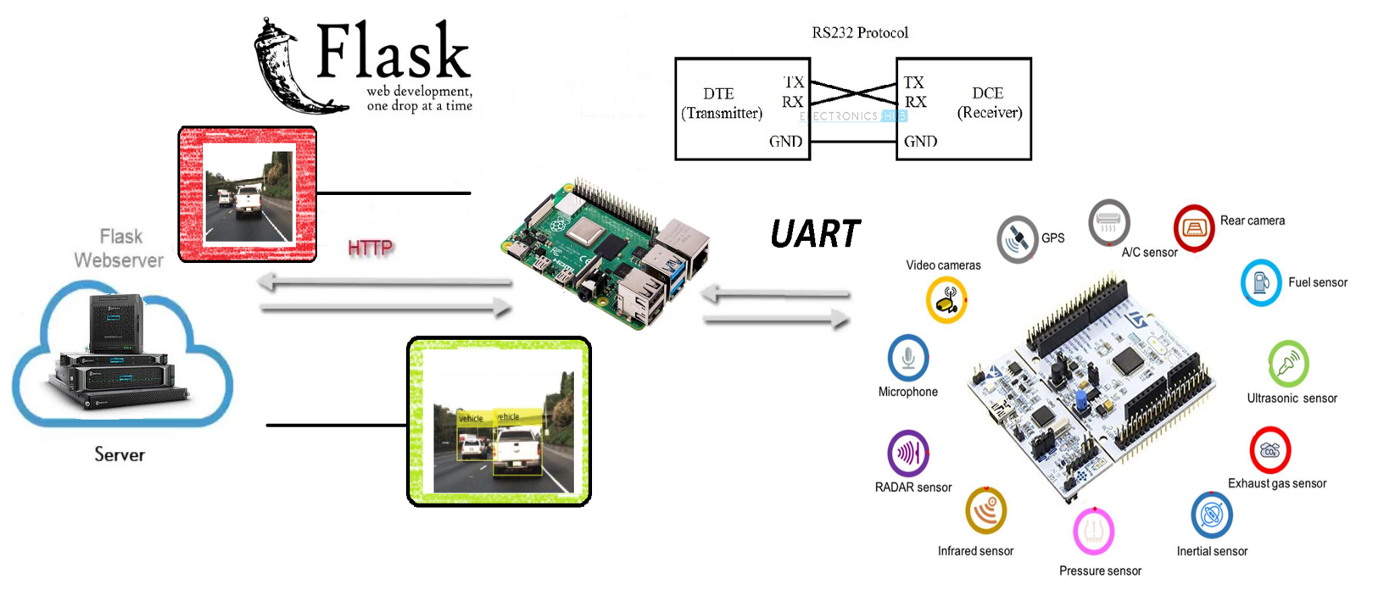
Para todo ello, el equipo ha tratado de crear una convergencia entre los mundos de la electrónica y la Inteligencia Artificial, haciendo uso de los medios más innovadores que tenía a su mano. Con una Raspberry Pi 3, un microcontrolador de bajo nivel equivalente a Arduino Mega, diferentes medios para la comunicación, algoritmos, librerías y redes neuronales convolucionales se ha tratado de alcanzar la solución con la mayor satisfacción posible.
El proyecto
Para el proyecto de Saturdays.AI se ha pensado en desarrollar un proyecto Watchdog (perro guardián) que vigila la distancia mínima recomendada por los protocolos Anti-COVID.
El planteamiento inicial ha sido el de programar un robot capaz de emitir un ladrido cuando la distancia de seguridad (requerido por los protocolos Anti-COVID) fuera quebrantada, enviando los datos adquiridos a un servidor y realizar un mapeo (mapa de calor) en tiempo real.
El objetivo básico del proyecto es converger el mundo OT con el mundo IT, es decir, la convergencia de la electrónica con el de la IA (inteligencia artificial) muy de moda en el mundo IT, utilizando técnicas de Deep Learning, que es una de las ramas del Machine Learning. De hecho, a pesar de que esta primera edición de AI Saturdays Euskadi se haya orientado al Machine Learning en general, hemos decidido profundizar en el Deep Learning por voluntad propia.
Poco a poco se están desarrollando tarjetas electrónicas autónomas que funcionan At The Edge (es decir que la misma tarjeta de control aplica los algoritmos) sin utilizar el Cloud para ello, o sin utilizar una unidad PC más potente para su procesado. Este fenómeno, conocido como Edge Computing, permite aliviar la carga de procesamiento a servidores centrales delegando tareas que puedan ser sencillas pero repetitivas a los nodos externos.
Funcionamiento
Cuando se detectan 2 personas, manda la posición de la detección y la imagen de violación de la distancia a un servidor Web, creado con Flask.
En lo que al mapeo respecta, la idea inicial era realizar un mapeo SLAM (simultaneous localization and mapping) utilizando un sensor LIDAR o una cámara 3D, pero nos hemos encontrado con limitaciones para hacer un Point Cloud que nos permitiera ejecutar el mapeo. Se describe esta limitación en los Trabajos a Futuro.
Objetivo
El objetivo inicial era plasmar todo el código dentro de una tarjeta Raspberry PI 3 (de aquí en adelante RPi3), pero a pesar de existen librerías para controlar los módulos de entradas y salidas (GPIO), el dispositivo no es lo suficientemente potente para poder procesar todo en tiempo real. Para ello existen módulos dedicados y deterministas que facilitan estas tareas.
Para tratar de cumplir con el objetivo aquí propuesto se ha utilizado un microcontrolador STM32F411RET. Se trata de un microcontrolador de gama baja equivalente a un Arduino Mega, pero con un sistema operativo de tiempo real (Real Time Operating System o RTOS), al ser determinista se tiene el control del timing y tareas, pudiendo tener un mayor control para la adquisición de datos y respuesta de los actuadores.
Se decidió utilizar esta tecnología por la gran cantidad de librerías robustas que existen para controlar los periféricos.
Algoritmo YOLOv4
El algoritmo final que se ha usado ha sido por goleada YOLO (para nuestro caso), respecto a otros conocidos como SSD (Single Shot Detection) o la más precisa de todas las tecnologías RESNET.
El reto en este apartado ha sido buscar la tecnología que mejor se adapta al tiempo real y nos basamos en las reglas de oro que dijo uno de los mentores:
1. ¿Qué pasa en el mercado? ¿Cuál es la tendencia del mismo? ¿Qué tipo de arquitectura es más viable con las restricciones presupuestarias y de tiempo que tenéis?
2. Mirad lo que hacen los grandes. ¿Podemos pensar igual a ellos? Es decir, ¿tenemos que plantearnos entrenar redes extremadamente complejas, o tenemos que poner los pies en la tierra y plantear ejemplos más rápidos para construir un Producto Mínimo Viable (MVP)?
3. ¡Adáptate!
En esta fórmula, el resultado de 1+1 en ingeniería sería determinista pero en la vida real el resultado es estocástico, así que depende. ?
Este proyecto está acotado para capacidad computacional de gama media y se ha querido estrujar al máximo desde ese punto de vista. Por ello, el mejor algoritmo que encontramos, el cual estaba puramente escrito en C (siendo un terrible reto el aplicar funciones matemáticas a pelo; aprovechamos para agradecer a Joseph Redmon) es lo más rápido comparado con librerías escritas a mayor alto nivel (TensorFlow, pyTorch).
Como curiosidad, usando la versión para embebidos de SSD se llega a unos 18 Frames por Segundo (FPS) comparado con YOLO, que llega a 24 FPS. Sin haber añadido telecomunicaciones nos dimos cuenta cuál era el camino a seguir, pero se encontraron todo tipo de resoluciones de las distintas tecnologías.
“Cabe destacar que para el equipo, el algoritmo o tecnología más completo y adaptado si se tuviera un poco más de capacidad computacional serían RNN o FAST-RNN, ya que de una tirada no solo tendríamos la posición de los objetos, sino cada pixel de la imagen estaría vinculado a una clase y con esto se podría dotar al proyecto de la capacidad de contextualizarse en el entorno. Y esto nos llevaría a más poder de adaptación, teniendo en particular un efecto positivo para el ámbito del Machine Learning, donde se dispondría de más DATO al que poder darle valor sacado del entorno.”
Si se tiene aún más curiosidad al respecto, os dejamos este link.
Como esto se extendería hasta el infinito, no se van a explicar los detalles del funcionamiento a fondo; se adjunta un link donde se explica detalladamente el algoritmo en su versión v3. La diferencia está en que en la versión v4 aumenta la precisión pero en su versión tiny la velocidad se mantiene constante.
EDA: Y ahora… ¡Metemos los “Datos” de nuestros sensores a la caja negra!
La analogía del “EDA” realizado en nuestro proyecto de Deep Learning tendría que ver, entre otros, con limpieza y preprocesamientos hechos de las imágenes obtenidas. El primer preprocesamiento ejecutado sería el que ofrece la función BLOB de OpenCV que reduce la escala de 8 bits (255 RGB) a escala porcentual unitaria.
Este detalle es muy importante ya que pasa el resultado de cualquier cámara a la que el algoritmo necesita de entrada. ¿Lo malo? Que se vuelen datos de coma flotante y eso requiere más gasto computacional pero de ese problema ya se encargaron sus autores.
El “tuning” de los parámetros en este aspecto que hemos hecho ha sido pasar la imagen de entrada a la escala más pequeña (316 x 316 píxeles).
Habiendo hecho este primer paso, la imagen pasará por múltiples filtros internos cambiando la dimensionalidad de la entrada y readaptando al mejor estilo de Nolan con películas del calibre de Tenet o Inception. ¿El resultado?
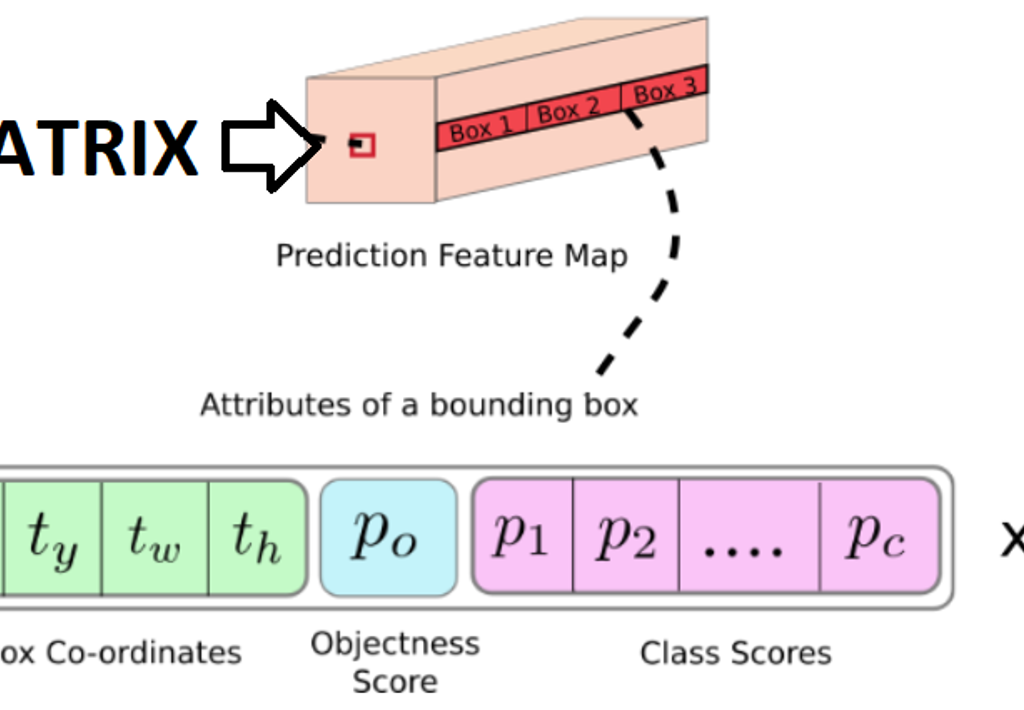
El algoritmo YOLOv4 entrega los datos de la imagen en una matriz compuesta de 13x13x (A x ((B+P) + C)), siendo:
A: La cantidad de anchor boxes (siendo una anchor box un “espacio en el que se puede detectar la posible presencia de un objeto”).
B: Las coordenadas de posición del objeto.
P: La probabilidad de confianza de que hay objeto.
C: Las clases que deseamos identificar y su respectiva probabilidad.
Dentro del archivo “coco.names” están las clases asociadas a sus respectivos nombres pero de este resultado se filtran “únicamente” los resultados en la que la clase es una persona
? ¿Y por qué no reentrenar la red aplicando transfer learning?
Mucho ojo, ya que nuestro equipo se peleó para mejorar la respuesta de este algoritmo para aumentar y darle más valor a la matriz de salida de la versión tiny.
Los resultados, por desgracia, no fueron los esperados. El mapa de características que se crea en estos modelos se basa en cantidades muy grandes de datos y de mucha variedad en el tema de la visión, donde son necesarias grandes cantidades (10.000 imágenes) para que el procesamiento pueda ser fluido. Y es cierto, si se reentrenara partiendo de transfer learning nos ahorraríamos muchas imágenes de entrada, pero también hay que tener en cuenta las clases de objetos que se quieran reconocer. Mientras más clases de objetos haya el mapa de características aprende mejor a separar cada clase.
Por ello, se han usado los pesos de la versión COCO para el algoritmo YOLO, ya que era la más similar para nuestro caso.
A continuación, se aplica un segundo filtro, usado para aplicar el BBOX de los distintos anchor boxes para ver cuál es el mejor.
Estos pasos anteriores formarían el proceso EDA como tal. Sin embargo, y en comparación con un proceso de ML, el filtro que se aplicaría dependería del grado de confianza que se tenga de la detección de un objeto, mientras que en un proceso de ML la “manipulación” se suele hacer sobre el mismo dato.
Todo esto se ensambla en una función llamada “Impure Detector” que nos va a devolver los datos que más nos interesan en una lista de Python de la siguiente forma:
[Coordenadas de las Personas, Index_Impuros]
RPI3
La Raspberry 3B+ cuenta con el sistema operativo Raspbian y librerías OpenCV (4.1.0.22).
El funcionamiento de manera general es sencillo: Se procesan los datos de la imagen y se reenvían a un servidor Web Flask instalado en un PC.
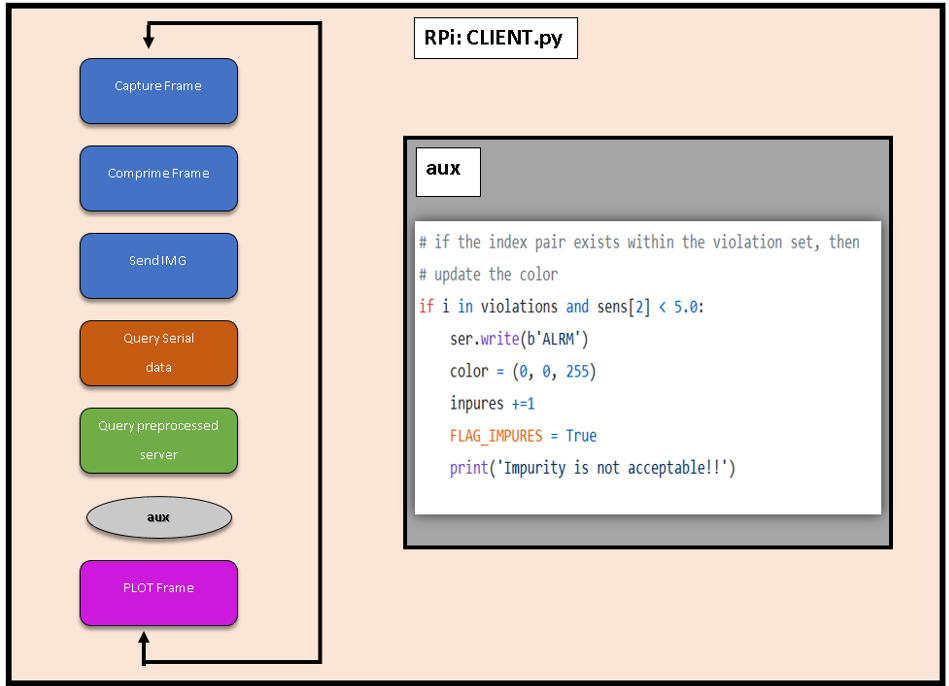
Podemos ver más detalles sobre el código de la RPi en CLIENT.py:
● Comunicación Serie
Tenemos una comunicación serie con el microcontrolador. Después de unas cuantas pruebas nos hemos dado cuenta de que, a la velocidad máxima con la que puede trabajar la RPi con python es con un BaudRate 115200 Bits/s, lo que limita la capacidad de mejorar el tiempo de espera entre Cliente-Servidor. Anotamos este aspecto como Trabajo futuro.
● MQTT
También se ha usado MQTT para enviar los datos respecto a la “violación” de la distancia de seguridad” a otro servidor. Sin embargo, como se ha mencionado antes, no se ha llegado a hacer un mapa de calor con el área de los “delitos de distancia de seguridad” a tiempo real, pero conseguimos enviar los datos e insertarlos en un archivo remoto, guardándolos en un fichero CSV dentro del servidor.
Un trabajo a futuro al que, por desgracia no pudimos llegar, era el de generar un pequeño script para graficar o plotear esos datos.
El diagrama de bloques obtenido para nuestro proceso.
Las imágenes son bastante problemáticas ya que enviar los paquetes de información tan largos y en la que la que el orden influya es complicado, es necesario indexarlos. Se han probado muchas, pero muchas metodologías distintas y la que mejores resultados ha dado ha sido usando una REST API del servidor.
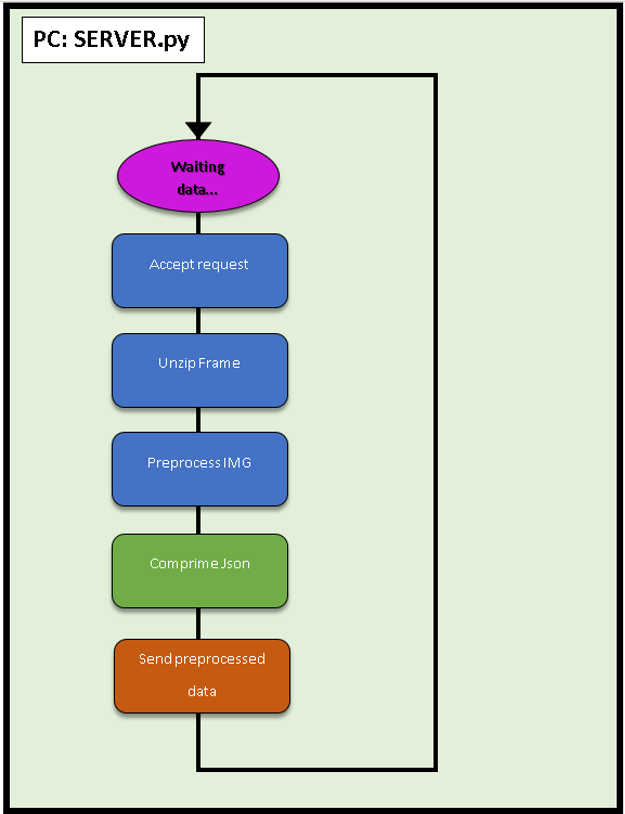
Servidor FLASK:
En Internet se encuentra de todo excepto lo que realmente se quiere, por lo tanto hemos tenido que desarrollar el sistema de envío de imágenes comprimidas por HTTP.
Para ello se han utilizado las funciones de imágenes por excelencia, recogidas en el paquete Open Source OpenCV utilizando un buffer dinámico, evitando la escritura en el disco. Esto se debe ya que por experiencia se ha visto que, a la larga, si no se cuidan, los servidores “envejecen” o “degeneran”. Esto evita por ejemplo forzar los soportes de memoria flash y controlar los ciclos de lectura/escritura aplicados.
Después de emplear OpenCV, nuestro sistema crea la captura en un buffer, lo comprime y se envía al servidor, quien lo descomprime y escribe a disco, dejándolo preparado para su almacenamiento y/o post procesamiento. Este envío se hace en formato JSON ya que se tenían errores al enviarlos en otros formatos.
? ¿Cómo enviar datos que son variables en el tiempo de forma constante?
Normalmente, para que dos personas y/o máquinas se comuniquen tienen que hablar el mismo idioma. En Machine Learning, además, los datos suelen enviarse en bloques constantes de información y de tamaño reducido. En nuestro caso, los pasos que va a ejecutar nuestro cliente son secuenciales y si se tropieza en algún punto todo se va al traste.
Por tanto, se han creado datos “ficticios” para enviarlos como mínimo para que todas las piezas del proyecto puedan funcionar sincronizadamente y en armonía.
Los “impuros” nos van a marcar el index del objeto al que esté pecando pero en los negativos no se va a fijar. Por tanto, esa es la razón por la que el proyecto consigue funcionar sin que se note este pequeño bug.
Esquema general del funcionamiento del servidor Flask.
Microcontrolador
Se ha elegido este microcontrolador (STM32F411RET) por una opción que un Arduino no ofrecía:
La programación de distintas subtareas para que se ejecuten de manera concurrente además de las interrupciones.
Programar en el STMCubeIde nos da la opción de tener la facilidad de programación de Arduino, así como librerías de entornos más industriales.
A diferencia del Arduino en el que el uso de multitareas metiéndolas en un proceso Round Robin es muy complejo, sumado a la limitación de la cantidad de temporizadores o timers que ofrece Arduino Uno 3, con el STM32F404RE estos problemas para insertarlos en la industria se mitigan.
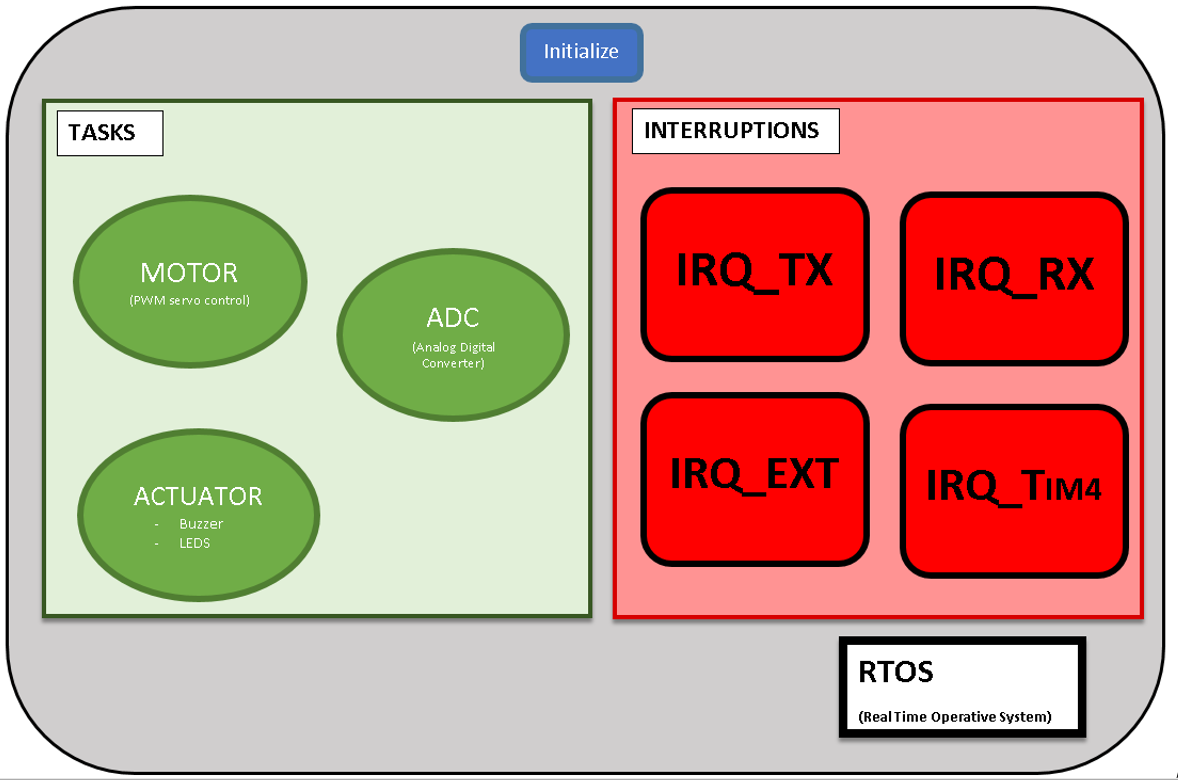
Por tanto, una vez que el micro haya ejecutado la configuración inicial (tareas, interrupciones, timers…) el programa empezará a ejecutar las tareas aplicando un Round Robin, las cuales se agrupan en el siguiente esquema:
Esquema de las Tareas o Programas Concurrentes existentes.
Dentro de las tareas o programas concurrentes existentes existen tres:
1. ADC
Este subprograma se encarga de leer las entradas digitales y procesarlas en 10–12 bits; aspecto que en una lectura por Arduino solo ofrecerá 8 bits de conversión.
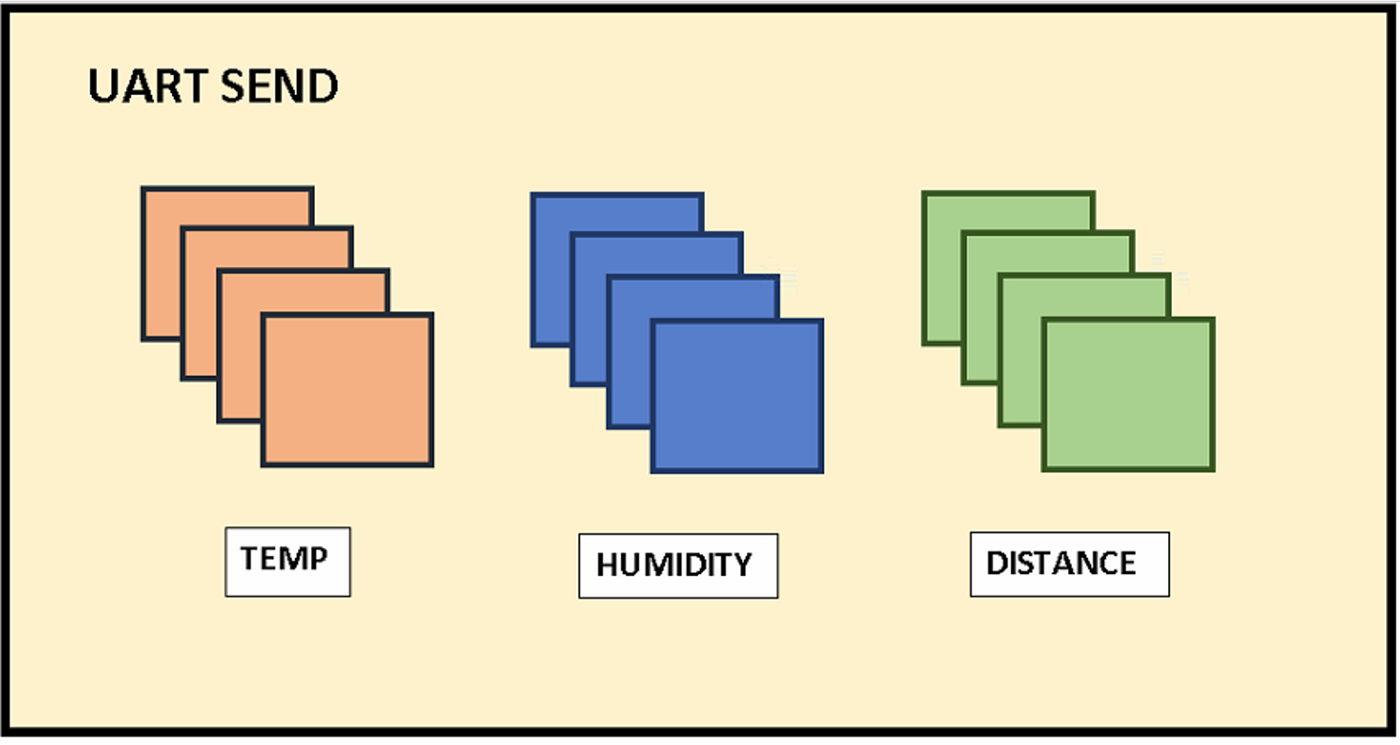
Una vez acabadas una por una en orden secuencial, insertará los datos aplicando sus respectivas conversiones en un vector global int32, siendo el motivo para guardarlos como int y no en float que la cantidad de espacio que ocupan se duplicaría (de 32 a 64 bits, por la coma flotante).
Como se puede apreciar en la imagen del envío del Transmisor-Receptor Asíncrono Universal (UART), se envían 4 datos por cada sensor. El último dato es el que quedaría detrás de la coma flotante para su posterior preprocesamiento sencillo en la RPi.
Ejemplo de esto sería recibir del sensor de distancia un valor de 1004 y transformarlo a 100, 4 en este caso simulando metros de profundidad.
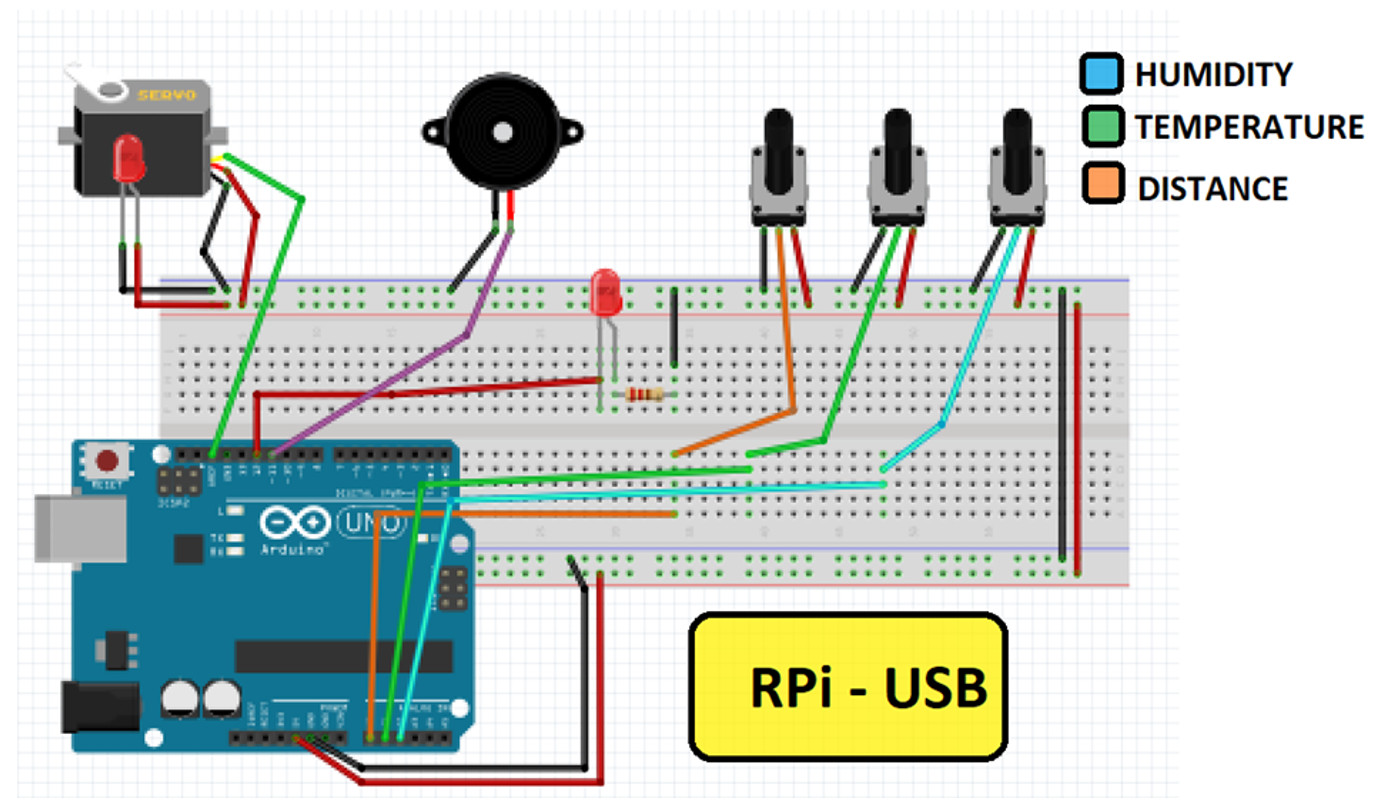
Sensores conectados por UART al microcontrolador
2. ACTUATORS
Dentro de los actuadores podemos encontrar que se conmutarán los estados de las salidas digitales pertenecientes al Buzzer y LED_EXT encargados de dotar al robot de notificar al entorno de manera acústica y visual.
No se ha añadido el actuador del motor porque se cree que separado se entiende mejor a la hora de distribuir el código.
3. MOTOR
Los servomotores trabajan entre 500 y 2500 ticks por lo que nuestra tarea TASK_MOTOR se aprovechará de las interrupciones del timer_4 para cambiar su valor ON/OFF.
Además, se ha añadido un acumulador, de tal manera que si mientras se detecta una violación de la distancia de seguridad y antes de que la función se apague se vuelve a recibir una interrupción por la violación de distancia, aumentará el tiempo de espera 5 segundos más en esa posición. Con esto nos aseguramos de que hay un mayor control de las presencias detectadas.
Interrupciones
Las interrupciones son peticiones síncronas o asíncronas al reloj en la que el procesador va a dejar de lado la tarea que esté realizando para centrarse en la interrupción.
Nosotros hemos definido 4 tipos de interrupciones.
1. IRQ_EXT:
Es la interrupción externa por botón a la que se va a acceder en caso de que haya un error tanto de comunicación o de cualquier otro tipo para resetear la configuración del microcontrolador sin que resetee todo. Reenviará la información y nos avisará enviando un “DONE” por el puerto serial.
2. IRQ_TIM4
Se ha configurado el timer_4 del microcontrolador para que se ejecute cada 1 MHz.
En resumen, para que tardemos 50 Hz que es la velocidad del servomotor tenemos que añadir un registro contador de 0–2000 unidades para que entre en la interrupción cada 50 Hz.
Es decir, que en cada 200 ms recibiremos 20000 ticks. O dicho de otra manera, cada 200 milisegundos nuestro micro interrumpirá la interrupción de ese timer.
3. IRQ_TX:
Esta interrupción únicamente va a encender un LED interno del microcontrolador para saber de manera rápida que todo está funcionando correctamente.
En la figura inferior, además de ver la distribución de los pines se puede ver el pin del LED interno así como el pulsador interno del microcontrolador.
Distribución de los pines del proyecto.
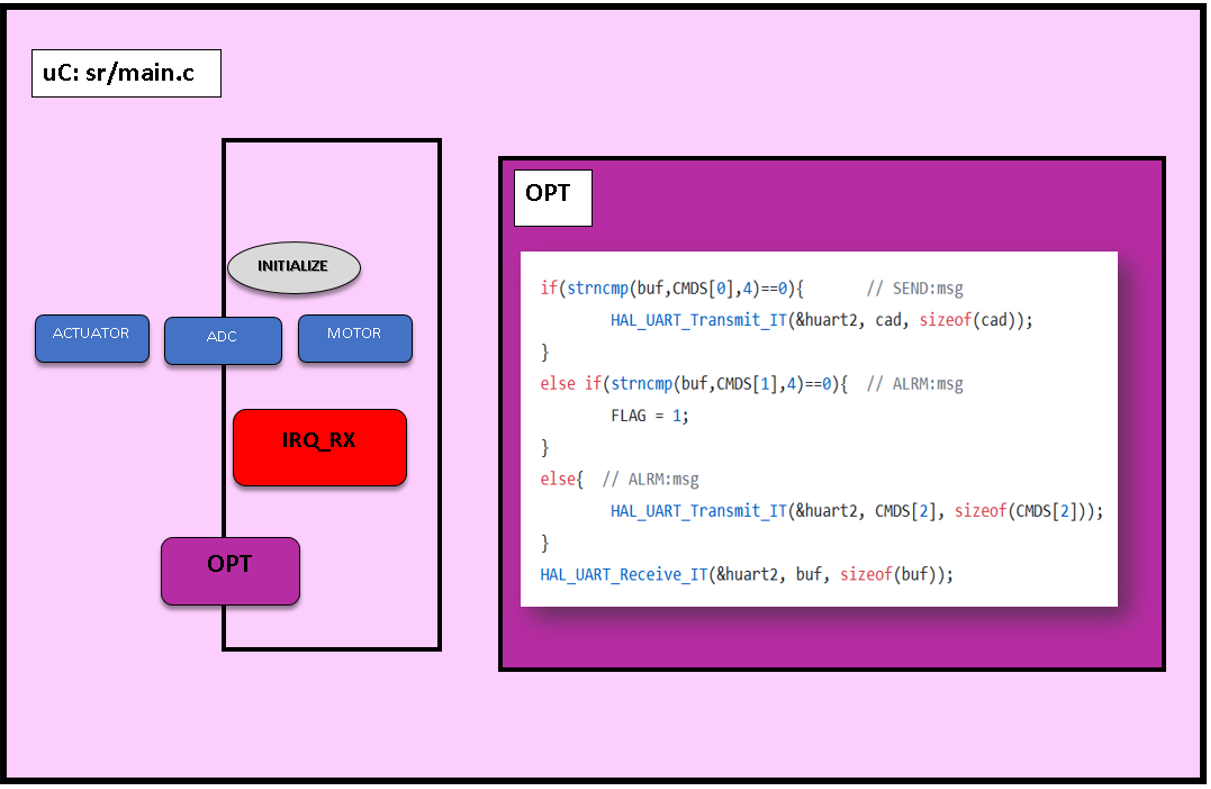
4. IRQ_RX:
A pesar de estar la última en la lista, es la interrupción más importante. Para que la RPi actúe como “cabeza pensante”, es necesaria una interrupción que esté atenta a cualquier señal asíncrona que reciba del microPC y que alerte a la RPi.
Los comandos que se van a enviar desde la RPi son dos:
“SEND”
“ALRM”
Cuando recibamos SEND el microcontrolador enviará los datos que tenga en ese momento en el vector “sens”.
Si recibe ALRM ejecutará los actuadores y si antes de que se acabe vuelve a recibir una entrada ALRM, aumentará el tiempo del mismo.
Figura que muestra el envío de señales a las tareas.
Conclusiones
Se trata de un proyecto aparentemente simple, pero que detrás de todo existe un ecosistema muy complejo al que se le quería meter mano. Solo hay que ver la arquitectura de la infraestructura que ha quedado:
Sensores – Unidad del Microcontrolador (MCU).
MCU – RPi.
RPi – PC: Uso de protocolo HTTP con peticiones POST al servidor web (REST API montada en Flask).
Aunque el objetivo era aplicar temas de Machine Learning, estos temas requieren de una determinada arquitectura y funciones para comunicaciones, tratamiento de imágenes etc. El tema de SLAM + ML se ha quedado a las puertas pero sí se han dado pasos para poder continuar con la misma.
Y a la larga, el objetivo que se había planteado que era aplicar esta tecnología al mundo real aparte de la IT y darle una aplicación más industrial, creemos que aunque no se haya logrado, se está un paso más cerca con el uso de estas “herramientas caseras”.
Como reflexión obtenido, hemos detectado que si se va a empezar a usar el Cloud Computing, para las próximas generaciones hará falta un cifrado de la información muy densa que se envíe (aunque se sacrifique la latencia), ya que es un tema muy serio al que poca importancia se le está dando actualmente.
Trabajo a futuro
Hemos detectado diferentes tareas como trabajo futuro de cara a este proyecto:
El mapeo del entorno, así como la geolocalización indoor. Hemos realizado pruebas con el sistema GPS que adquirimos, pero este sistema requiere que esté en un espacio abierto para su funcionamiento. Para facilitar esta geolocalización con sistemas alternativas, consideraríamos el uso de geolocalización indoor (mediante AprilTags, Bluetooth de Baja Energía o BLE, etc.).
La mejora del microcontrolador, aspecto que podría ayudar a mejorar en más del doble la velocidad de procesamiento de la RPI, lo que nos podría ayudar a compensar el retardo generado en la comunicación Cliente-Servidor.
La creación de un script de plotting para graficar los datos obtenidos mediante la conexión MQTT.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
La Paz 2021. Las técnicas de Inteligencia Artificial tienen muchas aplicaciones actuales en el campo de las fotografías. Una de ellas tiene que ver con la manipulación de imágenes, campo en el cual se inscribe nuestro proyecto.
En particular, la restauración de imágenes (image restoration) es el proceso de recuperar una imagen a partir de una versión degradada. Image restoration es un caso de estudio que normalmente es tratado con procesamiento de imágenes. Se parte de la idea de que la imagen ha pasado a través de una función de degradación y se le ha añadido ruido; la restauración entonces consistirá en revertir el proceso y recuperar la imagen original.
El propósito de este proceso es “compensar” o “deshacer” aquellos defectos que generaron la degradación de la imagen, obteniendo un estimado de la imagen original.
La degradación puede provenir de diferentes fuentes, como la difuminación de movimiento (motion blur), ruido, desenfoque de la cámara o una combinación de todas éstas. También hablaremos de degradación al referirnos a aquellas fotografías impresas o negativos que sufrieron cualquier tipo de desgaste debido al envejecimiento del papel, polvo, manchas, etc.
De manera tradicional, una vez identificado el tipo de degradación, es posible procesar la imagen con un tratamiento de procesamiento de imágenes. Existen diferentes estudios y especializaciones con respecto a estos procesos, especialmente para revertir el ruido agregado a la función de degradación. Cada caso es único, por lo cual el tiempo de procesamiento puede llegar a ser muy largo. Al mismo tiempo, podemos encontrar estudios de fotografía que ofrecen el servicio de restauración aplicando técnicas de edición digital, lo cual resulta costoso.
Ejemplo de restauración de imágenes
Por otro lado, tenemos los films negativos fotográficos producidos por las cámaras analógicas que son preservados por varios tipos de usuarios, desde historiadores y bibliotecarios hasta quienes simplemente desean conservar recuerdos familiares. Estas películas normalmente deben pasar por un proceso químico (revelado) para la obtención de la fotografía física que describe la escena que fue capturada con la cámara analógica.
Revelado digital de negativo
Existen técnicas de manipulación de la imagen digital de un negativo para obtener la imagen que correspondería a la revelada en el proceso tradicional. Estas técnicas siguen una secuencia de pasos que consisten en ajustar ciertos parámetros de la imagen que van más allá de la inversión de colores, algo que también se debe hacer imagen por imagen.
DESCRIPCIÓN DEL PROBLEMA y OBJETIVO
La selección de la técnica de procesamiento de imágenes que debe aplicarse a la imagen degradada proviene de una apreciación visual y resulta subjetiva. Muchas veces debemos aplicar varias técnicas en cascada para obtener un resultado óptimo. Este proceso consume tiempo, es específico a cada caso que se presente y en la mayoría de los casos no se puede paralelizar.
¿Y si pudiéramos utilizar la inteligencia artificial para crear un solo modelo que sea capaz de restaurar la imagen degradada sin necesidad de categorizar el tipo de degradación, cómo también realizar el revelado de las fotografías a partir de los negativos en film?
Éste es precisamente nuestro objetivo. Utilizaremos técnicas de Inteligencia Artificial para construir un modelo de restauración de fotografías que podrá recuperar la imagen original a partir de las degradaciones descritas y/o a partir de los negativos fotográficos. Para hacer el desafío más interesante incluiremos además imágenes en formato blanco y negro que deberán ser coloreadas; y también imágenes con regiones suprimidas, es decir taparemos regiones de la escena simulando manchas o rasguños que pudieran haber eliminado por completo estas regiones. Por más que existen modelos que hacen ciertas funciones que describimos, una de las dificultades será el de combinar todas estas restauraciones (colorización, revelado, restauración e incluso generación creativa) en un sólo modelo.
SELECCIÓN DE LOS MODELOS
El proyecto presentado está basado en varias librerías de Fast.ai, que proporcionan herramientas de manipulación de fotografías mediante inteligencia artificial, de datasets para entrenamientos e incluso de modelos pre entrenados que son un buen punto de partida. La arquitectura general escogida es la de trabajar con una GAN (Generative Adversarial Network), que es apropiada para resolver nuestra problemática.
La estructura general utilizada consiste en un generador de imágenes, que intenta crear imágenes con la mejor calidad posible, ya sea en el color, la resolución, la textura… Por otra parte se entrena un discriminador que debe distinguir entre las imágenes reales dadas cómo input y las imágenes generadas por el generador. Finalmente se hace un tercer entrenamiento donde se combinan los dos modelos anteriores, lo que crea la GAN: en este proceso ambos modelos compiten y obligan a mejorarse el uno al otro.
Nuestro modelo generador ya viene pre entrenado y consta de dos partes. La primera son las convoluciones que llevan una imagen de input hacia dimensiones cada vez más pequeñas, y la otra parte es cuando se hace el camino inverso para recuperar una nueva imagen de las mismas dimensiones que la que se tiene como input. La arquitectura total es UNET, que tiene como particularidad que cierta información del proceso de reducción de la imagen se le envía directamente a su contraparte (cuando las dimensiones son equivalentes). Este proceso se puede ver en la siguiente imagen.
Unet
De igual manera, las diferentes operaciones y convoluciones utilizadas están basadas en una arquitectura CNN (Convolutional Neural Network) Resnet34 (34 capas de profundidad), que utiliza bloques residuales o de identidad durante las operaciones de convolución. Cuando cargamos este modelo, se puede entrenar solo la parte de la derecha (aproximadamente 20 millones de parámetros) utilizando la opción freeze(), o se puede entrenar el modelo entero (aprox. 40 millones de parámetros) con la opción unfreeze(). En este momento del proceso, y viendo que se utiliza una loss function de Mean Squared Error (MSELossFlat()), el generador solo intenta acercarse lo más posible a los valores de los píxeles de la imagen original. Sin embargo, esto no es suficiente para capturar, por ejemplo, el entorno de los píxeles, en específico ciertas texturas que son muy importantes para obtener una imagen correcta y de buena resolución. Es por eso que se utiliza el generador junto al discriminador en una estructura GAN.
El discriminador (también llamado critic) utiliza una loss function de cross-entropy con logits permitiendo una clasificación binaria (BCEWithLogitsLoss()), que está bien adaptada a su objetivo. Antes de entrenar la GAN, el discriminador se puede entrenar entre imágenes creadas por el generador y los input reales. Sin embargo, lo que más nos interesa es el entrenamiento de la GAN.
En esta etapa, los dos modelos generador y discriminador se entrenan juntos. La idea es utilizar un switcher que decidirá si es momento de entrenar el generador para mejorar las imágenes creadas y confundir al discriminador, o al contrario entrenar el discriminador cuando un cierto umbral de imágenes están siendo clasificadas como reales cuando en realidad son creadas por el generador.
Este proceso se lo puede realizar iterativamente cambiando el tamaño de las imágenes con las cuales va trabajando el modelo, yendo de dimensiones más pequeñas a las más grandes. De esta manera, el modelo va mejorando progresivamente. Esta técnica se utiliza por ejemplo para mejorar la resolución de las imágenes que se le da al modelo de Inteligencia Artificial y mejorar así las fotografías.
PREPARACIÓN Y CONSTRUCCIÓN DEL DATA SET
Es bien sabido que uno de los aspectos más importantes en la construcción de cualquier modelo inteligente son los datos. Es así que pusimos énfasis en la obtención, preparación y construcción de un dataset que nos pudiera proporcionar todo el espectro de degradaciones que requerimos que nuestro modelo sea capaz de reconstruir y que contemos con la cantidad y variedad necesaria.
Trabajamos con el dataset VOC2012 y ColorizationDataSet como datos iniciales (imágenes variadas a color y sin defectos). Decidimos utilizar 9895 imágenes en total. A una mitad se le aplicó un proceso de negativización artificial gracias a un preprocesamiento de imagenes y para la otra mitad se tomó en cuenta las imágenes en blanco y negro. A todas éstas imágenes se le aplicó un segundo procesamiento de imágenes dónde a un 65% se le aplicó algún tipo de degradación como ser compresión jpeg, ruido sal y pimienta, difuminado (blur), entre otros; y a un 25% se aplicó una degradación más importante cómo son unos huecos o manchas en varios sectores de las imágenes. A continuación podemos ver varios ejemplos de este tratamiento.
Imágenes degradadas generadas artificialmente
Para el entrenamiento del modelo, se dividió el dataset en un train set de 8906 imágenes y un test set de 989 imágenes.
EVALUACIÓN DE MODELOS
Para entrenar nuestro modelo, utilizamos la GPU proporcionada por Google Colab. Antes del entrenamiento de la GAN, se puede entrenar el generador y el discriminador con sus respectivas loss function detalladas en el punto 4.
Para el generador, vemos que existe una cierta mejora al avanzar el número de épocas, tanto para el train set como para el test set. Hay que tener en cuenta que esto es sólo una parte del entrenamiento del generado,que en realidad se hará durante el entrenamiento de la GAN.
Curva de Loss function en uno de los entrenamientos del Generador
Para el discriminador, de igual manera se lo puede entrenar solo, y en esta etapa podemos llegar a un accuracy de hasta 95 %, lo que demuestra que antes de entrenar la GAN, le es muy fácil distinguir las imágenes reales de aquellas producidas por el generador.
Durante el entrenamiento de la GAN, se utilizan otras loss function un tanto modificadas tanto para el generador como discriminador. Sin embargo, para evaluar el modelo final, se necesita hacer una verificación visual ya que las loss function de ambos no nos proporcionan información relevante porque ambas funciones irán mejorando y empeorando en función de qué modelo se esté entrenando.
ANÁLISIS DE RESULTADOS
Para el entrenamiento del modelo de Inteligencia Artificial especializado en las fotografías se preparó un conjunto de datos de 9895 imágenes de negativos fotográficos (artificiales) y 9895 imágenes a color, cada uno de los negativos tiene una imagen a color relacionada..
El conjunto de datos se dividió en 2 grupos uno de entrenamiento y otro de validación, bajo el siguiente detalle:
– Train (8906 imágenes)
– Valid (989 imágenes)
Para el entrenamiento se consideraron los siguientes grupos de imágenes:
a) Imágenes en blanco y negro.
b) Imágenes sin degradación.
c) Imágenes con ruido gaussiano.
d) Imágenes con degradación y supresión de regiones
Resultados Train:
– Imágenes en blanco y negro
Imagen: image2669.jpg
De izquierda a derecha: Imagen Original, Imagen degradada blanco y negro, predicción en el entrenamiento
– Imágenes en negativo sin degradación
Imagen: 2007_000039.jpg
De izquierda a derecha: Imagen Original, Imagen en negativo, predicción en el entrenamiento
Podemos ver que el modelo hace un buen trabajo al colorear ciertas imágenes negativas, encontrando el color correcto en la mayoría de los objetos de la imagen.
– Imágenes en negativo con ruido gaussiano.
Imagen: 2007_003118.jpg
De izquierda a derecha: Imagen Original, Imagen en negativo con ruido, predicción en el entrenamiento
La restauración de ruido hacia una mejor resolución no está completamente realizada, incluso para el train set. Podemos concluir que hace falta más tiempo de entrenamiento para continuar con el proceso.
– Imágenes en negativo con regiones suprimidas
Imagen: 2007_000033.jpg
De izquierda a derecha: Imagen Original, Imagen en negativo con supresión de regiones, predicción en el entrenamiento
Imagen: 2007_000027.jpg
De izquierda a derecha: Imagen Original, Imagen en negativo con supresión de regiones, predicción en el entrenamiento
Para las imágenes degradadas con partes enteras faltantes, el modelo reconoce el color que le debe dar a la zona oscura. Por el momento, la resolución es mala, pero con más entrenamiento, esto puede ir mejorando.
Resultados Test Set:
– Imágenes en blanco y negro.
Imagen: image0476.jpg
De izquierda a derecha: Imagen Original, Imagen degradada blanco y negro, predicción en el testing
– Imágenes en negativo sin degradación.
Imagen: image1027.jpg
De izquierda a derecha: Imagen Original, Imagen en negativo, predicción en el testing
– Imágenes con ruido gaussiano.
Imagen: image0850.jpg
De izquierda a derecha: Imagen Original, Imagen con ruido, predicción en el testing
– Imágenes con Degradación
Imagen: image4988.jpg
De izquierda a derecha: Imagen Original, Imagen en negativo con supresión de regiones, predicción en el entrenamiento
Resultados de imágenes que no forman parte del dataset:
A continuación presentamos resultados de predicción del modelo en imágenes completamente nuevas que no se utilizaron durante el entrenamiento. Podemos observar que dependiendo la imagen en blanco y negro, la colorización se hace de manera aceptable en algunas pero casi nada en otras. De igual manera en la segunda imagen se observa que la imagen del resultado ha mejorado la calidad de la imagen en cuanto al ruido que presenta la original. En cuanto a la imágenes en negativo, el modelo hace un buen trabajo en detectar los objetos de la imagen y colorearlos acorde a lo detectado.
CONCLUSIÓN
Este proyecto de Deep Learning nos permitió familiarizarnos con ciertas técnicas de manipulación de imágenes, código en Python, librerías especializadas en Deep Learning así como técnicas de entrenamientos de modelos en ciencia de datos, usando la Inteligencia Artificial aplicándola a las fotografías. Los resultados son aceptables considerando las limitaciones en tiempo de entrenamiento así como en GPU que se tuvieron. Vimos que el modelo puede trabajar tanto con negativos fotográficos como con fotografías antiguas en blanco y negro que pudieran presentar degradaciones leves o fuertes. Sin embargo, queda mucho margen de mejora como por ejemplo vimos que algunas restauraciones de negativos tienen un tinte azul de fondo, probablemente debido al hecho de haber utilizado negativos solo creados artificialmente y no “reales”. Estos negativos pueden presentar diferentes calidades químicas, de material… que pueden variar por modelo o marca. De igual manera es probable que utilizar imágenes degradadas reales aumente el poder del modelo.
Ziyu Wan, Bo Zhang, Dongdong Chen, Pan Zhang, Dong Chen, Jing Liao, and Fang Wen. Old photo restoration via deep latent space translation. arXiv preprint arXiv:2009.07047, 2020.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Today, thanks to deep learning algorithms of artificial intelligence, we have the possibility to automate the classification of images, so this tool can help medical personnel in the classification and early detection of breast cancer. In this way, women suffering from this disease could be diagnosed automatically, in time to start treatment.
Breast cancer is the most common type of cancer in women and is also one of the main causes of death according to the WHO (WHO, 2020). Early detection is the single most important factor in lowering cancer treatment costs and mortality. To make it possible it is necessary to have medical ultrasound images and specialists who can explain them. However, the lack of these creates a gap in access to early treatment in countries with little or not enough access to specialized diagnostic services and whose population receives low and middle income.
Description of the problem
Our project consists of the detection and classification of breast cancer in women between 25 and 75 years old. This is possible from the development of an deep learning model trained with images obtained using ultrasound scanners that result in the segmentation of the type of cancer that could be suffered.
Objective
Allow women suffering from breast cancer to be automatically diagnosed using a deep learning model so that they can start treatment early and safely, reducing costs and the mortality rate. To meet this objective, we have proposed a tool that uses artificial intelligence to provide greater agility to the process through self-diagnosis with ultrasound images.
Model selection
The breast cancer detection and classification project works with ultrasound images of three types, labeled as benign, malignant and neutral, so the deep learning model selected for its execution is convolutional networks with TensorFlow Keras.
Datasets
The dataset was collected from Baheya Hospital for Early Detection and Treatment of Women’s Cancer, Cairo, Egypt. It contains 780 breast ultrasound images, in women between 25 and 75 years old (133 normal, 437 benign and 210 malignant) with an average image size of 500 x 500 pixels, some of which are seen below,
Fig. 1. Samples of images
The images from the original dataset contain mask images that do not provide meaningful information to the model we developed, for this reason Shell statements were used to remove them from the dataset we are using.
Implemented techniques
We must emphasize that until now there is a shortage of public data sets of breast cancer ultrasound images and it prevents the good performance of the algorithms. Because of this, the authors who made public the dataset we used, recommend augmenting data using GANs.
Our project developed GAN networks for each class in order to obtain more accurate results and 150 epochs were used.
However, it failed to create usable images, for this reason we declined the use of this technique. The challenge is to develop the GAN with a greater number of epochs and with a better neural network configuration to obtain more realistic images.
Fig. 2. MALIGNANTSource: Compiled by authors using MatplotlibFig. 3. BENIGNSource: Compiled by authors using MatplotlibFig.4. NORMALSource: Compiled by authors using Matplotlib
Network definition
Within the possible design patterns in Keras, subclassing has been implemented to use the low-level APIs of Keras. You can consult more information about this in the following article:
Preprocessing layer: Resizing, Rescaling and Normalization
Conv2D: 32 filters, 4 strides, ‘same’ padding and ReLU activation
MaxPooling2D: pool_size of (3,3), ‘same’ padding and 2 strides
Flatten
Dense: 512 neurons and ReLU activation
Dropout (0.4)
Dense: 3 neurons and SoftMax activation
We are based on AlexNet architecture, on which we made some adjustments like number of neurons, fully connected layers and dropout values.
We use Adam optimizer with learning rate of 0.0001, the Sparse Categorical Crossentropy loss function and Sparse Categorical Accuracy function.
Fig. 5. Model summary — Source: Compiled by authors
Training
TensorBoard was used to observe the real-time behavior of the accuracy and loss values, which provides useful graphs to analyze results and many controls for their manipulation.
Fig. 6. Dashboard TensorBoard — Source: Compiled by authors
Earlystopping
We use EarlyStopping as a form of regularization to avoid overfitting when training the model. For example, if the loss value stops decreasing, the training will stop even though all iterations have not been completed.
Conclusions and future works
WomanLife is intended to be an easy-to-access, low-cost medical diagnostic tool.
This AI is not only beneficial for women who use it but also has the potential to become a medical assistant. We want to clarify that WomanLife does not intend to replace medical specialists but to provide a tool that facilitates their work.
From now on we intend to optimize the model using a GAN network to obtain greater precision and use techniques that find the correct parameters for training the model (Hyperparameter tuning).
Our project also developed an application that, given an image scanned with the camera or selected from the gallery, goes through the developed network and returns a series of probabilities related to the type of cancer suffered.
The model was developed in pure TensorFlow, converted, saved and exported to TensorFlow Lite.
Fig. 7. Sample of the operation of the application prototype — Source: Own elaborationFig. 8. Conversion from TensorFlow to TensorFlow Lite architecture — Source: Own elaboration
Sources
You can access to notebook and mobile application through my GitHub repositories bellow:
Here, you will can find more projects related to Data Science and Machine Learning. In summary, it contains all my work so far. Any reply or comment is always welcome.
About the authors
Erick Calderin Morales
Systems engineer with experience in software development, master’s student in systems engineering and master’s degree in data science with an affinity for artificial intelligence.
Al-Dhabyani, W., Gomaa, M., Khaled, H., & Aly, F. (2019). Deep learning approaches for data augmentation and classification of breast masses using ultrasound images. Int. J. Adv. Comput. Sci. Appl, 10(5), 1–11.
Al-Dhabyani, W., Gomaa, M., Khaled, H., & Fahmy, A. (2020). Dataset of breast ultrasound images. Data in brief, 28, 104863.
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of rogramas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!