Detección de estrés en tweets durante la pandemia SARS-CoV-2(COVID-19)

Latam online. Primera Edición 2020
El estrés: una ‘epidemia’ silenciosa que puede afectar a cualquier persona durante la era moderna, ahora es más notoria debido a la mayor crisis sanitaria enfrentada durante este siglo. Los niveles de preocupación, impacto económico y emocional que han tenido que afrontar las personas han sido factores que han impactado no solo la salud física también la mental de millones de personas.
En este trabajo de inteligencia artificial (ciencia de datos), se realiza un esfuerzo para analizar, predecir y determinar, si una persona está estresada con el uso de sus mensajes a través de la red social de Twitter.
Problema general
¿Es posible que una máquina pueda determinar si una persona está estresada solo con la expresión escrita?
Motivación
Social: ayudar a identificar y reconocer el estrés durante la crisis sanitaria para así conocer el estado emocional de las personas sin necesidad de un estudio en persona
Profesional: obtener, extender y aplicar los conocimientos sobre ciencia de datos e inteligencia artificial, en el análisis de lenguaje humano y en reconocimiento de emociones
Metodología
La metodología con la que se trabajó en este proyecto está basada en la metodología tradicional de CRISP-DM [1]. A continuación se muestra el diagrama general de los pasos que se llevaron a cabo en este trabajo.

Diseño del modelo de reconocimiento:
Recolección de datos
Para llevar a cabo el análisis se recolectaron datos de tweets de 3 diferentes ciudades para poder tener muestras variadas y esperar resultados diferentes. Las ciudades fueron elegidas solamente tomando en cuenta que fueran ciudades grandes en diferentes países angloparlantes.
Las ciudades de las que se obtuvieron los datos fueron las siguientes:
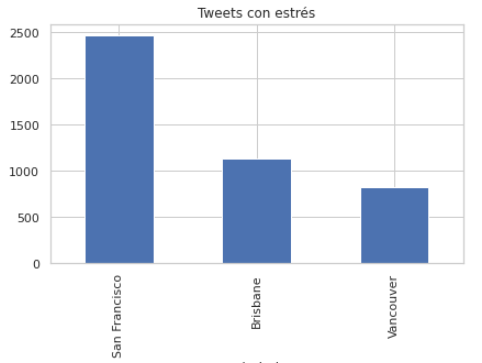
- Brisbane, Australia (2225 tweets)
- San Francisco, Estados Unidos (5000 tweets)
- Vancouver, Canadá (1699 tweets)
Cabe mencionar que los datos fueron recolectados el 24 de octubre y los tweets tienen fecha máxima de publicación una semana anterior a la fecha de recolección y mínima del mismo día de la recolección.
Las palabras claves que se utilizaron para la recolección fueron las siguientes:
covid OR COVID OR coronavirus OR corona OR coronavirus OR #coronavirus OR #covid19 OR covid19 OR sarscov2 OR #covid-19 OR #sarscov2 OR sars OR cov2 OR sars OR #quarantine OR pandemic OR #pandemic OR #2019ncov OR 2019ncov OR quarantine OR lockdown OR #lockdown OR social distancing OR #socialdistancing OR #COVID OR #covid”
La estructura de los datos es idéntica para los 3 datasets. Cada dataset está organizado en 3 columnas:
- user_location: Ubicación aproximada del usuario (si su ubicación está activada).
- date: Fecha de publicación del tweet.
- text: Texto del tweet.
Los datos anonimizados se obtuvieron a través de la API de Twitter a través de un script de Python utilizando Tweepy [2].

Etiquetado
Para el etiquetado de los datos, fue utilizada una herramienta llamada TensiStrength, la cuál está desarrollada en Java, y ayuda a evaluar el nivel de relajación o ansiedad que se puede encontrar en un texto sencillo. Esta herramienta funciona por medio de diccionarios de emociones en los cuales se asignan valores a las palabras positivas o negativas y a su vez también cuenta con un diccionario de palabras (booster words) que incrementan el valor de la expresión/emoción.

TensiStrength logra catalogar los textos de dos maneras disponibles, binaria o ternaria; la ternaria los clasifica en 1, 0, -1, positivo, neutral y negativo respectivamente. El esquema para la clasificación de emociones utilizado en nuestro modelo, utiliza la clasificación de tipo binaria, que consiste en usar las etiquetas 1 y 0, las cuales corresponden a “estrés” y “no estrés”.
Las clases se encuentran distribuidas con un porcentaje de:
Tweets con estrés = 49.972%
Tweets sin estrés = 50.028%
Exploración de los datos:
Cantidad de tweets con estrés.
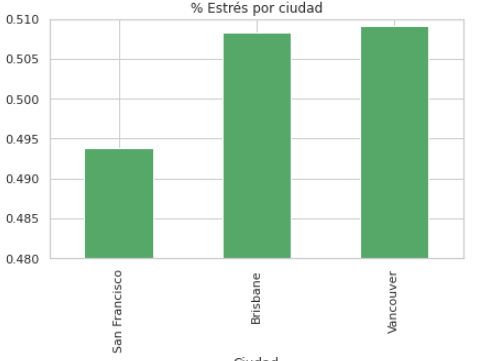
Porcentaje de estrés por ciudad, representa la cantidad de tweets con estrés respecto al total de tweets.
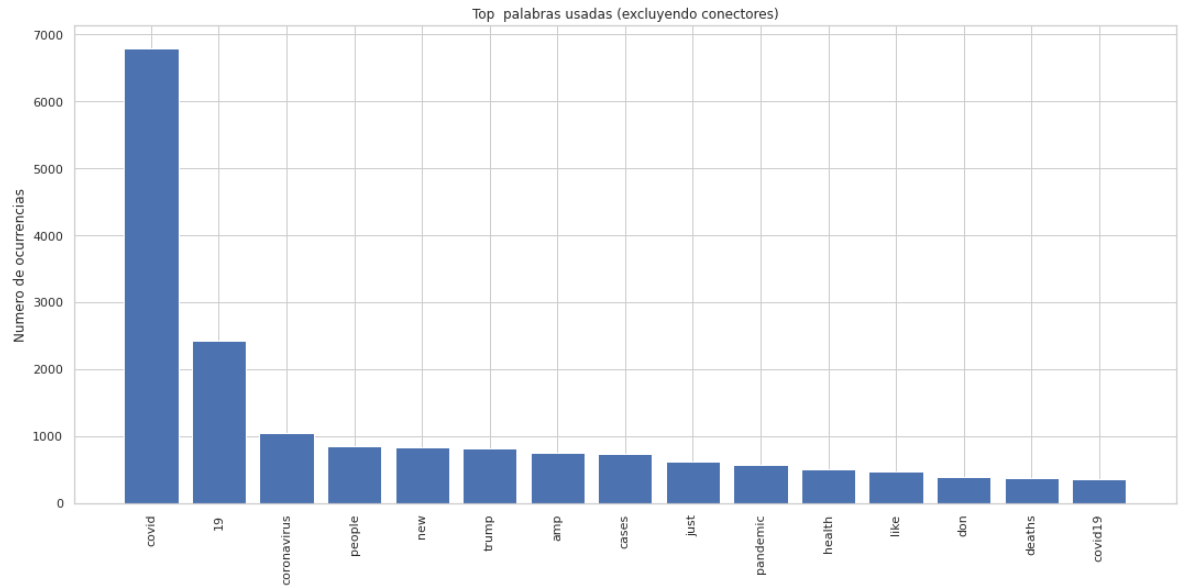
Palabras más usadas en los tweets, excluyendo conectores.
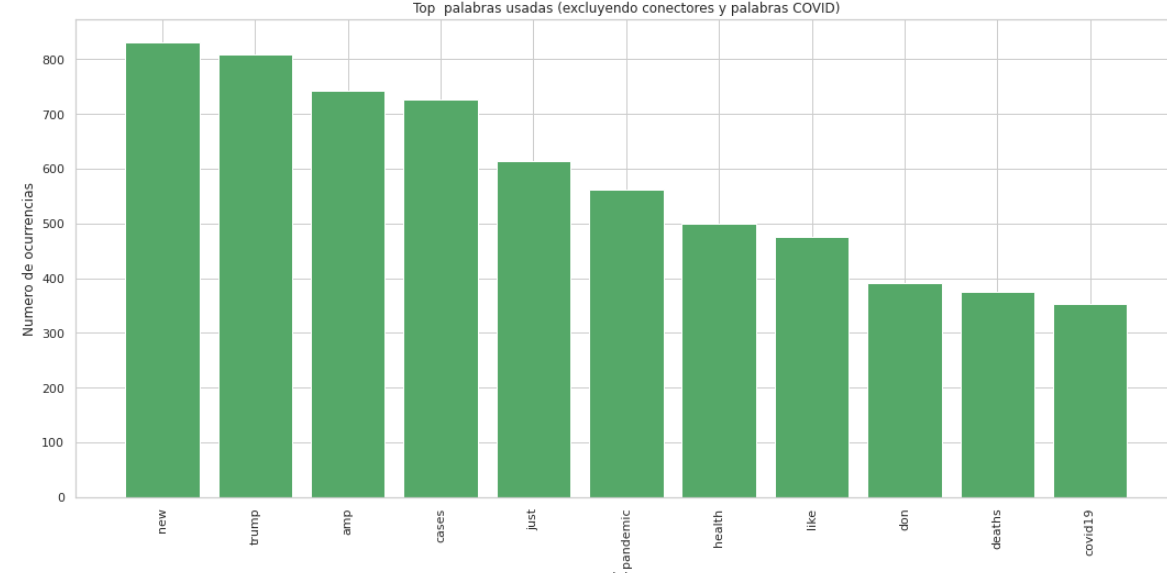
Palabras más usadas en los tweets, excluyendo conectores y palabras relacionadas con Covid.
Distribución de las palabras en los Tweets según su longitud
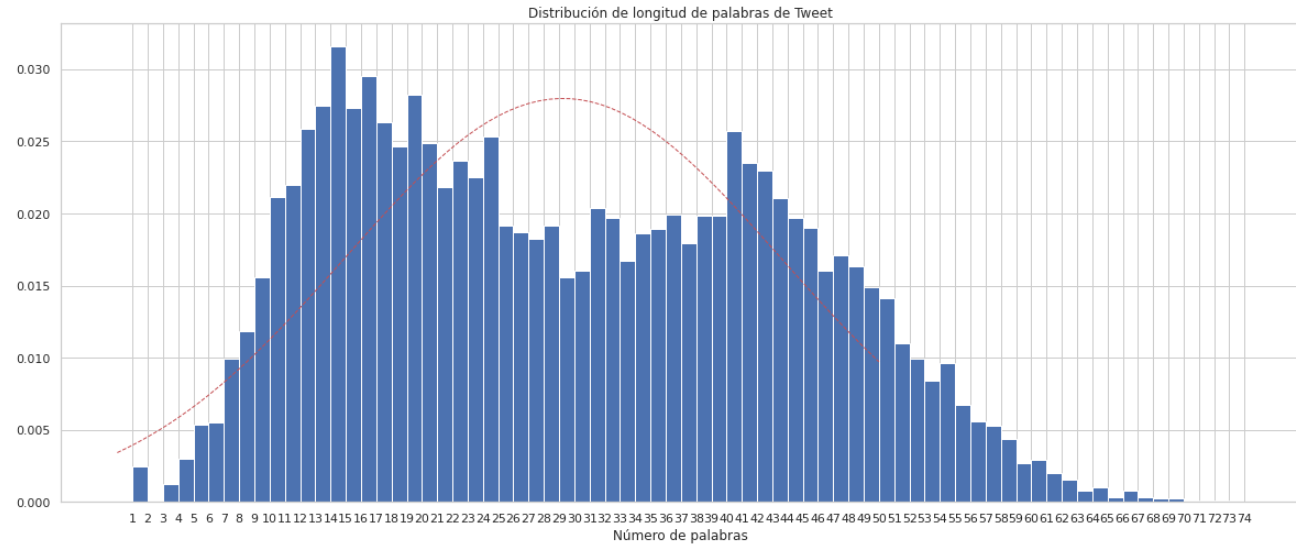
Pre-procesamiento de los datos:
Después de recolectar los datos, se llevó a cabo un pre-procesamiento con el fin de que los datos se pudieran utilizar para entrenar un modelo clasificador. Este paso es uno de los más importantes y es aquel que comúnmente consume más tiempo en un proyecto de aprendizaje de máquina.
- Reducción de Ruido: se eliminaron espacios extras, carácteres especiales y ligas a otras páginas.
- Normalización: los carácteres se transformaron a minúsculas, se eliminaron puntuaciones y se expandieron las contracciones.
- Eliminación de palabras vacías o Stopwords: se removieron aquellas palabras que no tienen un significado por sí mismas (artículos, pronombres, preposiciones y algunos verbos)
- Lematización: se llevó a cabo una lematización, la cual consiste en convertir la palabra a su forma base (i.e. mesas a mesa).
- Tokenización: finalmente los textos se separaron en palabras, también llamados tokens.
Antes del pre-procesamiento, el texto se visualiza de la siguiente manera:

Posterior a la limpieza y previo a la tokenización, el texto se visualiza de la siguiente manera:

Visualización de datos
Fue realizada por medio de nubes de palabras, en general y dividiendo los datos por clase.
Palabras más recurrentes en general:
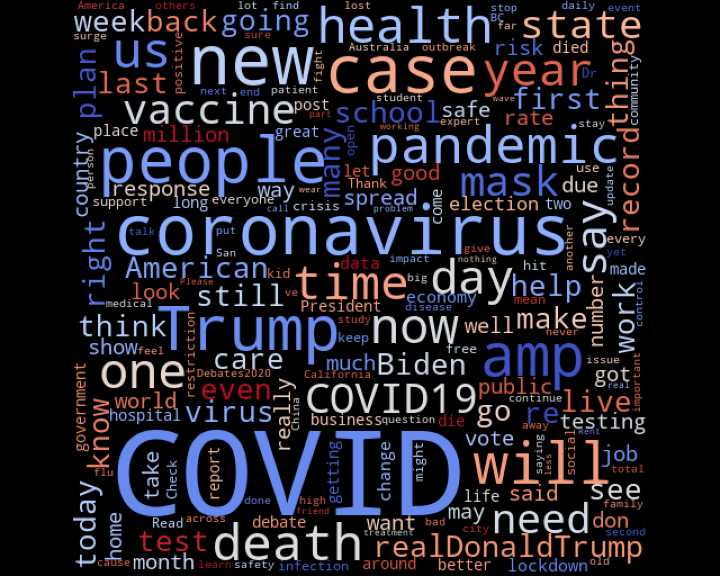
Palabras más recurrentes dentro de los datos clasificados como SIN estrés

Palabras más recurrentes dentro de los datos clasificados como CON estrés

LDA (Latent Dirichlet Allocation)
Se utilizó un clasificador de modelo generativo LDA (no supervisado), que permite que a partir de una bolsa de palabras, se genere un conjunto de observaciones que puedan ser explicadas por algunas de las partes de los datos que son similares o que tienen cierta concordancia. Este es un modelo de categorías y fue presentado como un modelo de grafos para descubrir categorías por David Blei, Andrew Ng y Michael Jordan en 2002.
En nuestro trabajo se utilizó a partir de de la vectorización de la data tratada y limpia de los tweets obtenidos, una tokenización y generando una vectorización de las palabras.
Obteniendo un clasificador de 2 tópicos, en las cuales sus principales palabras fueron:
Tópico 0: Covid case new health vaccine death year trump plan day
Tópico 1: Covid people trump go new case mask know say need
y utilizando la librería pyLDAvis
se obtuvo el visualizador:
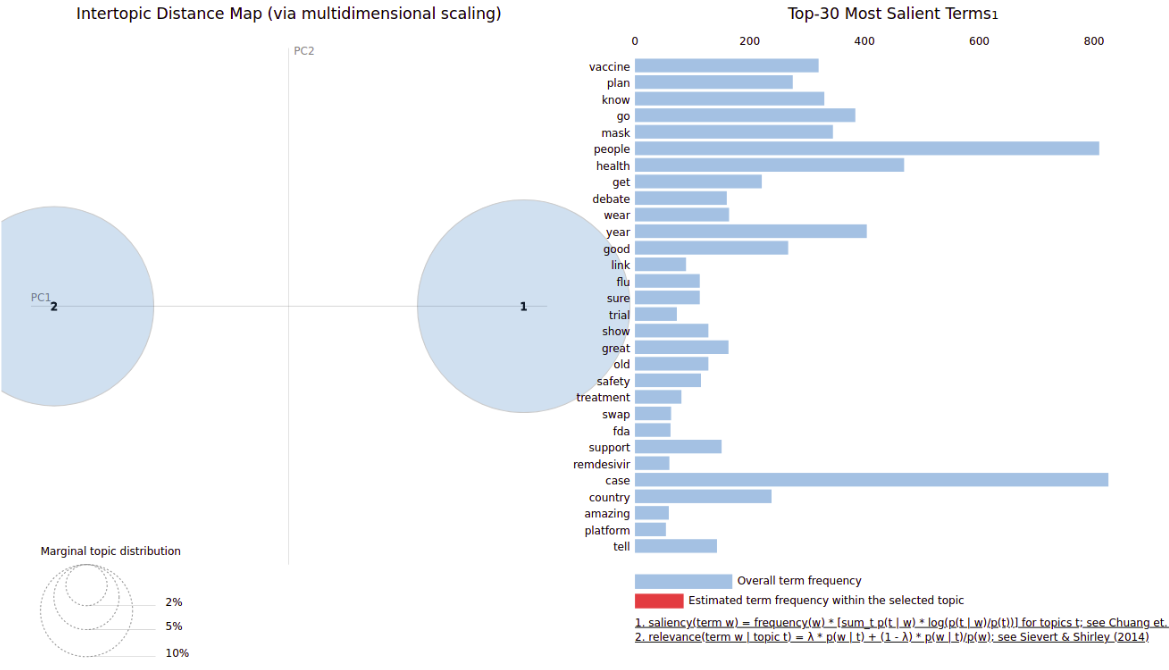
Modelado
Para este proyecto se evaluaron cinco modelos de Machine Learning. Como modelo base se utilizó Naive Bayes y se comparó con:
- Regresión Logística
- K-Nearest Neighbors
- Random Forest
- Gradient Boosting.
Para la vectorización [4] de los tweets se evaluaron 2 técnicas: Bag of Words y TF-IDF (term frequency — inverse document frequency) y dos estrategias para sus n-gramas: Bigrama y Trigramas [5].

Los resultados se midieron por medio del AUC (Area Bajo la Curva) y se evaluaron con validación cruzada (k = 10). Tanto el preprocesamiento, entrenamiento y evaluación del modelo se llevaron a cabo dentro de un “pipeline” creado dentro de una clase utilizando el lenguaje de programación de Python.
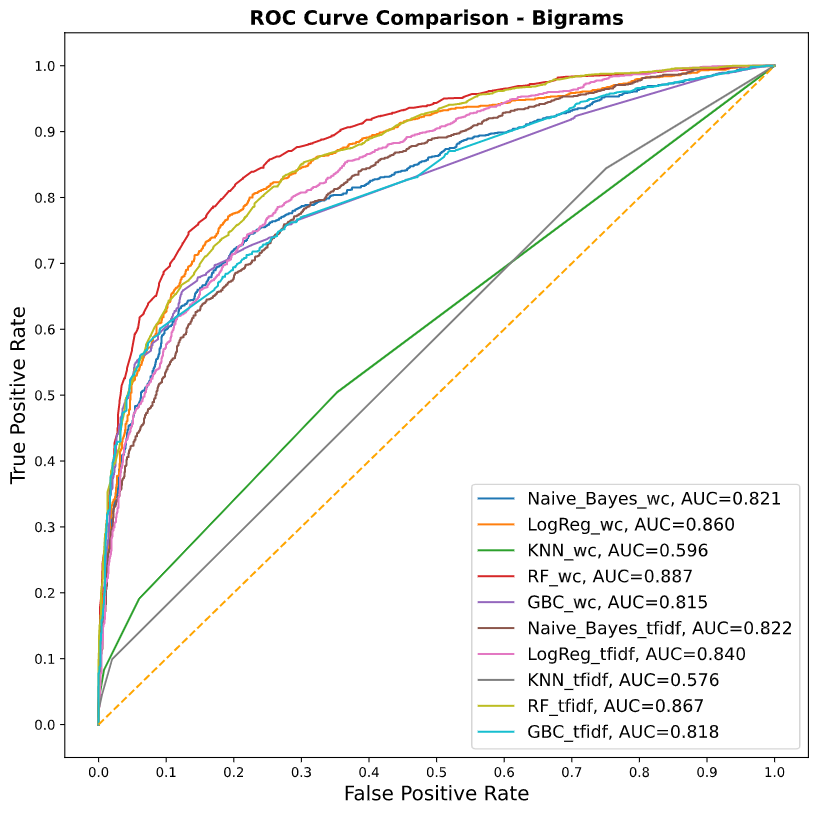

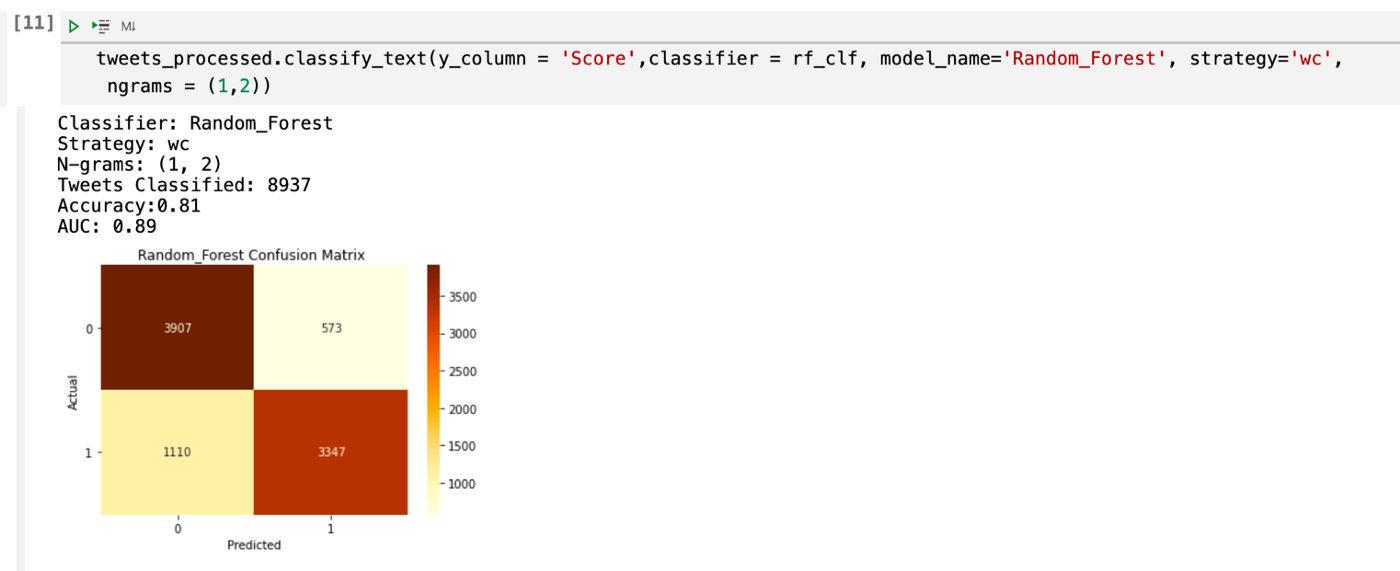
En las gráficas de AUC previas se muestra que la combinación ganadora es la de: RFt + BoW + Bigramas, ya que es la mejor en discernir los mensajes que tienen alguna relación con estrés de aquellos que no la tienen.
A continuación podemos observar la matriz de confusión del modelo ganador, así como los resultados de sus métricas.
Optimización (‘Tuneo’) del modelo:
El ajuste fue realizado para tres modelos con el fin de mejorar su desempeño.
Logistic Regression
Se genera una búsqueda de grilla utilizando grid search al cual se le definen ciertos valores con los que se ejecutará el modelo para obtener la versión con mejor Accuracy. Para esto se consideró:
1.- Valor C
2.- Penalty del modelo: L1 (Lasso) y L2 (Ridge)
Random Forest Classifier
Se genera una búsqueda de grilla utilizando grid search al cual se le definen ciertos valores con los que se ejecutará el modelo para obtener la versión con mejor Accuracy. Para esto se consideró:
1.- Número de Estimadores: número de árboles utilizados en el bosque. Este valor empezará en 200 e irá de 10 en 10 hasta llegar a 2000.
2.- Max_Features: es el número de atributos a considerar para la mejor división. Se prueba con “auto” que se refiere a que el máximo de atributos será la raíz cuadrada del número de atributos.
3.- Max_depth: esto se refiere a la máxima profundidad del árbol. Para este caso se parte en 10 hasta 110 avanzando de 11.
4.- Min_Samples_split: es el número mínimo de muestras requeridas para la división interna del nodo. Se prueba con 2, 5 y 10.
5.- Min_samples_leaf: el número mínimo de muestras requeridas para ser una hoja de nodo. Se considera 1, 2 y 4 para realizar la búsqueda de grilla.
6.- Bootstrap: Si es Verdadero, usará bottstrap en la construcción de los árboles. Si es falso no se utilizará. Se probará con ambas.
Gradient Boosting Classifier
Se genera una búsqueda de grilla utilizando grid search al cual se le definen ciertos valores con los que se ejecutará el modelo para obtener la versión con mejor Accuracy. Para esto se consideró:
1.- Loss: se usa desviance para evaluar como regresión logística la función de pérdida
2.- Learning:rate: es la medición que mide la contribución de cada árbol.
3.- Max_Features: es el número de atributos a considerar para la mejor división. Se prueba con “sqrt” que se refiere a que el máximo de atributos será la raíz cuadrada del número de atributos, en el caso de “log2” se usa el logaritmo del número de atributos.
4.- Max_depth: esto se refiere a la máxima profundidad del árbol. Para este caso se usa 3, 5 y 8.
5.- Min_Samples_split: es el número mínimo de muestras requeridas para la división interna del nodo. Se prueba con un linspace de 0.1, 0.5 y 12.
6.- Min_samples_leaf: el número mínimo de muestras requeridas para ser una hoja de nodo. Se prueba con un linspace de 0.1, 0.5 y 12.
7.- Numero de Estimadores: número de árboles utilizados en el bosque. Este valor empezará en 200 e irá de 10 en 10 hasta llegar a 2000.
Evaluación:
El modelo generado con mayor eficacia fue el de Random Forest, ya que es capaz de reconocer si un tweet contiene o no estrés con una precisión de 88%, lo cual es una métrica muy buena, ya que la velocidad con la que se puede evaluar un conjunto masivo de tweets con esta exactitud ayuda enormemente en una tarea que un humano tardaría mucho más tiempo, y de esta manera es posible encontrar o tratar posibles casos que requieran asistencia sin necesidad de esperar a que esto lleve a un problema mayor como lo es la depresión.
Análisis de resultados:
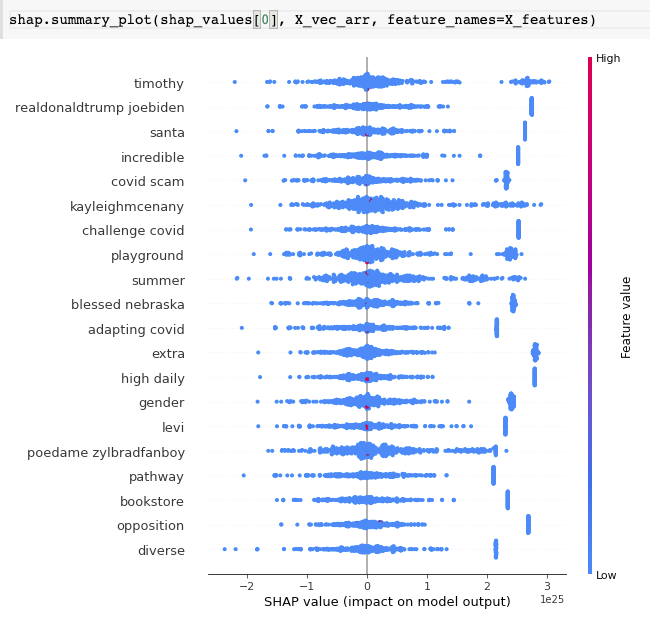
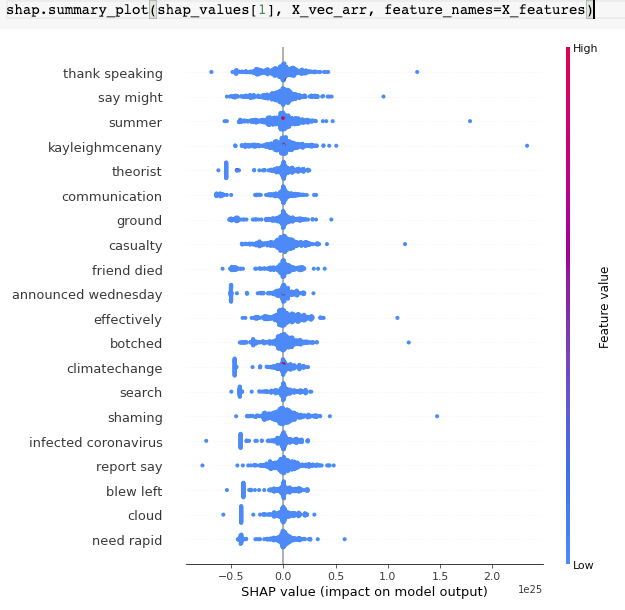
Para poder adentrarnos más en por qué el modelo se comporta de la manera que lo hace, hicimos uso de SHAP, una técnica de teoría de juegos utilizada para explicar los modelos. El modelo utilizado fue un Random Forest con 100 estimadores.
En este caso utilizamos un TreeExplainer de la librería shap. Para calcular estos valores se tuvo que usar solamente el 5% de los datos de entrenamiento y 10,000 features, de otro modo, el tiempo de ejecución sobrepasa la hora y media en Google Colab.
Resultados para tweets que NO tienen estrés:
Resultados para tweets que SÍ tienen estrés:
Casos de uso para el modelo generado:
Instituciones públicas, gubernamentales o privadas que estén interesadas en conocer o monitorear el estado anímico de una población, o conjunto de personas por zona geográfica, para evaluar el nivel de estrés.
Personal que labore en el área médica enfocada en la salud mental, para lograr identificar las condiciones sobre la estabilidad emocional de algún sector de la población.
Empresas privadas que puedan ofrecer servicios de consultoría para el bienestar emocional y que ofrezcan análisis o proyección de campañas de salud mental en la sociedad.
Desarrollo de Modelo en un App Web
Para alojar nuestro modelo de Machine Learning usamos el framework Flask. Este es usado por su facilidad de uso, ser muy escalable y además, está desarrollado para Python. Lo cual permite en un lenguaje realizar todo el desarrollo. Hay que tener claro que una aplicación web tiene dos partes fundamentales.
Partes de una App Web:
- El Front-end el cual es una página desarrollada con Html y Css. Sin ninguna parte de JavaScript ya que es una app sencilla de utilizar.
- El Back-end será desarrollado con Flask, donde permite crear la integración con el Front-end y además correr el modelo ya entrenado.
Desarrollo de la interfaz de usuario
En esta parte fueron utilizadas dos herramientas en línea bastante útiles que son Flask y Heroku.
Flask es un framework para desarrollo web con gran interacción con Python; Heroku es usado como un servidor para el despliegue y disponibilidad pública de la aplicación.
La aplicación se encuentra disponible en:
Integrantes
- Elías Garcés (Ing. Civil)
- Daniela Gómez (Ing. Industrial y de Sistemas )
- Enrique Ramos García(Lic. en Matemáticas )
- Fernando Vizcarra Salva( Ing. Mecatrónico )
- Jonathan Chávez(Desarrollador Web)
Presentación del proyecto: DemoDay
Repositorio
En el siguiente repositorio de encuentra el código usado par desarrollar esta aplicación: https://github.com/SaturdaysAI/Projects/tree/master/LATAM_remote/DataExtraction-master
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!