La COVID-19 es la enfermedad causada por el nuevo coronavirus conocido como SARS-CoV-2. La OMS tuvo noticia por primera vez de la existencia de este nuevo virus el 31 de diciembre de 2019, al ser informada de un grupo de casos de «neumonía vírica» que se habían declarado en Wuhan (República Popular China). En este artículo intentaremos describir la forma de aplicar Machine Learning para detectar el Covid-19.
Se llama SARS-CoV-2, por las siglas:
“SARS” porque puede producir un “Síndrome Respiratorio Agudo Grave” (siglas en inglés: Severe Acute Respiratory Syndrome, SARS).
“CoV” porque es un coronavirus.
“2” porque ya existió un virus parecido en 2002–2003 que producía también SARS.
¿QUÉ PRUEBAS SE UTILIZAN PARA DIAGNOSTICAR EL COVID-19?
PCR
Las PCR (siglas en inglés de “Reacción en Cadena de la Polimersa”), son un tipo de pruebas de diagnóstico que se llevan utilizando durante años en diferentes crisis de salud pública relacionadas con enfermedades infecciosas. Estas pruebas se están usando desde los primeros días del estallido de la pandemia de coronavirus en España. Sin embargo, los test rápidos se han incorporado recientemente y, como su nombre indica, son más rápidos y sencillos. Ambos sirven para comprobar si una persona está infectada o no por el Covid-19.
ANTÍGENO
Prueba de antígeno. Esta prueba para la COVID-19 detecta ciertas proteínas en el virus. Se usa un hisopo para tomar una muestra de fluido de la nariz, y las pruebas de antígeno pueden dar resultados en minutos.
RADIOGRAFÍA DE TÓRAX
Los escáneres o las radiografías producen una imagen de los órganos y estructuras (corazón, pulmones y vías respiratorias) del tórax. Pueden detectar bloqueos, inflamación y exceso de líquido.
Las radiografías utilizan una pequeña cantidad de radiación para producir una imagen en dos dimensiones. Por lo general, las realiza un radiólogo en el hospital mediante un equipo fijo, pero también se pueden hacer con una máquina portátil.
La tomografía computarizada (TC) utiliza una computadora para fusionar varias radiografías tomadas desde diferentes ángulos y producir así una imagen bidimensional que se puede convertir en una imagen tridimensional. Requiere de un equipo muy especializado y la realiza en el hospital un radiólogo especialista.
Se pueden realizar en un hospital o en otros centros sanitarios, como la consulta de un médico o una clínica.
PROBLEMÁTICA
Dado que hay kits de prueba de COVID-19 son de acceso limitado para la población en general, debemos confiar en otras medidas de diagnóstico.
IMÁGENES DE RAYOS X
En el campo de la medicina se utilizan con frecuencia radiografías y tomografías computarizadas para diagnosticar neumonía, inflamación pulmonar, abscesos y / o ganglios linfáticos agrandados. Dado que COVID-19 ataca las células epiteliales que recubren nuestro tracto respiratorio, podemos usar rayos X para analizar la salud de los pulmones de un paciente.
Una gran mayoría de los hospitales tienen máquinas de imágenes de rayos X, se plantea la siguiente pregunta: ¿Cómo se podría detectar COVID-19 en imágenes de rayos X?, sin los kits de prueba dedicados.
OBJETIVOS
Recopilar las entradas del modelo en datasets para el entrenamiento, pruebas y validación.
Desarrollar un modelo de diagnóstico del covid a través de imágenes de rayos X usando deep learning, con un porcentaje de confiabilidad aceptable.
Evaluar los resultados del modelo a través de la matriz de confusión.
DESARROLLO DEL MODELO
Para el desarrollo del modelo se ha utilizado un dataset del repositorio de kaggle que tiene un total de 5.856 imágenes, se ha usado radiografías de pacientes que tenían neumonía porque estos pacientes tienen una alta probabilidad de tener covid-19.
Para la construcción del modelo de Machine Learning para detectar el Covid-19 se utilizó Redes Neuronales Convolucionales, porque son redes neuronales diseñadas y ampliamente usadas para trabajar con imágenes.
Las redes convolucionales contienen varias hidden layers, las cuales se encargan de detectar líneas, curvas y así con las convoluciones se permitirá detectar formas más complejas como siluetas, rostros, etc.
Las herramientas utilizadas son: Tensorflow y keras. Tensorflow es una plataforma de código abierto usada para aprendizaje automático compuesta por un conjunto de herramientas, librerías y recursos que facilitan el trabajo en el desarrollo e implementación de soluciones con inteligencia artificial (IA). Keras es una librería, actualmente es API de alto nivel que proporcionan interfaces que simplifican el trabajo en el desarrollo de aplicaciones con IA, a partir de la versión 2.0 keras ya viene integrada dentro de Tensorflow.
DESARROLLO DEL PROYECTO
Debido a que es una pequeña prueba de concepto de clasificación de imágenes para un curso introductorio a Deep Learning, se ha subido las imágenes del dataset a una carpeta de google drive y para el desarrollo del modelo Machine Learning para detectar el Covid-19 se utilizó los servicios de colab.research de Google.
Las imágenes fueron ajustadas a un tamaño de 500×500, para poder entrenar, en la siguiente imagen se observa una radiografía de un paciente normal.
Con la integración de Keras con Tensorflow, se tienen nuevas clases como “ImageDataGenerator” que facilitan la carga de imágenes:
Las imágenes fueron divididas en 3 grupos: entrenamiento, pruebas y validación.
El modelo de clasificación se puede observar en la siguiente gráfica:
EVALUACIÓN DEL MODELO
Para realizar la evaluación se ha utilizado la matriz de confusión:
Donde se puede observar que el modelo ha identificado:
Para personas que estaban sanas y que el modelo predijo como personas sanas fueron 175 casos de verdaderos negativos (VN).
Para personas que estaban enfermas y que el modelo predijo como personas enfermas fueron 384 casos de verdaderos positivos (VP).
Para personas que estaban enfermas y que el modelo predijo como personas sanas fueron 59 casos de falsos negativos (FN).
Para personas que estaban sanas y que el modelo predijo como personas enfermas fueron 6 casos de falsos positivos (FP).
Con estos datos podemos calcular los siguientes indicadores:
Exactitud = (VP + VN) / (VP + VN + FN + FP)
Exactitud = (175 + 384) / (175 + 384 + 59 + 6)
Exactitud = 0,8958
La exactitud es la cantidad de predicciones que fueron positivas que fueron correctas y se llegó a un valor de 89,58%
Precisión = VP / (VP + FP)
Precisión = 384 / (384 + 6)
Precisión = 0,9846
La precisión es el porcentaje de casos positivos detectados llegó a un valor de 98,46%
Sensibilidad = VP / (VP + FN)
Sensibilidad = 384 / (384 + 59)
Sensibilidad = 0,8668
La sensibilidad es la proporción de casos positivos correctamente identificados llegó a un valor de 86,68%
Especificidad = VN / (VN + FN)
Especificidad = 175 / (175 + 59)
Especificidad = 0,7478
La especificidad trata de la cantidad de casos negativos correctamente identificados llegó a un valor de 74,78%.
ANÁLISIS DE RESULTADOS
Del proceso de desarrollo del modelo, de acuerdo a las librerías de Keras y Tensorflow pudimos llegar a una precisión del 89,59 %.
Con los resultados obtenidos podemos observar en la figura que el valor de la precisión se mantuvo por encima del 80%, el valor de la pérdida fue inferior al 20 %.
CONCLUSIÓN
De acuerdo a los resultados obtenidos se tiene:
El valor de confiabilidad del modelo es aceptable, representado por el 89%.
El modelo de diagnóstico del covid a través de imágenes de rayos X usando Machine Learning, podría aplicarse en nuestro medio como otra alternativa de diagnóstico.
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.
El proyecto comenzó con esta pregunta: ¿Será posible mejorar la toma de decisiones en al Industria textil con Machine Learning? Después de decidir que queríamos responder a la incógnita decidimos la industria y como sabemos en Bolivia y encontramos a la industria textilera que hasta el 2015, tuvo una contribución de la industria textil boliviana al Producto Interno Bruto (PIB) era del 0,9%, equivalente a 451 millones de dólares,sin embargo este sector se ve severamente afectado por varios problemas tales como:
Mercadería Ilegal que ingresa al País
Ropa usada
Prendas chinas
Porque vimos estos problemas y creemos que Bolivia puede mejorar su competitividad escogimos al sector de la industria textil para aplicarle Machine Learning.
DESARROLLO
Encontramos el dataset en Kaggle, este tenía las siguientes variables (están traducidas al español al lado):
date – Fecha ()
smv – valor promedio por trabajo
day – Dia (Lun-Dom)
wip – trabajos en cola
quarter – 5 periodos / mes
over time – sobrehora
department – departamento
incentive – incentivo
teamno – # de equipo
idle time – tiempos ociosos
no of workers – # de trabajadores
idleman – # de trabajadores ociosos
no of style change – # de cambios
actual productivity – productividad actual
targeted_productivity – productividad esperada
Nuestro dataset obtenido de Kaggle tenía esas características, después de ver las variables vimos que la variable SMV valor (promedio de trabajo) tenía algunos huecos,por lo que viendo su distribución decidimos rellenarla con la tendencia de la media y así ya obtuvimos todos los datos listos para trabajar.
Comenzamos con la idea de regresión pero los métodos parecían no servir o nos daban unos resultados muy bajos por lo cual tuvimos que cambiar de aproach, después se procedió a un problema de clasificación, realizamos una normalización de los datos y ya con los datos trabajados comenzamos a trabajar,acá un ejemplo de la matriz de correlación que logramos obtener una vez pasamos a la parte de clasificación de datos con datos ya normalizados.
Después se comenzó a probar modelos,el con mejores resultados predictivos fue ADAboost(insertamos imagen referencial)
Logramos un 0.82 de accuracy lo cual fue simplemente increible despues de ver como otros métodos no llegaban ni al 0.50, decidimos probar con varios modelos adicionales como Random Forest, pero la precisión era menor (no por mucho)
Al final nos quedamos con Adaboost y logramos un trabajo excelente.
CONCLUSIONES
Con los modelos de regresión de acuerdo al rendimiento (scores de 0.5) calculado, no se acomodan al dataset propuesto, se realizó un tratamiento al target para volver un problema de clasificación.
Los modelos de clasificación aplicados al dataset dieron resultados favorables en especial Adaboost con un score de 0.82
Los mecanismos y procesos de machine learning permitieron en el problema reutilizar el modelo como uno de clasificación.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Todos sabemos la importancia de las plantas y a muchas personas les gustaría tener plantas en casa, pero existen varios problemas que lo impiden como por ejemplo el tiempo disponible para cuidarlas. El presente proyecto plantea resolver estos problemas por medio del Machine Learning creando un huerto inteligente que reconoce que planta va a cuidar y aplica un protocolo de cuidado adecuado. Las tecnologías usadas son redes neurales convolucionales, visión artificial, python y arduino.
Las plantas son una parte importante de nuestro diario vivir y no nos damos cuenta de su importancia. Las plantas en casa vienen con muchas ventajas como es la reducción de contaminación del aire, la reducción de estrés, y la reducción de la contaminación acústica. Pero, con tantas ventajas ¿porque no´ todos tenemos plantas en casa?
Esto pasa porque existen algunos problemas a la hora de tener plantas en casa. Los tres principales problemas son: La falta de conocimiento, descuido y falta de tiempo. El proyecto consiste en un huerto inteligente para los hogares de personas que quieren tener plantas en casa. El huerto reconocería la planta que va a cuidar por medio de visión artificial y redes neurales convolucionales y aplicaría un protocolo adecuado para la planta. Gracias a esto cualquier persona podrá tener plantas en casa sin tener el tiempo o el conocimiento que esto conlleva.
TECNOLOGÍA USADA
· CNN
· Visión artificial Python
· Arduino
· Dataset propio
El modelo utilizado para la creacion del huerto inteligente aplicando Machine Learning es una red YOLOv5 la cual se modifica para aceptar las clases de nuestro dataset. Por ahora el dataset solo cuenta con siete clases (tipos de plantas) por el tiempo que implica crear un dataset, aun así, se logró un funcionamiento aceptable. El código se realizó en Jypiter y el dataset en la web Roboflow.
FUNCIONAMIENTO
El huerto, por medio de una cámara, recoge la imagen de la planta que se procesa por medio de redes neurales convolucionales y visión artificial para así obtener una predicción de que planta está en el huerto. Después, esa predicción hace que se mande una señal, dependiendo de la planta que se identificó, a un arduino el cual al recibir esta señal selecciona el protocolo de cuidado dependiendo el tipo de planta y así controla los tiempos de regado y la cantidad de agua.
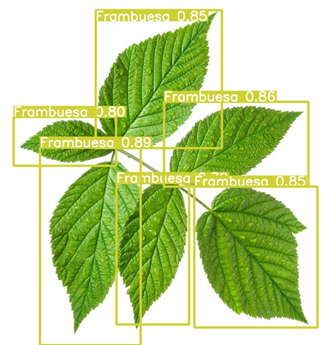
Figura 2. Detección de Frambuesa
OBSERVACIONES
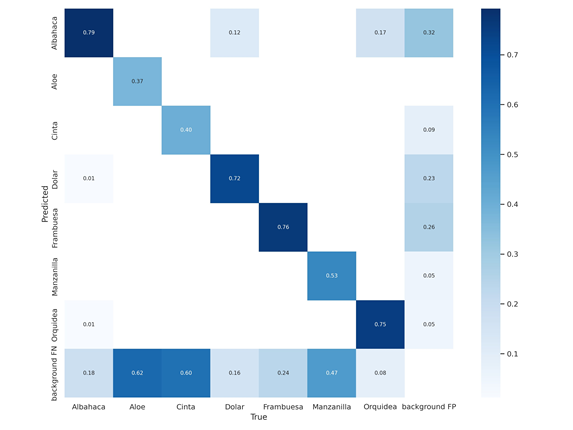
Figura 3. Matriz de confusiónFigura 4. Resultados
Como se puede observar en los resultados, después del entrenamiento, se logró una precisión de 0.52 sin llegar a un overfeating. Esto se debe a la falta de datos en el dataset. También se puede observar que hay una gran confusión entre las plantas de Aloe y Cinta, posiblemente el error se debe al parecido de las hojas y la falta de imágenes en el dataset. Aun así, en las pruebas realizadas en otras plantas como la orquídea y la frambuesa son satisfactorias.
PROXIMOS AVANCES
Actualmente se continua la mejora del dataset para obtener más imágenes y de esta manera el huerto pueda reconocer mayor cantidad de plantas y con mayor precisión. También se está experimentando con diferentes modelos de deep learning para mejorar el funcionamiento del huerto.
Se planea mejorar mucho la estructura para tener un diseño más estético y cómodo para los hogares de personas en el área urbana. Además, se planea mejorar la parte del hardware para minimizar costos de producción y controlar más factores externos como la temperatura y la luz.
Finalmente se espera poder implementar una versión del huerto para cultivos a gran escala.
Presentación del proyecto: DemoDay
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.
Durante la última década, la explosión de la cantidad de datos disponibles, la optimización de algoritmos y la evolución constante de la potencia informática han permitido que la inteligencia artificial (IA) realice cada vez más tareas humanas [1]. Y desde hace un tiempo la inteligencia artificial se ha convertido en una poderosa herramienta para devolvernos al pasado. Lo demuestran la cada vez mayor cantidad de imágenes y videos restaurados a través de diferentes técnicas de inteligencia artificial, como por ejemplo la capacidad de colorear videos en blanco y negro.
En términos de coloración de imágenes y videos la Inteligencia artificial ha evolucionado y durante los últimos años se ha observado una mejora significativa. Ya que la coloración manual requiere una gran cantidad de tiempo y es un proceso costoso, la aplicación de técnicas de inteligencia artificial es una gran opción para este tipo de tareas porque es capaz de trabajar por sí misma y colorear automáticamente en un corto periodo de tiempo [2].
Problemática
Existen pocos registros filmográficos que capturen la vida cotidiana de antaño de nuestro país es por ello que quisimos tener otra perspectiva de estos videos añadiendo color a los pocos que encontramos.
Objetivo
Extraer imágenes de videos antiguos para darles color haciendo uso de una red GAN, para posteriormente generar un video a color.
Dataset
El dataset se pudo obtener a partir de videos encontrados en youtube, de tipo documental y grabaciones de los distintos paisajes de Bolivia, se usaron 10 videos distintos ya que se tienen videos antiguos a color, que tienen un color más opaco, otros videos de los paisajes con un color más definido pero con una calidad no mayor a 480p, y otro con una calidad mayor. No se tomaron todos los frames de estos ya que se optó por usar los frames significativos y asi no tener varios frames de una misma escena.
Selección del modelo y técnicas usadas
La arquitectura usada para colorear mediante Inteligencia Artificial fue la de Unet-GAN por su gran capacidad para sintetizar las características de las imágenes lo que mejora ampliamente los resultados finales.
Una red generativa antagonica (GAN) tiene dos redes. Una es el discriminador que intentará discriminar entre imágenes reales y falsas. Y la segunda red de la GAN es el generador que se encargará de generar imágenes falsas pero muy cercanas a las imágenes originales más bien podemos decir que las imágenes falsas estarán en la misma distribución de las imágenes originales.
UNET se utiliza básicamente en problemas de segmentación de imágenes donde las dimensiones de entrada y salida son las mismas. GAN intenta generar nuevas imágenes a partir de un ruido aleatorio. Entonces, el generador de GAN tiene muy pocas dimensiones en la entrada, pero la salida es en gran dimensión. Puede usar UNET como generador en el GAN (pix2pix usa esto).
En este caso, generará imágenes falsas no a partir de ruido aleatorio sino de otra imagen de referencia. Tiene otras opciones como red deconvolución, codificador automático, etc.
Al inicio se realizó la obtención de videos, se segmentó los videos en frames que se usaron como ground truths, se estandarizó las imágenes a un tamaño y se hizo la conversión de los frames RGB a grayscale para usarlos como inputs. Al finalizar con el proceso de colorización se unió los frames resultantes para convertirlos de nuevo en video.
Análisis de resultados
En la gráfica 1 podemos observar la pérdida del discriminador y la del generador y se puede ver que existe una tendencia exponencial y que la pérdida es estacionaria en el valor 0.4 para el discriminador y 0 para el generador.
Gráfica 1. Pérdida del discriminador y del generador
Se puede apreciar en las imágenes de entrenamiento con 600 épocas que se llega a tener un color correcto, pero no tan intenso como en las imágenes RGB reales, también se puede ver que llega a tener errores cuando se tiene una sección con mayor brillo en la imagen, como ser rayos del sol o secciones de blanco.
Con las imágenes de testeo se puede ver que las imágenes se llegan a colorear pero se sigue teniendo el problema con las secciones de brillo y que tiene una mayor predisposición a la gama de rojos y azules.
En las imagenes del video en blanco y negro elegido para poner a prueba nuestro modelo se tiene una buena coloracion siendo que al ser una grabacion de la ciudad de La Paz-Bolivia se tiene más imagenes de edificios no se necesita tener una gran variedad de colores, el color más intenso que se ve es en el cielo.
Conclusión y recomendaciones
Se logró implementar un modelo con arquitectura Unet-GAN capaz de colorear imágenes en blanco y negro y con el conjunto de las imagenes coloreadas se obtuvo un video a color, todo este proceso nos permitio familiarizarnos con modelos de Inteligencia Artificial del tipo Deep Unsupervised Learning, preparación de datasets, lenguaje Python, librerias especializadas en Deep learning y Colab como herramienta para la implementacion de nuestro modelo. Los resultados son aceptables sin embargo quedan algunas falencias que subsanar como que ciertas imágenes con brillo que forman parte de nuestro dataset de entrenamiento presentan error al momento de ser reproducidas por la GAN, además algunas colorizaciones no son completas, esto debido a que el dataset no contaba con muchas variaciones de color, por lo tanto es recomendable ampliar la paleta de colores con las que se realiza el entrenamiento.project_color.mp4Edit descriptiondrive.google.com
[2] film colorization, colorize video, colorize black and white videos, colorize video software, film colorization software, colorization of film. (n.d.). Retrieved December 4, 2021, from https://pixbim.com/film-colorization
Códigos
Código para la recoleccion del dataset a partir de videos descargados de youtube
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.
Existen diversos servicios para viajeros, desde páginas de hoteles hasta ofertas turísticas a unos cuantos clics de distancia, no obstante, el ser humano ha conseguido su información por siglos y siglos a través de preguntas y bases de conocimiento, por lo que le es más natural hacer consultas de esa forma, así surge Pangea, como un servicio web de Inteligencia Artificial conversacional con el que el viajero puede interactuar y conseguir las respuestas a sus más inquietantes preguntas.
Un viajero prudente nunca se lanza a viajar si no tiene la información más relevante de su destino, en su cabeza se encuentran preguntas que en primera instancia cuestionan su seguridad, por lo que investiga al respecto y logra resolver sus dudas en probablemente muchos minutos, de igual forma si ya se aventuró a viajar y necesita conocer alguna costumbre, plato típico, música o lugares para visitar, son tantas las preguntas y mucho el tiempo invertido en responderlas, de esa forma los viajeros pierden tan importante recurso.
Por lo que al usar textos como datos a analizar en la tarea de respuesta a preguntas se requiere el uso de Natural Language Processing (NLP) o en español conocido como el procesamiento del lenguaje natural, entiéndase como la rama de la Inteligencia artificial (IA) que entrena a una computadora para comprender, procesar y generar lenguaje (conversacional).
Descripción del problema
Concretamente el problema es el tedioso y tardío acceso a respuestas inmediatas sobre dudas y consultas acerca de un destino turístico, como ser: comida, hospedaje, actividades turísticas, transporte, centros de salud, cultura, música, conflictos políticos, entre otros.
Objetivo
Desarrollar mediante Inteligencia Artificial un servicio web conversacional de pregunta-respuesta para viajeros aplicando NLP mediante la aplicación de un modelo dedeep learning.
Técnicas implementadas
Se presentan las técnicas complementarias a la resolución del problema, ya que todo modelo de Deep Learningrequiere ser alimentado por datos.
Búsqueda de datos
La Inteligencia Artificial conversacional Pangea se centra en responder preguntas y no sería posible sin cantidades ingentes de información con las cuales interactuar y usarlas como una fuente de conocimiento (contexto), en ese sentido, se realizó la búsqueda de páginas web que contengan las respuestas más coincidentes de acuerdo a la pregunta del usuario viajero; hacerlo de forma manual representaría demasiado trabajo, por lo cual, se decidió usar la biblioteca de Python, Google Search, el cual emplea al motor de búsqueda Google como fuente de información para brindar las URLs de los sitios webs requeridos.
Captura de datos
Una vez obtenidas las URLs de los sitios webs que contienen la información requerida, se empleó la técnica del Web Scraping para obtener el contenido literal de dichos sitios, es decir, los distintospárrafos y textos presentes en el sitio. Web Scraping es una técnica cuyo objetivo es recolectar información de la web a través de código. En este caso se usó la biblioteca Beautiful Soup disponible en pypi.
Selección y evaluación del modelo
Modelo Bert: es un codificador bidireccional de transformers, que aprende a interpretar el lenguaje.
Cuando al modelo Bert se le añade capas adicionales y es entrenado con un propósito o tarea especializada, se obtiene un modelo Bert que resuelve una tarea en específico.
En el proyecto se aplicó ya modelos ajustados para la tarea de pregunta y respuestas, que fueron previamente ajustados mediante el dataset de los conjuntos de datos de respuesta a preguntas Stanford(SQuAD).
Ambos modelos fueron obtenidos y reutilizados de la biblioteca hugging Face Transformers. Dichos modelos reciben una pregunta y un contexto para procesarlo y analizarlo con el fin de devolver las respuestas que mejor se ajusten a la pregunta.
La elección del mejor modelo fue dado en base a los resultados:
Bert en inglés:bert-large-uncased-whole-word-masking-finetuned-squad
Bert en español (Beto): distill-bert-base-spanish-wwm-cased-Finetuned-spa-squad2-es
Tabla 1. Evaluación de Modelos
Se seleccionó y grafico un caso en específico, para demostrar como se comportan ambos modelos a una misma pregunta y cuales son las respuestas textuales que dan cada uno en su respectivo lenguaje, figura 1.
Figura 1. Gráfico de barras — Representación de respuestas Modelo Bert y Beto a la misma pregunta.
Flujo de Trabajo del Sistema
El sistema consta de distintos procedimientos para resolver una determinada pregunta, por lo que el usuario viajero debe partir lanzando una pregunta, posteriormente el sistema realiza una búsqueda con Google Search en relación a tal pregunta y devuelve unas cuantas URLs (máximo 5) con las que el web scraper realiza la tarea de extraer todo el texto (párrafos) del sitio hospedado en la URL para pasarle como contexto al modelo, el modelo utiliza el contexto, la pregunta y lanza una respuesta, se captura la respuesta y la url,ambas son representadasen formato de mensaje de chat, figura 2.
Figura 2 . Elaboración propia
Análisis de resultados (Bert vs Beto)
Pangea devuelve las respuestas y la URLs de donde han sido obtenidas tales respuestas, según la cantidad de pruebas se puede observar que el uso de Beto se adecua más según el porcentaje de aciertos. Y en las gráficas se visualiza como el modelo Beto da respuestas con mayor precisión a la misma pregunta realizada en ambos idiomas de acuerdo al modelo.
Conclusión y recomendaciones
Las conclusiones obtenidas tras el desarrollo y resolución del objetivo general son:
Se obtuvo un 64.7 % de respuestas correctas de un total de 17 preguntas por parte del modelo BERT en español en relación al 30% del modelo BERT en inglés, en ese sentido, el modelo BERT pre-entrenado con mayor precisión en sus respuestas es el español, ya que las preguntas tuvieron a Bolivia como contexto principal y es razonable puesto que no muchos sitios en inglés tienen información actualizada y específica de Bolivia.
La técnica del Web Scraping aportó correctamente el contenido web necesario para que el modelo BERT pudiese responder las preguntas adecuadamente.
Dado que el servicio (Pangea) se desplegó por un momento se logró registrar el uso de 2.5 GB de memoria RAM con una demora de aproximadamente 30 segundos mientras el modelo responde a la pregunta.
El Servicio Web que se ofreció por unos instantes logró capturar la curiosidad y asombro de los usuarios por su diseño minimalista e interesante forma de interactuar.
Por otra parte las recomendaciones al respecto son:
El modelo BERT empleado fue afinado (fine-tuning ) con el dataset SQUAD el cual tiene un formato pregunta-respuesta de dominio parcialmente general, por lo que se tiene mayores expectativas con un afinado específico para el área de turismo.
La información recolectada por el servicio proviene de Google que es un motor de búsqueda, el sistema funcionaría mucho mejor y tendría una mayor calidad en sus respuestas si el motor de búsqueda y los datos que en él residen fueran recolectados cautelosa y selectivamente.
Como Pangea se centra en el servicio para viajeros y turistas, es recomendable incrementar distintos modelos BERT en varios lenguajes.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.