La Paz. Segunda Edición. 2021
En el mundo, los incendios forestales constituyen la causa más importante de destrucción de bosques. En un incendio forestal no sólo se pierden árboles y matorrales, sino también casas, animales, fuentes de trabajo e inclusive vidas humanas.
Como se puede apreciar en la Fig.1 en Bolivia los últimos siete meses este fenómeno se multiplicó de manera alarmante el área afectada debido a múltiples factores la Fig. 2 muestra algunas de las causas estudiadas para los incendios forestales. Otro factor importante identificado es el cambio climático que debido al aumento de temperatura en los lugares afectados, aumenta las áreas afectadas de manera alarmante.
Debido a las consecuencias de los incendios forestales no controlados ni planificados se deben tomar diferentes estrategias que permitan mitigar su ocurrencia en zonas protegidas o prohibidas para esta actividad.
Descripción del problema
En base a lo mencionado anteriormente se plantea el siguiente problema:
¿Cómo identificar de manera oportuna incendios forestales no controlados para minimizar su impacto?
Objetivo general
Se plantea como objetivo general implementar un modelo de Deep Learning para la detección temprana de incendios forestales mediante el reconocimiento de humo en las áreas llanas/boscosas utilizando imágenes del lugar.
El siguiente gráfico muestra la idea central del proyecto.
Recolección de la información
El dataset para realizar el entrenamiento de los modelos se realizó mediante la descarga de imágenes clasificadas como “incendio forestal” (imágenes tomadas en perspectiva con presencia de humo en zonas forestales) y “no incendio forestal” (imágenes tomadas en perspectiva en zonas forestales sin presencia de humo o fuego).
Las imágenes descargadas (4 grupos de imágenes) fueron llevadas a un repositorio github para su importación sencilla en Google Colab.

Impresión de las 8 primeras imágenes de entrenamiento y 8 primeras imágenes de validación:
Selección de los modelos
La selección de los modelos parte de las siguientes consideraciones:
- Facilidad de su implementación.
- Rendimiento del modelo.
- Limitación de cálculo.
Estas consideraciones son debido a los recursos que se tienen para realizar el objetivo general. Los modelos a desarrollarse son:
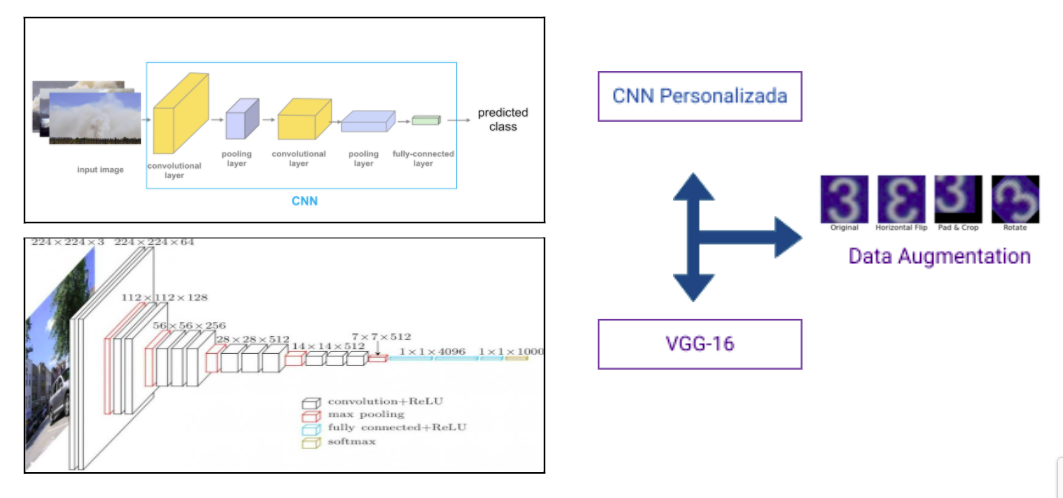
- CCN Personalizado
- VGG-16
Técnicas implementadas
La principal técnica utilizada para compensar el dataset de tamaño limitado por la limitación de búsqueda de imágenes en Google fue la de “data augmentation” realizada por la librería de keras “ImageDataGenerator”.
Evaluación de modelos
1. CNN personalizado
2. VGG-16
Análisis de resultados
A continuación se muestran los resultados del modelo CNN personalizado y VGG-16.
1. Precisión y Curva de ROC de CNN personalizado:
2. Precisión y Curva de ROC de VGG-16:
Las predicciones de los modelos a continuación:
1. CNN Personalizado
2. VGG-16
Conclusiones
El modelo CNN personalizado tiene un desempeño adecuado para la detección de incendios forestales. El modelo VGG-16 con el elemento de pre-entrenamiento requiere más elaboración para obtener resultados más precisos. De esta manera un modelo Deep Learning no siempre requiere tener una alta complejidad para realizar la clasificación de manera eficiente.
El modelo desarrollado obtiene muy buenos pronósticos para el problema planteado y es una solución complementaria al problema de incendios forestales.
La utilización de modelos de AI Deep Learning pueden ser mejor explotados como complemento a la solución de problemas coyunturales.
Integrantes
Presentación del proyecto: DemoDay
¡Más Inteligencia Artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!