Comparar dos IAs programando no consiste solo en ver quién escribe mejor código. En la práctica, la diferencia más relevante aparece en cómo entienden una tarea abierta, cuánto contexto necesitan, qué decisiones toman cuando algo no está completamente especificado y cómo reaccionan a las correcciones.
Para demostrarlo, he realizado un experimento: he clonado FoodCheck, una app publicada en GitHub Pages, manteniendo la misma lógica de negocio y la misma interfaz. Este es el resultado.
El reto tenía la condición de que la app tenía que ser 100% estática. GitHub Pages no ejecuta servidores, no maneja variables de entorno del lado del servidor ni permite un backend tradicional.
La misma aplicación, dos IAs:
- Codex (modelo gpt-5.1-codex-max), mi anterior asistente para desarrollar la app original.
- MiniMax M2.1 (Chat-Agent), con quien he intentado replicarla simplemente dándole la URL para que la analizara.
El contraste entre ambos estilos fue más interesante de lo que esperaba.
FoodCheck como caso de estudio
FoodCheck no es solo una interfaz donde subes una foto y salen números. Por debajo hay decisiones de arquitectura críticas:
- Visión artificial avanzada capaz de interpretar platos complejos, no solo objetos aislados.
- Datos nutricionales y reglas que dependen del perfil de salud del usuario.
- Persistencia local (registro diario) sin base de datos.
- Despliegue estático obligatorio en GitHub Pages.
Estas restricciones no son detalles técnicos, son el producto. Y aquí es donde la forma de trabajar de cada IA marca la diferencia.
Codex como copiloto: muy potente, pero necesita tareas bien acotadas

Con Codex (gpt-5.1-codex-max) la sensación general fue la de tener un copiloto sólido. Con un matiz: si no divides el trabajo en tareas muy específicas, tiende a dar más rodeos. Y además, cuando la app crece, a veces se olvida de lo que hizo varios mensajes atrás y hay que volver a explicarle el contexto.
No es que se equivoque, sino que tiende a dispersarse si no le guías: necesita que dividas el problema en pasos más concretos, puede proponer soluciones intermedias que no encajan del todo con el despliegue final, y a veces insiste en patrones estándar del desarrollo web aunque choquen con las restricciones previas.
En mi caso, esto se notó especialmente en dos puntos: la detección de alimentos y la adaptación a una app estática.
La detección simulada como punto de partida
Igual que me ocurrió después con MiniMax, el punto de partida fue una detección ficticia simplificada, suficiente para que la UI y el flujo funcionen pero no aceptable si el objetivo es un análisis real de platos.
Aprendí que, si no insistes, la IA prefiere cerrar primero el producto visible y ya luego afinar el corazón técnico.
Llegar a una solución viable para GitHub Pages llevó iteraciones
Codex fue proponiendo ideas que en un entorno general de desarrollo web son normales (por ejemplo, configuraciones estilo .env o piezas propias de un backend). Pero en GitHub Pages eso es inviable.
Hizo falta iterar hasta aterrizar en una solución compatible con una app estática, donde la parte inteligente vive fuera del frontend (por ejemplo, vía servicios externos).
Iniciativa conservadora
Al no haberle dado una indicación explícita sobre la base de datos nutricional a utilizar, Codex optó por una base de datos local muy reducida, con valores nutricionales introducidos manualmente para unos pocos alimentos. Desde el punto de vista del desarrollo incremental, esta decisión tiene sentido, ya que permite avanzar sin dependencias externas y validar el flujo completo de la aplicación.
Sin embargo, también muestra el patrón de Codex como copiloto, tendiendo a elegir soluciones seguras si no se le fuerza a ampliar el alcance. La integración con una base de datos real como OpenFoodFacts no surgió por inferencia de dominio, sino solo cuando se le indicó de forma explícita. Codex no se equivoca, pero tampoco asume contexto de producto si no se le pide.
MiniMax M2.1 como agente: rapidez, foco y buena inferencia de contexto

Con MiniMax M2.1 el enfoque fue distinto desde el principio. Lo utilicé directamente para replicar FoodCheck.
La diferencia se vio enseguida, ya que en apenas unos minutos fue capaz de:
- Hacer una primera lectura visual y lógica del producto original.
- Crear la carpeta y los archivos (index.html, styles.css, app.js, README.md).
- Desplegar una versión inicial funcional.
Y él solo se corregía sin que yo llegara a ver el error, solo veía el resultado final funcionando.
Base de datos nutricional sin instrucciones explícitas
Un detalle clave es que no tuve que mencionar OpenFoodFacts. El agente lo incluyó por iniciativa propia como fuente de datos nutricionales, demostrando una capacidad de inferencia superior sobre “qué necesita una app de este tipo”.
Del token en el frontend al diseño correcto del sistema
Al integrar LLaVA vía Cloudflare, MiniMax propuso inicialmente que el usuario introdujera su API token en la app. Es una solución rápida, pero muy mala desde el punto de vista de experiencia de usuario.
Cuando se le pidió una alternativa, el agente dio un salto importante: propuso un Cloudflare Worker como proxy para guardar el token de forma segura y mantener el frontend completamente estático.
En la práctica, este fue el punto donde MiniMax mostró más instinto de sistema y mayor capacidad para cerrar una solución completa de producto, no solo de código.
El punto débil de MiniMax: la fidelidad de la interfaz
Sin embargo, esta autonomía que brilló en el backend, fracasó en el frontend. Donde MiniMax M2.1 no consiguió cerrar el objetivo fue en la replicación exacta de la interfaz.
Aunque intentó replicar exactamente el diseño y llegó a desplegar versiones afirmando que lo había conseguido, seguía habiendo diferencias. Y esto conecta con una realidad práctica, y es que “parecido” es fácil, pero “idéntico” es más complejo.
Un agente puede aproximar estilos, pero para clonar una interfaz de forma fiable suele necesitar acceso directo al CSS original, assets y una validación visual metódica (capturas comparativas, inspección de estilos, etc.). Sin eso, se queda en “muy similar” rellenando los huecos de diseño con su propia imaginación.
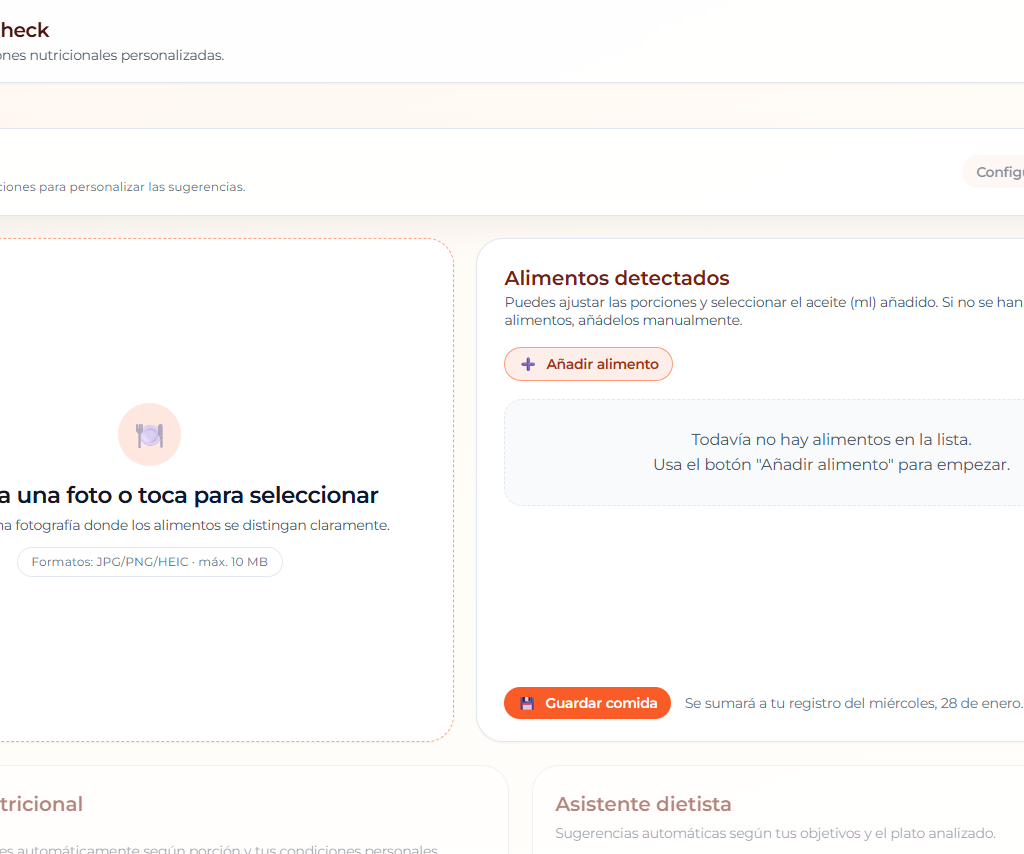
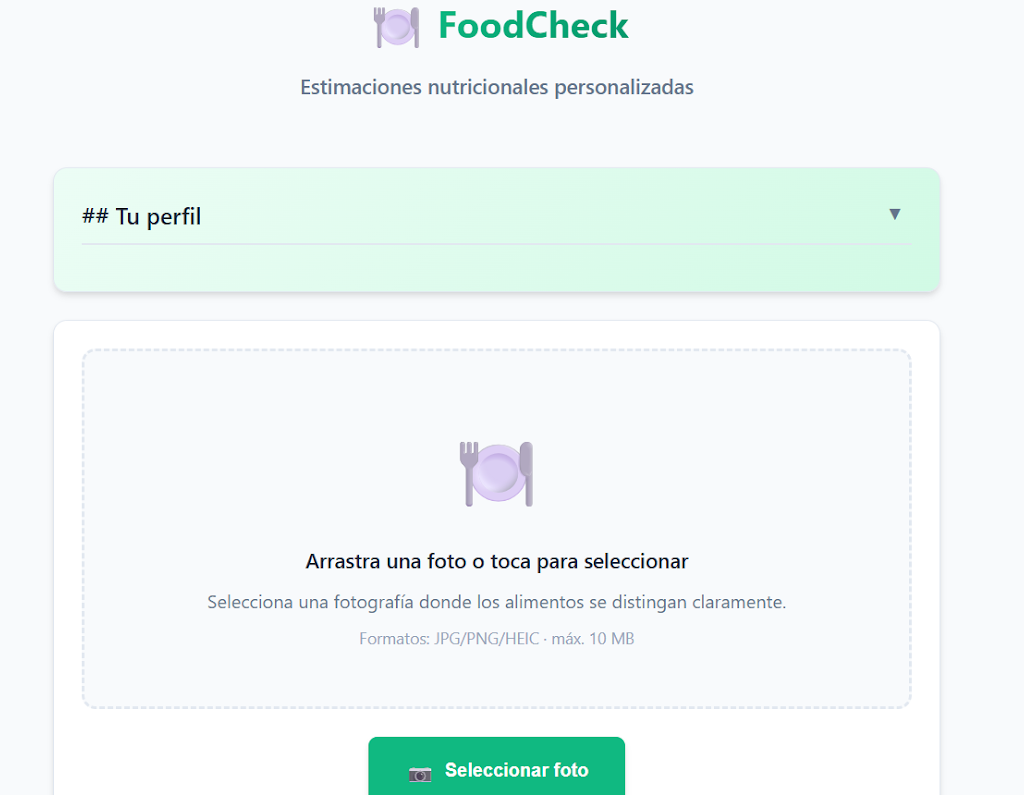
El tropiezo compartido con el «mínimo viable»
A pesar de sus diferencias, ambas IAs cayeron en la misma trampa al inicio: la detección simulada o simplificada. Pero esto no es un error raro, es un patrón. Se construye el “cascarón” del producto, y luego se conecta el motor real.
Tanto Codex en su momento como MiniMax después propusieron por defecto usar TensorFlow.js + COCO-SSD. El problema es que COCO-SSD detecta tan solo ciertos alimentos concretos, pero no detecta alimentos de un plato de comida normal. Para una app de comida, eso es inútil.
Esto nos enseña una lección, y es que la IA tiende al camino de menor resistencia técnica. Prefiere cerrar el producto visible con una librería estándar antes que buscar la solución compleja (modelos multimodales) que realmente se necesita. Tuve que intervenir en ambos casos para forzar el uso de visión real.
Qué aporta Codex que MiniMax no
La principal fortaleza de Codex no es la velocidad ni la autonomía, sino el control. Cuando el desarrollador tiene claro el diseño, las restricciones y el resultado esperado, Codex se comporta de forma más predecible y menos creativa en el mal sentido. Rara vez inventa arquitectura, fuentes de datos o flujos no solicitados si se le han dado las órdenes correctas.
Esto reduce el riesgo de soluciones elegantes pero incorrectas desde el punto de vista del producto. El coste es que exige más trabajo previo: descomponer el problema, anticipar restricciones y guiar activamente el camino. Codex no suele cerrar el sistema por ti, pero respeta mejor lo que tú defines como correcto.
Qué aporta MiniMax que Codex no
MiniMax M2.1 destaca cuando el problema es abierto y el objetivo es tener algo completo funcionando lo antes posible. Toma la iniciativa para que el código sea una solución de mercado y no una estándar basada en lo que la mayoría de desarrolladores hace. Su capacidad para inferir contexto (como elegir OpenFoodFacts sin indicación explícita o proponer un Worker como proxy seguro) demuestra un mayor instinto de producto y de sistema.
Esta autonomía acelera enormemente las primeras fases, pero introduce un riesgo. El modelo tiende a decidir qué es suficientemente bueno si no se le dan métricas claras. MiniMax no espera a que definas todos los detalles, los asume. Eso lo convierte en un generador de soluciones, pero en un asistente que necesita auditoría constante cuando la fidelidad importa.
Además, MiniMax parece ser mejor detective. Si el código falla, MiniMax suele mirar el error y proponer una solución que arregla el problema actual e incluso problemas futuros que uno aún no ha visto. Codex suele limitarse a arreglar solo lo que le pides.
Conclusión: dos estilos de IA, una misma responsabilidad humana
Este experimento deja una reflexión clara, y es que hoy en día, con IAs, hacer que una app exista es barato. En minutos puedes tener archivos, pantallas, incluso un flujo completo desplegado. Lo complejo empieza cuando tu objetivo no es simplemente que funcione, sino que sea exactamente lo que tú quieres.
Las dos IAs, de maneras distintas, rellenaron huecos. Si no defines con precisión cómo debe ser la arquitectura, proponen una. Si no delimitas qué significa “visión de platos complejos”, te ofrecen el modelo más a mano. Y si no instrumentas la fidelidad visual, te entregan una interfaz “bastante parecida” y la dan por buena.
Por eso, la IA es el motor de aproximación, pero el desarrollador es el sistema de medida. Y medir no es solo pasar tests unitarios. En productos como FoodCheck también significa comprobar que el despliegue cumple restricciones (GitHub Pages, sin backend), validar integración (tokens, CORS, endpoints, “Failed to fetch”), y tener un criterio tangible para lo subjetivo (qué es “idéntico” en una interfaz).
Si hay que destacar alguna diferencia práctica entre ambos modelos, podría decir que con Codex el trabajo humano se concentra al inicio, definiendo bien tareas, restricciones y arquitectura. Con MiniMax, el esfuerzo se desplaza al final revisando decisiones, detectando supuestos incorrectos y validando que tienes realmente lo que querías.
Ninguno elimina el trabajo del desarrollador; simplemente lo mueve de sitio. Elegir uno u otro no es tanto una cuestión de potencia del modelo como de en qué fase prefieres invertir tu atención. Pero en ambos casos, el resultado final depende menos del modelo que de la claridad con la que el desarrollador define qué cuenta como éxito.
En cualquier caso, quizá la enseñanza más interesante de todas es que cuando tienes un asistente que programa rápido, el trabajo se desplaza. Ya no es tanto escribir código, sino definir con precisión qué cuenta como correcto. Porque, si no lo defines tú, lo definirá la IA… y lo hará a su manera.