Descubre cómo la IA está transformando nuestro mundo, desde la detección temprana de enfermedades hasta la lucha contra el cambio climático, yendo más allá de los chatbots y los algoritmos que comúnmente conocemos.

Descubre cómo la IA está transformando nuestro mundo, desde la detección temprana de enfermedades hasta la lucha contra el cambio climático, yendo más allá de los chatbots y los algoritmos que comúnmente conocemos.

Zaragoza. Primera Edición. 2022
¡Cómo nos ha cambiado la vida en los últimos años!
Una pandemia mundial, un asalto a la Casa Blanca, una Filomena, una erupción de un volcán, hasta el comienzo de un conflicto entre naciones ? ¡… y un curso de IA en Zaragoza!
Una ventosa tarde de viernes, tres intrépidos zaragozanos comenzamos nuestra andadura en este ámbito.

Somos el equipo Aragón Feliz, venimos de diferentes mundos, pero compartimos un interés común por la Inteligencia Artificial, y buscamos ampliar y aplicar los conocimientos adquiridos durante el programa de Saturdays AI. El equipo está conformado por:
· Fernando Jiménez
· Héctor Soria
· Virginia Navarro
Y gracias a la ayuda de nuestros mentores del programa Saturdays IA, que nos han dado la base, hemos podido acometer este proyecto.
Cuando desde Saturdays AI-Zaragoza nos plantearon desarrollar un proyecto basado en IA, nos planteamos varias preguntas.

Y es que la contingencia sanitaria Covid-19 ha ocasionado circunstancias excepcionales con alto impacto en la sociedad, confinamiento masivo, soledad, incertidumbre, crisis económica, sanitaria y social, lo cual ha generado diferentes tipos de reacciones en la población, incrementando las patologías presentes tanto físicas como psíquicas, problemas económicos, entre otros.
Algunos datos
Según la Confederación de Salud Mental España en el estudio #saludmentalvscovid19 (https://consaludmental.org/centro-documentacion/salud-mental-covid19/)

Los datos están claros, toda esta situación ha tenido un alto impacto ya en la sociedad y probablemente se irá manifestando todavía más a lo largo de los próximos años.
A nosotros personalmente nos preocupa, pero… ¿es algo que preocupa?
Diferentes fuentes muestran que sí, que es un tema que preocupa en todos los rangos de edades, veamos por ejemplo esta encuesta realizada a un perfil más joven.

Pero ¿qué podríamos hacer nosotros?, ¿cómo podríamos revertir este efecto?, ¿cómo podríamos hacer que la balanza se inclinara hacia el otro polo opuesto: la Felicidad?
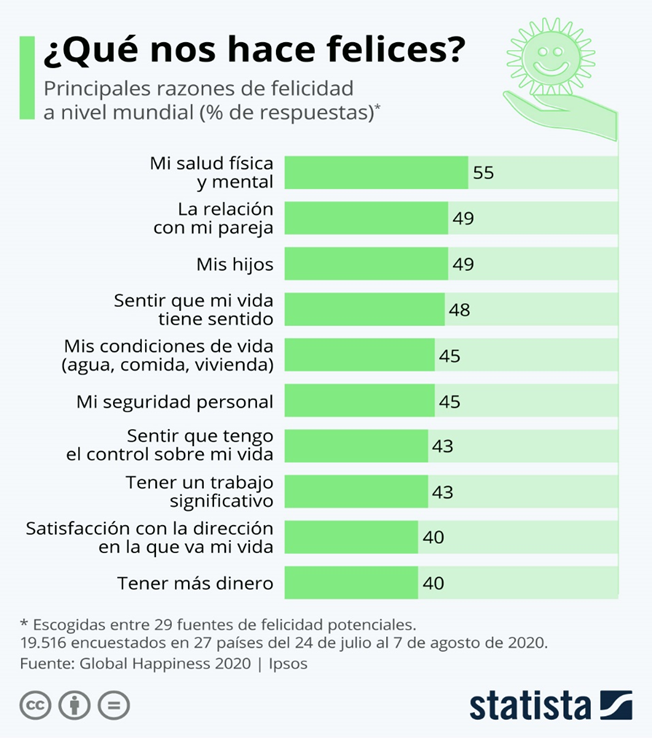
Para empezar, ¿qué es la Felicidad y cómo concretamos esa Felicidad? ¿Qué es lo que a cada uno de nosotros nos hace felices?
Según esta encuesta podemos ver qué aspectos concretos se valoran cuando se piensa en Felicidad.
Y las siguientes preguntas que nos surgieron entonces fueron:
¿Cómo estábamos antes?
¿Cómo estuvimos durante los picos más altos de la pandemia?
¿Cómo se fue modulando ese estado conforme íbamos navegando en las olas y en las diferentes curvas?
¿Cómo estamos ahora realmente?
En definitiva …
¿Cómo tomamos consciencia del viaje emocional que hemos sufrido?
¿Cómo lo hemos ido concretando en el lenguaje?
Pero sobre todo…
¿Cómo lo traducimos a algo medible que poder analizar?
¿Somos capaces de anticiparnos y a través de las palabras, detectar estados y lanzar posibles alertas que con las debidas herramientas faciliten el cambio?
Nuestros primeros planteamientos
Con todas las preguntas anteriores fuimos conscientes de la magnitud del problema que estábamos considerando.
Para empezar, ¿cómo íbamos a poder medir todo esto? ¿Es posible generar algún indicador e información oportuna acerca del impacto emocional en las personas y de cómo éstas, consciente o inconscientemente, lo reflejan a través de su lenguaje?
¿Es posible a través de algoritmos de análisis de sentimientos y tópicos, detectar preocupaciones relacionadas con la contingencia sanitaria, así como otras situaciones a nivel general que le pueden afectar a cada individuo?
Uno de los principales handicaps al que nos enfrentamos es la correcta interpretación del lenguaje, para lo que existen numerosas técnicas y recursos dentro del PLN (Procesado del Lenguaje Natural). En nuestro caso, nos enfocamos en el español, un idioma en el que, aunque ampliamente usado, todavía se están desarrollando y mejorando algoritmos y modelos de IA verdaderamente eficientes que den resultados precisos, a diferencia del Inglés.
Bien, después de toda esta reflexión, éste iba a ser entonces nuestro reto inicial.
Problema
Dada la situación de pandemia vivida a lo largo del último año queremos analizar cómo esta situación ha podido afectar a la percepción general a nivel psicológico de los ciudadanos de Aragón, y cómo ha podido influir este estado respecto a diferentes temáticas (inferidas o prefijadas) en sus comentarios en diferentes medios, redes sociales, prensa, etc.
Quizá, ¿demasiado ambicioso?…
Quizá sí, por lo que intentamos acotar nuestro alcance y a partir de ahí evaluar si era viable realizarlo, por lo que nos centramos en el siguiente problema.
Problema acotado
Existe una alta complejidad a la hora de realizar un análisis de sentimientos (necesidad de datasets etiquetados manualmente por parte de expertos, tiempo para realizar esta anotación manual, la ambigüedad del lenguaje y subjetividad de las emociones, impacto del idioma con el que vamos a trabajar y alto riesgo de errores). Siendo conscientes de esta complejidad, desarrollamos nuestros objetivos principales.
Objetivo realista
Brindar a la sociedad una herramienta que dé una clasificación o etiquetado automático de la Felicidad y subsane la complejidad de una evaluación manual, facilite esta labor y reduzca la ambigüedad y el error.
Demostrar que la herramienta es viable y desarrollar toda la metodología necesaria para llegar a ese etiquetado automático.
Objetivo WOW
Desarrollar un modelo que analice la evolución del sentimiento de los ciudadanos en Aragón respecto a diferentes temáticas (extraídas del propio contexto o predefinidas en base a una categorización estándar), teniendo en cuenta diferentes fuentes como redes sociales, prensa, etc. Y en función del análisis llevado a cabo, que realice recomendaciones y proporcione herramientas con el objeto de mitigar el impacto negativo en su estado emocional.
Disponible para público general, organismos públicos y medios de comunicación.
Objetivo con Impacto Social
Nuestro eje rector está englobado dentro de los Objetivos de Desarrollo Sostenible, en concreto en el 3. Salud y bienestar, aunque al ser tan amplio tiene repercusión en muchos más objetivos.
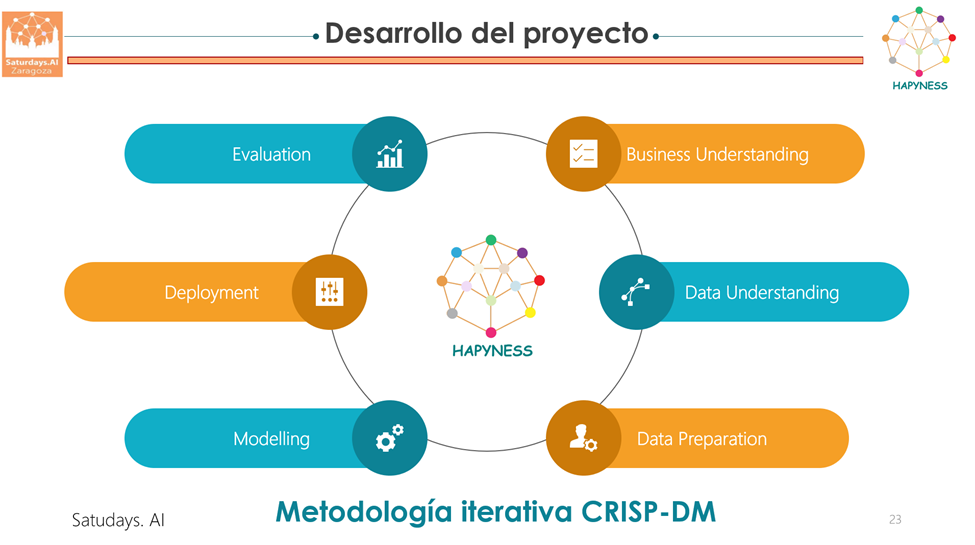
Para la ejecución del proyecto hemos seguido la siguiente metodología iterativa basada en el estándar CRISP-DM (Cross Industry Standard Process for Data Mining).
En este momento del proyecto, trabajamos en la identificación de recursos, restricciones, problemáticas y procesos involucrados.
Como hemos ido comentando, sin duda el periodo de pandemia ha sido una etapa de alto impacto emocional, pero en este concepto tan global, ¿entendemos todos de la misma forma estas emociones?
Empezamos por las emociones
Problemas del lenguaje
Trabajaremos sobre textos escritos, por lo que comenzamos a plantearnos qué posibles problemas nos podíamos encontrar a la hora de gestionar y analizar este tipo de información.

Además, nuestro modelo, en la medida de lo posible, debería reconocer y considerar diferentes fenómenos lingüísticos relevantes para interpretar de forma autónoma la opinión de los usuarios. Así, en la práctica, debería tener en cuenta y poder reconocer la ironía, la negación y las emociones, entre otras cuestiones.
Como reflexión final, por todo lo anterior, vimos clara la dificultad de extraer las emociones de los textos, lo cual nos llevó a plantearnos construir un diccionario propio y como primera aproximación plantearnos un algoritmo de clasificación semi-automático.
Y continuamos con los datos, el caballo de batalla de todos los proyectos.

No contábamos con un dataset etiquetado específico de Aragón y sobre la pandemia y nos planteamos cómo resolver el problema sin utilizar textos de otros ámbitos y épocas. Pero, aun así, se han utilizado los disponibles para hacer una comparación cualitativa de nuestra solución.
Encontramos diferentes fuentes de datos que podrían sernos útiles y estuvimos navegando en ellas para ver cuál podría sernos más valiosa, ya que necesitábamos un dataset previamente categorizado.
Datos etiquetados
Inicialmente utilizamos el corpus de TASS, por lo que acudimos a la Sociedad Española de Procesamiento del Lenguaje Natural (SEPLN), a través de la cual se creó el TASS, que es un Taller de Análisis de Sentimiento en español organizado cada año http://tass.sepln.org/
La carpeta con los datos fue solicitada a la organización y se nos concedió el permiso para usarla.
Revisando la data nos encontramos con diferentes archivos de tweets, agrupados por países y años. No todos tienen la misma categorización, diversos archivos tienen diferentes esquemas dependiendo de que edición del TASS sean, algunos de ellos están etiquetados con su sentimiento (polaridad — positivo/negativo/neutro-, o con emociones como feliz/triste).

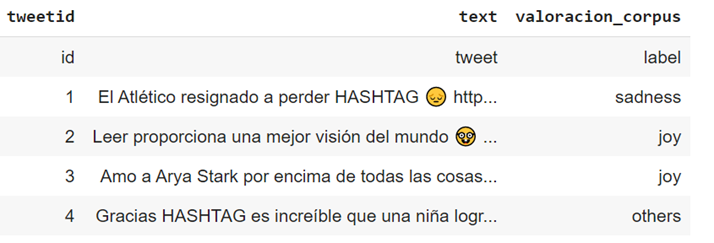
Los archivos del corpus están en formato XML, que hemos procesado y adaptado para que nuestro modelo lo comprenda, transformando los datos a un formato .csv, “Comma Separated Values”, para poder proceder con la siguiente fase.
Datos no etiquetados
En cuanto a los datos para evaluar el modelo seguimos dos vías:
1) Por un lado volvimos a utilizar los datos de test del Corpus TASS, cuya estructura de los archivos es similar a esta:

2) y por otro recopilamos datos directamente desde Twitter gracias a la herramienta Tweepy que nos permitió realizar la búsqueda de publicaciones de usuarios en esta red social a través de su API, durante el periodo de pandemia. La selección de publicaciones se realizó con los siguientes criterios: Aragón, covid, fecha, geolocalización,…
Para poder hacer este proceso, creamos una cuenta en Twitter/desarrollador para poder empezar a descargar los tweets.
Utilizamos como referencia este artículo:
Tardaron un poco en darnos acceso, pero finalmente lo conseguimos y pudimos seguir avanzando en esta parte.
La estructura de los archivos es similar a esta:

Y empezamos a considerar qué variables podrían ser relevantes en nuestro estudio para ayudarnos a conseguir nuestro objetivo (aunque probablemente no dispongamos de todas ellas).


Para nuestro análisis, el dataset inicial cuenta con la siguiente descripción:

Como hemos mencionado, el corpus contiene múltiples niveles de polaridad. No obstante, hay diferencias entre diferentes archivos, por ejemplo, algunos archivos sólo tienen los niveles Positivo, Negativo y Neutral, mientras que otros incluyen un nivel adicional denominado None.Por lo tanto, si quisiéramos trabajar con todos los archivos conjuntamente, deberíamos convertir la polaridad en una variable dicotómica (binaria) con los valores (Positivo=1, Negativo=0).
En nuestro caso, partimos de los que partían de positivo-negativo para pasar después a Feliz-Triste, que se adecuaba más a la categorización que podríamos conseguir de nuestro diccionario que está asociado a los términos Felicidad/Tristeza
Previo al análisis y modelado necesitamos hacer un proceso de eliminación de ruido y normalización.
Creamos la funcion limpia_tweet() que va a eliminar stopwords y algunos caracteres peculiares de Twitter, posteriormente fuimos ajustando esta limpieza debido al ruido de la data y a los problemas que nos iba planteando el código.
1. Se eliminaron las stopwords como: de, con, por, …entre otras.
2. Se eliminó cualquier tipo de mención, RTs, #, links, URLs.
3. Se eliminó cualquier tipo de puntuación.
4. Se buscaron abreviaturas y textos con jergas cibernéticas como: “u” para “you”, “ur” para “your”, “k” para “que”, entre otras.
5. Se eliminaron emojis, y cualquier tipo de valor alfanumérico, caracteres numéricos, vinculados a monedas, porcentajes, etc…
6. Se exploraron los datos, analizando las palabras más comunes en los Tweets.
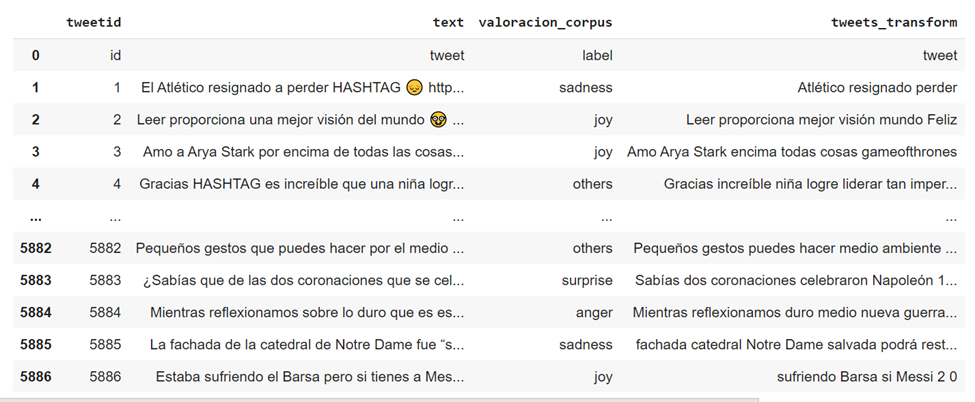
Una vez que se ha realizado el proceso, el texto limpio se almacena en una nueva columna ‘tweets_transform’:
Para poder tratar matemáticamente los tweets preprocesados, tenemos que extraer y estructurar la información contenida en el texto. Para ello, usaremos la clase sklearn.feature_extraction.CountVectorizer.
CountVectorizer convierte la columna de texto en una matriz en la que cada palabra es una columna cuyo valor es el número de veces que dicha palabra aparece en cada tweet.
De esta forma podemos trabajar con estos vectores en vez de con texto plano.
Para cada tweet realizaremos el siguiente proceso:
1. Tokenización: este paso convierte una cadena de texto en una lista de palabras (tokens)
2. Conversión a minúsculas
3. Eliminar stopwords. Se llama stopwords a las palabras que son muy frecuentes pero que no aportan gran valor sintáctico. Ejemplos de stopwords en español serían: de, por, con…
4. Filtros semánticos (Stemming/lematización) es el proceso por el cual transformamos cada palabra en su raíz. Por ejemplo, las palabras maravilloso, maravilla o maravillarse comparten la misma raíz y se consideran la misma palabra tras el stemming.
5. Creación de una bolsa de palabras.
Con WordCloud visualizamos las palabras más utilizadas en el dataset:

Comprobamos si con estos datos nos es suficiente o es necesario tratar algún dato más (data, geolocalización, etc..) o construir nuevos datos a partir de la información existente (valoración).
A. Datos de geolocalización
B. Datos Fecha. Transformación para adecuarlos al formato necesario para la gráfica de evolución.
¿Cómo lo podemos abordar?

Variante 1: Resolver el problema con técnicas de clasificación, específicamente “análisis de sentimiento”, que tiene como clases o etiquetas de sentimiento: “positivo”, “negativo” o “neutral”. Para ello, será necesario conseguir un data set con dichas etiquetas que estén relacionadas con Aragón (por ejemplo, data sets de Twitter) o buscar información textual (por ejemplo, periódicos regionales, etc.) y previamente clasificarlos usando etiquetas de sentimiento (a través de un proceso manual, o bien automatizado usando diccionarios).
Variante 2: Resolver el problema aplicando técnicas de agrupamiento. En este caso, sería necesario recopilar información textual (por ejemplo, periódicos regionales, Twitter, etc.) y agrupar la información, y analizar estos grupos.
Todo el código y los datos utilizados, por si quieres consultarlo en mayor detalle, los tienes disponibles en nuestro respositorio de Github: https://github.com/FJDevelop/HaPyness-Saturdays-AI

Con el objetivo de poder hacer este proceso de clasificación semi-automática necesitábamos disponer de un diccionario con el que poder comparar y clasificar. Ante la dificultad de encontrar uno especialmente válido en castellano, decidimos crear nuestro propio diccionario, y estos fueron los pasos que fuimos siguiendo:
El diccionario está incialmente basado en 3000 palabras relacionadas con ‘felicidad’ y ‘tristeza’.
Tras el post procesado intensivo de las mismas y formateado, se ha ajustado el vocabulario a las 2600 palabras con la menor ambigüedad posible.
Las 3000 palabras han sido revisadas manualmente, para eliminar ambigüedades y errores de valoración.
En la generación de este diccionario, siguiendo este documento de referencia, que explica cómo extraer características relevantes de un corpus textual:
https://www.geeksforgeeks.org/using-countvectorizer-to-extracting-features-from-text/
Utilizamos countvectorizer: convierte textos (= tweets procesados) en filas, los pasa a minúsculas (pero conserva los acentos), y en cada columna aparecen las palabras utilizadas (su frecuencia en la frase), en orden alfabético. El ejemplo que se muestra aquí es muy sencillo.
Del objeto resultante podemos extraer:
– un diccionario con las palabras encontradas (se obtiene directamente mediante ‘vectorizer. vocabulary’)
– la matriz para analizar, con las frecuencias (en unos pasos sencillos)

Problemática:
Había miles de palabras y llevó mucho tiempo, por lo que, del resultado inicial, decidimos acotarlo a las pestañas más útiles (son las amarillas), suficientes para valoración “Feliz/Triste”, ya que trabajar con más valores (Muy feliz, feliz, triste, muy triste) nos implicaría mucho más tiempo de desarrollo y queríamos avanzar en el resto de la metodología y evaluación de nuestra solución. Los datos de entrada a este proceso se muestran a continuación, donde junto con el diccionario elaborado manualmente se analiza el corpus etiquetado y mapeado a las etiquetas de Felicidad/Tristeza para completar el vocabulario de valoración.

a. Importa el vocabulario
· Prepara stopwords españolas del vocabulario
· Aplica funciones steemer
b. Prepara el vocabulario stemmed
c. Lee los tweets
d. Aplica filtros limpieza
e. Valora sentimientos sobre los textos con el vocabulario steemed, creando un nuevo campo valoración calculada.
f. Guarda los tweets valorados en ficheros distintos según el resultado comparativo frente a los textos etiquetados (Ok, errores, sospechosas)


Con respecto al fichero con las palabras sospechosas, realizamos un análisis del mismo para comprobar si nuestro proceso estaba funcionando correctamente.

Nos dimos cuenta de que las que salían tenían cierto sentido, si se quitaban parece que podría empeorar, por lo que haría falta tener otra lista “palabras interesantes”, donde mirar antes de quitarlas, lo cual suponía un esfuerzo adicional considerable, por lo que decidimos abordarlo posteriomente si nos daba tiempo.
Como causa considerábamos que sin contexto las palabras son muchas veces ambiguas, por lo que como con lo que habíamos obtenido hasta ese momento, obteníamos un 60% acierto, y no parece fácil de aumentar cuantitativamente, decidimos continuar con el fichero OUT_es con las dos columnas (Valoracion_corpus y Valoracion_calculada) con el que podríamos alimentar la parte de IA.
El objetivo de este problema de Machine Learning es predecir el sentimiento de los tweets incluidos en nuestro fichero usando el corpus de TASS como training data (datos para entrenar al modelo predictivo).
Hay que puntualizar que el dataset se ha divido en TRAIN y EVAL/DEV



Las 15 palabras más utilizadas antes del stemming

Representación Numérica
Después del stemming, creamos una bolsa de palabras (Bag of Words, BoW), que es una representación de cada documento en base a las palabras únicas que aparecen entre todos los documentos disponibles, a partir de la unión de todas las frases junto con la cantidad de veces que aparece cada palabra.
Con la idea de compensar aquellas de mayor frecuencia, aplicamos TF-IDF (TermFrequency–Inverse DocumentFrequency), que nos indica la relevancia de un término en el documento, teniendo en cuenta el ámbito en el que se suele usar (corpus).
Selección Algoritmos ML
A continuación listamos el conjunto de algoritmos de aprendizaje automático que hemos considerado en esta fase (se ha utilizado el etiquetado manual original como clases verdaderas):
Random Forest Classifier





SVM




XGBoost




Aplicación teniendo en cuenta el módulo Valoración
Random Forest

SVM

XGBoost

Dado que RF es el que mejor resultado da con la valoración humana, en términos de clasificación, quisimos mejorar el modelo de RF para la valoración algorítmica. Para ello empleamos un GridSearchCV en los dos tipos de valoración, humana y algoritmia. En el caso de la valoración humana parece que no se mejora el resultado, parece que estamos en el máximo valor alcanzable aunque también es probable, que sea un máximo local y no global.
Por otro lado, en la valoración algorítmica conseguimos mejorar el resultado del modelo, usando los mismos parámetros de calidad: Accuracy, Recall, Precision y F1.



☝ ¡eh! ¡que mejoramos de forma significativa! Vamos a guardar el modelo, por si las moscas ?
Aplicamos el modelo Kmeans, pero lo cierto es que no nos resultó demasiado útil, no conseguimos conclusiones demasiado claras ni obtuvimos conjuntos de términos muy claros, quizá podríamos conseguir mejores resultados realizando una labor adicional de limpieza de datos o quizá tener más volumen de tweets como para poder sacar conclusiones.



TSNEt-DistributedStochasticNeighborEmbedding


Para poder visualizar palabras en 2D vamos modificando diferentes parámetros de la función word2vec. Las que más influencia tienen en nuestro sistema son el número máximo de palabras consideradas y el número de veces que una palabra tiene que estar repetida en el texto para ser considerada representativa. Como podemos ver en la representación de tsne, es difícil sacar conclusiones. Se debería limpiar mejor el texto para evitar la dependencia de los acentos o terminar de eliminar caracteres que solo añaden ruido como ‘ji’ o ‘san’.
Seguimos los mismos pasos sobre los tweets obtenidos y no etiquetados previamente para evaluar la potencia de los modelos ante textos no vistos previamente y de otros dominios. A continuación vemos los resultados.
Partimos de un análisis exploratorio de los datos y pretratamiento de los mismos.



Vemos cuáles son las palabras más comunes


Aplicamos el módulo de valoración para obtener la valoración calculada:


Aplicamos ahora modelos de Machine Learning y analizamos resultados (tomando como referencia la valoración calculada):
Random Forest Classifier

SVM

XGBoost

El modelo de RF, de nuevo, es el más prometedor, por lo que volvemos a usar GridSearchCV para ver si podemos mejorar la clasificación.

? no hay mucha mejora que digamos, parece que no es muy bueno generalizando…
Todo el código y los datos utilizados, por si quieres consultarlo en mayor detalle, los tienes disponibles en https://github.com/FJDevelop/HaPyness-Saturdays-AI

Entre los diferentes modelo de ML utilizando directamente las clases etiquetadas manualmente, el SVM es el que arroja unos resultados ligeramente superiores.

Se puede observar que el modelo de valoración tiene un desempeño próximo a los modelos automáticos tradicionales de ML.
Evaluación de los resultados de los modelos en relación con la evaluación de tweets no etiquetados previamente
Utilizando los mejores modelos previamente entrenados y guardados (model.pkl), se observan algunas diferencias:


Por tanto: comparando los modelos en distintos escenarios

Como se puede ver en la imagen, el valorado automático en una muestra de novo tiene una menor capacidad de clasificación que en la muestra original. La heterogeneidad de la muestra y una limpieza menos eficaz conlleva una menor potencia.
Transformamos el campo fecha, y clasificamos aquellos tweets que pertenecen a una fase precovid o que corresponden a la etapa covid


Se observa un mayor desequilibrio en la etapa covid, con comentarios más cercanos a la tristeza que en el periodo precovid, donde a pesar de predominar la tristeza los resultados eran mucho más cercanos
Visualización de la evolución

Vemos que aplicando Machine Learning el resultado predice tweets más negativos, en general.
Para la puesta en producción de los modelos finales y los resultados obtenidos, utilizamos Streamlit que es una librería de Python de código abierto que facilita la creación y el uso compartido de aplicaciones web personalizadas para el aprendizaje automático y la ciencia de datos.
Nuestra aplicación en streamlit es un Valorador de felicidad que te permite realizar el análisis del texto que introduzcas, dando como resultado la valoración del mismo, así como las palabras que han determinado esa valoración.


Por otro lado, permite la visualización de la evolución de los sentimientos en cuanto a Felicidad/Tristeza en la muestra seleccionada.

Las conclusiones obtenidas tras el desarrollo y resolución del objetivo general son:
Con respecto a las vinculadas con nuestros objetivos:
Hemos conseguido desarrollar una herramienta de etiquetado automático para Felicidad y tristeza con un porcentaje de acierto satisfactorio (63% respecto al corpus y de un 53,2% con respecto al modelo de Machine Learning respecto al etiquetado automático), que puede facilitar la labor y evitar la complejidad de un etiquetado manual.
Además, hemos desarrollado un modelo que analiza la evolución del sentimiento en este caso de los ciudadanos en Aragón respecto a las emociones felicidad y tristeza inferidas de sus comentarios en rrss, que nos permite ver claramente el impacto que la pandemia u otros acontecimientos significativos han tenido en su percepción y bienestar.
A nivel general, las principales conclusiones que hemos obtenido son:
– El concepto de Felicidad y Tristeza no es común a todas las personas tanto en la expresión como en la evaluación, por lo que esto puede afectar en la valoración por la dificultad de estandarizar la expresión de un sentimiento.
– La complejidad de interpretación de los tweets es tan grande que puede tener un gran impacto tanto la subjetividad de la persona como la del momento de la evaluación. Para solucionar este se podría realizar una votación entre varias personas a nivel de vocabulario y a nivel de tweets.
– Riesgo de confusión entre positividad-negatividad y felicidad -tristeza a la hora de valorar las palabras.
– Sesgo de la fuente elegida Twitter (redes sociales más tendenciosas que otras, mensaje de 280 caracteres puede limitar la expresión de la emoción, ¿accesible a toda la tipología de la población?).
– Sesgo en el lenguaje, que se traslada a nuestro diccionario. Ponderación de las palabras felices y tristes (30 -70).
– Riesgo de pérdida de información en el pretratamiento: En el proceso de pretratamiento de los tweets con objeto de facilitar el proceso, hemos eliminado elementos que nos podrían ampliar el análisis, por ejemplo, emoticonos o hahtags (#), con lo que puede que se haya desvirtuado la valoración final (fase evolución 20.0).
– Importancia del contexto en el análisis y la valoración.
– El resultado de los tres modelos que hemos utilizado han sido muy parecidos, aunque el modelo Random Forest parece que es el que mejor se adapta a la clasificación y dominio bajo estudio, a tenor de los resultados, puede deberse al volumen de la muestra, aunque se podría evolucionar buscando mejores parámetros en SVM y XGboost o probar redes neuronales.
– Existen numerosas técnicas y recursos dentro del PLN (Procesado del Lenguaje Natural) en inglés, pero no están tan desarrolladas en español, lo cual dificultaba en nuestro caso la aplicación.
Como posibles propuestas de evolución de la herramienta

ML Funcionalidades del análisis:
Fuentes:
Análisis de emociones:
Visualización:
Alertas y recomendaciones:
A todo el equipo de Saturdays AI, y sobre todo al equipo de Saturdays AI Zaragoza, en especial a Rosa Montañés, Mª del Carmen Rodríguez, Rocío Aznar y Rafael del Hoyo ya que sin ellos no habría sido posible.
La experiencia ha sido muy agradable y recomendable, con una metodología de aprendizaje muy efectiva basada en la práctica, ¡Gracias por todo vuestro apoyo, paciencia y dedicación!
Y a ti, por haber llegado hasta aquí en la lectura del artículo.
Github
Todo el código y los datos utilizados los tienes disponibles en https://github.com/FJDevelop/HaPyness-Saturdays-AI/tree/main
Vocabulario relacionado con felicidad y tristeza http://www.ideasafines.com.ar/buscador-ideas-relacionadas.php
Datasets
Tass Corpus:
Acceso personalizado al Corpus de TASS
http://tass.sepln.org/tass_data/download.php
https://gplsi.dlsi.ua.es/sepln15/es/taller-de-analisis-de-sentimientos-en-la-sepln-tass
Análisis del Sentimientos
NRC Word-Emotion Association Lexicon (aka EmoLex)
https://saifmohammad.com/WebPages/NRC-Emotion-Lexicon.htm
Sentiment Analysis in Python
https://neptune.ai/blog/sentiment-analysis-python-textblob-vs-vader-vs-flair
Desarrollos
Ejemplo sentimental Analysis en español
https://pybonacci.org/2015/11/24/como-hacer-analisis-de-sentimiento-en-espanol-2/
Análsis de tweets
https://www.cienciadedatos.net/documentos/py25-text-mining-python.html
Información de interés
Herramienta para realizar la Demo.
Streamlit: https://docs.streamlit.io/library/get-started/create-an-app
Información Covid
Datos salud Mental afectación coronavirus
https://consaludmental.org/sala-prensa/manifiesto-salud-mental-covid-19/
Se puede encontrar el código de este proyecto en GitHub
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Zaragoza. Primera Edición. 2022
El cáncer de mama es la principal causa de mortalidad en las mujeres. En 2020, alrededor de 685 000 mujeres fallecieron como consecuencia de esa enfermedad. La mayoría de los casos de cáncer de mama y de las muertes por esa enfermedad se registran en países de ingresos bajos y medianos.
El cáncer de mama es el más prevalente entre las mujeres. Se estima que la prevalencia en España en 2020 es de 516.827 personas, según la REDECAN.
Generalmente, el cáncer de mama se origina en las células de los lobulillos, que son las glándulas productoras de leche, o en los conductos, que son las vías que transportan la leche desde los lobulillos hasta el pezón.
A pesar del aumento progresivo de la supervivencia por cáncer de mama, mejorar las tasas de mortalidad de la enfermedad es una necesidad médica y social, puesto que se ha estudiado que un 30% de las pacientes diagnosticadas tendrán una recaída de la enfermedad. Asimismo, el cáncer de mama afecta también a los hombres, siendo más mortal debido a la escasez de tejido mamario, por lo que se extiende a otros órganos con mayor facilidad.
El cáncer de mama es el tumor maligno más frecuente en mujeres y el riesgo de sufrirlo aumenta con la edad, con incidencia máxima a partir de los 50 años. El cribado de este cáncer mediante mamografía, que se realiza entre la población de 50 a 70 años, permite reducir su mortalidad. El 5.4 por mil de los pacientes cribados son positivos. Un diagnóstico precoz de estos casos es fundamental para llevar a cabo tratamiento correcto y eficaz.
El año pasado 800 nuevos cánceres de mama fueron detectados tan solo en la comunidad de Aragón.
La tendencia actual es a un incremento de los casos no solo por los hábitos de vida menos saludables, sino que va ligada al incremento de la población en el programa de detección por la llegada de los boomers, como podemos apreciar en el siguiente gráfico. De modo, que la posibilidad de que haya un gran incremento de casos en estos años es bastante alta.
Como consecuencia de todo lo anterior vemos una necesidad real en la existencia de alguna herramienta que ayude con este problema de detección de cáncer. Es por esto que, animados por el proyecto de Saturdays AI, iniciamos el abordaje de este problema mediante la aplicación del Machine Learning y posterior desarrollo de una herramienta (Mama Mia) de predicción del diagnóstico de Cáncer de Mama.
Se trata de una solución que se alinea a la perfección con el ODS 3: Objetivo de Desarrollo Sostenible Salud y Bienestar.
Asimismo con el ODS 10 de Reducción de Desigualdades, ya que es en zonas de menores ingresos donde se registran más muertes. Se libera el uso por de todo el trabajo aquí realizado.
¿Cómo lo vamos a hacer ?
Como todo proceso en que se quiere implementar una tecnología en algún negocio es necesario una metodología. No reinventaremos la rueda, vamos a hacer uso de la metodología iterativa CRISP-DM (Cross Industry Estándar Process for Data Minnig) que nos facilita una guía estructurada en seis fases, algunas de las cuales son bidireccionales, pudiendo volver a una fase anterior para revisarla.
El objetivo de este proyecto es el desarrollo de una herramienta para la predicción del cáncer de mama. Para lo cual contamos con el dataset de
https://archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+(diagnostic)
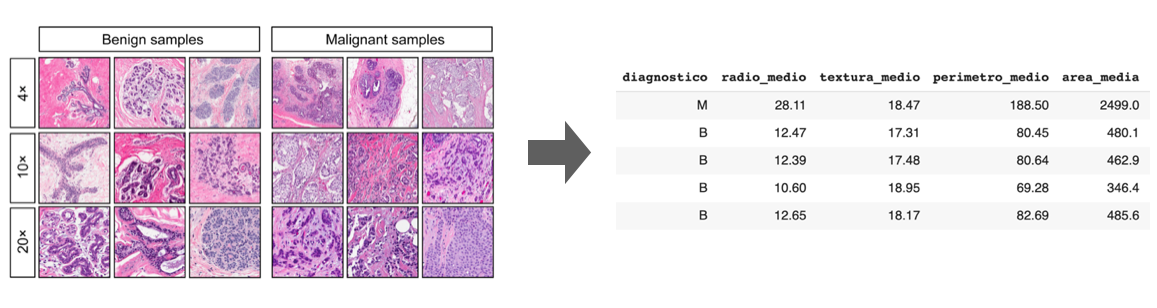
Conseguidos a partir de una imagen digitalizada de un aspirado con aguja fina (FNA) de una masa mamaria, describen las características de los núcleos celulares presentes en la imagen.
Hemos comenzado el proyecto viendo con qué datos contamos específicamente. Tras obtener nuestros datos de UCI y entrando en detalle, nuestra base de datos se compone de 31 variables útiles que podemos desglosar en la variable de diagnóstico (si es positivo o negativo) y 10 parámetros que definen las células se dan bajo 3 situaciones: el valor promedio, la desviación estándar y el peor caso.
Estas 30 variables se obtienen a partir del análisis de la biopsia.
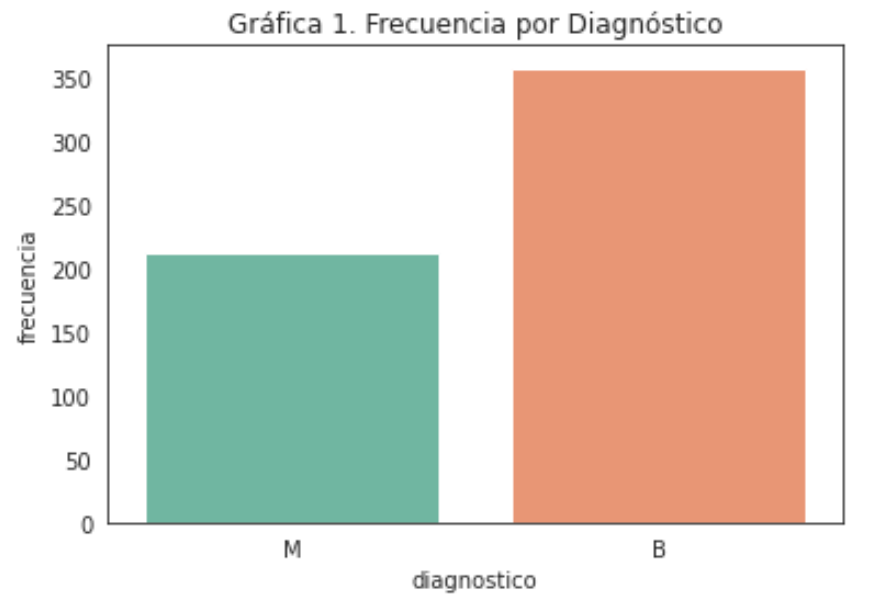
Dentro de nuestros datos tenemos 213 casos malignos y 357 casos benignos.
Aparte de las 31 variables útiles encontramos una columna con valores NaN que eliminamos junto con el ID (identificador) de cada caso ya que no aporta ninguna información para la predicción y sustituimos los datos de diagnóstico: M y B por valores numéricos binarios: 1 y 0.
Por lo que lo primero ha sido ver que tipo de datos teníamos: todos números de coma flotante excepto el diagnóstico. Analizando los datos podemos ver que no tenemos valores NaN y tienen los siguientes datos estadísticos:

Hemos obtenido la gráfica de correlación mediante un mapa de calor para ver cómo se relacionan entre sí las variables y en nuestro caso la relación con la que más nos importa: el diagnóstico (‘diagnosis’).
Podemos ver en la primera fila como hay parámetros con una alta correlación directa (colores claros) y parámetros con una leve correlación inversa (colores oscuros).
Ahora vamos a comprar todas las variables mediante diagramas de caja, separando para cada variable los casos malignos (en rojo) y los casos benignos (en verde). Estas gráficas nos sirven para ser capaces de identificar algunas variables claves. Estas serán aquellas que la distribución de malignos y benignos sea muy diferente.
Vemos que se producen con bastante frecuencia valores atípicos, normalmente por encima. Esta variabilidad es posible ya que los datos en estudios médicos suelen ser más variables que los que podemos encontrar en otras bases de datos.
Antes de pasar al modelado debemos normalizar las variables para hacer predicciones de mejor calidad.
Dada la tipología de datos que tenemos hemos usado modelos supervisados (los datos están etiquetados) y de clasificación (predice una categoría). Los modelos que hemos evaluado son:
En estos modelos hemos probado con random state 2. Para ello antes de introducirlos en el modelo hemos separado los datos con una relación 70–30 en entrenamiento y evaluación respectivamente.
Tras evaluar estos modelos hemos obtenido los siguientes resultados:

Podemos ver cómo obtenemos valores de excatitud (accuracy), precisión (precision), Recall y F-score superiores al 90%. Los modelos con un F-score mayor del 95% son los que destacamos de cara a los mejores modelos de cara a las siguientes etapas, no sin antes comprobar varias elementos del modelo.
Se trata de un modelo con un alto número de características por lo que nos planteamos varias preguntas: ¿Se podría conseguir un resultado con menos variables? ¿Hay dependencias entre estas? ¿Son buenos resultados siempre o ha sido casualidad del random state?
Para ello pasamos a observar la importancia de las variables (en los casos que nos lo permite).
Variables de influencia
En el caso del árbol de decisión (Decision tree) podemos ver según qué variables va clasificando.
Reducción de variables y nuevas métricas
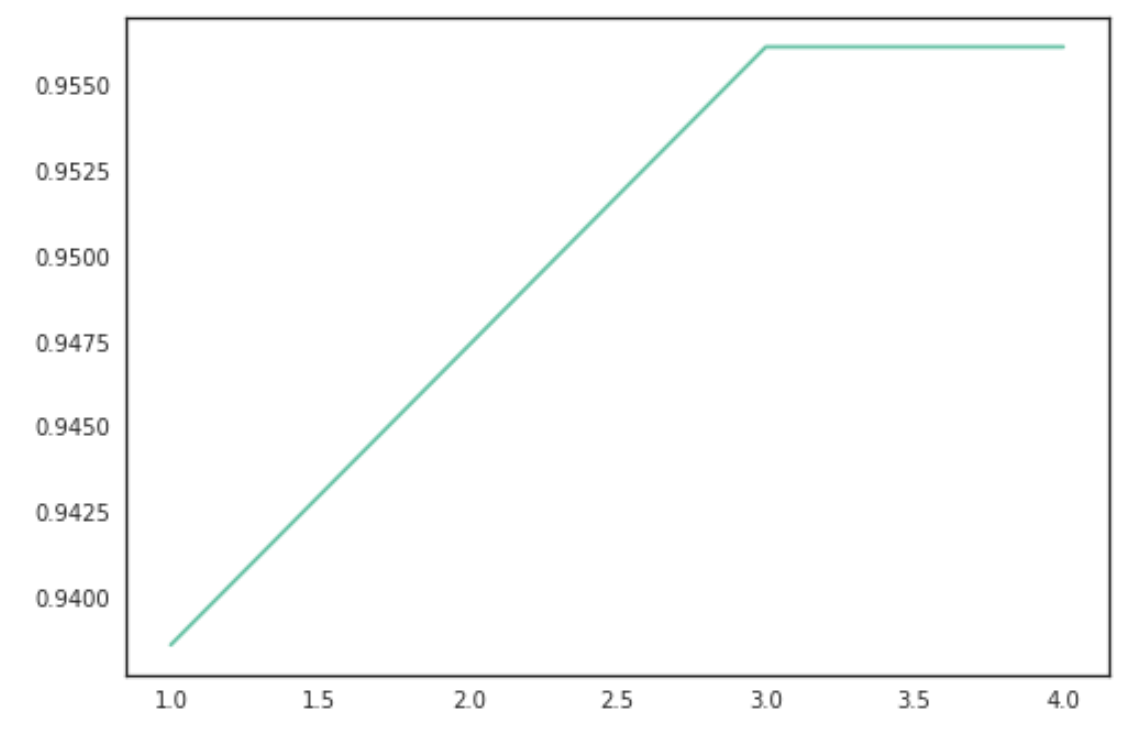
En base a la importancia de las variables que hemos visto hemos elegido 3 combinaciones para simular: con 10, 16 o todas las variables. Elegidas tal que así:

Se obtienen los siguientes resultados en las predicciones para cada uno de los 3 casos:



Fijamos un criterio de elección de un F-score de 95% mínimo, por lo tanto elegimos un modelo con 16 parámetros ya que permite predecir con unas métricas suficientemente buenas pero con casi la mitad de parámetros que la opción de 30 parámetros.
Tras esto pasamos a ver cómo es su comportamiento frente a la predicción de probabilidades en relación con el efecto de la semilla. Para ello miraremos en las 200 primeras semillas, cómo se comportan. Para ello realizaremos un histograma donde iremos acumulando las probabilidades con las que predice tanto para verdaderos positivos como negativos, y para falsos negativos y positivos.
Con todas las simulaciones realizadas vemos como hay ciertos modelos que concentran sus valores en más altas métricas y más concentradas, estas seremos las que elegiremos.
Variando únicamente el estado aleatorio inicial, conseguimos muy altas métricas máximas, clasificadas en esta tabla.

Una vez elegimos los mejores modelos (con mayores y más concentradas F-score): SVM, Regresión logística y MLP Classification (Perceptrón Multicapa).
A partir de ahora probaremos a conseguir mayor robustez mejorando los 3 modelos finalistas. Para ello testearemos diferentes combinaciones y una vez seleccionado el modelo (o combinación de modelos finalistas) pasaremos a optimizarlo (si se puede).
Hemos elegido los modelos de Regresión logística, Support Vector Machine, y Perceptrón Multicapa. Ya que tienen altas métricas en un rango que ha variado menos, por lo que suponemos mejor.
Ensamble de varios métodos
Una vez tenemos modelos muy buenos, uno incluso con métricas del 100% decidimos combinarlos. ¿Por qué combinarlos si ya tienen métricas excelentes? Para que sea más robustos y sea más posible que frente a un caso no evaluado ni entrenado acierte el resultado.
Probando con Adaboosting y Bagging obtenemos peores métricas.
Y con voting obtenemos unos valores levemente menores distribuidos tal que así:
Con unas métricas de:

Selección de modelo
Seleccionando las mejores semillas obtenemos las siguientes histogramas:
Vemos cómo el MLP predice con unas probabilidades mucho más altas, pero con un falso negativo. Destaca la regresión logística que acierta el 100% de los casos. Aquí podemos ver las métricas de los modelos:

Ajuste hiperparámetros
Vamos a usar la librería de Scikit-Learn para ajustar los hiperparámetros del algoritmo de cara a encontrar cuales serían los valores que mejorasen los datos anteriormente obtenidos.
Hacemos uso de GridSearchCV con los siguientes valores:
Obteniendo los mejores resultados de 97,11%, con C igual a 1, gamma igual a 0,001 y kernel linear.
No conseguimos ninguna mejora significativa a los parámetros por defecto.
Resultados finales
Elegimos regresión logística ya que es la que mejores resultados ha tenido y la hemos preferido al voting ya que no podemos asegurar que con el voting obtengamos un sistema más robusto.
Una vez elegido y ajustado el modelo, para evitar realizar de nuevo el proceso, es guardado mediante la librería joblib pudiendo así utilizarlo posteriormente. Para dotar el proyecto de una gran accesibilidad decidimos publicar una web que utilice el modelo, para lo cual, recurrimos a la librería open-source: streamlit, que nos permite de una forma sencilla crear una sencilla aplicación web que utilice dicho modelo.
Tan solo es necesario crear un formulario de recogida de datos para que se rellene y al enviar el formulario, la web normaliza y escala los datos de acuerdo a los datos con los que ha sido entrenado el modelo para pasárselos a este y que realice la predicción.

Estudiante del Programa conjunto en máster de Ingeniería Industrial y máster de Energías renovables y eficiencia energética. Apasionado de lo desconocido y la naturaleza, manitas y scout.
Actualmente Técnico de Gestión de Sistemas y T. I en el SALUD (Gobierno de Aragón). Curioso e inquieto tecnológico.
El código está disponible en https://github.com/gitmecalvon/mamamIA
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!

Redes Neuronales aplicadas a la seguridad vial, proyecto «Focus on Driving» – inteligencia artificial para conducir mejor
La Paz. Machine Learning. Segunda edición. 2020
El cáncer de mama es la primera causa de muerte por tumores malignos en las mujeres a nivel mundial. Al menos en el año 2019 murieron cerca de 688 mil debido este padecimiento, lo cual nos da una tasa de mortalidad para mujeres mayores de 20 años de 24.7 por cada 100 mil.
Existe una brecha de mortalidad por cáncer de mama entre países por nivel de ingresos, el 70%(483,000) de los fallecimientos ocurren en los países de ingresos medios y bajos. ¿A qué se deberá?, sucede que en los países de ingresos medios y bajos, hay una falta de acceso a servicios de diagnóstico y tratamiento de esta enfermedad.
Tasa de mortalidad e incidencia
Entre el 50 y 63% de las muertes por cáncer de mama en todo el mundo son prevenibles con detección temprana y tratamiento adecuado. Entre el 66 y 74% de estas muertes que son prevenibles ocurren en países en desarrollo. Asimismo, el cáncer de mama, detectado a tiempo y con tratamiento adecuado puede curarse. Y en caso de que no, puede elevar la calidad de vida de las pacientes al menos hasta 5 años (en Norteamérica).
De esta problemática surge nuestro proyecto social. Sabemos que la situación es muy desfavorable para las mujeres, así que podemos contribuir a generar un modelo de machine learning que pueda ayudar a la predicción de este tipo de tumores con el cual, en un futuro muchas mujeres podrían acceder a un método de detección barato y digno, aumentando así su calidad de vida al enfrentarse con esta enfermedad genética.
Explorar distintos algoritmos de ML (Machine Learning, por sus siglas en inglés) supervisados y no supervisados utilizando el dataset de Wisconsin sobre diagnóstico (explicado más adelante), para compararlos y verificar cual es el que nos proporciona el mejor modelo de detección de cáncer de mama, así como revisar que variables proporcionan mayor información sobre la detección.
Como objetivo sería plantear una generalización de base de datos que pudiera implementarse en cualquier país al que se lleve este diagnóstico.
Se trabajó en una comparativa de ciertos modelos supervisados y no supervisados para determinar la precisión de cada uno y posteriormente utilizarlo para la predicción.
Los datos que vamos a utilizar para este primer ejercicio son los proporcionados en el dataset de diagnóstico de Wisconsin que contiene variables sobre la forma del tumor (en términos de núcleo de las células) y su dianóstico, como se muestra a continuación:
De las variables 3–12 asociamos las métricas: media, error estándar, error extremo.

Después de haber revisado las variables del dataset procedemos a evaular la distribución del feature diagnostico para saber el balanceo de los datos, esto tiene una repercusión a la hora de entrenar a los modelos, porque como podemos ver en la gráfica siguiente tiene una mayor cantidad de datos asociada a diagnóstico de tumores benignos.
Posteriormente procederemos a ver los mapas de correlaciones entre variables para identificar si hay que hacer algún preprocesamiento antes de entrenar los modelos.

Las gráficas anteriores ilustran que en general los tres mapas muestran correlaciones similares, los promedios muestran una correlación más intensa que los valores extremos y a su vez, los valores extremos muestran una correlación más clara que el error estándar, sin embargo en los tres mapas se mantiene la tendencia entre variables.
Destacaremos las correlaciones más evidentes:
Después se realizaron los mapas de correlaciones más específicos que incluyen las tres métricas de las variables con relaciones más destacadas mencionadas anteriormente.

La siguiente gráfica tiene una particularidad, se observa que para las métricas del área los extremos están altamente correlacionados con la media. Y el error estándar es la métrica menos correlacionada con respecto a las otras dos.

Por último mostraremos las distribuciones y diagramas de dispersión para la media por el tipo de diagnostico, lo cual nos da un indicador de como se comportan las densidades que se puede englobar en los siguientes grupos:

Proponemos este análisis debido a que la estructura de nuestra base de datos tiene una dimensión alta (30 variables) por lo tanto esta técnica de análisis no supervisado nos ayudará a reducir la cantidad de componentes (variables) de nuestra base de datos, proyectando las variables originales a un subconjunto de las mismas.
El conjunto final de las variables escenciales después de este análisis, eliminará las que estén posiblemente correlacionadas. Tenemos ahora una aproximación apriori que terminará de definirse con este análisis, dado que queremos formar dos clusters por la forma binaria que tiene nuestra variable objetivo diagnostico.
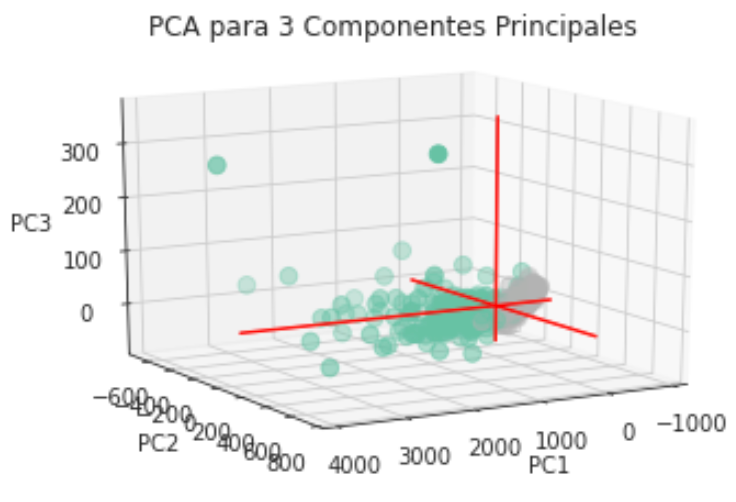
La siguiente tabla muestra el porcentaje de varianza que acumula cada una de las componentes principales, consideramos en principio 10 componentes principales, como se observa en la tabla la primera y segunda componente explican el 44.27% y el 18.97% de la varianza respectivamente, lo que implica que las primeras dos componentes explican el 63.24% de la varianza.

Así que repetiremos el procedimiento pero para ahora solo sacar 2 componentes, ya que obtienen más del 60% de la varianza total.

Ahora vamos a intentarlo con n=3 y podremos observar el mismo comportamiento que con dos dimensiones. En conclusión hay un agrupamiento claro con respecto al tipo de diagnóstico, incluso podría separarse linealmente (con una recta en el caso bidimensional y con un plano en el caso tridimensional) salvo algunas observaciones que se diseminan por completo.
Para este algoritmo de ML, utilizamos el dataset sin reducción, y entrenamos el modelo para que realizara una maximización de la separación de los clústers dadas las características que tenemos (28 variables, removiendo el label).
Para este caso una visualización tipo silueta puede ayudar mucho a explicar los resultados. El Silhouetter Score fue de 0.697 es decir, que tan bien separados están los clústers, recordando que 0 quiere decir que hay overlapping y 1 que están perfectamente delimitados.

Para probar este modelo decidimos generar datos random con las variables seleccionadas del dataframe y estos fueron los resultados:

El modelo es capaz de clasificar si están en 1 (Benigno) y 0 (Maligno) dependiendo de los valores entrantes que fueron generados de manera random. Esto posteriormente con datos reales, podría detectar tumores de mama hasta con una probabilidad de 69%, lo cual es poco deseable. Más adelante con los algoritmos supervisados podremos elevar este porcentaje.
Nuestro proyecto entra en la categoría de clasificación binaria, debido a que tenemos una variable diagnostico que solo nos muestra si es benigno o maligno. Por tanto, este modelo nos beneficia al darnos una primera aproximación para la resolución del problema. En primera instancia, aplicamos el algoritmo de regresión logística para los datos en sus 30 dimensiones y para ver claramente como está funcionando este clasificador, emplearemos una matriz de confusión como se muestra a continuación.

Dada la predicción anterior podemos incluir la precisión del modelo calculada con la métrica de sklearn accuracy_score fue de 0.962765. Resultado que es mucho mejor que nuestro anterior modelo no supervisado (KMeans).
Un diagnóstico más específico es la probabilidad de predicción por observación, es decir, qué tan probable es que esa observación sea clasificada como Benigno o Maligno. Así que vamos a ver su desempeño por cross-validation. Cross-Validation Accuracy Scores [0.94871795 0.92105263 0.94736842 0.92105263 0.97368421 0.97368421 0.97368421 0.94736842 0.92105263 0.94736842].
Por lo anterior concluimos que en promedio tenemos una precisión del 94.6%, sin embargo es necesario revisar la estructura del modelo y los supuestos del mismo.
Después de la pasada primera aproximación del modelo es momento de revisar si se cumplen ciertos supuestos requeridos para el desarrollo de la regresión logística, algunos de estos supuestos los enunciaremos a continuación.
Procederemos a la construcción de la regresión lineal cuidando estos supuestos.
En un principio detectamos que nuestra muestra no estaba balanceada en cantidad de observaciones malignas (~37%) y benignas (~62%), para lo cual se utilizó la biblioteca SMOTE debido a que realiza una generación aleatoria de las observaciones faltantes basada en KNN.

Nota: Solo sobremuestreamos en el conjunto de datos de entrenamiento, puesto que la información que hay en los datos de prueba no será incorporada en el modelo de entrenamiento.
Para “Solo deben incluirse las variables significativas”, es necesario identificar las variables que tengan el mejor rendimiento, así poder incluir finalmente variables o características más pequeñas y más representativas. Estas fueron las variables elegidas:
“radio_medio”,”textura_medio”,”perimetro_medio”,”area_media”,”suavidad_media”,”compacidad_media”,”concavidad_media”,”puntos_concavidad_media”,”simetria_media”,”dim_fractal_media”,”radio_ee”,”textura_ee”,”perimetro_ee”,”area_ee”,”suavidad_ee”,”compacidad_ee”,”concavidad_ee”,”puntos_concavidad_ee”,”simetria_ee”,”dim_fractal_ee”,”radio_extremo”,”textura_extremo”,”perimetro_extremo”,”area_extremo”,”suavidad_extremo”,”compacidad_extremo”,”concavidad_extremo”,”puntos_concavidad_extremo”,”simetria_extremo”,”dim_fractal_extremo”
Ahora implementaremos el modelo con las nuevas variables seleccionadas y los datos balanceados:

Verificando manualmente el valor p de cada una de las variables, quitamos aquellas tales que el valor p exceda .05 que es nuestro nivel de confianza. Ahora vamos a revisar el supuesto de independencia revisaremos nuevamente las correlaciones con las variables finales de nuestro modelo.

El mapa de correlaciones anterior sugiere una alta correlación para radio_medio y perimetro_extremo por lo que quitaremos una de las dos basándonos en la calificación obtenida en el desempeño del modelo.

Ahora las variables seleccionadas muestran una correlación en general baja, lo que aporta a la hipótesis de independencia. Ahora calificaremos nuevamente el desempeño de nuestro modelo. Primero obtendremos la nueva matriz de confusión y posteriormente la precisión.

Ahora nuestra precisión es de 0.918. Así se ve la matriz de confusión:

Por último, vamos a comprobar con un ROC Curve que es una herramienta usada en modelos de clasificación binarios, la forma de interpretar esta gráfica es que un clasificador preciso debe estar lo más lejos de la línea identidad (excepto en los extremos).

Después de este procesamiento, podemos concluir que tenemos una precisión del 92% en promedio la cual es inferior a la propuesta en el primer modelo de regresión logística, la ventaja de este último modelo es la reducción de dimensión de 30 variables a 6 además de que se apega más a los supuestos del modelo de Regresión Logística, esto puede tener implicaciones en cuanto a generalización (que funcione en otras bases de datos) y costo computacional (menos tiempo de procesamiento).
Este algoritmo tiene como objetivo clasificar con base en distancias a hiperplanos diferentes clases de observaciones, es preferido por su nivel de precisión y su bajo costo computacional. Además otra ventaja de este algoritmo es que funciona bien para grandes dimensiones, es decir para gran cantidad de variables explicativas.
Después de esta implementación obtuvimos una precisión del 92.98% sin embargo, hay ciertas observaciones que es importante resaltar sobre este algoritmo.
Implementaremos ahora el algoritmo de KNN que es un algoritmo no paramétrico usado con frecuencia como modelo de clasificación o regresión.
Primero graficaremos el número de clústers que maximiza la función.
Obtuvimos una precisión del 96.27% que es mayor a las precisiones obtenidas en los modelos anteriores, sin embargo hay que hacer ciertas observaciones sobre este modelo:
And last but not least…
Como esperábamos este modelo tiene una precisión del 97.36% que es la más alta con respecto a los demás modelos, algunos comentarios sobre este modelo son:
Después de probar los modelos anteriores notamos que cada una de las implementaciones tienen ventajas y desventajas, además existen modelos que se complementan entre sí como observamos en el caso de PCA, regresión logística y SVM, en donde un modelo de aprendizaje no supervisado puede trazar las posibilidades de clasificación y reducción de dimensiones, posteriormente implementar un modelo de aprendizaje supervisado para la predicción de la variable dependiente.
Cada problema tiene un contexto particular que debe ser considerado para la propuesta de modelos específicos, la cantidad y tipo de variables explicativas configuran el marco de referencia para la implementación de modelos.
En el caso particular de nuestro problema, el objetivo de predicción de la variable dependiente diagnóstico puede ser abordado en general desde dos perspectivas:
Es cierto que para el objetivo de generalización perdemos puntos porcentuales de precisión (dado que la Regresión Logística paso a paso tiene una precisión del 92% en promedio) pero la ventaja de generalizar este modelo es una prioridad específicamente dadas las cifras de mortalidad que actualmente están asociadas al cáncer de mama.
Extender este modelo a bases de datos generadas por otros países, especialmente los de menor ingreso y peor cobertura de salud pública se traduce en menores tiempos de espera en diagnóstico, menor costo de procedimientos y tratamiento oportuno para las pacientes.
Otra ventaja en términos prácticos que sigue el mismo eje, es que las variables relevantes incluídas en el modelo final son 6, lo que representa una disminución del 80% en la dimensión del problema, para los países con menor presupuesto para investigación y salud será más barato crear bases de datos con solo 6 métricas por observación, también el almacenamiento y el posterior procesamiento de la información será más fácil y oportuno.
Los datos presentados en la introducción fueron obtenidos de los siguientes artículos:
En el siguiente repositorio se encuentra el código usado para desarrollar esta aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Lapaz/2021.ML2/Equipo%204
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
ANÁLISIS DE DEPRESIÓN EN REDES SOCIALES: UNA APLICACIÓN EN BIOESTADÍSTICA

Donostia. Primera edición. 2020
En la vida cotidiana, ¿Cuántas veces nos ocurre que preguntamos a una persona qué tal está, y la respuesta es positiva mientras que su rostro indica lo contrario? ¿Cuántas veces has ido a la peluquería y has pretendido salir contenta cuando realmente, no te gustaba el resultado final? ¿Alguna vez has querido recibir el feedback de miles de personas en una conferencia o en el transcurso de ella?

Si nos ponemos a reflexionar sobre las cuestiones mencionadas, probablemente nos daremos cuenta de que muchas veces se miente cuando se tratan las emociones, ¿pero nuestra cara también miente?
Muchas veces se da más importancia a lo que se dice con la voz, que a lo que se dice con la expresión facial, siendo más fácil mentir o esconder la realidad con la primera de ellas. Con este proyecto queríamos, además de desplegar un proyecto real de inteligencia artificial, hacer algo que pudiese ser útil, pudiese detectar las emociones de las personas según su cara, mediante una imagen o la detección de la cara con una webcam. Las emociones surgen cuando ocurre algo relevante. Aparecen rápidamente, de forma automática, y hacen cambiar nuestro foco de atención.
La inteligencia emocional es algo que ha ido adquiriendo mucha relevancia los últimos años, la importancia en percibir, usar, comprender y manejar las emociones, tanto las correspondientes a uno mismo como a las del resto. Para ello, es evidente que necesitamos emociones reales, por lo que queríamos facilitar la forma en la que se pueden percibir las emociones. ¿Será una máquina capaz de detectar y clasificar las emociones mejor que el ser humano?
Facial Expression Recogniser será una aplicación encargada de detectar las emociones a tiempo real. En esta primera versión se utilizarán las imágenes y, a continuación, su función será clasificar las emociones en cuanto la cámara pueda detectar caras.
El dataset utilizado para el desarrollo de este proyecto, que se obtuvo en Kaggle, consistía en una serie de imágenes divididas en carpetas en función de la expresión de rostro. Las etiquetas de las carpetas se dividían según la siguiente clasificación:
0 — Angry
1 — Disgust
2 — Fear
3 — Happy emotions
4 — Sad
5 — Surprise
6 — Neutral
El objetivo principal del proyecto era detectar y clasificar las emociones según estas etiquetas. Para dicha predicción, se usaría imágenes obtenidas mediante la webcam.

Tal y como ha sido mencionado con anterioridad, a la hora de describir el dataset utilizado, se ha visto que se contaba con imágenes y con las etiquetas de las emociones correspondientes. Esto ha hecho que el proceso de EDA haya restado importancia en este proyecto.
Sin embargo, si ha sido necesario cierto análisis y transformación de los datos. Para empezar, se ha tenido que crear dataframes partiendo del dataset. Para ello, se ha pasado de las fotos que se tenían a pixeles, y se han creado dos columnas en dicha tabla, una la relacionada con la emoción y la otra con los píxeles.

Además, cabe destacar que desde un inicio se contaba con una clasificación del dataset entre train y test, por lo que la transformación de imágenes a pixels se hizo dos veces, terminando así con dos dataframes: train_data y test_data

El proyecto realizado se basa en Deep Learning, por lo que ha sido necesario el uso de redes neuronales. En nuestro caso, se han utilizado redes neuronales convolucionales, las cuales se utilizan sobre todo para tareas de visión artificial, pues son muy efectivas en la clasificación y segmentación de imágenes, entre otras aplicaciones.
Para ello, se ha presentado un modelo secuencial, lo que permite apilar capas secuenciales en orden de entrada a salida.


Las capas añadidas al modelo han sido:
– Conv2D
– Batch Normalization
– MaxPooling2D
– Flatten
– Dense
– Activation
– Dropout
Para crear el modelo anteriormente mencionado, se ha utilizado Tensorflow y Keras. Este último es una biblioteca de Redes Neuronales escrita en Python. Es capaz de ejecutarse sobre TensorFlow. Este último satisface las necesidades de los sistemas capaces de construir y entrenar redes neuronales para detectar y descifrar patrones y correlaciones.
Después de crear el modelo se inició el entrenamiento del modelo. Al principio, se entrenó el modelo con un solo epoch, lo que además de tardar mucho tiempo, solo obtuvo un accuracy del 0,29. Es por esto por lo que se tuvo que modificar el entrenamiento del modelo, aumentando los epochs, cambiando los pasos a dar en cada epoch, etc.
Además, debido a un problema de guardado se tuvo que crear un callback al ModelCheckpoint, para que almacenará un checkpoint cada vez que un epoch finalizara, así, se pudo obtener un modelo final con más epochs.
Al final, el modelo obtenido ha conseguido un accuracy final del 0.9602. Esto indica la precisión de lo que se entrenó. Sin embargo, si analizamos el val_accuracy, el cual se refiere a cuánto funciona su modelo en general para casos fuera del conjunto de entrenamiento, el valor obtenido ha sido del 0.6035.

Sin embargo, si calculamos la precisión del modelo con el dataset utilizado para el testeo, veremos que el accuracy es bastante bajo, del 0,1733, lo que implica tener mucho margen de mejora este modelo.

Una vez tuviésemos el modelo listo, había que predecir y probarlo. Para ello, se codificó de forma que nos indicase aquellas emociones que se podían considerar en la expresión facial de la imagen introducida, y según el porcentaje, concluir con el sentimiento más significativo. Por ejemplo:

Introducimos esta primera imagen, donde es evidente que el chico está mostrando cierto enfado. De esta forma, nuestro modelo lo ha clasificado de la siguiente manera:


Recalcando que el enfado es el sentimiento que predomina en la imagen. Si utilizamos nuestro modelo, con el fin de detectar alguna otra emoción, veremos que también funciona.

Tal y como se mencionara en las conclusiones, la intención era incorporar la detección de caras mediante las webcam y así, poder detectar las emociones de una forma más real.
Una vez finalizado el proyecto, en una reflexión grupal, se comentó lo mucho que se ha aprendido en el desarrollo de este mismo, además de habernos dado cuenta de lo lejos que puede llegar la tecnología, y para ser más precisos la inteligencia artificial.
Hemos visto que en este ámbito de reconocimiento facial se están dando grandes avances, existen modelos que reconocen rostros incluso llevando la mascarilla puesta, y las aplicaciones de esta tecnología sólo están limitadas por nuestra imaginación. Desde el punto de vista de marketing, recoger el feedback de los usuarios y clientes es un proceso muy importante, pero obtener esta información suele costar, casi nadie nos paramos a rellenar un formulario para decir cómo ha sido nuestra experiencia a menos que haya sido negativa.
Es por ello que si somos capaces de detectar puntos rojos en la experiencia de los usuarios sin que suponga para ellos un esfuerzo más se podría mejorar el servicio, y gracias a esta tecnología esto sí es posible.
Los próximos pasos que se darán con este proyecto están directamente relacionados con los problemas que se han tenido en la culminación del proyecto. La primera dificultad sufrida por el equipo fue la correspondiente al despliegue en Amazon Web Services, lo que debía facilitar el entrenamiento, hizo que el proyecto quedase parado dada la inexperiencia de los integrantes del equipo con dicha herramienta. Esto ha hecho que el entrenamiento no se pudiese hacer en los servidores de Amazon, lo que ha tardado mucho tiempo y dificulta cualquier modificación y ejecución en el modelo. Es por esto por lo que, próximamente, se intentará realizar dicho despliegue para poder trabajar de una manera más eficiente y eficaz.
Este problema hizo que la desviación sufrida en el tiempo fuese muy elevada, lo que dificultó la culminación de toda la funcionalidad que previmos en primera instancia. Además, esto también estaba directamente relacionado con el pequeño margen que nos quedaba para entrenar el modelo, lo que implica que la eficacia y precisión del modelo no sea la óptima, y aun quede un margen bastante amplio de mejora. Es por esto por lo que se podría, mediante más entrenamientos, obtener un modelo de mayor calidad.
No considerábamos tener tantos problemas cuando definimos el proyecto que queríamos realizar, debido a la inexperiencia que teníamos en este ámbito. Una de las funcionalidades que planteamos al principio era la incorporación de una Web Cam que nos permitiera sacar fotos al instante y poder clasificar las emociones de dicha imagen, para poder hacerlo más real. Sin embargo, debido a la falta de tiempo, es un aspecto que no se ha podido desarrollar pero que sería lo primero que realizaríamos en el futuro.
Sería muy útil integrar nuestro modelo con webcams en las entradas/salidas de todos aquellos lugares que quieran valorar la satisfacción o experiencia del cliente en dicho lugar. Por ejemplo, restaurantes, tiendas, conferencias, etc.
Además, en el futuro sería genial programar que la aplicación fuese capaz de reconocer una imagen tomada en la salida de un lugar con aquella imagen tomada en la entrada a la misma persona. Eso haría que se pudiese comparar eficientemente los resultados de todos los usuarios, y sería un paso adelante enorme ya que dotaríamos a la empresa/institución que lo utilice de inteligencia empresarial. Si a eso le sumásemos una serie de gráficos que visualicen los resultados en una especie de dashboard, podría ayudar a los directivos a tomar diversas decisiones en base a la satisfacción del cliente.
En el siguiente repositorio se encuentra el código usuado para desarrollar esta aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Donostia/Donostia2020/Facial_Expression_Saturdays
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!

Latam online. Primera Edición. 2020
Según la Organización Mundial de la Salud, la contaminación del aire representa uno de los mayores riesgos para la salud, mostrando una relación directa con la carga de morbilidad derivada de accidentes cerebrovasculares, diferentes cánceres de pulmón y neumopatías crónicas e incluso agudas, entre ellas el asma.
Existen estudios que confirman que alinearse a las directrices recomendadas por la OMS derivan en un impacto de hasta 22 meses más en el aumento de la esperanza de vida en la población (WHO, 2016).
En 2016, el 91% de la población vivía en lugares donde no se respetaban las Directrices de la OMS sobre la calidad del aire. Según estimaciones de 2016, la contaminación atmosférica en las ciudades y zonas rurales provoca cada año 4.2 millones de defunciones prematuras. Un 91% de esas defunciones prematuras se producen en países de bajos y medianos ingresos, y las mayores tasas de morbilidad se registran en las regiones del Sudeste de Asia y el Pacífico Occidental.
En los países de bajos y medianos ingresos, la exposición a contaminantes en el interior y alrededor de las viviendas como consecuencia del uso de combustibles en estufas abiertas o cocinas tradicionales incrementa el riesgo de infecciones agudas de las vías respiratorias inferiores, así como el riesgo de cardiopatías, neumopatía obstructiva crónica y cáncer de pulmón en los adultos.
Existen graves riesgos sanitarios no solo por exposición a las partículas (PM10 y PM2.5, es decir, partículas menores que 10 y 2.5 micrómetros respectivamente), sino también al ozono (O3), el dióxido de nitrógeno (NO2) y el dióxido de azufre (SO2). Como en el caso de las partículas, las concentraciones más elevadas suelen encontrarse en las zonas urbanas. El ozono es un importante factor de mortalidad y morbilidad por asma, mientras que el dióxido de nitrógeno y el dióxido de azufre pueden tener influencia en el asma, los síntomas bronquiales, las alveolitis y la insuficiencia respiratoria.
Las industrias, los hogares, los automóviles y los camiones emiten mezclas complejas de contaminantes atmosféricos, muchos de los cuales son perjudiciales para la salud. De todos estos contaminantes, el material particulado fino tiene el mayor efecto sobre la salud humana. La mayor parte del material particulado fino proviene de la quema de combustible, tanto de fuentes móviles como vehículos, como de fuentes estacionarias como centrales eléctricas, industria, hogares o quema de biomasa.
La calidad del aire se mide a partir de las concetraciones de los contaminantes que están presentes en la atmósfera, en particular en el caso de las partículas finas se representa por la concentración media anual.
Aunque las partículas finas se mide en muchos lugares a lo largo del mundo, la cantidad de monitores en diferentes áreas geográficas varía, y algunas áreas tienen poco o ningún monitoreo. Para producir estimaciones globales de alta resolución, se requieren datos adicionales. La concentración media urbana anual de PM2.5 se estima con modelos mejorados utilizando la integración de datos de sensores remotos por satélite, estimaciones de población, topografía y mediciones terrestres.
Con la finalidad de poder entender a nuestro amenazante enemigo, nos dimos a la tarea de hacerlo nuestro mejor amigo. Conocer hasta el más microscópico detalle para que con la ayuda de la Inteligencia Artificial nos pudiéramos adelantar a sus pasos.
La concentración promedio diaria de PM2.5 se puede predecir a partir de los contaminantes y parámetros meteorológicos que se monitorean de manera rutinaria en la Ciudad de México.
En la literatura se recomienda seguir el siguiente plan de modelación:
A estos pasos se agregaría un paso previo: seleccionar los datos para responder al problema a modelar.
En el tema de calidad del aire los gobiernos locales cuentan en la mayoría de las veces con información de este tipo, sin embargo, a veces llega a presentar un alto porcentaje de datos faltantes. Por otro lado, no toda la información se encuentra disponible de manera frecuente o pasa por un proceso de validación, por lo tanto se determinó emplear datos de una zona metropolitana, que cada mes publica la información validada, es el caso de la información del Sistema de Monitoreo Atmosférico de la Ciudad de México — SIMAT-).
Periodo de análisis: se consideró 5 años completos (2015 a 2019) y lo que va del año 2020.
Se descargaron los datos de contaminantes y parámetros meteorológicos de los sitios de monitoreo del SIMAT (monóxido de carbono -CO-, dióxido de nitrógeno -NO2-, óxidos de nitógeno -NOx-, óxido nitrico -NO-, ozono -O3-, partículas menorea a 10 micrómetros -PM10-, partículas PM coarse que corresponde a la diferencia entre PM10 y PM2.5 -PMCO-, partículas menores a 2.52 micrómetros -PM2.5-, dióxido de azufre -SO2-, temperatura ambiente -TMP-, humedad relativa -RH-, presión atmosférica -PA-, presión barométrica -PBa-, velocidad del viento -WSP- y dirección del viento -WDR-) y se generó una base única. La información inicial representa los registros horarios de 39 sitios (ACO, SUR, TAH, TLA, TLI, SJA, PED, SAG, SFE, TPN, XAL, CCA, MGH, AJM, VIF, UAX, UIZ, CAM, MON, CHO, COY, CUA, MER, INN, HGM, CUT, AJU, ATI, LLA, LPR, NEZ, FAC, IZT, BJU, GAM, LAA, MPA, FAR y SAC) de monitoreo automático, sin embargo, por la construcción propia de un sistema de monitoreo de calidad del aire, no todos los sitios monitorean todos los contaminantes y parámetros meteorológicos. Aunado a esto, en el año 2017 se registró un sismo en la Ciudad de México que dañó la infraestructura de algunas instituciones en las que se localizaba estaciones de monitoreo, lo cual derivó en retirar los equipos de medición de esos lugares. Otra característica que presenta este tipo de fenómenos es la dependencia de sus registros con los ciclos temporales ya que su comportamiento se ve influenciado por la época del año y la hora del día (efecto de inversiones térmicas, época de lluvias, estabilidad atmosférica, horas pico del día, ubicación de fuentes de contaminación, entre otras).
Tabla.1. Listado de los sitios de monitoreo de calidad del aire del SIMAT.
Todo esto implicó que se realizaran varios pasos para determinar la inclusión de los sitios para este análisis.
Selección de sitios:
El registro continuo de este tipo de datos requiere un programa de aseguramiento y control de calidad de las mediciones, el cual implica la pérdida de registros, por ejemplo, cuando se realizan calibraciones y revisión del correcto funcionamiento de los equipos automáticos; así como, por la falta de insumo de energía eléctrica que conlleva la reactivación de los equipos. Esto se refleja en tener valores faltantes (missing values) en las bases de datos, por lo tanto, se debe plantear un tratamiento para el relleno de datos faltantes.
Para el análisis exploratorio se empleó la librería Open air de r-project.
Para el proceso de relleno de datos faltantes se exploraron varias técnicas sin llegar a buenos resultados ya que generaban valores constantes para el relleno (por ejemplo las opciones que tiene implementada la rutina Fancyimpute de Python), entre ellas:
Por lo que se decidió rellenar a partir del perfil horario de la serie de datos, es decir considerando el promedio de registros para la misma hora a lo largo de la serie, esto asegura que se cuente con un valor diferenciado por hora y no se generan datos constantes para todos los registros faltantes.
En algunas ocasiones es recomendable transformar los datos para obtener un mejor ajuste, sin embargo algunas transformaciones pueden ocasionar falta de interpretación de los resultados, por lo cual se recomienda emplear transformaciones sencillas y fácil de revertir al momento de la interpretación.
En el caso de la variable respuesta (PM2.5) se transformará con el logaritmo natural para contar con un mejor comportamiento de los datos.
Y=ln(PM2.5)
En el caso de los regresores (o covariables) se estandarizan los datos en cada variable, debido a que cada una por su naturaleza está en unidades y escalas variadas.

La librería Prophet de facebook (fbprophet),permite pronosticar datos de series de tiempo basado en un modelo aditivo donde las tendencias no lineales se ajustan a la estacionalidad anual, semanal y diaria, más los efectos de los días festivos. Funciona mejor con series de tiempo que tienen marcados efectos estacionales y varias temporadas de datos históricos. Prophet es robusto ante los datos faltantes y los cambios de tendencia, y normalmente maneja bien los valores atípicos.
Para modelar la serie temporal Prophet, separamos la señal en los siguientes componentes aditivos:
y(t)= g(t) + s(t) + h(t) + εt
Dónde:
Para un descripción más detallada del algoritmo consultar https://peerj.com/preprints/3190/
El algoritmo funciona mejor con series de tiempo que tienen fuertes efectos estacionales y varias temporadas de datos históricos. Prophet es robusto ante los datos faltantes en la variable de salida y a los cambios de tendencia, y normalmente maneja bien los valores atípicos (outliers).
Se establecieron los grupos de entrenamiento y prueba para evaluar los modelos considerando la secuencia de la información y a diferencia de tomarlos al azar, se estableció dejar los primeros cuatro años como periodo de entrenamiento y el último año como periodo de prueba.
Se seleccionaron los datos de calidad del aire de las estaciones localizadas en la Zona Metropolitana de la Ciudad de México, que presentan registros entre los años 2015 y 2020, de estas estacione se realizó un filtro para tener las estaciones que contaban con registros de PM2.5, a estas estaciones se les realizó un segundo filtro para contar con las estaciones que registraron dato en el año 2019 y que contaron con suficiencia anual (al menos el 75% de registros horarios en el año) de esta manera se contó con un conjunto de once estaciones (ver Mapa 2).
El análisis exploratorio permitió conocer el comportamiento de cada variables, en el caso de PM2.5 (Figura 1) se observó que hay diferencias entre las estaciones, ya que algunas presentan mayor cantidad de eventos atípicos, esto se debe principalmente al lugar en el que se localiza cada estación y las fuentes de contaminación asociadas a ellas.

Para ejemplificar el resto de los resultados se presenta el caso de la estación Ajusco Medio (AJM), para su localización consulte el Mapa 2.
El análisis por variable deja ver que son frecuentes los periodos de ausencia de datos, la diferencia en el comportamiento de cada parámetro (algunos presentan distribuciones sesgadas a la derecha, otros a la izquierda y algunos su distribución es simétrica, algunos presentan más de una moda y suele haber datos atípicos) (Figura 2).
El comportamiento de PM2.5 con respecto a la dirección del viento, muestra una clara asociación en meses de invierno (enero y diciembre) en la dirección noreste y con una franja de influencia del norte al este, y en los meses de abril y mayo se repite con un ligero corrimiento hacia el sur (colores rojos en la Figura 3), también se identifica la dilución de este contaminante en los meses de lluvias, ya que predominan los colores azules, verdes y amarilos en todas las direcciones del viento.

La desagregación por época climática para cada año permite apreciar los cambios a lo largo del periodo, (cabe comentar que la época invernal considera el diciembre de un año y el enero y febrero del siguiente año), se identifica el cambio de rojos a naranjas a lo largo de los años en la época invernal y en 2020 no registró esos colores (presenta concentraciones menores). También se marca la influencia de la primavera (marzo a mayo) con concentraciones altas principalmente en 2016, 2017 y 2019 (Figura 4).


La serie de tiempo de los registros horarios de PM2.5 se representa en la Figura 5, se puede apreciar los espacios en blanco correspondientes a los valores faltantes en esos días, así como la variación del fenómeno y los valores extremos.
La modelación se realizará con registros promedios diarios de PM2.5 por lo que se visualizó el comportamiento de estos en la Figura 6.
La variación de PM2.5 a partir de registros diarios permite identificar la presencia de ciclos asociados a los meses y años (Figura 7).
En el caso de PM2.5 la transformación fue con el logaritmo natural, la Figura 8 muestra el comportamiento original y la transformación, donde se busca tener una distribución más apegada a la simetría.

En el caso de los regresores se realizó la transformación por separado para el conjunto de datos de entrenamiento y de prueba (Figura 9).
Comenzamos modelando la serie univariada de PM2.5 sin imputar faltantes ya que el modelo maneja la falta de información en la variable de salida.
Generamos el conjunto de entrenamiento desde el 2015–01–01 hasta el 2018–12–31 y el conjunto de prueba a partir del 2019–01–01 y hasta el 2020–09–30 para entrenar y evaluar el modelo respectivamente. Se incorporan los días festivos de México al modelo para lograr un mejor ajuste.
Fragmento de código con los valores de los hiperparametros utilizados para entrenar el algoritmo:
pro_change=Prophet(changepoint_range=0.9,yearly_seasonality=True,
holidays=holidays)
pro_change.add_country_holidays(country_name=’MX’)
forecast = pro_change.fit(train).predict(future)
fig= pro_change.plot(forecast);
a = add_changepoints_to_plot(fig.gca(), pro_change, forecast)
El modelo genera un valor predictivo llamado yhat, y un intervalo de confianza con límite inferior yhat_lower y límite superior yhat_upper para la concentración de PM2.5, fijamos el nivel de confianza del 95%.
Fragmento de código para hacer el cross validation
from fbprophet.diagnostics import cross_validation
cv_results = cross_validation( model = pro_change, initial = ‘731 days’, horizon = ‘365 days’)
En la Figura 10 los puntos negros representan los valores de concentración promedio diaria de PM2.5, la curva en azul oscuro es el pronóstico generado por el modelo y la zona azul celeste es el intervalo de confianza al 95 %.
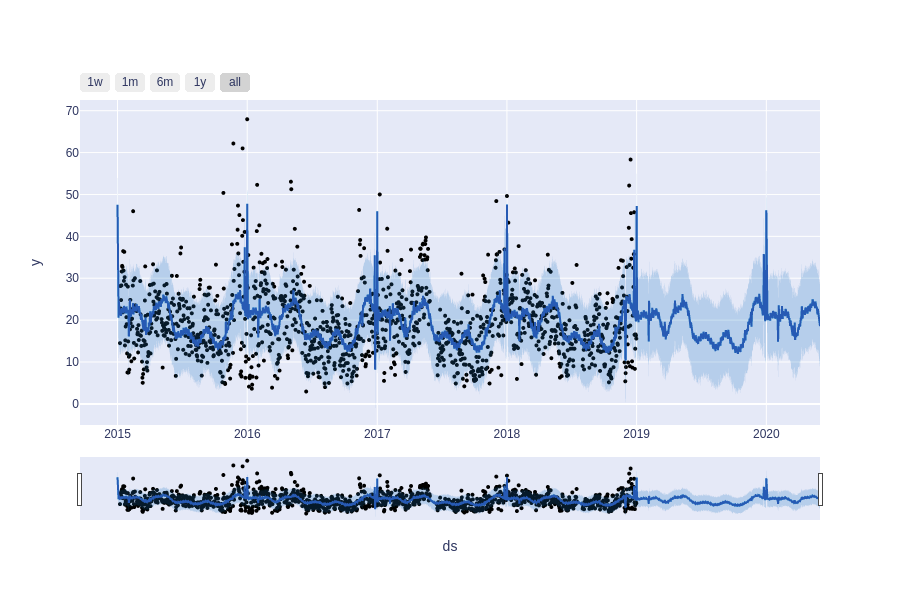
En la Figura 11 se muestra la descomposición de la serie en su tendencia, los días festivos, la estacionalidad semanal y anual.
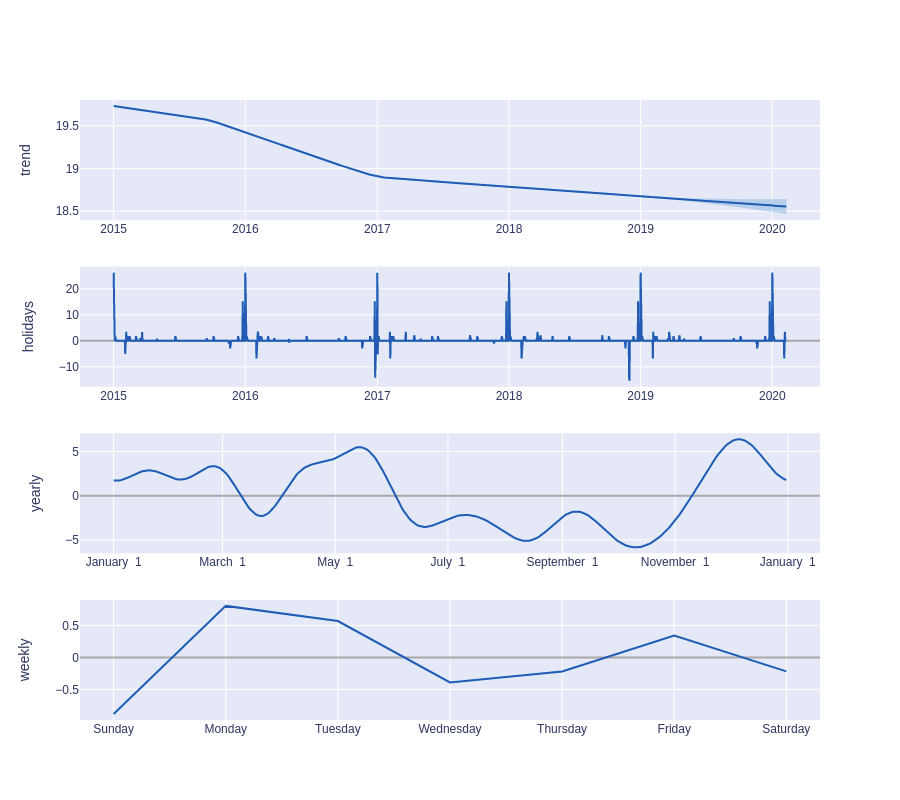
La función performance_metrics se puede utilizar para calcular algunas estadísticas útiles para medir el desempeño de la predicción (yhat, yhat_lower y yhat_upper versus y), en función de la distancia desde el límite (qué tan lejos en el futuro estaba la predicción). Las estadísticas calculadas son el error cuadrático medio (MSE), la raíz cuadrada del error cuadrático medio (RMSE), el error absoluto medio (MAE), el error porcentual absoluto medio (MAPE), el error porcentual absoluto medio (MDAPE) y la cobertura de las estimaciones yhat_lower y yhat_upper. Estos se calculan en una ventana móvil de las predicciones en el dataframe después de clasificar por horizonte (ds menos cutoff). Por defecto, el 10% de las predicciones se incluirán en cada ventana, pero esto se puede cambiar con el argumento rolling_window.
Fragmento de código para la obtención de las métricas
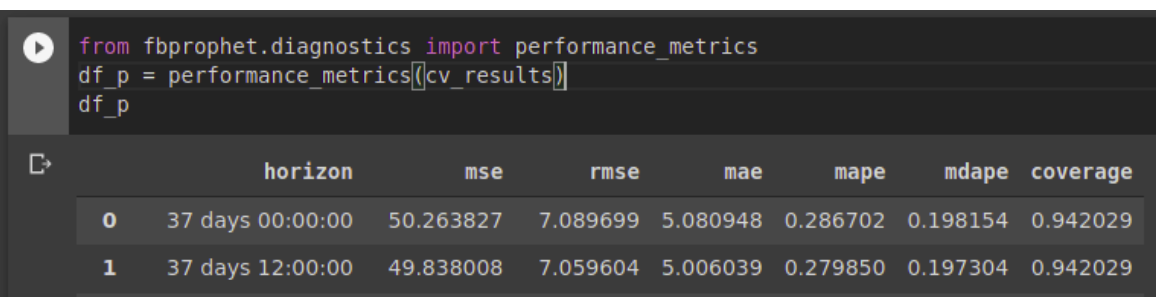
Una vez que se corrieron los diferentes modelos, se realizó la comparación de las métricas para determinar el mejor modelo. En el caso de AJM, el mejor modelo a partir de RMSE fue el ajuste con hiperparámetros, seguido del modelo con regresores en general. Para todas las métricas, el modelo con menor error fue el de los hiperparámetros.
Tabla 2. Comparativa de las métricas de los modelos ajustados (AJM, 2015–2020)
A continuación se presenta la representación gráfica del mejor modelo ajustado, distinguiendo el periodo de entrenamiento, el de prueba y el pronóstico (Figura 12).
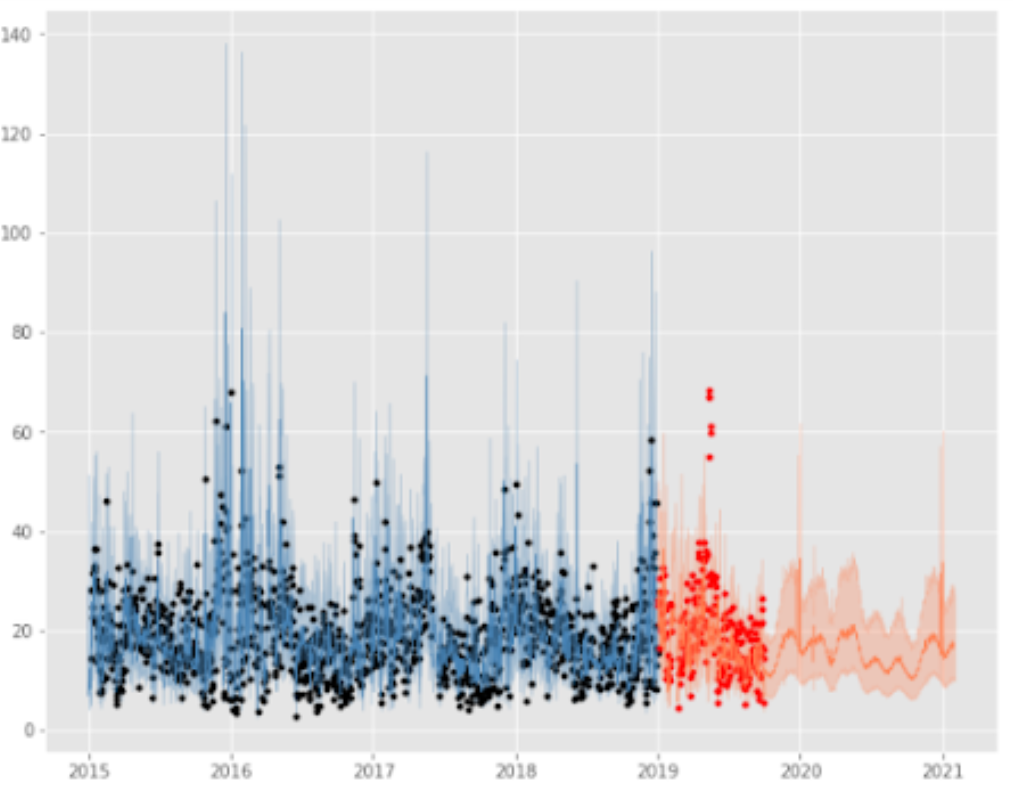
Como resultado agregado al modelar estos datos, podemos detectar si en días futuros se puede presentar algún riesgo para la salud, con referencia a las Directrices de la Organización Mundial de la Salud para el promedio de 24 horas de PM2.5 (25 g/m³) y los rangos establecidos en el Índice AIRE y SALUD de México (NOM-172-SEMARNAT-2019).
Tabla 3. Niveles de riesgo de la calidad del aire (2020)

Fuente:Comisión Ambiental de la Megalópolis (CAMe)
En el caso de Ajusco Medio el pronóstico identifica registros posibles entre las bandas de calidad del aire buena y aceptable, y al considerar el intervalo de confianza del modelo (Figura 13) se identifica que los registros podrían llegar hasta la banda de calidad el aire mala, lo que podría presentar algún riesgo para la población.
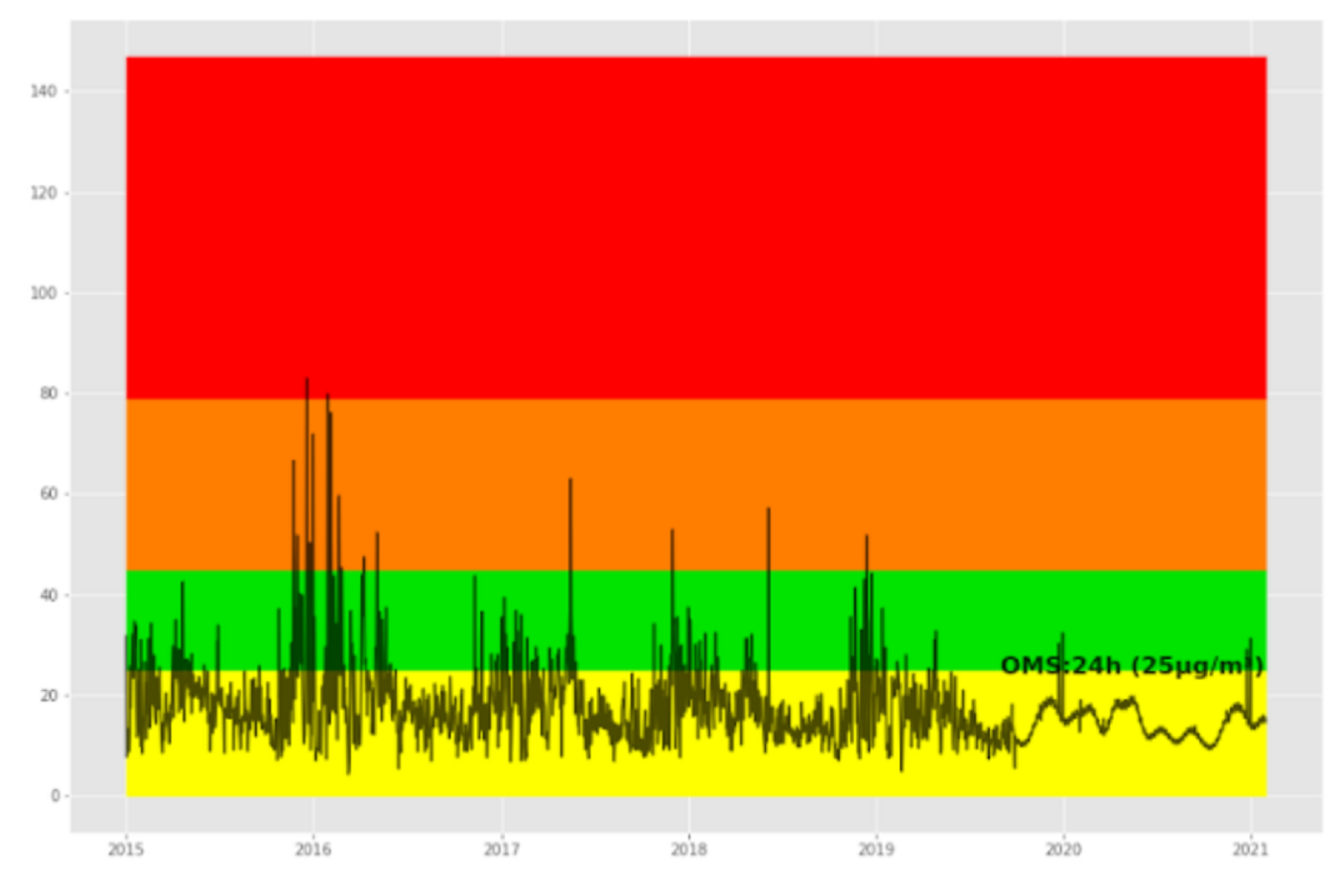
Se abre un mar de oportunidades para mejorar este primer acercamiento a modelar la calidad del aire por medio de inteligencia artificial. Los modelos se aplicaron a cada una de las estaciones, pero se puede desarrollar un modelo multiseries. De igual manera se estableció el total de variables contra las que se realizó el ajuste, pero se puede realizar una búsqueda entre los regresores que mayor aportación presentan al modelado de PM2.5.
Desarrollar una aplicación para dar difusión de los resultados.
Probar otros conjuntos de datos de diferentes ciudades.
y mucho más…
Medina F. y Galván M. Imputación de datos: teoría y práctica. CEPAL, 2007.
Shaadan N. and RahimN A M. 2019 J. Phys.: Conf. Ser. 1366 012107.
Taylor SJ, Letham B. 2017. Forecasting at scale. PeerJ Preprints 5:e3190v2
Carslaw, D. C. and K. Ropkins, (2012) openair — — an R package for air quality data analysis. Environmental Modelling & Software. Volume 27–28, 52–61.
Facebook Open Source, Prophet. https://facebook.github.io/prophet/
Fancyimpute https://github.com/iskandr/fancyimpute
En el siguiente repositorio se encuentra el código usado para desarrollar esa aplicación: https://github.com/SaturdaysAI/Projects/tree/master/LATAM_remote/SaturdaysAI-LATAM_AIreySalud_2020-main
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Guadalajara. Segunda Edición 2020
¿Sabias que las enfermedades cardiovasculares (ECV) son la principal causa de muerte en todo el mundo?
En México, el 19% de mujeres y hombres de 30 a 69 años mueren de enfermedades cardiovasculares, y se estima que el 70.3% de la población adulta vive con al menos un factor de riesgo cardiovascular.
Las enfermedades cardiovasculares son un grupo de desórdenes que afectan al corazón y/o los vasos sanguíneos , las cuales representan un problema de salud pública en México .
Estudios epidemiológicos han permitido identificar un conjunto de variables denominadas factores de riesgo de tipo cardiovascular (FRCV), que son todas aquellas características biológicas no modificables y características conductuales modificables (estilos de vida), cuya presencia se relaciona con una mayor probabilidad de sufrir una enfermedad cardiovascular en el futuro. Su identificación temprana es fundamental para implementar cambios en los hábitos de los pacientes con el objetivo de prevenir un evento de enfermedad cardiovascular primario.
En los últimos años México ha implementado varias estrategias enfocadas en el sector salud que prometen buenos resultados. A pesar de esto, se han encontrado inconsistencias en los procesos de atención primaria, práctica clínica e instrumentos de vigilancia que limitan la monitorización cardiovascular de la población.
El proyecto de CARDIOSIGHT nace debido a la presente necesidad en nuestro país de crear métodos y herramientas de identificación temprana para los individuos con alto riesgo de sufrir enfermedades cardiovasculares. Con el fin de prevenir eventos cardíacos primarios y ayudar a disminuir la incidencia de nuevos casos, por medio de hábitos de prevención. Este método de detección será diseñado con ayuda de la inteligencia artificial.
Ventajas de la aplicación:
● La población tendrá la facilidad de conocer su nivel de riesgo sin la necesidad de asistir a una unidad médica de salud. Acelerando de esta manera la identificación de los individuos con un riesgo alto antes de que se desarrolle un evento cardiovascular primario.
● Posterior a la identificación, dependiendo del resultado, se le sugerirá al usuario visitar las páginas disponibles del Instituto Mexicano del seguro social que brindan la información sobre las campañas preventivas actuales relacionadas a este tipo de enfermedades, en las cuales encontrarán la información necesaria para educarse sobre la problemática, además de la posibilidad de encontrar su clínica más cercana para realizar su primer chequeo médico.
Se decidió trabajar con el dataset Cardiovascular Disease encontrado en la página Kaggle. El cual consiste en 70,000 datos recabados de pacientes, contiene 11 características y una variable objetivo, información recabada por medio de resultados médicos, compartida por el paciente o de forma factual.

Tras realizar el análisis exploratorio y transformación de nuestros datos se decidió experimentar con el modelo de Random Forest debido a su excelente capacidad de clasificación.

Tras realizar varias pruebas y tuneo de hiperparámetros se encontró el modelo ideal para nuestra aplicación.
Con un accuracy de 0.73 y una curva ROC de 0.8, se decidió obtener gráficas complementarias del modelo para entender de una forma más profunda su comportamiento probabilístico.
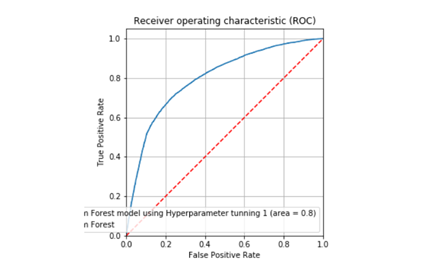
Uno de los retos más grandes en el desarrollo de este proyecto fue encontrar un punto de corte para decidir si una persona tenia una alto o bajo riesgo de sufrir de una enfermedad cardiovascular. Es aquí donde la confianza probabilística entra en juego, y también poner en la balanza cuál situación es mejor: Decirle a los pacientes que tendrán una enfermedad cardiovascular cuando no la tienen, o decirles que no, cuando sí la tienen. En mi caso preferí que mi modelo identificara al mayor numero de personas de sufrir de una enfermedad cardiovascular, con la premisa de que los falsos positivos pueden ser detectados al realizar pruebas clínicas complementarias.

Como apoyo para la selección de este punto de corte nos basamos en el modulo de Youden, gráficas de calibración y los valores de predicción obtenidos.
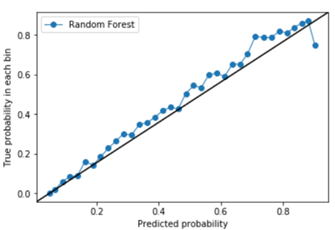
Debido a que se deseaba que la población pudiera hacer uso de este recurso, se decidió implementar una aplicación web usando la plataforma streamlit. En la cual el usuario podría consultar su indicador de riesgo por medio del llenado de sus FRC. En caso de que su resultado fuera “Alto” se le redireccionaría a la pagina oficial del IMSS.
Se logró obtener un algoritmo capaz de indicar si un individuo tiene alto riesgo de sufrir una enfermedad cardiovascular o no, con resultados comparables a los mencionados en la bibliografía consultada.
Tras un análisis del poder predictivo de los datos se encontró que tener un grado de hipertensión y ser mayor de 50 años, puede influir a que seas un individuo con alto riesgo. El colesterol y el índice de masa corporal también son características a considerar, ya que, si sus niveles son más altos de lo normal, también pueden influir a un riesgo mayor. Una identificación temprana de estas variables de riesgo es fundamental para poder prevenir un episodio de enfermedad cardiovascular primario.
No, este proyecto sirve como precedente para saber si la metodología utilizada es útil y qué tipo de recursos son necesarios para realizar una investigación más elaborada enfocada a la población mexicana.
Cómo siguientes pasos, es indispensable trabajar con un dataset enfocado en la población mexicana, con él se podría hacer un análisis más profundo respecto a cómo las variables de alimentación, sociales, económicas y educacionales afectan a las predicciones. Además de que se podría crear un algoritmo de cálculo de factor de riesgo, enfocado a esta población.
Se desea trabajar más con el algoritmo creado, para mejorar su desempeño de clasificación aplicando feature selection y otros algoritmos de machine learning.
Todavía queda mucho por hacer, pero definitivamente esta experimentación le da dirección a los próximos esfuerzos, te invito a que me sigas, para que puedas seguir leyendo sobre este proyecto.
Rebeca Sarai Nuñez Ramirez
En el siguiente repositorio se encuentra el código usado para desarrollar esta aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Guadalajara/July2020/Cardiosight
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!

Donostia. Primera Edición. 2020
El fatídico 11 de marzo del 2020, la OMS declaró la pandemia mundial por COVID-19. Más de 300 días después, hemos decidido hacer público y accesible para el mundo entero el trabajo que hemos venido desarrollando durante más de 8 semanas.

Prepárense, gobiernos e instituciones sanitarias del planeta, pues lo que van a ver en este artículo establecerá los cimientos de un nuevo sistema de vigilancia que permitirá asegurar el cumplimiento de una de las medidas que más se ha repetido durante estos fatídicos 300 días: la distancia de seguridad interpersonal de metro y medio.
Nuestro incombustible grupo, formado por 3 “locos” ingenieros (alguno de ellos en proceso) ha trabajado día y noche para traer la mejor solución posible a este problema.
El proyecto, que comenzó bajo el nombre de WATCHDOG (perro guardián) por la misión inicial que teníamos en mente (un robot con autonomía de movimientos que vigilase el cumplimiento de la distancia de seguridad y que ladrase cada vez que esta fuera quebrantada) iba a ofrecer, más allá del obvio beneficio de un constante recordatorio a las personas de la necesidad de cumplir con la medida de la distancia interpersonal, una herramienta para el mapeo y creación de “puntos calientes” en los que la distancia se incumpliese más a menudo.
Para todo ello, el equipo ha tratado de crear una convergencia entre los mundos de la electrónica y la Inteligencia Artificial, haciendo uso de los medios más innovadores que tenía a su mano. Con una Raspberry Pi 3, un microcontrolador de bajo nivel equivalente a Arduino Mega, diferentes medios para la comunicación, algoritmos, librerías y redes neuronales convolucionales se ha tratado de alcanzar la solución con la mayor satisfacción posible.
Para el proyecto de Saturdays.AI se ha pensado en desarrollar un proyecto Watchdog (perro guardián) que vigila la distancia mínima recomendada por los protocolos Anti-COVID.
El planteamiento inicial ha sido el de programar un robot capaz de emitir un ladrido cuando la distancia de seguridad (requerido por los protocolos Anti-COVID) fuera quebrantada, enviando los datos adquiridos a un servidor y realizar un mapeo (mapa de calor) en tiempo real.
El objetivo básico del proyecto es converger el mundo OT con el mundo IT, es decir, la convergencia de la electrónica con el de la IA (inteligencia artificial) muy de moda en el mundo IT, utilizando técnicas de Deep Learning, que es una de las ramas del Machine Learning. De hecho, a pesar de que esta primera edición de AI Saturdays Euskadi se haya orientado al Machine Learning en general, hemos decidido profundizar en el Deep Learning por voluntad propia.
Poco a poco se están desarrollando tarjetas electrónicas autónomas que funcionan At The Edge (es decir que la misma tarjeta de control aplica los algoritmos) sin utilizar el Cloud para ello, o sin utilizar una unidad PC más potente para su procesado. Este fenómeno, conocido como Edge Computing, permite aliviar la carga de procesamiento a servidores centrales delegando tareas que puedan ser sencillas pero repetitivas a los nodos externos.
Cuando se detectan 2 personas, manda la posición de la detección y la imagen de violación de la distancia a un servidor Web, creado con Flask.
En lo que al mapeo respecta, la idea inicial era realizar un mapeo SLAM (simultaneous localization and mapping) utilizando un sensor LIDAR o una cámara 3D, pero nos hemos encontrado con limitaciones para hacer un Point Cloud que nos permitiera ejecutar el mapeo. Se describe esta limitación en los Trabajos a Futuro.
El objetivo inicial era plasmar todo el código dentro de una tarjeta Raspberry PI 3 (de aquí en adelante RPi3), pero a pesar de existen librerías para controlar los módulos de entradas y salidas (GPIO), el dispositivo no es lo suficientemente potente para poder procesar todo en tiempo real. Para ello existen módulos dedicados y deterministas que facilitan estas tareas.
Para tratar de cumplir con el objetivo aquí propuesto se ha utilizado un microcontrolador STM32F411RET. Se trata de un microcontrolador de gama baja equivalente a un Arduino Mega, pero con un sistema operativo de tiempo real (Real Time Operating System o RTOS), al ser determinista se tiene el control del timing y tareas, pudiendo tener un mayor control para la adquisición de datos y respuesta de los actuadores.
Se decidió utilizar esta tecnología por la gran cantidad de librerías robustas que existen para controlar los periféricos.
El algoritmo final que se ha usado ha sido por goleada YOLO (para nuestro caso), respecto a otros conocidos como SSD (Single Shot Detection) o la más precisa de todas las tecnologías RESNET.
El reto en este apartado ha sido buscar la tecnología que mejor se adapta al tiempo real y nos basamos en las reglas de oro que dijo uno de los mentores:
1. ¿Qué pasa en el mercado? ¿Cuál es la tendencia del mismo? ¿Qué tipo de arquitectura es más viable con las restricciones presupuestarias y de tiempo que tenéis?
2. Mirad lo que hacen los grandes. ¿Podemos pensar igual a ellos? Es decir, ¿tenemos que plantearnos entrenar redes extremadamente complejas, o tenemos que poner los pies en la tierra y plantear ejemplos más rápidos para construir un Producto Mínimo Viable (MVP)?
3. ¡Adáptate!
En esta fórmula, el resultado de 1+1 en ingeniería sería determinista pero en la vida real el resultado es estocástico, así que depende. ?
Este proyecto está acotado para capacidad computacional de gama media y se ha querido estrujar al máximo desde ese punto de vista. Por ello, el mejor algoritmo que encontramos, el cual estaba puramente escrito en C (siendo un terrible reto el aplicar funciones matemáticas a pelo; aprovechamos para agradecer a Joseph Redmon) es lo más rápido comparado con librerías escritas a mayor alto nivel (TensorFlow, pyTorch).
Como curiosidad, usando la versión para embebidos de SSD se llega a unos 18 Frames por Segundo (FPS) comparado con YOLO, que llega a 24 FPS. Sin haber añadido telecomunicaciones nos dimos cuenta cuál era el camino a seguir, pero se encontraron todo tipo de resoluciones de las distintas tecnologías.
“Cabe destacar que para el equipo, el algoritmo o tecnología más completo y adaptado si se tuviera un poco más de capacidad computacional serían RNN o FAST-RNN, ya que de una tirada no solo tendríamos la posición de los objetos, sino cada pixel de la imagen estaría vinculado a una clase y con esto se podría dotar al proyecto de la capacidad de contextualizarse en el entorno. Y esto nos llevaría a más poder de adaptación, teniendo en particular un efecto positivo para el ámbito del Machine Learning, donde se dispondría de más DATO al que poder darle valor sacado del entorno.”
Si se tiene aún más curiosidad al respecto, os dejamos este link.
Como esto se extendería hasta el infinito, no se van a explicar los detalles del funcionamiento a fondo; se adjunta un link donde se explica detalladamente el algoritmo en su versión v3. La diferencia está en que en la versión v4 aumenta la precisión pero en su versión tiny la velocidad se mantiene constante.
La analogía del “EDA” realizado en nuestro proyecto de Deep Learning tendría que ver, entre otros, con limpieza y preprocesamientos hechos de las imágenes obtenidas. El primer preprocesamiento ejecutado sería el que ofrece la función BLOB de OpenCV que reduce la escala de 8 bits (255 RGB) a escala porcentual unitaria.
Este detalle es muy importante ya que pasa el resultado de cualquier cámara a la que el algoritmo necesita de entrada. ¿Lo malo? Que se vuelen datos de coma flotante y eso requiere más gasto computacional pero de ese problema ya se encargaron sus autores.
El “tuning” de los parámetros en este aspecto que hemos hecho ha sido pasar la imagen de entrada a la escala más pequeña (316 x 316 píxeles).
Habiendo hecho este primer paso, la imagen pasará por múltiples filtros internos cambiando la dimensionalidad de la entrada y readaptando al mejor estilo de Nolan con películas del calibre de Tenet o Inception. ¿El resultado?
El algoritmo YOLOv4 entrega los datos de la imagen en una matriz compuesta de 13x13x (A x ((B+P) + C)), siendo:
? ¿Y por qué no reentrenar la red aplicando transfer learning?
Mucho ojo, ya que nuestro equipo se peleó para mejorar la respuesta de este algoritmo para aumentar y darle más valor a la matriz de salida de la versión tiny.
Los resultados, por desgracia, no fueron los esperados. El mapa de características que se crea en estos modelos se basa en cantidades muy grandes de datos y de mucha variedad en el tema de la visión, donde son necesarias grandes cantidades (10.000 imágenes) para que el procesamiento pueda ser fluido. Y es cierto, si se reentrenara partiendo de transfer learning nos ahorraríamos muchas imágenes de entrada, pero también hay que tener en cuenta las clases de objetos que se quieran reconocer. Mientras más clases de objetos haya el mapa de características aprende mejor a separar cada clase.
Por ello, se han usado los pesos de la versión COCO para el algoritmo YOLO, ya que era la más similar para nuestro caso.
A continuación, se aplica un segundo filtro, usado para aplicar el BBOX de los distintos anchor boxes para ver cuál es el mejor.
Estos pasos anteriores formarían el proceso EDA como tal. Sin embargo, y en comparación con un proceso de ML, el filtro que se aplicaría dependería del grado de confianza que se tenga de la detección de un objeto, mientras que en un proceso de ML la “manipulación” se suele hacer sobre el mismo dato.
Todo esto se ensambla en una función llamada “Impure Detector” que nos va a devolver los datos que más nos interesan en una lista de Python de la siguiente forma:
La Raspberry 3B+ cuenta con el sistema operativo Raspbian y librerías OpenCV (4.1.0.22).
El funcionamiento de manera general es sencillo: Se procesan los datos de la imagen y se reenvían a un servidor Web Flask instalado en un PC.
Podemos ver más detalles sobre el código de la RPi en CLIENT.py:
● Comunicación Serie
Tenemos una comunicación serie con el microcontrolador. Después de unas cuantas pruebas nos hemos dado cuenta de que, a la velocidad máxima con la que puede trabajar la RPi con python es con un BaudRate 115200 Bits/s, lo que limita la capacidad de mejorar el tiempo de espera entre Cliente-Servidor. Anotamos este aspecto como Trabajo futuro.
● MQTT
También se ha usado MQTT para enviar los datos respecto a la “violación” de la distancia de seguridad” a otro servidor. Sin embargo, como se ha mencionado antes, no se ha llegado a hacer un mapa de calor con el área de los “delitos de distancia de seguridad” a tiempo real, pero conseguimos enviar los datos e insertarlos en un archivo remoto, guardándolos en un fichero CSV dentro del servidor.
Un trabajo a futuro al que, por desgracia no pudimos llegar, era el de generar un pequeño script para graficar o plotear esos datos.
Las imágenes son bastante problemáticas ya que enviar los paquetes de información tan largos y en la que la que el orden influya es complicado, es necesario indexarlos. Se han probado muchas, pero muchas metodologías distintas y la que mejores resultados ha dado ha sido usando una REST API del servidor.
En Internet se encuentra de todo excepto lo que realmente se quiere, por lo tanto hemos tenido que desarrollar el sistema de envío de imágenes comprimidas por HTTP.
Para ello se han utilizado las funciones de imágenes por excelencia, recogidas en el paquete Open Source OpenCV utilizando un buffer dinámico, evitando la escritura en el disco. Esto se debe ya que por experiencia se ha visto que, a la larga, si no se cuidan, los servidores “envejecen” o “degeneran”. Esto evita por ejemplo forzar los soportes de memoria flash y controlar los ciclos de lectura/escritura aplicados.
Después de emplear OpenCV, nuestro sistema crea la captura en un buffer, lo comprime y se envía al servidor, quien lo descomprime y escribe a disco, dejándolo preparado para su almacenamiento y/o post procesamiento. Este envío se hace en formato JSON ya que se tenían errores al enviarlos en otros formatos.
? ¿Cómo enviar datos que son variables en el tiempo de forma constante?
Normalmente, para que dos personas y/o máquinas se comuniquen tienen que hablar el mismo idioma. En Machine Learning, además, los datos suelen enviarse en bloques constantes de información y de tamaño reducido. En nuestro caso, los pasos que va a ejecutar nuestro cliente son secuenciales y si se tropieza en algún punto todo se va al traste.
Por tanto, se han creado datos “ficticios” para enviarlos como mínimo para que todas las piezas del proyecto puedan funcionar sincronizadamente y en armonía.
Los “impuros” nos van a marcar el index del objeto al que esté pecando pero en los negativos no se va a fijar. Por tanto, esa es la razón por la que el proyecto consigue funcionar sin que se note este pequeño bug.
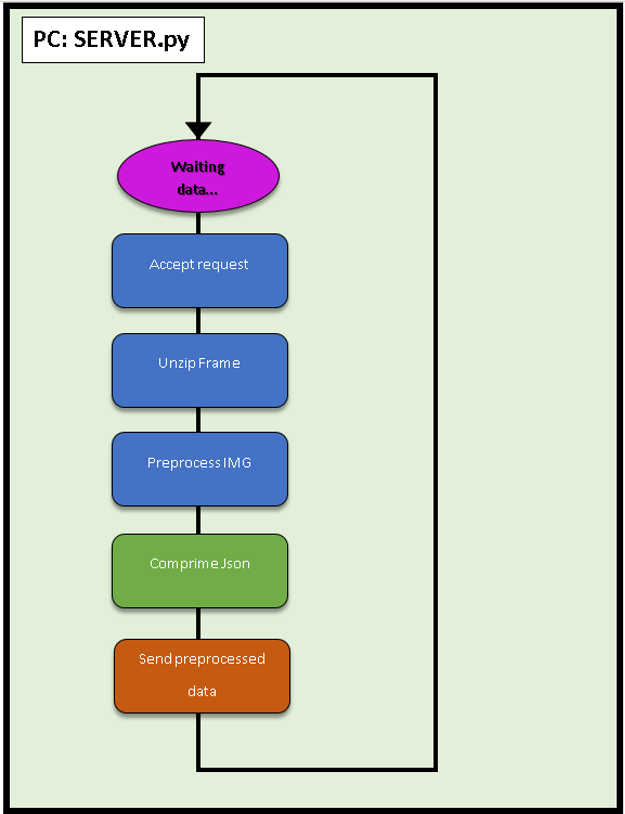
Se ha elegido este microcontrolador (STM32F411RET) por una opción que un Arduino no ofrecía:
La programación de distintas subtareas para que se ejecuten de manera concurrente además de las interrupciones.
Programar en el STMCubeIde nos da la opción de tener la facilidad de programación de Arduino, así como librerías de entornos más industriales.
A diferencia del Arduino en el que el uso de multitareas metiéndolas en un proceso Round Robin es muy complejo, sumado a la limitación de la cantidad de temporizadores o timers que ofrece Arduino Uno 3, con el STM32F404RE estos problemas para insertarlos en la industria se mitigan.
Por tanto, una vez que el micro haya ejecutado la configuración inicial (tareas, interrupciones, timers…) el programa empezará a ejecutar las tareas aplicando un Round Robin, las cuales se agrupan en el siguiente esquema:
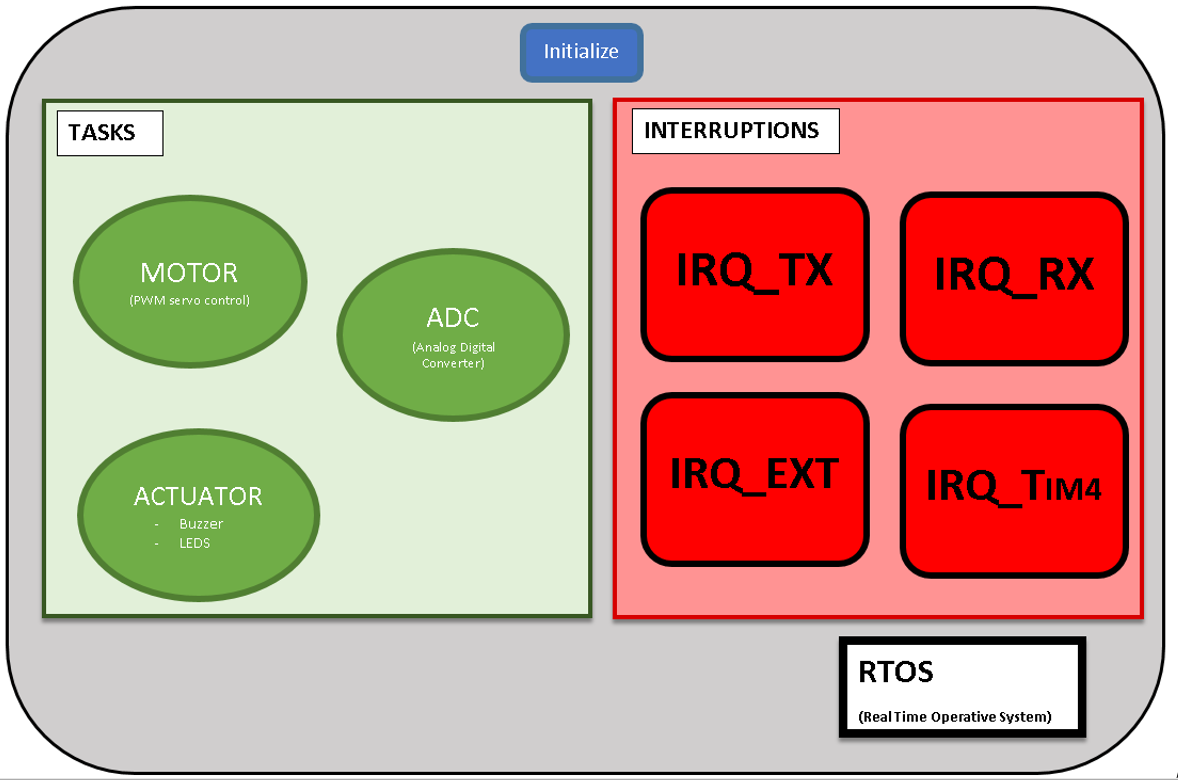
Dentro de las tareas o programas concurrentes existentes existen tres:
1. ADC
Este subprograma se encarga de leer las entradas digitales y procesarlas en 10–12 bits; aspecto que en una lectura por Arduino solo ofrecerá 8 bits de conversión.
Una vez acabadas una por una en orden secuencial, insertará los datos aplicando sus respectivas conversiones en un vector global int32, siendo el motivo para guardarlos como int y no en float que la cantidad de espacio que ocupan se duplicaría (de 32 a 64 bits, por la coma flotante).
Como se puede apreciar en la imagen del envío del Transmisor-Receptor Asíncrono Universal (UART), se envían 4 datos por cada sensor. El último dato es el que quedaría detrás de la coma flotante para su posterior preprocesamiento sencillo en la RPi.
Ejemplo de esto sería recibir del sensor de distancia un valor de 1004 y transformarlo a 100, 4 en este caso simulando metros de profundidad.
2. ACTUATORS
Dentro de los actuadores podemos encontrar que se conmutarán los estados de las salidas digitales pertenecientes al Buzzer y LED_EXT encargados de dotar al robot de notificar al entorno de manera acústica y visual.
No se ha añadido el actuador del motor porque se cree que separado se entiende mejor a la hora de distribuir el código.
3. MOTOR
Los servomotores trabajan entre 500 y 2500 ticks por lo que nuestra tarea TASK_MOTOR se aprovechará de las interrupciones del timer_4 para cambiar su valor ON/OFF.
Además, se ha añadido un acumulador, de tal manera que si mientras se detecta una violación de la distancia de seguridad y antes de que la función se apague se vuelve a recibir una interrupción por la violación de distancia, aumentará el tiempo de espera 5 segundos más en esa posición. Con esto nos aseguramos de que hay un mayor control de las presencias detectadas.
Las interrupciones son peticiones síncronas o asíncronas al reloj en la que el procesador va a dejar de lado la tarea que esté realizando para centrarse en la interrupción.
Nosotros hemos definido 4 tipos de interrupciones.
1. IRQ_EXT:
Es la interrupción externa por botón a la que se va a acceder en caso de que haya un error tanto de comunicación o de cualquier otro tipo para resetear la configuración del microcontrolador sin que resetee todo. Reenviará la información y nos avisará enviando un “DONE” por el puerto serial.
2. IRQ_TIM4
Se ha configurado el timer_4 del microcontrolador para que se ejecute cada 1 MHz.
En resumen, para que tardemos 50 Hz que es la velocidad del servomotor tenemos que añadir un registro contador de 0–2000 unidades para que entre en la interrupción cada 50 Hz.
Es decir, que en cada 200 ms recibiremos 20000 ticks. O dicho de otra manera, cada 200 milisegundos nuestro micro interrumpirá la interrupción de ese timer.
3. IRQ_TX:
Esta interrupción únicamente va a encender un LED interno del microcontrolador para saber de manera rápida que todo está funcionando correctamente.
En la figura inferior, además de ver la distribución de los pines se puede ver el pin del LED interno así como el pulsador interno del microcontrolador.
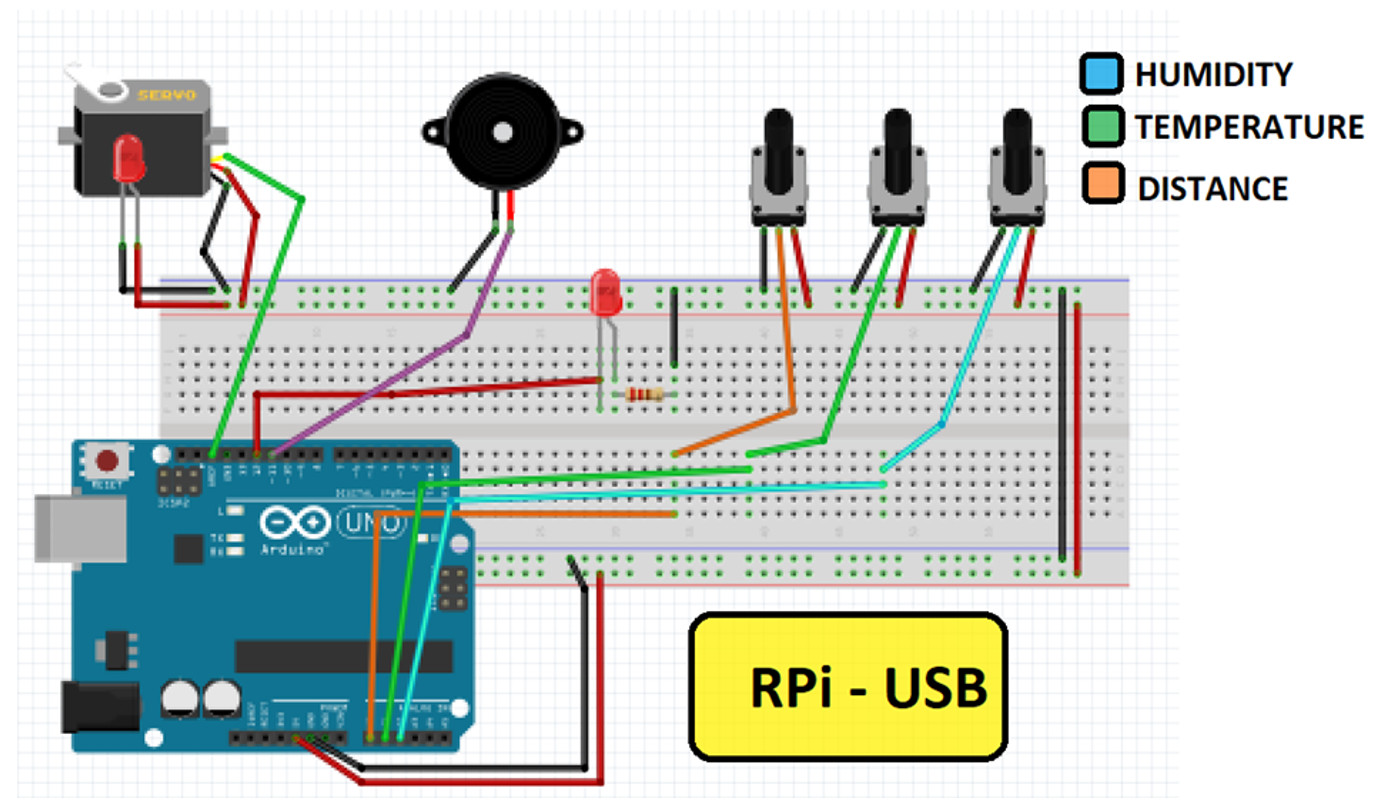
4. IRQ_RX:
A pesar de estar la última en la lista, es la interrupción más importante. Para que la RPi actúe como “cabeza pensante”, es necesaria una interrupción que esté atenta a cualquier señal asíncrona que reciba del microPC y que alerte a la RPi.
Los comandos que se van a enviar desde la RPi son dos:
Cuando recibamos SEND el microcontrolador enviará los datos que tenga en ese momento en el vector “sens”.
Si recibe ALRM ejecutará los actuadores y si antes de que se acabe vuelve a recibir una entrada ALRM, aumentará el tiempo del mismo.
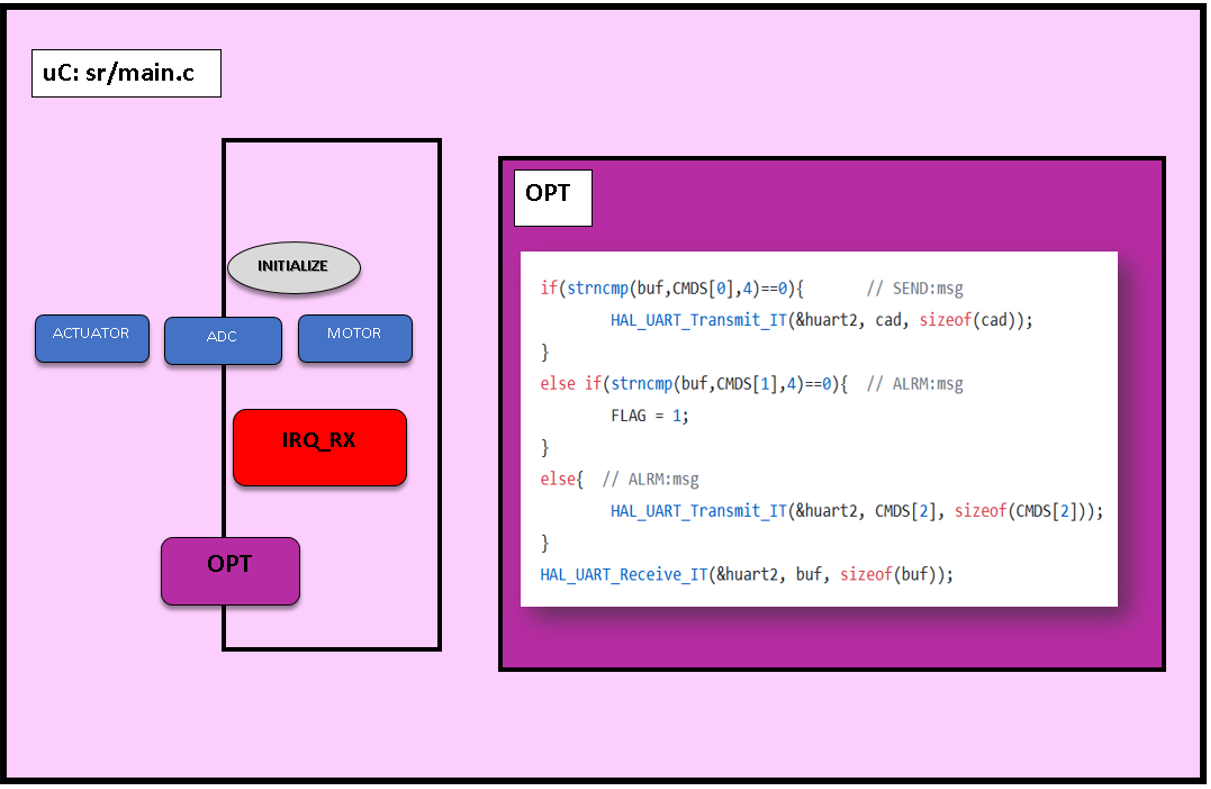
Se trata de un proyecto aparentemente simple, pero que detrás de todo existe un ecosistema muy complejo al que se le quería meter mano. Solo hay que ver la arquitectura de la infraestructura que ha quedado:
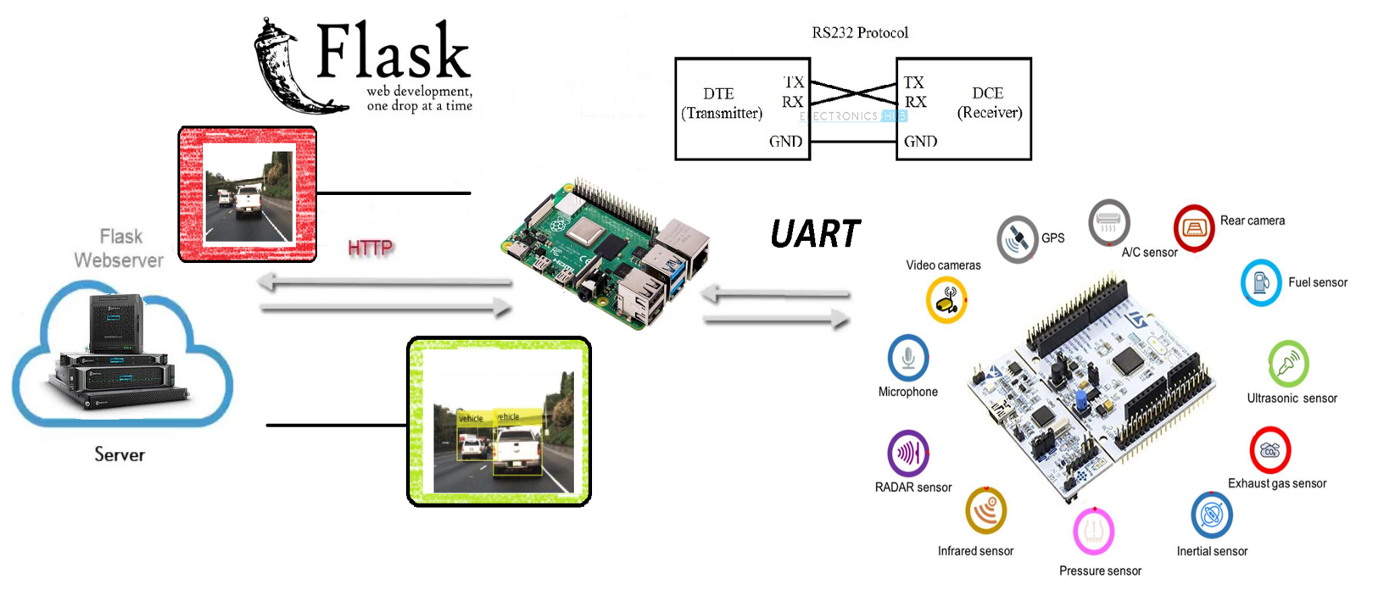
Aunque el objetivo era aplicar temas de Machine Learning, estos temas requieren de una determinada arquitectura y funciones para comunicaciones, tratamiento de imágenes etc. El tema de SLAM + ML se ha quedado a las puertas pero sí se han dado pasos para poder continuar con la misma.
Y a la larga, el objetivo que se había planteado que era aplicar esta tecnología al mundo real aparte de la IT y darle una aplicación más industrial, creemos que aunque no se haya logrado, se está un paso más cerca con el uso de estas “herramientas caseras”.
Como reflexión obtenido, hemos detectado que si se va a empezar a usar el Cloud Computing, para las próximas generaciones hará falta un cifrado de la información muy densa que se envíe (aunque se sacrifique la latencia), ya que es un tema muy serio al que poca importancia se le está dando actualmente.
Hemos detectado diferentes tareas como trabajo futuro de cara a este proyecto:
En el siguiente repositorio se encuentra el código usado para desarrollar esta aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Donostia/Donostia2020/Impure_Detector-main
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!