A lo largo de la lectura exploraremos la transformación de la educación a través de la integración de inteligencia artificial y hologramas. Este artículo profundiza en cómo estas tecnologías están redefiniendo las metodologías de enseñanza para adaptarse a las necesidades de una generación digital. Aborda los retos y oportunidades presentes en la implementación de estas innovaciones en el aula, destacando la importancia de mantener un equilibrio entre los avances tecnológicos y la interacción humana esencial en el proceso educativo. Además mostramos casos donde la inteligencia artificial se usa junto con los hologramas para mejorar la sociedad.
Bienvenidos a la Clase del Futuro
Adiós a la escuela aburrida
Innovación en cada lección
Un mundo sin fronteras
No más distracción digital
IA y Hologramas al Rescate
¿Alguna vez te has preguntado cómo sería aprender historia con un paseo holográfico por las pirámides de Egipto? o ¿Resolver ecuaciones matemáticas con un profesor IA que nunca pierde la paciencia?.
Bueno, prepárate, porque la educación está a punto de recibir un cambio de imagen al estilo de ciencia ficción.
En esta nueva era educativa, la fusión de la inteligencia artificial (IA) y los hologramas está revolucionando la enseñanza y el aprendizaje. Las aulas, antes dominadas por pizarras y libros, ahora se están transformando en espacios donde la tecnología avanzada es esencial.
Imagina lecciones de historia donde los hologramas dan vida a personajes y eventos, y la IA personaliza la enseñanza para cada estudiante, mejorando la comprensión y la retención.
Un Mundo Sin Fronteras... Literalmente
Programas como el Código Escuela 4.0 en España están integrando habilidades digitales cruciales en el currículo, preparando a los estudiantes para el futuro y fomentando habilidades como el pensamiento crítico. Estas tecnologías también abren puertas para democratizar la educación, permitiendo a estudiantes en áreas remotas acceder a la misma calidad educativa encontrada en zonas más privilegiadas.
No obstante, estos avances traen desafíos como la brecha digital y la reducción de la interacción humana, aspectos que requieren atención cuidadosa. La IA y los hologramas ofrecen una experiencia de aprendizaje más rica y envolvente, pero es crucial garantizar una transición equitativa. Estamos al umbral de una transformación educativa, donde la enseñanza se convierte en una experiencia más eficiente y estimulante. La escuela del futuro promete ser un espacio transformador y emocionante, adaptado a las necesidades de una generación cada vez más digital.
Esta revolución tecnológica en la educación llega en un momento crucial, donde los jóvenes, acostumbrados a una constante estimulación visual y acceso rápido a la información, enfrentan retos en concentración y retención de memoria. La IA y los hologramas, con su capacidad de crear entornos de aprendizaje interactivos y visuales, ofrecen una solución a estos problemas. Estas herramientas no solo hacen las lecciones más atractivas, sino que también están diseñadas para adaptarse a las preferencias y estilos de aprendizaje de la generación digital, mejorando la concentración y la comprensión del material.
De ciencia ficción a la Realidad
Aunque aún no se han materializado los hologramas impulsados por inteligencia artificial, su incorporación en nuestro entorno está al alcance. Para el año 2024, se planea implementar un proyecto del Ministerio del Interior y la Guardia Civil, el cual incluye el lanzamiento de guardias civiles virtuales. Estos agentes digitales avanzados, creados con inteligencia artificial, tienen el propósito de compensar la falta de personal en áreas rurales y ofrecer soluciones efectivas en lugares con limitada presencia de la Guardia Civil. Con un presupuesto de 500.000 euros, se proyecta establecer 10 de estos agentes virtuales que no solo interactuarán y brindarán información clave a la ciudadanía, sino también analizarán grandes volúmenes de datos y anticiparán tendencias para reforzar la seguridad. Estos agentes virtuales tendrán la capacidad de reconocer y adaptarse a la voz, idioma y emociones de los usuarios, enriqueciendo la interacción con la población.
El Futuro es Ahora
Aunque este ejemplo de la unión de la inteligencia artificial con hologramas no pertenezca al ámbito de la educación, representa un gran paso hacia la integración de estas tecnologías en nuestra vida cotidiana. Demuestra cómo la IA puede ser aplicada para mejorar servicios esenciales y resolver problemas complejos. Este avance sienta un precedente para futuras aplicaciones en otros sectores, como la educación, donde la IA tiene el potencial de personalizar el aprendizaje, facilitar el acceso a recursos educativos y mejorar la interacción entre estudiantes y maestros. Es un claro indicio de cómo la IA puede transformar diversos aspectos de la sociedad, ofreciendo soluciones innovadoras y eficientes para desafíos tanto actuales como futuros.
Mientras nos adentramos en una era de educación transformada por la tecnología, es esencial abordar tanto las oportunidades como los desafíos. La clave será encontrar un equilibrio entre la utilización de estas tecnologías avanzadas y el mantenimiento de la interacción humana vital en la educación. La escuela del futuro, equipada con herramientas como la IA y los hologramas, promete ser un espacio donde el aprendizaje es no solo eficiente y accesible, sino también emocionante y profundamente enriquecedor, preparando a los estudiantes para un mundo en constante cambio.
Visita nuestras RRSS
¡Tenemos un cuento que nos habla de la IA y los Hologramas!
He creado un minijuego interactivo llamado Pokémon Quiz. La idea surge para combinar mi afición por los clásicos Pokémon con un poco de programación en
En el mundo de la inteligencia artificial aplicada a la educación, dos nombres destacan por su capacidad para ayudar a los estudiantes: DeepSeek-R1 y ChatGPT-o1.
¿Lovable o Bolt? Descubre cuál de estas herramientas impulsadas por IA es la ideal para desarrollar tu próxima web app con Supabase. En este artículo, comparo ambas opciones mientras construyo una app para el manejo de medicamentos. ¡Explora sus diferencias y encuentra la mejor para ti!
La Inteligencia Artificial está transformando la industria farmacéutica, acelerando el descubrimiento de medicamentos, personalizando tratamientos y optimizando procesos. En este artículo exploramos cómo gigantes como AstraZeneca, Pfizer y Johnson & Johnson están liderando esta revolución tecnológica que promete cambiar para siempre la forma en que tratamos las enfermedades. ¡Descubre el futuro de la medicina impulsado por IA!
¿Sabías que una herramienta como ChatGPT puede facilitarte la vida académica en el bachillerato? Desde crear ejercicios personalizados y resolver problemas paso a paso, hasta ayudarte con ensayos, idiomas y planificación de estudios. En este artículo, te contamos cómo aprovechar al máximo sus funciones para destacar y reducir el estrés.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible #ai4all mediante cursos y programas intensivos donde se realizan proyectos para el bien #ai4good. También realizamos proyectos y consultoría para organizaciones que quieren sacar el máximo partido de la IA.
Si como nosotros te gusta la tecnología, hazte miembro premium de Saturdays y podrás aprovechar todos los beneficios de una comunidad líder en Inteligencia Artificial: https://saturdays.ai/become-a-member
En nuestra web tienes cursos online gratuitos y contenido para ayudarte, así como una comunidad de personas apasionadas como tú, ¡te esperamos!
En la actualidad, el hostigamiento u acoso sexual online es conocido en el lenguaje anglosajón como grooming online; donde un adulto logra tener contacto a través de un medio tecnológico contra un menor de edad, siendo el objetivo del abusador atacar a través de interacciones como: acoso a su moral, hablar de sexo, conseguir material íntimo o acordar un encuentro sexual.
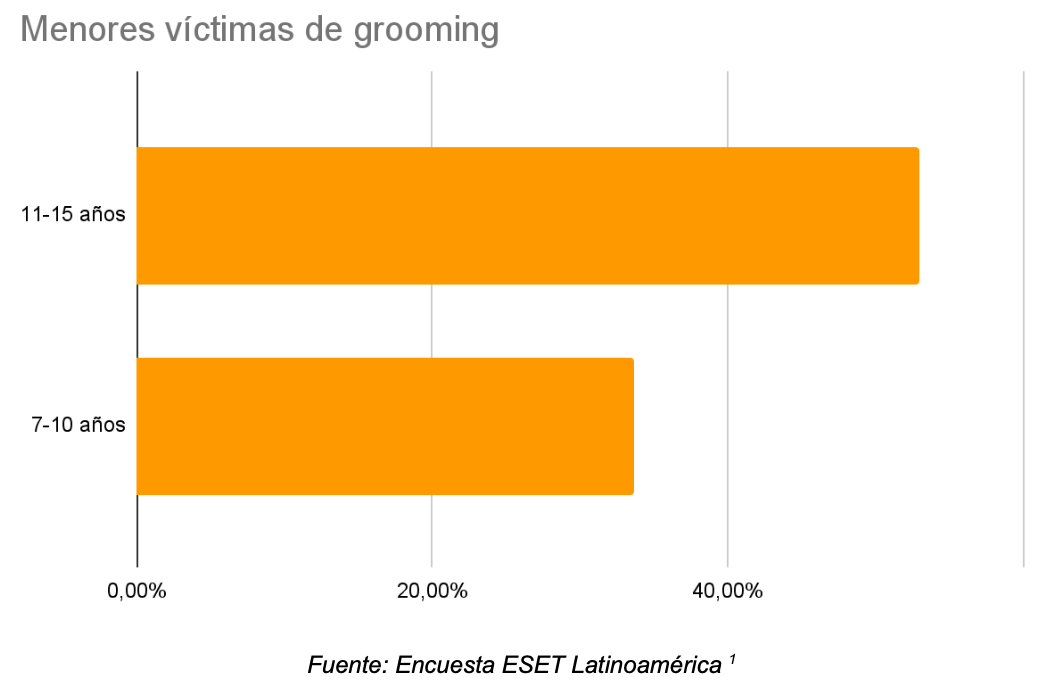
El grooming online se ha incrementado a raíz del confinamiento por el COVID-19. En Argentina aumentó más del 30% en el 2020(2), en datos del INEGI del 2019 arrojan que en México creció el 27%(3) , mientras que el diario ABC de España, reportó un incremento del 410% en los últimos años (4).
Contexto… please!
Los aplicativos actuales para el control parental recurren a bloqueos de aplicaciones, algunos sitios inapropiados, evitar compras online o el acceso de algún virus a los dispositivos como celulares, tablets o computadoras de niños y adolescentes. Sin embargo ninguno analiza conversaciones en redes sociales y tampoco clasifica las que puedan ser catalogadas como peligrosas.
Derivado del confinamiento por el COVID-19 los niños y adolescentes se han visto más vulnerables debido a la necesidad de utilizar los dispositivos móviles como parte de sus actividades diarias, gran parte de eso fue para tomar clases virtuales, realizar tareas y en otras ocasiones como medio de entretenimiento y comunicación, al verse limitados por no poder salir y compartir tiempo con familiares y amigos.
La nula supervisión ha permitido que menores de edad hayan experimentado situaciones indeseadas sin el conocimiento de los adultos.
De acuerdo al sitio salud con lupa, el 39% de los acosos se han experimentado por Facebook, seguida por el 23% en Instagram y un 14% por WhatsApp (5).
La propuesta
Tótem significa protector
Tótem = “Déjalo Navegar sin Preocupaciones”
Sin tanto rollo, esto es lo que hicimos.
Actualmente contamos con un dataset de conversaciones en inglés, las cuales son analizadas y catalogadas como normales o peligrosas, una vez obtenido esté resultado se enviará una notificación al padre o tutor si se detecta una conversación inapropiada.
¡¿Cómo hicieron eso?!
Aquí te explicamos qué fue lo que aplicamos para obtener los resultados que te mostraremos más adelante…
Fase 1 (Aquí vamos…)
Obtención de los datos
Los datos fueron adquiridos del proyecto PAN Lab 20126. La carpeta con los datos fue solicitada y se nos concedió el permiso para usarla. Revisando la data nos encontramos con conversaciones de diversa duración, en las que los participantes tenían diferentes formas de escribir y el archivo del corpus que tenía un formato .xml. Por lo que se procedió con la conversión de la data a un formato .csv, “Comma Separated Values”, para poder proceder con la siguiente fase.
Fase 2 (Analicemos esto…)
Limpieza de datos
La segunda tarea presentó un grado de dificultad alto, debido al ruido de la data. Por lo tanto se siguieron los siguientes pasos.
Se eliminó cualquier tipo de puntuación.
Se convirtieron los números a palabras usando la librería num2words.
Se buscaron abreviaturas y textos con jergas cibernéticas como: “u” para “you”, “ur” para “your”, “what ‘s” para “what is”, entre otras. Además se creó un diccionario con estas palabras nuevas.
Se eliminaron las stopwords como: the, and, that, a, any, an, be, with. Entre otras.
Se eliminaron emojis, URL, hashtags y cualquier tipo de valor alfanumérico.
Se empleó la técnica de lematización, para llevar todos los verbos a su forma en infinitivo. Para así crear incrustaciones a partir de palabras más simples.
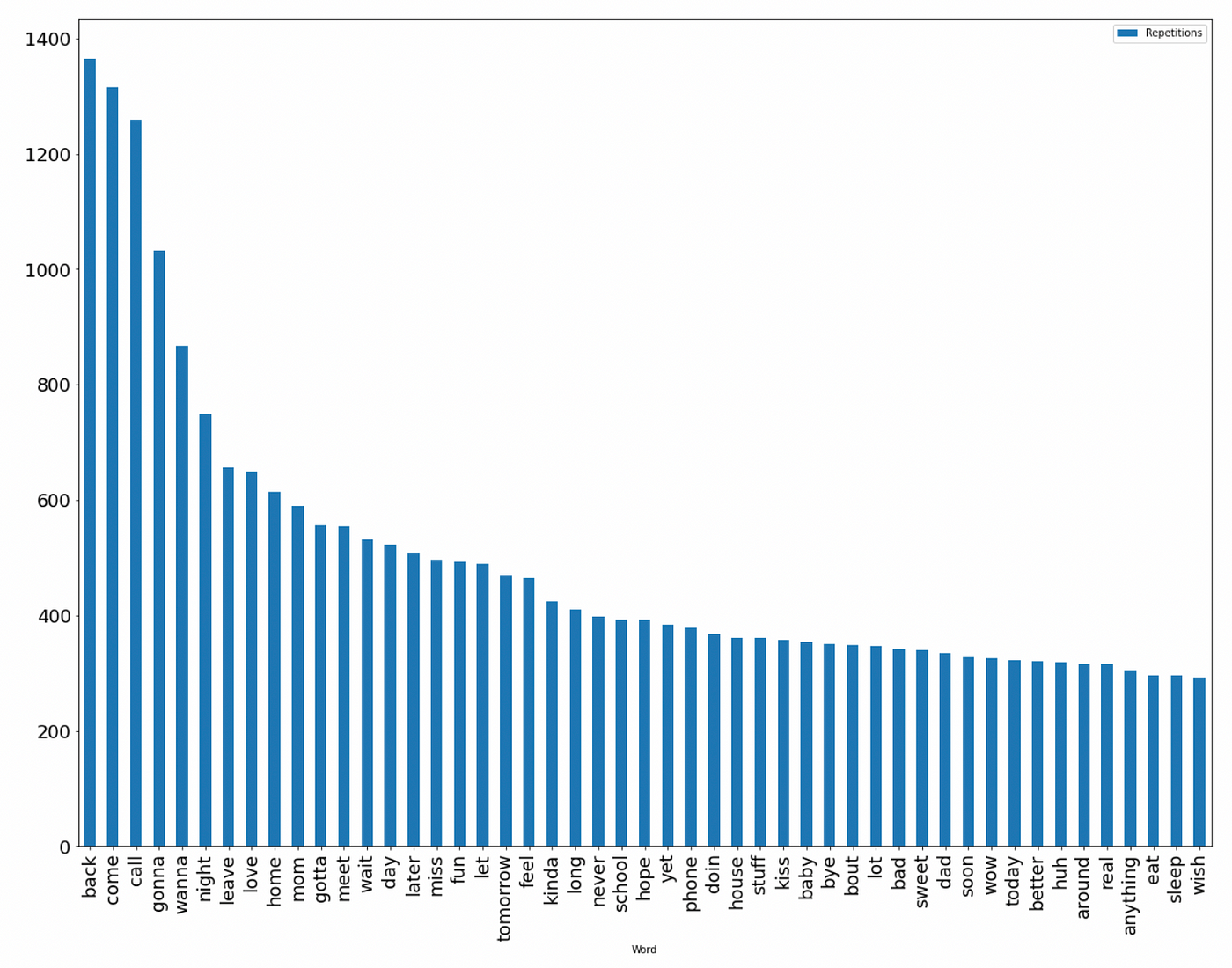
Se exploraron los datos, analizando las 100 palabras más comunes en las conversaciones de los predadores.
Fase 3 (Entrenemos esto…)
Vectorización
La extracción de características representó un desafío particular, en primera instancia se optó realizarlo con base a las palabras más frecuentes presentes en las conversaciones de depredadores; no obstante, varias de estas eran de uso común, por lo que fue necesario analizar alternativas para lograr un óptimo desempeño. Es así que se optó por el uso del método TF-IDF (Term Frequency — Inverse Document Frequency), siendo una de sus características el resaltar la importancia de una palabra en un conjunto de documentos (corpus). En ese sentido, para transformar la secuencia de palabras (provenientes de las conversaciones) a vectores de características con representaciones numéricas se usó el vectorizador TF-IDF (TfidfVectorizer) de la librería de scikit-learn. Este transformador permitió generar una matriz de características, con una representación adecuada para realizar el entrenamiento del modelo. Para dicho propósito, se dividió el dataset en:
Datos de entrenamiento: 80%
Datos de testeo: 20%
Entrenamiento
Para el entrenamiento del modelo se usó la librería scikit-learn y se escogió el modelo Support Vector Machines (SVM) para emplear un clasificador binario.
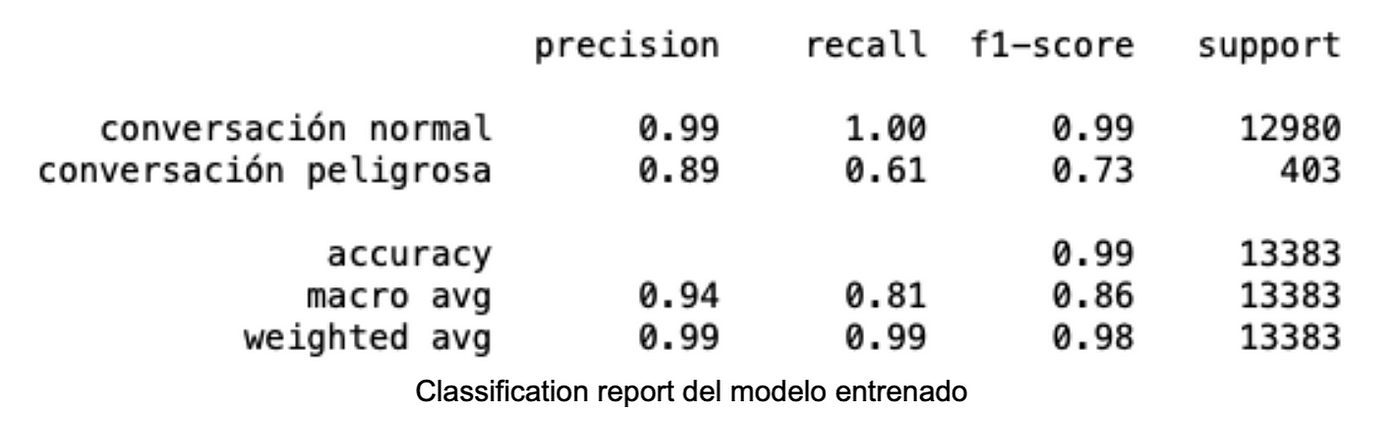
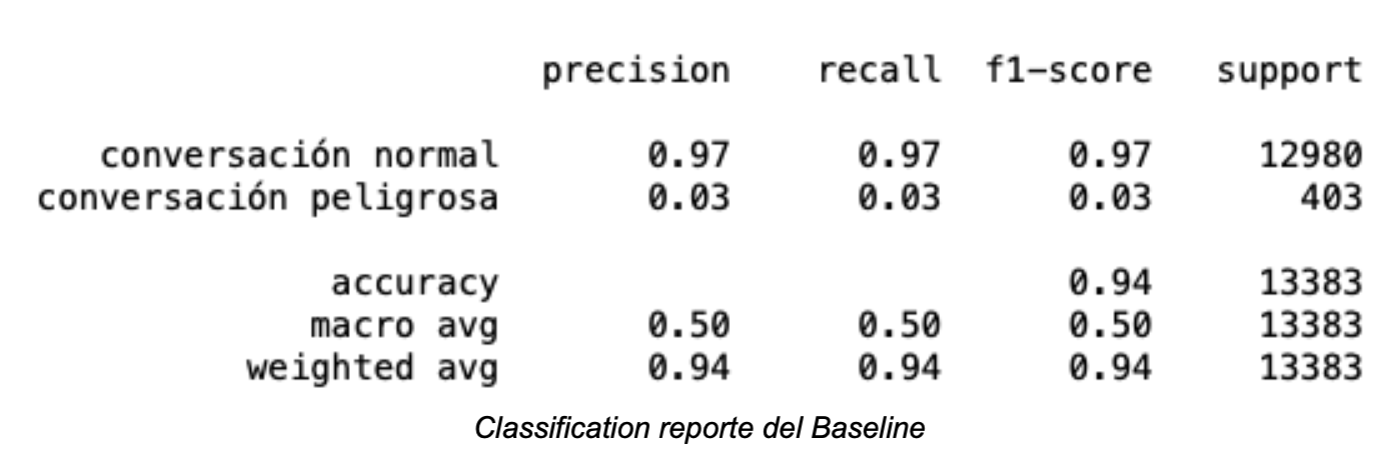
Durante la evaluación del modelo se obtuvieron los siguientes resultados:
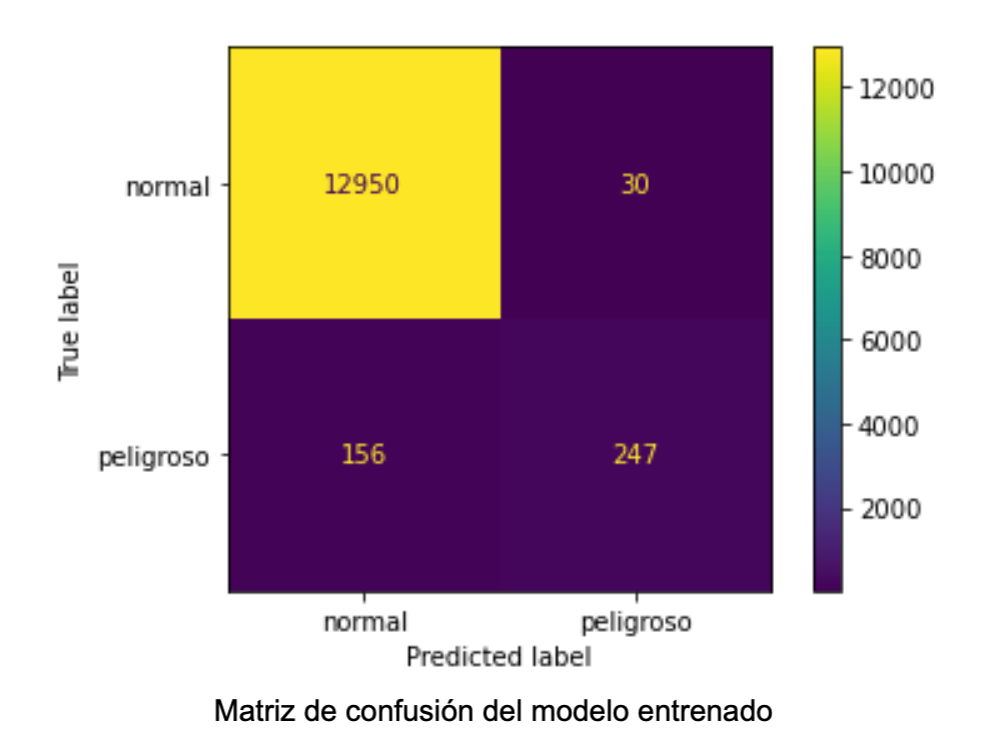
Siendo la matriz de confusión la siguiente:
Los resultados del modelo muestran una notable mejora en comparación a aquellos correspondientes al Baseline:
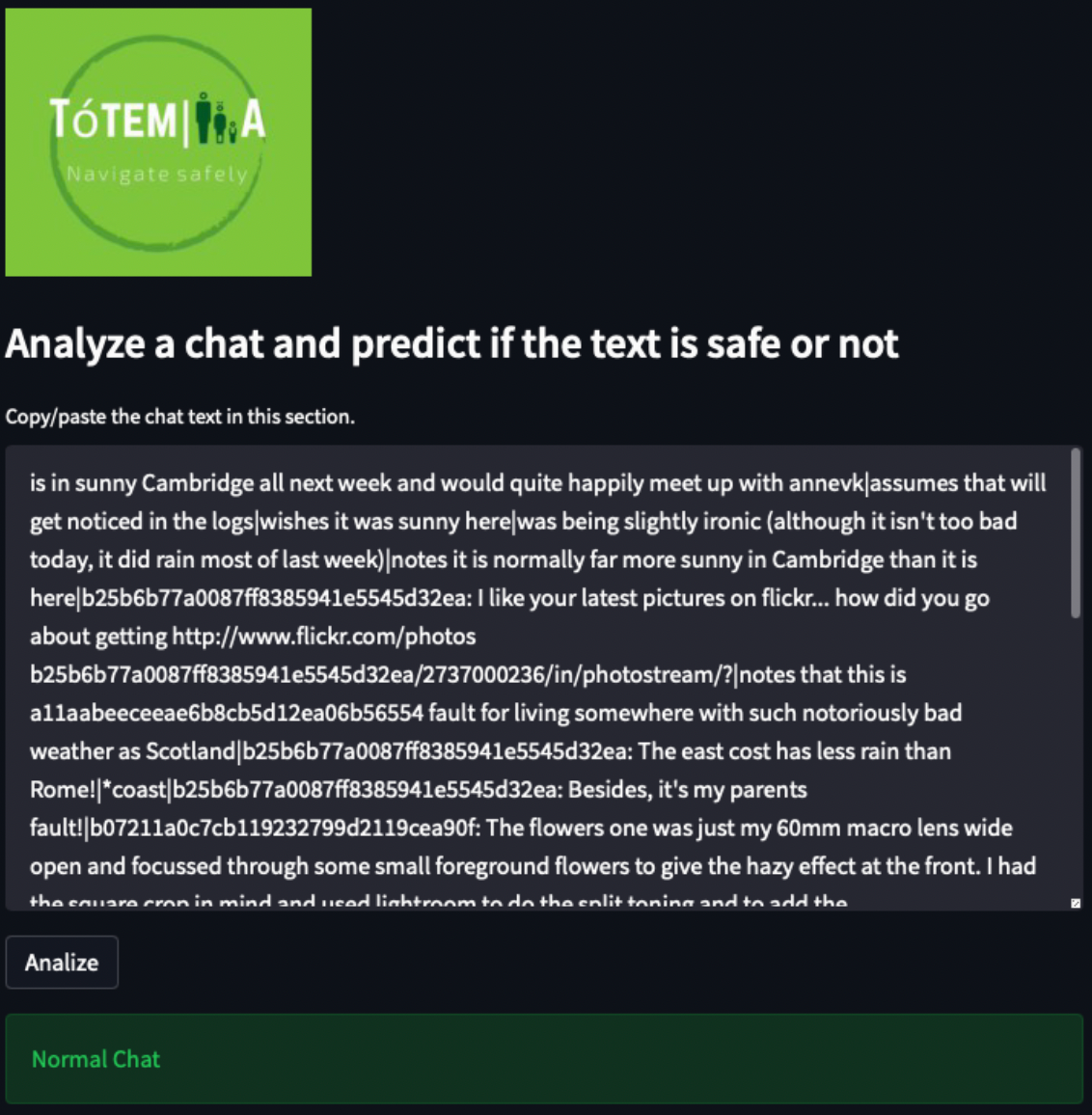
El modelo desarrollado se desplegó en una aplicación web haciendo uso de la herramienta Streamlit, en la cual a través de la interfaz se proporciona la conversación a ser analizada y la aplicación muestra la alerta si es una aplicación normal o peligrosa, a continuación se observa algunos ejemplos del funcionamiento:
Resultado del análisis en una conversación normal
Resultado del análisis de una conversación peligrosa
¿Te hace sentido nuestra propuesta?
Hasta ahora hemos podido analizar y clasificar conversaciones inapropiadas que se pueden reportar y de está forma proporcionar herramientas a los padres para el monitoreo de aplicaciones cuya función no es interferir con la privacidad sino prever situaciones peligrosas en conversaciones online.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Tradition, from latin tradere, to transmit, is the act of sharing a behavior or belief from generation to generation. And as such, this heritage becomes part of our ourselves, our identity.
Innovation, in contrast, is the introduction of new ideas, of new ways or approaches that change how things were done before. This new approaches are often seen as a threat to tradition, as the adoption of new methods or behaviors tends to change the way that things were done, the tradition.
However, do things always need to be this way? Can innovation be used to leverage and spread tradition among society?
Bertso, doinu and neurri a glimpse of the basque tradition
Among the various treasures basque culture has manged to keep alive are bertsoak, improvised verses with rhyme that are sung following a doinu, a melody, that has to match with certain neurri, or verse length.
This bertsos are typically sung in front of an audience, and, the bertsolaris, the basque rhyme singers, sing about different topics which are provided by the moderator, gaijartzaile, while they interact with the rest of bertsolaris (in a rather acid way) in pursue of the public’s applause.
How does this look like? Well lets take a look of how a modern bertso saio looks like lets take a look to the following video.
Did you notice that the base used by both of the bertsolari is the same? This base is called doinu(a). Doinus are transmitted from generation to generation, and it is very important for bertsolaris to know them well, because they need to use the doinu suggested by the gaijartzaile (moderator) or the other bertsolaris to sing their bertsoz.
Can we improvise over the improvisation?
Bertsos are like rap, and rap battles happen on the fly, there is no script to follow. This means the abbility of the bertsolari to improvise becomes the cornerstone of the bertso. However, the base, the doinu, is already known by everyone, it is something fixed, rigid.
Which is a pity, isn’t it? If improvisation is part of the great art of the bertsolari… Why not provide an improvised doinu so that the bertso experience becomes even more challenging and unique?
With these thoughts in mind, and with the newly adquiered Deep Learning skillset, @jperezvisaires and @klopetx had an instant match in our mind. If there was anything that could create doinus by itself… that would be a Generative Adversarial Network.
Could bertsolarism be revolutionized with the use of AI?
Well… maybe not that much, but it was worth a try.
GANS where technology and tradition (could) meet
With the insightful courses we had during our SaturdayAI lessons, we learned about the latest innovations on the field of Deep Learning, such as the different architectures, (convolutional, recurrent, autoencoder…) as well as the different uses such as reinforcement learning and generative adversarial networks. The question at this point was, could the magic of generative adversarial networks be used to create new doinus? If so, what did we need for that purpose?
Data! Of course.
Gathering the data
Fortunately for us (and for the basque culture) there exists an entity, Bertsozale Elkartea, who has a webpage that includes all the known doinus, around 3000, with their meta-data included. It is in basque, but just in case you wanted to give it a look.
And well… you know what they say right? It’s easier to ask for forgiveness than to get permission… So… We scrapped the web (thank you bertsozale for your work, and sorry for overloading your servers and getting your data wihout formally asking permission).
First we downloaded the metadata of the doinus. We made a selection of the most used ones considering the number of syllables and type, and we donwloaded the ‘Zortziko/Txiki’ ones that had 7 syllables in the first berse followed by 6 in the second which decreased the list of doinus to around 200.
Midi format
«But wait a minute, donwload what exactly?»
Fortunately for us, we had the chance to download the doinus in either mp3 or midi formats.
«Midi? What’s that? I know about mp3 but midi reminds me of how french people names the mid day…»
MIDI (Musical Instrument Digital Interface) is a technological standard used to transfer up to 16 information channels. It transfers messages of events that include musical notation, tone and speed among other things. Basically, this files explain what notes are played, when, for how long and how loud.
Example of a midi.
Feeding our little generative monster
Once the data was ready, we just needed to feed the GAN.
And our experience of using midi directly for the GAN is perfectly summarized by the following poem:
We used the midi as input Well, at least we tried we faced some problems and hence, gave up.
You know, everyone uses Deep Learning with images, why should we do otherwise?
So, instead of using midis directly, we created images with them, cause, due to the nature of the midi files, it is quite simple to visualize/represent them as images.
Once at the more comfortable image domain it was easier to work with the problem, as there is much more content dealing with images and convolutional neural networks.
GAN structure
Let’s take a breath for a second. We started talking about how well GANs are supposed to work in the creation of new unheared soinus, but what are GANs exactly?
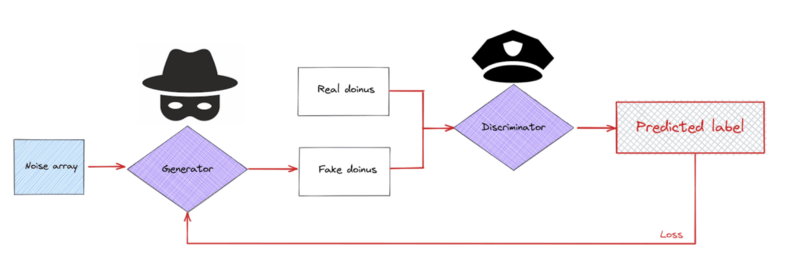
GANs were introduced by Goodfellow et. al. and are essentially two separate models that are trained together with an opposed purpose. One of the models, the generator, generates new data samples from a random seed; the second model, the discriminator, tries to tell whether the data is original (real) or if it was created by the generative model (fake). Due to their behavior, they are typicall compared to a counterfeiter and a cop. The counterfeiter keeps improving the quality of the works while the cop gets better at detecting which ones are real or faked.
The structure of a GAN fed with doinus.
Basically, during the training process, the counterfeiter should get much better at creating new data (in this case images of new possible doinus) while the cop should improve at the detection of fake doinus, forcing the improvement of the counterfeiter. At some point, the generative model should be good enough at creating doinus that it would become absolutely impossible for the discriminative model to discern among real or fake doinus, meaning we have a model capable of creating good enough doinus.
MiliaGAN, the generator part of the GAN.
Easy peasy lemon squeezy isn’t it?
SPOILER: Nothing went as expected.
Round 1: If what one has to say is not better than silence…
We started to feed our monster (well, monsters actually). We waited until the training converged. And we freaked out with the resulting doinus.
Yep, this is not a mistakenly black image, its a “shy” midi with no notes.
Yes, an empty midi. Apparently our GAN was so smart that it preferred to remain silent instead of saying something worse than silence… It went full Simon & Garfunkel and published its own version of the Sound of Silence.
Why?
The images we were trying to create were really sparse, with lots of zeroes and only some ones on the notes being played. The generator initially learnt that by switching all the pixels off, it could trick the dumb discriminator at the beginning. However, during training, at some point, even the dumbest of discriminators was able to detect that a blank image was not a real doinu, which meant that all the efforts made by the generator to produce blank images from noise were now worthless. The generator was not able to adapt fast enough to trick the new discriminator and the training diverged.
To solve the problem of sparse images, we took the argmax of all the columns, esentially turning a 128×1024 image into a a 1×1024 vector. This was possible because the doinus only play one note at a time.
Lesson: Ensure you synthesize your data as much as possible, make life easy for your neural network.
Round 2: Damn it! Who cares about mixing different doinus?
Initially, we wanted the generator to focus on creating one type of doinu only; the most popular doinu: zortziko txikia. We only had about 180 usable samples of this kind of doinu, and it soon became apparent that training GANs requires a substantial amount of data just to get barely passable results. So instead of focusing on a small fraction of the doinus, we decided to take all the database in the end. This meant jumbling all kind of different doinus together, but got us a dataset of around 2700 samples; still really small for GAN training, but worth a shot.
Yeap, the whole database with the different neurris, rhymes etc. Everything. Goes. In.
In addition, we reduced the resolution of the images so that they were less sparse, in order to avoid the problem of the shy gan.
And we reduced the midi resolution even more. We needed to simplify if we wanted to make some kind of progress.
And, surprisingly, the magic happened.
Lessons learned
So, what have we learned after the creation of our little monster, the MiliaGAN?
The amount of data needed to properly train a GAN is a lot more than we had available, bigger datasets give better results in this kind of networks. Few-shot learning in GANs is a key point being worked on in the academic community right now.
Time is key in training GANs, if the training is stable and there aren’t any divergences, the results keep improving with training time, sometimes getting pretty good results as the training goes on.
Simplify the data to be generated and fed to the neural networks as much as possible. Make life easier for your neural networks. Sparse matrices are the devil and should be condensed into a vector if possible, as neural networks love to give outputs full of zeroes if this are available to them.
Final remarks
The MiliaGAN project has been a great chance to learn DeepLearning techniques, and Generative Adversarial Networks in particular. It has only been possible thanks to the help from the AI Saturdays crew, who have created an ideal environment to learn about AI, boost the creation of a great community and the development of new projects and ideas. And, of course, to the rest of Fellows, that have helped and shared their thoughts. We are very grateful to all of you for making MiliaGAN possible. Thank you for creating this great community!
On the personal side, this project has been both challenging and a great source of fun. It combines two key aspects of our identity, our culture and our geekness. It is, additionally, the first time that Jon and Kerman join forces in a crazy technological project (not first time for crazy projects, but this is not the place for this discussion).
Will MiliaGAN revolutionize the world of bertsolarism? We frankly doubt it, but hey, if someone ever asks, we had fun and we learned.
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) a la vez que se realizan proyectos de impacto social (#ai4good). Si quieres aprender más sobre este proyecto (y otros) únete a nuestra comunidad en o aprende a crear los tuyos en nuestro programa AI Saturdays.
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
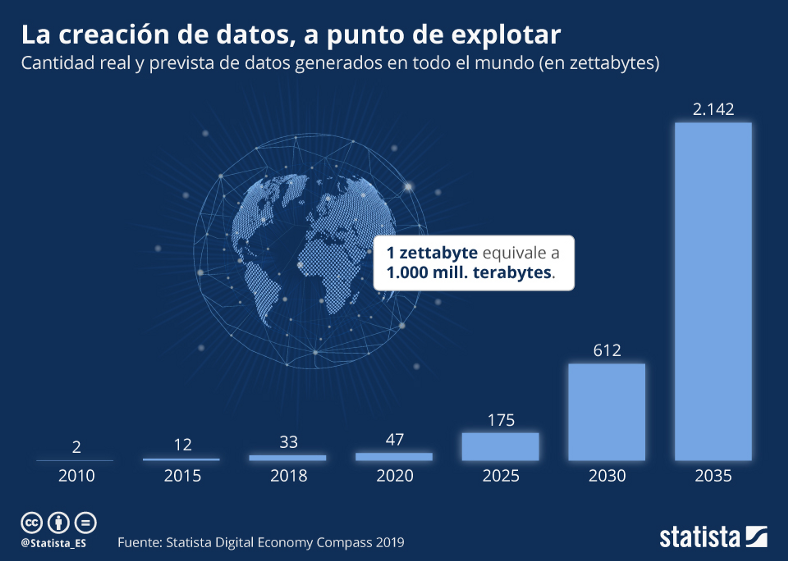
El resumen de texto es el proceso de extraer la información más importante de un texto fuente para producir una versión abreviada para un usuario. Los seres humanos llevamos a cabo la tarea de resumen, ya que tenemos la capacidad de comprender el significado de un documento y extraer características destacadas para resumir los documentos utilizando nuestras propias palabras. Sin embargo, los métodos automáticos para el resumen de texto son cruciales en el mundo actual, donde hay falta de trabajadores y de tiempo para interpretar los datos.
Figura 1: Cantidad de datos generados de manera anual
Problema
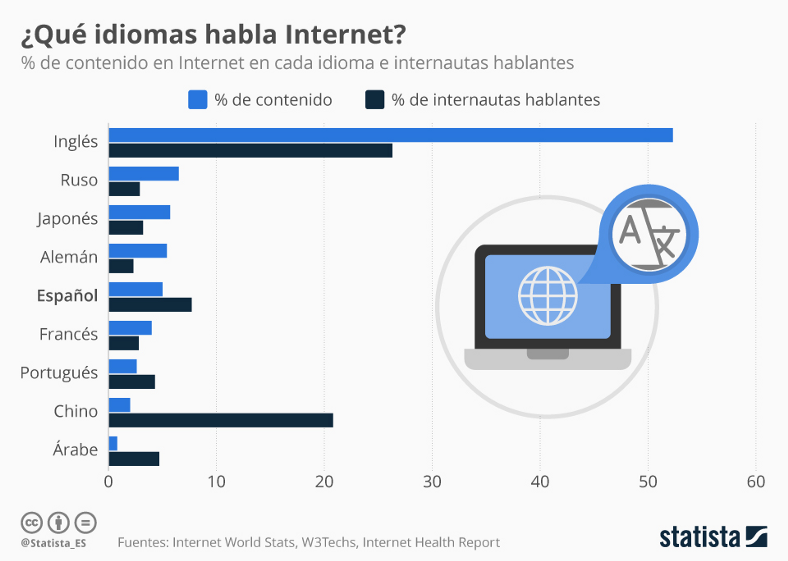
Figura 2:Idiomas predominantes en internet
Hoy en día, con el constante crecimiento de la información el estar actualizados en cualquier tema es una necesidad. Pero las fuentes de información usualmente son extensas y poseen una gran cantidad de texto pero lo más importante es que la información está en inglés.
Objetivo
Desarrollar una aplicación que pueda ayudar a la comprensión de un documento de texto en inglés y acorte el tiempo de comprensión de un texto largo.
Solución propuesta
Hacer la aplicación en base a métodos de DeepLearning enfocados a attention mechanism. Estas técnicas imitan la atención cognitiva. Esto provoca la mejora en las partes más importantes de los datos de entrada y desvanece el resto.
Dataset
CNN Daily Mail es un conjunto de datos de más de 300 mil artículos en inglés escritos por periodistas en CNN y en Daily Mail. El tamaño del conjunto de datos es de 1.27 GiB en la versión actual, esta admite el resumen extractivo y abstracto, aunque la versión original se creó para la lectura y comprensión automática y la respuesta a preguntas abstractas. Los datos se pueden usar para entrenar un modelo para el resumen abstracto y extractivo
Modelo de DL
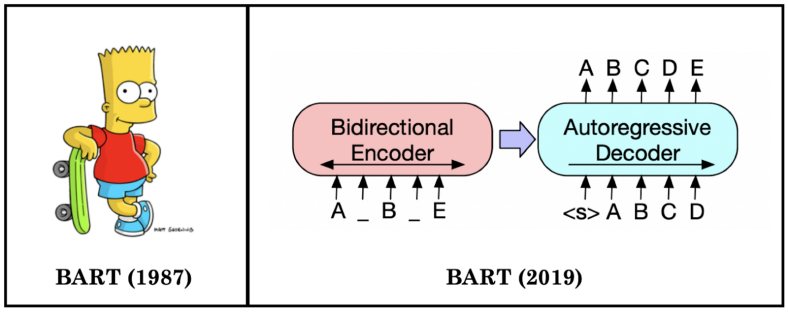
Figura 3: Esquema BART
BART es una arquitectura que se basa tanto en BERT y GPT, BART utiliza la arquitectura de transformer seq2seq estándar pero, después de GPT, que modificamos las funciones de activación de ReLU a GeLU. La arquitectura está estrechamente relacionada con BERT, con las siguientes diferencias:
Cada capa del decodificador, además, realiza una atención cruzada sobre la capa oculta final del codificador (como en el modelo de secuencia a secuencia del transformador)
BERT utiliza una feed-forward network antes de la predicción de palabras, lo que BART no hace.
Entonces en pocas palabras usa la comprensión de texto o input de BERT y GPT para el output o la generación de palabras.
Para trabajar con este modelo se lo hizo mediante el modelo base que nos provee HuggingFace.
HuggingFace es una plataforma Open Source que se enfoca en NLP, nos ayuda a construir, entrenar e implementar modelos que son estado del arte. En este caso nos ayudó a construir el modelo y con el dataset.
Entrenamiento del modelo
El proyecto fue realizado en base a los modelos provistos por la página de Hugging Face, la cual posee una gran colección tanto de modelos como de datasets para tareas de NLP (Procesamiento de Lenguaje Natural). De todas las opciones se seleccionó el modelo de sumarización abstractiva BART.
El código hace uso de las librerías “datasets” y “transformers” de HuggingFace, además de nltk para realizar la evaluación.
# Imported libraries from datasets import load_dataset, load_metric from transformers import AutoTokenizer from transformers import AutoModelForSeq2SeqLM, DataCollatorForSeq2Seq, Seq2SeqTrainingArguments, Seq2SeqTrainer import nltk import numpy as np from transformers import pipeline
Para realizar el fine tuning se hizo uso del dataset “cnn_dailymail”, para la evaluación se utilizó la métrica “rouge”, y el modelo base que se usó fue “facebook/bart-base”.
Del dataset “cnn_dailymail” se extrajeron los elementos que se encuentran bajo las etiquetas de “article” y “highlights” como datos de entrada y salida respectivamente.
max_input_length = 512 max_target_length = 128def preprocess_function(examples): inputs = [doc for doc in examples[“article”]] model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True) # Setup the tokenizer for targets with tokenizer.as_target_tokenizer(): labels = tokenizer(examples[“highlights”], max_length=max_target_length, truncation=True)model_inputs[“labels”] = labels[“input_ids”] return model_inputstokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
Antes de entrenar el modelo se realiza la configuración de hiperparámetros.
Se crea una función para realizar el cómputo de métricas haciendo uso de rouge score.
def compute_metrics(eval_pred): predictions, labels = eval_pred decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True) # Replace -100 in the labels as we can’t decode them. labels = np.where(labels != -100, labels, tokenizer.pad_token_id) decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Rouge expects a newline after each sentence decoded_preds = [“\n”.join(nltk.sent_tokenize(pred.strip())) for pred in decoded_preds]decoded_labels = [“\n”.join(nltk.sent_tokenize(label.strip())) for label in decoded_labels]
result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True) # Extract a few results result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
# Add mean generated length prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in predictions]result[“gen_len”] = np.mean(prediction_lens)
return {k: round(v, 4) for k, v in result.items()}
Una vez inicializado el modelo, definidos los hiperparámetros, datasets, tokenizer y métricas creamos un Trainer.
Descargamos punkt tokenizer que nos permite transformar un texto por oraciones.
nltk.download(‘punkt’)
Finalmente realizamos el entrenamiento y la evaluación
trainer.train()trainer.evaluate()
Resultados
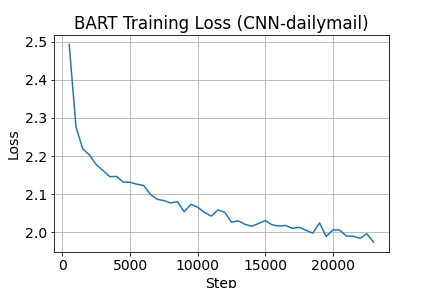
Figura 4:Pérdida a lo largo del entrenamiento
Una vez finalizada la fase de entrenamiento podemos observar la pérdida a lo largo del entrenamiento realizado en el dataset “train”.
Si bien se muestran buenos resultados, se pueden mejorar haciendo mejor sintonización y tiempos de entrenamiento con el modelo.
Los resultados obtenidos al evaluar el modelo entrenado con la métrica rouge score fueron los siguientes:
eval_loss: 1.5510817766189575
eval_rouge1: 46.8771
eval_rouge2: 23.5647
eval_rougeL: 39.6525
eval_rougeLsum: 43.3625
eval_gen_len: 17.8154
Conclusiones
Se logró realizar una aplicación que resume y traduce el texto dado, se vio que los resultados obtenidos son óptimos para la tarea.
Se usó dos modelos para hacer la aplicación, el primer modelo es el que se entrenó de resumen este modelo ya esta en huggingface , para la parte de traducción se usó un modelo ya entrenado de huggingface. (https://huggingface.co/Helsinki-NLP/opus-mt-en-es).
Trabajo Futuro
Mejorar los tiempos de inferencia que tienen los modelos al usar servicios en la nube.
Expandir los tipos de entradas que pueda tener, puesto que ahora solo soporta texto puro. (txt, docx)
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) a la vez que se realizan proyectos para el bien (#ai4good). Los talleres que realizamos forman parte del programa AI 4 Schools para que cualquier persona “aprenda haciendo” IA sin importar su especialidad o nivel de partida.
Usamos técnicas de Machine Learning para la clasificación de idiomas.
Bolivia lucha para que no desaparezcan los idiomas indígenas, sin embargo, es aún muy complicado acceder a recursos que ayuden la asimilación y aprendizaje de los mismos. Es por ello que planteamos crear una herramienta con Machine Learning para la clasificación de idiomas, que si bien es una tarea sencilla es elemental para realizar tareas más complejas como la traducción automática, el análisis de sentimientos, conversión de habla a texto, texto a habla, etc. Este modelo de clasificación se creó usando herramientas de NLP (procesamiento de lenguaje natural) y ML (aprendizaje automático), obteniendo una precisión superior al 99%.
Desde 2006 Bolivia es líder en la defensa y reivindicación de los pueblos y las culturas indígenas en su territorio y en el mundo.
“Hoy en día, las 36 lenguas originarias en Bolivia son idiomas oficiales. En Bolivia se tiene que hablar y enseñar inicialmente un idioma originario» [1].
Pero todo esté trabajo ¿realmente tiene resultados positivos en la asimilación y aprendizaje de las lenguas originarias en Bolivia?.
Descripción del problema
Si bien en nuestro país se lucha porque no desaparezcan estos idiomas indígenas es aún muy complicado acceder a recursos que ayuden la asimilación y aprendizaje de los mismos. Sin embargo, actualmente se puede usar la tecnología como un aliado para solucionar este problema y la detección de idiomas es un punto inicial y primordial para crear herramientas de traducción automática de texto, de conversión de texto a voz, voz a texto, voz a voz, entre muchas otras aplicaciones.
Objetivo
Crear una herramienta con Machine Learning capaz de identificar y clasificar idiomas originarios de Bolivia, para agilizar tareas relacionadas como la traducción, recuperación de la información, etc.
Límites y alcances
LÍMITES: Debido a la dificultad de conseguir un conjunto de datos suficientemente grande de los idiomas más hablados en Bolivia (quechua, guaraní, aymara), solo nos centramos en el idioma quechua.
ALCANCES: La herramienta de identificación, en una primera etapa, será capaz de clasificar el idioma de frases ya sea como quechua o español.
Metodología
Para la clasificación de idiomas mediante Machine Learning se utilizó una metodología iterativa incremental, que conlleva las siguientes fases:
Figura 1. Metodología (Dataiku)
Captura de datos
Posterior a la creación del dataset nos dimos cuenta que éste estaba desbalanceado porque el número de frases en quechua duplicaban el de español, por esa razón decidimos balancear los datos agregando frases de español obtenidos de un dataset de Kaggle.
Figura 2. Captura de datos (Imagen extraída de un sitio web)
Pre-procesamiento
En esta etapa se realizaron diversas formas de pre-procesamiento, desde la ingeniería de características (feature engineering) hasta la vectorización. Las cuales se describen a continuación.
Limpieza de caracteres irrelevantes
Las frases en español de Kaggle tenían caracteres de otros idiomas e irrelevantes para la clasificación, es por ello que antes de unir con el dataset que se tenía se pasó a realizar una limpieza de todos esos caracteres de las frases de Kaggle. Una vez unido el dataset aún se tenían caracteres que no aportaban información como: dígitos, signos de puntuación, etc. y por tanto se realizó una limpieza de estos caracteres.
Técnicas implementadas
En base a la información del dataset se pudo notar que había un dato mal tabulado y se realizó la imputación de datos por valores nulos. Por otro lado, como el dataset cuenta con solo un feature y el target, no se tuvo la necesidad de reducir las dimensiones.
Análisis de los features
Cada idioma tiene sus propias reglas gramaticales y el idioma Quechua no es ajeno a eso, por ende se investigó las reglas de este idioma y se pudo notar ciertas características interesantes que lo diferencian de otros idiomas, por mencionar algunas:
El alfabeto quechua cuenta con 28 consonantes (algunas consonantes son diferentes al de español como: ch’, chh, qh, p’) y 3 vocales (a, i, u)
Las consonantes del quechua se clasifican según el modo de articulación, algunas de estas son:
Oclusivas (p, t, k, q)
Aspiradas (ph, th, chh, kh, qh)
Glotalizadas (p’, t’, ch’, k’, q’)
Semiconsonantes (w, y)
3. Para diferenciar el género de una persona se usan las palabras: warmi y qhari
4. La interrogación en el quechua se realiza agregando a la palabra el sufijo -chu.
Estas y muchas más características de la gramática Quechua, así como la gramática del Español fueron tomadas en cuenta para realizar las gráficas, las cuales nos permiten corroborar estas diferencias entre las reglas gramaticales en el dataset.
Uno de los gráficos que realizamos fue la frecuencia de las vocales por idioma en el dataset (Figura 3). La frecuencia de las vocales fueron calculadas según el número de caracteres de cada frase.
Figura 3. Frecuencia de vocales (Elaboración propia)
Otras gráficas que realizamos fueron la frecuencia de las consonantes como: K, H, M, R (Figura 4) y caracteres especiales como: á, é, í, ó, ú, ä, ü, ‘ (Figura 4), según el idioma.
Figura 4. Histograma de caracteres (Elaboración propia)
Estas gráficas nos permitieron aclarar algunas dudas sobre las diferencias gramaticales entre el idioma Español y Quechua, y representaron un punto clave para realizar el pre-procesamiento de los datos.
Por las diferencias de algunas letras y caracteres utilizados para cada idioma, además de ciertos sufijos o prefijos propios, numeración y demás características, decidimos vectorizar las frases según el modelo n-gram de caracteres. Para capturar características importantes en ambos idiomas delimitamos el modelo n-gram de 1 a 5, esto por temas de rendimiento y también porque consideramos que este número nos permite abstraer aquellas características gramaticales que citamos anteriormente.
Figura 5: Pre-procesamiento y vectorización de los features (Elaboración propia)
Además de vectorizar las frases según la frecuencia de caracteres únicos que tiene cada frase se aplicó la frecuencia TF-IDF, medida estadística que evalúa cuán relevante es un término para un documento en una colección. En este caso cada término es representado por cada carácter y el documento es representado por la frase del idioma en el dataset (colección de frases).
Selección y evaluación de modelos
Con los datos listos se procedió a construir los modelos de predicción. Se utilizaron modelos de clasificación debido a que tenemos un problema de clasificación binaria, sólo se tienen dos posibles etiquetas, “Quechua” y “Español”.
Por lo tanto, se utilizaron los siguientes algoritmos de aprendizaje supervisado:
Naive Bayes
Support vector Machine
Logistic regression
Para encontrar la mejor combinación de hiperparámetros se utilizo GridSearch de la biblioteca Sklearn.
Las matrices de confusión para los 3 modelos son:
Figura 6. Matrices de confusión, balanced accuracy y tiempo de ejecución de los 3 modelos (Elaboración propia)
Clasificación de nuevos datos
Una vez seleccionado nuestro mejor modelo, es necesario probarlo con algunas frases nunca antes vistas, por ello probamos frases que solo contienen palabras de un idioma, frases que contienen palabras de ambos idiomas que es usual en el habla coloquial de los quechua hablantes y por último una frase sin sentido. Nuestro modelo seleccionado se comporta bien con los dos primeros tipos de frases, sin embargo, al ingresar frases sin sentido que no pertenece ni al español o al quechua, estas frases son clasificadas directamente como quechua, esto se debe a que como manejamos un modelo binario el texto ingresado sea cual sea debe etiquetarlos con una etiqueta u otra.
Figura 7. Resultados del modelos (Elaboración propia)
Conclusión
En general, el modelo de Machine Learning para la clasificación de idiomas basado en Support Vector Machine ofrece el mejor resultado predictivo con una puntuación de precisión balanceada superior al 99%.
Específicamente, el modelo funciona bien para clasificar Español y Quechua dada la alta precisión, y puntajes f1 para estos dos idiomas.
Si bien la mejor precisión se obtuvo con SVM, considerando las variables precisión y rendimiento el mejor modelo sería el basado en Regresión Logística, ya que ofrece un tiempo de ejecución menor al de SVM y tiene una precisión superior al 99%, lo cual es un factor importante en aplicaciones en real time.
Se logró abstraer algunas características del idioma quechua, por lo que es posible realizar el mismo análisis con otros idiomas originarios de Bolivia
Trabajos futuros
Si bien este problema aparenta ser sencillo es un paso necesario para:
Traducción automática
Detección de idioma para el uso de boots
Análisis de sentimientos, etc.
El codigo fuente de este proyecto se puede encontrar en: github
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
¿Cómo calificarías la experiencia de aprendizaje que viviste/estás viviendo en la universidad? ¿Sabrías decir qué es lo que hace que estás más satisfecho/a con un profesor?
Cuando hablamos de experiencias, es complicado poner nombres y apellidos a nuestras sensaciones. Además, estas sensaciones de una persona pueden ser muy diferentes a las de otra, y no es fácil encontrar patrones comunes. Sin embargo, todos/as somos capaces de recordar con cariño a algún/a profesor/a de nuestra etapa preuniversitaria, una persona que nos transmitió algo diferente al resto.
¿No sería ideal tener claro qué es lo que hace que ese profesor/a nos haya generado una experiencia positiva? ¿No sería útil que ese/a profesor/a (y el equipo de coordinación) tuviera esto en cuenta como un factor crítico para medir su desempeño?
Y, seamos claros. Además de la experiencia, valoramos mucho el resultado final del proceso. La motivación extrínseca de la evaluación final es un factor muy relevante, por lo que, ¿no sería importante conocer qué es lo que hace que un/a profesor/a mejore los resultados académicos de un grupo? De esta forma, no solo tener un grupo contento, sino un grupo que ofrece su mayor potencial. Y, estando la universidad tan cerca del mercado laboral, esto es si cabe más importante que en otras etapas formativas.
Por qué nos hemos metido en esto
Cuando empezamos a pensar sobre estas preguntas, creíamos que ya estarían respondidas la mayoría de ellas. Pero, al parecer la medición de la experiencia universitaria no es un tema de debate nacional. Y los ranking están casi más dedicados a lo bien clasificados que están los MBAs que a la satisfacción del alumnado.
Así que desde Saturdays.AI Bilbao un equipo formado por dos estudiantes universitarios (Gorka Legarreta Ibarra y Rubén García Pedrejón) y un servidor, profesor universitario, (Iñaki Fernández López-Zuazo) nos pusimos manos a la obra. Los 3, por motivos obvios, tenemos interés en hacer que la experiencia y los resultados académicos sean los mejores posibles. Y, desde una visión muy personal como profesor, si algo me irrita es que todo el mundo crea que tenga la razón sobre cuál es la mejor forma de enseñar/educar. Así que, citando a Deming “para no ser una persona más con una opinión” vamos a trabajar para llegar a conclusiones basadas en datos.
Ninguno de los 3 teníamos experiencia en programación, pero a fuerza de practicar, practicar, y practicar (y un poquito de controlC+controlV, todo hay que decirlo) hemos llegado a alguna conclusión interesante.
Si eres estudiante, ¿preparado/a para saber qué es lo que tienes pedir a tu universidad para tener la mejor experiencia y notas posibles?
Si eres profesor/a universitario/a ¿preparado/a para conocer los elementos en los que más tienes que enfocarte para mejorar tu desempeño profesional?
El dataset
Sin datos no hay paraíso, y ha sido complicado hacerse con una buena base de datos, que contuviera información suficiente para llegar a conclusiones de interés. Una universidad ha cedido amablemente un dataset, anonimizando cualquier atributo de caracterización, e introduciendo multiplicadores a algunos atributos para evitar su identificación. Estos cambios no han afectado en ningún caso al resultado del proyecto, pues ambos dataset (el original y el modificado) arrojan las mismas conclusiones. Por último, aunque en este análisis se han utilizado los comentarios aportados por los alumnos/as en el dataset, se han borrado posteriormente, pues contenían información que hacía fácil identificar a profesores/as y situaciones concretas.
Este dataset contiene información sobre más de 20.000 encuestas de satisfacción realizadas al alumnado desde febrero 2015 a diciembre 2020. Se ha completado la información de la encuesta con datos identificativos del profesor/a que impartía la asignatura y de la nota media del grupo.
Entrando al detalle, la información que más se trabajará a lo largo del dataset es:
Respuestas a las preguntas concretas de satisfacción: Se evalúa el conocimiento del/a profesor/a, su manera de explicar, la metodología que utiliza en el aula y el feed-back que da. Por último, se le da una nota general.
Nota media: Se ha realizado una media de todo el grupo que responde a la encuesta. Es decir, un registro no contiene la nota que ha sacado el alumno/a en la evaluación, sino la nota media de todo el grupo al que pertenece
Datos identificativos del profesor/ay su asignatura: Sexo, edad, campus donde trabaja habitualmente, tipo de asignatura que imparte…
EDA: Cuánta razón tenían…
En las primeras sesiones de Saturdays.AI siempre se menciona la importancia de la limpieza de datos, y que es una tarea que lleva más del 80% del tiempo de casi cualquier proyecto. Sinceramente, parecía una exageración, pero quizás hemos llegado al 90% 🙂
Para no liarnos demasiado en este punto, estas han sido las mayores transformaciones:
Eliminación de registros con NaN: Al tener una BBDD tan grande, creíamos que no merecía la pena inferir resultados, y nos quedamos solo con aquellos registros que tenían toda la información.
Foco en un grado en particular: Teníamos información de varios grados, pero la información del resto de ellos era parcial, y además no disponíamos de sus notas, claves para el proyecto. Por lo que decidimos centrarnos en un solo grado.
Homogeneización y eliminación de atributos: En un año en concreto, se cambió el modelo de aprendizaje hacia la co-docencia, y por cada aula hay 3 profesores/as. Por tanto, el/la estudiante ponía nota a los/as tres, y eso trabajo algunos problemas para la homogeneización del dataset. Todos solucionados con mucho esfuerzo y tesón 🙂
Categorización de atributos: Para mejorar posteriores análisis se categorizaron las respuestas a las preguntas de satisfacción (con el Net Promoter Score) y las notas. En la satisfacción categorizamos en detractores (0 a 6) pasivos/neutros (7 y 8) y promotores (9 y 10). En las notas: suspensos (0 a 4,9) aprobados (de 5 a 7,9) y sobresalientes (8 a 10).
Explorando los datos: reafirmando intuiciones
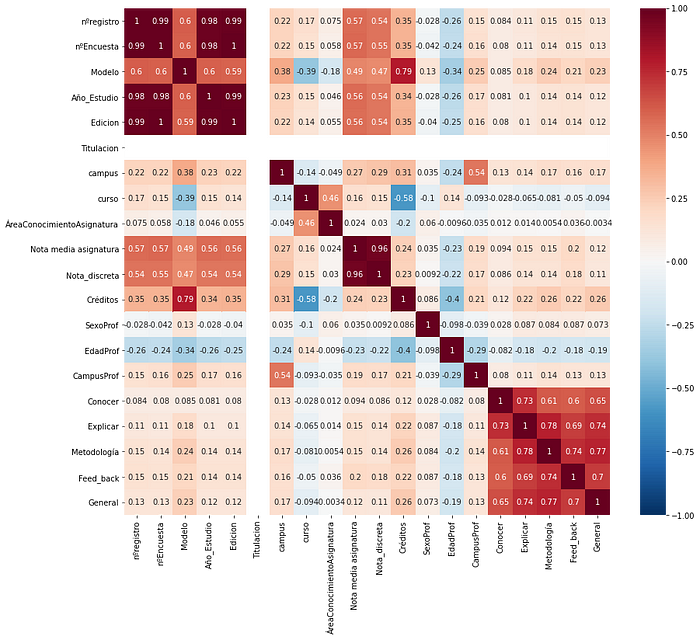
Con el dataset preparadito para trabajar en él, empezamos con un Heatmap para conocer la correlación entre todas las variables:
Si nos fijamos en las variables relacionadas con la satisfacción, podemos comprobar que la metodología es lo que más correlaciona con la nota general del profesor/a (aunque explicar y feed_back están muy cerca) y el conocimiento del/a profesor/a, lo que menos. Vamos, que empezamos a reafirmar algo que ya imaginábamos: por mucho que sepa una persona, como no cuenta con la metodología adecuada, puede no llegar a satisfacer lo suficiente al alumnado. Pero ojo, conocer también se correlaciona con explicar, por tanto, para poder explicar bien hay que conocer bien lo que se imparte. Condición necesaria, pero no suficiente.
También nos pareció interesante conocer si el sexo y la edad influyen en la satisfacción del alumnado, así que pasamos a agrupar con estos criterios:
Pues parece que los/as más jóvenes obtienen generalmente mejor puntuación. Sin diferencias destacables entre sexos, aunque es cierto que las mujeres más adultas (>55) parecen ofrecer una mejor experiencia que los hombres de su edad.
Por último, queríamos saber si, más allá de la edad, lo relevante era la antigüedad del/a profesor/a en la universidad. El profesorado está ordenado según su entrada en la facultad, por lo que bastaba con plotear este orden respecto a la nota de satisfacción.
Pues sí, parece que los nuevos fichajes tienen menos puntuaciones negativas que los/as veteranos/as del lugar. Eso sí, les cuesta más llegar al 10.
Ahora que tenemos ya algunas ideas sobre el dataset, pasamos a los modelos.
De aprendizaje supervisado a no supervisado, aderezado con NLP de preescolar
Hemos trabajado 4 modelos, cada uno con un objetivo.
-Regresión lineal: Para poder predecir la satisfacción general si contamos con los 4 ítems de satisfacción, y conocer la importancia de cada uno de ellos.
-Asociación: Para conocer qué atributos se “mezclan” más con otros.
-Decision Trees: Para clasificar de forma sencilla a promotores/detractores/neutros.
-Clustering: Para identificar la relación entre nota y satisfacción, y lo más importante, describir los grupos de profesores/as que se forman.
-NLP: Para conocer qué comentarios se repiten más según la satisfacción y la nota del grupo.
Regresión lineal
Escogimos las 4 variables de satisfacción como variables independientes, y la satisfacción general como la variable dependiente del modelo. Suponíamos, vistas las correlaciones, que íbamos a tener buenos resultados.
Y así fue, utilizando la técnica Ridge de regresión obtenemos un accuracy del… ¡67%! Seguro que jugando con los datos train y test podemos llegar a un resultado mejor, pero nos dimos por satisfechos. Para contextualizar mejor este dato, medimos la importancia relativa de cada variable.
Es decir, podemos predecir el resultado, y comprobamos que explicar es el elemento que más hace variar este resultado. Así que ya sabéis profesores/as, si os parece que os está yendo mal con un grupo, ¡a explicar mejor!
Asociación
Ya tenemos varias pistas sobre qué afecta más a la satisfacción, pero todavía no sabemos si hay relación entre un grupo con buenas notas y un buen profesor/a. Para comprobarlo, implementamos el algoritmo “a priori” para visualizar las asociaciones entre variables. A continuación, adjuntamos las asociaciones con un lift>1 (ocurren más de lo esperado).
Aunque hay un poco de todo, la asociación con mayor lift y confianza es “sobresaliente” con “promotor” Por lo tanto, podemos intuir que aquellos grupos que tienen una media sobresaliente, tienen un/a profesor/a que han valorado muy positivamente, pero no al contrario. Y tampoco podemos concluir que malas notas llevan mayoritariamente aparejadas malos/as profesores/as.
Para profundizar más en qué es lo que hace que ese profesor/a tenga promotores o detractores, empezamos con los decision trees.
Decision Trees
La primera prueba que hicimos fue con una profundidad de 2, para empezar a visualizar los primeros resultados.
Conclusiones similares a lo anterior para el profesorado: Explicar es lo que más diferencia a promotores de detractores/neutros. Pero para asegurar un mayor número de alumnos/as promotores, mejor tener una buena metodología en las sesiones. Y, si explicar no es tu fuerte, céntrate en dar un buen feedback para no tener detractores.
Pero bueno, el score del árbol es de 0.35, así que hay que coger el resultado con cierto escepticismo.
Si ampliamos la profundidad a 5, ya vemos que entran nuevos atributos, y sube el score a 0.45. Un insight que descubrimos con este árbol es que, si el feedback no es lo suficientemente bueno, pero el conocimiento percibido por el alumno/a es alto, la posibilidad de tener promotores sube.
Visto todo esto, vamos a centrarnos en cómo son los/as profesores/as según la satisfacción de los/as alumnos/as y las notas que ponen.
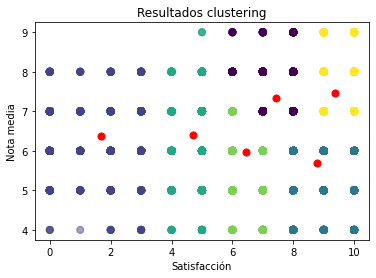
Clustering
Antes que nada, aplicamos el algoritmo K-Means para identificar el número óptimo de clústeres: 6. Pasamos a plottear esta relación entre notas y satisfacción:
Tenemos 6 grupos diferenciados, pero vamos a poner el foco en 3 de ellos:
Profesores/as que solo tienen detractores, al margen de la nota media del grupo:. Tiene más de 55 años, de la zona oeste de Gipuzkoa, con los conocimientos suficientes para ser bien valorados, pero sin las metodologías adecuadas según la opinión de sus alumnos/as. Es decir, profesores/as mayores con metodologías poco atractivas (¿quizás anticuadas?) tienen muchas papeletas para tener detractores.
Profesores/as que solo tienen promotores, teniendo sus grupos notas medias <6. Entre 35 y 55 años, imparten asignaturas de finanzas, son del este de Gipuzkoa y son bien valorados por sus conocimiento. En cambio, el feedback que ofrecen no parece ser el suficiente. Se puede inferir que por muy satisfecho que esté un alumno/a, como no se le de el feedback necesario para su mejora, no tendrá resultados notables.
Profesores/as que tienen mayoritariamente promotores y su nota media mínima es de 7: Menores de 35, de asignaturas de estrategia, con mucho conocimiento y buenas explicaciones.
Para profundizar algo más en cómo clasificar a estos profesores, vamos a darle un poco al NLP.
NLP
Como todo proyecto, en las fases finales quedan pocas energías. Y si lo último es NLP, que no es precisamente el algoritmo más sencillo, cuesta llegar a conclusiones reveladores. Sin embargo, con un simple counts de cuáles son las frases más repetidas (cuando se les pregunta aspectos a mantener) de los/as alumnos/as en función de la nota que dan al profesorado y las notas que reciben, obtenemos los siguientes insights.
En el caso de los detractores, los comentarios giran en torno al trabajo en equipo. Vamos, que lo positivo de la asignatura han sido sus compañeros/as de clase más que la propia clase. En cambio, los comentarios más repetidos con los promotores ensalzan al profesor/a: su conocimiento, formas diferentes de dar clase, buen feedback a todos los trabajos…
Si analizamos las respuestas según la nota obtenida, los comentarios más repetidos en el caso de los suspensos hacen referencia al material aportado. Es decir, lo único bueno que tiene que decir es que la asignatura o los PPTs son buenos. Y en el caso de los sobresalientes, ya aparecen (por primera vez) muchos comentarios sobre la disposición del profesor/a: atención, actitud, motivación, ganas de ayudar…
Vamos acabando: 3 grandes conclusiones
La forma de explicar del profesor/a es el elemento clave para la satisfacción.
Generalmente, profesores/as con promotores tienen grupos con mejores resultados. Especialmente si son jóvenes y son percibidos con mucho conocimiento.
Para mejorar los resultados de un grupo, la actitud y la disposición del profesor parece ser el elemento diferencial.
No son conclusiones reveladoras que nos hagan ganar el nobel de educación, y puede que no sean extrapolables a otras universidades y contextos. Pero al menos ya hay una base por dónde empezar, y aunque ahora lo complicado sea precisamente cómo mejorar esas explicaciones o la actitud, los profesores/as ya sabemos dónde incidir, y los alumnos/as qué exigir 😉
Si tuviéramos que cerrar con una conclusión final, sería precisamente la importancia de la actitud. Es el comentario más repetido, con diferencia, en el caso de los grupos con notas sobresalientes. Ya no es cuestión de que estén más o menos satisfechos, sino de que obtienen mejores resultados. Y aunque mejores calificaciones no equivalen necesariamente a un mejor desarrollo futuro, nos surgen dos preguntas de cierre.
Como profesores/as, o desde la coordinación: ¿Se hacen los esfuerzos suficientes para mejorar la actitud y disposición del profesorado hacia los/as alumnos/as? ¿Puede más la burocracia o la experiencia del estudiante?
Como alumnos/as: ¿Hasta qué punto existe actitud hacia el aprendizaje? ¿Cuánta responsabilidad tiene el profesor en motivarnos? ¿No sería más lógico venir motivados/as de casa?
Líneas futuras
Todavía queda mucho por hacer…
Un buen análisis NLP, más allá de contar las frases más repetidas. Mucho potencial para extraer el valor a más de 4.000 comentarios.
Clustering: se podría mejorar tanto el clustering hecho al profesorado, como introducir nuevas variables del alumnado para hacer un nuevo clustering.
Y más allá de la programación, implementar un sistema “close the loop” para tomar acciones y decisiones en base a los resultados de las encuestas. Que lleven a proyectos accionables.
Cierre
En el siguiente enlace de GitHub encontrarás el dataset y los diferentes notebooks utilizados en el proyecto.
Si quieres ver la presentación que se hizo del proyecto, la tienes por aquí.
Y para acabar, un agradecimiento a todo el equipo de Saturdays.AI Bilbo. De estar contando filas en un Excel hemos pasado a un proyecto presentable, nada habría sido posible sin la comunidad. Mila esker denoi!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) a la vez que se realizan proyectos para el bien (#ai4good). Los talleres que realizamos forman parte del programa AI 4 Schools para que cualquier persona “aprenda haciendo” IA sin importar su especialidad o nivel de partida.