Guadalajara. Tercera Edición. 2021
Nuesta experiencia Saturday.AI
Nuestro equipo está formado por 5 personas de diversas áreas profesionales y niveles de experiencia, además de distintos lugares de origen, lo cual enriqueció aún más nuestro proyecto debido a los diferentes puntos de vista. Nuestro proyecto fue nombrado Moody.AI

Integrantes:
Raúl Sandoval
Karla Ramírez
Aldo Álvarez
Israel Castillo
Jaime Chacoff
Cuando se creó el equipo cada integrante dió su propuesta de proyecto, debido a que todos estábamos muy interesados en el procesamiento de imágenes se seleccionó el proyecto que involucraba este tema. El cual se trataba de reconocimiento de emociones faciales, basándonos en la primicia de que incluso nosotros éramos víctimas de las clases virtuales, decidimos que un buen enfoque sería la educación; ya que los niños son un sector más vulnerable se decidió enfocarnos en ellos.
En un inicio el proyecto estableció crear una herramienta que permitiera detectar, en una fase temprana, las emociones negativas de los niños durante clases virtuales ya que sería de gran ayuda para las autoridades de las escuelas y para los padres de los niños.
Sin embargo, revisando el tema más a fondo nos topamos con ciertas barreras, como el hecho de que no teníamos un dataset especializado en niños, el que se iba a necesitar consentimiento explícito de los padres para poder capturar imágenes de sus rostros, entre otras cosas.
Al continuar investigando los efectos de la pandemia y las comunicaciones virtuales descubrimos que el impacto también es significativo en los adultos trabajando remotamente (home office).
Considerando que también podíamos tener un impacto social significativo al enfocar el proyecto en adultos, se decidió cambiar el enfoque del proyecto y orientarlo a la detección de emociones en los adultos que están viviendo la modalidad del trabajo remoto (home office).
También influyó el hecho de que los datasets disponibles en Internet en su mayoría son de adultos. De igual manera un aspecto importante fue la posibilidad de hacer pruebas con los rostros de los integrantes del equipo (todos mayores de edad) y cuya participación fue voluntaria.
En conclusión se trabajó en un modelo para la detección de emociones por medio de la expresión facial, para adultos trabajando remotamente (home office). Se tuvo un enfoque en las emociones negativas, para que esta herramienta ayude a las áreas de recursos humanos de las empresas a detectar el estado de ánimo en el ambiente laboral y que con dicha información puedan tomar las acciones necesarias.
Introducción
NOM-035-STPS-2018: tiene el objetivo de establecer los elementos para identificar, analizar y prevenir los factores de riesgo psicosocial, así como para promover un entorno organizacional favorable en los centros de trabajo.
Hoy en día, lo que necesita la salud emocional es más atención, visibilidad y menor estigma. Para ello, se propuso el uso de la Inteligencia Artificial en proyectos con impacto social positivo, considerando como factor el estar viviendo en tiempo de pandemia.
En un inicio el proyecto estableció contar con una herramienta que permitiera detectar, en una fase temprana, las emociones negativas de los niños durante clases virtuales ya que sería de gran ayuda para las autoridades de las escuelas y para los padres de los niños.
Al considerar que podemos tener un impacto social más amplio al incluir adultos en este proyecto, y tomando en cuenta que para utilizar los rostros de menores de edad es necesario contar con un consentimiento de los padres o tutores, se decidió cambiar el enfoque del proyecto y orientarlo a la detección de emociones en los adultos que están viviendo la modalidad del trabajo remoto (home office).
Problemática
Debido a la pandemia mundial del COVID-19, la población ha tenido que permanecer en cuarentena por más de un año. Un porcentaje significativo de empresas han implantado el trabajo remoto para no frenar las operaciones durante la pandemia. Ahora el trabajo se realiza en modalidad de “oficina en casa”, lo cual ha generado problemas que han afectado a los colaboradores en trabajo remoto. Entre estos problemas se destaca la falta de convivencia con los colegas de trabajo, la falta de distancia entre la vida personal con la vida laboral, y la ansiedad debido a la incertidumbre y el confinamiento. Todos estos problemas terminan reduciendo la estabilidad emocional de un individuo, lo cual llega a tener grandes repercusiones en su rendimiento y bienestar general.
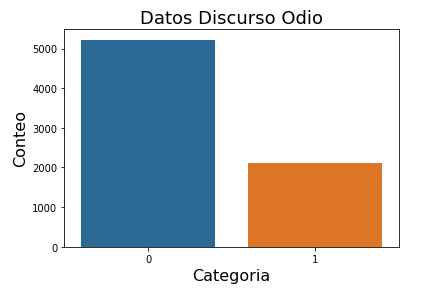
Existen estudios psicológicos y sociales que resaltan el enorme impacto negativo que puede tener la pandemia en la estabilidad mental de un individuo. De esta forma, se considera que es de gran ayuda que las empresas estén alertadas para visualizar en tiempo real las emociones negativas detectadas en sus colaboradores, las cuales pueden ser: tristeza, enojo, miedo o disgusto. Con esto, se haría una detección preliminar de comportamientos emocionales negativos, la cual servirá como una primera guía para darle seguimiento al caso con una consulta profesional.
Dataset
Se utilizó un set de datos existente y de acceso libre en línea, el cual fue creado por Pierre-Luc Carrier y Aaron Courville como parte de un proyecto de investigación [3]. En este archivo se clasifican expresiones faciales de 35,685 imágenes. Cada imagen tiene un tamaño de 48×48 píxeles en escala de grises y está recortada de modo que únicamente se incluya la cara de una sola persona. Cada cara en el set de datos está clasificada con base en las expresiones faciales. Las clases en las que se dividen las expresiones son: felicidad, neutral, tristeza, enojo, sorpresa, disgusto y miedo.
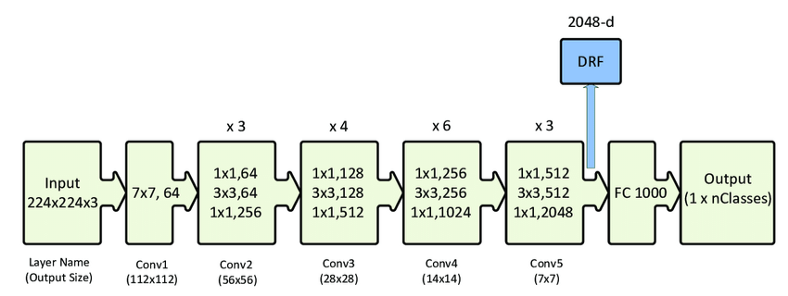
Modelo
Todas las capas se han organizado de manera secuencial utilizando TensorFlow 2.5 y Keras. La red se asemeja a una red convolucional del tipo VGG-16 con varias capas convolucionales CONV, manteniendo el padding y siempre con un kernel de 3×3 excepto en las 2 primeras capas convolucionales que tienen un kernel de 5×5.
Además, capas de MaxPooling entremedio de las CONV para la reducción espacial pero manteniendo la información relevante de la imagen. Para prevenir overfitting, se han añadido capas de BatchNorm y Dropout como regularizadores.
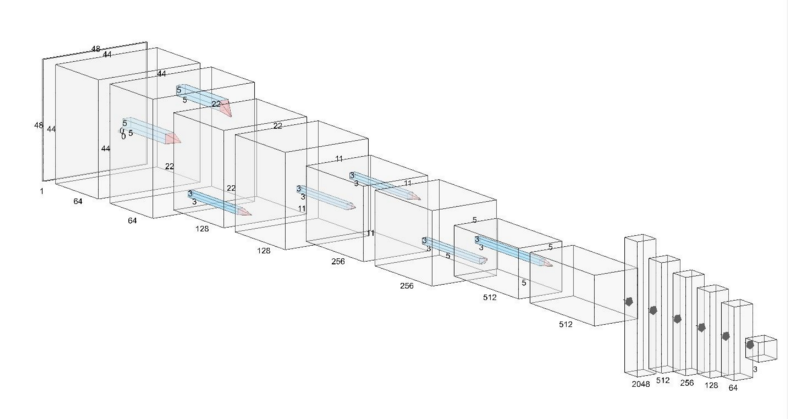
Cada capa convolucional tiene una activación ReLU (Rectified Linear Unit) para que valores negativos no sean transferidos a la siguiente capa.
Después de las capas convolucionales, vienen las capas densas, para eso, se aplasta (flatten) la matriz resultante de las capas convolucionales para seguir hacia 4 capas densas con una activación ReLU y una última capa densa, con el número de parámetros igual al número de clases, con una activación softmax. La última capa softmax entregará valores entre 0 y 1, que corresponden a la probabilidad de cada una de clases.
El optimizador que se ha utilizado es ADAM.
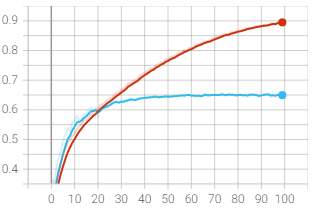
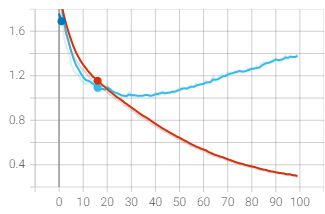
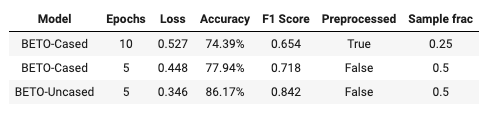
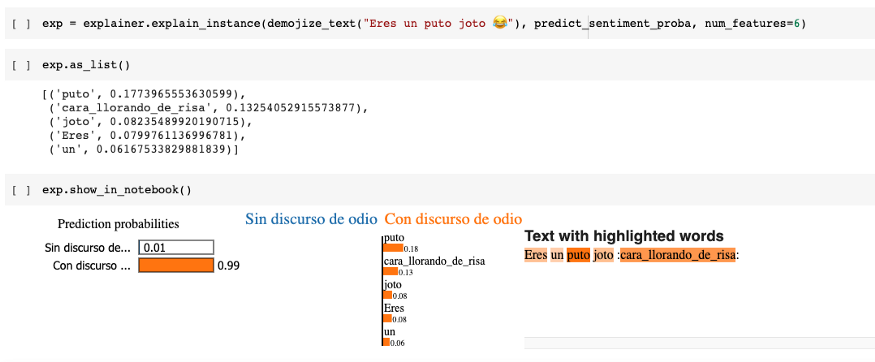
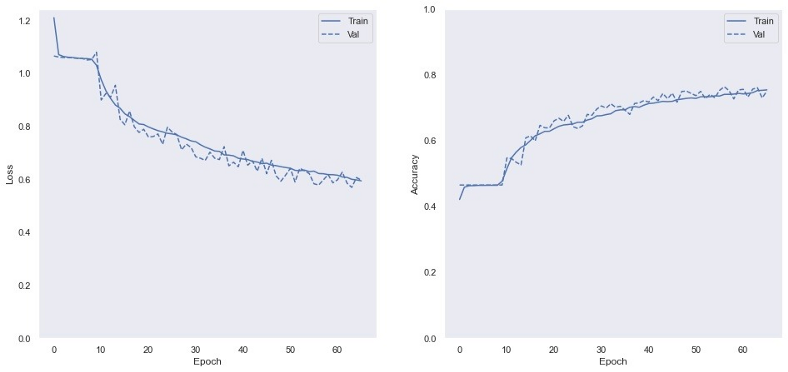
Resultados
Conclusiones
Con el producto final se obtiene un algoritmo capaz de hacer un análisis del tipo de emociones que predominan en cada usuario por medio del material visual que se le proporciona, haciendo especial énfasis en alertar la prevalencia de emociones negativas. Con el análisis especializado del perfil emocional de cada usuario, los miembros de la empresa encargados de monitorear el bienestar de los trabajadores tendrán la oportunidad de dar un seguimiento a las alertas de usuarios que podrían estar padeciendo algún problema emocional durante sus jornadas de trabajo. Brindar este tipo de atención personalizada a los miembros de la empresa puede resultar crucial para mejorar el rendimiento y la satisfacción laboral de cada individuo, así como su calidad de vida.
Creemos que podemos ayudar bastante a los departamentos de Recursos Humanos para poder asegurar que los colaboradores tengan la mejor predisposición posible, así como la mayor salud emocional que podamos darles. Es una herramienta que permite mejorar la atención de las personas que trabajan en vez de solo enfocarse en su performance laboral. Es una forma de aceptar que el bienestar emocional de las personas produce un cambio en como trabajan y como se desarrolla el espacio en donde se desenvuelven profesionalmente.
Proyección a futuro
Estamos seguros de que esta primera versión de Moody.ai es perfectible y expandible a versiones más sofisticadas y con enfoques diferentes. Entre las ideas que han surgido en el equipo para versiones posteriores de Moody.ai están las siguientes aplicaciones:
- Automatizar la detección de emociones y disparar eventos con base en estas detecciones. Por ejemplo, el identificar, en tiempo real, rostros de conductores de transporte cansados, parpadeando con más frecuencia de lo normal, bostezando, etc.
- Detección de emociones de los colaboradores en temas específicos tratados en los ambientes de trabajo remotos y que las empresas lo identifiquen de manera temprana.
- Identificar, en tiempo real, de forma temprana a personas con emociones negativas desempeñando actividades potencialmente riesgosas: operadores de maquinaria, personal en líneas de producción, trabajadores de la construcción, etc.
Consideramos que el seguir desarrollando a Moody.ai podría alcanzar un impacto social sin límites. Esta herramienta es fácil de adaptar al contexto donde necesite ser implementada y conforme crezca la red se obtendrá un modelo cada vez más robusto que será capaz de hacer predicciones más certeras.
Presentación del proyecto: DemoDay
Repositorio
En el siguiente repositorio se encuentra el código usado para desarrollar esta aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Guadalajara/March2021/EmotionsDetector-main
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) a la vez que se realizan proyectos para el bien (#ai4good). Los talleres que realizamos forman parte del programa AI 4 Schools para que cualquier persona “aprenda haciendo” IA sin importar su especialidad o nivel de partida.
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en este link o visítanos en nuestra web www.saturdays.ai ¡te esperamos!

WRITTEN BY