Quito. 2021
Utilizamos la Inteligencia Artificial para ayudarnos a realizar el diagnóstico presuntivo de trastornos en niños en edad escolar.
Saturdays.AI es una iniciativa a nivel global, cuyo principio es promover escenarios para la democratización del aprendizaje de la Inteligencia Artificial para todos y de forma ubicua. Democratizar, significa facilitar el acceso a todos los ciudadanos que deseen alcanzar una formación pertinente, relevante y de calidad, en cualquiera de los niveles educativos o profesionales. Por ese motivo, el equipo de investigación y desarrollo, conformado por: {Andrea Mariana Escobar, Danny Aguirre, Luis Chamba Eras, Marco Chiluiza, Paúl Quezada}, decidió participar en la Tercera Edición del Saturdays AI Quito, que de manera inédita, ubicua y flexible, se desarrolló de manera virtual.
En la primera sesión, se desarrolló la lluvia de ideas, con el objetivo de identificar la línea de investigación base, sobre el cual se desarrollaría el proyecto, sobre todo que tenga un impacto social y relacionado con los objetivos-metas de la Agenda 2030.
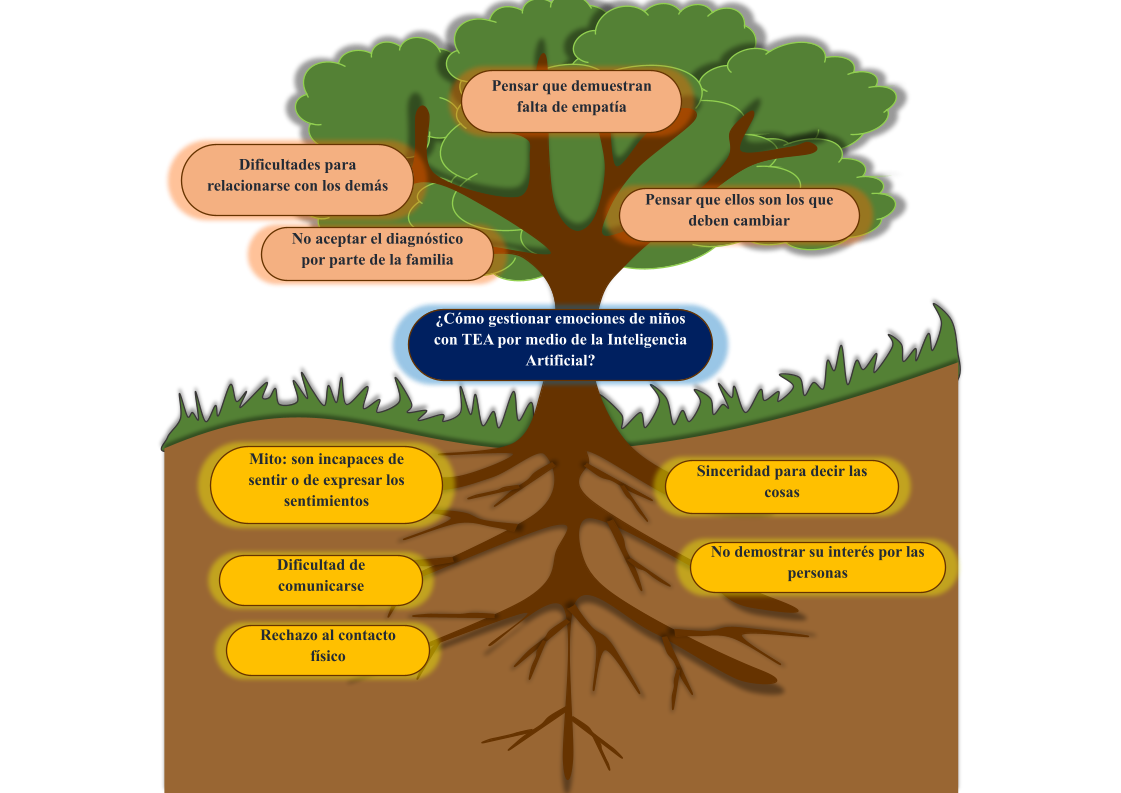
Originalmente se propuso el tema “Chatbot para la gestión de emociones de niños autistas”, obteniendo el primer árbol de problemas (Fig. 1), luego, se puso en marcha la estrategia de búsqueda de literatura que permita definir el alcance a la propuesta, se encontró 27 artículos científicos vinculados a esa línea base (ver Tabla 1).
La literatura científica permitió conocer y comprender lo que se ha hecho y lo que se puede hacer en temas con el autismo, con ello se concluyó que el tema es muy amplio y con mucho futuro de trabajo para proyectos vinculados a la parte informática con un fin social. Además, se identificó que no existe un conjunto de datos de acceso libre que sirva como punto de partida para el tema planteado.
Otro punto clave, fue hacer búsquedas en grupos afines al tema del autismo, tanto en redes sociales como en la Web, con ello se observó que es un tema muy delicado y complejo, desde el punto de vista de los que conviven con el autismo, o los que no lo hacemos. Posiblemente es un tema que no ha tenido una visibilidad y democratización que permita, definir políticas para apoyar y educar a todos los que nos relacionamos con personas con autismo, sea de manera directa o indirecta. Con esto, se necesitó acudir con los profesionales o especialistas en campo, para despejar muchas dudas surgidas por la exploración preliminar, y con ello ver la viabilidad de la propuesta.
En el camino surgieron nuevas pistas, se encontró un conjunto de datos en Kaggle (https://www.kaggle.com/gpiosenka/autistic-children-data-set-traintestvalidate), relacionado con el autismo, que ha sido utilizado para construir algunos modelos que permiten por medio de la visión por computador predecir por medio de una fotografía si un niño tiene o no autismo. Con ello, cambió la perspectiva del proyecto, de pasar de las emociones (sin un conjunto de datos) al reconocimiento facial (con un conjunto de datos) en el mismo ámbito del autismo.
Para seguir en línea de conocer la opinión profesional sobre la propuesta, se realizó dos entrevistas, la primera con la especialista Amparito Morales, a la cual, se le presentó nuestra nueva idea, de que por medio de la tecnología se podía ayudar a mejorar en los diagnósticos en el área del autismo, inicialmente, se tuvo resistencia en el uso de la tecnología, pero eso fue bueno, porque permitió como equipo, convencer a la profesional de la utilidad real en escenario como en los grandes colegios o escuelas, en dónde el trabajo de los pocos especialistas (Departamento de Consejería Estudiantil (DECE)) puede ser apoyado por una herramienta que apoye en las tareas de automatización, en este caso, reconociendo cuáles de los niños por medio de una fotografía podría tener su atención prioritaria en la detección temprana del autismo.
De la primera entrevista surgió la segunda, con la reconocida investigadora Catalina López, pionera en el Ecuador por su enfoque senso-perceptivo para identificar los perfiles de autismo de acuerdo a la idiosincrasia de un país.
Actualmente, se encuentra terminando una herramienta de tamizaje orientado para niños y adolescentes de 4 a 17 años (características para alerta al diagnóstico clínico), además, durante la entrevista, Catalina López, validó la idea del proyecto, agregándole nuevas ideas vinculadas con las tecnologías, y que han surgido de sus investigaciones, como por ejemplo, realidad virtual para aplicar las herramientas de tamizaje, automatización de la herramienta de tamizaje considerando la protección de datos, privacidad, anonimato, confidencialidad, código de ética bajo principios mundiales, consentimiento informado, entre otros.
Finalmente, la investigadora propuso que un chatbot mediante la interacción sea por voz o texto, permitiría identificar patrones de comportamiento y el tema de emociones. Esta entrevista, fijó el trabajo o líneas futuras que se derivan del proyecto, centrándo el tema de reconocimiento fácil y una herramienta de tamizaje (Fig. 3), como el límite para la propuesta final del proyecto DETECTAA-AI, con la que se trabajó en el Saturdays AI.
Contexto
Los trastornos del desarrollo, técnicamente conocidos como trastornos del neurodesarrollo, son trastornos con base neurológica que pueden afectar la adquisición, retención o aplicación de habilidades específicas o conjuntos de información. Consisten en alteraciones en la atención, la memoria, la percepción, el lenguaje, la resolución de problemas o la interacción social. Estos trastornos pueden ser leves y fácilmente abordables con intervenciones conductuales y educativas o más graves, de modo que los niños afectados requieran un apoyo educativo particular. Entre los trastornos del neurodesarrollo tenemos: trastorno de déficit de atención/hiperactividad, trastornos del espectro autista, dificultades del aprendizaje, como la dislexia y las deficiencias en otras áreas académicas, discapacidad intelectual, síndrome de Rett.
“El autismo es un trastorno neurológico complejo que generalmente dura toda la vida. Es parte de un grupo de trastornos conocidos como trastornos del espectro autista (TEA). Actualmente se diagnostica con autismo a 1 de cada 68 individuos y a 1 de cada 42 niños varones, haciéndolo más común que los casos de cáncer, diabetes y SIDA pediátricos combinados. Se presenta en cualquier grupo racial, étnico y social, y es cuatro veces más frecuente en los niños que en las niñas. El autismo daña la capacidad de una persona para comunicarse y relacionarse con otros. También, está asociado con rutinas y comportamientos repetitivos, tales como arreglar objetos obsesivamente o seguir rutinas muy específicas. Los síntomas pueden oscilar desde leves hasta muy severos” [1].
El autismo en Ecuador
De acuerdo a la especialista Catalina López, se tiene los siguientes avances:
- Estudio piloto para la validación concurrente del Cuestionario de comunicación social (SCQ), como instrumento de cribado para la detección del espectro autista en una muestra de población ecuatoriana de 0 a 12 años (2016). Reporte Técnico.
- Autismo en Ecuador: un Grupo Social en Espera de Atención (2017). Artículo en Revista.
- Estudio comparativo de las concepciones acerca del autismo, desde la perspectiva de las neurociencias y la neurodiversidad (2019). Reporte Técnico.
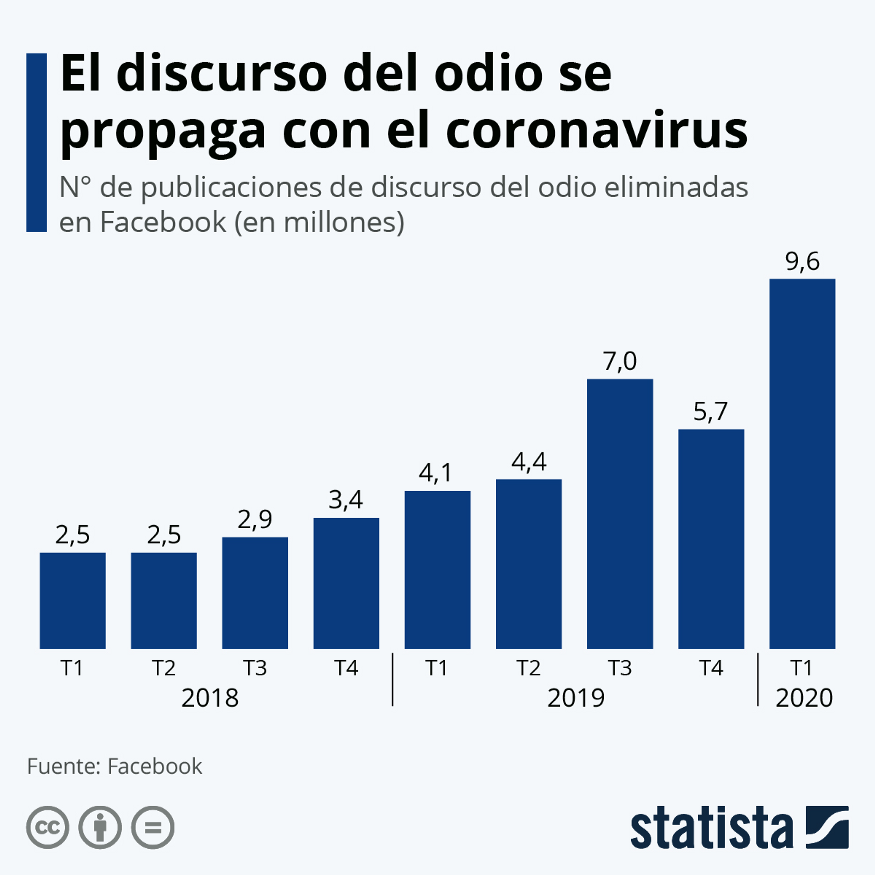
A nivel mundial se estima que el 1% puede estar dentro del TEA, según la Organización Mundial de la Salud, en 2018 se reportaron 1.521 en Ecuador, y aproximadamente un 13,75% se tiene diagnósticos erróneos.
¿Cuál es el problema?
El personal que labora en los departamentos de consejería estudiantil de las unidades educativas (DECE) debe realizar evaluaciones para determinar los alumnos que pudiesen presentar problemas de comportamiento. Debido a la gran cantidad de estudiantes asignados a cada profesional de estos departamentos, el proceso de evaluación consume la mayor cantidad de tiempo disponible por este personal, dejando muy pocos recursos para profundizar el diagnóstico y apoyo a los niños que realmente presentan trastornos del desarrollo. En la Fig. 4 se observa el árbol de problemas, que se lo obtuvo, previa lluvia de ideas, lectura de la literatura y luego de las entrevistas.

¿Cómo lo pensamos resolver?
Se desarrollará una aplicación Web formada por dos componentes (Fig. 3).
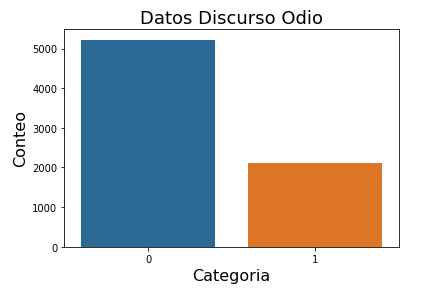
El primer componente ayudará a predecir qué estudiantes pueden o no tener el TEA basado en una imagen fotográfica (tipo tamaño carné) por medio de visión por computador. Los rasgos que se determinen dependen de las bases de datos disponibles. En una primera fase se utilizará la base de datos disponible en Kaggle (https://www.kaggle.com/gpiosenka/autistic-children-data-set-traintestvalidate) para detección facial de TEA, considerando definir un proceso de entrenamiento del sistema que permita detectar nuevos factores de comportamiento a medida que se disponga de bases de imágenes adicionales.
Técnicamente, el tamizaje corresponde a la aplicación de un test o procedimiento a personas “asintomáticas”, con el objetivo de separarlos en dos grupos; aquellos que tienen una condición que podría beneficiarse de una intervención temprana; y aquellos que no.
El segundo componente realizará un tamizaje, usando el test MCHAT, y que sea la base para en el futuro implementar el procesamiento de lenguaje natural (chatbot de preguntas y respuestas).
¿Cómo se vincula el proyecto con los objetivos de desarrollo sustentables?
Se vincula con dos objetivos:
Primero, con el de Salud y bienestar (ODS 3), meta: reforzar la capacidad de todos los países, en particular los países en desarrollo, en materia de alerta temprana, reducción de riesgos y gestión de los riesgos para la salud nacional y mundial.
Segundo, con la Reducción de las desigualdades (ODS 10), meta: el avance en la reducción de la desigualdad, tanto dentro de los países como entre ellos, ha sido desigual. Todavía se debe dar más peso a la opinión de los países en desarrollo en los foros decisorios de las instituciones económicas y financieras internacionales. Además, si bien las remesas pueden ser un medio de supervivencia para las familias y las comunidades de los trabajadores migrantes internacionales en sus países de origen, el elevado costo de transferir dinero sigue reduciendo los beneficios.
¿Cuál es la hipótesis del proyecto?
El uso de la Inteligencia Artificial permitirá crear un prototipo que permita apoyar al diagnóstico presuntivo de trastornos del desarrollo en niños de edad escolar.
¿Cuál es la población objetivo?
- Niños de 0 a 12 años
- Padres, madres, cuidadores
- Educadores
- Especialistas de los DECE
- Investigadores
¿Qué nos dice la literatura científica sobre proyectos relacionados con el reconocimiento facial?
La literatura científica que soporta nuestro proyecto se resume en la Tabla 2.
¿Qué es la visión por computador?
Es un campo de la Inteligencia Artificial enfocado a que las computadoras puedan extraer información a partir de imágenes, ofreciendo soluciones a problemas del mundo real (Fig. 5).
¿Qué áreas del conocimiento se vinculan?
- Ciencias de la Salud (Salud Mental).
- Ciencias de la Computación (Inteligencia Artificial, Visión por Computador).
Metodología
La metodología que se utilizó fue Desing Thinking, en la Fig. 6 se observa un resumen de cada una de las etapas desarrolladas.
En la Fig. 7, se tiene un lienzo de trabajo proporcionado por https://www.analogolab.co/, para poner en marcha los principios de la metodología Desing Thinking. En este enlace Web, se observa el diseño completo del proyecto.
Resultados
Arquitectura
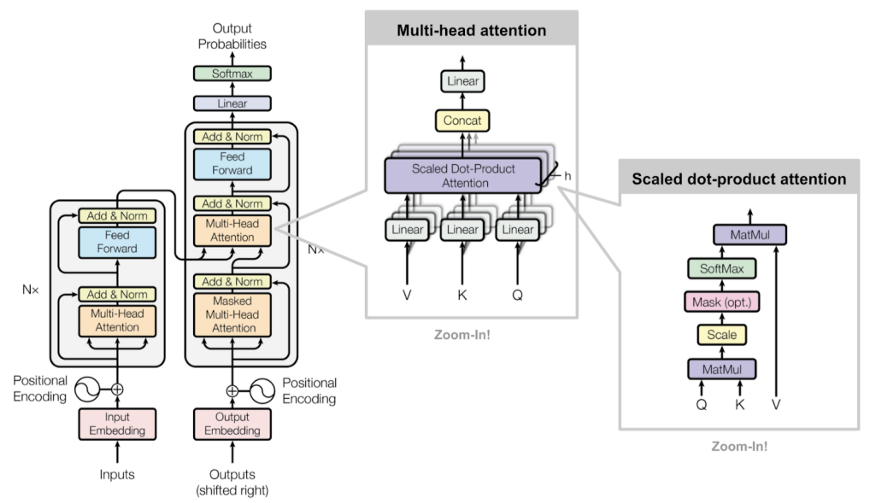
La arquitectura del proyecto está dividida en una aplicación de Frontend y una aplicación de Backend (ver Fig. 8). El Frontend, desarrollado con Flask (Framework de Python), contiene todas las interfaces con las cuales el usuario final interactúa. Esta, a su vez, se conecta mediante un endpoint al Backend. En el Backend se encuentra una API, desarrollada con Flask, que contiene un modelo de Deep Learning entrenado con librerías de TensorFlow y un conjunto de imágenes obtenidas desde Kaggle. El Frontend también interactúa con un modelo entrenado en Teachable Machine (una plataforma de Google para entrenar modelos de machine learning de forma rápida y fácil).
Enlaces Web a las API y a la aplicación de DETECTAA-AI:
- Teachable Machine: https://teachablemachine.withgoogle.com/models/5O0q09n5c/
- API Modelo Tensorflow: https://reconocimientoteaapi.herokuapp.com/
- FrontEnd: https://detectai.herokuapp.com/
Flujo de trabajo de DETECTAA-AI
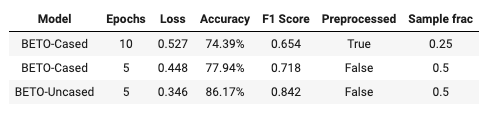
Los resultados obtenidos para el primer caso (niño con TEA) son bastante favorables, ya que tanto los modelos como el cuestionario dan un porcentaje alto de detección de TEA en la persona evaluada, tal como se muestra en la Fig. 9.
Los resultados del segundo caso (niña sin TEA), presentan porcentajes aceptables en el diagnóstico de TEA. Tal como muestra la Fig. 10, los resultados obtenidos fueron: Teachable Machine: 100%, TensorFlow: 85.28% y M-Chat: Riesgo Bajo.
En el tercer caso (niño sin TEA) los resultados obtenidos de los modelos y M-chat reflejan resultados diferentes, ya que los modelos de machine learning devuelven diagnósticos acertados en cuanto a la prueba realizada, sin embargo, el M-chat retorna un Riesgo alto de tener un diagnóstico de TEA, como se muestra en la Fig. 11.
Conclusiones
Con el desarrollo del proyecto DETECTAA-AI se llegó a las siguientes conclusiones:
- Es posible detectar indicios de TEA en las personas mediante el uso de modelos de inteligencia artificial.
- Para que un modelo tenga una tasa de confiabilidad más alta, es necesario una mayor cantidad de imágenes de entrenamiento y mejor procesamiento de esa información.
- Los algoritmos de inteligencia artificial sirven como un apoyo a los profesionales de la salud, más no como un reemplazo.
- Es necesario un vínculo entre la academia, estado, empresas, gremios, sociedades, para que estas iniciativas se puedan poner en marcha de acuerdo al contexto Ecuatoriano.
- Combinar la investigación científica a procesos profesionales, permite construir prototipos escalables en el tiempo.
- El prototipo DETECTAA-AI, debe usarse con fines académicos y de investigación, como ejemplo de prueba de concepto, y no para ofrecerla como herramienta de diagnóstico final, ya que se necesita un equipo de profesionales que aporten en la detección del TEA.
Líneas futuras
- Implementar la herramienta de tamizaje con NLP, de tipo de preguntas y respuestas, utilizando el cuestionario propuesto por la Dra. Catalina López en el contexto Ecuatoriano, considerando la privacidad, protección de datos, entre otros.
- Obtener una base de datos propia de imágenes en el contexto de Ecuador, para realizar pruebas al prototipo DETECTAA-AI.
- Es recomendable aumentar una tercera herramienta de detección de TEA por NLP, el cual permita detectar presencia de tea mediante el análisis de patrones en la voz de la persona que se requiera diagnosticar.
- Concientizar a la población que la tecnología puede ser un apoyo muy importante en el contexto de la Salud.
Recursos del proyecto DETECTAA-AI
- Página de Teachable Machine: https://teachablemachine.withgoogle.com/
- Dataset De imágenes de entrenamiento y pruebas: https://www.kaggle.com/gpiosenka/autistic-children-data-set-traintestvalidate
- Repositorio GitHub: https://github.com/detectaai
- Link API: reconocimientoteaapi.herokuapp.com
- Link Aplicación Final: https://detectai.herokuapp.com/
Referencias
[1] https://www.uasb.edu.ec/reconocimiento-a-la-directora-del-area-de-salud-catalina-lopez-id1550289/
Presentación del proyecto: DemoDay
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!Saturdays.AI
WRITTEN BY
Luis Chamba-Eras
Profesor e investigador de la Universidad Nacional de Loja. Investigación en Inteligencia Artificial en Educación.

Saturdays.AI
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.