¿Sabias que las enfermedades cardiovasculares (ECV) son la principal causa de muerte en todo el mundo?
En México, el 19% de mujeres y hombres de 30 a 69 años mueren de enfermedades cardiovasculares, y se estima que el 70.3% de la población adulta vive con al menos un factor de riesgo cardiovascular.
Las enfermedades cardiovasculares son un grupo de desórdenes que afectan al corazón y/o los vasos sanguíneos , las cuales representan un problema de salud pública en México .
Estudios epidemiológicos han permitido identificar un conjunto de variables denominadas factores de riesgo de tipo cardiovascular (FRCV), que son todas aquellas características biológicas no modificables y características conductuales modificables (estilos de vida), cuya presencia se relaciona con una mayor probabilidad de sufrir una enfermedad cardiovascular en el futuro. Su identificación temprana es fundamental para implementar cambios en los hábitos de los pacientes con el objetivo de prevenir un evento de enfermedad cardiovascular primario.
En los últimos años México ha implementado varias estrategias enfocadas en el sector salud que prometen buenos resultados. A pesar de esto, se han encontrado inconsistencias en los procesos de atención primaria, práctica clínica e instrumentos de vigilancia que limitan la monitorización cardiovascular de la población.
¿Qué es CARDIOSIGHT?
El proyecto de CARDIOSIGHT nace debido a la presente necesidad en nuestro país de crear métodos y herramientas de identificación temprana para los individuos con alto riesgo de sufrir enfermedades cardiovasculares. Con el fin de prevenir eventos cardíacos primarios y ayudar a disminuir la incidencia de nuevos casos, por medio de hábitos de prevención. Este método de detección será diseñado con ayuda de la inteligencia artificial.
Ventajas de la aplicación:
● La población tendrá la facilidad de conocer su nivel de riesgo sin la necesidad de asistir a una unidad médica de salud. Acelerando de esta manera la identificación de los individuos con un riesgo alto antes de que se desarrolle un evento cardiovascular primario.
● Posterior a la identificación, dependiendo del resultado, se le sugerirá al usuario visitar las páginas disponibles del Instituto Mexicano del seguro social que brindan la información sobre las campañas preventivas actuales relacionadas a este tipo de enfermedades, en las cuales encontrarán la información necesaria para educarse sobre la problemática, además de la posibilidad de encontrar su clínica más cercana para realizar su primer chequeo médico.
¡Experimentando con los datos!
Se decidió trabajar con el dataset Cardiovascular Disease encontrado en la página Kaggle. El cual consiste en 70,000 datos recabados de pacientes, contiene 11 características y una variable objetivo, información recabada por medio de resultados médicos, compartida por el paciente o de forma factual.
Figura 1. Relación entre BMI (Indice de masa corporal) y la presencia o no de ECV.
Tras realizar el análisis exploratorio y transformación de nuestros datos se decidió experimentar con el modelo de Random Forest debido a su excelente capacidad de clasificación.
Figura 2. Modelo Random Forest
Tras realizar varias pruebas y tuneo de hiperparámetros se encontró el modelo ideal para nuestra aplicación.
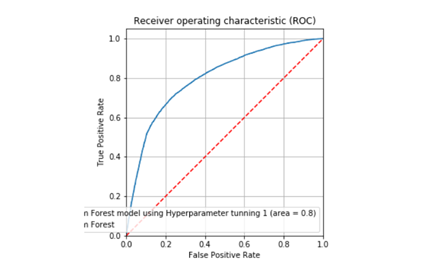
Con un accuracy de 0.73 y una curva ROC de 0.8, se decidió obtener gráficas complementarias del modelo para entender de una forma más profunda su comportamiento probabilístico.
Figura 3. Curva ROC Y AUC
Uno de los retos más grandes en el desarrollo de este proyecto fue encontrar un punto de corte para decidir si una persona tenia una alto o bajo riesgo de sufrir de una enfermedad cardiovascular. Es aquí donde la confianza probabilística entra en juego, y también poner en la balanza cuál situación es mejor: Decirle a los pacientes que tendrán una enfermedad cardiovascular cuando no la tienen, o decirles que no, cuando sí la tienen. En mi caso preferí que mi modelo identificara al mayor numero de personas de sufrir de una enfermedad cardiovascular, con la premisa de que los falsos positivos pueden ser detectados al realizar pruebas clínicas complementarias.
Figura 4. Relación entre probabilidad y punto de corte
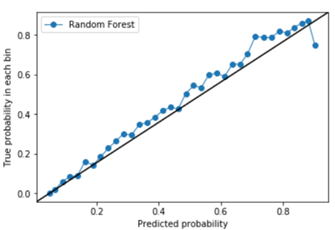
Como apoyo para la selección de este punto de corte nos basamos en el modulo de Youden, gráficas de calibración y los valores de predicción obtenidos.
Figura 5. Curva de calibración obtenida
Debido a que se deseaba que la población pudiera hacer uso de este recurso, se decidió implementar una aplicación web usando la plataforma streamlit. En la cual el usuario podría consultar su indicador de riesgo por medio del llenado de sus FRC. En caso de que su resultado fuera “Alto” se le redireccionaría a la pagina oficial del IMSS.
Resultados
Se logró obtener un algoritmo capaz de indicar si un individuo tiene alto riesgo de sufrir una enfermedad cardiovascular o no, con resultados comparables a los mencionados en la bibliografía consultada.
Tras un análisis del poder predictivo de los datos se encontró que tener un grado de hipertensión y ser mayor de 50 años, puede influir a que seas un individuo con alto riesgo. El colesterol y el índice de masa corporal también son características a considerar, ya que, si sus niveles son más altos de lo normal, también pueden influir a un riesgo mayor. Una identificación temprana de estas variables de riesgo es fundamental para poder prevenir un episodio de enfermedad cardiovascular primario.
¿Esto es todo?
No, este proyecto sirve como precedente para saber si la metodología utilizada es útil y qué tipo de recursos son necesarios para realizar una investigación más elaborada enfocada a la población mexicana.
Cómo siguientes pasos, es indispensable trabajar con un dataset enfocado en la población mexicana, con él se podría hacer un análisis más profundo respecto a cómo las variables de alimentación, sociales, económicas y educacionales afectan a las predicciones. Además de que se podría crear un algoritmo de cálculo de factor de riesgo, enfocado a esta población.
Se desea trabajar más con el algoritmo creado, para mejorar su desempeño de clasificación aplicando feature selection y otros algoritmos de machine learning.
Todavía queda mucho por hacer, pero definitivamente esta experimentación le da dirección a los próximos esfuerzos, te invito a que me sigas, para que puedas seguir leyendo sobre este proyecto.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
El fatídico 11 de marzo del 2020, la OMS declaró la pandemia mundial por COVID-19. Más de 300 días después, hemos decidido hacer público y accesible para el mundo entero el trabajo que hemos venido desarrollando durante más de 8 semanas.
Prepárense, gobiernos e instituciones sanitarias del planeta, pues lo que van a ver en este artículo establecerá los cimientos de un nuevo sistema de vigilancia que permitirá asegurar el cumplimiento de una de las medidas que más se ha repetido durante estos fatídicos 300 días: la distancia de seguridad interpersonal de metro y medio.
Nuestro incombustible grupo, formado por 3 “locos” ingenieros (alguno de ellos en proceso) ha trabajado día y noche para traer la mejor solución posible a este problema.
El proyecto, que comenzó bajo el nombre de WATCHDOG (perro guardián) por la misión inicial que teníamos en mente (un robot con autonomía de movimientos que vigilase el cumplimiento de la distancia de seguridad y que ladrase cada vez que esta fuera quebrantada) iba a ofrecer, más allá del obvio beneficio de un constante recordatorio a las personas de la necesidad de cumplir con la medida de la distancia interpersonal, una herramienta para el mapeo y creación de “puntos calientes” en los que la distancia se incumpliese más a menudo.
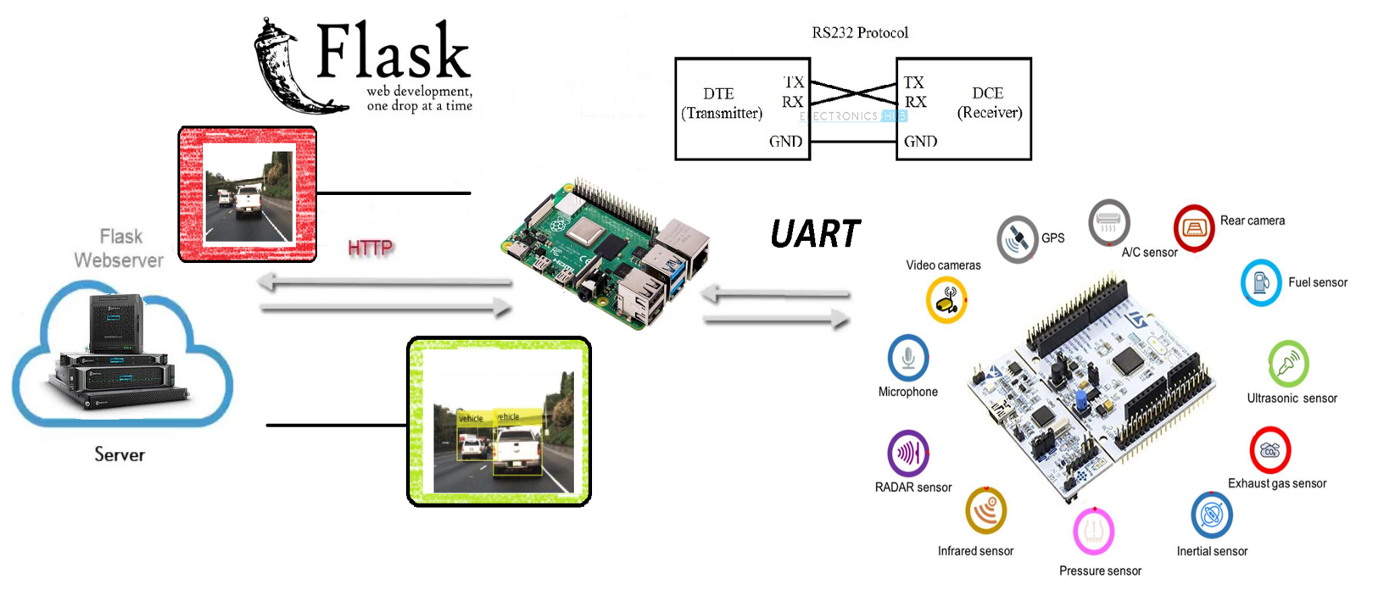
Para todo ello, el equipo ha tratado de crear una convergencia entre los mundos de la electrónica y la Inteligencia Artificial, haciendo uso de los medios más innovadores que tenía a su mano. Con una Raspberry Pi 3, un microcontrolador de bajo nivel equivalente a Arduino Mega, diferentes medios para la comunicación, algoritmos, librerías y redes neuronales convolucionales se ha tratado de alcanzar la solución con la mayor satisfacción posible.
El proyecto
Para el proyecto de Saturdays.AI se ha pensado en desarrollar un proyecto Watchdog (perro guardián) que vigila la distancia mínima recomendada por los protocolos Anti-COVID.
El planteamiento inicial ha sido el de programar un robot capaz de emitir un ladrido cuando la distancia de seguridad (requerido por los protocolos Anti-COVID) fuera quebrantada, enviando los datos adquiridos a un servidor y realizar un mapeo (mapa de calor) en tiempo real.
El objetivo básico del proyecto es converger el mundo OT con el mundo IT, es decir, la convergencia de la electrónica con el de la IA (inteligencia artificial) muy de moda en el mundo IT, utilizando técnicas de Deep Learning, que es una de las ramas del Machine Learning. De hecho, a pesar de que esta primera edición de AI Saturdays Euskadi se haya orientado al Machine Learning en general, hemos decidido profundizar en el Deep Learning por voluntad propia.
Poco a poco se están desarrollando tarjetas electrónicas autónomas que funcionan At The Edge (es decir que la misma tarjeta de control aplica los algoritmos) sin utilizar el Cloud para ello, o sin utilizar una unidad PC más potente para su procesado. Este fenómeno, conocido como Edge Computing, permite aliviar la carga de procesamiento a servidores centrales delegando tareas que puedan ser sencillas pero repetitivas a los nodos externos.
Funcionamiento
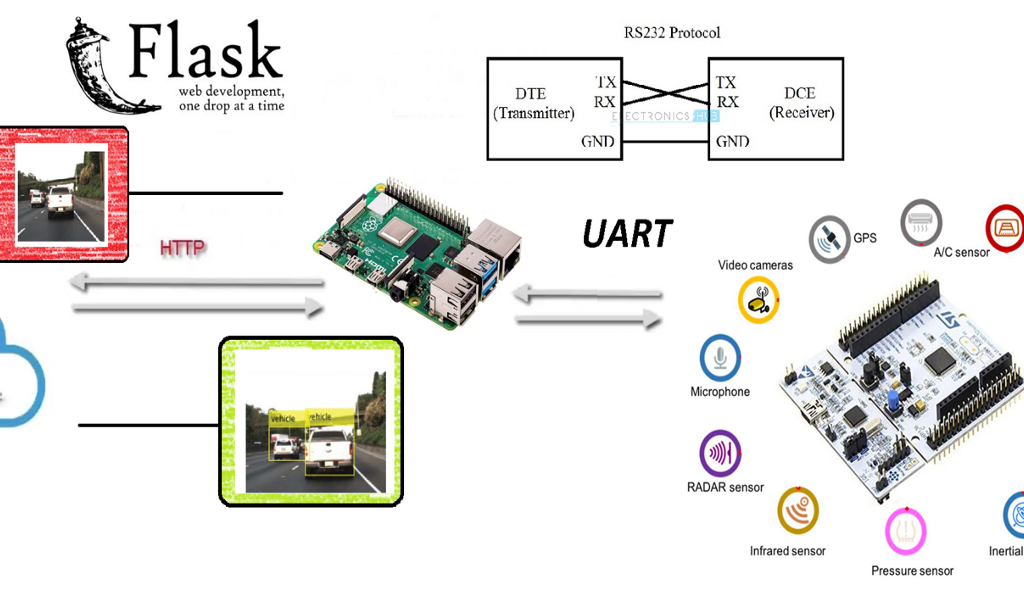
Cuando se detectan 2 personas, manda la posición de la detección y la imagen de violación de la distancia a un servidor Web, creado con Flask.
En lo que al mapeo respecta, la idea inicial era realizar un mapeo SLAM (simultaneous localization and mapping) utilizando un sensor LIDAR o una cámara 3D, pero nos hemos encontrado con limitaciones para hacer un Point Cloud que nos permitiera ejecutar el mapeo. Se describe esta limitación en los Trabajos a Futuro.
Objetivo
El objetivo inicial era plasmar todo el código dentro de una tarjeta Raspberry PI 3 (de aquí en adelante RPi3), pero a pesar de existen librerías para controlar los módulos de entradas y salidas (GPIO), el dispositivo no es lo suficientemente potente para poder procesar todo en tiempo real. Para ello existen módulos dedicados y deterministas que facilitan estas tareas.
Para tratar de cumplir con el objetivo aquí propuesto se ha utilizado un microcontrolador STM32F411RET. Se trata de un microcontrolador de gama baja equivalente a un Arduino Mega, pero con un sistema operativo de tiempo real (Real Time Operating System o RTOS), al ser determinista se tiene el control del timing y tareas, pudiendo tener un mayor control para la adquisición de datos y respuesta de los actuadores.
Se decidió utilizar esta tecnología por la gran cantidad de librerías robustas que existen para controlar los periféricos.
Algoritmo YOLOv4
El algoritmo final que se ha usado ha sido por goleada YOLO (para nuestro caso), respecto a otros conocidos como SSD (Single Shot Detection) o la más precisa de todas las tecnologías RESNET.
El reto en este apartado ha sido buscar la tecnología que mejor se adapta al tiempo real y nos basamos en las reglas de oro que dijo uno de los mentores:
1. ¿Qué pasa en el mercado? ¿Cuál es la tendencia del mismo? ¿Qué tipo de arquitectura es más viable con las restricciones presupuestarias y de tiempo que tenéis?
2. Mirad lo que hacen los grandes. ¿Podemos pensar igual a ellos? Es decir, ¿tenemos que plantearnos entrenar redes extremadamente complejas, o tenemos que poner los pies en la tierra y plantear ejemplos más rápidos para construir un Producto Mínimo Viable (MVP)?
3. ¡Adáptate!
En esta fórmula, el resultado de 1+1 en ingeniería sería determinista pero en la vida real el resultado es estocástico, así que depende. ?
Este proyecto está acotado para capacidad computacional de gama media y se ha querido estrujar al máximo desde ese punto de vista. Por ello, el mejor algoritmo que encontramos, el cual estaba puramente escrito en C (siendo un terrible reto el aplicar funciones matemáticas a pelo; aprovechamos para agradecer a Joseph Redmon) es lo más rápido comparado con librerías escritas a mayor alto nivel (TensorFlow, pyTorch).
Como curiosidad, usando la versión para embebidos de SSD se llega a unos 18 Frames por Segundo (FPS) comparado con YOLO, que llega a 24 FPS. Sin haber añadido telecomunicaciones nos dimos cuenta cuál era el camino a seguir, pero se encontraron todo tipo de resoluciones de las distintas tecnologías.
“Cabe destacar que para el equipo, el algoritmo o tecnología más completo y adaptado si se tuviera un poco más de capacidad computacional serían RNN o FAST-RNN, ya que de una tirada no solo tendríamos la posición de los objetos, sino cada pixel de la imagen estaría vinculado a una clase y con esto se podría dotar al proyecto de la capacidad de contextualizarse en el entorno. Y esto nos llevaría a más poder de adaptación, teniendo en particular un efecto positivo para el ámbito del Machine Learning, donde se dispondría de más DATO al que poder darle valor sacado del entorno.”
Si se tiene aún más curiosidad al respecto, os dejamos este link.
Como esto se extendería hasta el infinito, no se van a explicar los detalles del funcionamiento a fondo; se adjunta un link donde se explica detalladamente el algoritmo en su versión v3. La diferencia está en que en la versión v4 aumenta la precisión pero en su versión tiny la velocidad se mantiene constante.
EDA: Y ahora… ¡Metemos los “Datos” de nuestros sensores a la caja negra!
La analogía del “EDA” realizado en nuestro proyecto de Deep Learning tendría que ver, entre otros, con limpieza y preprocesamientos hechos de las imágenes obtenidas. El primer preprocesamiento ejecutado sería el que ofrece la función BLOB de OpenCV que reduce la escala de 8 bits (255 RGB) a escala porcentual unitaria.
Este detalle es muy importante ya que pasa el resultado de cualquier cámara a la que el algoritmo necesita de entrada. ¿Lo malo? Que se vuelen datos de coma flotante y eso requiere más gasto computacional pero de ese problema ya se encargaron sus autores.
El “tuning” de los parámetros en este aspecto que hemos hecho ha sido pasar la imagen de entrada a la escala más pequeña (316 x 316 píxeles).
Habiendo hecho este primer paso, la imagen pasará por múltiples filtros internos cambiando la dimensionalidad de la entrada y readaptando al mejor estilo de Nolan con películas del calibre de Tenet o Inception. ¿El resultado?
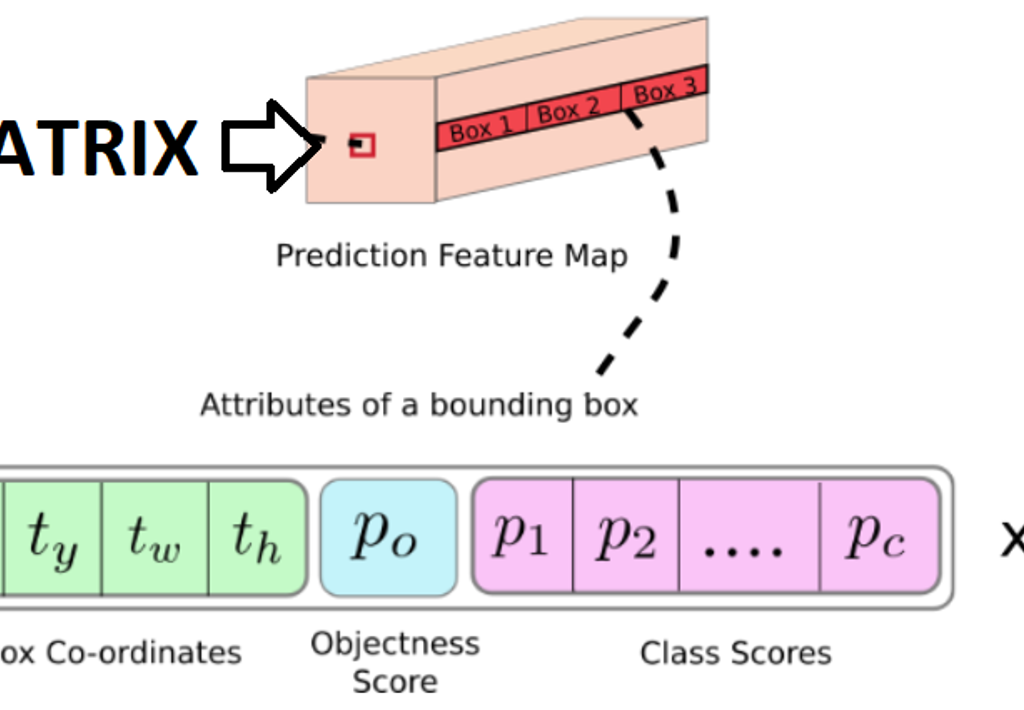
El algoritmo YOLOv4 entrega los datos de la imagen en una matriz compuesta de 13x13x (A x ((B+P) + C)), siendo:
A: La cantidad de anchor boxes (siendo una anchor box un “espacio en el que se puede detectar la posible presencia de un objeto”).
B: Las coordenadas de posición del objeto.
P: La probabilidad de confianza de que hay objeto.
C: Las clases que deseamos identificar y su respectiva probabilidad.
Dentro del archivo “coco.names” están las clases asociadas a sus respectivos nombres pero de este resultado se filtran “únicamente” los resultados en la que la clase es una persona
? ¿Y por qué no reentrenar la red aplicando transfer learning?
Mucho ojo, ya que nuestro equipo se peleó para mejorar la respuesta de este algoritmo para aumentar y darle más valor a la matriz de salida de la versión tiny.
Los resultados, por desgracia, no fueron los esperados. El mapa de características que se crea en estos modelos se basa en cantidades muy grandes de datos y de mucha variedad en el tema de la visión, donde son necesarias grandes cantidades (10.000 imágenes) para que el procesamiento pueda ser fluido. Y es cierto, si se reentrenara partiendo de transfer learning nos ahorraríamos muchas imágenes de entrada, pero también hay que tener en cuenta las clases de objetos que se quieran reconocer. Mientras más clases de objetos haya el mapa de características aprende mejor a separar cada clase.
Por ello, se han usado los pesos de la versión COCO para el algoritmo YOLO, ya que era la más similar para nuestro caso.
A continuación, se aplica un segundo filtro, usado para aplicar el BBOX de los distintos anchor boxes para ver cuál es el mejor.
Estos pasos anteriores formarían el proceso EDA como tal. Sin embargo, y en comparación con un proceso de ML, el filtro que se aplicaría dependería del grado de confianza que se tenga de la detección de un objeto, mientras que en un proceso de ML la “manipulación” se suele hacer sobre el mismo dato.
Todo esto se ensambla en una función llamada “Impure Detector” que nos va a devolver los datos que más nos interesan en una lista de Python de la siguiente forma:
[Coordenadas de las Personas, Index_Impuros]
RPI3
La Raspberry 3B+ cuenta con el sistema operativo Raspbian y librerías OpenCV (4.1.0.22).
El funcionamiento de manera general es sencillo: Se procesan los datos de la imagen y se reenvían a un servidor Web Flask instalado en un PC.
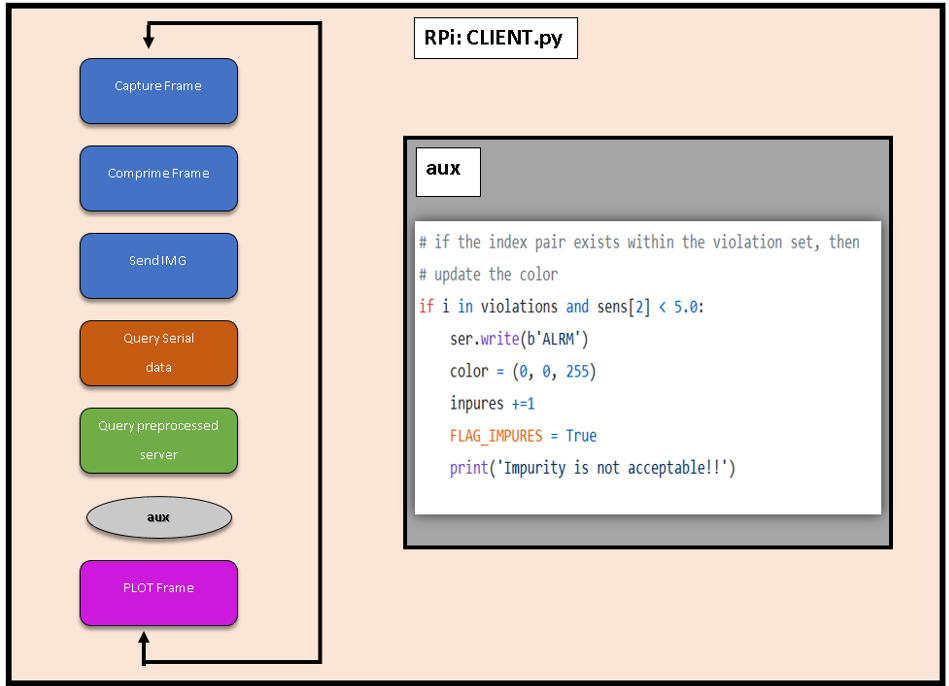
Podemos ver más detalles sobre el código de la RPi en CLIENT.py:
● Comunicación Serie
Tenemos una comunicación serie con el microcontrolador. Después de unas cuantas pruebas nos hemos dado cuenta de que, a la velocidad máxima con la que puede trabajar la RPi con python es con un BaudRate 115200 Bits/s, lo que limita la capacidad de mejorar el tiempo de espera entre Cliente-Servidor. Anotamos este aspecto como Trabajo futuro.
● MQTT
También se ha usado MQTT para enviar los datos respecto a la “violación” de la distancia de seguridad” a otro servidor. Sin embargo, como se ha mencionado antes, no se ha llegado a hacer un mapa de calor con el área de los “delitos de distancia de seguridad” a tiempo real, pero conseguimos enviar los datos e insertarlos en un archivo remoto, guardándolos en un fichero CSV dentro del servidor.
Un trabajo a futuro al que, por desgracia no pudimos llegar, era el de generar un pequeño script para graficar o plotear esos datos.
El diagrama de bloques obtenido para nuestro proceso.
Las imágenes son bastante problemáticas ya que enviar los paquetes de información tan largos y en la que la que el orden influya es complicado, es necesario indexarlos. Se han probado muchas, pero muchas metodologías distintas y la que mejores resultados ha dado ha sido usando una REST API del servidor.
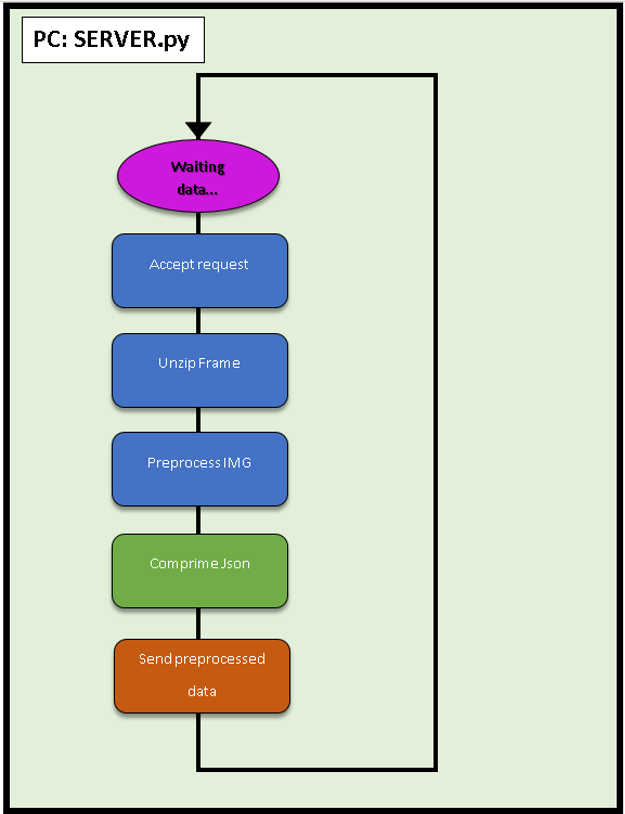
Servidor FLASK:
En Internet se encuentra de todo excepto lo que realmente se quiere, por lo tanto hemos tenido que desarrollar el sistema de envío de imágenes comprimidas por HTTP.
Para ello se han utilizado las funciones de imágenes por excelencia, recogidas en el paquete Open Source OpenCV utilizando un buffer dinámico, evitando la escritura en el disco. Esto se debe ya que por experiencia se ha visto que, a la larga, si no se cuidan, los servidores “envejecen” o “degeneran”. Esto evita por ejemplo forzar los soportes de memoria flash y controlar los ciclos de lectura/escritura aplicados.
Después de emplear OpenCV, nuestro sistema crea la captura en un buffer, lo comprime y se envía al servidor, quien lo descomprime y escribe a disco, dejándolo preparado para su almacenamiento y/o post procesamiento. Este envío se hace en formato JSON ya que se tenían errores al enviarlos en otros formatos.
? ¿Cómo enviar datos que son variables en el tiempo de forma constante?
Normalmente, para que dos personas y/o máquinas se comuniquen tienen que hablar el mismo idioma. En Machine Learning, además, los datos suelen enviarse en bloques constantes de información y de tamaño reducido. En nuestro caso, los pasos que va a ejecutar nuestro cliente son secuenciales y si se tropieza en algún punto todo se va al traste.
Por tanto, se han creado datos “ficticios” para enviarlos como mínimo para que todas las piezas del proyecto puedan funcionar sincronizadamente y en armonía.
Los “impuros” nos van a marcar el index del objeto al que esté pecando pero en los negativos no se va a fijar. Por tanto, esa es la razón por la que el proyecto consigue funcionar sin que se note este pequeño bug.
Esquema general del funcionamiento del servidor Flask.
Microcontrolador
Se ha elegido este microcontrolador (STM32F411RET) por una opción que un Arduino no ofrecía:
La programación de distintas subtareas para que se ejecuten de manera concurrente además de las interrupciones.
Programar en el STMCubeIde nos da la opción de tener la facilidad de programación de Arduino, así como librerías de entornos más industriales.
A diferencia del Arduino en el que el uso de multitareas metiéndolas en un proceso Round Robin es muy complejo, sumado a la limitación de la cantidad de temporizadores o timers que ofrece Arduino Uno 3, con el STM32F404RE estos problemas para insertarlos en la industria se mitigan.
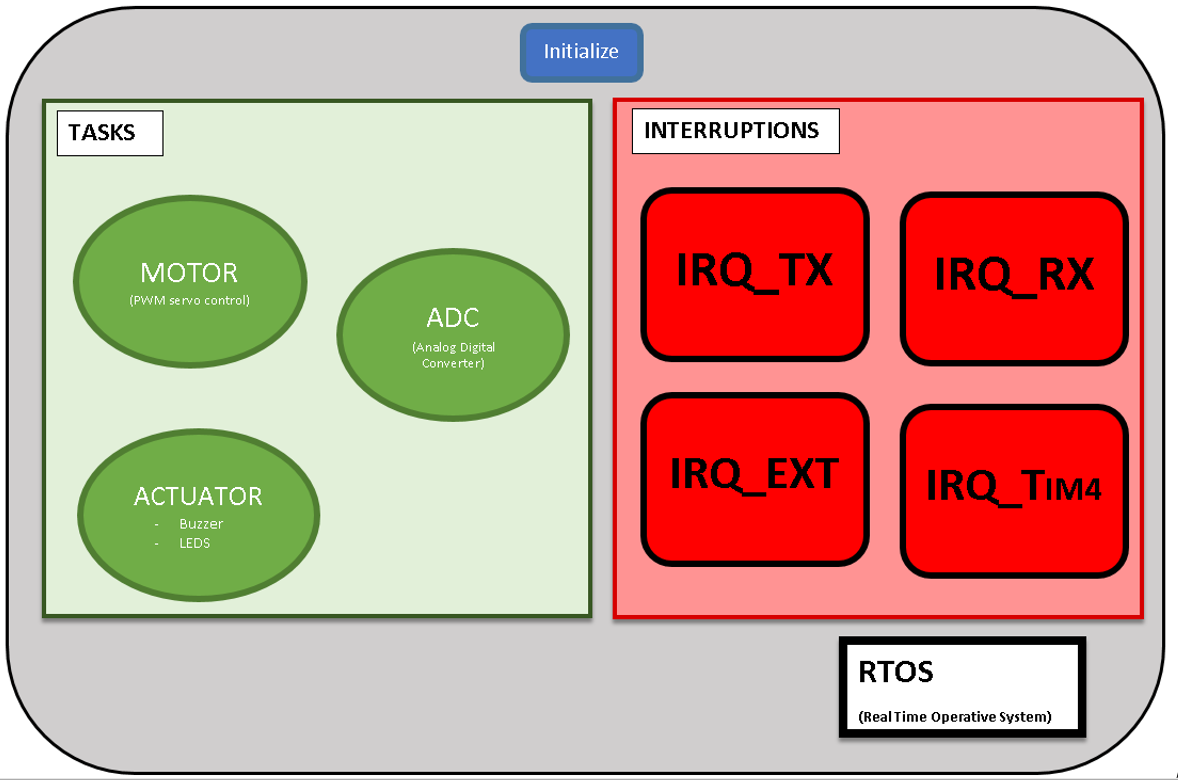
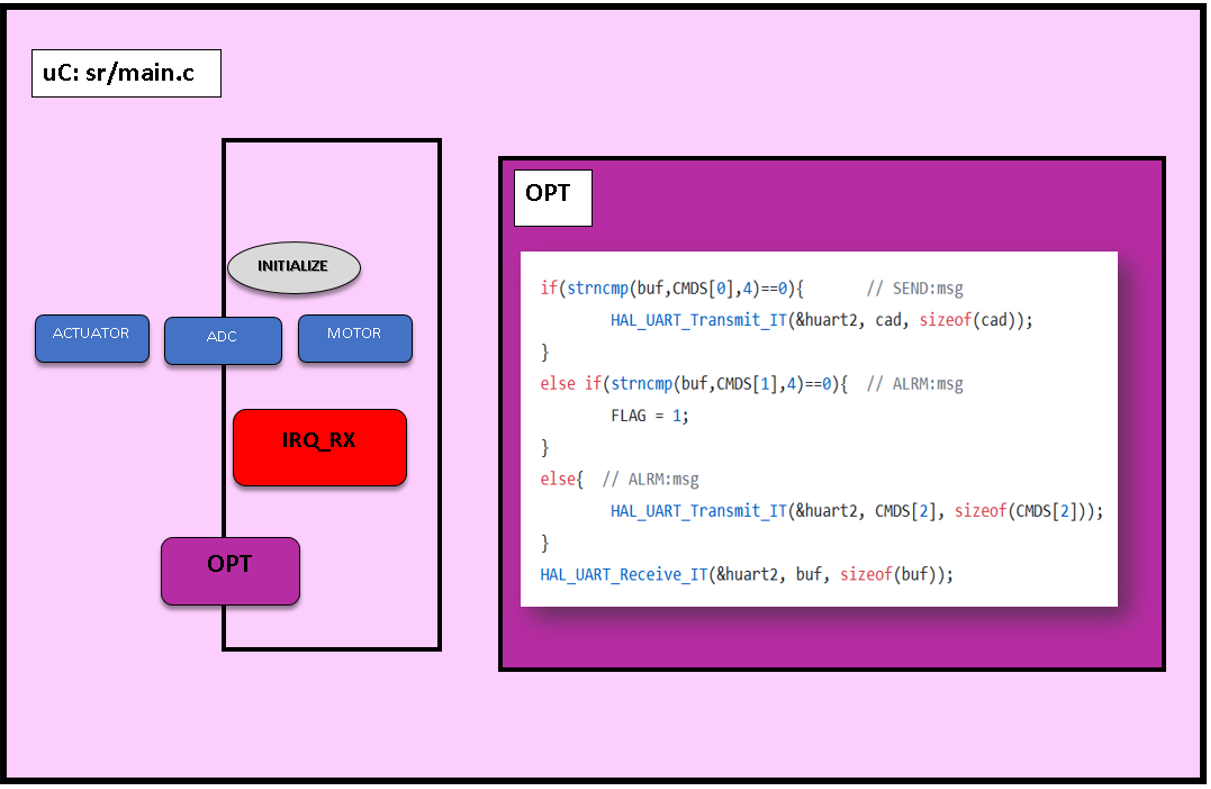
Por tanto, una vez que el micro haya ejecutado la configuración inicial (tareas, interrupciones, timers…) el programa empezará a ejecutar las tareas aplicando un Round Robin, las cuales se agrupan en el siguiente esquema:
Esquema de las Tareas o Programas Concurrentes existentes.
Dentro de las tareas o programas concurrentes existentes existen tres:
1. ADC
Este subprograma se encarga de leer las entradas digitales y procesarlas en 10–12 bits; aspecto que en una lectura por Arduino solo ofrecerá 8 bits de conversión.
Una vez acabadas una por una en orden secuencial, insertará los datos aplicando sus respectivas conversiones en un vector global int32, siendo el motivo para guardarlos como int y no en float que la cantidad de espacio que ocupan se duplicaría (de 32 a 64 bits, por la coma flotante).
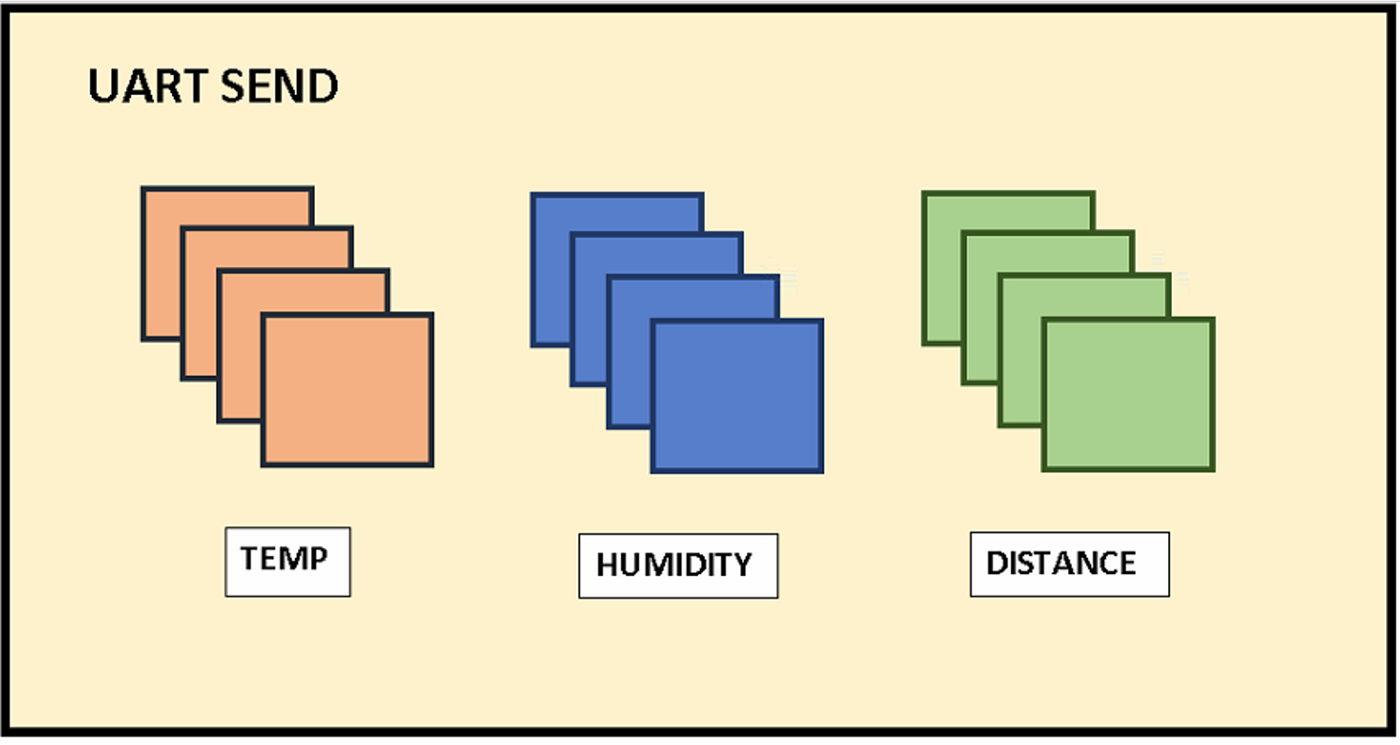
Como se puede apreciar en la imagen del envío del Transmisor-Receptor Asíncrono Universal (UART), se envían 4 datos por cada sensor. El último dato es el que quedaría detrás de la coma flotante para su posterior preprocesamiento sencillo en la RPi.
Ejemplo de esto sería recibir del sensor de distancia un valor de 1004 y transformarlo a 100, 4 en este caso simulando metros de profundidad.
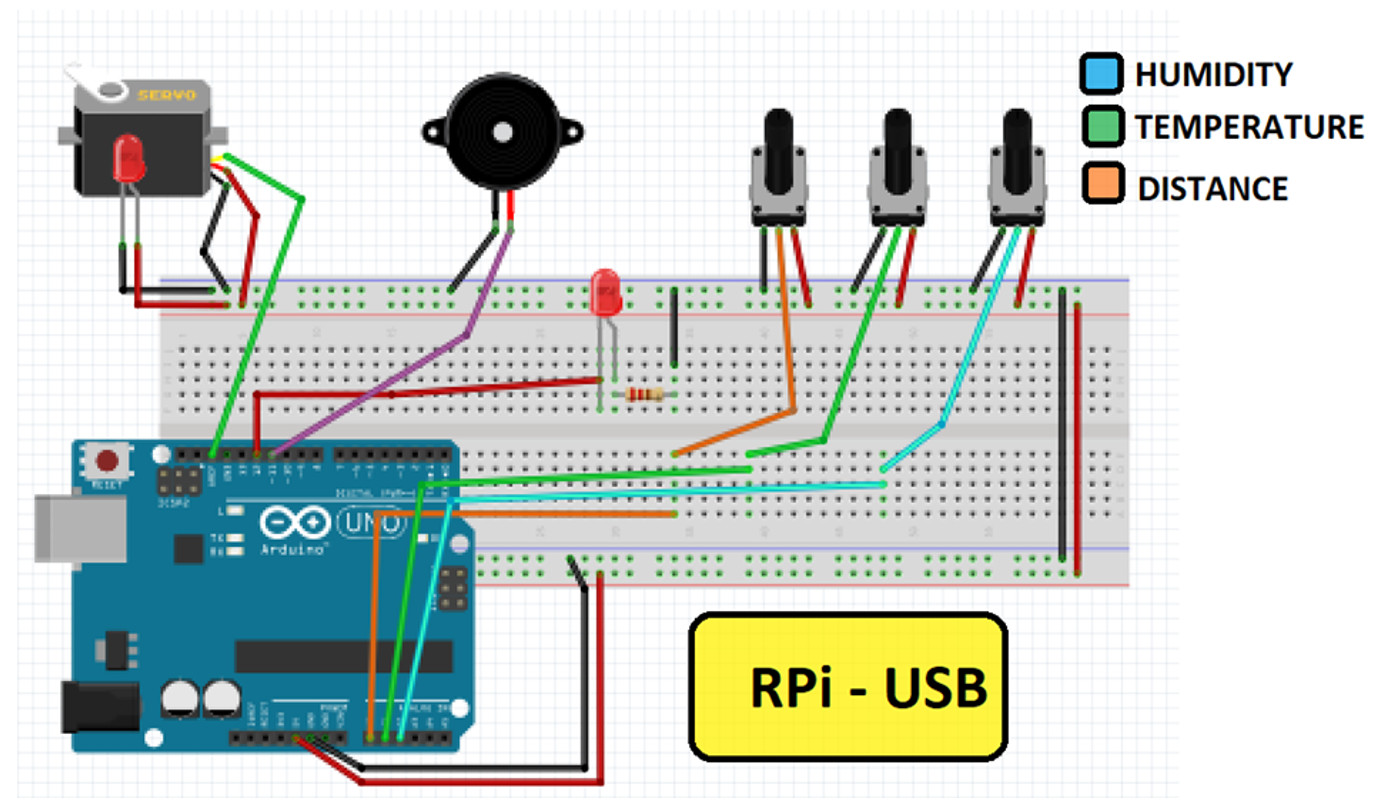
Sensores conectados por UART al microcontrolador
2. ACTUATORS
Dentro de los actuadores podemos encontrar que se conmutarán los estados de las salidas digitales pertenecientes al Buzzer y LED_EXT encargados de dotar al robot de notificar al entorno de manera acústica y visual.
No se ha añadido el actuador del motor porque se cree que separado se entiende mejor a la hora de distribuir el código.
3. MOTOR
Los servomotores trabajan entre 500 y 2500 ticks por lo que nuestra tarea TASK_MOTOR se aprovechará de las interrupciones del timer_4 para cambiar su valor ON/OFF.
Además, se ha añadido un acumulador, de tal manera que si mientras se detecta una violación de la distancia de seguridad y antes de que la función se apague se vuelve a recibir una interrupción por la violación de distancia, aumentará el tiempo de espera 5 segundos más en esa posición. Con esto nos aseguramos de que hay un mayor control de las presencias detectadas.
Interrupciones
Las interrupciones son peticiones síncronas o asíncronas al reloj en la que el procesador va a dejar de lado la tarea que esté realizando para centrarse en la interrupción.
Nosotros hemos definido 4 tipos de interrupciones.
1. IRQ_EXT:
Es la interrupción externa por botón a la que se va a acceder en caso de que haya un error tanto de comunicación o de cualquier otro tipo para resetear la configuración del microcontrolador sin que resetee todo. Reenviará la información y nos avisará enviando un “DONE” por el puerto serial.
2. IRQ_TIM4
Se ha configurado el timer_4 del microcontrolador para que se ejecute cada 1 MHz.
En resumen, para que tardemos 50 Hz que es la velocidad del servomotor tenemos que añadir un registro contador de 0–2000 unidades para que entre en la interrupción cada 50 Hz.
Es decir, que en cada 200 ms recibiremos 20000 ticks. O dicho de otra manera, cada 200 milisegundos nuestro micro interrumpirá la interrupción de ese timer.
3. IRQ_TX:
Esta interrupción únicamente va a encender un LED interno del microcontrolador para saber de manera rápida que todo está funcionando correctamente.
En la figura inferior, además de ver la distribución de los pines se puede ver el pin del LED interno así como el pulsador interno del microcontrolador.
Distribución de los pines del proyecto.
4. IRQ_RX:
A pesar de estar la última en la lista, es la interrupción más importante. Para que la RPi actúe como “cabeza pensante”, es necesaria una interrupción que esté atenta a cualquier señal asíncrona que reciba del microPC y que alerte a la RPi.
Los comandos que se van a enviar desde la RPi son dos:
“SEND”
“ALRM”
Cuando recibamos SEND el microcontrolador enviará los datos que tenga en ese momento en el vector “sens”.
Si recibe ALRM ejecutará los actuadores y si antes de que se acabe vuelve a recibir una entrada ALRM, aumentará el tiempo del mismo.
Figura que muestra el envío de señales a las tareas.
Conclusiones
Se trata de un proyecto aparentemente simple, pero que detrás de todo existe un ecosistema muy complejo al que se le quería meter mano. Solo hay que ver la arquitectura de la infraestructura que ha quedado:
Sensores – Unidad del Microcontrolador (MCU).
MCU – RPi.
RPi – PC: Uso de protocolo HTTP con peticiones POST al servidor web (REST API montada en Flask).
Aunque el objetivo era aplicar temas de Machine Learning, estos temas requieren de una determinada arquitectura y funciones para comunicaciones, tratamiento de imágenes etc. El tema de SLAM + ML se ha quedado a las puertas pero sí se han dado pasos para poder continuar con la misma.
Y a la larga, el objetivo que se había planteado que era aplicar esta tecnología al mundo real aparte de la IT y darle una aplicación más industrial, creemos que aunque no se haya logrado, se está un paso más cerca con el uso de estas “herramientas caseras”.
Como reflexión obtenido, hemos detectado que si se va a empezar a usar el Cloud Computing, para las próximas generaciones hará falta un cifrado de la información muy densa que se envíe (aunque se sacrifique la latencia), ya que es un tema muy serio al que poca importancia se le está dando actualmente.
Trabajo a futuro
Hemos detectado diferentes tareas como trabajo futuro de cara a este proyecto:
El mapeo del entorno, así como la geolocalización indoor. Hemos realizado pruebas con el sistema GPS que adquirimos, pero este sistema requiere que esté en un espacio abierto para su funcionamiento. Para facilitar esta geolocalización con sistemas alternativas, consideraríamos el uso de geolocalización indoor (mediante AprilTags, Bluetooth de Baja Energía o BLE, etc.).
La mejora del microcontrolador, aspecto que podría ayudar a mejorar en más del doble la velocidad de procesamiento de la RPI, lo que nos podría ayudar a compensar el retardo generado en la comunicación Cliente-Servidor.
La creación de un script de plotting para graficar los datos obtenidos mediante la conexión MQTT.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
El estrés: una ‘epidemia’ silenciosa que puede afectar a cualquier persona durante la era moderna, ahora es más notoria debido a la mayor crisis sanitaria enfrentada durante este siglo. Los niveles de preocupación, impacto económico y emocional que han tenido que afrontar las personas han sido factores que han impactado no solo la salud física también la mental de millones de personas.
En este trabajo de inteligencia artificial (ciencia de datos), se realiza un esfuerzo para analizar, predecir y determinar, si una persona está estresada con el uso de sus mensajes a través de la red social de Twitter.
Problema general
¿Es posible que una máquina pueda determinar si una persona está estresada solo con la expresión escrita?
Motivación
Social: ayudar a identificar y reconocer el estrés durante la crisis sanitaria para así conocer el estado emocional de las personas sin necesidad de un estudio en persona
Profesional: obtener, extender y aplicar los conocimientos sobre ciencia de datos e inteligencia artificial, en el análisis de lenguaje humano y en reconocimiento de emociones
Metodología
La metodología con la que se trabajó en este proyecto está basada en la metodología tradicional de CRISP-DM [1]. A continuación se muestra el diagrama general de los pasos que se llevaron a cabo en este trabajo.
Diseño del modelo de reconocimiento:
Recolección de datos
Para llevar a cabo el análisis se recolectaron datos de tweets de 3 diferentes ciudades para poder tener muestras variadas y esperar resultados diferentes. Las ciudades fueron elegidas solamente tomando en cuenta que fueran ciudades grandes en diferentes países angloparlantes.
Las ciudades de las que se obtuvieron los datos fueron las siguientes:
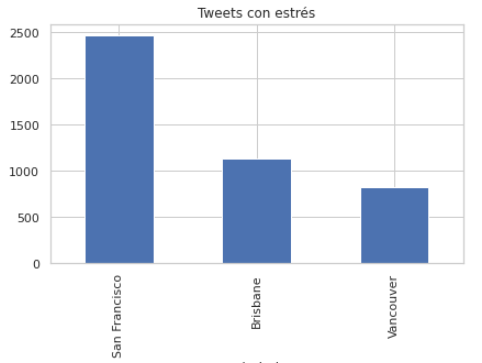
Brisbane, Australia (2225 tweets)
San Francisco, Estados Unidos (5000 tweets)
Vancouver, Canadá (1699 tweets)
Cabe mencionar que los datos fueron recolectados el 24 de octubre y los tweets tienen fecha máxima de publicación una semana anterior a la fecha de recolección y mínima del mismo día de la recolección.
Las palabras claves que se utilizaron para la recolección fueron las siguientes:
covid OR COVID OR coronavirus OR corona OR coronavirus OR #coronavirus OR #covid19 OR covid19 OR sarscov2 OR #covid-19 OR #sarscov2 OR sars OR cov2 OR sars OR #quarantine OR pandemic OR #pandemic OR #2019ncov OR 2019ncov OR quarantine OR lockdown OR #lockdown OR social distancing OR #socialdistancing OR #COVID OR #covid”
La estructura de los datos es idéntica para los 3 datasets. Cada dataset está organizado en 3 columnas:
user_location: Ubicación aproximada del usuario (si su ubicación está activada).
date: Fecha de publicación del tweet.
text: Texto del tweet.
Los datos anonimizados se obtuvieron a través de la API de Twitter a través de un script de Python utilizando Tweepy [2].
Etiquetado
Para el etiquetado de los datos, fue utilizada una herramienta llamada TensiStrength, la cuál está desarrollada en Java, y ayuda a evaluar el nivel de relajación o ansiedad que se puede encontrar en un texto sencillo. Esta herramienta funciona por medio de diccionarios de emociones en los cuales se asignan valores a las palabras positivas o negativas y a su vez también cuenta con un diccionario de palabras (booster words) que incrementan el valor de la expresión/emoción.
TensiStrength logra catalogar los textos de dos maneras disponibles, binaria o ternaria; la ternaria los clasifica en 1, 0, -1, positivo, neutral y negativo respectivamente. El esquema para la clasificación de emociones utilizado en nuestro modelo, utiliza la clasificación de tipo binaria, que consiste en usar las etiquetas 1 y 0, las cuales corresponden a “estrés” y “no estrés”.
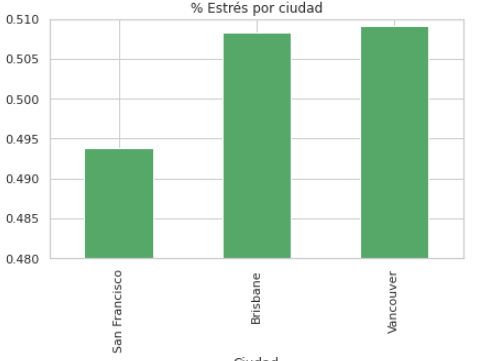
Las clases se encuentran distribuidas con un porcentaje de: Tweets con estrés = 49.972% Tweets sin estrés = 50.028%
Exploración de los datos:
Cantidad de tweets con estrés.
Porcentaje de estrés por ciudad, representa la cantidad de tweets con estrés respecto al total de tweets.
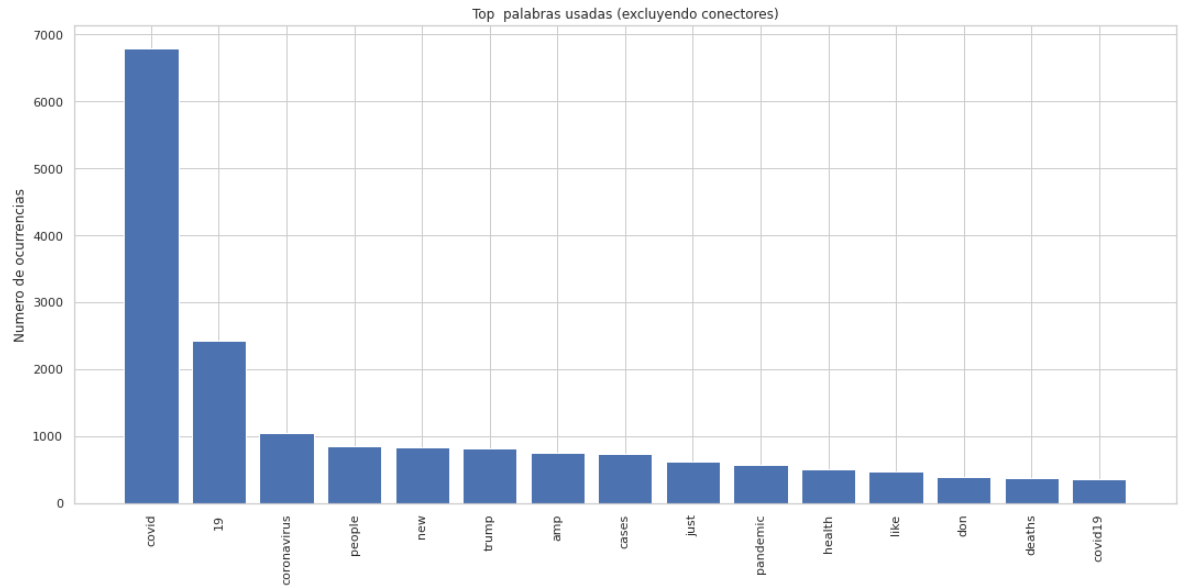
Palabras más usadas en los tweets, excluyendo conectores.
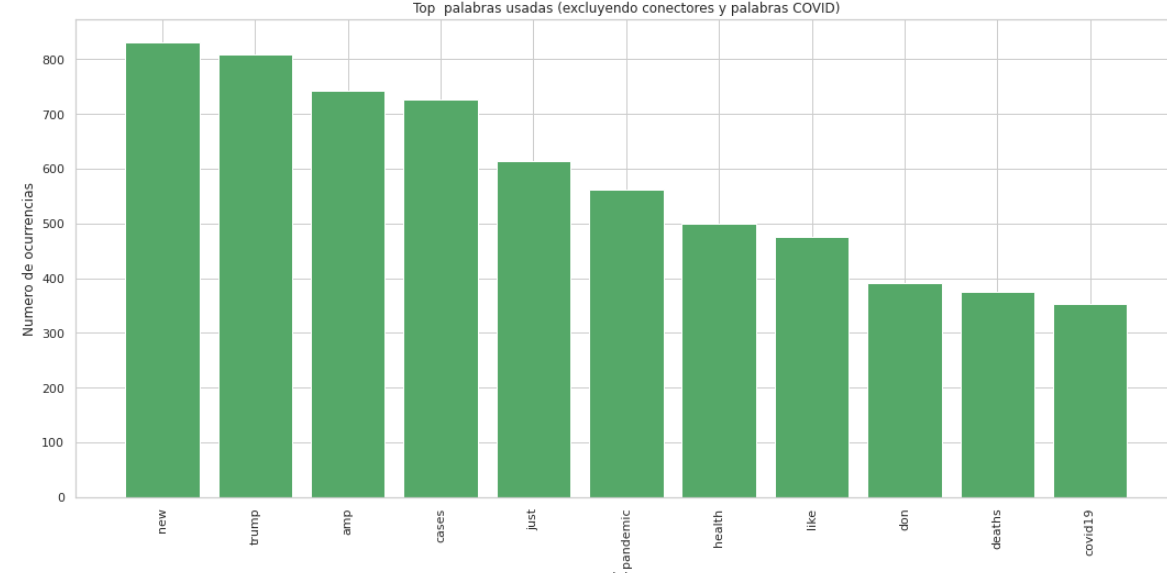
Palabras más usadas en los tweets, excluyendo conectores y palabras relacionadas con Covid.
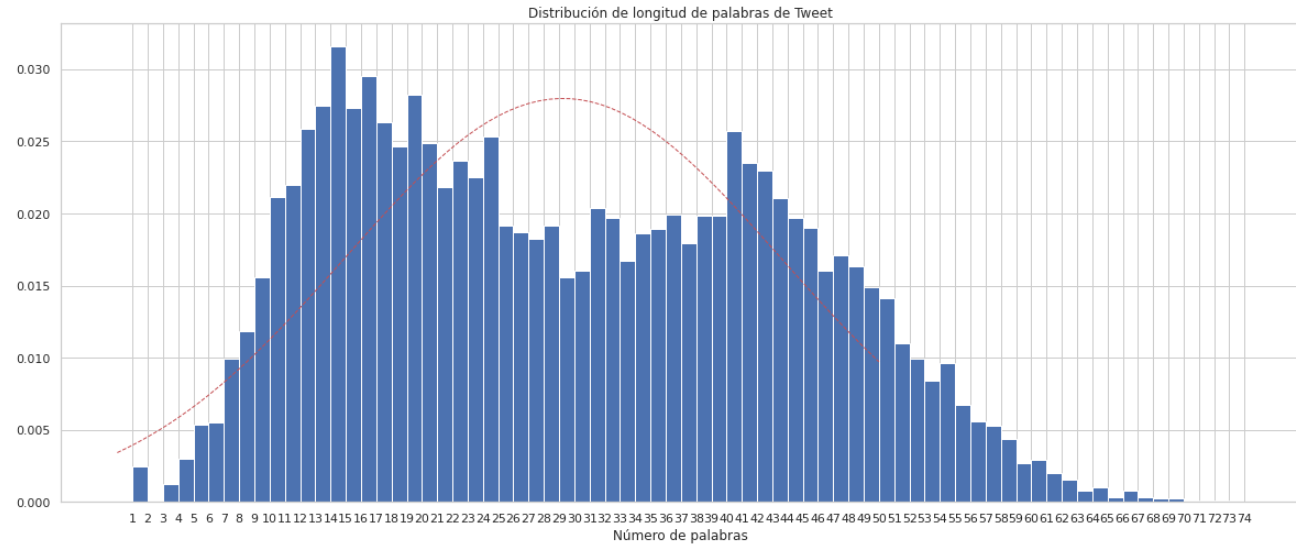
Distribución de las palabras en los Tweets según su longitud
Pre-procesamiento de los datos:
Después de recolectar los datos, se llevó a cabo un pre-procesamiento con el fin de que los datos se pudieran utilizar para entrenar un modelo clasificador. Este paso es uno de los más importantes y es aquel que comúnmente consume más tiempo en un proyecto de aprendizaje de máquina.
Reducción de Ruido: se eliminaron espacios extras, carácteres especiales y ligas a otras páginas.
Normalización: los carácteres se transformaron a minúsculas, se eliminaron puntuaciones y se expandieron las contracciones.
Eliminación de palabras vacías o Stopwords: se removieron aquellas palabras que no tienen un significado por sí mismas (artículos, pronombres, preposiciones y algunos verbos)
Lematización: se llevó a cabo una lematización, la cual consiste en convertir la palabra a su forma base (i.e. mesas a mesa).
Tokenización: finalmente los textos se separaron en palabras, también llamados tokens.
Antes del pre-procesamiento, el texto se visualiza de la siguiente manera:
Posterior a la limpieza y previo a la tokenización, el texto se visualiza de la siguiente manera:
Visualización de datos
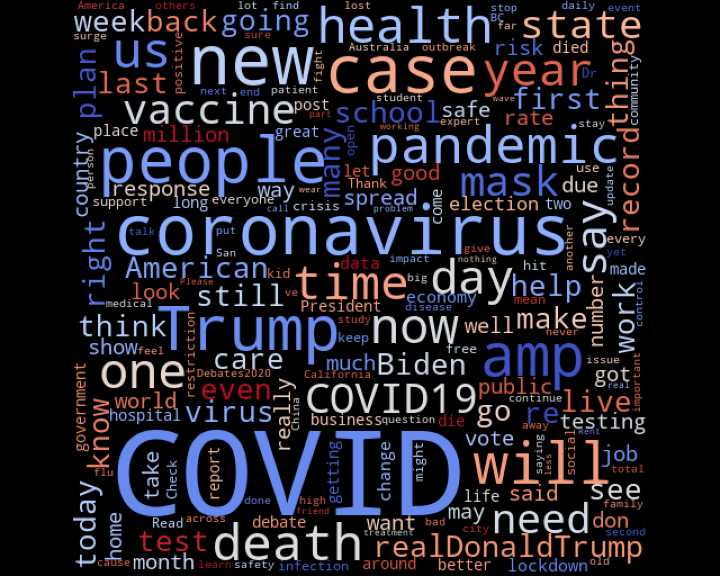
Fue realizada por medio de nubes de palabras, en general y dividiendo los datos por clase.
Palabras más recurrentes en general:
Palabras más recurrentes dentro de los datos clasificados como SIN estrés
Palabras más recurrentes dentro de los datos clasificados como CON estrés
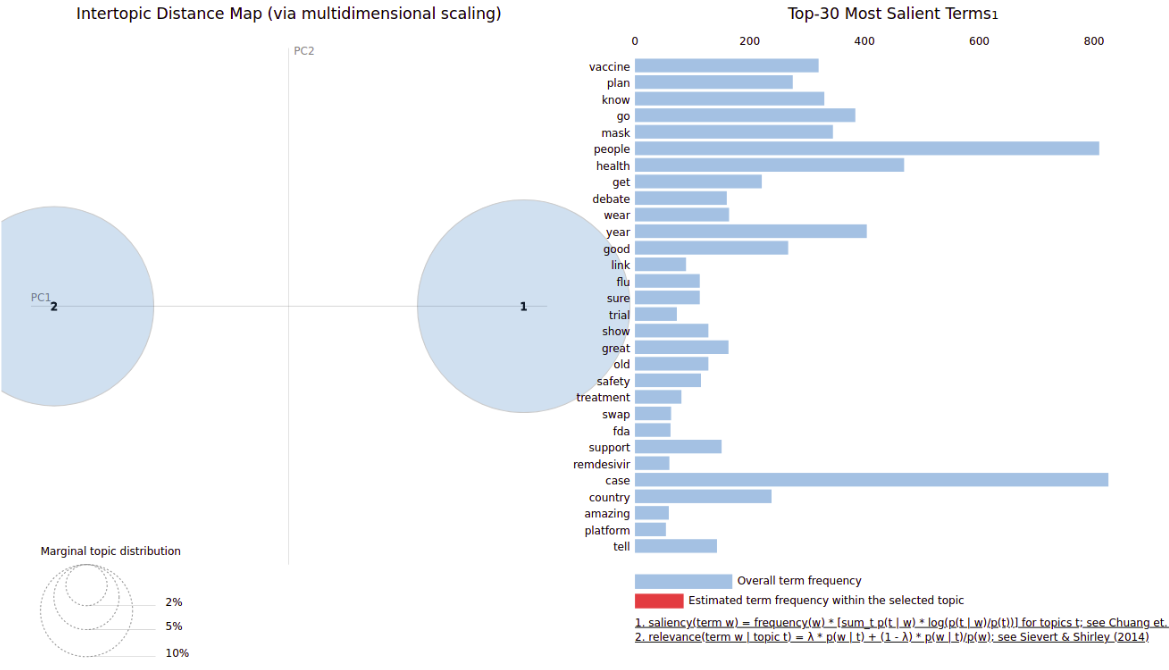
LDA (Latent Dirichlet Allocation)
Se utilizó un clasificador de modelo generativo LDA (no supervisado), que permite que a partir de una bolsa de palabras, se genere un conjunto de observaciones que puedan ser explicadas por algunas de las partes de los datos que son similares o que tienen cierta concordancia. Este es un modelo de categorías y fue presentado como un modelo de grafos para descubrir categorías por David Blei, Andrew Ng y Michael Jordan en 2002.
En nuestro trabajo se utilizó a partir de de la vectorización de la data tratada y limpia de los tweets obtenidos, una tokenización y generando una vectorización de las palabras. Obteniendo un clasificador de 2 tópicos, en las cuales sus principales palabras fueron:
Tópico 0: Covid case new health vaccine death year trump plan day
Tópico 1: Covid people trump go new case mask know say need
y utilizando la librería pyLDAvis se obtuvo el visualizador:
Modelado
Para este proyecto se evaluaron cinco modelos de Machine Learning. Como modelo base se utilizó Naive Bayes y se comparó con:
Regresión Logística
K-Nearest Neighbors
Random Forest
Gradient Boosting.
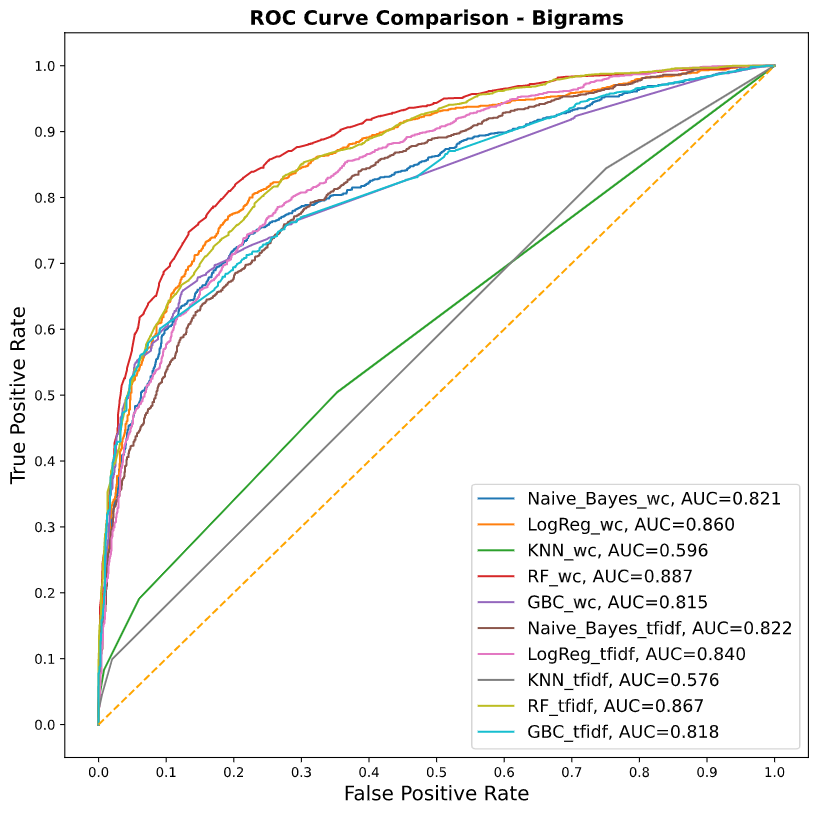
Para la vectorización [4] de los tweets se evaluaron 2 técnicas: Bag of Words y TF-IDF (term frequency — inverse document frequency) y dos estrategias para sus n-gramas: Bigrama y Trigramas [5].
Los resultados se midieron por medio del AUC (Area Bajo la Curva) y se evaluaron con validación cruzada (k = 10). Tanto el preprocesamiento, entrenamiento y evaluación del modelo se llevaron a cabo dentro de un “pipeline” creado dentro de una clase utilizando el lenguaje de programación de Python.
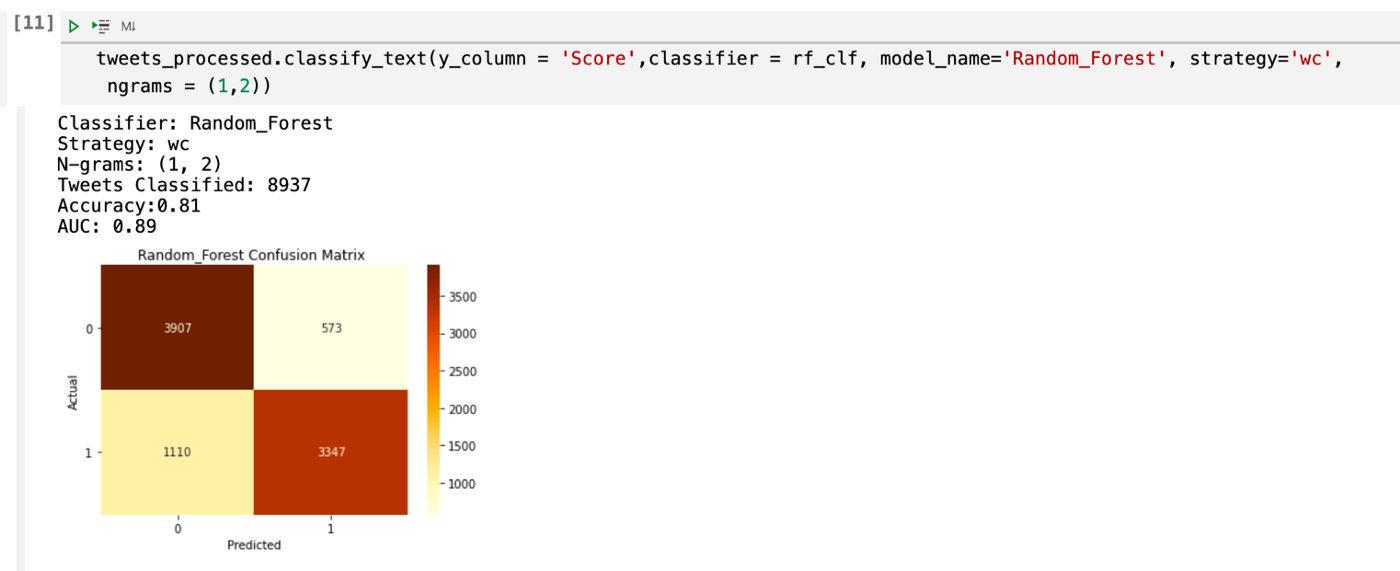
Nivel de precisión para cada modelo implementado con “Bigrams”
Nivel de precisión para cada modelo implementado con “Trigrams”
En las gráficas de AUC previas se muestra que la combinación ganadora es la de: RFt + BoW + Bigramas, ya que es la mejor en discernir los mensajes que tienen alguna relación con estrés de aquellos que no la tienen.
A continuación podemos observar la matriz de confusión del modelo ganador, así como los resultados de sus métricas.
Optimización (‘Tuneo’) del modelo:
El ajuste fue realizado para tres modelos con el fin de mejorar su desempeño.
Logistic Regression Se genera una búsqueda de grilla utilizando grid search al cual se le definen ciertos valores con los que se ejecutará el modelo para obtener la versión con mejor Accuracy. Para esto se consideró: 1.- Valor C 2.- Penalty del modelo: L1 (Lasso) y L2 (Ridge)
Random Forest Classifier Se genera una búsqueda de grilla utilizando grid search al cual se le definen ciertos valores con los que se ejecutará el modelo para obtener la versión con mejor Accuracy. Para esto se consideró: 1.- Número de Estimadores: número de árboles utilizados en el bosque. Este valor empezará en 200 e irá de 10 en 10 hasta llegar a 2000. 2.- Max_Features: es el número de atributos a considerar para la mejor división. Se prueba con “auto” que se refiere a que el máximo de atributos será la raíz cuadrada del número de atributos. 3.- Max_depth: esto se refiere a la máxima profundidad del árbol. Para este caso se parte en 10 hasta 110 avanzando de 11. 4.- Min_Samples_split: es el número mínimo de muestras requeridas para la división interna del nodo. Se prueba con 2, 5 y 10. 5.- Min_samples_leaf: el número mínimo de muestras requeridas para ser una hoja de nodo. Se considera 1, 2 y 4 para realizar la búsqueda de grilla. 6.- Bootstrap: Si es Verdadero, usará bottstrap en la construcción de los árboles. Si es falso no se utilizará. Se probará con ambas.
Gradient Boosting Classifier Se genera una búsqueda de grilla utilizando grid search al cual se le definen ciertos valores con los que se ejecutará el modelo para obtener la versión con mejor Accuracy. Para esto se consideró: 1.- Loss: se usa desviance para evaluar como regresión logística la función de pérdida 2.- Learning:rate: es la medición que mide la contribución de cada árbol. 3.- Max_Features: es el número de atributos a considerar para la mejor división. Se prueba con “sqrt” que se refiere a que el máximo de atributos será la raíz cuadrada del número de atributos, en el caso de “log2” se usa el logaritmo del número de atributos. 4.- Max_depth: esto se refiere a la máxima profundidad del árbol. Para este caso se usa 3, 5 y 8. 5.- Min_Samples_split: es el número mínimo de muestras requeridas para la división interna del nodo. Se prueba con un linspace de 0.1, 0.5 y 12. 6.- Min_samples_leaf: el número mínimo de muestras requeridas para ser una hoja de nodo. Se prueba con un linspace de 0.1, 0.5 y 12. 7.- Numero de Estimadores: número de árboles utilizados en el bosque. Este valor empezará en 200 e irá de 10 en 10 hasta llegar a 2000.
Evaluación:
El modelo generado con mayor eficacia fue el de Random Forest, ya que es capaz de reconocer si un tweet contiene o no estrés con una precisión de 88%, lo cual es una métrica muy buena, ya que la velocidad con la que se puede evaluar un conjunto masivo de tweets con esta exactitud ayuda enormemente en una tarea que un humano tardaría mucho más tiempo, y de esta manera es posible encontrar o tratar posibles casos que requieran asistencia sin necesidad de esperar a que esto lleve a un problema mayor como lo es la depresión.
Análisis de resultados:
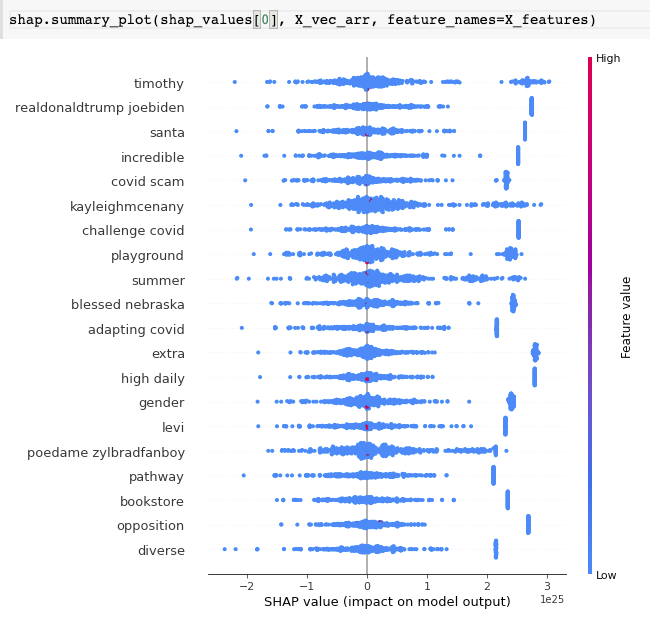
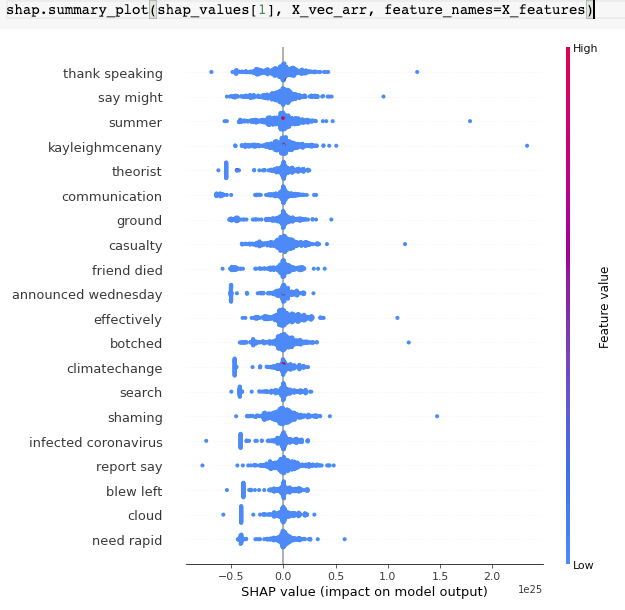
Para poder adentrarnos más en por qué el modelo se comporta de la manera que lo hace, hicimos uso de SHAP, una técnica de teoría de juegos utilizada para explicar los modelos. El modelo utilizado fue un Random Forest con 100 estimadores.
En este caso utilizamos un TreeExplainer de la librería shap. Para calcular estos valores se tuvo que usar solamente el 5% de los datos de entrenamiento y 10,000 features, de otro modo, el tiempo de ejecución sobrepasa la hora y media en Google Colab.
Resultados para tweets que NO tienen estrés:
Resultados para tweets que SÍ tienen estrés:
Casos de uso para el modelo generado:
Instituciones públicas, gubernamentales o privadas que estén interesadas en conocer o monitorear el estado anímico de una población, o conjunto de personas por zona geográfica, para evaluar el nivel de estrés.
Personal que labore en el área médica enfocada en la salud mental, para lograr identificar las condiciones sobre la estabilidad emocional de algún sector de la población.
Empresas privadas que puedan ofrecer servicios de consultoría para el bienestar emocional y que ofrezcan análisis o proyección de campañas de salud mental en la sociedad.
Desarrollo de Modelo en un App Web
Para alojar nuestro modelo de Machine Learning usamos el framework Flask. Este es usado por su facilidad de uso, ser muy escalable y además, está desarrollado para Python. Lo cual permite en un lenguaje realizar todo el desarrollo. Hay que tener claro que una aplicación web tiene dos partes fundamentales.
Partes de una App Web:
El Front-end el cual es una página desarrollada con Html y Css. Sin ninguna parte de JavaScript ya que es una app sencilla de utilizar.
El Back-end será desarrollado con Flask, donde permite crear la integración con el Front-end y además correr el modelo ya entrenado.
Desarrollo de la interfaz de usuario
En esta parte fueron utilizadas dos herramientas en línea bastante útiles que son Flask y Heroku. Flask es un framework para desarrollo web con gran interacción con Python; Heroku es usado como un servidor para el despliegue y disponibilidad pública de la aplicación.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Angiotomografías con contraste ¿Cuál es el problema?
El reto
Los medios de contraste vía endovenosa que se usan en las angiotomografias contrastadas pueden tener incidencia en la salud nefrológica de los pacientes, sobre todo en aquellos que tienen antecedentes de hipertensión arterial, hipercolesterolemia, antecedentes genéticos, en edad adulta mayor (60 años en adelante) y un riesgo cardiovascular aumentado (1), es decir, son más propensos a:
tener accidentes cerebrovasculares,
infarto agudo de miocardio,
enfermedad arterial periférica y,
enfermedades de la aorta en general
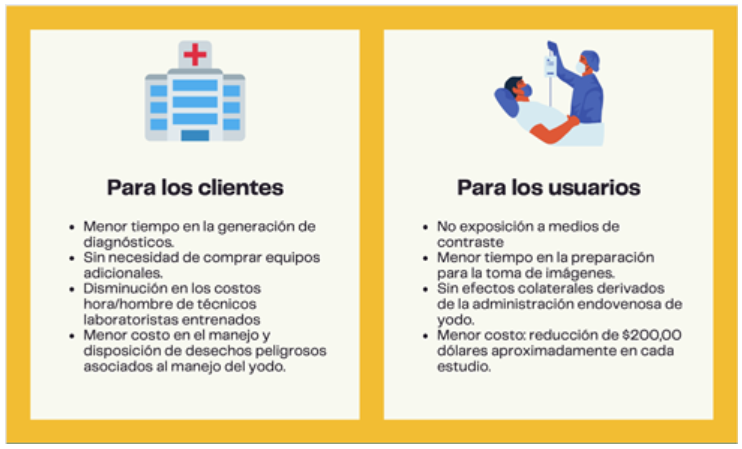
Existe la posibilidad de realizar angiotomografias simples que no requieren el uso de medios de contraste y que tienen un costo menor (alrededor de $200,00 de diferencia), pero estas no permiten una visualización completa de las estructuras aórticas con claridad (2), por lo que no son útiles en muchos casos, como en el de Jesús.
Por qué escogimos Angiotomografías?
La oportunidad ¿Cómo proponemos solucionarlo?
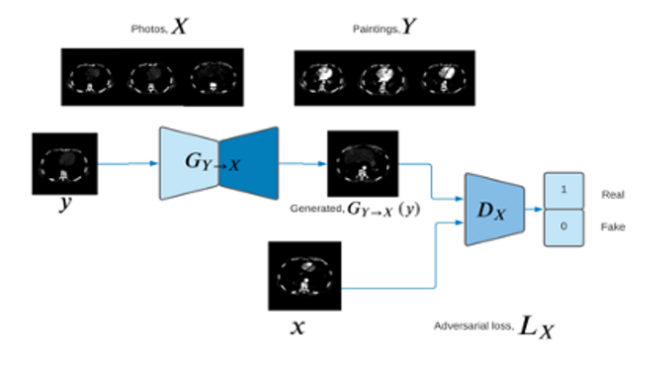
ANGIOP.AI (Sistema de Transformación de Imágenes de Angiotomografía) genera avances significativos en el análisis de imágenes médicas mediante modelos de análisis de inteligencia artificial para angiotomografias, brindando una alternativa que signifique un menor impacto para la salud de los pacientes que, por su diagnóstico y estado general, requieren realizarse este tipo de análisis de manera recurrente.
Figura 1. Estructura del modelo GAN aplicado a la transformación de imágenes de Angiotomografía
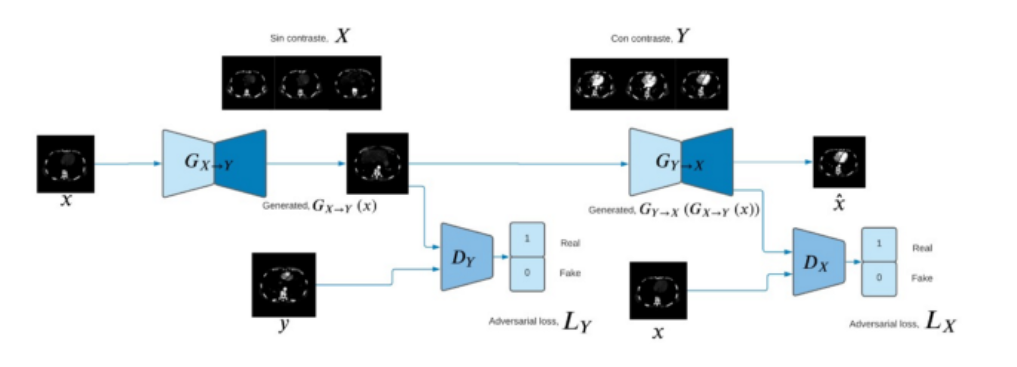
ANGIOP.AI basa su funcionamiento en el entrenamiento, validación y evaluación de un modelo CycleGAN para procesar imágenes de angiotomografias sin contraste y transformarlas en imágenes similares a las que se obtendrían usando métodos de contraste; se entrena un CycleGan para leer una imagen de un dataset X (imágenes sin contraste) y transformarlo para que parezca como si perteneciera a un dataset Y (imágenes con contraste).
¿Cuáles son los beneficios?
ANGIOP.AI está alineada al cumplimiento de los objetivos de desarrollo sostenible de las Naciones Unidas al 2030.
Lo explicamos paso a paso: metodología, modelo usado y datasets
Los datasets utilizados corresponden a los provistos por el Dr. Gonzalo Pullas, director de la carrera de Medicina en la Universidad de las Fuerzas Armadas; quien facilitó las imágenes de angiotomografias con contraste y angiotomografias simples (sin contraste) de 10 pacientes anónimos.
El total de imágenes facilitadas fueron de 5.144, de tamaño 512 x 512, en escala de grises, a las que se les aplicó una exploración de los datos — análisis estadístico para descartar imágenes a color y en 3D, sin datos atípicos y con Diferencias en distribución de pixeles (zonas / cortes). Es importante mencionar que las angiotomografías fueron tomadas en la misma zona anatómica, pero en diferentes oportunidades, es decir, las imágenes no corresponden a una paridad 1:1.
El modelo utilizado es CycleGan con pre-procesamiento de imágenes de escala -1 a 1 para la entrada del modelo. Los discriminadores son redes convolucionales con 5 capas que receptan imágenes de 256×256. Las 4 capas son de definición de patrones y una capa de clasificación. El generador utiliza tres capas convolucionales y seis bloques residuales. Para el cálculo de las funciones de costos, tanto para las imágenes reales como falsas, se está utilizando el proceso del error cuadrático medio (mean squared error).
El modelo utiliza los siguientes parámetros:
20000 épocas
Tasa de aprendizaje del 0,0001
Para el entrenamiento se aplicaron los siguientes pasos:
Seleccionar una cantidad de imágenes reales
El generador toma las imágenes reales y les agrega ruido para crear una cantidad de imágenes falsas
Entrenar al discriminador, haciendo que clasifique las imágenes como falsas o verdaderas un cierto número de veces o épocas
Generar otra cantidad de imágenes falsas para entrenar el generador
Se entrena al modelo
Para finalizar el modelo, se debe revisar la veracidad de la ejecución, revisando el gráfico de pérdidas a través del tiempo y revisando las muestras generadas por el modelo.
Veamos los resultados:
Lecciones aprendidas
Enseñar al modelo a validar las imágenes de entrada si corresponde a la zona angio toráxica.
Aumentar el Dataset para futuros entrenamientos.
Se requiere una validación de las imágenes generadas con un panel de expertos médicos.
Lo que se viene: Futuro de ANGIOP.AI
Usar la data generada para medir el impacto del uso del sistema en reducción de incidencia de enfermedades renales.
Diego Chiza, Ana Gayosso, Gabriela Jiménez, Paola Peralta, Patricia Román José Daniel Sacoto, María Teresa Vergara, Hilario Villamar, David Medrano.
Presentación del proyecto: DemoDay
Repositorio
El código fuente de este proyecto se puede encontrar en: github
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
El brote de COVID-19 y las respuestas sociales adoptadas para combatir su propagación (por ejemplo, el confinamiento y el distanciamiento social) han tenido consecuencias de gran alcance, pero han brindando también una oportunidad única para examinar los efectos que el estrés crónico y la incertidumbre pueden tener en los patrones de sueño de la población en general.
Está bien documentado que el sueño puede verse afectado cuando se está bajo estrés y que los cambios en el sueño pueden tener consecuencias negativas en las emociones y el bienestar mental. Un metanálisis reciente mostró que la pandemia de COVID-19(1) ha provocado una alta prevalencia de trastornos del sueño, que afectan aproximadamente al 40 % de las personas de la población general.
Se sabe que además del estrés debido a la pandemia por COVID-19, hay otros factores que podrían alterar la resiliencia mostrada bajo estrés, por ejemplo,la falta de interacción social, la falta de ejercicio físico, el bienestar económico etc.
Este proyecto tiene como objetivo determinar qué factores pueden afectar la calidad del sueño de la población cuando están sujetas a situaciones de estrés crónico como es el caso de una pandemia. Predecir dichos factores permitiría emitir consejos útiles para la población, de tal forma que estén mejor preparados para futuras pandemias y/o situaciones de estrés crónico que permitan mitigar el impacto emocional causado por la mala calidad de sueño.
Metodología
La base de datos seleccionada para este proyecto ha sido la publicada por la Universidad de Boston2, que consiste de una serie de encuestas realizadas a 1,518 personas a través de redes sociales para evaluar el impacto de la pandemia en el bienestar emocional y mental de las personas dependiendo diversos factores como la edad, el impacto económico, la condición de minoría y o el estado de riesgo.
Una vez seleccionada la base de datos proseguimos a la limpieza y procesamiento de los datos. Después de este proceso, el número de variables de nuestra base de datos fue de 216 y el tamaño de la muestra se redujo a 839 sujetos debido a que no toda la información estaba completa.
Las variables principales incluyen información demográfica (edad, identidad de género, ingresos, etc.), información relativa a los hábitos de sueño, niveles de ansiedad, regulación emocional cognitiva, y personalidad, entre otras.
La métrica elegida para evaluar la calidad del sueño fue la variable del índice total de calidad del sueño de Pittsburgh (PSQI), que tiene una escala de 0 a 21. En dicha escala, una puntuación global de 5 o más indica una mala calidad del sueño; cuanto mayor sea la puntuación, peor será la calidad.
Análisis del dataset
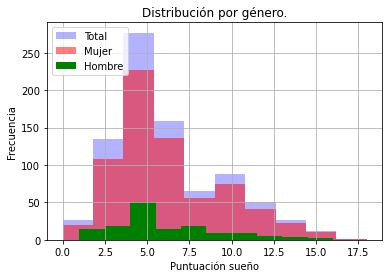
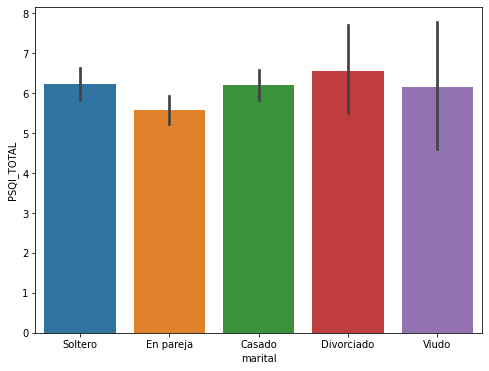
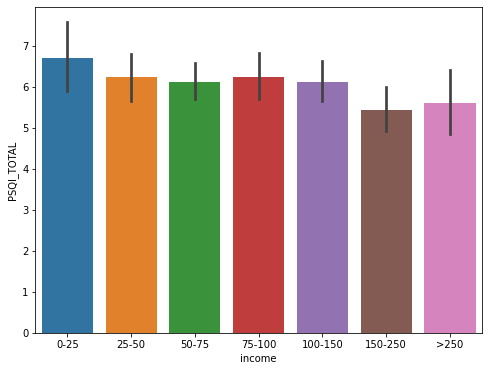
Observamos la distribución de los datos
Puntuación sueño
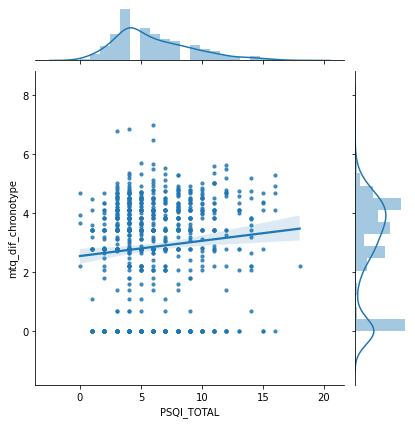
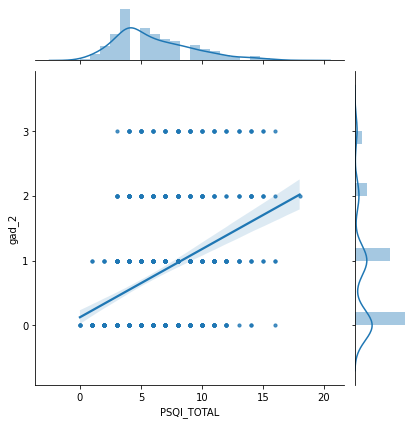
Observamos la correlación que entra la calidad de sueño con otras variables no asociadas al sueño:
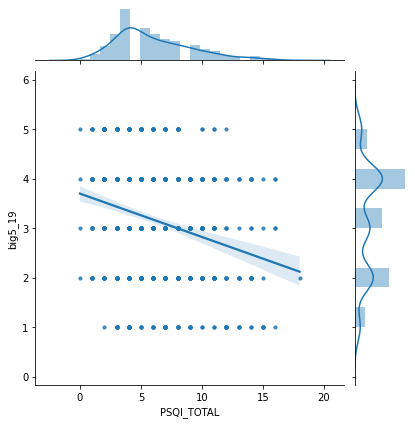
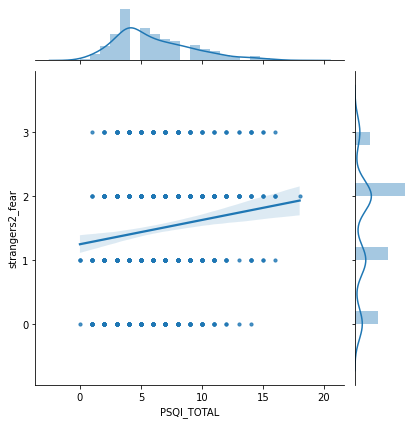
Diferencia de cronotipo pre y post covid
Variable de ansiedad (No consigue dejar de preocuparse)
Variable de personalidad (Se considera relajado)
Variable de ansiedad social (Miedo a extraños post covid)
Modelos
Clasificación
En el conjunto de datos, nuestra métrica elegida para evaluar toma valores del 0 al 18 (no se han observado casos de 19 a 21). Si tomamos estos valores como si fueran clases o subconjuntos podemos aplicar un método de clasificación.
Hemos elegido aplicar el algoritmo de RandomForestClassifier con el que en un principio obtenemos valores muy bajos de precisión rondando el 0,20. A continuación, probamos a recudir las clases agrupando los valores originales de la métrica. A medida que vamos reduciendo las clases observamos que los valores de precisión van mejorando, para 6 clases el resultado mejora en torno a 0,5 y para 4 clases el resultado llega a 0,7.
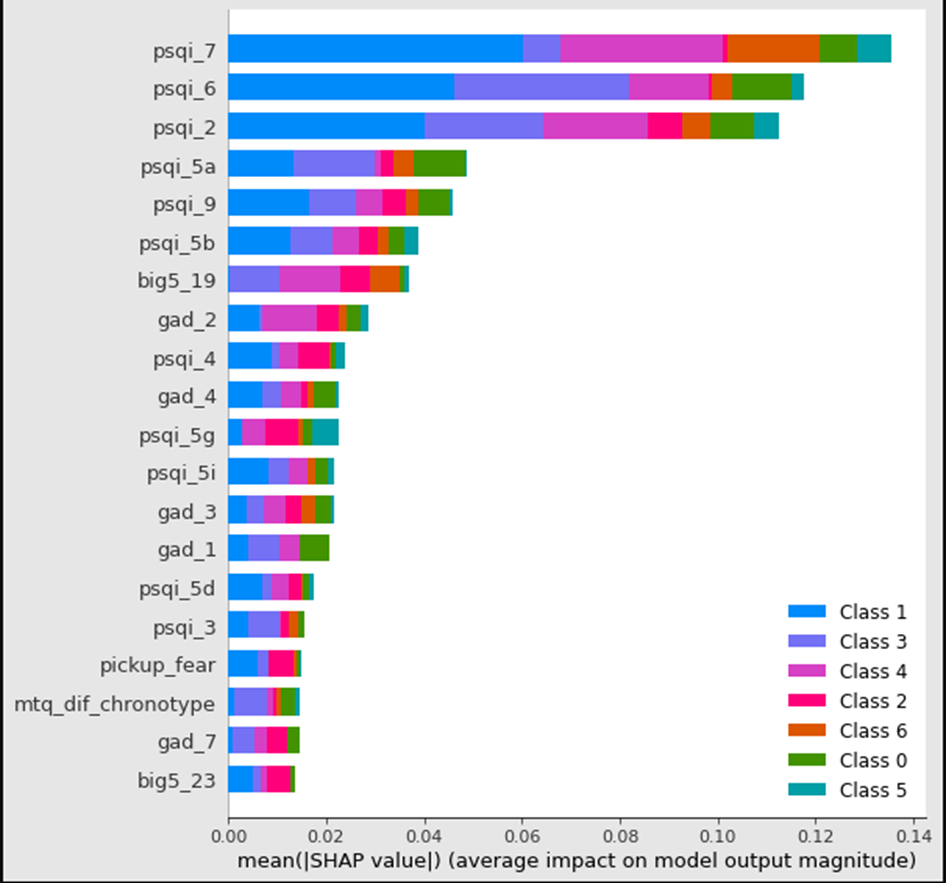
Para tener una explicación de estos resultados mostramos los shap values de las predicciones:
Podemos observar que las variables que aparecen con más peso, son las que están directamente ligadas con datos de sueño (psqi_*). Las primeras de todas ellas son si la persona ha recurrido a medicinas para dormir, la percepción que declara de su calidad de sueño, y el tiempo que tarda en conciliar el sueño. Dentro de estas variables también observamos que tienen impacto datos de personalidad (big5_*) , como si se considera una persona relajada, o ansiedad (gad_*), como la capacidad de dejar las preocupaciones.
Según lo observado podemos concluir que el algoritmo está funcionando correctamente y que los datos en los que se basa para realizar las estimaciones son los esperados. Creemos que el número de observaciones con las que contamos son muy bajas para el número de clases a predecir y que aumentando los datos se podrían mejorar las predicciones.
Regresión
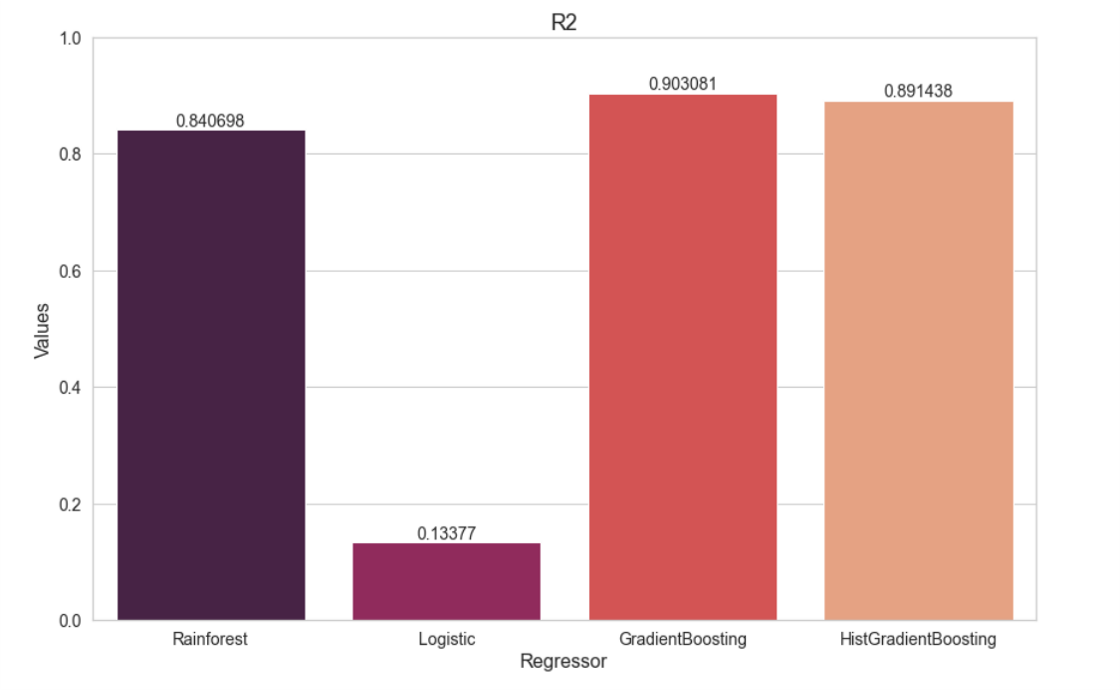
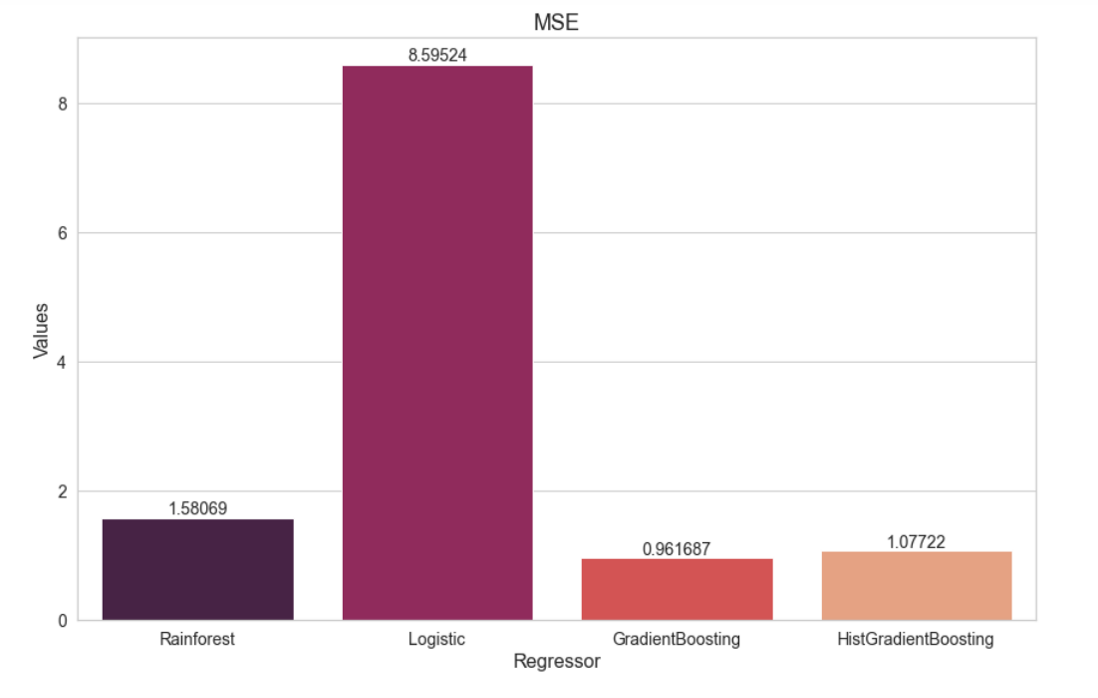
Para la regresión hemos elegido cuatro algoritmos distintos: RandomForest, Logistic, GradientBoosting y HistGradientBoosting.
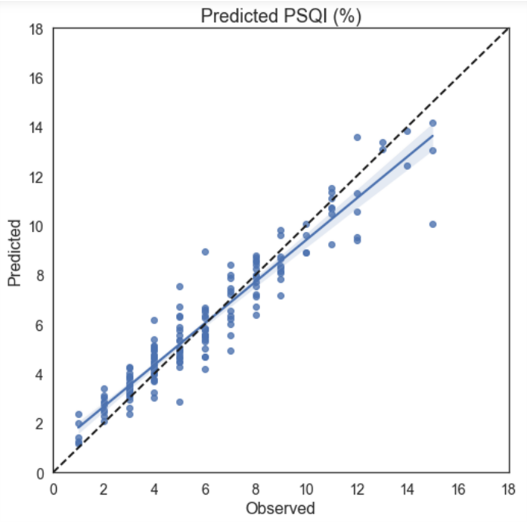
El algoritmo que produjo el mayor coeficiente de determinación fue el de GradientBoosting, con un R2=0.9. Lo que significa que el 90% de los puntos se ajustan a la línea de regresión.
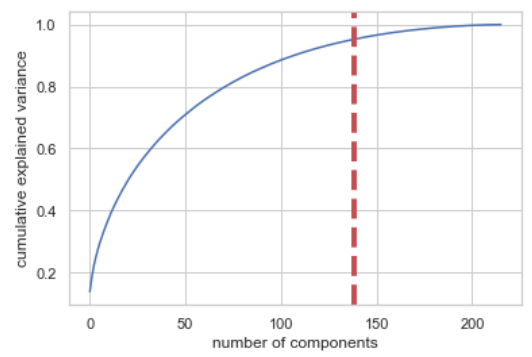
Una vez seleccionado el mejor algoritmo intentamos utilizar la optimización de los argumentos usando RandomizedSearchCV pero no obtuvimos nada mejor. Además probamos reducir el número de variables mediante el uso de PCA. Obtuvimos el número óptimo de variables y redujimos el tamaño de la base de datos a ese número, en este caso 138, pero los resultados empeoraron, la R2 disminuyó hasta 0.57.
Análisis PCA para reducir el número de variables
Por esta razón decidimos quedarnos con el resultado obtenido con el algoritmo de GradientBooster como la mejor opción para predecir la calidad del sueño.
Conclusión
Es posible predecir la calidad del sueño con un 90% de precisión. Pudimos observar que la calidad del sueño depende en mayor medida de variables relacionadas con:
Medicación
Tiempo que toma a la persona conciliar el sueño
Entusiasmo por llevar a cabo cosas
Manejo del estrés
Control de las preocupaciones
Esta predicción, aunque intuitiva, puede ser de utilidad para implantar medidas que puedan ayudar a la población a mejorar la calidad del sueño en situaciones de estrés crónico como la sufrida durante una pandemia.
En el futuro, este proyecto se podría mejorar aumentando el número de muestras de la base de datos actual.
Referencias
1. Jahrami, H. et al. Sleep problems during COVID-19 pandemic by population: a systematic review and meta-analysis. J Clin Sleep Med, jcsm-8930. (2020).
2. Cunningham, T.J., Fields, E.C. & Kensinger, E.A. (2021) Boston College daily sleep and well-being survey data during early phase of the COVID-19 pandemic. Sci Data 8, 110. https://www.nature.com/articles/s41597-021-00886-y
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
En Ecuador, el uso del celular mientras se conduce un vehículo registró un incremento en los primeros nueve meses del 2021; entre enero y septiembre de 2021 se reportaron 15,393 siniestros de tránsito. De ellos, 3,989 están relacionados con distracciones, ejemplo el uso del celular el cual representa el 26% del total mencionado. Si se compara con igual periodo del 2020 se observa un incremento: 240 siniestros más causados por este tipo de distracciones. (ANT, 2021)
Como se puede apreciar en la Figura 1, solo en Guayaquil, una de las ciudades más importantes del país, registra un total de 1,450 accidentes de tránsito por conducir desatento a las condiciones de tránsito (celular, pantallas de video, comida, maquillaje o cualquier otro elemento distractor) etiquetada como C14; estos tipos de distractores dejaron 1,256 fallecidos en la vía”, siendo una de las primeras causales de esto. El conducir en estado de somnolencia o malas condiciones físicas (C03) solo registra un total de 9 accidentes y 11 fallecidos en el año 2021.
Clasificación de estados y distractores
Existen varios tipos de distracciones al conducir y así lo determina la National Center for Statistics and Analysis (NCSA por sus siglas en inglés) las cuales se clasifican de la siguiente manera: (NHTSA, 2021)
Estado del conductor:
Atento
Distraído
Miró, pero no vio
Tiene sueño o se quedó dormido
Distracciones relacionadas al conductor:
Comer o beber
Persona, objeto o evento externo
Ajuste de radio, casete o CD
Otros ocupantes del vehículo
Objeto en movimiento en el vehículo
Descripción del problema
De acuerdo con los datos estadísticos obtenidos un número importante de personas mueren como resultado de accidentes de tránsitos. De todos ellos, muchos son provocados por lo que se conoce como inatención, cuyos principales factores contribuyentes son tanto la distracción como la somnolencia. Por lo tanto, los conductores con fatiga pueden beneficiarse de un sistema que los alerte al momento de perder la atención.
En base a lo mencionado en líneas anteriores, se plantea el siguiente problema:
¿Cómo evitar que un conductor de vehículo se distraiga o caiga en estado de somnolencia?
Objetivo general
El objetivo fue diseñar una herramienta para entornos vehiculares, la cual, mediante técnicas de Deep Learning detecte tanto la distracción como la somnolencia en los conductores y pueda enviar una alerta sonora directamente al conductor, para que vuelva la atención inmediatamente a la vía y así evitar que ocurra un siniestro de tránsito, además de que se pueda monitorear las alertas mediante una consola de administración, con el fin de controlar al personal que está maniobrando el vehículo.
Estructura de la herramienta
La Figura 2 muestra la estructura de la herramienta, su funcionamiento será de la siguiente manera:
Cámara web con altavoz implementada en la cabina del conductor de manera frontal directa.
Servidor Web donde se ejecutará el algoritmo, el cual procesará las imágenes y realizará las detecciones acordes al entrenamiento, sea por distracciones o estado de somnolencia. Luego del procesamiento y la detección, este, enviará una alerta directa al conductor, el tipo de esta alerta será sonora, con el objetivo de que regrese la atención a la vía.
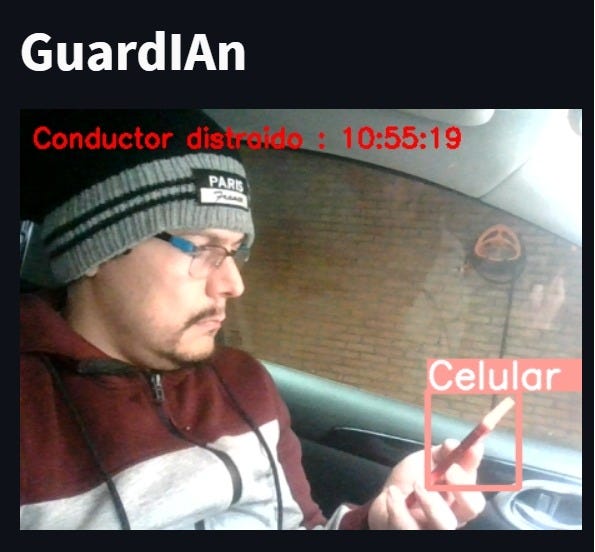
Panel de administración o control, luego del procesamiento y ejecución del algoritmo, se enviará también una alerta visual o textual al administrador de la herramienta, para que internamente se lleve un control de los actos cometidos por el conductor.
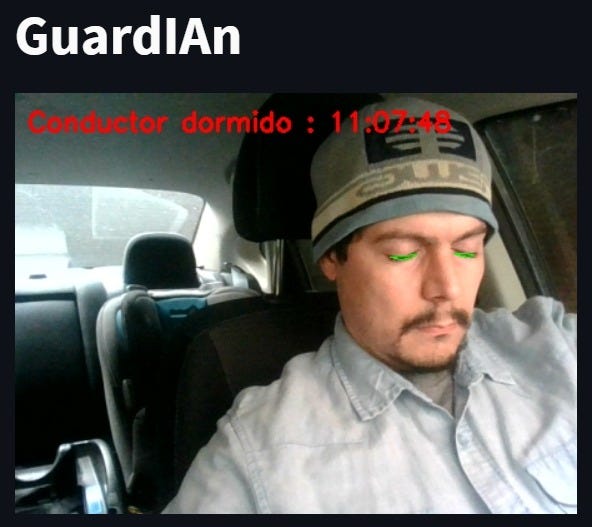
La Figura 3 y 4, muestra la alerta que se mostrará en el panel administrativo de la herramienta en diseño, enviando la imagen del conductor con el objeto distractor o con el estado del conductor.
Técnicas implementadas
A. Detección de inatención
Para detectar las distracciones del conductor necesitamos entrenar un modelo de detección de objetos. La detección de objetos es una tecnología de visión artificial que localiza e identifica objetos en una imagen, debido a su versatilidad, se ha convertido en los últimos años en la tecnología de visión artificial más utilizada.
La tarea de detección de objetos localiza objetos en una imagen y los etiqueta como pertenecientes a una clase objetivo, como se muestra en la imagen a continuación.
Los modelos de detección de objetos logran este objetivo al predecir las coordenadas X1, X2, Y1, Y2 y las etiquetas de clase de objeto.
Para nuestro proyecto utilizamos YOLO V5, YOLO se introdujo inicialmente como el primer modelo de detección de objetos que combinaba la predicción de cuadros delimitadores y la clasificación de objetos en una única red diferenciable de extremo a extremo. Fue escrito y se mantiene en un framework llamado Darknet. YOLO V5 es el primero de los modelos de YOLO escrito en el marco PyTorch y es mucho más liviano y fácil de usar. Dicho esto, YOLO V5 no realizó cambios importantes en la arquitectura de la red en YOLO V4 y no supera a YOLO V4 en un punto de referencia común, el conjunto de datos utilizado fue de COCO dataset.
La Figura 6, nos muestra la arquitectura utilizada de Yolo V5, que está compuesta de la siguiente manera:
Backbone:
Model Backbone actúa como un extractor de características de una imagen de entrada. El extractor de características no es más que el uso de capas convolucionales como kernel, stride, la normalización por lotes se aplica a las imágenes de entrada para extraer características importantes como bordes, formas, etc. CSP (redes parciales de etapa cruzada) se utilizan como columna vertebral en YOLO V5 para extraer características útiles de una imagen de entrada.
Cuello:
En la capa de cuello, la red se diseñó para realizar predicciones de múltiples escalas además de la red de pirámide de características. La predicción multiescalar ayuda a detectar objetos de diferentes tamaños al enviar imágenes a tres valores de cuadrícula diferentes. Entonces, las imágenes de cuadrículas pequeñas detectan objetos grandes y las imágenes de cuadrículas grandes detectan objetos pequeños.
Head:
El modelo Head es el principal responsable del paso final de detección. Utiliza cuadros de anclaje para construir vectores de salida final con probabilidades de clase, puntajes de objetividad y cuadros delimitadores.
B. Detección de sueño y distracción de la visión
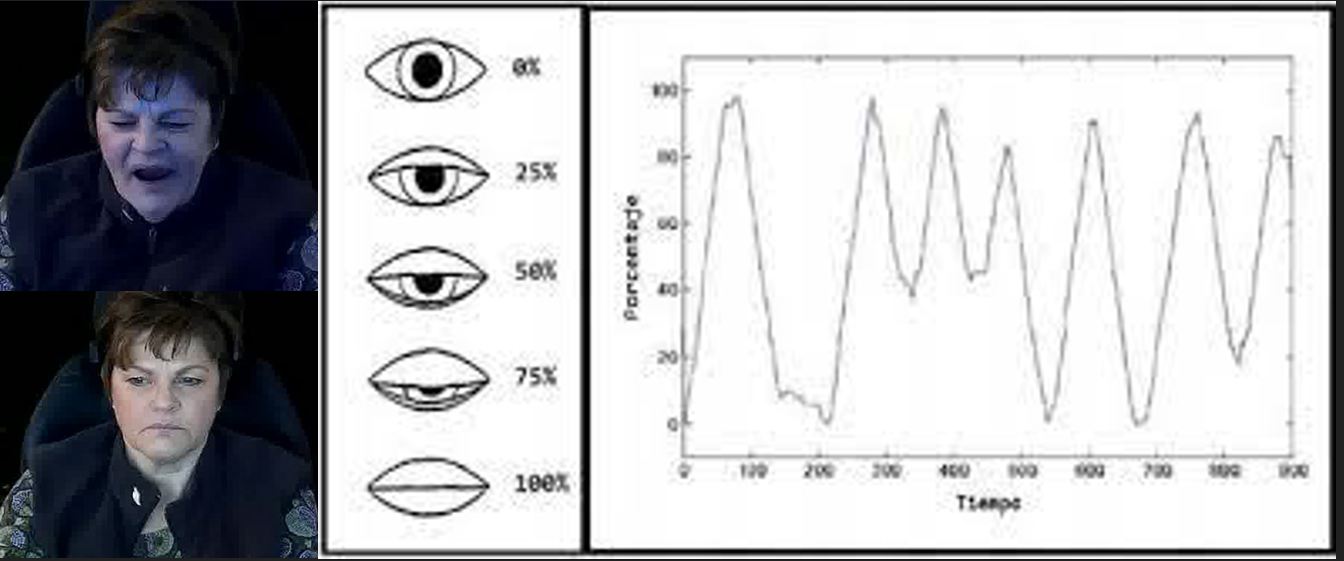
Para la detección de los ojos se utilizó la librería Dlib en conjunto con el modelo de referencia de rostros: shape_predictor_68_face_landmarks.dat, el cual utiliza la máscara de detección de puntos (Figura 7) para determinar ubicaciones clave que conforman un rostro.
Utilizando estas herramientas se logró identificar la ubicación de los ojos tomando como referencia desde el punto 36 hasta el 41 para delinear el ojo izquierdo y del 42 al 47 el ojo derecho.
Con esta información se logró determinar si frente a la cámara se encontraba un rostro humano, y en caso afirmativo se utilizó la distancia euclidiana (para determinar la longitud de una línea recta entre dos puntos) y así establecer si los ojos se encuentran abiertos o cerrados.
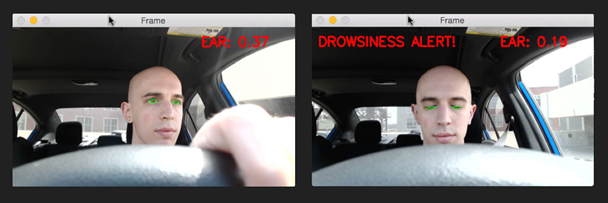
Posteriormente, si los ojos permanecen cerrados por más de dos segundos entonces se activa una alarma cuya finalidad es despertar al conductor (Figura 3). Por otra parte, si el conductor está viendo en cualquier dirección que no sea el frente, después de cuatro segundos la alarma se activa para alertar respecto a la distracción (Figura 3).
Evaluación del modelo
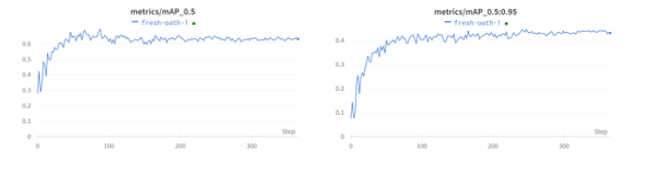
Utilizamos YOLO V5, posterior al entrenamiento, evaluamos las pérdidas de entrenamiento y las métricas de rendimiento en Weights & Biases.
El mAP a 0,5 y el mAP a 0,5:0,95 se trazan para 200 épocas. mAP@[0.5:0.95] significa mAP promedio sobre diferentes umbrales de IoU, de 0.5 a 0.95, paso 0.05 (0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95).
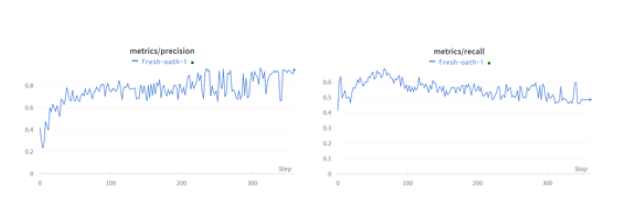
En cuanto a la precisión y la recuperación para 200 épocas se dan a continuación. La precisión fue buena durante las últimas épocas, pero los valores de recuperación fueron más bajos durante las últimas épocas.
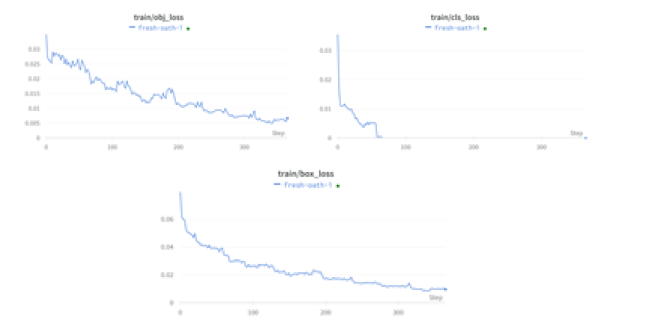
Pérdida de entrenamiento y validación:
En detección de objetos, hubo un total de 3 pérdidas para calcular
Pérdida de caja: que es una pérdida al cuadrado porque detectar las coordenadas de la caja es una tarea de regresión simple
Pérdida de clase, que es una pérdida de registro porque predice la probabilidad de que un objeto pertenezca a una clase.
Pérdida de objetos
Generación y preparación del conjunto de datos
Para entrenar nuestro modelo de detección de objetos necesitamos supervisar su aprendizaje con anotaciones de cuadro delimitador. Dibujamos un cuadro alrededor de cada distractor que el detector reconozca: celular, comida, cigarrillo y botellas para identificar cuando el conductor está distraído o realizando alguna actividad ajena a la conducción. Existen muchas herramientas de etiquetado (CVAT , LabelImg , VoTT, Roboflow ) y soluciones a gran escala (Scale, AWS Ground Truth), en nuestro caso utilizamos Roboflow.
Las imágenes para construir nuestro conjunto de datos fueron descargadas de Kaggle y COCO Dataset:
Dataset containing smoking and not-smoking images (smoker vs non-smoker)
Mobile Images Dataset
COCO Dataset
Ventajas de usar guardian
Innovador, diseñado con Inteligencia Artificial, algoritmo de Deep Learning
Preciso, algoritmo entrenado con una precisión de 92% de distractores y parpadeos de ojos.
Accesible, la herramienta se puede implementar en cualquier parte del mundo.
Adaptable, el algoritmo se puede re-entrenar las veces que haga falta.
Liviano y fácil de manejar, no necesita de instalación y su uso administración es muy fácil.
Confiable, herramienta diseñada para la nube, capaz de mantenerse activa 24/7
Conclusión
La inteligencia artificial ha incrementado sus posibilidades, especialmente desde la aparición de tecnologías como las redes neuronales y el aprendizaje automático (machine learning).
Al utilizar Deep Learning, para identificar patrones en fotos o vídeos y llevar a cabo la detección de distractores o estado de somnolencia del conductor, es posible enviarle una alerta sonora que regresaría la atención inmediata y probablemente se evitaría un siniestro de tránsito, reduciendo así la tasa de mortalidad por estas causas.
El proyecto se diseñó como un sistema para entornos vehiculares funcional, capaz de detectar la fatiga y los objetos distractores mientras se conduce un vehículo, además de emitir los dos tipos de alertas (sonora y textual). El modelo logra detectar los distractores correctamente en un 92 %.
El algoritmo podrá seguir entrenando y ampliando los objetos distractores para su detección.
Planes a futuro
El presente proyecto tiene la intención de llevar a las siguientes empresas:
Empresas de transporte masivo (Terminal terrestre, estación de autobuses)
Empresas de transporte ejecutivo (Uber, Cabify, Taxi amigo)
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Today, thanks to deep learning algorithms of artificial intelligence, we have the possibility to automate the classification of images, so this tool can help medical personnel in the classification and early detection of breast cancer. In this way, women suffering from this disease could be diagnosed automatically, in time to start treatment.
Breast cancer is the most common type of cancer in women and is also one of the main causes of death according to the WHO (WHO, 2020). Early detection is the single most important factor in lowering cancer treatment costs and mortality. To make it possible it is necessary to have medical ultrasound images and specialists who can explain them. However, the lack of these creates a gap in access to early treatment in countries with little or not enough access to specialized diagnostic services and whose population receives low and middle income.
Description of the problem
Our project consists of the detection and classification of breast cancer in women between 25 and 75 years old. This is possible from the development of an deep learning model trained with images obtained using ultrasound scanners that result in the segmentation of the type of cancer that could be suffered.
Objective
Allow women suffering from breast cancer to be automatically diagnosed using a deep learning model so that they can start treatment early and safely, reducing costs and the mortality rate. To meet this objective, we have proposed a tool that uses artificial intelligence to provide greater agility to the process through self-diagnosis with ultrasound images.
Model selection
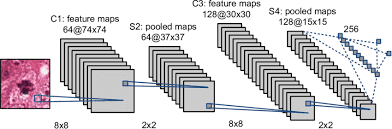
The breast cancer detection and classification project works with ultrasound images of three types, labeled as benign, malignant and neutral, so the deep learning model selected for its execution is convolutional networks with TensorFlow Keras.
Datasets
The dataset was collected from Baheya Hospital for Early Detection and Treatment of Women’s Cancer, Cairo, Egypt. It contains 780 breast ultrasound images, in women between 25 and 75 years old (133 normal, 437 benign and 210 malignant) with an average image size of 500 x 500 pixels, some of which are seen below,
Fig. 1. Samples of images
The images from the original dataset contain mask images that do not provide meaningful information to the model we developed, for this reason Shell statements were used to remove them from the dataset we are using.
Implemented techniques
We must emphasize that until now there is a shortage of public data sets of breast cancer ultrasound images and it prevents the good performance of the algorithms. Because of this, the authors who made public the dataset we used, recommend augmenting data using GANs.
Our project developed GAN networks for each class in order to obtain more accurate results and 150 epochs were used.
However, it failed to create usable images, for this reason we declined the use of this technique. The challenge is to develop the GAN with a greater number of epochs and with a better neural network configuration to obtain more realistic images.
Fig. 2. MALIGNANTSource: Compiled by authors using MatplotlibFig. 3. BENIGNSource: Compiled by authors using MatplotlibFig.4. NORMALSource: Compiled by authors using Matplotlib
Network definition
Within the possible design patterns in Keras, subclassing has been implemented to use the low-level APIs of Keras. You can consult more information about this in the following article:
Preprocessing layer: Resizing, Rescaling and Normalization
Conv2D: 32 filters, 4 strides, ‘same’ padding and ReLU activation
MaxPooling2D: pool_size of (3,3), ‘same’ padding and 2 strides
Flatten
Dense: 512 neurons and ReLU activation
Dropout (0.4)
Dense: 3 neurons and SoftMax activation
We are based on AlexNet architecture, on which we made some adjustments like number of neurons, fully connected layers and dropout values.
We use Adam optimizer with learning rate of 0.0001, the Sparse Categorical Crossentropy loss function and Sparse Categorical Accuracy function.
Fig. 5. Model summary — Source: Compiled by authors
Training
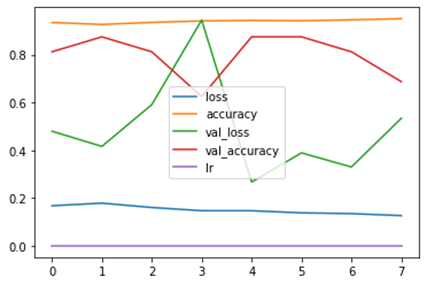
TensorBoard was used to observe the real-time behavior of the accuracy and loss values, which provides useful graphs to analyze results and many controls for their manipulation.
Fig. 6. Dashboard TensorBoard — Source: Compiled by authors
Earlystopping
We use EarlyStopping as a form of regularization to avoid overfitting when training the model. For example, if the loss value stops decreasing, the training will stop even though all iterations have not been completed.
Conclusions and future works
WomanLife is intended to be an easy-to-access, low-cost medical diagnostic tool.
This AI is not only beneficial for women who use it but also has the potential to become a medical assistant. We want to clarify that WomanLife does not intend to replace medical specialists but to provide a tool that facilitates their work.
From now on we intend to optimize the model using a GAN network to obtain greater precision and use techniques that find the correct parameters for training the model (Hyperparameter tuning).
Our project also developed an application that, given an image scanned with the camera or selected from the gallery, goes through the developed network and returns a series of probabilities related to the type of cancer suffered.
The model was developed in pure TensorFlow, converted, saved and exported to TensorFlow Lite.
Fig. 7. Sample of the operation of the application prototype — Source: Own elaborationFig. 8. Conversion from TensorFlow to TensorFlow Lite architecture — Source: Own elaboration
Sources
You can access to notebook and mobile application through my GitHub repositories bellow:
Here, you will can find more projects related to Data Science and Machine Learning. In summary, it contains all my work so far. Any reply or comment is always welcome.
About the authors
Erick Calderin Morales
Systems engineer with experience in software development, master’s student in systems engineering and master’s degree in data science with an affinity for artificial intelligence.
Al-Dhabyani, W., Gomaa, M., Khaled, H., & Aly, F. (2019). Deep learning approaches for data augmentation and classification of breast masses using ultrasound images. Int. J. Adv. Comput. Sci. Appl, 10(5), 1–11.
Al-Dhabyani, W., Gomaa, M., Khaled, H., & Fahmy, A. (2020). Dataset of breast ultrasound images. Data in brief, 28, 104863.
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of rogramas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
La COVID-19 es la enfermedad causada por el nuevo coronavirus conocido como SARS-CoV-2. La OMS tuvo noticia por primera vez de la existencia de este nuevo virus el 31 de diciembre de 2019, al ser informada de un grupo de casos de «neumonía vírica» que se habían declarado en Wuhan (República Popular China).
Se llama SARS-CoV-2, por las siglas:
“SARS” porque puede producir un “Síndrome Respiratorio Agudo Grave” (siglas en inglés: Severe Acute Respiratory Syndrome, SARS).
“CoV” porque es un coronavirus.
“2” porque ya existió un virus parecido en 2002–2003 que producía también SARS.
¿QUÉ PRUEBAS SE UTILIZAN PARA DIAGNOSTICAR EL COVID-19?
PCR
Las PCR (siglas en inglés de “Reacción en Cadena de la Polimersa”), son un tipo de pruebas de diagnóstico que se llevan utilizando durante años en diferentes crisis de salud pública relacionadas con enfermedades infecciosas. Estas pruebas se están usando desde los primeros días del estallido de la pandemia de coronavirus en España. Sin embargo, los test rápidos se han incorporado recientemente y, como su nombre indica, son más rápidos y sencillos. Ambos sirven para comprobar si una persona está infectada o no por el Covid-19.
ANTÍGENO
Prueba de antígeno. Esta prueba para la COVID-19 detecta ciertas proteínas en el virus. Se usa un hisopo para tomar una muestra de fluido de la nariz, y las pruebas de antígeno pueden dar resultados en minutos.
RADIOGRAFIA DE TORAX
Los escáneres o las radiografías producen una imagen de los órganos y estructuras (corazón, pulmones y vías respiratorias) del tórax. Pueden detectar bloqueos, inflamación y exceso de líquido.
Las radiografías utilizan una pequeña cantidad de radiación para producir una imagen en dos dimensiones. Por lo general, las realiza un radiólogo en el hospital mediante un equipo fijo, pero también se pueden hacer con una máquina portátil.
La tomografía computarizada (TC) utiliza una computadora para fusionar varias radiografías tomadas desde diferentes ángulos y producir así una imagen bidimensional que se puede convertir en una imagen tridimensional. Requiere de un equipo muy especializado y la realiza en el hospital un radiólogo especialista.
Se pueden realizar en un hospital o en otros centros sanitarios, como la consulta de un médico o una clínica.
PROBLEMATICA
Dado que hay kits de prueba de COVID-19 son de acceso limitado para la población en general, debemos confiar en otras medidas de diagnóstico.
IMÁGENES DE RAYOS X
En el campo de la medicina se utilizan con frecuencia radiografías y tomografías computarizadas para diagnosticar neumonía, inflamación pulmonar, abscesos y / o ganglios linfáticos agrandados. Dado que COVID-19 ataca las células epiteliales que recubren nuestro tracto respiratorio, podemos usar rayos X para analizar la salud de los pulmones de un paciente.
Una gran mayoría de los hospitales tienen máquinas de imágenes de rayos X, se plantea la siguiente pregunta: ¿Cómo se podría detectar COVID-19 en imágenes de rayos X?, sin los kits de prueba dedicados.
OBJETIVOS
Recopilar las entradas del modelo en datasets para el entrenamiento, pruebas y validación.
Desarrollar un modelo de diagnóstico del covid a través de imágenes de rayos X usando deep learning, con un porcentaje de confiabilidad aceptable.
Evaluar los resultados del modelo a través de la matriz de confusión.
DESARROLLO DEL MODELO
Para el desarrollo del modelo se ha utilizado un dataset del repositorio de kaggle que tiene un total de 5.856 imágenes, se ha usado radiografías de pacientes que tenían neumonía porque estos pacientes tienen una alta probabilidad de tener covid-19.
Para la construcción del modelo se utilizó Redes Neuronales Convolucionales, porque son redes neuronales diseñadas y ampliamente usadas para trabajar con imágenes.
Las redes convolucionales contienen varias hidden layers, las cuales se encargan de detectar líneas, curvas y así con las convoluciones se permitirá detectar formas más complejas como siluetas, rostros, etc.
Las herramientas utilizadas son: Tensorflow y keras. Tensorflow es una plataforma de código abierto usada para aprendizaje automático compuesta por un conjunto de herramientas, librerías y recursos que facilitan el trabajo en el desarrollo e implementación de soluciones con inteligencia artificial (IA). Keras es una librería, actualmente es API de alto nivel que proporcionan interfaces que simplifican el trabajo en el desarrollo de aplicaciones con IA, a partir de la versión 2.0 keras ya viene integrada dentro de Tensorflow.
DESARROLLO DEL PROYECTO
Debido a que es una pequeña prueba de concepto de clasificación de imágenes para un curso introductorio a Deep Learning, se ha subido las imágenes del dataset a una carpeta de google drive y el desarrollo del modelo se utilizó los servicios de colab.research de Google.
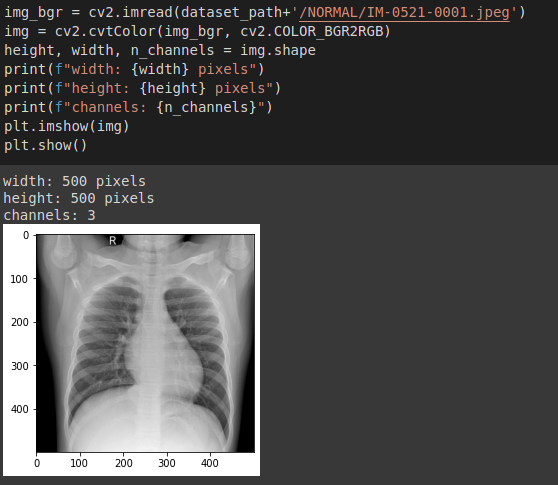
Las imágenes fueron ajustadas a un tamaño de 500×500, para poder entrenar, en la siguiente imagen se observa una radiografía de un paciente normal.
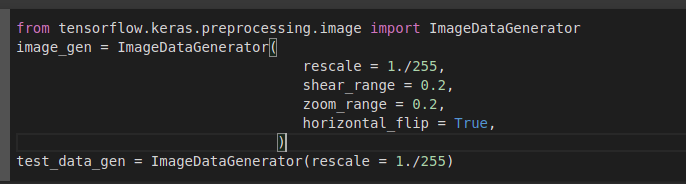
Con la integración de Keras con Tensorflow, se tienen nuevas clases como “ImageDataGenerator” que facilitan la carga de imágenes:
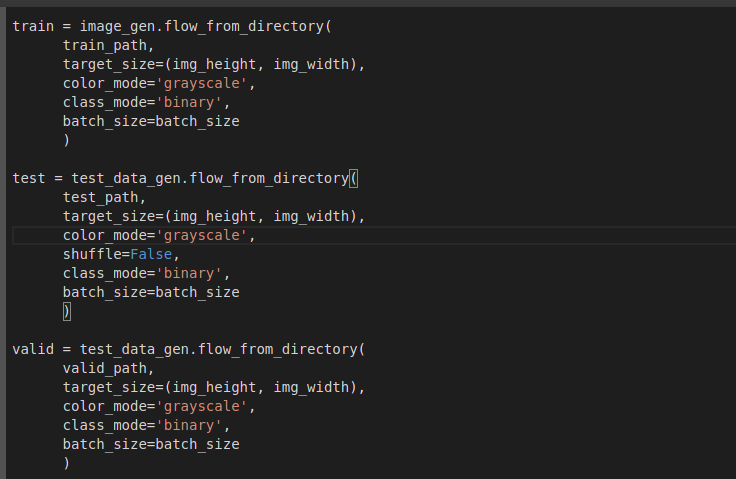
Las imágenes fueron divididas en 3 grupos: entrenamiento, pruebas y validación.
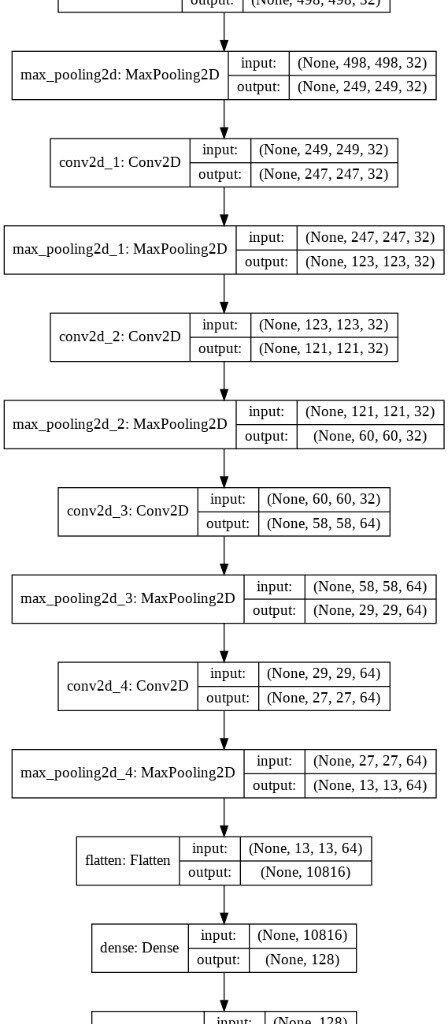
El modelo de clasificación se puede observar en la siguiente gráfica:
EVALUACION DEL MODELO
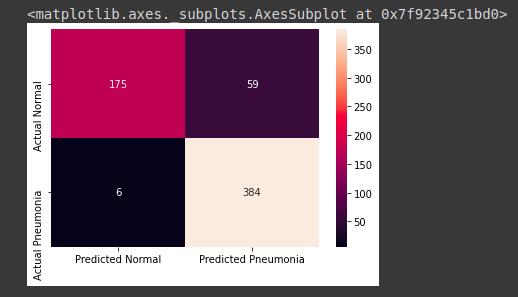
Para realizar la evaluación se ha utilizado la matriz de confusión:
Donde se puede observar que el modelo ha identificado:
Para personas que estaban sanas y que el modelo predijo como personas sanas fueron 175 casos de verdaderos negativos (VN).
Para personas que estaban enfermas y que el modelo predijo como personas enfermas fueron 384 casos de verdaderos positivos (VP).
Para personas que estaban enfermas y que el modelo predijo como personas sanas fueron 59 casos de falsos negativos (FN).
Para personas que estaban sanas y que el modelo predijo como personas enfermas fueron 6 casos de falsos positivos (FP).
Con estos datos podemos calcular los siguientes indicadores:
Exactitud = (VP + VN) / (VP + VN + FN + FP)
Exactitud = (175 + 384) / (175 + 384 + 59 + 6)
Exactitud = 0,8958
La exactitud es la cantidad de predicciones que fueron positivas que fueron correctas y se llegó a un valor de 89,58%
Precisión = VP / (VP + FP)
Precisión = 384 / (384 + 6)
Precisión = 0,9846
La precisión es el porcentaje de casos positivos detectados llegó a un valor de 98,46%
Sensibilidad = VP / (VP + FN)
Sensibilidad = 384 / (384 + 59)
Sensibilidad = 0,8668
La sensibilidad es la proporción de casos positivos correctamente identificados llegó a un valor de 86,68%
Especificidad = VN / (VN + FN)
Especificidad = 175 / (175 + 59)
Especificidad = 0,7478
La especificidad trata de la cantidad de casos negativos correctamente identificados llegó a un valor de 74,78%.
ANALISIS DE RESULTADOS
Del proceso de desarrollo del modelo, de acuerdo a las librerías de Keras y Tensorflow pudimos llegar a una precisión del 89,59 %.
Con los resultados obtenidos podemos observar en la figura que el valor de la precisión se mantuvo por encima del 80%, el valor de la pérdida fue inferior al 20 %.
CONCLUSION
De acuerdo a los resultados obtenidos se tiene:
El valor de confiabilidad del modelo es aceptable, representado por el 89%.
El modelo de diagnóstico del covid a través de imágenes de rayos X usando deep learning, podría aplicarse en nuestro medio como otra alternativa de diagnóstico.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) a la vez que se realizan proyectos de impacto social (#ai4good). Si quieres aprender más sobre este proyecto (y otros) únete a nuestra comunidad en o aprende a crear los tuyos en nuestro programa AI Saturdays.
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Las herramientas de visión artificial han demostrado vez tras vez el gran potencial que posee en sus distintas áreas de aplicación. Una de estas está justamente relacionada con los vehículos y sus conductores. Abarcando desde movilidades autónomas hasta herramientas de uso personal el espectro es muy amplio. Por ello, en este texto se explica la implementación de un detector de fatiga en conductores mediante Inteligencia Artificial utilizando OpenCV y Dlib.
DESCRIPCIÓN DEL PROBLEMA
Los accidentes de tránsito son una de las principales causas de muerte en ciudadanos de todos los países. Estos se pueden clasificar de acuerdo a sus causas. Se calcula que entre un 20% y un 30% de los accidentes se deben a conductores que conducen con fatiga. Si bien la fatiga al conducir es un riesgo evitable, lastimosamente, muchos conductores no toman las precauciones necesarias cuando conducen por periodos prolongados de tiempo. Por lo tanto, los conductores con fatiga pueden beneficiarse de un sistema de Inteligencia Artificial que los alerte al momento de perder la atención.
OBJETIVO
Diseñar un sistema para detectar la fatiga en conductores.
SELECCIÓN DEL MODELO
Se seleccionó un modelo de visión artificial pre entrenado basado en la librería cv2 de OpenCV y dlib para detección facial.
TÉCNICAS IMPLEMENTADAS
OpenCV: La biblioteca libre de visión artificial que se está usando para obtener la imagen del conductor.
Dlib face landmarks: Son 68 puntos que se colocan sobre el rostro detectado para la identificación de facciones faciales, en este caso los ojos.
NumPy: Esta biblioteca se está usando para el cálculo de la proporción de abertura de los ojos, mediante álgebra lineal y el posicionamiento de los puntos faciales de los ojos.
EVALUACIÓN DE MODELOS
El sistema construido hace uso de un modelo pre entrenado de detección facial. Con ayuda de las bibliotecas previamente mencionadas se realiza un procedimiento como sigue:
Se carga el modelo detector y predictor que son los que detectan el rostro del conductor así como los 68 puntos faciales.
Una función lineal detecta la proporción de aspecto en los ojos midiendo distancias entre los puntos oculares.
Según el valor que se obtenga en esta proporción el programa se ramifica según el estado que considere correspondiente (despierto, cansado o dormido). Para que se considere la transición de un estado a otro debe haber una permanencia en ese estado durante un periodo de tiempo.
El sistema indica en pantalla el estado identificado, este es el paso donde podría activarse o no una alarma.
Este procedimiento se realiza fotograma a fotograma para tener una predicción constante del estado de fatiga de la persona.
ANÁLISIS DE RESULTADOS
Como se utilizó un modelo pre entrenado los resultados obtenidos por el detector facial y de los puntos de referencia del rostro son buenos.
Sin embargo, los resultados que obtuvimos en la detección del estado de fatiga son más bien fluctuantes. En ocasiones el sistema es poco sensible y no detecta estados con los ojos cerrados o, por el contrario, el sistema es pronto para indicar un estado posiblemente falso. Las razones que podrían causar este problema incluyen la calidad del video y el enfoque exclusivo en los ojos del conductor (cuando podrían tomarse en consideración otros factores como la boca).
CONCLUSIÓN
El proyecto ha desarrollado un sistema funcional capaz de detectar la fatiga en conductores de vehículos. La consistencia en estas detecciones no es buena así que se proponen algunas sugerencias: Aplicar operaciones de erosión y dilatación para reducir el ruido en la captura de video, implementar un sistema que detecte la proporción de abertura de la boca para aumentar la consistencia, y modificar los umbrales de detección para ajustarse a las necesidades de cada conductor.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.