Adentrarse en el mundo de la Inteligencia Artificial (IA) puede ser un viaje fascinante y revelador. La IA, un campo en constante evolución, está redefiniendo el futuro de la tecnología y la sociedad. Si buscas iniciarte en este dominio desde los fundamentos hasta sus aplicaciones más avanzadas, estás en el lugar perfecto. En este blog, descubrirás los libros esenciales sobre la inteligencia artificial.
Libros sobre Historia y Ética de la Inteligencia Artificial
Antes de sumergirnos en los aspectos técnicos, es esencial comprender la historia y la ética que rodean a la IA. Exploraremos 3 libros que te proporcionarán una base sólida en estos aspectos clave:
1- Para una comprensión profunda y filosófica de la inteligencia artificial (IA), el libro ‘Inteligencia Artificial: Una Introducción Filosófica‘ de Jack Copeland es una lectura imprescindible. Publicado en 1993 y manteniéndose relevante hasta hoy, este trabajo pionero ofrece una visión completa de la historia de la IA y sus conceptos fundamentales. Copeland examina meticulosamente la evolución de la IA, proporcionando una perspectiva amplia tanto de su desarrollo histórico como de sus aspectos filosóficos.
Este libro es una fuente valiosa para aquellos interesados en las cuestiones éticas y teóricas de la IA, explorando a fondo sus impactos tecnológicos y sociales. Es ideal para estudiantes, profesionales y cualquier persona fascinada por la IA, ofreciendo análisis detallados y reflexiones sobre cómo la inteligencia artificial no solo funciona, sino que también influye en nuestra sociedad y filosofía. ‘Inteligencia Artificial: Una Introducción Filosófica’ es una guía esencial para entender las complejidades y las implicaciones de la IA en el mundo moderno.
2- Descubre en ‘El Enemigo Conoce el Sistema‘ de Marta Peirano, una exploración detallada y perspicaz sobre cómo la tecnología está remodelando nuestra sociedad. Marta Peirano, experta en tecnología y sociedad, te lleva en un viaje desde los albores de la informática hasta los desafíos actuales de la era digital y la vigilancia. Este libro se destaca por su enfoque crítico y accesible, proporcionando una visión única de la compleja red de intereses y poder detrás de las tecnologías cotidianas.
Peirano desvela con maestría cómo las prácticas digitales impactan nuestra vida diaria y nuestras libertades. Con un análisis profundo y comprometido, ‘El Enemigo Conoce el Sistema’ es más que un libro: es una guía esencial para entender las implicaciones éticas y políticas de nuestra interacción con la tecnología. Perfecto para lectores interesados en el impacto de la tecnología en la sociedad, la privacidad en línea y la seguridad digital. Sumérgete en esta lectura esencial para estar al día con los desafíos tecnológicos del siglo XXI.
3- El libro ‘El algoritmo ético‘ de Michael Kearns y Aaron Roth aborda dos preocupaciones principales en el campo de la IA: cómo los algoritmos pueden funcionar incorrectamente y las consecuencias de su funcionamiento óptimo. Kearns y Roth profundizan en temas críticos como los sesgos algorítmicos, ofreciendo un análisis analítico y práctico para medir y diseñar algoritmos con criterios éticos.
Lo destacable de ‘El algoritmo ético’ es su equilibrio entre lo práctico y lo cuantitativo, presentando estos conceptos complejos de una manera accesible sin ser excesivamente técnico. El libro te guía a través del análisis y la quantificació de los algoritmos, enfatizando la importancia de tomar decisiones conscientes en su diseño. Es una lectura ideal para aquellos interesados en comprender cómo los algoritmos afectan nuestra sociedad y cómo podemos diseñarlos de manera responsable y ética.
Aprende las Diferentes Partes que Forman la IA
La IA es un campo extenso que incluye diversas áreas interrelacionadas, cada una con su propia especialidad y contribución al avance de la tecnología inteligente. Para cada una de estas áreas, recomendamos un libro específico que te ayudará a comprender y profundizar desde un nivel básico:
1. Aprendizaje Automático (Machine Learning) es el núcleo de la IA moderna, donde las máquinas aprenden de los datos utilizando algoritmos estadísticos para mejorar su rendimiento en tareas específicas con el tiempo. Para profundizar en este campo, «Aprende Machine Learning con Scikit-Learn, Keras y TensorFlow» de Aurélien Géron ofrece una introducción completa.
2. Aprendizaje Profundo (Deep Learning), una especialización del aprendizaje automático, emplea redes neuronales profundas para aprender patrones en grandes volúmenes de datos, siendo fundamental en áreas como la visión por computadora y el procesamiento de lenguaje natural. «Deep Learning: teoría y aplicaciones» de Jesús Alfonso López es una guía esencial para explorar este campo.
3. Procesamiento de Lenguaje Natural (NLP) permite a las máquinas interpretar y responder al lenguaje humano, siendo clave para el desarrollo de asistentes virtuales y herramientas de traducción automática. Sumérgete en el vanguardista mundo del Procesamiento de Lenguaje Natural (NLP) con ‘Transformers en Procesamiento de Lenguaje Natural‘. Un libro esencial para entender cómo los modelos Transformer están remodelando el campo de la Inteligencia Artificial. Ideal para estudiantes y profesionales, este texto ofrece una comprensión detallada de las técnicas más avanzadas en NLP, mezclando teoría con aplicaciones prácticas. Un recurso indispensable para mantenerse al día en las últimas innovaciones y desarrollos en procesamiento de lenguaje y IA
4. Robótica integra la IA con la ingeniería para crear robots capaces de realizar tareas complejas. «Introducción a la Robótica» de Phillip John McKerrow es una lectura recomendada para adentrarse en esta fascinante intersección entre la IA y la robótica.
5. La Visión por Computadora otorga a las máquinas la habilidad de «ver» e interpretar información visual. «Aprendizaje Profundo» de los autores: Gonzalo Pajares Martinsanz, Pedro Javier Herrera Caro, Eva Besada Portas. Este libro se enfoca en el uso del aprendizaje profundo en el campo de la visión por computadora, ofreciendo una perspectiva actualizada y en línea con las últimas tendencias y tecnologías en este campo. Cubre temas desde los fundamentos del aprendizaje profundo hasta su aplicación en tareas específicas de visión por computadora, como el reconocimiento de imágenes, la detección de objetos y más.
6. Los Sistemas Expertos imitan la toma de decisiones humanas en campos específicos utilizando conocimientos y reglas lógicas. «El diseño de sistemas expertos en IA utilizando PRÓLOGO«. Este libro es una guía esencial para diseñar sistemas expertos en inteligencia artificial, destacando la combinación de aprendizaje automático con IA basada en reglas. Explora aplicaciones prácticas en automóviles autónomos y el juego de Go, y proporciona detalles y ejemplos para representación de conocimiento y algoritmos de razonamiento
7. Las Redes Neuronales Artificiales (ANN), inspiradas en el cerebro humano, son esenciales en el aprendizaje automático y el aprendizaje profundo para reconocer patrones y tomar decisiones. «Redes Neuronales: Guia Sencilla de Redes Neuronales Artificiales» te enseñara acerca de las redes neuronales artificiales y a entender cómo estas funcionan en general.
8. Aprendizaje por Refuerzo (Reinforcement Learning) se centra en cómo los agentes aprenden a tomar decisiones optimizando recompensas. Te recomendamos el libro de Jordi Torres: «Introducción al aprendizaje por refuerzo profundo: Teoría y práctica«. Debido a la complejidad del aprendizaje por refuerzo y a la falta de manuales sobre el tema, a menudo existen dificultades a la hora de establecer una ruta adecuada para empezar, ya que no resulta sencillo saltar la barrera de entrada a este apasionante campo de innovación. El objetivo del libro recomendado es ser una guía de iniciación para quienes quieran conocer los fundamentos teóricos del área.
Cada uno de estos componentes contribuye a la evolución y el progreso de la IA, abriendo un mundo de posibilidades y desafíos. Estos libros son puertas de entrada para explorar cada área, brindando tanto a principiantes como a profesionales las herramientas necesarias para comprender y participar en este emocionante campo.
Para seguir aprendiendo sobre Inteligencia Artificial (IA)
La Inteligencia Artificial (IA) está revolucionando el periodismo, ofreciendo herramientas avanzadas que optimizan la redacción y edición de contenido. Esta tecnología no sólo acelera el proceso editorial, sino que también eleva la precisión y fiabilidad del periodismo. Con la verificación de hechos en tiempo real y la mejora de la calidad de escritura, la IA se convierte en un aliado clave en la lucha contra la desinformación y las noticias falsas. Su integración en las salas de redacción modernas garantiza una entrega de noticias más rápida y una información de calidad que los lectores pueden confiar.
Periodista usando herramientas de inteligencia artificial que le ayudan a hacer más fácil su trabajo
Herramientas de inteligencia artificial que debes utilizar como periodista
La Inteligencia Artificial está ayudando a los periodistas a trabajar más rápido y con mayor precisión. Estas herramientas de IA son muy útiles, ya que ofrecen consejos para escribir mejor, corrigen la gramática y verifican los hechos al momento.
El objetivo principal de escribir noticias es compartir información de forma clara y correcta. La Inteligencia Artificial ayuda a los periodistas dándoles consejos instantáneos para escribir mejor y más claro. Herramientas como Grammarly o Hemingway Editor ofrecen ayuda en el momento para que la escritura sea más directa y comprensible.
La Inteligencia Artificial también es muy buena corrigiendo la gramática. A veces, los periodistas no ven pequeños errores por la prisa o por tener que actualizar constantemente sus artículos. Pero las herramientas de IA como Language Tool pueden encontrar y arreglar estos errores rápido, para que los textos sean de alta calidad antes de que se publiquen.
Verificar que lo que se dice es muy importante para que las noticias sean confiables. Programas de IA como Newtral o Snopes ayudan a los periodistas a comprobar los datos rápidamente antes de difundir una noticia. Esto no solo hace que la información sea más precisa, sino que también ayuda a luchar contra las noticias falsas, que son un problema grande hoy en día.
Redacción de noticias futurista
Conclusión
La Inteligencia Artificial no busca reemplazar a los periodistas, sino fortalecer su labor, permitiendo que se enfoquen en lo que mejor hacen: investigar, analizar y contar historias que importan. En un mundo inundado de información, la IA se presenta como una herramienta poderosa para asegurar la calidad, precisión y rapidez en el periodismo contemporáneo.
Información acerca de Saturdays.ai
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible #ai4all mediante cursos y programas intensivos donde se realizan proyectos para el bien #ai4good. También realizamos proyectos y consultoría para organizaciones que quieren sacar el máximo partido de la IA.
Si como nosotros te gusta la tecnología, hazte miembro premium de Saturdays y podrás aprovechar todos los beneficios de una comunidad líder en Inteligencia Artificial: https://saturdays.ai/become-a-member
En nuestra web tienes cursos online gratuitos y contenido para ayudarte, así como una comunidad de personas apasionadas como tú, ¡te esperamos!
La ingeniería de prompts es un proceso esencial para mejorar la interacción con los modelos de lenguaje de inteligencia artificial (IA). Este artículo explora la historia, las técnicas y las aplicaciones de la ingeniería de prompts, así como los desafíos técnicos y éticos que plantea.
Descubre cómo la IA está transformando nuestro mundo, desde la detección temprana de enfermedades hasta la lucha contra el cambio climático, yendo más allá de los chatbots y los algoritmos que comúnmente conocemos.
El mercado laboral que todos conocemos se desarrolla sobre un esquema a modo de dos grandes tablones de anuncios, uno frente al otro: el primero con los que ofrecen puestos de trabajo y el segundo con quienes los demandan. Y en muchas ocasiones es el segundo el que se adapta al primero.
Pero creemos que esto tiene que cambiar. Más que un encuentro en el que la mayor parte de las veces se elige por eliminación, las relaciones laborales deberían de parecerse un poco más a las personales, al menos en sus planteamientos iniciales. En las apps de contactos, hay que aportar muchos datos acerca de quiénes somos y también de lo que buscamos. De allí surgen candidatos y con eso se busca el MATCH por ambas partes.
No es cuestión de enamorarse a primera vista, pero sí creemos que es bueno conocer más en profundidad en qué consisten las ofertas de trabajo. Son datos públicos que nos pueden contar aspectos importantísimos tanto de la empresa, como del territorio donde están asentadas. Los requisitos que piden a sus futuros trabajadores y su análisis pueden ayudar tanto a las personas que buscan empleo, como al sector de la educación o a los gobiernos e instituciones de cara a prever situaciones de déficit o superávit en alguno de ellos. En una economía interdependiente y globalizada como la que vivimos, ofrecer un excelente comportamiento del flujo de la mano de obra puede ayudar a asentar empresas, y ser un buen apoyo para la economía y la toma de decisiones.
En el caso de Aragón, la situación se complica en lugares como Teruel, al aplicarse el factor de la despoblación en muchas zonas. Insistiendo en la misma idea que el objetivo de nuestro trabajo, la consejera de Presidencia de Aragón, Mayte Pérez en una reunión en Teruel comentó hace unos días la importancia de generar “foros y sinergias para adelantarnos a las necesidades de empleo que van a surgir. Debemos analizar el mercado laboral hoy, pero ver también las expectativas de futuro que tiene la provincia para acompañarlas de una oferta formativa cualificada” [1].
Figura 1: Elconfidencial.com 15/12/2021.
Figura 2: La Comarca 27/01/2022.
Las empresas de construcción, tanto de obra pública como civil, ya alertaron en otoño de la carencia de mano de obra para su sector, lo que podría ocasionar problemas.
Figura 3: El Periódico de Aragón 11/09/2021.
Figura 4: Heraldo de Aragón 05/07/2021.
Y no sólo la construcción.
Figura 5: Heraldo de Aragón 10/10/2021.
Se cifra ya en 30.000 millones de euros anuales las pérdidas por la falta de mano de obra en Europa [2].
Frente a estos datos, los del paro. En Aragón hay más de 61.000 personas en desempleo. La mayor parte, más de 42.000, son del sector servicios. Pero en el sector de la construcción hay 3.871 trabajadores en paro, en industria 7.000 y en agricultura y ganadería, 3.624. A todos ellos se suman más de 4.500 personas sin empleo anterior.
¿Por qué hay desempleo en un sector cuando hay más demanda? ¿las personas que están en el paro en ese sector no cumplen los requisitos? ¿no acceden a las ofertas por no estar en la misma población en la que se publican?
Se plantean muchos interrogantes, y muchos más cuando las empresas e instituciones planifican la actividad de aquí a los próximos diez años, para recuperar el parón que ha supuesto el COVID y ya marcan las necesidades de mano de obra que van a tener.
Figura 6: La Voz de Galicia 16/10/2021.
Problema
Nos enfocamos en el siguiente problema: ¿Cómo podríamos facilitar el análisis de las ofertas de empleo en Aragón para brindar a sus ciudadanos conclusiones relevantes?¿Cómo podemos ayudar a las empresas a encontrar mano de obra que se ajuste a sus necesidades?¿Pueden las instituciones planificar oferta y demanda de empleo conociendo mucho más el mercado laboral?
Tanto el problema identificado como el proyecto desarrollado están enmarcados en el ODS 8 (Objetivo de Desarrollo Sostenible) de trabajo decente y crecimiento económico [3], y está motivado por la carencia de herramientas que faciliten a los aragoneses estudiar en términos globales la situación actual de las ofertas de empleo en Aragón.
Objetivo general
Para resolver el problema identificado nos planteamos como objetivo general: Desarrollar una herramienta basada en técnicas de Procesamiento del Lenguaje Natural que facilite analizar las ofertas de empleo disponibles en Aragón a partir de diferentes criterios (sector, provincia, ciudad, oficina del INAEM, fechas, etc.) Su utilidad puede ser de interés para empresas, instituciones, planificación educativa, estudiantes, desempleados, empresas de formación, etc…
Con el propósito de cumplir con el objetivo planteado y llevar a cabo el proyecto de manera organizada, seguimos la metodología CRISP-DM (Cross-Industry Standard Process for Data Mining) [4], orientada a trabajos de Minería de Datos, que en nuestro caso se enfoca específicamente en técnicas básicas de Procesamiento del Lenguaje Natural (PLN) [11]. En la siguiente figura se presentan las diferentes fases que abarca la metodología.
Al iniciar el planteamiento de nuestra propuesta, consideramos estudiar el ámbito laboral en Aragón al completo, oferta y demanda. Para la oferta vimos que podíamos contar con el Instituto Aragonés de Empleo, INAEM [5], que de lunes a viernes facilita un PDF con las ofertas de empleo disponibles esa jornada en todo el territorio, distribuídas en 28 sectores productivos.
También planteamos usar Infojobs, pero la información que se facilita allí no se encuentra tan bien clasificada. Además, Infojobs aporta unos tipos de trabajo determinados. No suelen ser empleos de alta formación y sueldos elevados, lo que sesgaría las características del estudio.
Para la demanda pensamos en LinkedIn, que sí ofrece mucha información y buena indexación. Pero no todos los miembros de la comunidad LinkedIn buscan trabajo. Con lo cual quedaba descartado. Lo mismo sucedió con los demandantes de trabajo en Infojobs u otras páginas similares como Milanuncios.com. Suelen ser perfiles con urgencia en trabajar, que daría para otro estudio, quizá de carácter social, pero no en la línea que nosotras planteamos.
Por este motivo, decidimos acudir a la base, y crear un sistema capaz de interpretar la oferta diaria de puestos de trabajo en la comunidad autónoma de Aragón, e intentar sacar de allí el máximo partido al modelo de ficha con los datos básicos que encontramos en cada uno de los empleos que allí se anuncian. Hay también que tener en cuenta que el INAEM gestiona buena parte de los puestos de trabajo que salen al mercado laboral en Aragón, pero no el 100%. Por ello nuestras conclusiones, no podrán ser en ningún caso estrechamente ajustadas a la realidad, sino que se convierten en tendencias, aproximaciones y evoluciones cercanas a la oferta de empleo real.
El conjunto de datos que se obtuvo fue el resultado de analizar, extraer y preprocesar un conjunto de esos documentos PDF disponibles en el portal de INAEM [5], y también incorporando la información que aparece en la propia página web del INAEM, en el rango de fechas del 2021 hasta principios de marzo de 2022. En total 1152 ofertas de trabajo. Se distribuyen por sectores profesionales en Aragón (ver Figura 8). Cada oferta de empleo se divide en dos bloques. Uno más breve y esquemático con el título, provincia, ciudad, código, fecha de publicación y oficina. El segundo bloque es el de la descripción. Dentro de ella se obtiene información sobre las tareas a desempeñar, requisitos solicitados por la empresa, condiciones de trabajo, trámites y plazos, entre otras.
Figura 8: Ejemplo de una oferta de trabajo que encontramos en el documento PDF del INAEM.
Durante el proceso de extracción de la información textual desde los documentos de PDF se utilizó la librería de Python Tika [6]. El texto resultante de la extracción por cada documento PDF fue separado por sectores profesionales y luego por ofertas de empleo. De cada oferta, se extrajeron los textos de mayor interés a analizar (“sector”, “identificador de la oferta”, “fecha de publicación”, “título de la oferta”, “ciudad”, “provincia”, “oficina del INAEM”, “descripción global”, “descripción específica”, “tareas a desempeñar”, “requisitos solicitados por la empresa”, y “condiciones de trabajo”). Para ello, aplicamos expresiones regulares [7], también conocidas como regex por su contracción de las palabras inglesas regular expression, que no es más que una secuencia de caracteres que conforma un patrón de búsqueda sobre los textos. En la siguiente figura se puede ver un ejemplo para encontrar las “fechas de publicación” dentro de los textos de las ofertas.
A primera vista parecen tablas de datos con una pauta similar y un orden concreto. Pero lo cierto es que en la práctica se constata que no es así. Cada oficina tiene sus usos y costumbres, lo que dificulta el tratamiento de los datos. Por ejemplo, unas escriben las poblaciones con mayúsculas, y otras sólo la inicial va en mayúscula. Eso hace que se identifique como dos poblaciones distintas si vemos una oferta en BARBASTRO y otra en Barbastro, también se pueden diferenciar por los acentos (por ejemplo, Sabiñánigo y Sabiñanigo) o porque simplemente están mal escritas (por ejemplo, concinero en vez de cocinero, grú para referirse a grúa, etc.). También hay ofertas de trabajo duplicadas, y en cuanto a las características de la descripción global de la oferta, en algunas oficinas las detallan como “Requisitos” y en otras como “Tareas”,entre otras diferencias. Incluso algunas oficinas no ponen etiquetas que separen los distintos conceptos dentro de la descripción, lo que impide aplicar el modelo.
Ejemplo 1.- Lleva las etiquetas de TAREAS, REQUISITOS, CONDICIONES
Ejemplo 2.- Sin etiquetas ni separación. Únicamente aparece “Funciones” sin mayúscula ni negrita
En la fase de análisis y verificación de la calidad de los datos extraídos, identificamos este conjunto de problemas, que fueron tratados para su posterior explotación desde el dashboard: eliminamos ofertas de trabajo duplicadas (asegurando tener un identificador único por oferta), corrigiendo nombre de ofertas, ciudades, provincias, oficinas de empleo, y descripciones mal escritas a partir de diccionarios. También hemos tenido que unificar los textos que significan lo mismo para diferentes características.
Con el propósito de extraer información complementaria a la obtenida desde los documentos PDF, aplicamos en paralelo la técnica de web scraping al buscador de ofertas de empleo en Aragón de INAEM [5], como es el caso del “nivel profesional”, “requerimientos” y “duración del contrato” de las ofertas de empleo, que sólamente aparecían en la web. Adicionalmente, el web scraping permitió completar valores vacíos que no se consiguieron extraer desde los documentos PDF, tales como las “descripciones generales”, “condiciones de trabajo”, nombres de “ciudades” y “provincias”, al estar tanto en la web como en los documentos PDF. Tal vez el web scraping hubiera sido suficiente para tener una primera versión de los datos relacionados con las ofertas de empleo de INAEM, pero los campos “sector” y “oficina de empleo” de cada una de las ofertas sólo estaban presentes en los documentos PDF, los cuales considerábamos muy importantes para estudiar desde el dashboard. Por todo lo anterior, hay que resaltar que una gran parte del proyecto fue dedicada a la fase de extracción, análisis, limpieza y homogeneización de la información.
Dashboard de ofertas de empleo en Aragón
Con el propósito de facilitar el análisis de la situación actual de las ofertas de empleo en Aragón, desarrollamos un dashboard haciendo uso de la librería Streamlit [8]. Esta librería de python ofrece una plataforma de código abierto que permite crear y compartir fácilmente aplicaciones web personalizadas para ciencias de datos y aprendizaje automático. El código fuente del dashboard y de la extracción y preprocesamiento textual está disponible en nuestro repositorio de GitHub [9].
El dashboard cuenta con 4 apartados principales que vamos a desarrollar a continuación. Aunque hay más de una veintena de sectores, hemos querido fijarnos sobre todo en el turismo, por ser importante en la economía aragonesa y con requisitos y términos más conocidos para la sociedad:
1.- Estudio de ofertas por criterio:
En este apartado conocemos el número de ofertas que hay según los siguientes criterios de búsqueda: sector, oficina y provincia.
Según el criterio seleccionado se genera una gráfica de barras.
Figura 9: Captura de pantalla de estudio de ofertas por criterio
Análisis:
Con el criterio “Sector” analizamos 24 de los 28 sectores que contempla la página web del Servicio nacional de empleo. Hay 4 sectores que el INAEM o bien no contempla, o bien no existen ofertas de trabajo para ellos. Esos 4 sectores son Información y Manifestaciones artísticas, Minería y primeras transformaciones, Pesca y acuicultura y Piel y cuero. Vemos que los tres ámbitos que más ofertas han presentado desde noviembre a aquí son Turismo y Hostelería (en plena temporada de nieve y con las vacaciones de Navidad), Administración y Oficinas y Edificación y Obras Públicas. Las que menos personal han solicitado en este tiempo son Producción, Transformación y Distribución de Energía, Seguros y finanzas y Artesanía. En esta gráfica en este periodo podemos observar la temporalidad, con mucha demanda en Hostelería (una de las temporadas altas del turismo en Aragón) y con una oferta contenida por ejemplo en Agricultura, ya que en invierno disminuyen las labores del campo.
Con el criterio “Oficina” observamos que con mucha diferencia, la de Zaragoza Ranillas es la que más ofertas de empleo gestiona en toda la comunidad. Le sigue la oficina de Huesca Capital. Zaragoza acumula cinco oficinas de empleo, dos de las cuales, Zaragoza Centro y Zaragoza Compromiso de Caspe, se sitúan las siguientes en el ránking de las cinco primeras, que cerraría la oficina de Teruel Capital. Fuera de las tres capitales provinciales, destaca Sabiñánigo en número de ofertas de trabajo. En esa sucursal se une la oferta industrial de la capital del Alto Gállego, al abundante sector hostelero y turístico del Valle de Tena, que se complementa con construcción y ganadería. En el listado hay una oficina que no corresponde con Aragón. Ello es debido a que desde las oficinas de Castellón y Castelldefels (Barcelona) han lanzado a Aragón unas ofertas buscando esquiladores.
Con el criterio “Provincia” observamos la proporción actual de ofertas que se reparten entre los tres territorios provinciales de Aragón.
2.- Estudio de ofertas por fecha: En este apartado cruzamos varios de los datos que encontramos en las ofertas, para lograr conclusiones más específicas o perfiles más ajustados. Se genera una gráfica de temporalidad, que facilita el análisis del número de ofertas de trabajo combinando diversos criterios, tales como año, sector laboral y provincia.
Figura 10: Captura de pantalla de estudio de ofertas por fecha
Análisis:
Si seleccionamos el criterio “AÑO” podemos obtener sólo uno en concreto, como esta gráfica, correspondiente a 2021 para todo Aragón. Es evidente un pico en las ofertas de trabajo a mediados de diciembre, tras el puente, justo antes de las contrataciones de cara a la campaña navideña.
Para el año 2022 en todo Aragón, vemos escasa oferta en los primeros días, que aún son festivos, y un pico destacado al final del mes de enero. Llama la atención la caída en las ofertas llegado mitad del mes de febrero, que luego se recupera con un nuevo pico demanda de trabajadores a final de mes.
Y podemos unir los dos periodos que tenemos actualmente, 2021 y 2022. En esta gráfica, añadimos el criterio “PROVINCIA” seleccionando la de Zaragoza. Encontramos unas conclusiones similares en estos parámetros, con picos a mitad de diciembre y finales de enero, y una caída de ofertas a mitad de febrero, para encontrar una importante subida a final de este mes.
Analizamos ahora el número de ofertas aplicando el criterio “PROVINCIA” en este caso en la de Huesca para el año 2021 y 2022. Es muy llamativo el pico de ofertas a finales de enero, de cara parece a una contratación a más largo plazo. Destaca también el descenso de empleos propuestos a mitad de febrero.
En cuanto al número de ofertas en Teruel para el año 2021 y 2022, es también muy llamativo el pico a final del mes de enero, y también una caída significativa a mitad de mes de febrero:
Y también se puede analizar aplicando los tres criterios, es decir por cada uno de los sectores/años/provincia.
Por ejemplo, estudiamos aquí el sector TURISMO Y HOSTELERÍA y provincia ZARAGOZA para todos los años. Hay una subida a final del mes de enero, quizá preparando el puente festivo de San Valero o ante la previsión de la eliminación de algunas restricciones de hostelería, que se efectuó a principios de febrero.
En esta otra gráfica, hemos seleccionado el sector de la EDIFICACIÓN Y OBRA PÚBLICA, también en la provincia de Zaragoza, con demanda de trabajadores muy desigual en estos días.
3.-Nube de palabras: Generamos una nube de palabras a partir de los textos que contienen los títulos y descripciones globales de las ofertas laborales, las cuales se pueden filtrar por sector profesional. Adicionalmente, se puede ajustar diferentes parámetros de configuración de la nube de palabras, tales como el color del fondo de la imagen, el color de las palabras más frecuentes, el número máximo de palabras a generar, el tamaño máximo del fondo, y el estado aleatorio para que muestre palabras diferentes por cada valor definido. Por otra parte, permite subir una imagen (de tipo “silhouette”) para generar la nube de palabras con la forma de la figura dibujada en la imagen. Nuestra idea de “conocer es amar” aplicada a este proyecto nos ha animado a darle forma de corazón. Es una herramienta muy valiosa, porque más allá del dato, permite identificar otros conceptos no detectables en un primer análisis sobre las ofertas de empleo. Lo explicamos a continuación.
Figura 11: Captura de pantalla de la nube de palabras.
Para realizar el análisis de los datos exploratorios del PLN [11], utilizamos la librería de Python WordCloud [10]. A partir de esta librería pudimos hacer una representación visual de las palabras (también conocido como nube de palabras) que conforman los textos de los títulos y descripciones globales de las ofertas de trabajo, en donde el tamaño es mayor para aquellas palabras que aparecen con más frecuencia. Las gráficas de nube de palabras, nos permitieron visualizar las palabras claves contenidas en los textos para su posterior estudio. Previo a la representación visual y como parte del procesamiento de datos en lenguaje natural, eliminamos del texto un conjunto de palabras vacías (conocidas como stop words), que son palabras sin significado como artículos, pronombres, preposiciones, etc.
Análisis:
Para la primera nube de palabras que analizamos, hemos seleccionado, por ejemplo, los criterios Oferta + Sector TURISMO Y HOSTELERÍA. Es decir, esta nube de palabras es con el encabezamiento de la Oferta.
En las nubes de palabras, aparecen los términos más usados o habituales dentro del texto. Era de esperar encontrar ‘Camarero’, ‘Cocinero’ o ‘Barra’. Pero encontramos otros términos que nos dan pistas de tendencias. Por ejemplo, aparecen varios municipios donde hay especial demanda de Hostelería (Rubielos, Garrapinillos, Montañana, Cariñena), y otros servicios de Hostelería que no son los mayoritarios (Residencia, planchistas, marmitones, ancianos o discapacidad). Ello nos permite analizar, por ejemplo, una tendencia emergente dentro de este sector dando servicio residencial, y varias especializaciones que se necesitan en Aragón, como por ejemplo Barrancos. Observamos el sesgo de género ya que se solicita mucho más los Camareros (muy grande) que las Camareras (muy pequeño), o Cocinero un poco más grande que Cocineras. Es llamativo que las demandas especifican el género.
Si nos vamos a otro criterio, podemos analizar el texto de la Descripción global de la oferta, también en el mismo sector de TURISMO Y HOSTELERÍA. Buena parte de esta nube se la llevan palabras que indican trámites administrativos derivados de la gestión laboral. Pero hay varios términos que nos ofrecen características del sector. Entre las palabras destacadas, por ejemplo se encuentra ‘Experiencia’ y también ‘jornada completa’ que se lee bastante grande, frente a ‘jornada parcial’ que también se encuentra en la nube pero mucho más pequeña. Por contra, aparece con más tamaño ‘contrato temporal’ que ‘contrato indefinido’. Entre los requisitos que se solicitan se encuentra también carnet de conducir o posibilidad de conducción para el trabajo.
Analizamos ahora otro sector muy distinto. Seleccionamos OFERTAS y sector SERVICIOS A LA EMPRESA. En un sector tan genérico, los términos que aparecen nos ofrecen valiosa información sobre los perfiles que se buscan. Entre los que más, Técnico, Riesgos Laborales, Prevención, Teleoperadores, Seguridad o Informático. Una manera muy sencilla de definir perfiles en este sector.
Aportamos un ejemplo más de OFERTA en este caso, el de INDUSTRIA ALIMENTARIA. En un sector tan diverso, las características del mercado aragonés se definen en su vertiente de carnicería. Despiece, Cárnica, Carnicero, Tripería, Cárnicos, Aviar, Animal, Matadero, Carnicería constituyen las mayoría de las palabras de la nube.
4.- Mapa de ofertas: Con esta opción segenera un mapa donde se puede visualizar el número de ofertas por cada provincia, oficina de desempleo en Aragón y población donde se ofrece el puesto de trabajo, con círculos que amplían su radio proporcionalmente al número de empleos.
Figura 12: Captura de pantalla del mapa de ofertas.
MAPA 1.- Con el propósito de obtener automáticamente la latitud y longitud de las provincias, ciudades y oficinas de empleo en Aragón, usamos la librería GeoPy [12]. Por otra parte, la librería de Python pydeck [13] fue utilizada para visualizar los datos en el mapa de una manera interactiva. En la Figura 13, se muestra un ejemplo de visualización del mapa geográfico con el número de ofertas de empleo por cada una de las provincias de Aragón.
Figura 13: Ejemplo de mapa geográfico de ofertas por cada una de las provincias de Aragón.
Análisis:
Con esta primera imagen en mapa, de un simple vistazo nos hacemos una idea de cómo se reparte el volumen de ofertas del INAEM en Aragón entre sus tres provincias. Las proporciones mayores están en Zaragoza y Huesca, y se nota mayor distancia con las de la provincia de Teruel.
MAPA 2.- La siguiente posibilidad que ofrece nuestro modelo refleja las poblaciones donde se ofrecen los puestos de trabajo. Este mapa puede convertirse en una herramienta valiosa para la ordenación del territorio. Observando la evolución a lo largo de días o meses puede dar información, por ejemplo, de las necesidades de vivienda, educación o servicios, o al contrario, advertir del riesgo de despoblación o de que se inicien movimientos migratorios de los habitantes de una zona buscando trabajo en otro lugar.
MAPA 3.- La tercera posibilidad es conocer el volumen de ofertas de empleo de cada oficina del INAEM en Aragón. Podemos observarlo de manera general, incluyendo las de toda la comunidad autónoma como en este gráfico.
O bien acercarnos y descubrir las opciones de las distintas oficinas dentro de una misma ciudad, como ocurre en Zaragoza.
Conclusiones
En este artículo, hemos presentado el proyecto desarrollado en Saturdays.AI-Zaragoza, un primer paso para contribuir con la sociedad, ante la carencia de herramientas que faciliten a los aragoneses estudiar en términos globales la situación actual de las ofertas de empleo en su comunidad.
Tal y como hemos explicado, entre los problemas que nos hemos encontrado se encuentra la distinta indexación según cada oficina del INAEM. Si todas ellas rellenaran una misma plantilla online exactamente con los mismos criterios el tratamiento de los datos sería mucho más sencillo e inmediato. ¿De qué sirven los datos si no están semi-estructurados? ¿si no hay un patrón que facilite la extracción de la información? Si además nuestro enfoque se implementara y recopilara con esos datos día a día, sería una valiosa arma para la gestión del empleo en la comunidad de Aragón, permitiendo conocer puntualmente la evolución de los distintos sectores, de los lugares donde se ofrece trabajo, de los requisitos que solicitan las empresas para sus futuros empleados. Mucho de nuestro trabajo se ha invertido en solucionar detalles que no tendrían que estar allí. De no habernos encontrado esas diferencias en las formas de clasificación de datos, nuestro estudio nos permitiría hablar de otros análisis más profundos y precisos e incluso modelos de aprendizaje automático avanzados.
Simplemente continuar añadiendo los datos a diario a este trabajo, permitiría un estudio muy detallado de cómo se comporta el mercado laboral en un año, analizando así la evolución de sectores tan temporales como pueden ser el agrícola o el turismo, ambos con un peso muy relevante en la economía aragonesa e incluso pudiendo llegar a predecir las necesidades futuras del mercado laboral aragonés.
Además de todo ello, algunas de las principales aportaciones que realiza este trabajo son las siguientes:
Es una herramienta que aumenta el conocimiento sobre las ofertas de empleo en Aragón.
Consigue organizar los datos del INAEM a pesar de las dificultades.
Crea un sistema de interpretación del lenguaje natural del que obtenemos los datos deseados.
Generación automática de gráficas de barras según los datos por sectores, oficina y provincia.
Generación automática de gráficas según criterios independientes o combinados con año, sector y provincia.
Generación automática de nubes de palabras, que además de analizar la oferta, nos ofrece nuevas ideas o criterios, conceptos emergentes que son muy interesantes para analizar las ofertas.
Generación automática de mapas que permiten tener una visión de las ofertas directamente sobre el territorio, lo que ofrece una valiosa herramienta de comprensión sobre la evolución del empleo y su impacto en las distintas comarcas.
Para qué se puede aplicar:
Marcar líneas de formación para empresas o gobiernos.
Dar indicación a los jóvenes que buscan un horizonte laboral para tomar decisiones en cuanto a su formación de cara a futuro.
Dar información a las empresas de los requisitos que hay en el mercado para un puesto concreto, y conocer las condiciones medias de contratación.
Conocer el tiempo qué tarda en cubrirse una plaza en un sector.
Saber los lugares de Aragón dónde se demanda el empleo y dónde no.
Demanda de empleo según la época del año. Evolución de la temporalidad.
Planificación de la ordenación del territorio y de la sociedad según las necesidades de la población que pueda desplazarse buscando el empleo.
Como líneas de trabajo a seguir partiendo de lo que ya tenemos, se puede continuar con el desarrollo y mejora del dashboard.
Y de cara al futuro
Se podría desarrollar para que el programa se enriqueciera con más información que incorporara a diario de manera automática.
Se podría convertir en una aplicación web real y consultable por autoridades relacionadas con la gestión económica y social, empresas, trabajadores, sindicatos, estudiantes, etc.
Incorporar otras plataformas de empleo, puesto que la del INAEM no representa toda la oferta existente. Requeriría de un complejo estudio para encontrar en esas otras plataformas el modo de homogeneizar la información, es decir, unificar en un única característica aquellos textos que significan lo mismo pero se categorizan bajo etiquetas diferentes. Esto incluso podría pasar dentro de una misma plataforma, como tenemos en el INAEM.
Agradecimientos
Agradecemos la oportunidad que nos ha brindado Saturdays.AI para aprender los fundamentos básicos de Inteligencia Artificial, a pesar de no ser expertos en el ámbito. Y sobre todo a María del Carmen Rodríguez Hernández, por toda la ayuda que nos ha prestado y todas las horas de apoyo, sin las cuales, esto no sería una realidad.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
¿Alguna vez has pensado cómo influye la música en nuestra sociedad y viceversa?
Actualmente estamos rodeados de una gran cantidad de música que, aunque tiene ciertos filtros y criterios para su publicación, en ocasiones llega a oídos de cierta población que resulta afectada por el mensaje que se transmite. Hoy en día ya no es necesario contar con una disquera para promocionar una canción, ya que el acceso a las redes sociales permite que cualquier persona con un celular y acceso a internet se grabe y publique su canción llegando a miles de personas en el mundo, entre ellos menores de edad, como tus hijos.
Para que una canción llegue a ser escuchada existen varios canales de distribución como televisión, radio y las redes sociales, y si no se cuenta con un filtro adecuado, todo tipo de canciones con diferente contenido puede estar llegando a los oídos de menores de edad.
Nuestra propuesta se basa en identificar las canciones en las que, en su letra, exista contenido violento. De acuerdo al artículo “La violencia contra las mujeres en la música: Una aproximación metodológica”[1], dónde se habla sobre la violencia contra las mujeres en la música, indica que:
“en los casos más negativos se proyecta estereotipos que sitúan al hombre y a la mujer en posiciones sociales distintas, incluso llegando a justificar y potenciar la violencia contra las mujeres“.
Es por ello que este proyecto tiene como ambición contribuir al cumplimento de uno de los diecisiete Objetivos de Desarrollo Sostenible, planteados por las Naciones Unidas y aceptados por varios países en Latinoamérica, específicamente el objetivo cinco referente a la equidad de género. Para identificar y concientizar a la población sobre el mensaje que transmite la música y, de esta manera, empoderar a la población que tiene acceso a plataformas digitales de música, sobre los mensajes en las canciones que escucha.
Al inicio de este proyecto, se planteó una lluvia de ideas, se pensó en crear una app que al escuchar o ingresar una canción indique si esta contiene diversos tipos de violencia en sus letras, mediante el uso de Procesamiento Natural de Lenguaje (NLP), para lo cual se propuso el siguiente etiquetado:
Tipos de violencia según artículo “La violencia contra las mujeres en la música: Una aproximación metodológica”, algunos iconos fueron obtenidos del artículo “De qué hablamos cuando hablamos de violencia contra la mujer”, de .infojusnoticias.gov.ar
Apto para menores de edad
No contiene ningún tipo de violencia, el mensaje y contexto de la canción debe ser revisado por un adulto.
Extracción de datos
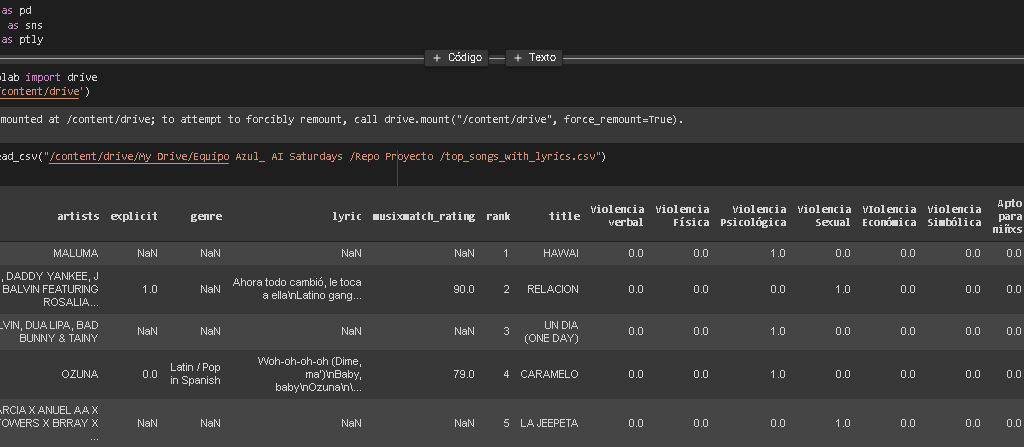
Para ello, se empezó a analizar una muestra de 500 canciones, las cuales se seleccionaron de listas de popularidad de música latina, ya que el proyecto se plantea para la población hispanoparlante de América Latina, por lo que el flujo de trabajo quedó de la siguiente manera:
1) Se buscó en los rankings de Billboard y de Scanner Sound, la lista de canciones más tocadas con un web scraper, con lo que se obtuvo artista y título.
2) Mediante las herramientas de desarrollador de musixmatch se obtuvo la api el género musical de cada canción y si estas tienen lenguaje ‘explícito’, sin embargo solo nos proporcionaba el 40% de las letras.
3) De Google se obtuvo la letra de las canciones el cual se nutre de dos proveedores: Musixmatch y LyricFind, con lo que, finalmente, se obtuvieron los siguientes campos:
Artista
Género
Título
Si es explícita o no (lenguaje inapropiado)
Luego, se realizó la extracción de las letras de las canciones mediante API’s que ofrecen los sitios más populares de música (Musixmatch y el Billboard) mediante sus herramientas para desarrolladores.
Una vez que se obtuvieron las letras de las canciones se procedió al etiquetado manual, el cual se realizó de acuerdo a los tipos de violencia anteriormente expuestos. El equipo desarrollador de este proyecto, etiquetó las categorías de entrenamiento, con lo que se obtuvo una siguiente fuente de datos, su representación se puede ver a continuación:
Ejemplo de conjunto de datos obtenido en un primer etiquetado
Resulta importante destacar que, debido a que el etiquetado de cada categoría está sujeto a los criterios de cada integrante del equipo, el conjunto de datos podría tener un sesgo. Vale la pena mencionar, que esta etapa del proyecto es una prueba de concepto que nos servirá para validar la factibilidad de realizar un etiquetado automático de acuerdo al objetivo planteado. Además, al observar que el número de positivos en cada categoría no era suficiente para que el algoritmo pudiese tener un buen aprendizaje, se decidió agregar una categoría adicional, llamada ‘clase’, la cual indica si tiene contenido violento. Este cambio dentro del alcance se abordará más adelante.
EDA
Luego se procedió a realizar el Análisis Expiatorio de Datos (EDA). Para preparar los datos utilizando la librería ‘pandas’ para Python, así como matplotlib, seaborn y plotly para este primer análisis que nos permitiera tomar decisiones previas al preprocesamiento de los datos y tener un panorama de cómo se distribuían las clases en nuestra ‘data set’. y obtener un corpus que nos sirviera de base para iniciar con el análisis utilizando NLP.
Del conjunto de datos generado se obtuvieron algunos ‘insights’ interesantes mediante un primer Análisis Expiatorio de Datos (EDA):
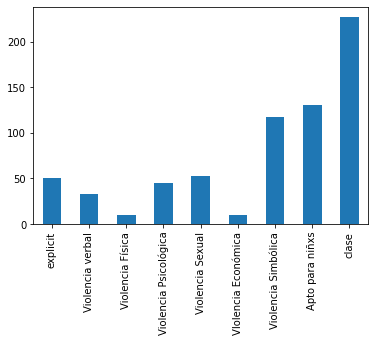
Análisis/distribución de tipos de violencia
Gráfica de Barras que muestra el número de incidencias en cada clase del ‘data set’
En esta gráfica de barras podemos observar la distribución de los tipos de violencia que contiene la música seleccionada, en este caso, la mayor predominancia son géneros musicales de reggaeton, regional mexicano y pop en español debido a que se obtuvieron las canciones más escuchadas del momento, sin embargo, esta información no se utilizará para el algoritmo ya que podría crear un sesgo importante, como se puede observar en el histograma de acuerdo a los géneros. Vale la pena mencionar que este análisis se hizo antes de normalizar los datos para tener un panorama de cómo están distribuidos los datos.
Gráfica de barras que muestra cómo se distribuyen los tipos de violencia por género musical.
Se realizó un mapa de calor para descubrir cómo se relacionan los tipos de violencia dentro de las canciones que se consideraron.
Después del análisis de los tipos violencia, consideramos que separar la cantidad de canciones en las siete categorías seleccionadas no sería suficiente para hacer una buena clasificación ya que tenemos relativamente pocos positivos en cada categoría. Con base en esta observación, para una primera fase, se realizará la separación solo en 2 categorías: “violento” y “no violento”. Algo muy importante de destacar es, que aunque una canción no contenga violencia, no quiere decir que sea apto para infantes, debido a que podría tocar temas no aptos para ciertas edades.
Análisis con mapas de palabras con y sin la etiqueta de violencia
En una segunda aproximación, durante el preprocesamiento de los datos se obtuvieron mapas de palabras, como un segundo EDA, con el fin de identificar las palabras más frecuentes en contenido violento y no violento y reconocer algunas “stopwords” que debemos considerar o, en dado caso, palabras que deban lematizarse.
El preprocesamiento de los datos, en este caso, se realizó de la siguiente manera:
1) Normalización datos/letras de canciones (acentos, mayúsculas, signos de puntuación y eliminación de palabras como ‘oh’, ‘yeah’, ‘ma’, etc.)
2) Tokenizado de palabras
3) Remoción de ‘stopwords’
4) Lematización (en una siguiente etapa se considera ver si ‘stemming’ podría ayudar a obtener mejores resultados)
5) Vectorización de las canciones (en esta etapa del proyecto se emplea Bag of Words).
Posterior a que se hizo el preprocesamiento, se emplearon nuevamente mapas de palabras para observar qué palabras podrían ser más recurrentes en una canción con violencia y sin violencia. Sin embargo, al obtener los mapas de palabras, se observó que en ambos casos predominan palabras como: haber, querer, hacer y tener. Por lo que se incluyeron a la lista de ‘stopwords’ y se volvió a hacer un análisis con una nube de palabras.
mapa de palabras «sin violencia» antes de quitar stop words muy comunesmapa de palabras «con violencia» antes de quitar stop words muy comunesmapa de palabras «sin violencia» después de quitar stop words muy comunesmapa de palabras «con violencia» después de quitar stop words muy comunes
Como se puede observar, ambas clasificaciones siguen teniendo algunas palabras en común como “decir” y “saber”. Sin embargo, se pueden observar diferentes palabras en el mapa de las canciones ‘con violencia’, como “olvidar”, “morir”, “perder”, “dejar”, etc.
Una vez que se tuvo la ‘corpora’ preparada y se aplicó la vectorización Bag of Words, se trabajó con la etiqueta de “violento” o “no Violento”, que va a representar si la canción tiene cualquier tipo de violencia en su contenido.
Entrenamiento y selección del modelo
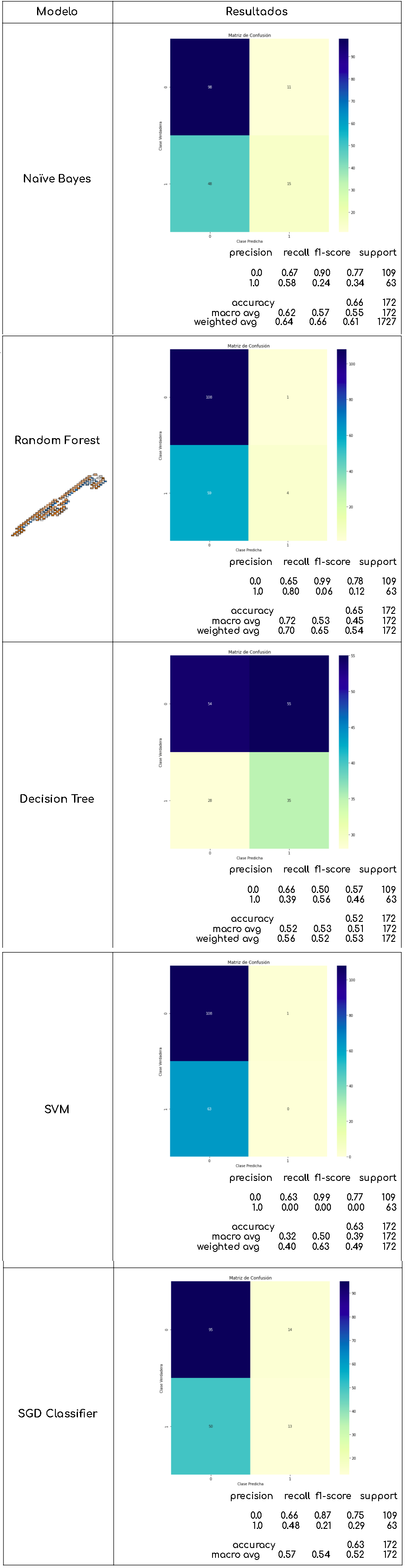
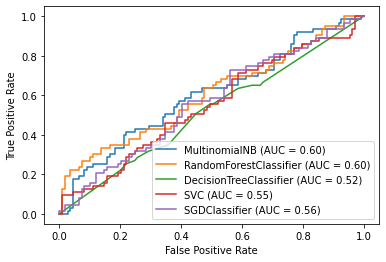
Se probó con diferentes algoritmos, después de aplicar la representación ‘bag of words’ y usando la técnica de lematización con las herramientas de nltk, para los modelos se ocuparon las librerías de sklearn como Naive Bayes, Random Forest, Decision Tree, SVM y SGD.
Por cada modelo, se presentó un reporte de clasificación para visualizar su precisión ‘accuracy’ , pero también se consideró el f1-score para evaluarlos junto con un mapa de calor de la matriz de confusión.
Resultados obtenidos de los clasificadores, matriz de confusión y métricas obtenidas con las librerías sklearn y seaborn
Para poder comparar mejor el desempeño de los modelos, también se emplearon las curvas ROC. Lo cual nos muestra de una forma más visual el comportamiento de los modelos entre sí
Curvas ROC de los modelos obtenidas con las librerías sklearn y matplotlib
Curvas ROC de los modelos
Como se observa en la gráfica de curvas ROC, los modelos que tuvieron mejor desempeño fueron ‘Random Forest’ y ‘Naïve Bayes’, que tienen resultados muy similares. Sin embargo, si observamos las matrices de confusión y el ‘F1 Score’ podemos concluir que con los datos que se tienen, ‘Naïve Bayes’ es el modelo que mejor comportamiento tiene en esta etapa del proyecto. Ya que para nosotros es mejor tener una etiqueta de violencia aunque no la tenga, a que una canción con violencia sea erróneamente clasificada y llegue a menores de edad. Es decir, en términos técnicos es mejor para nosotros tener un error tipo I (falsos positivos), a un error tipo II (Falsos negativos).
Escalabilidad del proyecto
Con base en los datos generados, se hizo el aprendizaje considerando sólo 2 categorías ‘con violencia’ y ‘sin violencia’, debido a que la cantidad de canciones utilizadas no serían suficientes para que el algoritmo pueda diferenciar entre 6 clases diferentes, incluso se piensa que en un futuro, con mayor cantidad de datos de aprendizaje, se pueda hace la clasificación en 3 o 4 categorías, dependiendo del número de positivos que podamos obtener.
De obtener buenos resultados, se podría crear una API para uso en aplicaciones móviles o como plug in, con el fin de facilitar el reconocimiento de una canción y saber si dicha canción tiene o no contenido violento.
El conocer de antemano si una canción tiene o no contenido violento, será de ayuda para empoderar a los usuarios y reflexionar sobre el impacto que tiene lo que se escucha en la cultura popular sobre nuestras vidas y la cultura de la población.
Un caso particular de una aplicación podría ser como herramienta de detección de ‘violencia mediática’, en una ley recientemente aprobada en México: la ley ‘Olimpia’, en la cual se integró este término, que como se puede leer en el periódico Excélsior[2], se define como:
Todo acto que a través de cualquier medio de comunicación:
-Promueva estereotipos sexistas.
-Haga apología de la violencia contra mujeres y niñas.
-Produzca o permita la producción y difusión de discursos de odio sexista.
-Promueva la discriminación de género o desigualdad entre mujeres y hombres.
-Cause daño a las mujeres y niñas de tipo psicológico, sexual, físico, económico, patrimonial o feminicida.
Ejemplo de API con el logo del equipo desarrollador
Glosario:
NLP: Procesamiento Natural del Lenguaje, por sus siglas en inglés (Natural Language Processing) es la rama de la Inteligencia Artificial que estudia la interacción del lenguaje humano con las computadoras.
Corpus (pl. corpora): Un corpus lingüístico es un conjunto amplio y estructurado de ejemplos reales de uso de la lengua. Estos ejemplos pueden ser textos (los más comunes), o muestras orales (generalmente transcritas). [3]
Lematización: Relaciona una palabra flexionada o derivada con su forma canónica o lema. Y un lema no es otra cosa que la forma que tienen las palabras cuando las buscas en el diccionario. [4]
Stopword: Palabras muy comunes y poco informativas desde el punto de vista léxico, tales como conjunciones (y, o, ni, qué), preposiciones (a, en, para, por, entre otras) y verbos muy comunes (ser, ir, y otros más).[4]
Referencias:
Gómez Escarda, María., Pérez Redondo, Rubuén J. (2016) “La violencia contra las mujeres en la música: Una aproximación metodológica”. Universidad Rey Juan Carlos, España.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
El estrés: una ‘epidemia’ silenciosa que puede afectar a cualquier persona durante la era moderna, ahora es más notoria debido a la mayor crisis sanitaria enfrentada durante este siglo. Los niveles de preocupación, impacto económico y emocional que han tenido que afrontar las personas han sido factores que han impactado no solo la salud física también la mental de millones de personas.
En este trabajo de inteligencia artificial (ciencia de datos), se realiza un esfuerzo para analizar, predecir y determinar, si una persona está estresada con el uso de sus mensajes a través de la red social de Twitter.
Problema general
¿Es posible que una máquina pueda determinar si una persona está estresada solo con la expresión escrita?
Motivación
Social: ayudar a identificar y reconocer el estrés durante la crisis sanitaria para así conocer el estado emocional de las personas sin necesidad de un estudio en persona
Profesional: obtener, extender y aplicar los conocimientos sobre ciencia de datos e inteligencia artificial, en el análisis de lenguaje humano y en reconocimiento de emociones
Metodología
La metodología con la que se trabajó en este proyecto está basada en la metodología tradicional de CRISP-DM [1]. A continuación se muestra el diagrama general de los pasos que se llevaron a cabo en este trabajo.
Diseño del modelo de reconocimiento:
Recolección de datos
Para llevar a cabo el análisis se recolectaron datos de tweets de 3 diferentes ciudades para poder tener muestras variadas y esperar resultados diferentes. Las ciudades fueron elegidas solamente tomando en cuenta que fueran ciudades grandes en diferentes países angloparlantes.
Las ciudades de las que se obtuvieron los datos fueron las siguientes:
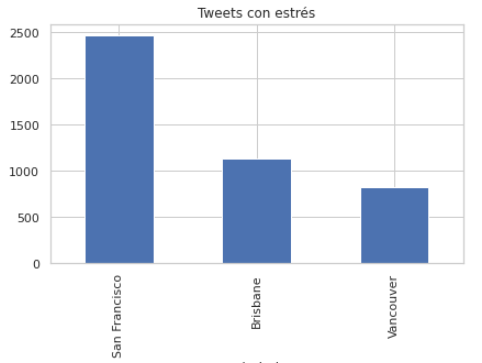
Brisbane, Australia (2225 tweets)
San Francisco, Estados Unidos (5000 tweets)
Vancouver, Canadá (1699 tweets)
Cabe mencionar que los datos fueron recolectados el 24 de octubre y los tweets tienen fecha máxima de publicación una semana anterior a la fecha de recolección y mínima del mismo día de la recolección.
Las palabras claves que se utilizaron para la recolección fueron las siguientes:
covid OR COVID OR coronavirus OR corona OR coronavirus OR #coronavirus OR #covid19 OR covid19 OR sarscov2 OR #covid-19 OR #sarscov2 OR sars OR cov2 OR sars OR #quarantine OR pandemic OR #pandemic OR #2019ncov OR 2019ncov OR quarantine OR lockdown OR #lockdown OR social distancing OR #socialdistancing OR #COVID OR #covid”
La estructura de los datos es idéntica para los 3 datasets. Cada dataset está organizado en 3 columnas:
user_location: Ubicación aproximada del usuario (si su ubicación está activada).
date: Fecha de publicación del tweet.
text: Texto del tweet.
Los datos anonimizados se obtuvieron a través de la API de Twitter a través de un script de Python utilizando Tweepy [2].
Etiquetado
Para el etiquetado de los datos, fue utilizada una herramienta llamada TensiStrength, la cuál está desarrollada en Java, y ayuda a evaluar el nivel de relajación o ansiedad que se puede encontrar en un texto sencillo. Esta herramienta funciona por medio de diccionarios de emociones en los cuales se asignan valores a las palabras positivas o negativas y a su vez también cuenta con un diccionario de palabras (booster words) que incrementan el valor de la expresión/emoción.
TensiStrength logra catalogar los textos de dos maneras disponibles, binaria o ternaria; la ternaria los clasifica en 1, 0, -1, positivo, neutral y negativo respectivamente. El esquema para la clasificación de emociones utilizado en nuestro modelo, utiliza la clasificación de tipo binaria, que consiste en usar las etiquetas 1 y 0, las cuales corresponden a “estrés” y “no estrés”.
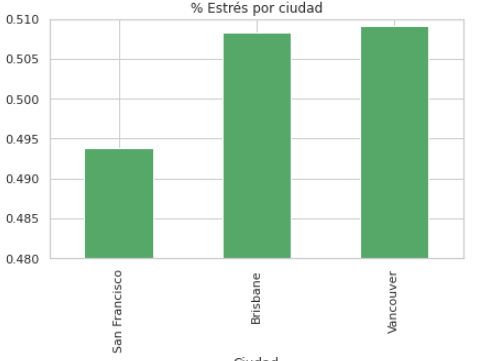
Las clases se encuentran distribuidas con un porcentaje de: Tweets con estrés = 49.972% Tweets sin estrés = 50.028%
Exploración de los datos:
Cantidad de tweets con estrés.
Porcentaje de estrés por ciudad, representa la cantidad de tweets con estrés respecto al total de tweets.
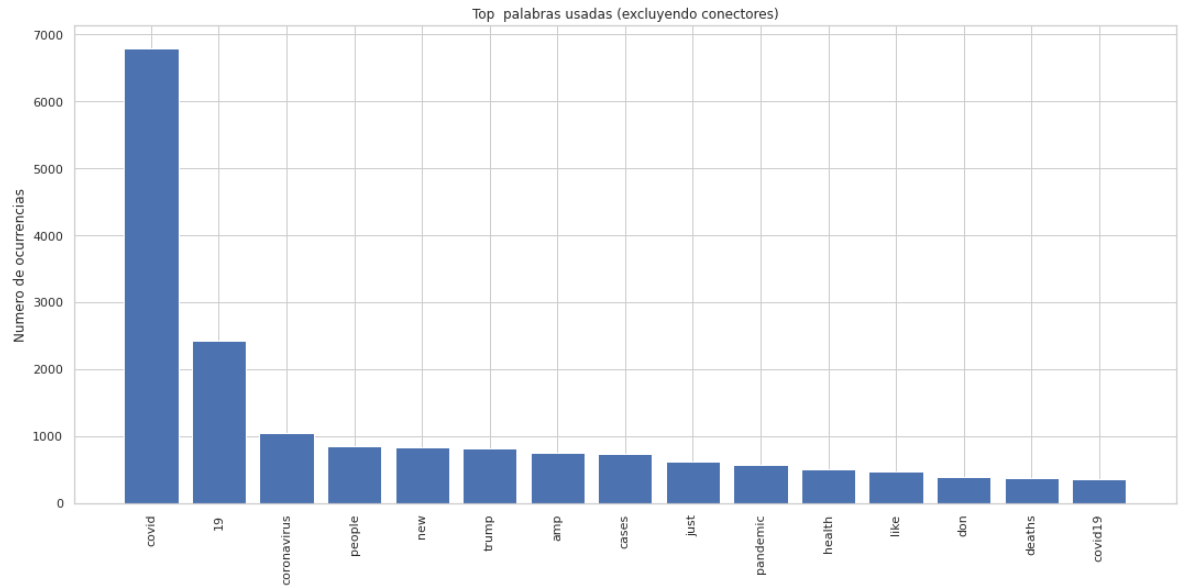
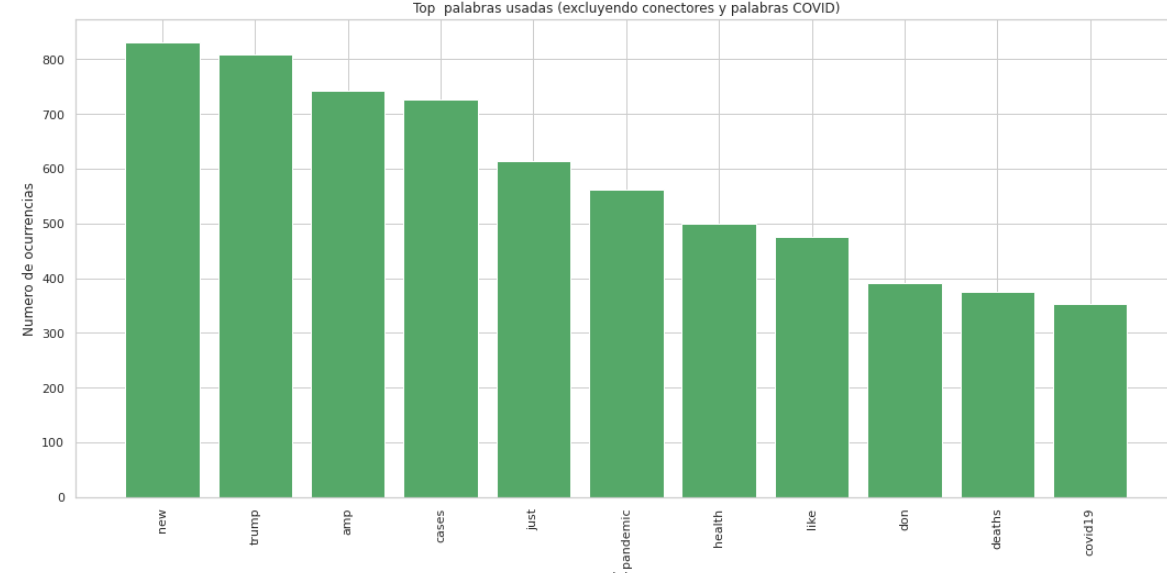
Palabras más usadas en los tweets, excluyendo conectores.
Palabras más usadas en los tweets, excluyendo conectores y palabras relacionadas con Covid.
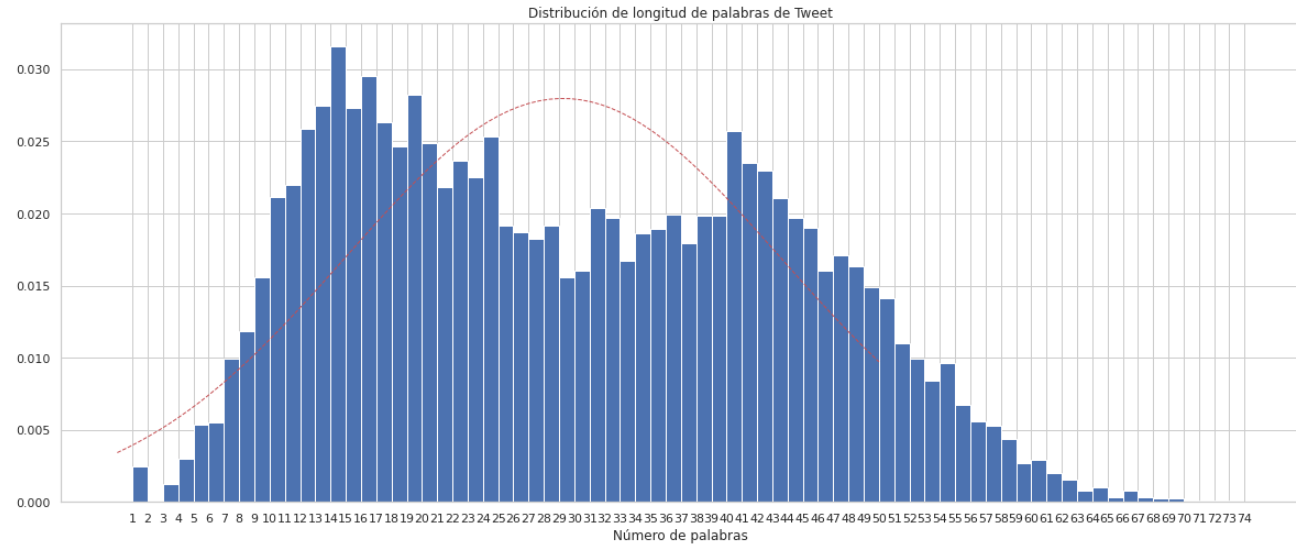
Distribución de las palabras en los Tweets según su longitud
Pre-procesamiento de los datos:
Después de recolectar los datos, se llevó a cabo un pre-procesamiento con el fin de que los datos se pudieran utilizar para entrenar un modelo clasificador. Este paso es uno de los más importantes y es aquel que comúnmente consume más tiempo en un proyecto de aprendizaje de máquina.
Reducción de Ruido: se eliminaron espacios extras, carácteres especiales y ligas a otras páginas.
Normalización: los carácteres se transformaron a minúsculas, se eliminaron puntuaciones y se expandieron las contracciones.
Eliminación de palabras vacías o Stopwords: se removieron aquellas palabras que no tienen un significado por sí mismas (artículos, pronombres, preposiciones y algunos verbos)
Lematización: se llevó a cabo una lematización, la cual consiste en convertir la palabra a su forma base (i.e. mesas a mesa).
Tokenización: finalmente los textos se separaron en palabras, también llamados tokens.
Antes del pre-procesamiento, el texto se visualiza de la siguiente manera:
Posterior a la limpieza y previo a la tokenización, el texto se visualiza de la siguiente manera:
Visualización de datos
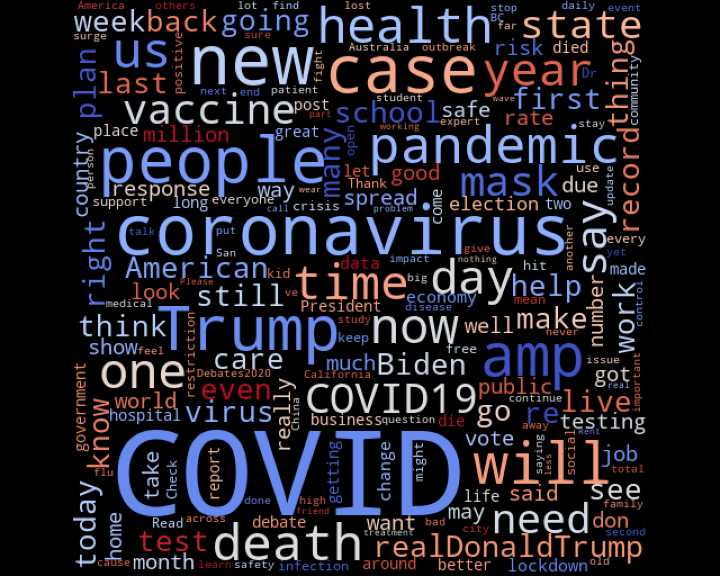
Fue realizada por medio de nubes de palabras, en general y dividiendo los datos por clase.
Palabras más recurrentes en general:
Palabras más recurrentes dentro de los datos clasificados como SIN estrés
Palabras más recurrentes dentro de los datos clasificados como CON estrés
LDA (Latent Dirichlet Allocation)
Se utilizó un clasificador de modelo generativo LDA (no supervisado), que permite que a partir de una bolsa de palabras, se genere un conjunto de observaciones que puedan ser explicadas por algunas de las partes de los datos que son similares o que tienen cierta concordancia. Este es un modelo de categorías y fue presentado como un modelo de grafos para descubrir categorías por David Blei, Andrew Ng y Michael Jordan en 2002.
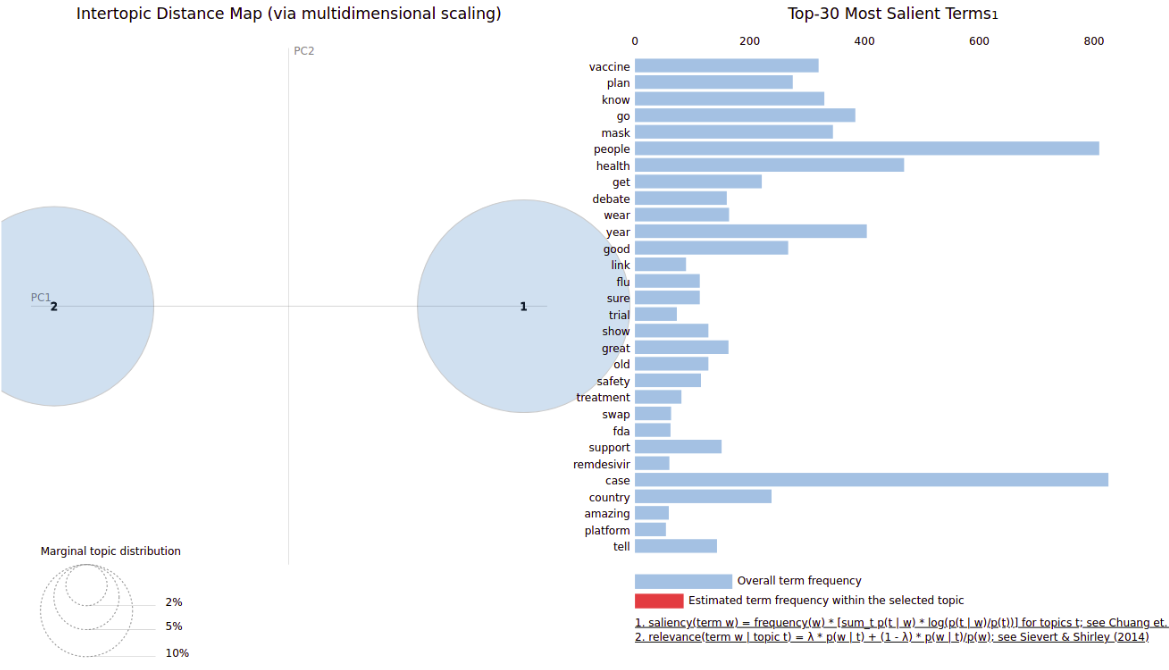
En nuestro trabajo se utilizó a partir de de la vectorización de la data tratada y limpia de los tweets obtenidos, una tokenización y generando una vectorización de las palabras. Obteniendo un clasificador de 2 tópicos, en las cuales sus principales palabras fueron:
Tópico 0: Covid case new health vaccine death year trump plan day
Tópico 1: Covid people trump go new case mask know say need
y utilizando la librería pyLDAvis se obtuvo el visualizador:
Modelado
Para este proyecto se evaluaron cinco modelos de Machine Learning. Como modelo base se utilizó Naive Bayes y se comparó con:
Regresión Logística
K-Nearest Neighbors
Random Forest
Gradient Boosting.
Para la vectorización [4] de los tweets se evaluaron 2 técnicas: Bag of Words y TF-IDF (term frequency — inverse document frequency) y dos estrategias para sus n-gramas: Bigrama y Trigramas [5].
Los resultados se midieron por medio del AUC (Area Bajo la Curva) y se evaluaron con validación cruzada (k = 10). Tanto el preprocesamiento, entrenamiento y evaluación del modelo se llevaron a cabo dentro de un “pipeline” creado dentro de una clase utilizando el lenguaje de programación de Python.
Nivel de precisión para cada modelo implementado con “Bigrams”
Nivel de precisión para cada modelo implementado con “Trigrams”
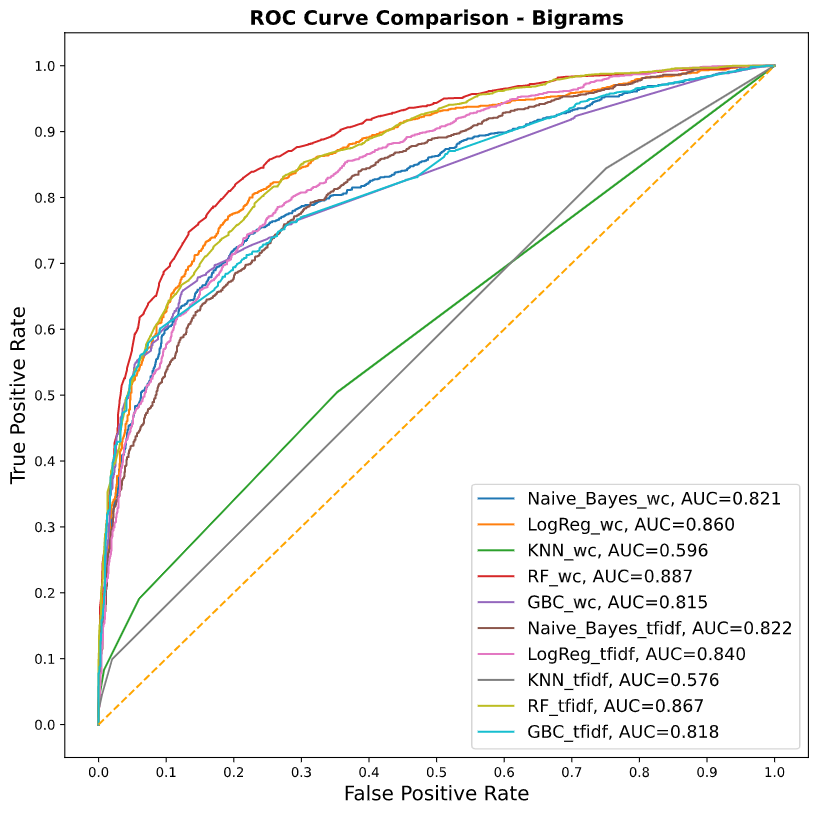
En las gráficas de AUC previas se muestra que la combinación ganadora es la de: RFt + BoW + Bigramas, ya que es la mejor en discernir los mensajes que tienen alguna relación con estrés de aquellos que no la tienen.
A continuación podemos observar la matriz de confusión del modelo ganador, así como los resultados de sus métricas.
Optimización (‘Tuneo’) del modelo:
El ajuste fue realizado para tres modelos con el fin de mejorar su desempeño.
Logistic Regression Se genera una búsqueda de grilla utilizando grid search al cual se le definen ciertos valores con los que se ejecutará el modelo para obtener la versión con mejor Accuracy. Para esto se consideró: 1.- Valor C 2.- Penalty del modelo: L1 (Lasso) y L2 (Ridge)
Random Forest Classifier Se genera una búsqueda de grilla utilizando grid search al cual se le definen ciertos valores con los que se ejecutará el modelo para obtener la versión con mejor Accuracy. Para esto se consideró: 1.- Número de Estimadores: número de árboles utilizados en el bosque. Este valor empezará en 200 e irá de 10 en 10 hasta llegar a 2000. 2.- Max_Features: es el número de atributos a considerar para la mejor división. Se prueba con “auto” que se refiere a que el máximo de atributos será la raíz cuadrada del número de atributos. 3.- Max_depth: esto se refiere a la máxima profundidad del árbol. Para este caso se parte en 10 hasta 110 avanzando de 11. 4.- Min_Samples_split: es el número mínimo de muestras requeridas para la división interna del nodo. Se prueba con 2, 5 y 10. 5.- Min_samples_leaf: el número mínimo de muestras requeridas para ser una hoja de nodo. Se considera 1, 2 y 4 para realizar la búsqueda de grilla. 6.- Bootstrap: Si es Verdadero, usará bottstrap en la construcción de los árboles. Si es falso no se utilizará. Se probará con ambas.
Gradient Boosting Classifier Se genera una búsqueda de grilla utilizando grid search al cual se le definen ciertos valores con los que se ejecutará el modelo para obtener la versión con mejor Accuracy. Para esto se consideró: 1.- Loss: se usa desviance para evaluar como regresión logística la función de pérdida 2.- Learning:rate: es la medición que mide la contribución de cada árbol. 3.- Max_Features: es el número de atributos a considerar para la mejor división. Se prueba con “sqrt” que se refiere a que el máximo de atributos será la raíz cuadrada del número de atributos, en el caso de “log2” se usa el logaritmo del número de atributos. 4.- Max_depth: esto se refiere a la máxima profundidad del árbol. Para este caso se usa 3, 5 y 8. 5.- Min_Samples_split: es el número mínimo de muestras requeridas para la división interna del nodo. Se prueba con un linspace de 0.1, 0.5 y 12. 6.- Min_samples_leaf: el número mínimo de muestras requeridas para ser una hoja de nodo. Se prueba con un linspace de 0.1, 0.5 y 12. 7.- Numero de Estimadores: número de árboles utilizados en el bosque. Este valor empezará en 200 e irá de 10 en 10 hasta llegar a 2000.
Evaluación:
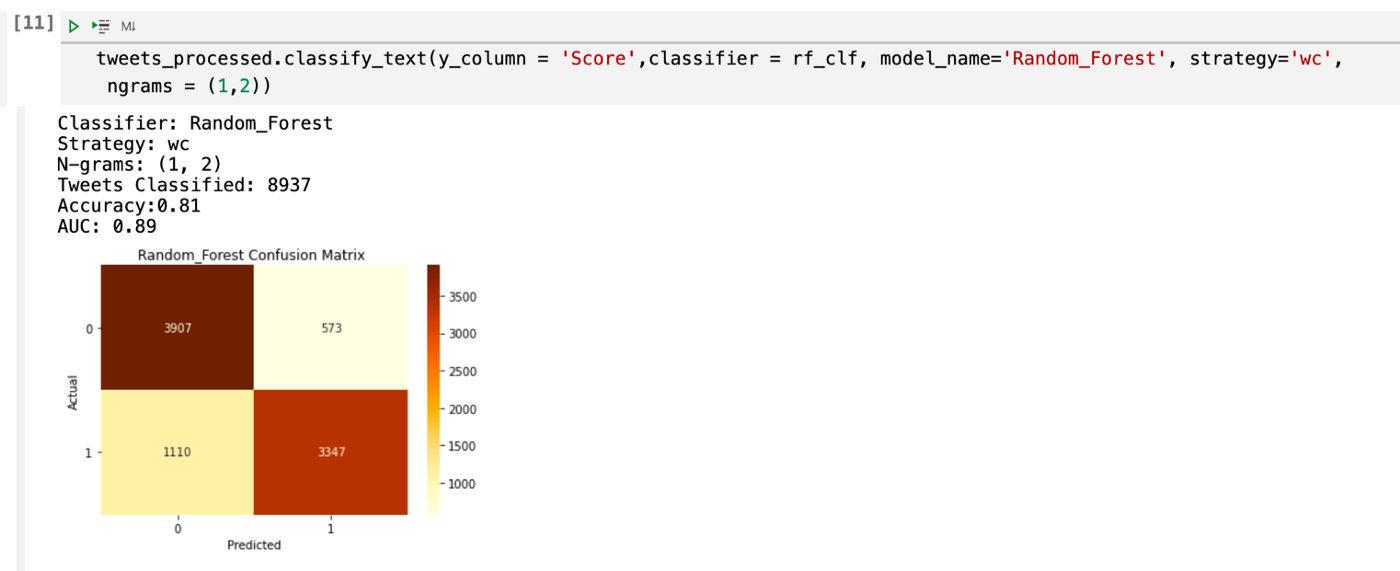
El modelo generado con mayor eficacia fue el de Random Forest, ya que es capaz de reconocer si un tweet contiene o no estrés con una precisión de 88%, lo cual es una métrica muy buena, ya que la velocidad con la que se puede evaluar un conjunto masivo de tweets con esta exactitud ayuda enormemente en una tarea que un humano tardaría mucho más tiempo, y de esta manera es posible encontrar o tratar posibles casos que requieran asistencia sin necesidad de esperar a que esto lleve a un problema mayor como lo es la depresión.
Análisis de resultados:
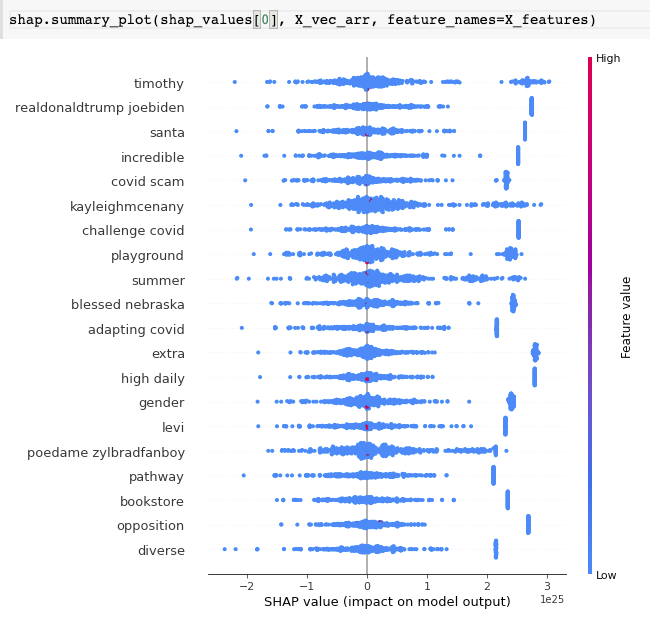
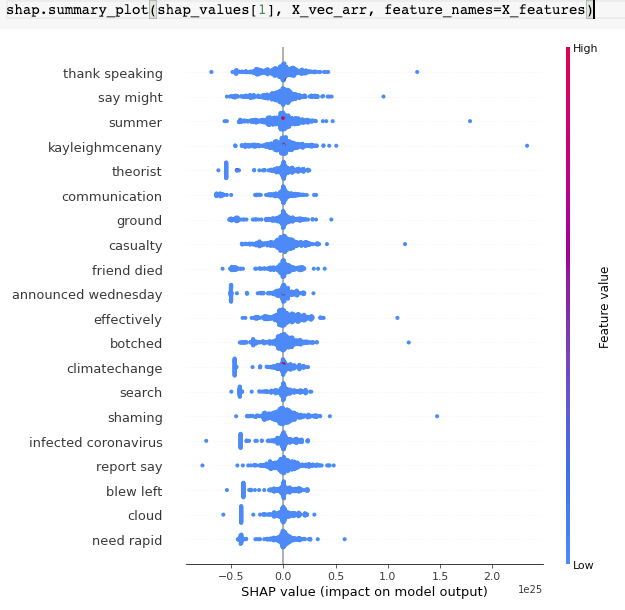
Para poder adentrarnos más en por qué el modelo se comporta de la manera que lo hace, hicimos uso de SHAP, una técnica de teoría de juegos utilizada para explicar los modelos. El modelo utilizado fue un Random Forest con 100 estimadores.
En este caso utilizamos un TreeExplainer de la librería shap. Para calcular estos valores se tuvo que usar solamente el 5% de los datos de entrenamiento y 10,000 features, de otro modo, el tiempo de ejecución sobrepasa la hora y media en Google Colab.
Resultados para tweets que NO tienen estrés:
Resultados para tweets que SÍ tienen estrés:
Casos de uso para el modelo generado:
Instituciones públicas, gubernamentales o privadas que estén interesadas en conocer o monitorear el estado anímico de una población, o conjunto de personas por zona geográfica, para evaluar el nivel de estrés.
Personal que labore en el área médica enfocada en la salud mental, para lograr identificar las condiciones sobre la estabilidad emocional de algún sector de la población.
Empresas privadas que puedan ofrecer servicios de consultoría para el bienestar emocional y que ofrezcan análisis o proyección de campañas de salud mental en la sociedad.
Desarrollo de Modelo en un App Web
Para alojar nuestro modelo de Machine Learning usamos el framework Flask. Este es usado por su facilidad de uso, ser muy escalable y además, está desarrollado para Python. Lo cual permite en un lenguaje realizar todo el desarrollo. Hay que tener claro que una aplicación web tiene dos partes fundamentales.
Partes de una App Web:
El Front-end el cual es una página desarrollada con Html y Css. Sin ninguna parte de JavaScript ya que es una app sencilla de utilizar.
El Back-end será desarrollado con Flask, donde permite crear la integración con el Front-end y además correr el modelo ya entrenado.
Desarrollo de la interfaz de usuario
En esta parte fueron utilizadas dos herramientas en línea bastante útiles que son Flask y Heroku. Flask es un framework para desarrollo web con gran interacción con Python; Heroku es usado como un servidor para el despliegue y disponibilidad pública de la aplicación.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Existen diversos servicios para viajeros, desde páginas de hoteles hasta ofertas turísticas a unos cuantos clics de distancia, no obstante, el ser humano ha conseguido su información por siglos y siglos a través de preguntas y bases de conocimiento, por lo que le es más natural hacer consultas de esa forma, así surge Pangea, como un servicio web de Inteligencia Artificial conversacional con el que el viajero puede interactuar y conseguir las respuestas a sus más inquietantes preguntas.
Un viajero prudente nunca se lanza a viajar si no tiene la información más relevante de su destino, en su cabeza se encuentran preguntas que en primera instancia cuestionan su seguridad, por lo que investiga al respecto y logra resolver sus dudas en probablemente muchos minutos, de igual forma si ya se aventuró a viajar y necesita conocer alguna costumbre, plato típico, música o lugares para visitar, son tantas las preguntas y mucho el tiempo invertido en responderlas, de esa forma los viajeros pierden tan importante recurso.
Por lo que al usar textos como datos a analizar en la tarea de respuesta a preguntas se requiere el uso de Natural Language Processing (NLP) o en español conocido como el procesamiento del lenguaje natural, entiéndase como la rama de la Inteligencia artificial (IA) que entrena a una computadora para comprender, procesar y generar lenguaje (conversacional).
Descripción del problema
Concretamente el problema es el tedioso y tardío acceso a respuestas inmediatas sobre dudas y consultas acerca de un destino turístico, como ser: comida, hospedaje, actividades turísticas, transporte, centros de salud, cultura, música, conflictos políticos, entre otros.
Objetivo
Desarrollar mediante Inteligencia Artificial un servicio web conversacional de pregunta-respuesta para viajeros aplicando NLP mediante la aplicación de un modelo dedeep learning.
Técnicas implementadas
Se presentan las técnicas complementarias a la resolución del problema, ya que todo modelo de Deep Learningrequiere ser alimentado por datos.
Búsqueda de datos
La Inteligencia Artificial conversacional Pangea se centra en responder preguntas y no sería posible sin cantidades ingentes de información con las cuales interactuar y usarlas como una fuente de conocimiento (contexto), en ese sentido, se realizó la búsqueda de páginas web que contengan las respuestas más coincidentes de acuerdo a la pregunta del usuario viajero; hacerlo de forma manual representaría demasiado trabajo, por lo cual, se decidió usar la biblioteca de Python, Google Search, el cual emplea al motor de búsqueda Google como fuente de información para brindar las URLs de los sitios webs requeridos.
Captura de datos
Una vez obtenidas las URLs de los sitios webs que contienen la información requerida, se empleó la técnica del Web Scraping para obtener el contenido literal de dichos sitios, es decir, los distintospárrafos y textos presentes en el sitio. Web Scraping es una técnica cuyo objetivo es recolectar información de la web a través de código. En este caso se usó la biblioteca Beautiful Soup disponible en pypi.
Selección y evaluación del modelo
Modelo Bert: es un codificador bidireccional de transformers, que aprende a interpretar el lenguaje.
Cuando al modelo Bert se le añade capas adicionales y es entrenado con un propósito o tarea especializada, se obtiene un modelo Bert que resuelve una tarea en específico.
En el proyecto se aplicó ya modelos ajustados para la tarea de pregunta y respuestas, que fueron previamente ajustados mediante el dataset de los conjuntos de datos de respuesta a preguntas Stanford(SQuAD).
Ambos modelos fueron obtenidos y reutilizados de la biblioteca hugging Face Transformers. Dichos modelos reciben una pregunta y un contexto para procesarlo y analizarlo con el fin de devolver las respuestas que mejor se ajusten a la pregunta.
La elección del mejor modelo fue dado en base a los resultados:
Bert en inglés:bert-large-uncased-whole-word-masking-finetuned-squad
Bert en español (Beto): distill-bert-base-spanish-wwm-cased-Finetuned-spa-squad2-es
Tabla 1. Evaluación de Modelos
Se seleccionó y grafico un caso en específico, para demostrar como se comportan ambos modelos a una misma pregunta y cuales son las respuestas textuales que dan cada uno en su respectivo lenguaje, figura 1.
Figura 1. Gráfico de barras — Representación de respuestas Modelo Bert y Beto a la misma pregunta.
Flujo de Trabajo del Sistema
El sistema consta de distintos procedimientos para resolver una determinada pregunta, por lo que el usuario viajero debe partir lanzando una pregunta, posteriormente el sistema realiza una búsqueda con Google Search en relación a tal pregunta y devuelve unas cuantas URLs (máximo 5) con las que el web scraper realiza la tarea de extraer todo el texto (párrafos) del sitio hospedado en la URL para pasarle como contexto al modelo, el modelo utiliza el contexto, la pregunta y lanza una respuesta, se captura la respuesta y la url,ambas son representadasen formato de mensaje de chat, figura 2.
Figura 2 . Elaboración propia
Análisis de resultados (Bert vs Beto)
Pangea devuelve las respuestas y la URLs de donde han sido obtenidas tales respuestas, según la cantidad de pruebas se puede observar que el uso de Beto se adecua más según el porcentaje de aciertos. Y en las gráficas se visualiza como el modelo Beto da respuestas con mayor precisión a la misma pregunta realizada en ambos idiomas de acuerdo al modelo.
Conclusión y recomendaciones
Las conclusiones obtenidas tras el desarrollo y resolución del objetivo general son:
Se obtuvo un 64.7 % de respuestas correctas de un total de 17 preguntas por parte del modelo BERT en español en relación al 30% del modelo BERT en inglés, en ese sentido, el modelo BERT pre-entrenado con mayor precisión en sus respuestas es el español, ya que las preguntas tuvieron a Bolivia como contexto principal y es razonable puesto que no muchos sitios en inglés tienen información actualizada y específica de Bolivia.
La técnica del Web Scraping aportó correctamente el contenido web necesario para que el modelo BERT pudiese responder las preguntas adecuadamente.
Dado que el servicio (Pangea) se desplegó por un momento se logró registrar el uso de 2.5 GB de memoria RAM con una demora de aproximadamente 30 segundos mientras el modelo responde a la pregunta.
El Servicio Web que se ofreció por unos instantes logró capturar la curiosidad y asombro de los usuarios por su diseño minimalista e interesante forma de interactuar.
Por otra parte las recomendaciones al respecto son:
El modelo BERT empleado fue afinado (fine-tuning ) con el dataset SQUAD el cual tiene un formato pregunta-respuesta de dominio parcialmente general, por lo que se tiene mayores expectativas con un afinado específico para el área de turismo.
La información recolectada por el servicio proviene de Google que es un motor de búsqueda, el sistema funcionaría mucho mejor y tendría una mayor calidad en sus respuestas si el motor de búsqueda y los datos que en él residen fueran recolectados cautelosa y selectivamente.
Como Pangea se centra en el servicio para viajeros y turistas, es recomendable incrementar distintos modelos BERT en varios lenguajes.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.
La declaración de facturas es uno de los deberes que tienen un porcentaje de la población boliviana, ya sean contribuyentes dependientes o independientes. Si bien es posible importar los datos de una factura electrónica por medio del escaneo de un código QR. El realizar dicha transcripción de una factura manual llega a ser más complicado, lento y moroso, a la hora de transcribir el número de NIT, el número de autorización y el número de factura de cada una. Especialmente para personas que no son muy familiarizadas con sistemas computacionales, siendo este una parte importante de la población adulta en Bolivia.
Figura 1. Imágenes de una Factura Manual
Figura 2. Imágenes de una Factura Manual y una Factura Digital
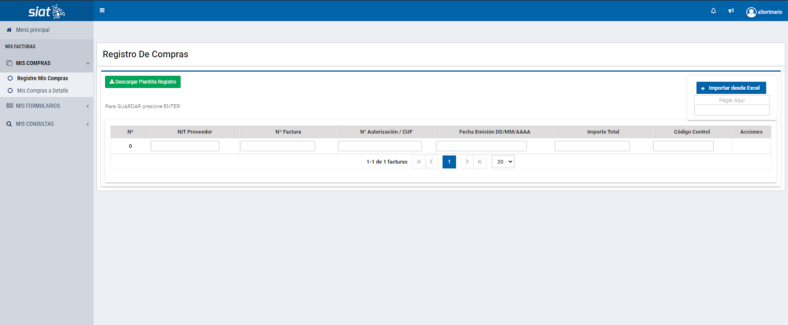
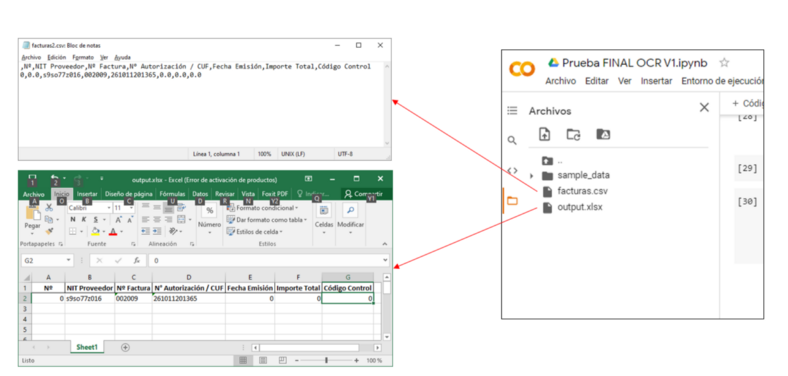
Es por ello, que el presente proyecto es un prototipo de un sistema de reconocimiento óptico de caracteres que identifique los valores previamente mencionados. Y por consiguiente permita al usuario exportar dicha información en un archivo CSV o XLSX, para su fácil importación en la plataforma de declaración de facturas SIAT (Sistema Integrado de Administración Tributaria).
Figura 3. Pantalla principal de la plataforma SIAT, para la importación de datos de facturación.
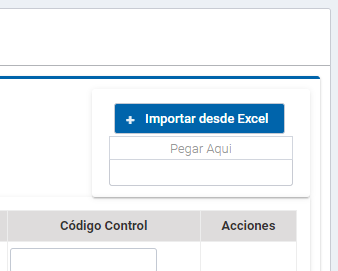
Figura 4. Botón de importación de archivos xls o xlsx.
Descripción del problema
El problema identificado es la cantidad de tiempo que se invierte a la hora de transcribir la información de cada una de las facturas manuales; tanto a personas con tiempo limitado por múltiples actividades personales o profesionales, como a personas con poca habilidad computacional.
Objetivo
El proyecto busca facilitar la detección de los datos más largos de facturas manuales, siendo estos el número de NIT de la empresa, el número de autorización, y el número de factura. Para su posterior exportación en formatos CSV o XLSX para su posterior importación en la página de Mis Facturas del SIAT (Sistema Integrado de Administración Tributaria).
Selección del modelo
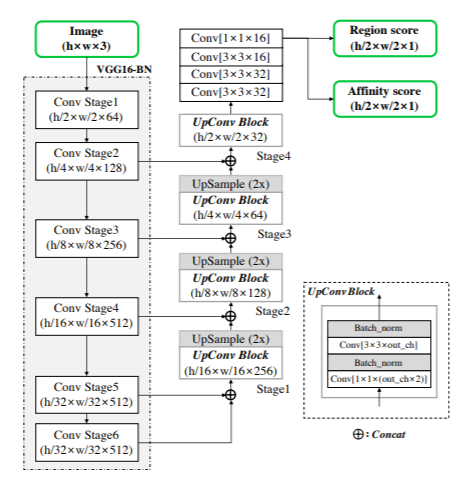
CRAFT
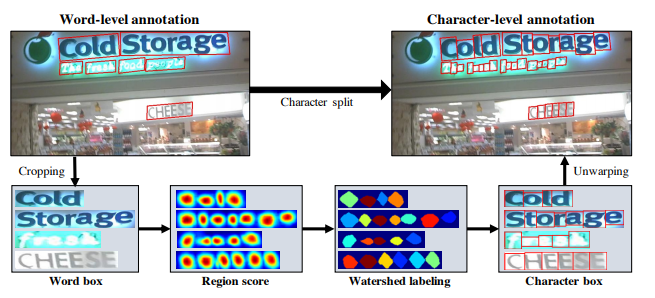
Se utiliza CRAFT (Character-Region Awareness For Text detection) [1], esto debido a que nos permite localizar las regiones de caracteres individuales y vincular los caracteres detectados a una instancia de texto. Se podría haber utilizado Tesseract el cual es un módulo de ORC pero falla en textos con curvas y formas irregulares en ciertos tipos de fuentes.
Figura 5. Ilustración esquemática de la Arquitectura del modelo CRAFT
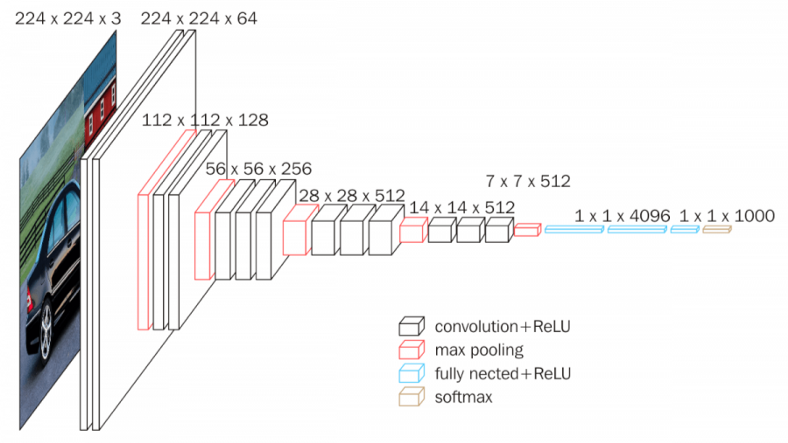
La arquitectura se basa en la red neuronal convolucional CNN, VGG-16 [2], es esencialmente para la extracción de características que se utiliza para codificar la entrada de la red en una determinada representación de características y el segmento de decodificación de la red CRAFT.
Figura 6. Modelo de la CNN VGG-16.
Técnicas implementadas
Las técnicas implementadas por el modelo CRAFT son las básicas para la detección de caracteres, como ser: cortes, rotaciones y/o también variaciones de colores.
Figura 7. Procedimiento de división de caracteres para lograr anotaciones a nivel de caracteres a partir de anotaciones a nivel de palabra: 1) Se recorta la imagen a nivel de palabra; 2) Se predice la puntuación de la región; 3) Se aplica el algoritmo watershed; 4) Se obtienen los cuadros delimitadores de caracteres; 5) Se desempaquetan los cuadros delimitadores de caracteres.
Evaluación de modelos
Al ser un modelo pre-entrenado de KERAS-OCR, con el modelo de CRAFT [3]. Podemos ver su eficacia con respecto a otros modelos similares para la detección de caracteres:
.
Figura 8. Comparativa de diferentes modelos, donde se utilizaron los dataset ICDAR y MSRA-TD500. Dónde: P es la Precisión, R es Recall, H es la H-mean y FPS los cuadros analizados por segundo [4].
Análisis de resultados
Una vez importada la imagen de la factura, se obtienen todos los valores que son detectados en la misma. Por lo que cortamos la imagen en dos, para tener solamente la parte derecha; donde se encuentran los datos que intentamos recopilar. Ya que como se ve en la Figura 9, la cantidad de datos es excesiva.
Figura 9. Detección de caracteres de una factura manual.
Una vez tenemos todos los datos detectados y convertidos en tipo STRING, en un dataframe creado con Pandas. Comparamos cada una de las columnas, buscando el texto deseado. Por tal motivo, comparamos la cantidad de caracteres que tiene el NIT del proveedor (de 8 a 10 caracteres), el Número de autorización (14 a 16 caracteres) y el Número de factura (4 a 6 caracteres). Por lo que, hallamos tras la búsqueda de columnas el valor deseado.
Figura 10. Detección de valores deseados, transformación a un dataframe con Pandas y conversión de los datos a STRING para su posterior comparación.
Finalmente, guardamos estos valores en un dataframe creado, con la misma distribución que pide el sistema de mis facturas de la plataforma SIAT. Y exportamos en CSV, o XLSX. Y como se ve en la figura 11.
Figura 11. Exportación de datos generados a los archivos CSV y XLSX.
Conclusión
Por medio de este prototipo, se puede identificar los valores más relevantes y complicados de transcribir para la mayoría de las personas que realizan su declaración de facturas. Además, que el importarlos desde una foto o imagen escaneada reduce drásticamente el tiempo de transcripción de datos. Lo que sería de mucha ayuda para personas no muy familiarizadas con las computadoras, como un buen porcentaje de adultos mayores en el país.
Si bien, muchos datos son identificados. El mayor problema reside en la calidad de la imagen tomada, ya que si esta no tiene una buena nitidez o tamaño llega a tener problemas con la identificación de algunos caracteres. Y que para trabajos futuros se podría intentar solventar con un entrenamiento más personalizado y no basándose en uno pre entrenado.
A su vez, el realizar una GUI (Interfaz gráfica de usuario), ayudaría bastante en poder llevar a este prototipo a ser más amigable con el usuario. Y por ende, facilita la importación de imágenes o facturas escaneadas para su reconocimiento de caracteres y exportación final.
[2] M. ul Hassan, “VGG16-Convolutional Network for Classification and Detection,” en l{\’\i}nea].[consulta 10 abril 2019]. Dispon. en https//neurohive. io/en/popular-networks/vgg16, 2018.
[4] Y. Baek, B. Lee, D. Han, S. Yun, and H. Lee, “Character region awareness for text detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 9365–9374.
El resumen de texto es el proceso de extraer la información más importante de un texto fuente para producir una versión abreviada para un usuario. Los seres humanos llevamos a cabo la tarea de resumen, ya que tenemos la capacidad de comprender el significado de un documento y extraer características destacadas para resumir los documentos utilizando nuestras propias palabras. Sin embargo, los métodos automáticos para el resumen de texto son cruciales en el mundo actual, donde hay falta de trabajadores y de tiempo para interpretar los datos.
Figura 1: Cantidad de datos generados de manera anual
Problema
Figura 2:Idiomas predominantes en internet
Hoy en día, con el constante crecimiento de la información el estar actualizados en cualquier tema es una necesidad. Pero las fuentes de información usualmente son extensas y poseen una gran cantidad de texto pero lo más importante es que la información está en inglés.
Objetivo
Desarrollar una aplicación que pueda ayudar a la comprensión de un documento de texto en inglés y acorte el tiempo de comprensión de un texto largo.
Solución propuesta
Hacer la aplicación en base a métodos de DeepLearning enfocados a attention mechanism. Estas técnicas imitan la atención cognitiva. Esto provoca la mejora en las partes más importantes de los datos de entrada y desvanece el resto.
Dataset
CNN Daily Mail es un conjunto de datos de más de 300 mil artículos en inglés escritos por periodistas en CNN y en Daily Mail. El tamaño del conjunto de datos es de 1.27 GiB en la versión actual, esta admite el resumen extractivo y abstracto, aunque la versión original se creó para la lectura y comprensión automática y la respuesta a preguntas abstractas. Los datos se pueden usar para entrenar un modelo para el resumen abstracto y extractivo
Modelo de DL
Figura 3: Esquema BART
BART es una arquitectura que se basa tanto en BERT y GPT, BART utiliza la arquitectura de transformer seq2seq estándar pero, después de GPT, que modificamos las funciones de activación de ReLU a GeLU. La arquitectura está estrechamente relacionada con BERT, con las siguientes diferencias:
Cada capa del decodificador, además, realiza una atención cruzada sobre la capa oculta final del codificador (como en el modelo de secuencia a secuencia del transformador)
BERT utiliza una feed-forward network antes de la predicción de palabras, lo que BART no hace.
Entonces en pocas palabras usa la comprensión de texto o input de BERT y GPT para el output o la generación de palabras.
Para trabajar con este modelo se lo hizo mediante el modelo base que nos provee HuggingFace.
HuggingFace es una plataforma Open Source que se enfoca en NLP, nos ayuda a construir, entrenar e implementar modelos que son estado del arte. En este caso nos ayudó a construir el modelo y con el dataset.
Entrenamiento del modelo
El proyecto fue realizado en base a los modelos provistos por la página de Hugging Face, la cual posee una gran colección tanto de modelos como de datasets para tareas de NLP (Procesamiento de Lenguaje Natural). De todas las opciones se seleccionó el modelo de sumarización abstractiva BART.
El código hace uso de las librerías “datasets” y “transformers” de HuggingFace, además de nltk para realizar la evaluación.
# Imported libraries from datasets import load_dataset, load_metric from transformers import AutoTokenizer from transformers import AutoModelForSeq2SeqLM, DataCollatorForSeq2Seq, Seq2SeqTrainingArguments, Seq2SeqTrainer import nltk import numpy as np from transformers import pipeline
Para realizar el fine tuning se hizo uso del dataset “cnn_dailymail”, para la evaluación se utilizó la métrica “rouge”, y el modelo base que se usó fue “facebook/bart-base”.
Del dataset “cnn_dailymail” se extrajeron los elementos que se encuentran bajo las etiquetas de “article” y “highlights” como datos de entrada y salida respectivamente.
max_input_length = 512 max_target_length = 128def preprocess_function(examples): inputs = [doc for doc in examples[“article”]] model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True) # Setup the tokenizer for targets with tokenizer.as_target_tokenizer(): labels = tokenizer(examples[“highlights”], max_length=max_target_length, truncation=True)model_inputs[“labels”] = labels[“input_ids”] return model_inputstokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
Antes de entrenar el modelo se realiza la configuración de hiperparámetros.
Se crea una función para realizar el cómputo de métricas haciendo uso de rouge score.
def compute_metrics(eval_pred): predictions, labels = eval_pred decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True) # Replace -100 in the labels as we can’t decode them. labels = np.where(labels != -100, labels, tokenizer.pad_token_id) decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Rouge expects a newline after each sentence decoded_preds = [“\n”.join(nltk.sent_tokenize(pred.strip())) for pred in decoded_preds]decoded_labels = [“\n”.join(nltk.sent_tokenize(label.strip())) for label in decoded_labels]
result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True) # Extract a few results result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
# Add mean generated length prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in predictions]result[“gen_len”] = np.mean(prediction_lens)
return {k: round(v, 4) for k, v in result.items()}
Una vez inicializado el modelo, definidos los hiperparámetros, datasets, tokenizer y métricas creamos un Trainer.
Descargamos punkt tokenizer que nos permite transformar un texto por oraciones.
nltk.download(‘punkt’)
Finalmente realizamos el entrenamiento y la evaluación
trainer.train()trainer.evaluate()
Resultados
Figura 4:Pérdida a lo largo del entrenamiento
Una vez finalizada la fase de entrenamiento podemos observar la pérdida a lo largo del entrenamiento realizado en el dataset “train”.
Si bien se muestran buenos resultados, se pueden mejorar haciendo mejor sintonización y tiempos de entrenamiento con el modelo.
Los resultados obtenidos al evaluar el modelo entrenado con la métrica rouge score fueron los siguientes:
eval_loss: 1.5510817766189575
eval_rouge1: 46.8771
eval_rouge2: 23.5647
eval_rougeL: 39.6525
eval_rougeLsum: 43.3625
eval_gen_len: 17.8154
Conclusiones
Se logró realizar una aplicación que resume y traduce el texto dado, se vio que los resultados obtenidos son óptimos para la tarea.
Se usó dos modelos para hacer la aplicación, el primer modelo es el que se entrenó de resumen este modelo ya esta en huggingface , para la parte de traducción se usó un modelo ya entrenado de huggingface. (https://huggingface.co/Helsinki-NLP/opus-mt-en-es).
Trabajo Futuro
Mejorar los tiempos de inferencia que tienen los modelos al usar servicios en la nube.
Expandir los tipos de entradas que pueda tener, puesto que ahora solo soporta texto puro. (txt, docx)
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) a la vez que se realizan proyectos para el bien (#ai4good). Los talleres que realizamos forman parte del programa AI 4 Schools para que cualquier persona “aprenda haciendo” IA sin importar su especialidad o nivel de partida.