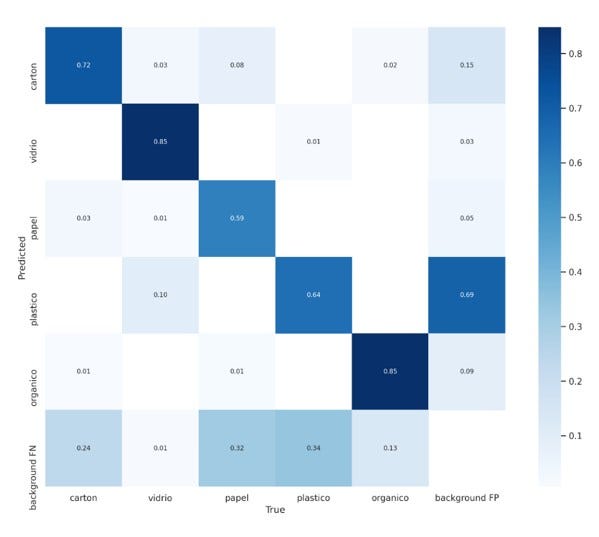
¿Sabias que las enfermedades cardiovasculares (ECV) son la principal causa de muerte en todo el mundo?
En México, el 19% de mujeres y hombres de 30 a 69 años mueren de enfermedades cardiovasculares, y se estima que el 70.3% de la población adulta vive con al menos un factor de riesgo cardiovascular.
Las enfermedades cardiovasculares son un grupo de desórdenes que afectan al corazón y/o los vasos sanguíneos , las cuales representan un problema de salud pública en México .
Estudios epidemiológicos han permitido identificar un conjunto de variables denominadas factores de riesgo de tipo cardiovascular (FRCV), que son todas aquellas características biológicas no modificables y características conductuales modificables (estilos de vida), cuya presencia se relaciona con una mayor probabilidad de sufrir una enfermedad cardiovascular en el futuro. Su identificación temprana es fundamental para implementar cambios en los hábitos de los pacientes con el objetivo de prevenir un evento de enfermedad cardiovascular primario.
En los últimos años México ha implementado varias estrategias enfocadas en el sector salud que prometen buenos resultados. A pesar de esto, se han encontrado inconsistencias en los procesos de atención primaria, práctica clínica e instrumentos de vigilancia que limitan la monitorización cardiovascular de la población.
¿Qué es CARDIOSIGHT?
El proyecto de CARDIOSIGHT nace debido a la presente necesidad en nuestro país de crear métodos y herramientas de identificación temprana para los individuos con alto riesgo de sufrir enfermedades cardiovasculares. Con el fin de prevenir eventos cardíacos primarios y ayudar a disminuir la incidencia de nuevos casos, por medio de hábitos de prevención. Este método de detección será diseñado con ayuda de la inteligencia artificial.
Ventajas de la aplicación:
● La población tendrá la facilidad de conocer su nivel de riesgo sin la necesidad de asistir a una unidad médica de salud. Acelerando de esta manera la identificación de los individuos con un riesgo alto antes de que se desarrolle un evento cardiovascular primario.
● Posterior a la identificación, dependiendo del resultado, se le sugerirá al usuario visitar las páginas disponibles del Instituto Mexicano del seguro social que brindan la información sobre las campañas preventivas actuales relacionadas a este tipo de enfermedades, en las cuales encontrarán la información necesaria para educarse sobre la problemática, además de la posibilidad de encontrar su clínica más cercana para realizar su primer chequeo médico.
¡Experimentando con los datos!
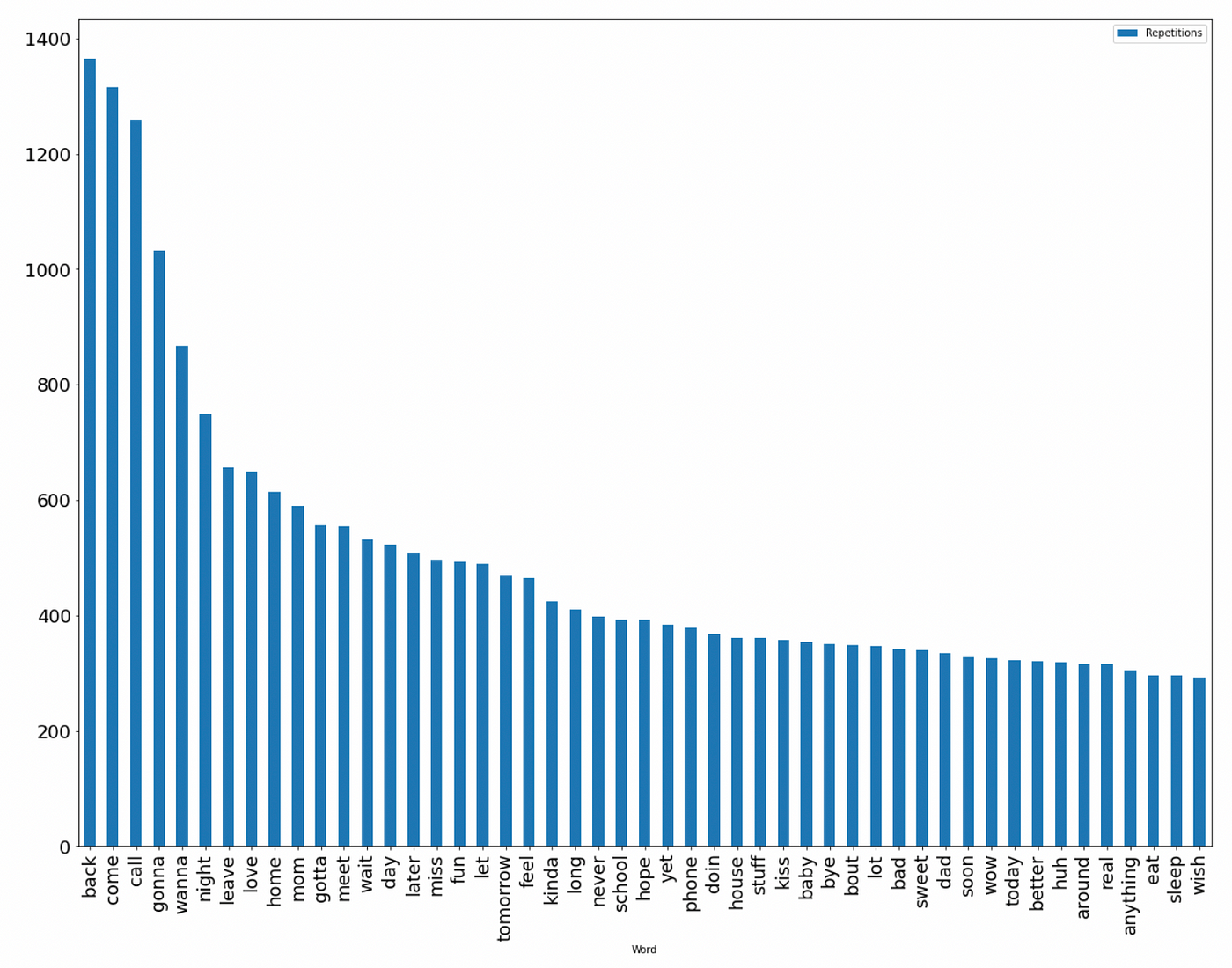
Se decidió trabajar con el dataset Cardiovascular Disease encontrado en la página Kaggle. El cual consiste en 70,000 datos recabados de pacientes, contiene 11 características y una variable objetivo, información recabada por medio de resultados médicos, compartida por el paciente o de forma factual.
Figura 1. Relación entre BMI (Indice de masa corporal) y la presencia o no de ECV.
Tras realizar el análisis exploratorio y transformación de nuestros datos se decidió experimentar con el modelo de Random Forest debido a su excelente capacidad de clasificación.
Figura 2. Modelo Random Forest
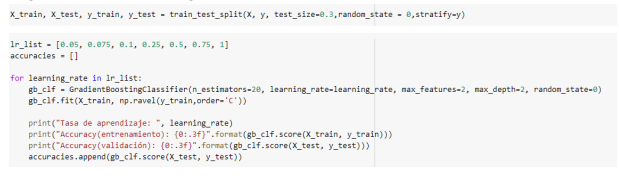
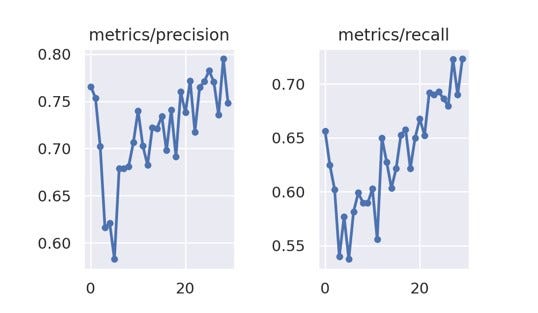
Tras realizar varias pruebas y tuneo de hiperparámetros se encontró el modelo ideal para nuestra aplicación.
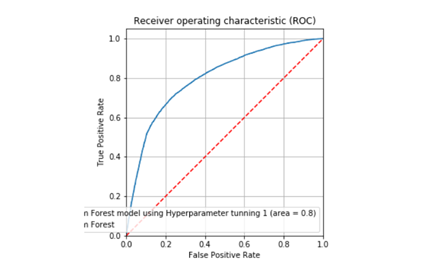
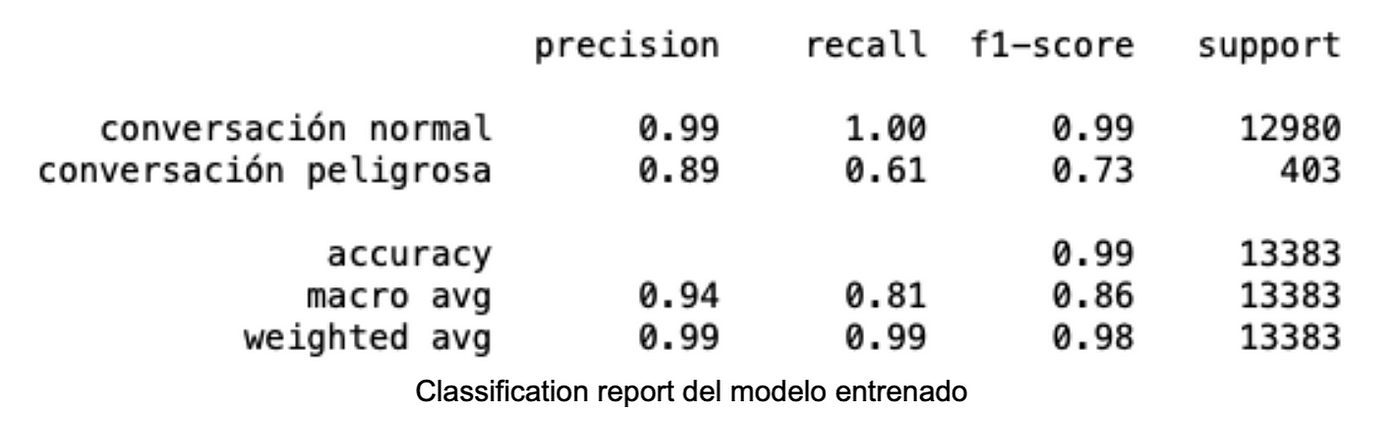
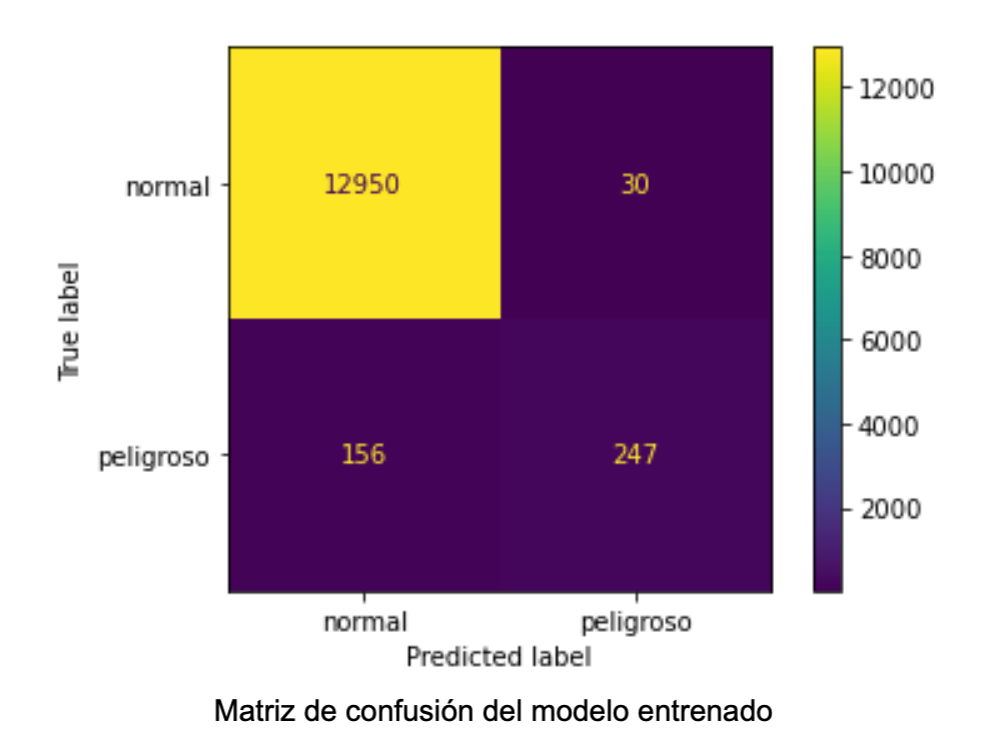
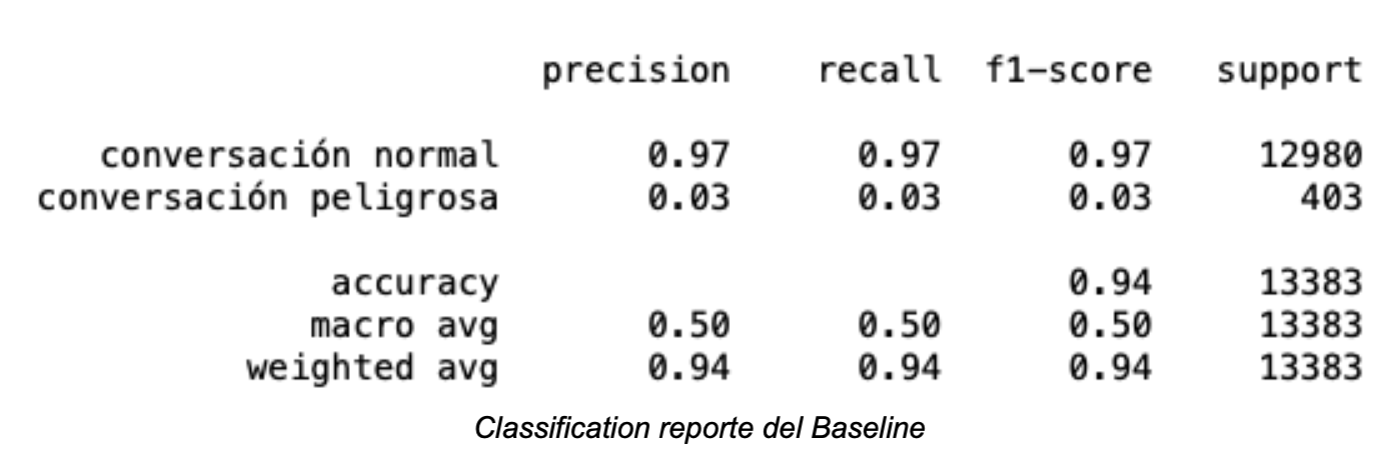
Con un accuracy de 0.73 y una curva ROC de 0.8, se decidió obtener gráficas complementarias del modelo para entender de una forma más profunda su comportamiento probabilístico.
Figura 3. Curva ROC Y AUC
Uno de los retos más grandes en el desarrollo de este proyecto fue encontrar un punto de corte para decidir si una persona tenia una alto o bajo riesgo de sufrir de una enfermedad cardiovascular. Es aquí donde la confianza probabilística entra en juego, y también poner en la balanza cuál situación es mejor: Decirle a los pacientes que tendrán una enfermedad cardiovascular cuando no la tienen, o decirles que no, cuando sí la tienen. En mi caso preferí que mi modelo identificara al mayor numero de personas de sufrir de una enfermedad cardiovascular, con la premisa de que los falsos positivos pueden ser detectados al realizar pruebas clínicas complementarias.
Figura 4. Relación entre probabilidad y punto de corte
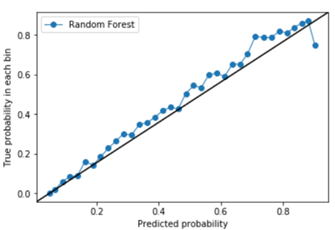
Como apoyo para la selección de este punto de corte nos basamos en el modulo de Youden, gráficas de calibración y los valores de predicción obtenidos.
Figura 5. Curva de calibración obtenida
Debido a que se deseaba que la población pudiera hacer uso de este recurso, se decidió implementar una aplicación web usando la plataforma streamlit. En la cual el usuario podría consultar su indicador de riesgo por medio del llenado de sus FRC. En caso de que su resultado fuera “Alto” se le redireccionaría a la pagina oficial del IMSS.
Resultados
Se logró obtener un algoritmo capaz de indicar si un individuo tiene alto riesgo de sufrir una enfermedad cardiovascular o no, con resultados comparables a los mencionados en la bibliografía consultada.
Tras un análisis del poder predictivo de los datos se encontró que tener un grado de hipertensión y ser mayor de 50 años, puede influir a que seas un individuo con alto riesgo. El colesterol y el índice de masa corporal también son características a considerar, ya que, si sus niveles son más altos de lo normal, también pueden influir a un riesgo mayor. Una identificación temprana de estas variables de riesgo es fundamental para poder prevenir un episodio de enfermedad cardiovascular primario.
¿Esto es todo?
No, este proyecto sirve como precedente para saber si la metodología utilizada es útil y qué tipo de recursos son necesarios para realizar una investigación más elaborada enfocada a la población mexicana.
Cómo siguientes pasos, es indispensable trabajar con un dataset enfocado en la población mexicana, con él se podría hacer un análisis más profundo respecto a cómo las variables de alimentación, sociales, económicas y educacionales afectan a las predicciones. Además de que se podría crear un algoritmo de cálculo de factor de riesgo, enfocado a esta población.
Se desea trabajar más con el algoritmo creado, para mejorar su desempeño de clasificación aplicando feature selection y otros algoritmos de machine learning.
Todavía queda mucho por hacer, pero definitivamente esta experimentación le da dirección a los próximos esfuerzos, te invito a que me sigas, para que puedas seguir leyendo sobre este proyecto.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
El fatídico 11 de marzo del 2020, la OMS declaró la pandemia mundial por COVID-19. Más de 300 días después, hemos decidido hacer público y accesible para el mundo entero el trabajo que hemos venido desarrollando durante más de 8 semanas.
Prepárense, gobiernos e instituciones sanitarias del planeta, pues lo que van a ver en este artículo establecerá los cimientos de un nuevo sistema de vigilancia que permitirá asegurar el cumplimiento de una de las medidas que más se ha repetido durante estos fatídicos 300 días: la distancia de seguridad interpersonal de metro y medio.
Nuestro incombustible grupo, formado por 3 “locos” ingenieros (alguno de ellos en proceso) ha trabajado día y noche para traer la mejor solución posible a este problema.
El proyecto, que comenzó bajo el nombre de WATCHDOG (perro guardián) por la misión inicial que teníamos en mente (un robot con autonomía de movimientos que vigilase el cumplimiento de la distancia de seguridad y que ladrase cada vez que esta fuera quebrantada) iba a ofrecer, más allá del obvio beneficio de un constante recordatorio a las personas de la necesidad de cumplir con la medida de la distancia interpersonal, una herramienta para el mapeo y creación de “puntos calientes” en los que la distancia se incumpliese más a menudo.
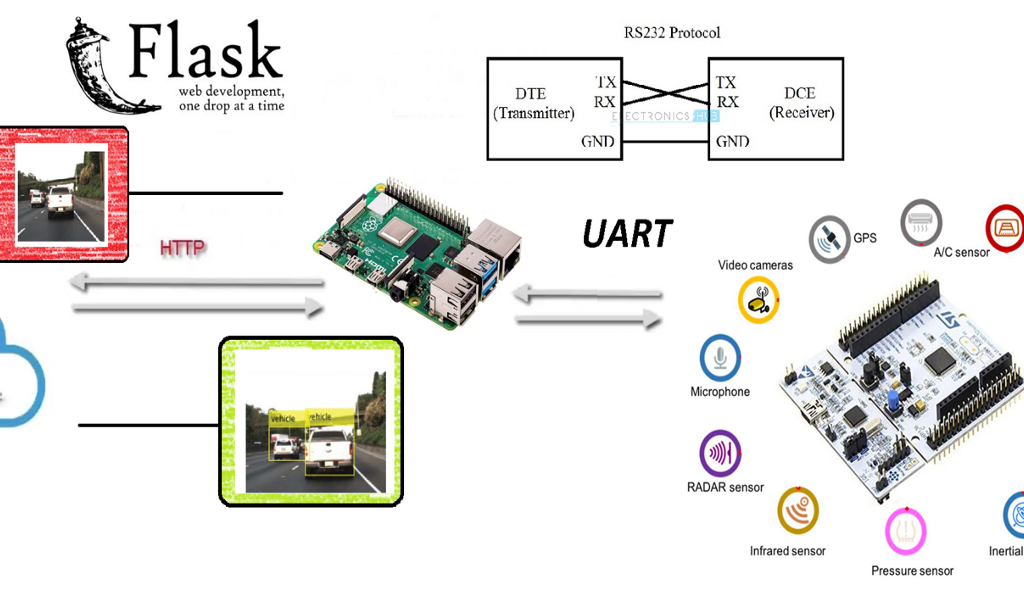
Para todo ello, el equipo ha tratado de crear una convergencia entre los mundos de la electrónica y la Inteligencia Artificial, haciendo uso de los medios más innovadores que tenía a su mano. Con una Raspberry Pi 3, un microcontrolador de bajo nivel equivalente a Arduino Mega, diferentes medios para la comunicación, algoritmos, librerías y redes neuronales convolucionales se ha tratado de alcanzar la solución con la mayor satisfacción posible.
El proyecto
Para el proyecto de Saturdays.AI se ha pensado en desarrollar un proyecto Watchdog (perro guardián) que vigila la distancia mínima recomendada por los protocolos Anti-COVID.
El planteamiento inicial ha sido el de programar un robot capaz de emitir un ladrido cuando la distancia de seguridad (requerido por los protocolos Anti-COVID) fuera quebrantada, enviando los datos adquiridos a un servidor y realizar un mapeo (mapa de calor) en tiempo real.
El objetivo básico del proyecto es converger el mundo OT con el mundo IT, es decir, la convergencia de la electrónica con el de la IA (inteligencia artificial) muy de moda en el mundo IT, utilizando técnicas de Deep Learning, que es una de las ramas del Machine Learning. De hecho, a pesar de que esta primera edición de AI Saturdays Euskadi se haya orientado al Machine Learning en general, hemos decidido profundizar en el Deep Learning por voluntad propia.
Poco a poco se están desarrollando tarjetas electrónicas autónomas que funcionan At The Edge (es decir que la misma tarjeta de control aplica los algoritmos) sin utilizar el Cloud para ello, o sin utilizar una unidad PC más potente para su procesado. Este fenómeno, conocido como Edge Computing, permite aliviar la carga de procesamiento a servidores centrales delegando tareas que puedan ser sencillas pero repetitivas a los nodos externos.
Funcionamiento
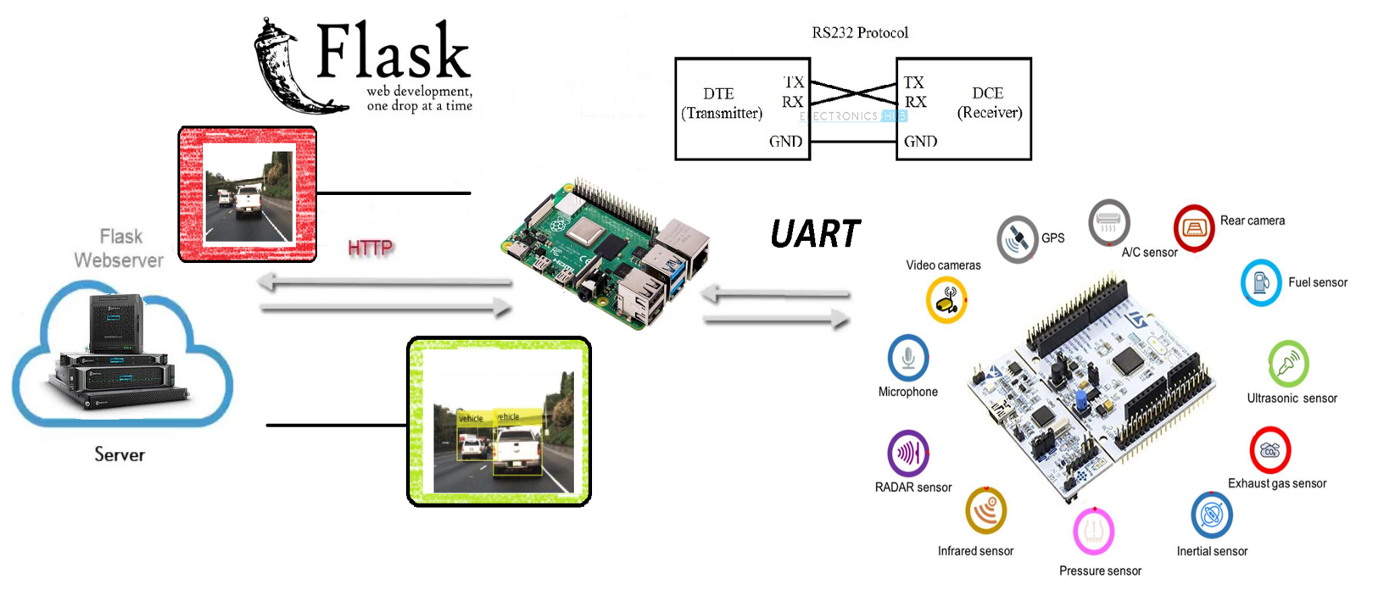
Cuando se detectan 2 personas, manda la posición de la detección y la imagen de violación de la distancia a un servidor Web, creado con Flask.
En lo que al mapeo respecta, la idea inicial era realizar un mapeo SLAM (simultaneous localization and mapping) utilizando un sensor LIDAR o una cámara 3D, pero nos hemos encontrado con limitaciones para hacer un Point Cloud que nos permitiera ejecutar el mapeo. Se describe esta limitación en los Trabajos a Futuro.
Objetivo
El objetivo inicial era plasmar todo el código dentro de una tarjeta Raspberry PI 3 (de aquí en adelante RPi3), pero a pesar de existen librerías para controlar los módulos de entradas y salidas (GPIO), el dispositivo no es lo suficientemente potente para poder procesar todo en tiempo real. Para ello existen módulos dedicados y deterministas que facilitan estas tareas.
Para tratar de cumplir con el objetivo aquí propuesto se ha utilizado un microcontrolador STM32F411RET. Se trata de un microcontrolador de gama baja equivalente a un Arduino Mega, pero con un sistema operativo de tiempo real (Real Time Operating System o RTOS), al ser determinista se tiene el control del timing y tareas, pudiendo tener un mayor control para la adquisición de datos y respuesta de los actuadores.
Se decidió utilizar esta tecnología por la gran cantidad de librerías robustas que existen para controlar los periféricos.
Algoritmo YOLOv4
El algoritmo final que se ha usado ha sido por goleada YOLO (para nuestro caso), respecto a otros conocidos como SSD (Single Shot Detection) o la más precisa de todas las tecnologías RESNET.
El reto en este apartado ha sido buscar la tecnología que mejor se adapta al tiempo real y nos basamos en las reglas de oro que dijo uno de los mentores:
1. ¿Qué pasa en el mercado? ¿Cuál es la tendencia del mismo? ¿Qué tipo de arquitectura es más viable con las restricciones presupuestarias y de tiempo que tenéis?
2. Mirad lo que hacen los grandes. ¿Podemos pensar igual a ellos? Es decir, ¿tenemos que plantearnos entrenar redes extremadamente complejas, o tenemos que poner los pies en la tierra y plantear ejemplos más rápidos para construir un Producto Mínimo Viable (MVP)?
3. ¡Adáptate!
En esta fórmula, el resultado de 1+1 en ingeniería sería determinista pero en la vida real el resultado es estocástico, así que depende. ?
Este proyecto está acotado para capacidad computacional de gama media y se ha querido estrujar al máximo desde ese punto de vista. Por ello, el mejor algoritmo que encontramos, el cual estaba puramente escrito en C (siendo un terrible reto el aplicar funciones matemáticas a pelo; aprovechamos para agradecer a Joseph Redmon) es lo más rápido comparado con librerías escritas a mayor alto nivel (TensorFlow, pyTorch).
Como curiosidad, usando la versión para embebidos de SSD se llega a unos 18 Frames por Segundo (FPS) comparado con YOLO, que llega a 24 FPS. Sin haber añadido telecomunicaciones nos dimos cuenta cuál era el camino a seguir, pero se encontraron todo tipo de resoluciones de las distintas tecnologías.
“Cabe destacar que para el equipo, el algoritmo o tecnología más completo y adaptado si se tuviera un poco más de capacidad computacional serían RNN o FAST-RNN, ya que de una tirada no solo tendríamos la posición de los objetos, sino cada pixel de la imagen estaría vinculado a una clase y con esto se podría dotar al proyecto de la capacidad de contextualizarse en el entorno. Y esto nos llevaría a más poder de adaptación, teniendo en particular un efecto positivo para el ámbito del Machine Learning, donde se dispondría de más DATO al que poder darle valor sacado del entorno.”
Si se tiene aún más curiosidad al respecto, os dejamos este link.
Como esto se extendería hasta el infinito, no se van a explicar los detalles del funcionamiento a fondo; se adjunta un link donde se explica detalladamente el algoritmo en su versión v3. La diferencia está en que en la versión v4 aumenta la precisión pero en su versión tiny la velocidad se mantiene constante.
EDA: Y ahora… ¡Metemos los “Datos” de nuestros sensores a la caja negra!
La analogía del “EDA” realizado en nuestro proyecto de Deep Learning tendría que ver, entre otros, con limpieza y preprocesamientos hechos de las imágenes obtenidas. El primer preprocesamiento ejecutado sería el que ofrece la función BLOB de OpenCV que reduce la escala de 8 bits (255 RGB) a escala porcentual unitaria.
Este detalle es muy importante ya que pasa el resultado de cualquier cámara a la que el algoritmo necesita de entrada. ¿Lo malo? Que se vuelen datos de coma flotante y eso requiere más gasto computacional pero de ese problema ya se encargaron sus autores.
El “tuning” de los parámetros en este aspecto que hemos hecho ha sido pasar la imagen de entrada a la escala más pequeña (316 x 316 píxeles).
Habiendo hecho este primer paso, la imagen pasará por múltiples filtros internos cambiando la dimensionalidad de la entrada y readaptando al mejor estilo de Nolan con películas del calibre de Tenet o Inception. ¿El resultado?
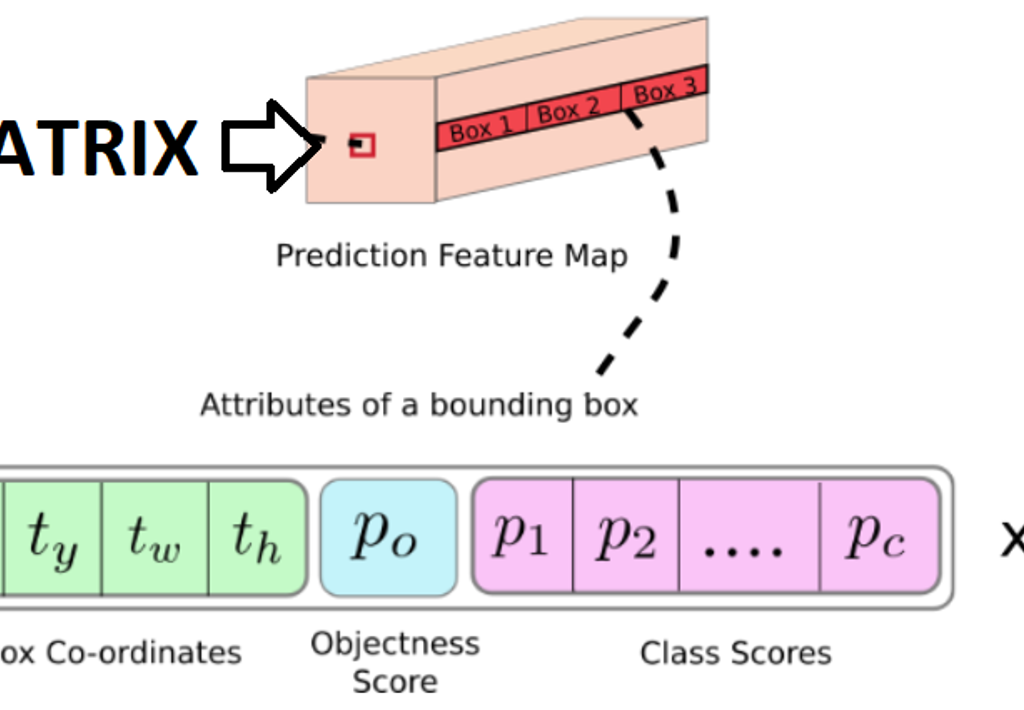
El algoritmo YOLOv4 entrega los datos de la imagen en una matriz compuesta de 13x13x (A x ((B+P) + C)), siendo:
A: La cantidad de anchor boxes (siendo una anchor box un “espacio en el que se puede detectar la posible presencia de un objeto”).
B: Las coordenadas de posición del objeto.
P: La probabilidad de confianza de que hay objeto.
C: Las clases que deseamos identificar y su respectiva probabilidad.
Dentro del archivo “coco.names” están las clases asociadas a sus respectivos nombres pero de este resultado se filtran “únicamente” los resultados en la que la clase es una persona
? ¿Y por qué no reentrenar la red aplicando transfer learning?
Mucho ojo, ya que nuestro equipo se peleó para mejorar la respuesta de este algoritmo para aumentar y darle más valor a la matriz de salida de la versión tiny.
Los resultados, por desgracia, no fueron los esperados. El mapa de características que se crea en estos modelos se basa en cantidades muy grandes de datos y de mucha variedad en el tema de la visión, donde son necesarias grandes cantidades (10.000 imágenes) para que el procesamiento pueda ser fluido. Y es cierto, si se reentrenara partiendo de transfer learning nos ahorraríamos muchas imágenes de entrada, pero también hay que tener en cuenta las clases de objetos que se quieran reconocer. Mientras más clases de objetos haya el mapa de características aprende mejor a separar cada clase.
Por ello, se han usado los pesos de la versión COCO para el algoritmo YOLO, ya que era la más similar para nuestro caso.
A continuación, se aplica un segundo filtro, usado para aplicar el BBOX de los distintos anchor boxes para ver cuál es el mejor.
Estos pasos anteriores formarían el proceso EDA como tal. Sin embargo, y en comparación con un proceso de ML, el filtro que se aplicaría dependería del grado de confianza que se tenga de la detección de un objeto, mientras que en un proceso de ML la “manipulación” se suele hacer sobre el mismo dato.
Todo esto se ensambla en una función llamada “Impure Detector” que nos va a devolver los datos que más nos interesan en una lista de Python de la siguiente forma:
[Coordenadas de las Personas, Index_Impuros]
RPI3
La Raspberry 3B+ cuenta con el sistema operativo Raspbian y librerías OpenCV (4.1.0.22).
El funcionamiento de manera general es sencillo: Se procesan los datos de la imagen y se reenvían a un servidor Web Flask instalado en un PC.
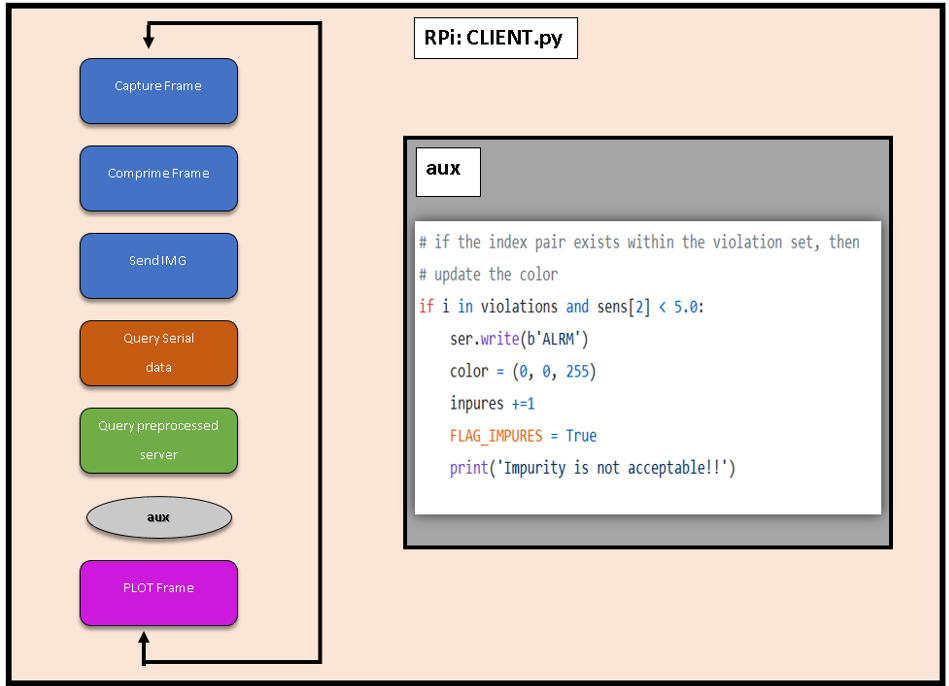
Podemos ver más detalles sobre el código de la RPi en CLIENT.py:
● Comunicación Serie
Tenemos una comunicación serie con el microcontrolador. Después de unas cuantas pruebas nos hemos dado cuenta de que, a la velocidad máxima con la que puede trabajar la RPi con python es con un BaudRate 115200 Bits/s, lo que limita la capacidad de mejorar el tiempo de espera entre Cliente-Servidor. Anotamos este aspecto como Trabajo futuro.
● MQTT
También se ha usado MQTT para enviar los datos respecto a la “violación” de la distancia de seguridad” a otro servidor. Sin embargo, como se ha mencionado antes, no se ha llegado a hacer un mapa de calor con el área de los “delitos de distancia de seguridad” a tiempo real, pero conseguimos enviar los datos e insertarlos en un archivo remoto, guardándolos en un fichero CSV dentro del servidor.
Un trabajo a futuro al que, por desgracia no pudimos llegar, era el de generar un pequeño script para graficar o plotear esos datos.
El diagrama de bloques obtenido para nuestro proceso.
Las imágenes son bastante problemáticas ya que enviar los paquetes de información tan largos y en la que la que el orden influya es complicado, es necesario indexarlos. Se han probado muchas, pero muchas metodologías distintas y la que mejores resultados ha dado ha sido usando una REST API del servidor.
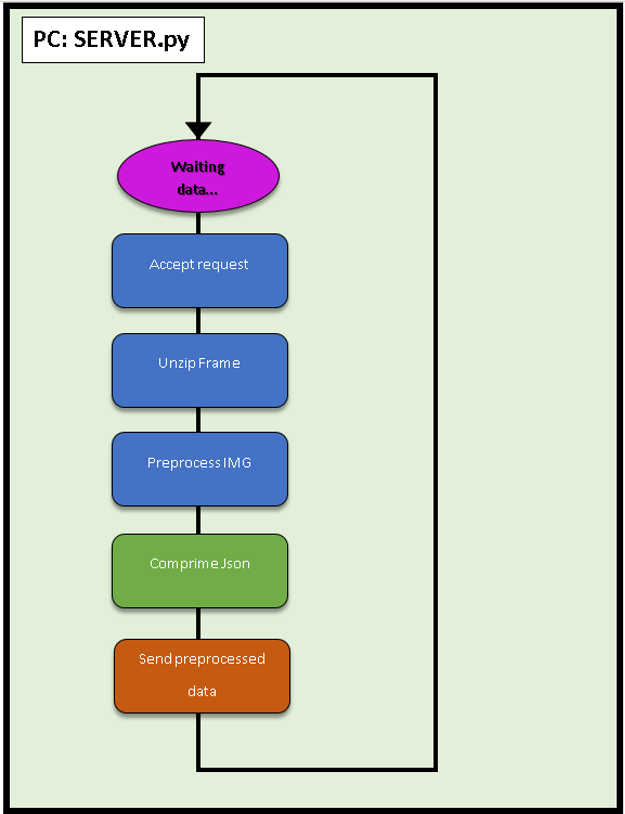
Servidor FLASK:
En Internet se encuentra de todo excepto lo que realmente se quiere, por lo tanto hemos tenido que desarrollar el sistema de envío de imágenes comprimidas por HTTP.
Para ello se han utilizado las funciones de imágenes por excelencia, recogidas en el paquete Open Source OpenCV utilizando un buffer dinámico, evitando la escritura en el disco. Esto se debe ya que por experiencia se ha visto que, a la larga, si no se cuidan, los servidores “envejecen” o “degeneran”. Esto evita por ejemplo forzar los soportes de memoria flash y controlar los ciclos de lectura/escritura aplicados.
Después de emplear OpenCV, nuestro sistema crea la captura en un buffer, lo comprime y se envía al servidor, quien lo descomprime y escribe a disco, dejándolo preparado para su almacenamiento y/o post procesamiento. Este envío se hace en formato JSON ya que se tenían errores al enviarlos en otros formatos.
? ¿Cómo enviar datos que son variables en el tiempo de forma constante?
Normalmente, para que dos personas y/o máquinas se comuniquen tienen que hablar el mismo idioma. En Machine Learning, además, los datos suelen enviarse en bloques constantes de información y de tamaño reducido. En nuestro caso, los pasos que va a ejecutar nuestro cliente son secuenciales y si se tropieza en algún punto todo se va al traste.
Por tanto, se han creado datos “ficticios” para enviarlos como mínimo para que todas las piezas del proyecto puedan funcionar sincronizadamente y en armonía.
Los “impuros” nos van a marcar el index del objeto al que esté pecando pero en los negativos no se va a fijar. Por tanto, esa es la razón por la que el proyecto consigue funcionar sin que se note este pequeño bug.
Esquema general del funcionamiento del servidor Flask.
Microcontrolador
Se ha elegido este microcontrolador (STM32F411RET) por una opción que un Arduino no ofrecía:
La programación de distintas subtareas para que se ejecuten de manera concurrente además de las interrupciones.
Programar en el STMCubeIde nos da la opción de tener la facilidad de programación de Arduino, así como librerías de entornos más industriales.
A diferencia del Arduino en el que el uso de multitareas metiéndolas en un proceso Round Robin es muy complejo, sumado a la limitación de la cantidad de temporizadores o timers que ofrece Arduino Uno 3, con el STM32F404RE estos problemas para insertarlos en la industria se mitigan.
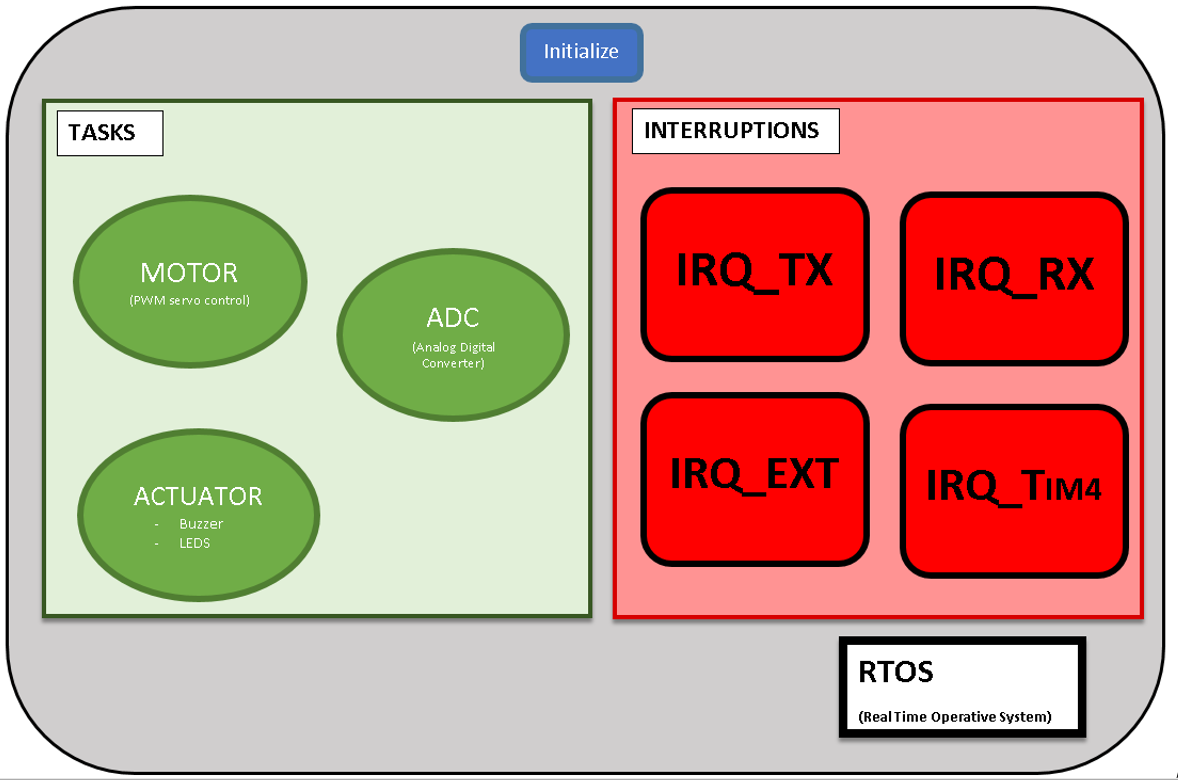
Por tanto, una vez que el micro haya ejecutado la configuración inicial (tareas, interrupciones, timers…) el programa empezará a ejecutar las tareas aplicando un Round Robin, las cuales se agrupan en el siguiente esquema:
Esquema de las Tareas o Programas Concurrentes existentes.
Dentro de las tareas o programas concurrentes existentes existen tres:
1. ADC
Este subprograma se encarga de leer las entradas digitales y procesarlas en 10–12 bits; aspecto que en una lectura por Arduino solo ofrecerá 8 bits de conversión.
Una vez acabadas una por una en orden secuencial, insertará los datos aplicando sus respectivas conversiones en un vector global int32, siendo el motivo para guardarlos como int y no en float que la cantidad de espacio que ocupan se duplicaría (de 32 a 64 bits, por la coma flotante).
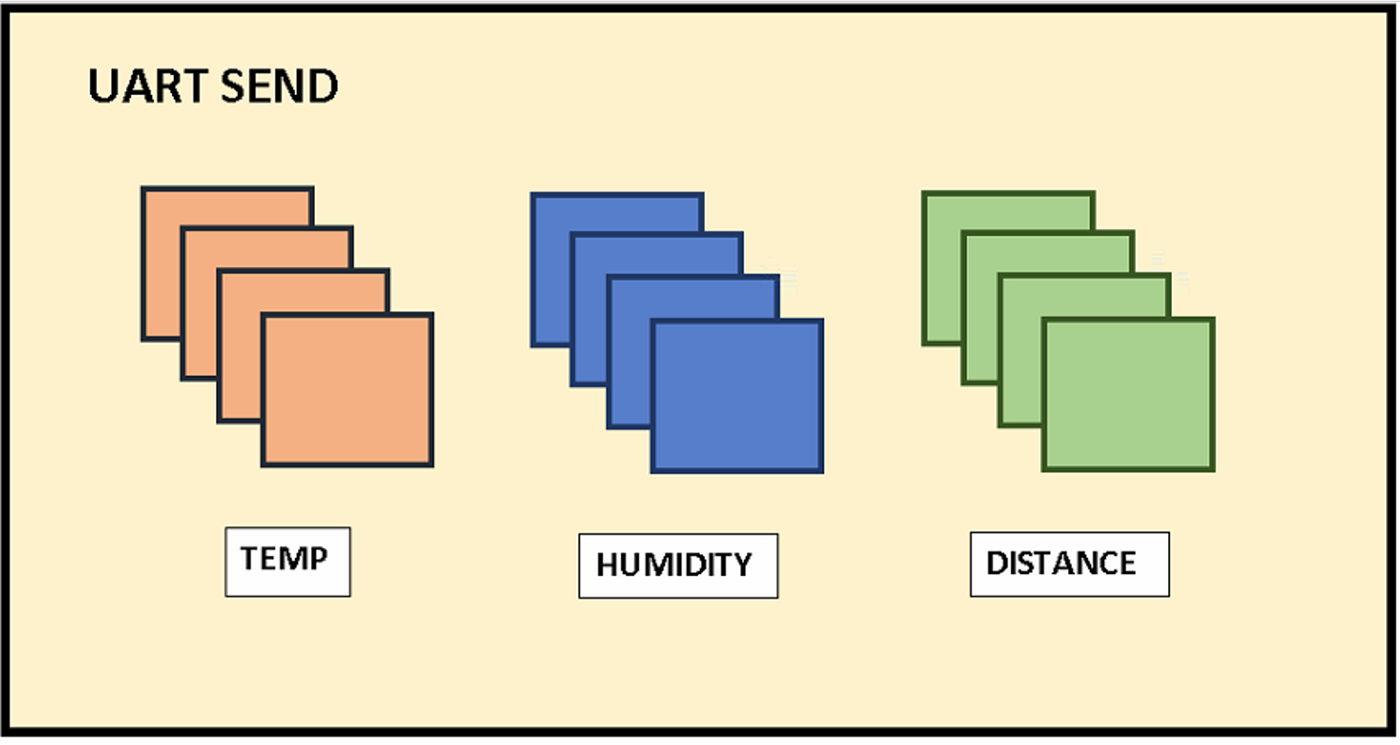
Como se puede apreciar en la imagen del envío del Transmisor-Receptor Asíncrono Universal (UART), se envían 4 datos por cada sensor. El último dato es el que quedaría detrás de la coma flotante para su posterior preprocesamiento sencillo en la RPi.
Ejemplo de esto sería recibir del sensor de distancia un valor de 1004 y transformarlo a 100, 4 en este caso simulando metros de profundidad.
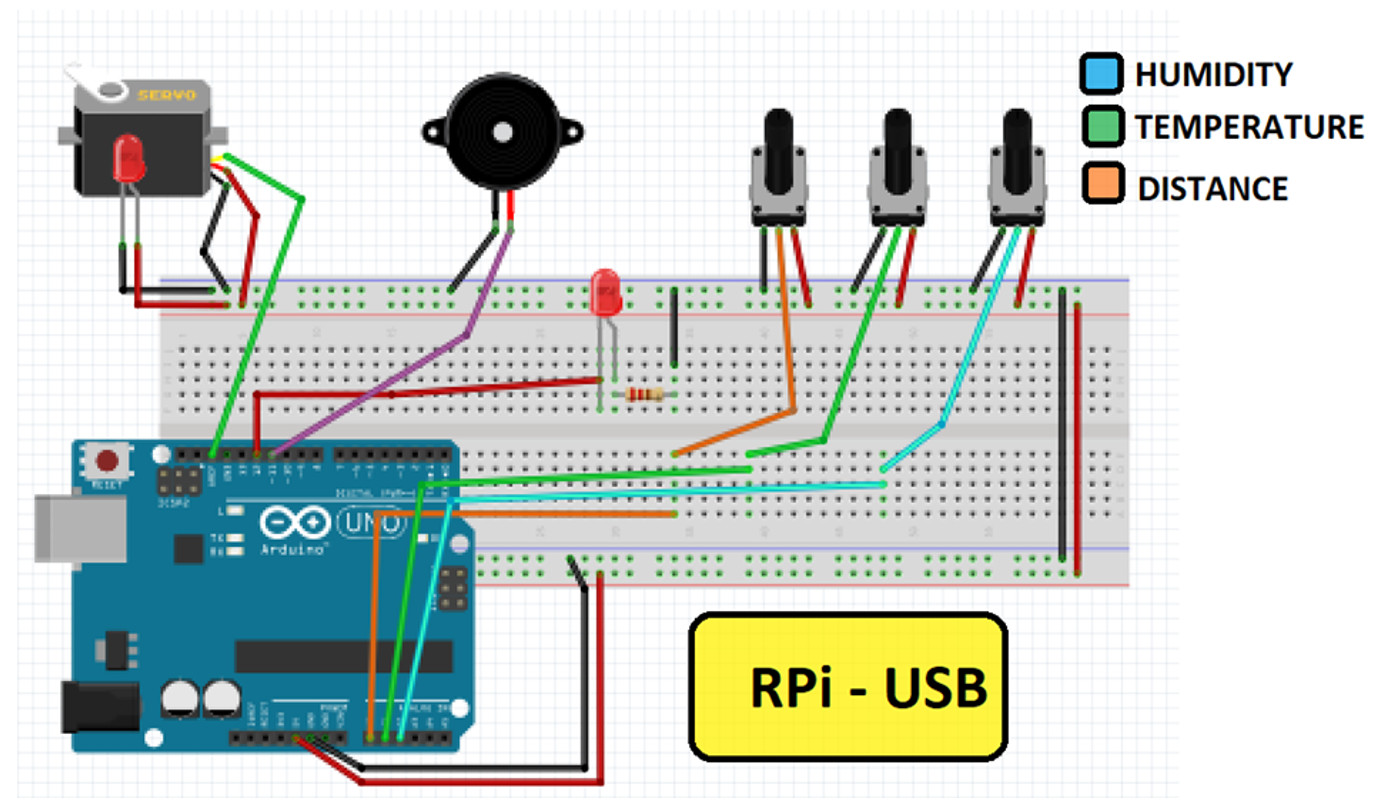
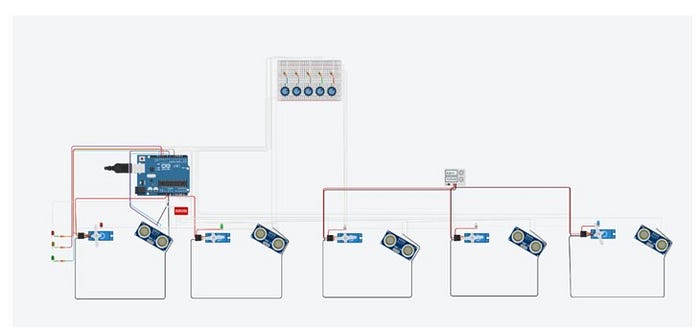
Sensores conectados por UART al microcontrolador
2. ACTUATORS
Dentro de los actuadores podemos encontrar que se conmutarán los estados de las salidas digitales pertenecientes al Buzzer y LED_EXT encargados de dotar al robot de notificar al entorno de manera acústica y visual.
No se ha añadido el actuador del motor porque se cree que separado se entiende mejor a la hora de distribuir el código.
3. MOTOR
Los servomotores trabajan entre 500 y 2500 ticks por lo que nuestra tarea TASK_MOTOR se aprovechará de las interrupciones del timer_4 para cambiar su valor ON/OFF.
Además, se ha añadido un acumulador, de tal manera que si mientras se detecta una violación de la distancia de seguridad y antes de que la función se apague se vuelve a recibir una interrupción por la violación de distancia, aumentará el tiempo de espera 5 segundos más en esa posición. Con esto nos aseguramos de que hay un mayor control de las presencias detectadas.
Interrupciones
Las interrupciones son peticiones síncronas o asíncronas al reloj en la que el procesador va a dejar de lado la tarea que esté realizando para centrarse en la interrupción.
Nosotros hemos definido 4 tipos de interrupciones.
1. IRQ_EXT:
Es la interrupción externa por botón a la que se va a acceder en caso de que haya un error tanto de comunicación o de cualquier otro tipo para resetear la configuración del microcontrolador sin que resetee todo. Reenviará la información y nos avisará enviando un “DONE” por el puerto serial.
2. IRQ_TIM4
Se ha configurado el timer_4 del microcontrolador para que se ejecute cada 1 MHz.
En resumen, para que tardemos 50 Hz que es la velocidad del servomotor tenemos que añadir un registro contador de 0–2000 unidades para que entre en la interrupción cada 50 Hz.
Es decir, que en cada 200 ms recibiremos 20000 ticks. O dicho de otra manera, cada 200 milisegundos nuestro micro interrumpirá la interrupción de ese timer.
3. IRQ_TX:
Esta interrupción únicamente va a encender un LED interno del microcontrolador para saber de manera rápida que todo está funcionando correctamente.
En la figura inferior, además de ver la distribución de los pines se puede ver el pin del LED interno así como el pulsador interno del microcontrolador.
Distribución de los pines del proyecto.
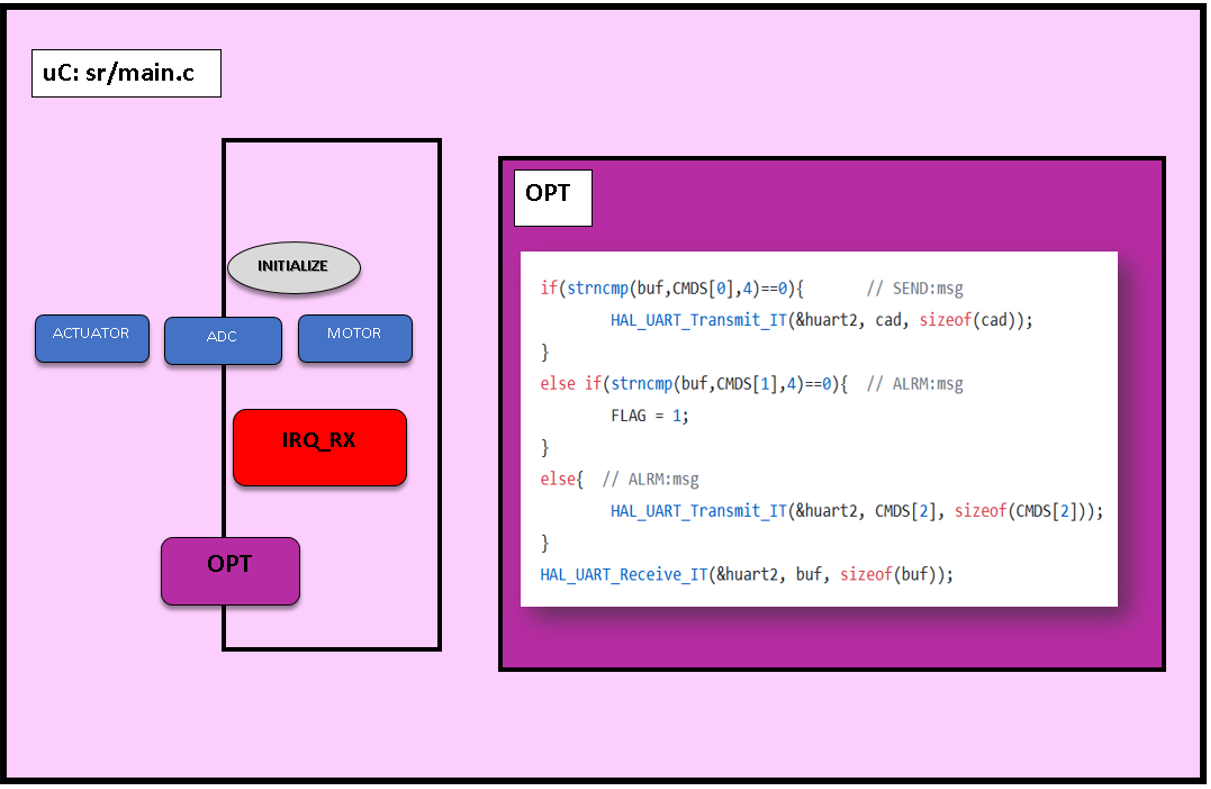
4. IRQ_RX:
A pesar de estar la última en la lista, es la interrupción más importante. Para que la RPi actúe como “cabeza pensante”, es necesaria una interrupción que esté atenta a cualquier señal asíncrona que reciba del microPC y que alerte a la RPi.
Los comandos que se van a enviar desde la RPi son dos:
“SEND”
“ALRM”
Cuando recibamos SEND el microcontrolador enviará los datos que tenga en ese momento en el vector “sens”.
Si recibe ALRM ejecutará los actuadores y si antes de que se acabe vuelve a recibir una entrada ALRM, aumentará el tiempo del mismo.
Figura que muestra el envío de señales a las tareas.
Conclusiones
Se trata de un proyecto aparentemente simple, pero que detrás de todo existe un ecosistema muy complejo al que se le quería meter mano. Solo hay que ver la arquitectura de la infraestructura que ha quedado:
Sensores – Unidad del Microcontrolador (MCU).
MCU – RPi.
RPi – PC: Uso de protocolo HTTP con peticiones POST al servidor web (REST API montada en Flask).
Aunque el objetivo era aplicar temas de Machine Learning, estos temas requieren de una determinada arquitectura y funciones para comunicaciones, tratamiento de imágenes etc. El tema de SLAM + ML se ha quedado a las puertas pero sí se han dado pasos para poder continuar con la misma.
Y a la larga, el objetivo que se había planteado que era aplicar esta tecnología al mundo real aparte de la IT y darle una aplicación más industrial, creemos que aunque no se haya logrado, se está un paso más cerca con el uso de estas “herramientas caseras”.
Como reflexión obtenido, hemos detectado que si se va a empezar a usar el Cloud Computing, para las próximas generaciones hará falta un cifrado de la información muy densa que se envíe (aunque se sacrifique la latencia), ya que es un tema muy serio al que poca importancia se le está dando actualmente.
Trabajo a futuro
Hemos detectado diferentes tareas como trabajo futuro de cara a este proyecto:
El mapeo del entorno, así como la geolocalización indoor. Hemos realizado pruebas con el sistema GPS que adquirimos, pero este sistema requiere que esté en un espacio abierto para su funcionamiento. Para facilitar esta geolocalización con sistemas alternativas, consideraríamos el uso de geolocalización indoor (mediante AprilTags, Bluetooth de Baja Energía o BLE, etc.).
La mejora del microcontrolador, aspecto que podría ayudar a mejorar en más del doble la velocidad de procesamiento de la RPI, lo que nos podría ayudar a compensar el retardo generado en la comunicación Cliente-Servidor.
La creación de un script de plotting para graficar los datos obtenidos mediante la conexión MQTT.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
El estrés: una ‘epidemia’ silenciosa que puede afectar a cualquier persona durante la era moderna, ahora es más notoria debido a la mayor crisis sanitaria enfrentada durante este siglo. Los niveles de preocupación, impacto económico y emocional que han tenido que afrontar las personas han sido factores que han impactado no solo la salud física también la mental de millones de personas.
En este trabajo de inteligencia artificial (ciencia de datos), se realiza un esfuerzo para analizar, predecir y determinar, si una persona está estresada con el uso de sus mensajes a través de la red social de Twitter.
Problema general
¿Es posible que una máquina pueda determinar si una persona está estresada solo con la expresión escrita?
Motivación
Social: ayudar a identificar y reconocer el estrés durante la crisis sanitaria para así conocer el estado emocional de las personas sin necesidad de un estudio en persona
Profesional: obtener, extender y aplicar los conocimientos sobre ciencia de datos e inteligencia artificial, en el análisis de lenguaje humano y en reconocimiento de emociones
Metodología
La metodología con la que se trabajó en este proyecto está basada en la metodología tradicional de CRISP-DM [1]. A continuación se muestra el diagrama general de los pasos que se llevaron a cabo en este trabajo.
Diseño del modelo de reconocimiento:
Recolección de datos
Para llevar a cabo el análisis se recolectaron datos de tweets de 3 diferentes ciudades para poder tener muestras variadas y esperar resultados diferentes. Las ciudades fueron elegidas solamente tomando en cuenta que fueran ciudades grandes en diferentes países angloparlantes.
Las ciudades de las que se obtuvieron los datos fueron las siguientes:
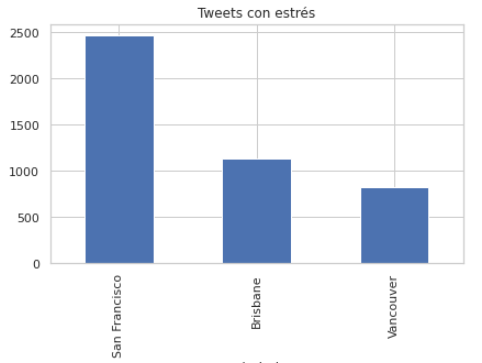
Brisbane, Australia (2225 tweets)
San Francisco, Estados Unidos (5000 tweets)
Vancouver, Canadá (1699 tweets)
Cabe mencionar que los datos fueron recolectados el 24 de octubre y los tweets tienen fecha máxima de publicación una semana anterior a la fecha de recolección y mínima del mismo día de la recolección.
Las palabras claves que se utilizaron para la recolección fueron las siguientes:
covid OR COVID OR coronavirus OR corona OR coronavirus OR #coronavirus OR #covid19 OR covid19 OR sarscov2 OR #covid-19 OR #sarscov2 OR sars OR cov2 OR sars OR #quarantine OR pandemic OR #pandemic OR #2019ncov OR 2019ncov OR quarantine OR lockdown OR #lockdown OR social distancing OR #socialdistancing OR #COVID OR #covid”
La estructura de los datos es idéntica para los 3 datasets. Cada dataset está organizado en 3 columnas:
user_location: Ubicación aproximada del usuario (si su ubicación está activada).
date: Fecha de publicación del tweet.
text: Texto del tweet.
Los datos anonimizados se obtuvieron a través de la API de Twitter a través de un script de Python utilizando Tweepy [2].
Etiquetado
Para el etiquetado de los datos, fue utilizada una herramienta llamada TensiStrength, la cuál está desarrollada en Java, y ayuda a evaluar el nivel de relajación o ansiedad que se puede encontrar en un texto sencillo. Esta herramienta funciona por medio de diccionarios de emociones en los cuales se asignan valores a las palabras positivas o negativas y a su vez también cuenta con un diccionario de palabras (booster words) que incrementan el valor de la expresión/emoción.
TensiStrength logra catalogar los textos de dos maneras disponibles, binaria o ternaria; la ternaria los clasifica en 1, 0, -1, positivo, neutral y negativo respectivamente. El esquema para la clasificación de emociones utilizado en nuestro modelo, utiliza la clasificación de tipo binaria, que consiste en usar las etiquetas 1 y 0, las cuales corresponden a “estrés” y “no estrés”.
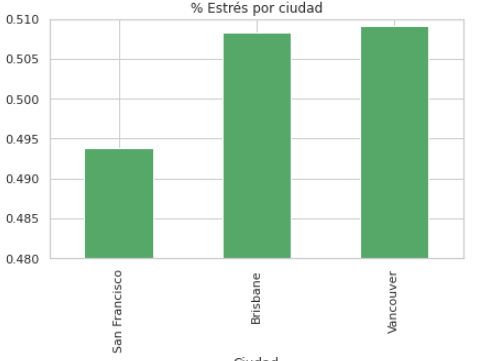
Las clases se encuentran distribuidas con un porcentaje de: Tweets con estrés = 49.972% Tweets sin estrés = 50.028%
Exploración de los datos:
Cantidad de tweets con estrés.
Porcentaje de estrés por ciudad, representa la cantidad de tweets con estrés respecto al total de tweets.
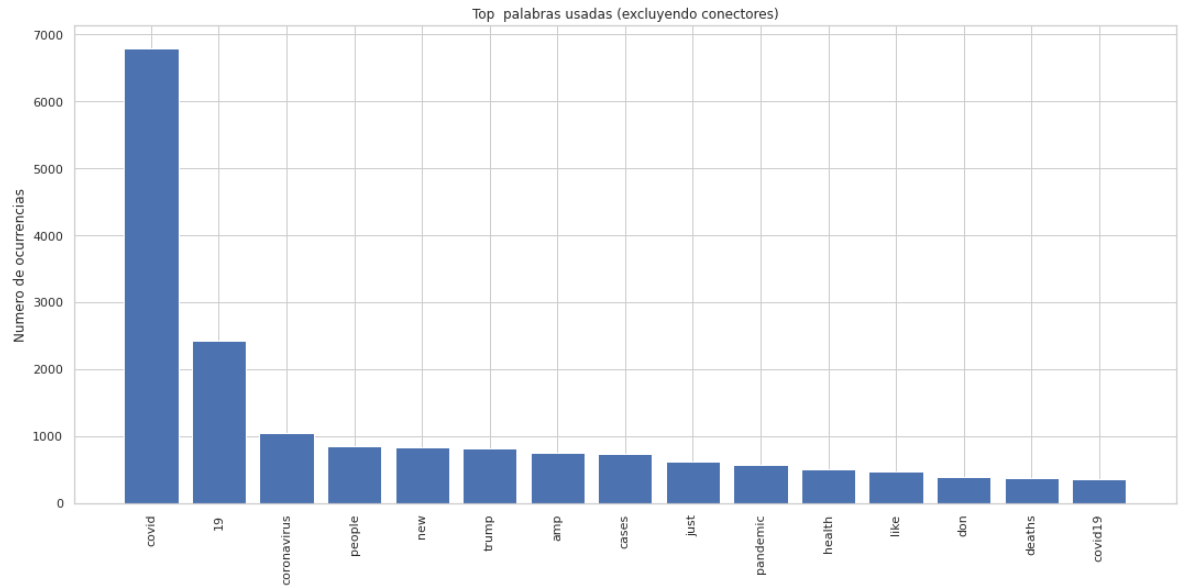
Palabras más usadas en los tweets, excluyendo conectores.
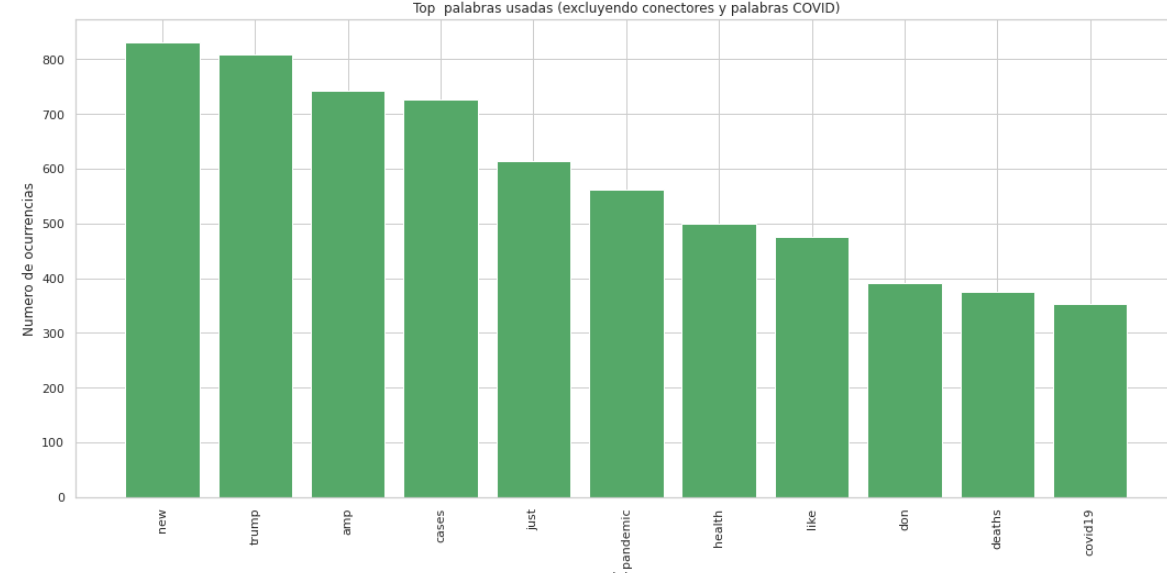
Palabras más usadas en los tweets, excluyendo conectores y palabras relacionadas con Covid.
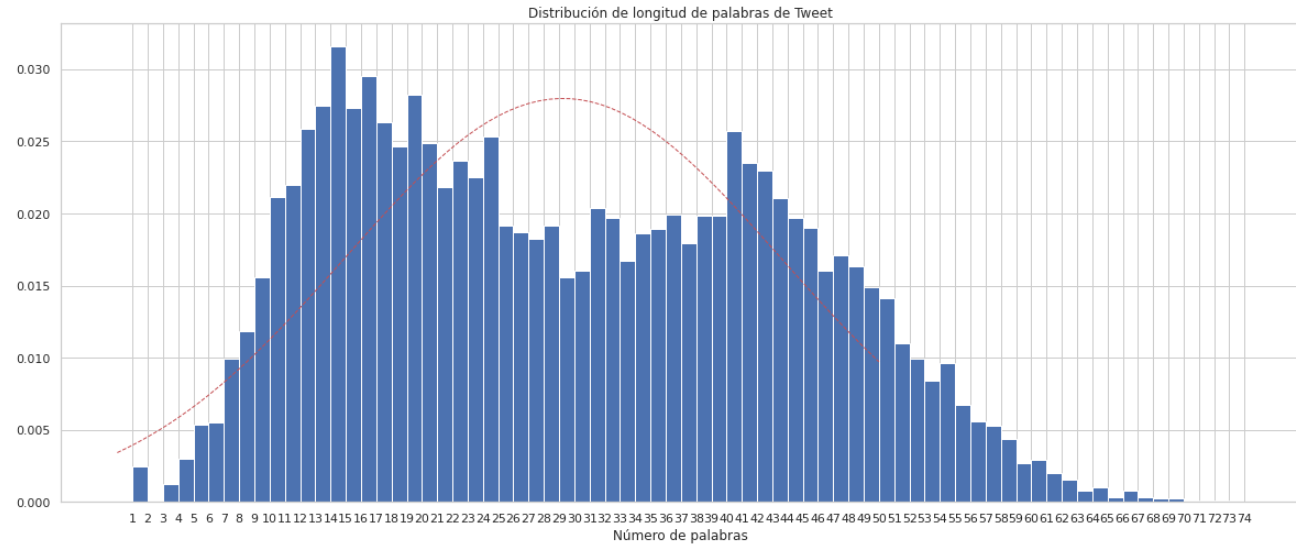
Distribución de las palabras en los Tweets según su longitud
Pre-procesamiento de los datos:
Después de recolectar los datos, se llevó a cabo un pre-procesamiento con el fin de que los datos se pudieran utilizar para entrenar un modelo clasificador. Este paso es uno de los más importantes y es aquel que comúnmente consume más tiempo en un proyecto de aprendizaje de máquina.
Reducción de Ruido: se eliminaron espacios extras, carácteres especiales y ligas a otras páginas.
Normalización: los carácteres se transformaron a minúsculas, se eliminaron puntuaciones y se expandieron las contracciones.
Eliminación de palabras vacías o Stopwords: se removieron aquellas palabras que no tienen un significado por sí mismas (artículos, pronombres, preposiciones y algunos verbos)
Lematización: se llevó a cabo una lematización, la cual consiste en convertir la palabra a su forma base (i.e. mesas a mesa).
Tokenización: finalmente los textos se separaron en palabras, también llamados tokens.
Antes del pre-procesamiento, el texto se visualiza de la siguiente manera:
Posterior a la limpieza y previo a la tokenización, el texto se visualiza de la siguiente manera:
Visualización de datos
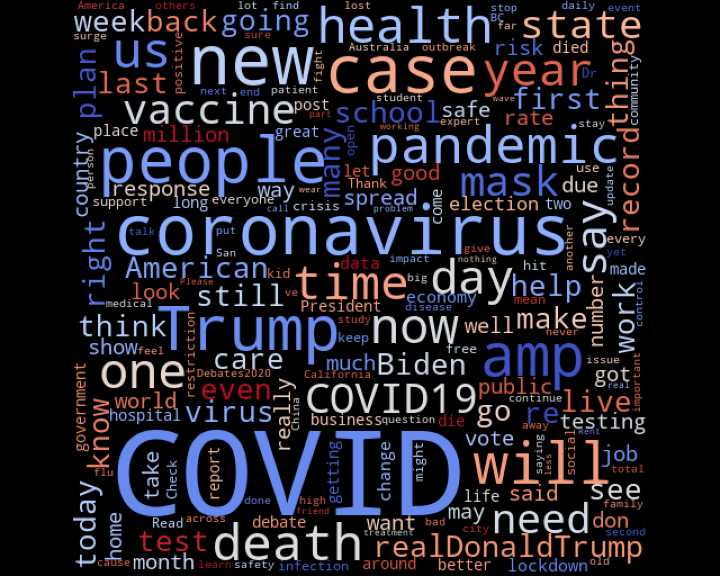
Fue realizada por medio de nubes de palabras, en general y dividiendo los datos por clase.
Palabras más recurrentes en general:
Palabras más recurrentes dentro de los datos clasificados como SIN estrés
Palabras más recurrentes dentro de los datos clasificados como CON estrés
LDA (Latent Dirichlet Allocation)
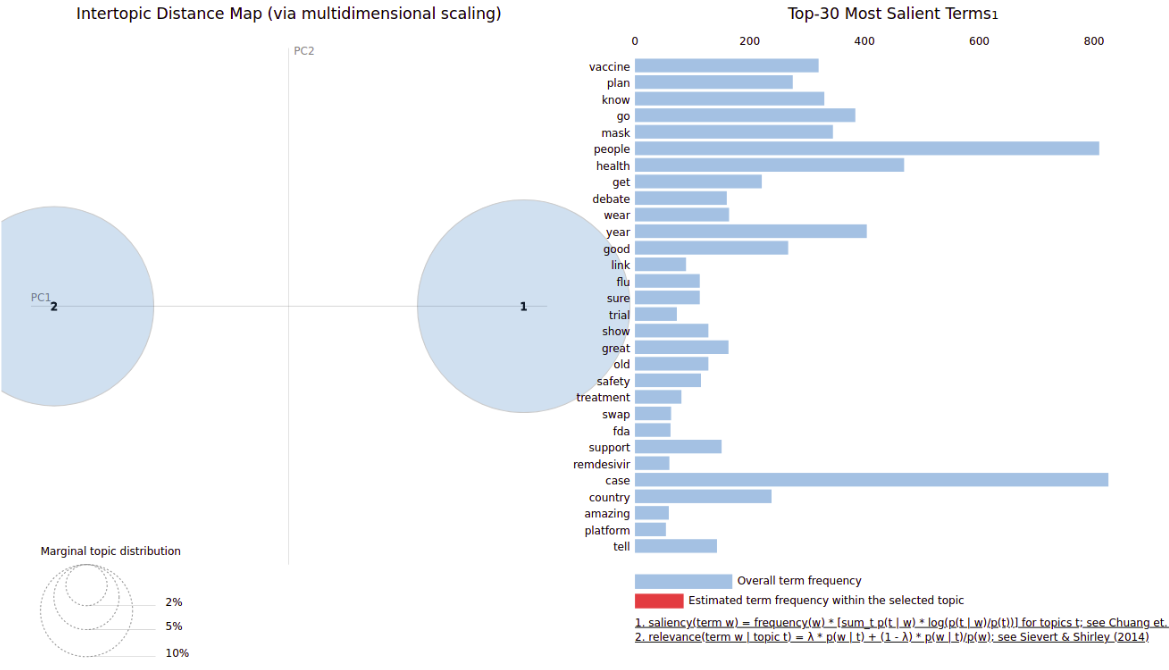
Se utilizó un clasificador de modelo generativo LDA (no supervisado), que permite que a partir de una bolsa de palabras, se genere un conjunto de observaciones que puedan ser explicadas por algunas de las partes de los datos que son similares o que tienen cierta concordancia. Este es un modelo de categorías y fue presentado como un modelo de grafos para descubrir categorías por David Blei, Andrew Ng y Michael Jordan en 2002.
En nuestro trabajo se utilizó a partir de de la vectorización de la data tratada y limpia de los tweets obtenidos, una tokenización y generando una vectorización de las palabras. Obteniendo un clasificador de 2 tópicos, en las cuales sus principales palabras fueron:
Tópico 0: Covid case new health vaccine death year trump plan day
Tópico 1: Covid people trump go new case mask know say need
y utilizando la librería pyLDAvis se obtuvo el visualizador:
Modelado
Para este proyecto se evaluaron cinco modelos de Machine Learning. Como modelo base se utilizó Naive Bayes y se comparó con:
Regresión Logística
K-Nearest Neighbors
Random Forest
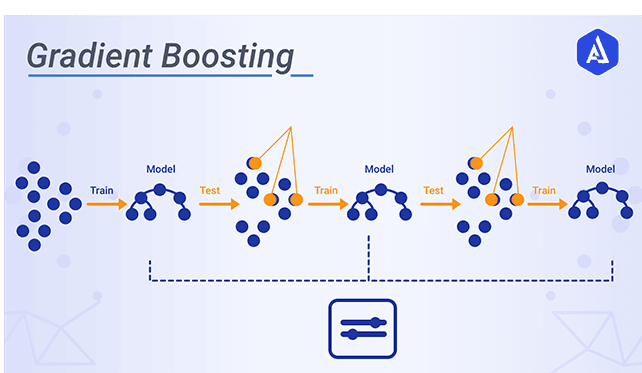
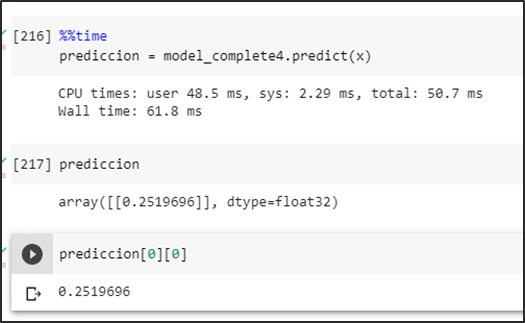
Gradient Boosting.
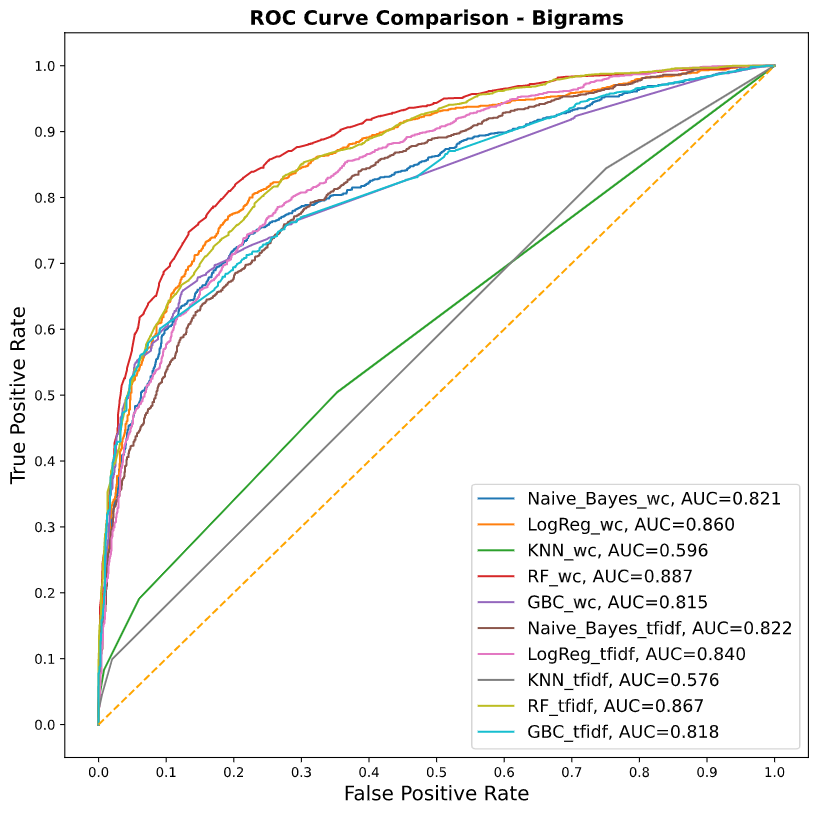
Para la vectorización [4] de los tweets se evaluaron 2 técnicas: Bag of Words y TF-IDF (term frequency — inverse document frequency) y dos estrategias para sus n-gramas: Bigrama y Trigramas [5].
Los resultados se midieron por medio del AUC (Area Bajo la Curva) y se evaluaron con validación cruzada (k = 10). Tanto el preprocesamiento, entrenamiento y evaluación del modelo se llevaron a cabo dentro de un “pipeline” creado dentro de una clase utilizando el lenguaje de programación de Python.
Nivel de precisión para cada modelo implementado con “Bigrams”
Nivel de precisión para cada modelo implementado con “Trigrams”
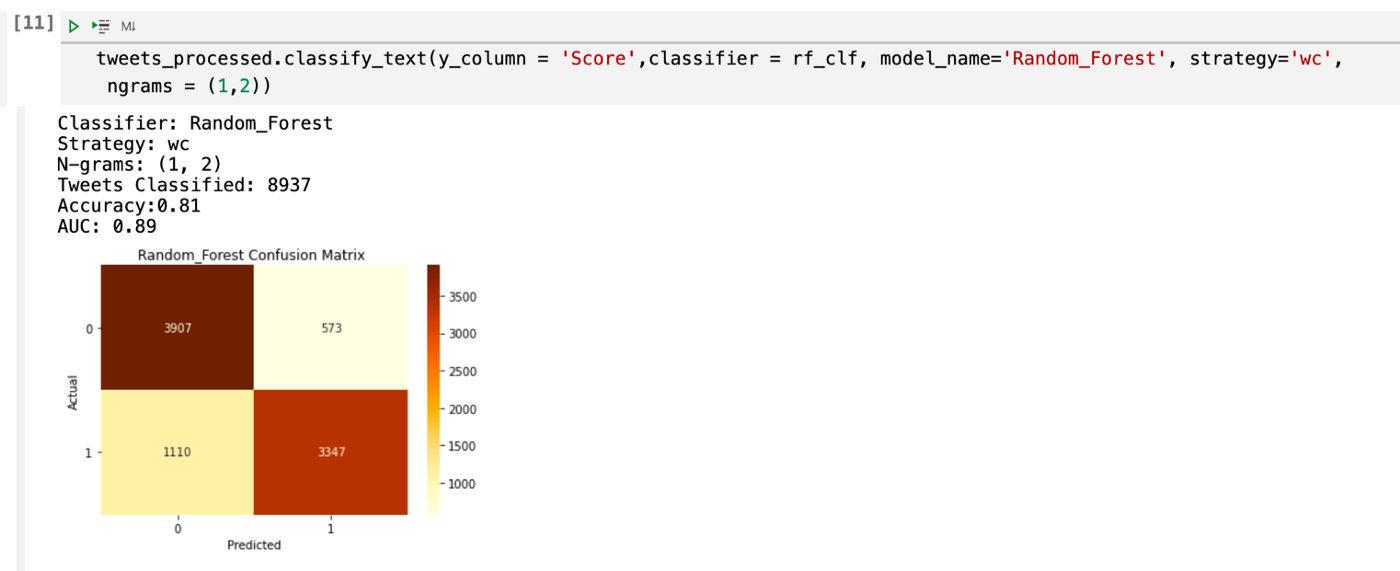
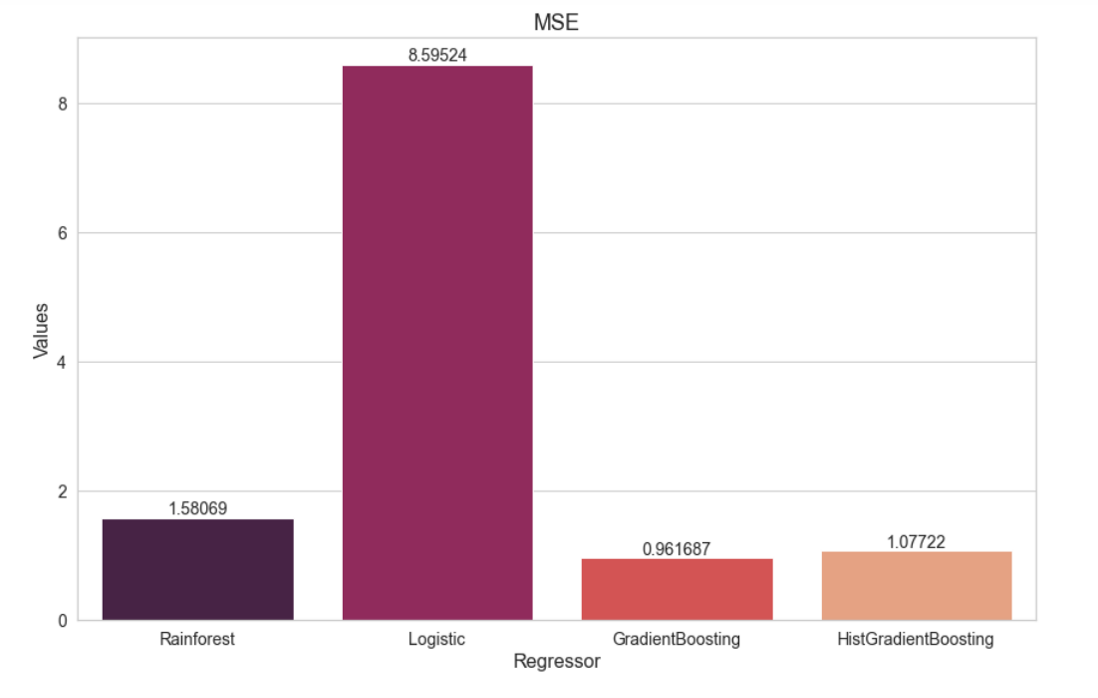
En las gráficas de AUC previas se muestra que la combinación ganadora es la de: RFt + BoW + Bigramas, ya que es la mejor en discernir los mensajes que tienen alguna relación con estrés de aquellos que no la tienen.
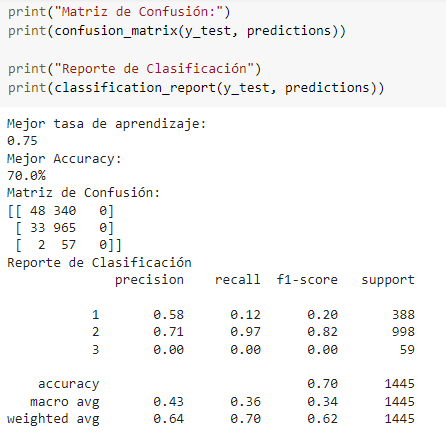
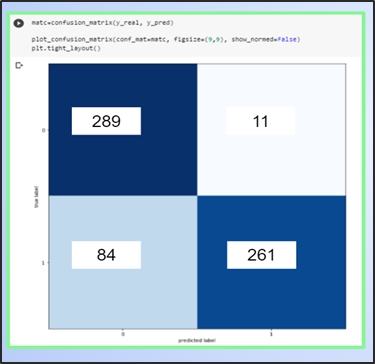
A continuación podemos observar la matriz de confusión del modelo ganador, así como los resultados de sus métricas.
Optimización (‘Tuneo’) del modelo:
El ajuste fue realizado para tres modelos con el fin de mejorar su desempeño.
Logistic Regression Se genera una búsqueda de grilla utilizando grid search al cual se le definen ciertos valores con los que se ejecutará el modelo para obtener la versión con mejor Accuracy. Para esto se consideró: 1.- Valor C 2.- Penalty del modelo: L1 (Lasso) y L2 (Ridge)
Random Forest Classifier Se genera una búsqueda de grilla utilizando grid search al cual se le definen ciertos valores con los que se ejecutará el modelo para obtener la versión con mejor Accuracy. Para esto se consideró: 1.- Número de Estimadores: número de árboles utilizados en el bosque. Este valor empezará en 200 e irá de 10 en 10 hasta llegar a 2000. 2.- Max_Features: es el número de atributos a considerar para la mejor división. Se prueba con “auto” que se refiere a que el máximo de atributos será la raíz cuadrada del número de atributos. 3.- Max_depth: esto se refiere a la máxima profundidad del árbol. Para este caso se parte en 10 hasta 110 avanzando de 11. 4.- Min_Samples_split: es el número mínimo de muestras requeridas para la división interna del nodo. Se prueba con 2, 5 y 10. 5.- Min_samples_leaf: el número mínimo de muestras requeridas para ser una hoja de nodo. Se considera 1, 2 y 4 para realizar la búsqueda de grilla. 6.- Bootstrap: Si es Verdadero, usará bottstrap en la construcción de los árboles. Si es falso no se utilizará. Se probará con ambas.
Gradient Boosting Classifier Se genera una búsqueda de grilla utilizando grid search al cual se le definen ciertos valores con los que se ejecutará el modelo para obtener la versión con mejor Accuracy. Para esto se consideró: 1.- Loss: se usa desviance para evaluar como regresión logística la función de pérdida 2.- Learning:rate: es la medición que mide la contribución de cada árbol. 3.- Max_Features: es el número de atributos a considerar para la mejor división. Se prueba con “sqrt” que se refiere a que el máximo de atributos será la raíz cuadrada del número de atributos, en el caso de “log2” se usa el logaritmo del número de atributos. 4.- Max_depth: esto se refiere a la máxima profundidad del árbol. Para este caso se usa 3, 5 y 8. 5.- Min_Samples_split: es el número mínimo de muestras requeridas para la división interna del nodo. Se prueba con un linspace de 0.1, 0.5 y 12. 6.- Min_samples_leaf: el número mínimo de muestras requeridas para ser una hoja de nodo. Se prueba con un linspace de 0.1, 0.5 y 12. 7.- Numero de Estimadores: número de árboles utilizados en el bosque. Este valor empezará en 200 e irá de 10 en 10 hasta llegar a 2000.
Evaluación:
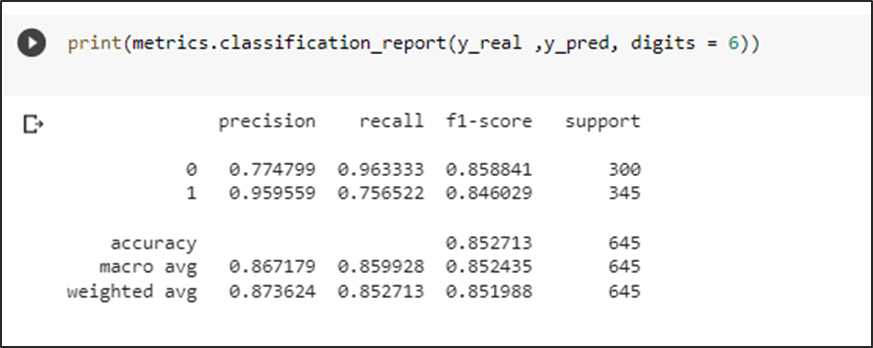
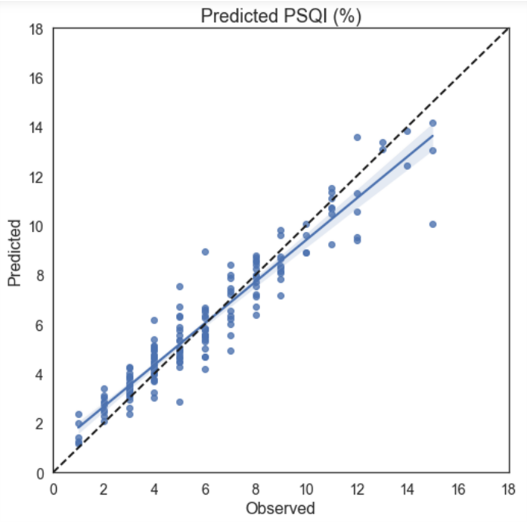
El modelo generado con mayor eficacia fue el de Random Forest, ya que es capaz de reconocer si un tweet contiene o no estrés con una precisión de 88%, lo cual es una métrica muy buena, ya que la velocidad con la que se puede evaluar un conjunto masivo de tweets con esta exactitud ayuda enormemente en una tarea que un humano tardaría mucho más tiempo, y de esta manera es posible encontrar o tratar posibles casos que requieran asistencia sin necesidad de esperar a que esto lleve a un problema mayor como lo es la depresión.
Análisis de resultados:
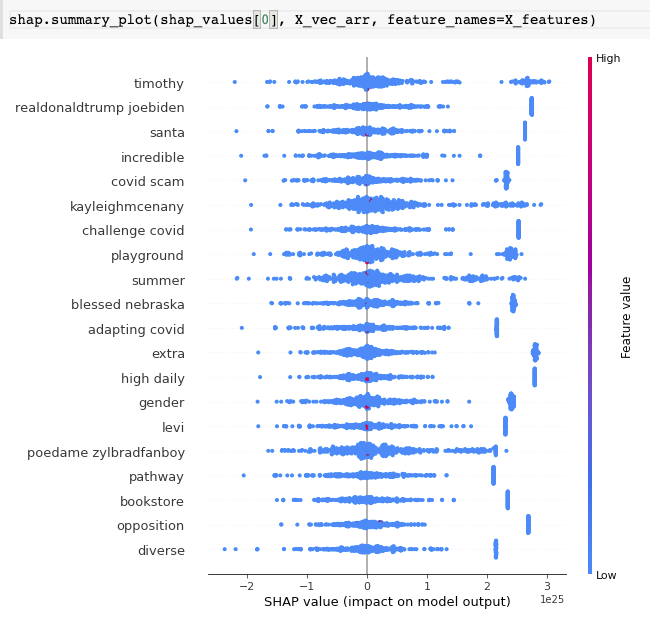
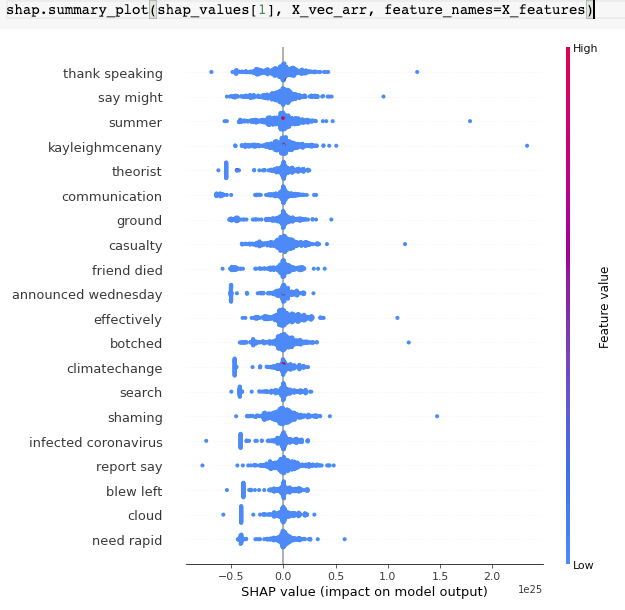
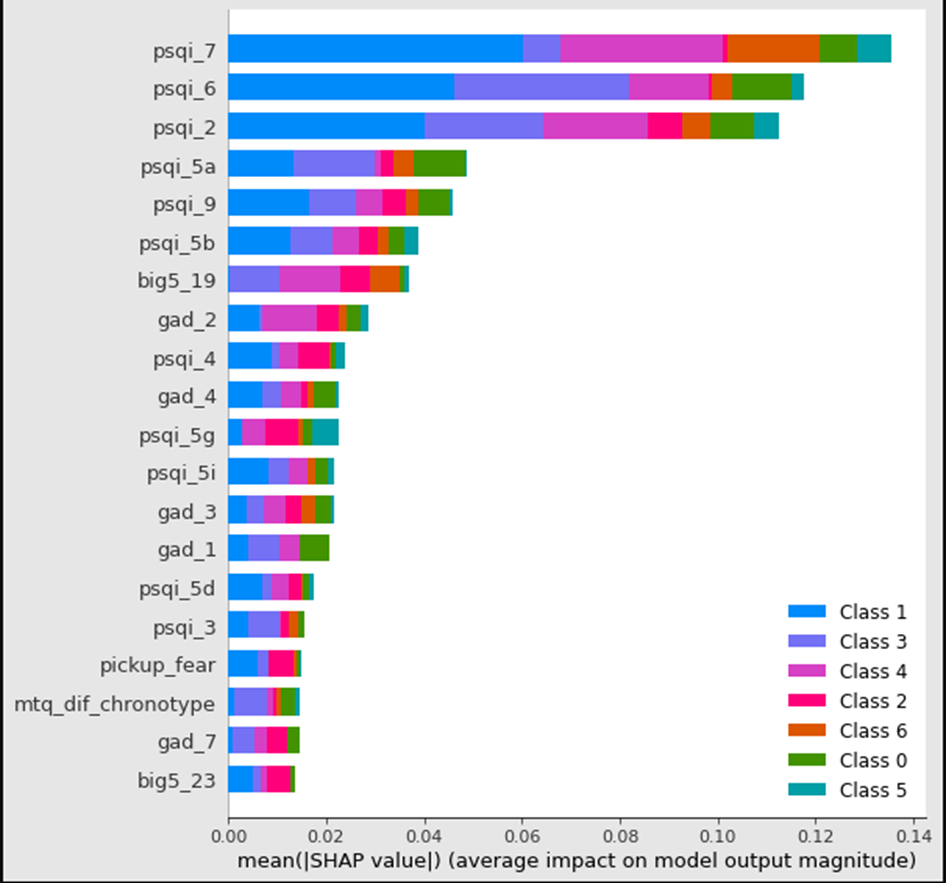
Para poder adentrarnos más en por qué el modelo se comporta de la manera que lo hace, hicimos uso de SHAP, una técnica de teoría de juegos utilizada para explicar los modelos. El modelo utilizado fue un Random Forest con 100 estimadores.
En este caso utilizamos un TreeExplainer de la librería shap. Para calcular estos valores se tuvo que usar solamente el 5% de los datos de entrenamiento y 10,000 features, de otro modo, el tiempo de ejecución sobrepasa la hora y media en Google Colab.
Resultados para tweets que NO tienen estrés:
Resultados para tweets que SÍ tienen estrés:
Casos de uso para el modelo generado:
Instituciones públicas, gubernamentales o privadas que estén interesadas en conocer o monitorear el estado anímico de una población, o conjunto de personas por zona geográfica, para evaluar el nivel de estrés.
Personal que labore en el área médica enfocada en la salud mental, para lograr identificar las condiciones sobre la estabilidad emocional de algún sector de la población.
Empresas privadas que puedan ofrecer servicios de consultoría para el bienestar emocional y que ofrezcan análisis o proyección de campañas de salud mental en la sociedad.
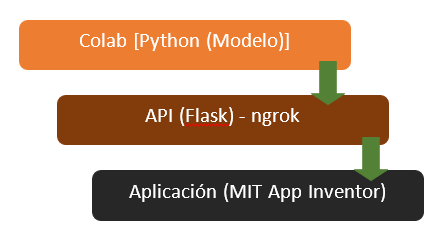
Desarrollo de Modelo en un App Web
Para alojar nuestro modelo de Machine Learning usamos el framework Flask. Este es usado por su facilidad de uso, ser muy escalable y además, está desarrollado para Python. Lo cual permite en un lenguaje realizar todo el desarrollo. Hay que tener claro que una aplicación web tiene dos partes fundamentales.
Partes de una App Web:
El Front-end el cual es una página desarrollada con Html y Css. Sin ninguna parte de JavaScript ya que es una app sencilla de utilizar.
El Back-end será desarrollado con Flask, donde permite crear la integración con el Front-end y además correr el modelo ya entrenado.
Desarrollo de la interfaz de usuario
En esta parte fueron utilizadas dos herramientas en línea bastante útiles que son Flask y Heroku. Flask es un framework para desarrollo web con gran interacción con Python; Heroku es usado como un servidor para el despliegue y disponibilidad pública de la aplicación.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
A mucha gente le motiva los retos en el trabajo, en los estudios y en la vida en general, pero pregunto, puedes imaginar una vida en donde cada día existen retos diferentes, iniciando desde la mañana cuando al levantarte y tomar un refrescante baño en la mañana, debes hacer lo necesario para no tropezar en el camino para encontrar tu ropa y combinarla adecuadamente para la ocasión, pues hoy debes ir al centro de la ciudad a cumplir con unos trámites burocráticos que requieres, además de hacer las compras del supermercado para la semana. Luego de prepararte un café y conseguir que no se te riegue del borde de la taza, estás listo para empezar tu día, sales de tu casa y esperas no tener que tropezar con obstáculos que son comunes en la calle: basura que no llegó a su respectivo tacho, las mejoras de la ciudad caracterizadas por sus constantes cambios de planificación a costa de dejar trabajos inconclusos en las calles, los no tan amigables perros en la calle que podrían poner a prueba tu instinto y la razón, pero bueno es algo que uno ya sabe y lo que debe hacer es llegar hasta la estación del bus y esperar que algún transeúnte de buen corazón te ayude a identificar la línea de bus que te acerque a tu destino. Ya habrá tiempo para ir luego al supermercado, conseguir lo necesario y confiar en recibir lo justo como cambio o tener la seguridad de pagar lo que corresponda.
Estas situaciones describen una vida llena de retos que deben afrontar las personas no videntes cotidianamente, y que muchas veces les impide integrarse socialmente en entornos laborales, comerciales, de ocio e incluso incrementan su dependencia de terceros, lo cual supone, además, un impacto psicológico que eventualmente y de a poco va minando su autoestima.
Dependiendo de la edad en que las personas no-videntes pierden el sentido de la vista puede llegar a ser una experiencia más o menos traumática que podrá ser llevadera si se cuenta con apoyo emocional sobre todo en la etapa inicial y se trabaja fuertemente para educarse y adaptarse a su nueva condición y calidad de vida, que demandará pasar por un tortuoso camino de duelo por la pérdida de la vista.
A pesar de estas situaciones nada alentadoras, existen muchas personas que no se dejan vencer por la adversidad y logran con éxito adaptarse tanto emocional y socialmente para llevar una vida digna y con razones para continuar retando la adversidad día a día.
De acuerdo a la OMS [1] “A nivel mundial, se estima que aproximadamente 1300 millones de personas viven con alguna forma de deficiencia visual.
A nivel mundial, las principales causas de la visión deficiente son los errores de refracción no corregidos y las cataratas.
La mayoría de las personas con visión deficiente tienen más de 50 años.”
Además, El deterioro de la vista o su pérdida, tiene impactos en la calidad de vida de las personas que lo padecen, de acuerdo a OMS, “Los niños pequeños con deterioro grave de la visión a edad temprana pueden sufrir retrasos en el desarrollo motor, lingüístico, emocional, social y cognitivo”.
“En el caso de los adultos mayores, el deterioro de la visión puede contribuir al aislamiento social, a la dificultad para caminar, a un mayor riesgo de caídas y fracturas, y a una mayor probabilidad de ingreso temprano en residencias de ancianos.”
The Lancet Global Health [ 2] afirma que:
“En 2020, un estimado de 596 millones de personas a nivel mundial, tienen deficiencia de visión a distancia, y de estos 43 millones son ciegos.”
“Una proporción grande de estos (90%), viven en países de ingresos bajos o medios”.
“Para 2050, el envejecimiento de la población, el crecimiento y la urbanización conllevarán un estimado de 895 millones de personas con deficiencia visual a distancia y 61 millones de ciegos.”
Ante esta problemática, y como parte de la aplicación práctica de un curso de Machine Learning [ 3] e Inteligencia Artificial (IA) [4], nace la idea de usar la tecnología para identificar ideas que puedan abordar la problemática de las personas con discapacidad visual y diseñar una herramienta que les apoye en la consecución de sus actividades cotidianas. La idea del grupo fue pensar en un proyecto que pueda aportar socialmente y que tenga un impacto en la comunidad. Desde el punto de vista de los Objetivos de Desarrollo Sostenible (ODS) [5] estarían relacionados: Salud y bienestar, Industria, innovación e infraestructura, reducción de las desigualdades y alianzas para lograr los objetivos.
El proyecto Ciclope.IA, como lo hemos llamado, busca integrar en una aplicación para celular, diferentes opciones (skills) orientadas a solucionar limitaciones que experimentan personas con discapacidad visual en sus actividades cotidianas tales como: Reconocimiento de billetes y monedas de manera rápida y efectiva, identificación de la línea de autobús, identificación de colores, conocer el nivel de llenado de un recipiente, encontrar objetos perdidos, etc.
Como se puede observar las opciones que se pretenden integrar son ambiciosas y demandarán un trabajo extenso, sin embargo, es necesario empezar por algo, se suele decir que una “torta se la come en pedazos” y es por ello que la aplicación inicialmente dispone de la funcionalidad que permite al usuario reconocer la cantidad de dinero en efectivo en dólares (billetes), haciendo uso de la cámara de su celular. Posterior a la detección, la app reproduce un mensaje de voz con el resultado del monto reconocido. El uso de Ciclope.IA brinda al usuario seguridad y autonomía al momento de realizar transacciones en efectivo y disminuye el riesgo de ser víctima de engaño. La interacción con la aplicación se puede realizar en idioma español bajo el sistema operativo Android.
Alcance inicial del proyecto
Cuando iniciamos el proyecto y luego de un acercamiento con un grupo de no-videntes identificamos algunas opciones (skills) que deberíamos incluir en la aplicación, así que para tomamos la opción más frecuentemente demandada que es la de identificación de billetes al momento de realizar transacciones monetarias con terceros. Adicionalmente se conoció que la mejor forma de interacción con personas no-videntes es a través de audio, por lo que decidimos que la interacción del usuario con la aplicación se debía hacer a través de voz tanto de entrada como de salida.
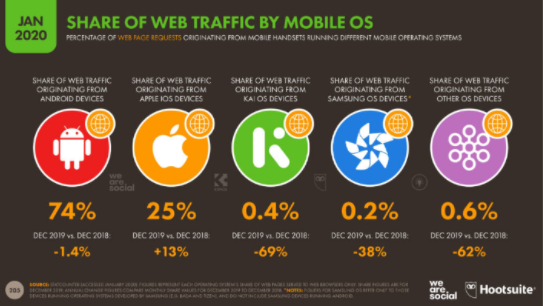
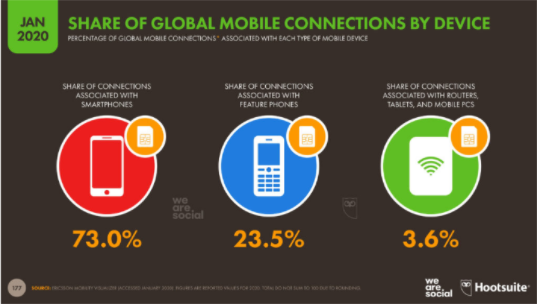
Para soportar nuestra configuración revisamos en algunas estadísticas en el sitio yiminshum.com, “actualmente hay 5.190 millones de usuarios únicos en dispositivos móviles, donde no divide el tipo de teléfono, esto cubre el 67% de la población.”
“El 73% de las personas están conectadas y comparten su tiempo desde un teléfono inteligente o smartphone. El 23,5% está asociado en un teléfono común, donde sus funciones son las básicas y limitadas que debe cumplir un teléfono que es llamar y enviar mensajes y el 3,6% está asociado a un router, tablet o PC móvil.”
“OS mejor conocido como sistema operativo, son importantes para el funcionamiento de los equipos en el mundo, el 74% de los usuarios son en equipos Android, 25% es iOS, 0,4% es KAI, 0,2% Samsung OS y 0,6% otros sistemas operativos.”
Con esta información se limitó el alcance del proyecto a teléfonos inteligentes Android que cubre una gran parte del mercado sobre todo en lugares diferentes a los Estados Unidos, a países hispanohablantes y que tengan su moneda de uso corriente el Dólar.
IA Aplicada
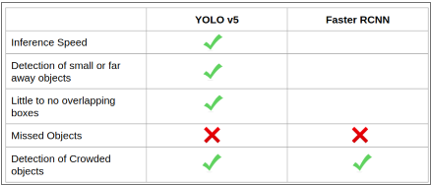
Frente a la problemática identificada se determinó que la mejor manera de apoyar a personas no-videntes es desarrollar una aplicación para celular que haga las veces de sus ojos en situaciones que se requieran, para ello desde el punto de vista técnico se exploraron diferentes modelos de reconocimiento de imágenes que podrían aplicarse, y al final se decidió usar YoloV5 por la versatilidad al momento de identificar objetos y basados en pruebas realizadas por Towards Data Science [6] que recomiendan el modelo frente a otro también muy conocido, otros elementos que consideramos fue la posibilidad de usar el modelo sin necesidad de tener una conexión de internet activa sino un modelo pre-entrenado que se copia en el celular en una versión Pytorch Lite que ocupe menos tamaño y recursos.
Para entrenar el modelo, se exploró opciones de dataset disponibles, desafortunadamente no se consiguió uno por lo que se optó por crear un dataset propio.
Unos de los grandes retos, justamente fue afinar el dataset para que incluya las imágenes adecuadas, considerando diferentes escenarios en los que podrían estar los billetes, considerar el reverso y adverso, y la cantidad suficientes de imágenes. Para conseguir las imágenes se usó una herramienta de Web scrapping y posteriormente con la herramienta online https://labelflow.ai/ se asignó a cada imagen las etiquetas para identificar a cada billete en las diferentes imágenes.
Luego de entrenar el modelo en la herramienta colab de Google se obtuvo un archivo con el mejor modelo generado y se lo uso en la aplicación de celular.
Sin lugar a dudas la IA dará solución a muchas problemáticas del día de hoy y permitirá que su aplicación se extienda masivamente en diferentes áreas del conocimiento y de la vida cotidiana. Nuestro trabajo es una pequeña muestra del potencial a explotar con IA y un aporte para aquellos interesados en apoyar a grupos como los no-videntes que deben superar la adversidad con poco o limitado apoyo de la sociedad.
Conclusiones
Las herramientas de Inteligencia Artificial pueden ser usadas para múltiples propósitos, sin embargo, desarrollar productos que permitan dar solución a necesidades de carácter social, representan una oportunidad enorme que reditúa en bienestar y mejora de la calidad de vida de grupos minoritarios de la sociedad.
Desde el punto de vista técnico el proyecto representó una oportunidad para continuar aprendiendo de este apasionante mundo de la IA y entender entre otras cosas que para crear modelos efectivos es importante trabajar de manera exhaustiva en:
Crear o disponer de datasets de calidad.
Aplicar diferentes modelos para evaluar el desempeño.
Hacer a los usuarios participes del desarrollo de productos.
Trabajar con equipos multidisciplinarios.
Mantener una permanente búsqueda de nuevas soluciones.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Los accidentes de tránsito constituyen una de las causas de fatalidad y gravedad más importantes en distintos lugares del mundo, a causa de esto es indispensable disponer de una manera de reducirlos en la medida de lo posible a fin de evitar tragedias y pérdidas de vidas humanas dentro de un determinado territorio.
La Organización Mundial de la Salud (OMS) señala que cada año fallecen más de 1,35 millones de personas en todo el mundo a causa de los siniestros de tránsito, es decir una muerte cada 25 segundos, lo que los convierte en la causa más frecuente de decesos entre las personas de 15 a 29 años y en la novena más común en la población general. Los países de ingresos bajos y medianos tienen la mayor carga y las tasas más altas de mortalidad por siniestros de tránsito.
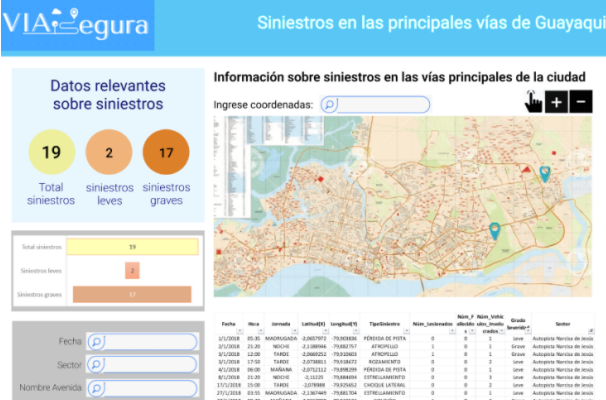
Los accidentes de tránsito en Ecuador tienen una ocurrencia bastante común, solo en la ciudad de Guayaquil entre el 2018 y el 2021 se registraron 17 671 accidentes con al menos un fallecido y 17 681 accidentes con al menos una persona lesionada de gravedad según fuentes oficiales de la Agencia de Tránsito y Movilidad (ATM); institución encargada de la seguridad vial en dicha ciudad.
Descripción del problema
En base a lo mencionado anteriormente se plantea el siguiente problema: ¿Se puede crear un sistema web que optimice los recursos de la agencia de tránsito y permita prevenir accidentes graves y/o fatales en la ciudad de Guayaquil?
Objetivo general
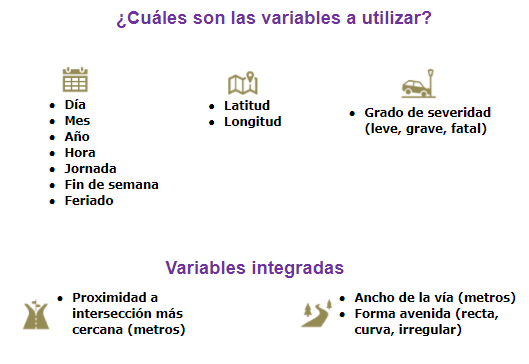
Se plantea como objetivo general implementar un modelo de Machine Learning para la estimación temprana de accidentes de tránsito graves o fatales mediante el análisis de datos previos relacionados a accidentes de tránsito en la ciudad de Guayaquil.
El siguiente gráfico muestra la idea central del proyecto.
Recolección de la información
La fuente principal de información es el dataset estructurado de la ATM que incluye ciertas condiciones suscitadas durante un siniestro. Luego de un análisis exhaustivo de las diferentes variables obtenidas, se procedió a descartar algunas de ellas debido a que no tenían dependencia significante con los siniestros, esta selección fue basada en artículos científicos relacionados con el tema.
Por motivos de privacidad de la ATM no podemos mostrar imágenes del dataset utilizado, sin embargo daremos información sobre las variables utilizadas:
Selección de los modelos
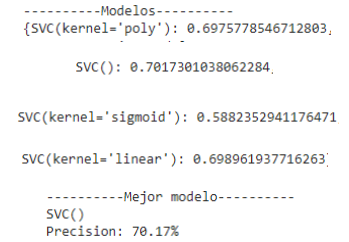
La selección de los modelos parte de las siguientes dos consideraciones:
Facilidad de su implementación.
Rendimiento del modelo.
Los modelos a desarrollarse son:
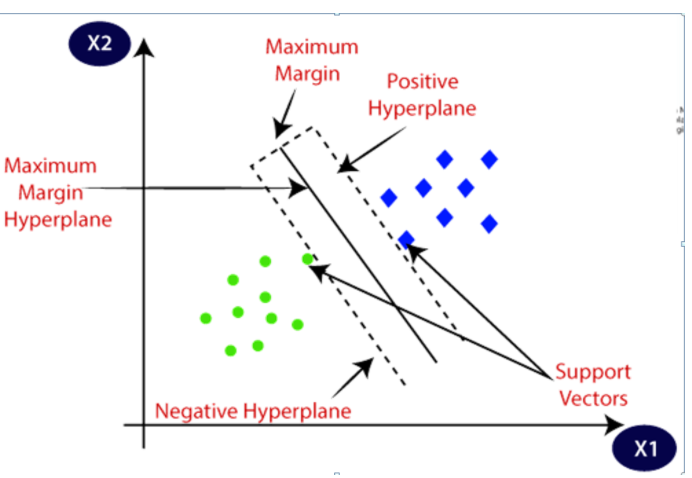
SVM (Máquina de Soporte Vectorial)
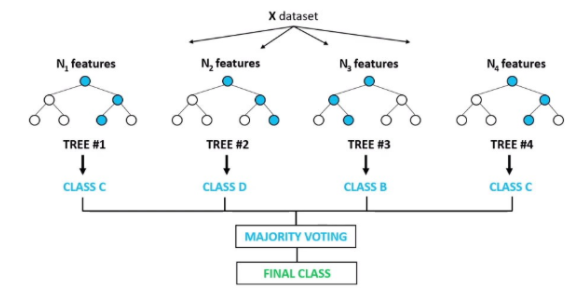
Random Forest
Regular Gradient Boosting
Técnicas implementadas
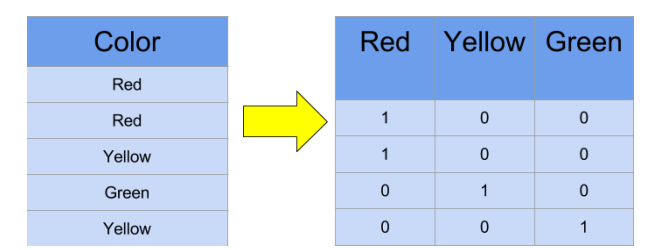
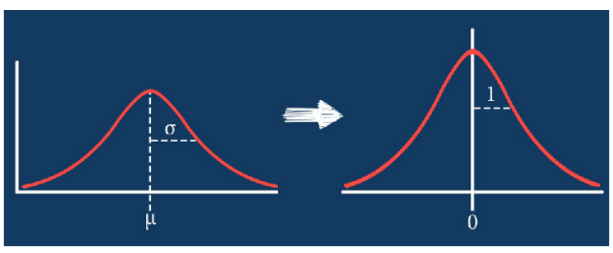
Las principales técnicas utilizadas para trabajar con el Dataset fueron la codificación de las variables categóricas a través del One-Hot-Encoding y la estandarización de las variables continuas.
Evaluación de modelos
SVM (Máquina de soporte vectorial)
Random Forest
Regular Gradient Boosting
Análisis de resultados
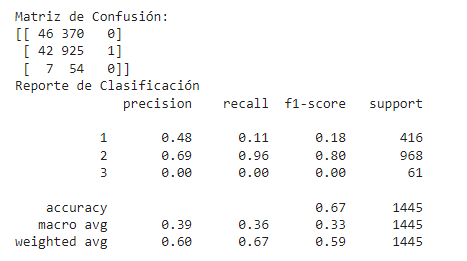
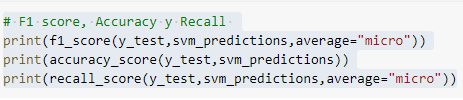
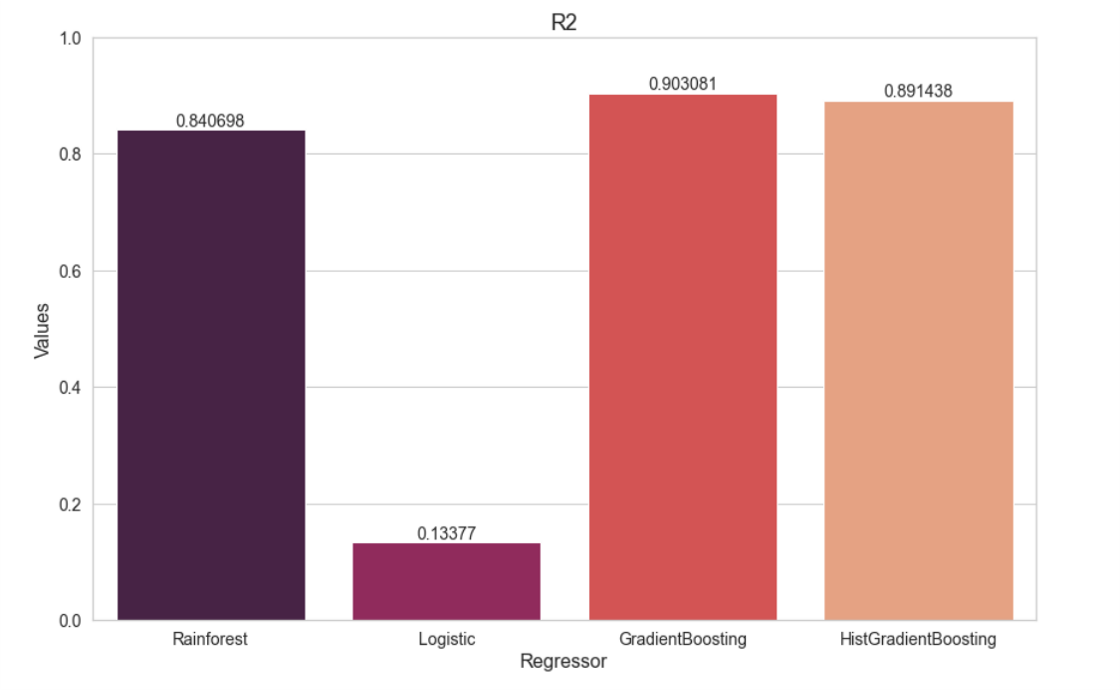
A continuación se muestran los resultados y precisión de los modelos SVM, Random Forest y Regular Gradient Boosting.
SVM
Random Forest
Regular Gradient Boosting
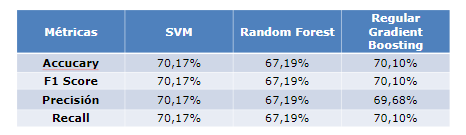
Precisiones finales
Conclusiones
El sistema se mostrará como una perfecta alternativa para la detección de accidentes graves y/o fatales, ya que permite visualizarlos durante cada hora en un mapa interactivo incrustado en una interfaz web.
Además, los modelos utilizados se encuentran entre los mejores para poder realizar clasificaciones multiclase, lo cual era el meollo del problema desde el inicio del mismo.
Planes a futuro
El presente proyecto tiene la intención de ser llevado las siguientes agencias e instituciones:
Agencia de Tránsito y Movilidad (ATM)
Comisión de Tránsito del Ecuador (CTE)
Agencias e instituciones destinadas al control del tránsito de los GAD y municipios que se encuentren en categoría A.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial, únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Angiotomografías con contraste ¿Cuál es el problema?
El reto
Los medios de contraste vía endovenosa que se usan en las angiotomografias contrastadas pueden tener incidencia en la salud nefrológica de los pacientes, sobre todo en aquellos que tienen antecedentes de hipertensión arterial, hipercolesterolemia, antecedentes genéticos, en edad adulta mayor (60 años en adelante) y un riesgo cardiovascular aumentado (1), es decir, son más propensos a:
tener accidentes cerebrovasculares,
infarto agudo de miocardio,
enfermedad arterial periférica y,
enfermedades de la aorta en general
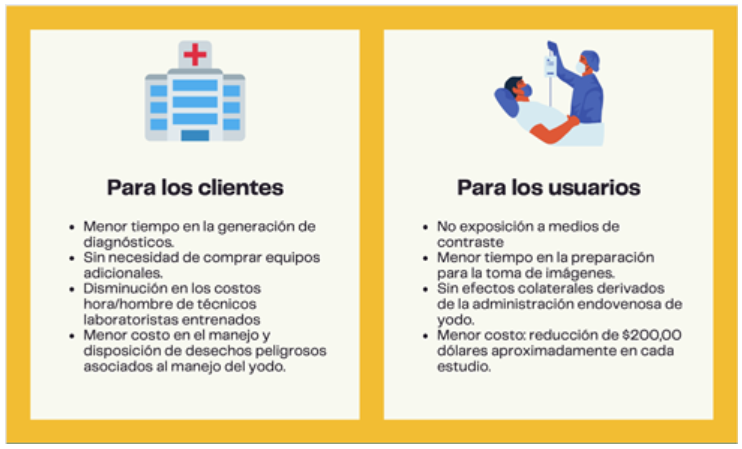
Existe la posibilidad de realizar angiotomografias simples que no requieren el uso de medios de contraste y que tienen un costo menor (alrededor de $200,00 de diferencia), pero estas no permiten una visualización completa de las estructuras aórticas con claridad (2), por lo que no son útiles en muchos casos, como en el de Jesús.
Por qué escogimos Angiotomografías?
La oportunidad ¿Cómo proponemos solucionarlo?
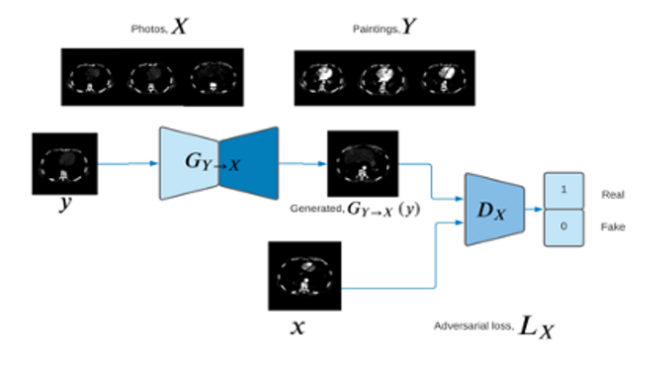
ANGIOP.AI (Sistema de Transformación de Imágenes de Angiotomografía) genera avances significativos en el análisis de imágenes médicas mediante modelos de análisis de inteligencia artificial para angiotomografias, brindando una alternativa que signifique un menor impacto para la salud de los pacientes que, por su diagnóstico y estado general, requieren realizarse este tipo de análisis de manera recurrente.
Figura 1. Estructura del modelo GAN aplicado a la transformación de imágenes de Angiotomografía
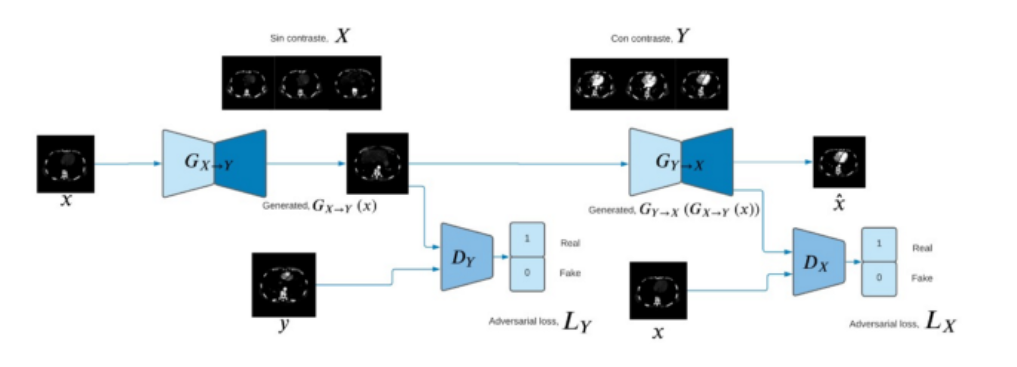
ANGIOP.AI basa su funcionamiento en el entrenamiento, validación y evaluación de un modelo CycleGAN para procesar imágenes de angiotomografias sin contraste y transformarlas en imágenes similares a las que se obtendrían usando métodos de contraste; se entrena un CycleGan para leer una imagen de un dataset X (imágenes sin contraste) y transformarlo para que parezca como si perteneciera a un dataset Y (imágenes con contraste).
¿Cuáles son los beneficios?
ANGIOP.AI está alineada al cumplimiento de los objetivos de desarrollo sostenible de las Naciones Unidas al 2030.
Lo explicamos paso a paso: metodología, modelo usado y datasets
Los datasets utilizados corresponden a los provistos por el Dr. Gonzalo Pullas, director de la carrera de Medicina en la Universidad de las Fuerzas Armadas; quien facilitó las imágenes de angiotomografias con contraste y angiotomografias simples (sin contraste) de 10 pacientes anónimos.
El total de imágenes facilitadas fueron de 5.144, de tamaño 512 x 512, en escala de grises, a las que se les aplicó una exploración de los datos — análisis estadístico para descartar imágenes a color y en 3D, sin datos atípicos y con Diferencias en distribución de pixeles (zonas / cortes). Es importante mencionar que las angiotomografías fueron tomadas en la misma zona anatómica, pero en diferentes oportunidades, es decir, las imágenes no corresponden a una paridad 1:1.
El modelo utilizado es CycleGan con pre-procesamiento de imágenes de escala -1 a 1 para la entrada del modelo. Los discriminadores son redes convolucionales con 5 capas que receptan imágenes de 256×256. Las 4 capas son de definición de patrones y una capa de clasificación. El generador utiliza tres capas convolucionales y seis bloques residuales. Para el cálculo de las funciones de costos, tanto para las imágenes reales como falsas, se está utilizando el proceso del error cuadrático medio (mean squared error).
El modelo utiliza los siguientes parámetros:
20000 épocas
Tasa de aprendizaje del 0,0001
Para el entrenamiento se aplicaron los siguientes pasos:
Seleccionar una cantidad de imágenes reales
El generador toma las imágenes reales y les agrega ruido para crear una cantidad de imágenes falsas
Entrenar al discriminador, haciendo que clasifique las imágenes como falsas o verdaderas un cierto número de veces o épocas
Generar otra cantidad de imágenes falsas para entrenar el generador
Se entrena al modelo
Para finalizar el modelo, se debe revisar la veracidad de la ejecución, revisando el gráfico de pérdidas a través del tiempo y revisando las muestras generadas por el modelo.
Veamos los resultados:
Lecciones aprendidas
Enseñar al modelo a validar las imágenes de entrada si corresponde a la zona angio toráxica.
Aumentar el Dataset para futuros entrenamientos.
Se requiere una validación de las imágenes generadas con un panel de expertos médicos.
Lo que se viene: Futuro de ANGIOP.AI
Usar la data generada para medir el impacto del uso del sistema en reducción de incidencia de enfermedades renales.
Diego Chiza, Ana Gayosso, Gabriela Jiménez, Paola Peralta, Patricia Román José Daniel Sacoto, María Teresa Vergara, Hilario Villamar, David Medrano.
Presentación del proyecto: DemoDay
Repositorio
El código fuente de este proyecto se puede encontrar en: github
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
En la actualidad, los desechos municipales a nivel mundial podrían aumentar un 70% en los próximos 30 años, provocando así montones de basura acumulados alrededor del mundo (Banco Mundial, 2019). Es por esto que, si no se toman medidas urgentes, se espera un futuro donde el convivir con basura sea algo normal para la sociedad.
Debido a las consecuencias de las acumulaciones de basura no controladas ni planificadas se deben tomar diferentes estrategias que amortigüen sus ocurrencias en distintos puntos del mundo.
Descripción del problema
El problema de la acumulación de basura no solo radica en el mal olor que se percibe, sino la imagen de insalubridad, desorden y hasta de inseguridad que la basura se desparrama en las calles genera. En las calles se puede encontrar desde cartones y pañales, hasta cáscaras de frutas, plástico y sábanas viejas. Todo esto al pie del canal de aguas lluvias, en cuyas bases también es común ver flotando todo tipo de desechos.
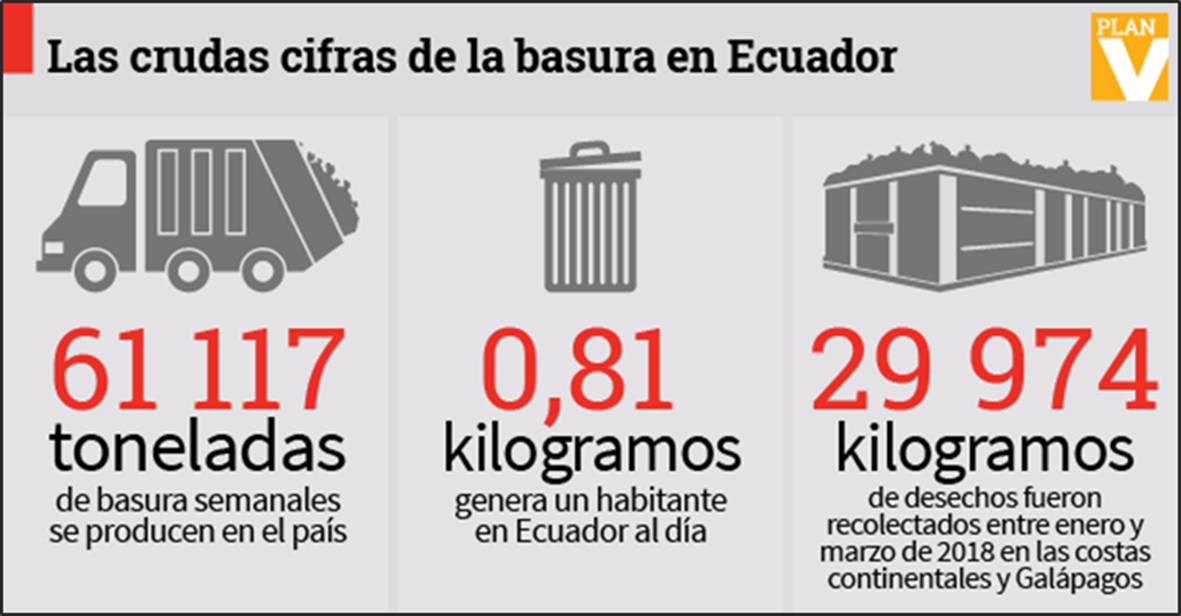
Según el Ministerio del Ambiente, en el Ecuador la más crítica es la Costa, en donde apenas el 10% de los municipios dispone de un relleno sanitario, manual o mecanizado; en la región Sierra son 25%, y en el Oriente, el 24%. Por lo que las cifras de basura dentro del país aumentan diariamente tal y como se visualiza en la Figura 2.
Figura 2.- Cifras de la basura en el Ecuador.
En la figura 2.1, se visualizan algunas de las consecuencias de la acumulación de basura como lo son: daños en la infraestructura pública, aumento de enfermedades y plagas, inundaciones en las calles, obstrucción en los alcantarillados y entre otros.
Figura 2.1.- Consecuencias de la acumulación de basura.
En la ciudad de Guayaquil, las penas por desechar desechos sólidos no peligrosos al margen de la frecuencia y horarios establecidos y acumular la basura en parterres y aceras; van desde los $80 a $500 .
¿Cómo nace nuestro proyecto?
Ciudad Limpia se basó en la siguiente pregunta : ¿Cómo identificar de manera oportuna la acumulación de la basura no controlada en la ciudad de Guayaquil para minimizar el impacto en la sociedad? Por tal motivo creamos una aplicación que nos permite contribuir en la recolección de basura. Haciendo participe a la ciudadanía en mejorar la limpieza de la ciudad y que alguna empresa se interese en nuestra herramienta tecnológica basada en Inteligencia artificial.
Integrantes del proyecto
Figura 3.- Equipo morado — SaturdayAI –ÉPICO 2021
Experiencia del equipo
Manuel Ahumada “Fue una experiencia de aprendizaje práctico: enfocado en el hacer para adquirir los temas y conceptos presentados. Eso refuerza el conocimiento.”.
Patricia Andrade “Mi experiencia fue muy enriquecedora debido a todo el nuevo conocimiento que aprendí. Además, me gustó mucho el compartir ideas con compañeros de distintos campos para solucionar un problema práctico”.
César Villarroel “Fue una experiencia de aprendizaje práctico: enfocado en el hacer para lograr adquirir los temas y conceptos presentados. Eso refuerza el conocimiento.”.
Ingrid León “La experiencia que se obtiene en esta modalidad es buena, El poder compartir conocimientos, desafíos y riesgos hacen que seamos más profesiones. Me quedo con una frase “«Son dos las opciones básicas: aceptar las condiciones como existen o aceptar la responsabilidad de modificarlas»”, entonces podemos mejorar siempre”.
Objetivo general
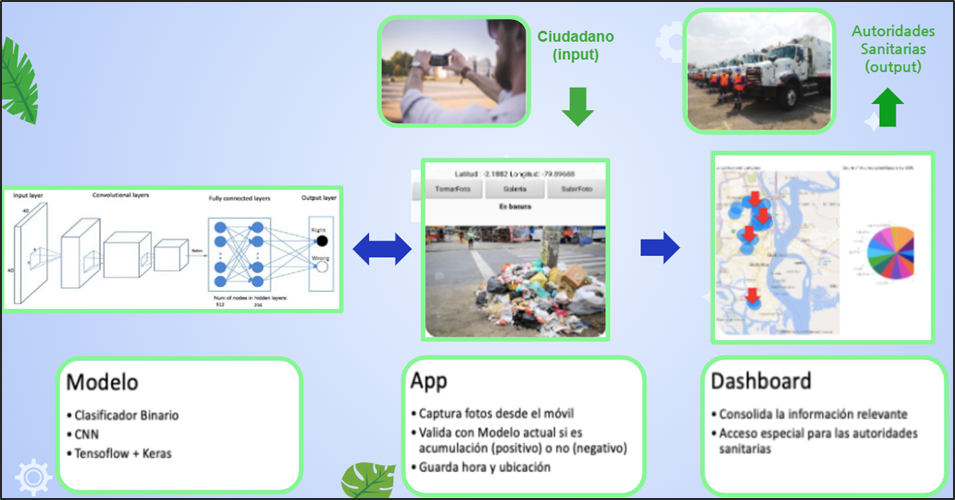
En la siguiente figura 4, se puede visualizar la idea principal del proyecto.
Desarrollar una aplicación basada en Inteligencia Artificial que permita identificar aglomeraciones de basura en la vía pública de zonas urbanas.
Figura 4.- Propuesta de valor del proyecto.
Planteamiento de la solución
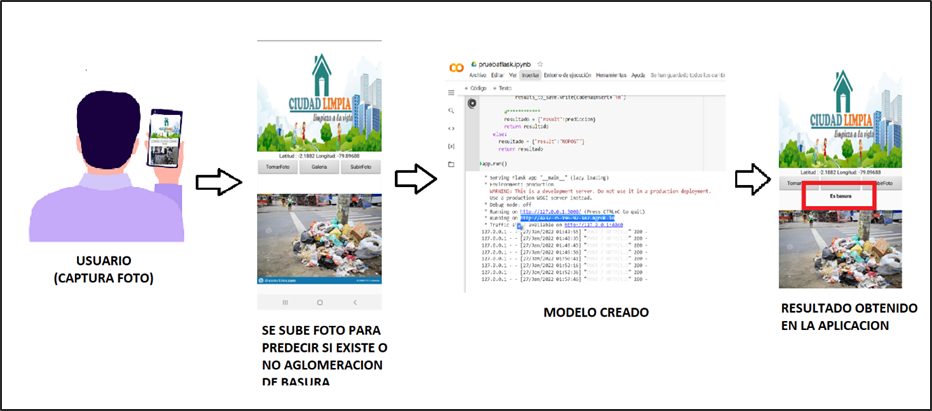
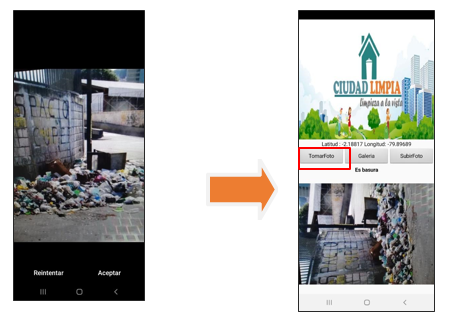
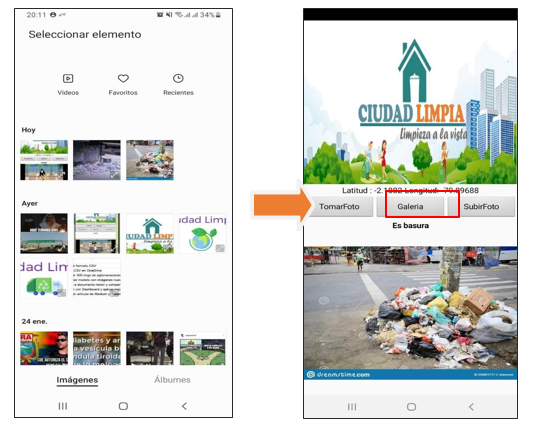
Se proyecta que mediante la colaboración de los ciudadanos se cree una concientización donde formen parte de la limpieza y cuidado de la ciudad. ¿Cómo lo van a hacer? Fácil, a través de la app “Ciudad Limpia” , en donde pueden tomar una foto para identificar y reportar la acumulación de basura de un sector determinado. Además, la aplicación registra la fecha, hora y ubicación del problema. Dicha aplicación estará basada en Inteligencia Artificial que permitirá identificar aglomeraciones de basura en la vía pública de zonas urbanas y fomentar un plan de acción inmediata para las autoridades sanitarias.
Figura 5.- Diagrama General de la solución.
Conjunto de datos
El conjunto de datos que se formó fue basado en descarga de imágenes de manera individual desde el Internet, videos transformados en fotogramas. Además, se sacó la plataforma de Kaggle y Google Street view donde se pudo obtener una gran cantidad de dataset de imágenes de aglomeración de basura.
Figura 6.- Medios para obtener el conjunto de datos
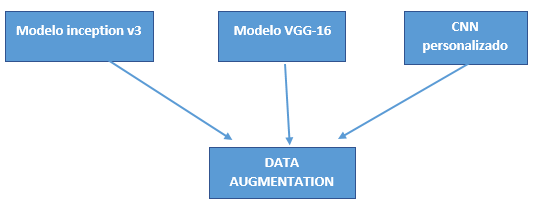
Selección del modelo
Para la selección de los modelos se obtuvo las siguientes consideraciones:
Fácil implementación.
Rendimiento del modelo.
Limitación de cálculo.
Estas consideraciones son debido a los recursos que se tienen para realizar el objetivo general. Los modelos a desarrollarse son:
CCN Personalizado.
VGG-16.
inicioV3.
Técnicas implementadas
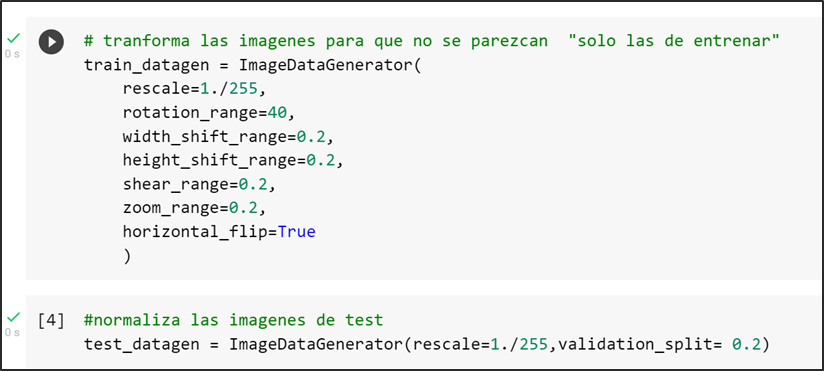
La principal técnica utilizada para compensar el conjunto de datos de tamaño limitado por la limitación de búsqueda de imágenes en Google fue la “aumentación de datos” realizada por la librería de keras “ImageDataGenerator”.
Data augmentation
El aumento de datos es la generación artificial de datos por medio de perturbaciones en los datos originales. Esto nos permite aumentar tanto en tamaño como en diversidad nuestro conjunto de datos de entrenamiento. En el computer vision, esta técnica se convirtió en un estándar de regularización, y también para mejorar el rendimiento y combatir el overfitting en CNNs.
Figura 7.- Ejemplo de aumento de datos.
En los tres modelos seleccionados se consideraron la técnica de aumento de datos con el objetivo de normalizar o re-escalar los píxeles en un rango de 0 a 1. Además de modificar las imágenes del conjunto tren con el objetivo de que existe una distinción en cada una de las imágenes seleccionadas tanto de ancho, largo, amplitud, rotación y escalamiento. A continuación, se observa el código donde se transforman las imágenes de entrenamiento con los parámetros seleccionados:
Figura 8.- Código del entrenamiento de imágenes.
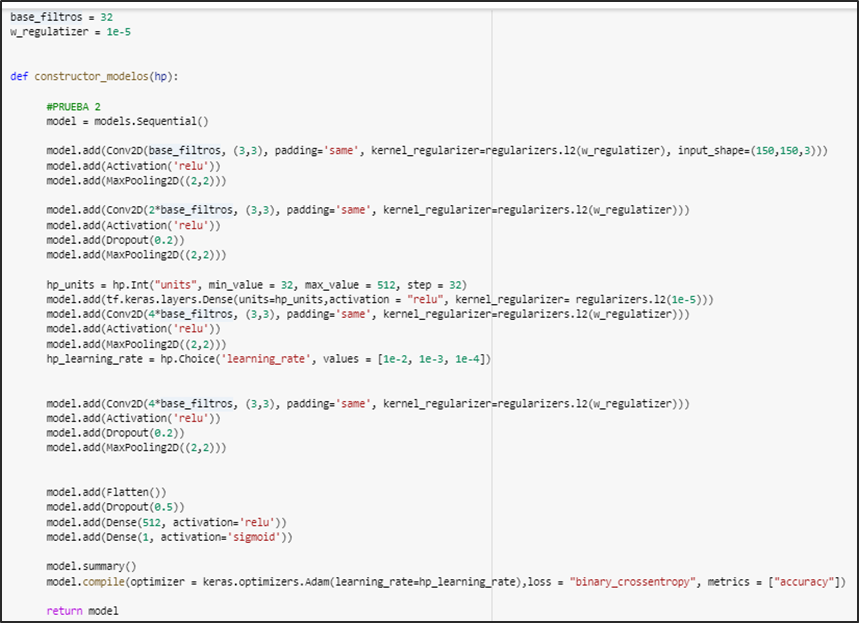
CNN personalizado
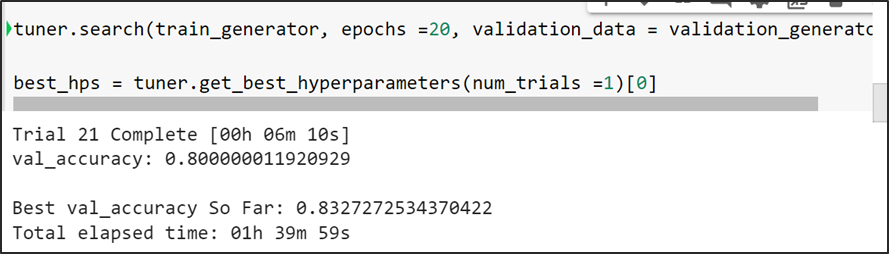
En el modelo CNN personalizado se aplicaron técnicas de regulación, callbacks y por último keras tuner.
Keras Tuner
Keras Tuner es una librería muy sencilla de utilizar que simplifica en gran medida complejidad el proceso de aplicar de optimización de hiper-parámetros sobre redes de neuronas profundas construidas mediante Keras, ofreciéndonos un amplio grado de versatilidad para optimizar tanto la estructura de nuestra red como la configuración de los parámetros de algunos de los algoritmos implicados en el proceso de entrenamiento.
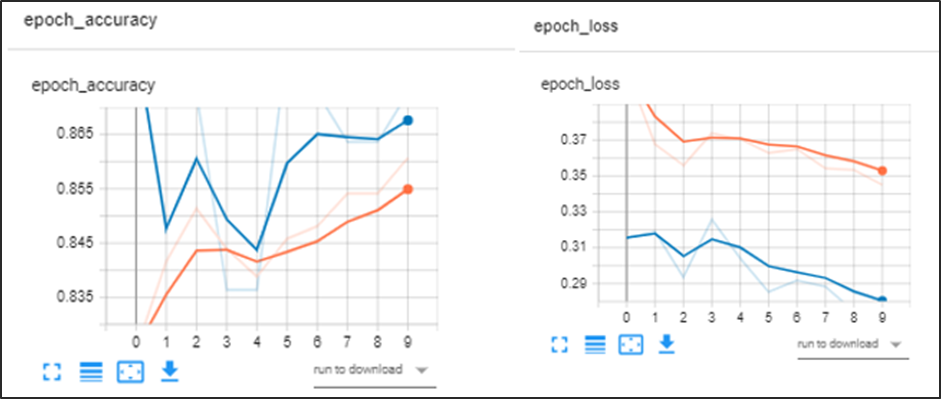
Figura 9.- se puede constatar el valor del ensayo y exactitud
Keras Tuner mientras va analizando cada trial, verifica el mejor valor de val accuracy infiriendo que es la mejor configuración de la arquitectura y la procede a guardar la mejor configuración de la arquitectura del modelo (número de capas) con el cual tiende a lograr la mejor métrico.
Figura 10.- código del modelo cnn
Arquitectura del modelo cnn personalizado cuenta con regularizadores, convolución, keras tuner
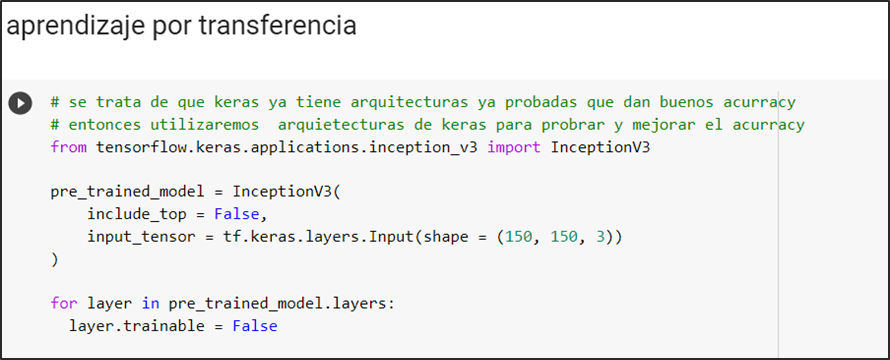
InceptionV3
Figura 11.- muestra el pre-entrenamiento
Se define el modelo pre-entrenado inceptionv3, valida el tamaño de las imágenes de input con que se entrena:
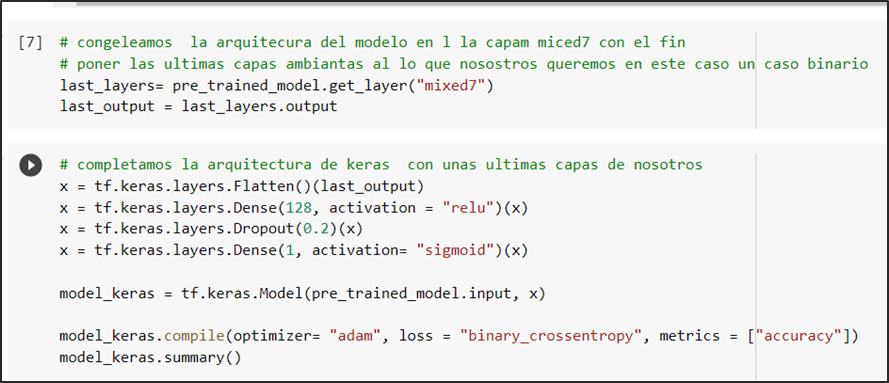
Figura 12.- uso de la arquitectura mixed7
Se congela la arquitectura en la capa “mixed7” para después alterarla añadiendo capas basadas en la predicción de nuestro modelo que es una clasificación binaria por el cual la última capa tiene activación sigmoidal la cual nos ofrece como resultado la probabilidad de que si un caso es positivo o negativo
VGG-16
Figura 13.- Características adicionales con VGG16
Se define el modelo pre-entrenado vgg16y valida el size de las imágenes de input con que se entrena
Figura 14.- aumento de capas (clasificación binaria)
Se procede a aumentar las capas basadas en la predicción de nuestro modelo que es una clasificación binaria por lo cual la última capa tiene activación sigmoidal la cual nos ofrece como resultado la probabilidad de que si un caso es positivo o negativo
Análisis de resultados
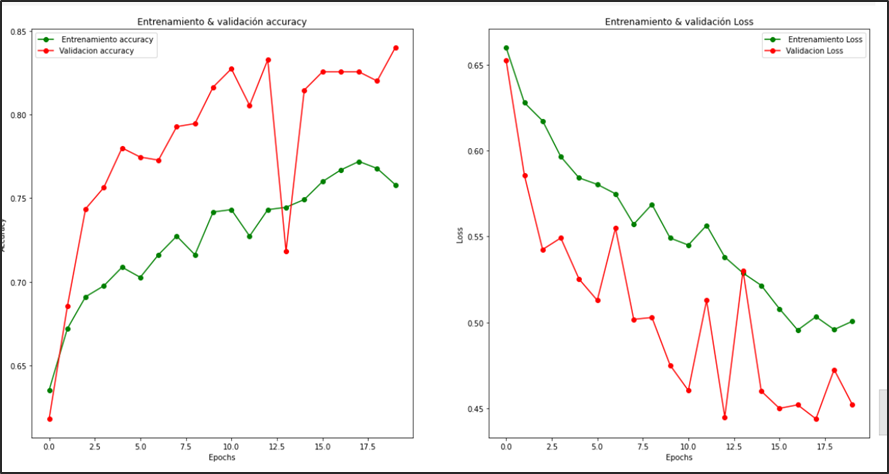
CNN personalizado
Figura 15.- gráfica del modelo cnn personalizado con 20 épocas
En la evaluación del modelo se entrenó con 20 épocas. Sé puede verificar que no logra converger en su totalidad. Logra una accuracy de la evaluación del conjunto test del 78 %
InceptionV3
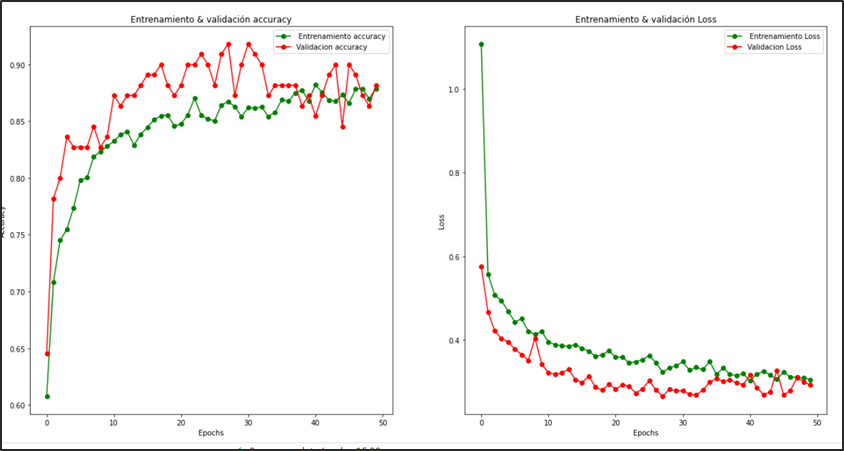
Figura 16.- grafica del modelo pre-entrenado con 50 épocas
En la evaluación del modelo el cual se entrenó con 50 épocas se puede analizar que logra converger en totalidad a partir de la época 28 en adelante, con una precisión de la evaluación del conjunto test del 85 %
VGG-16
Figura 17.- gráfica del modelo pre-entrenado con 10 épocas
En la evaluación del modelo el cual se entrenó con 10 épocas se puede analizar que logra converger, con una precisión de la evaluación del conjunto test del 84 %
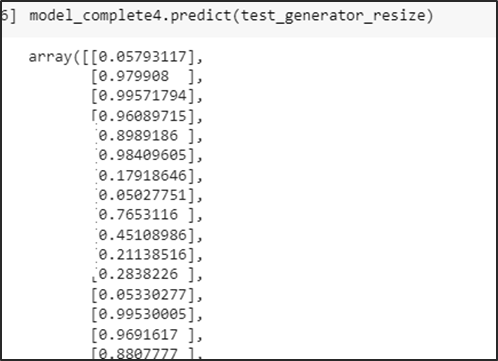
A continuación, mostramos las predicciones de los modelos:
InceptionV3
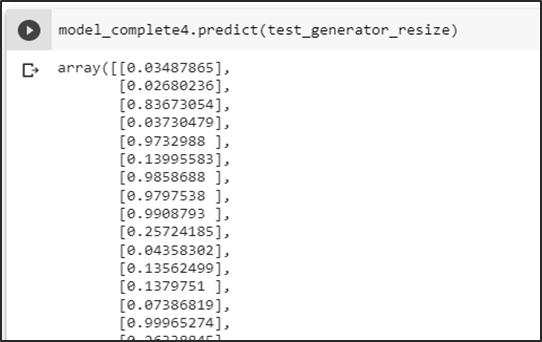
Predicción de la carpeta test
Se obtiene las probabilidades de predicción del conjunto test
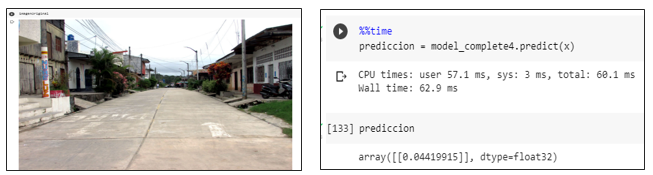
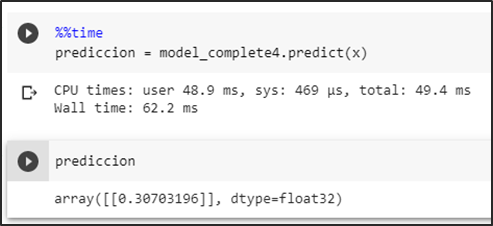
Primera prueba sin basura
Prueba del modelo prediciendo una imagen sin basura dando como resultado una probabilidad menor a un umbral de 0.5 se la identifica como una no aglomeración.
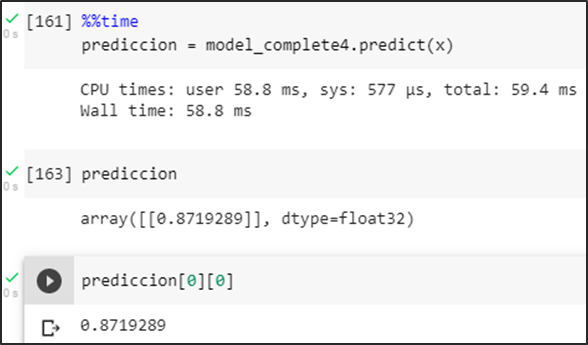
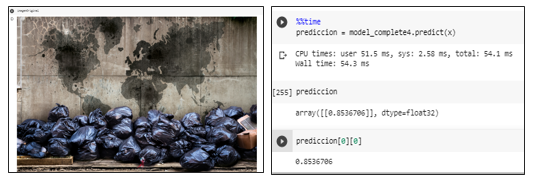
Segunda prueba con basura
Prueba del modelo prediciendo una imagen con basura generando una probabilidad mayor a un umbral de 0.5 se la identifica como una aglomeración.
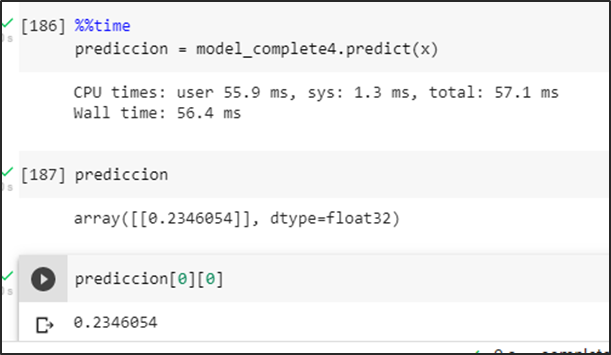
Tercera prueba con imagen y muchos colores
Prueba del modelo prediciendo una imagen falsa positiva intentando romper la predicción en consecuencia se obtiene una probabilidad menor a un umbral de 0.5 se la identifica como una no aglomeración
VGG-16
Predicción de la carpeta de test
Se obtienen las probabilidades de predicción del conjunto test
Primera prueba sin basura
Prueba del modelo prediciendo una imagen sin basura dando como resultado una probabilidad menor a un umbral de 0.5 se la identifica como una no aglomeración
Segunda prueba con basura
Prueba del modelo prediciendo una imagen con basura mostrando una probabilidad mayor a un umbral de 0.5 se la identifica como una aglomeración
Tercera prueba con imagen de diferentes colores
Prueba del modelo prediciendo una imagen falsa positiva intentando romper la predicción en consecuencia se obtiene una probabilidad menor a un umbral de 0.5 se la identifica como una no aglomeración
Métricas del modelo elegido: InceptionV3
Matriz de confusión
En la matriz de confusión podemos deducir que está prediciendo aceptablemente, pero puede mejorar la predicción de los falsos negativos esto se puede solucionar aumentando imágenes de positivos para que el entrenamiento del modelo mejore los positivos
Métricas
Las métricas obtenidas son aceptables con un f1 score del 85 % de predicción para casos negativos y un 84 % para casos positivos, esto confirmaría la teoría de aumentar los datos en positivos
Aplicación móvil (“Ciudad Limpia”)
Por qué elegimos App Inventor?
En la actualidad, existen muchas maneras de desarrollar aplicaciones en dispositivos móviles que cumplen con una función en específico y son compatibles con distintos sistemas operativos.
Es por esto, que se seleccionó como herramienta de programación y desarrollo de nuestra App “Ciudad Limpia” al entorno de App Inventor . Mediante esta plataforma se puede programar en JavaScript de manera fácil y sencilla debido a que utiliza una programación en bloques que permite un mayor entendimiento y uso por parte del usuario.
Figura 18.- Entorno de App Inventor
Arquitectura
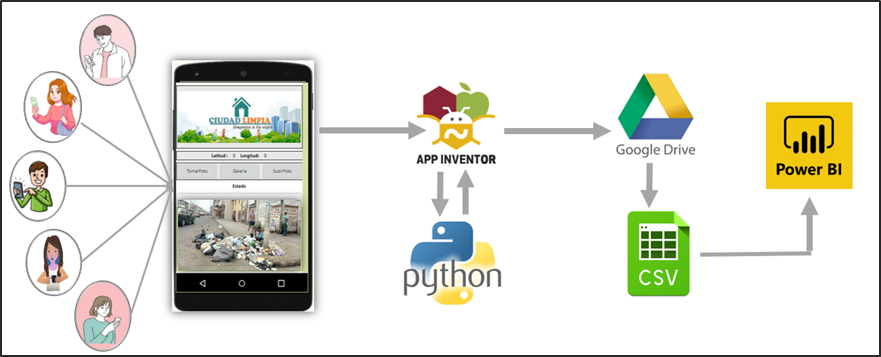
Con respecto a la arquitectura de nuestra aplicación “Ciudad Limpia”, se tiene los siguientes pasos a seguir, tal como se observa en la siguiente ilustración ():
Figura 19.- Arquitectura de la aplicación
Conexión de App Inventor con Google Colab
La conexión de la aplicación “Ciudad Limpia” con el modelo creado a través de Google Colab se realiza a través de la creación de un servidor local expuesto al Internet para el acceso de la aplicación móvil utilizando ngrok. Realizando una petición POST desde APP Inventor, se realiza el envío de la imagen codificada en bit64 al servidor el cual ejecuta el modelo y devuelve el resultado obtenido clasificado como aglomeración o no aglomeración de basura.
Funcionalidad de la aplicación «Ciudad Limpia»
Con respecto al entorno y manejo de la App “Ciudad Limpia” se consideran tres botones dentro de la interfaz con distintas funciones al momento de procesar una fotografía:
· Usuario “toma foto”: En este caso, el usuario utiliza la cámara de su dispositivo para capturar la imagen de la aglomeración de basura en su sector.
· Usuario selecciona “foto de galería”: En este caso, el usuario selecciona una foto que tenga registrado sobre la aglomeración de basura en su sector que encuentre dentro de su galería de imágenes de su celular.
· Usuario “sube foto”: En este caso, el usuario sube la foto de la aglomeración de basura en su sector para que sea registrado y notificado a las autoridades pertinentes y se pueda visualizar dentro de la aplicación el resultado de si existe o no una aglomeración.
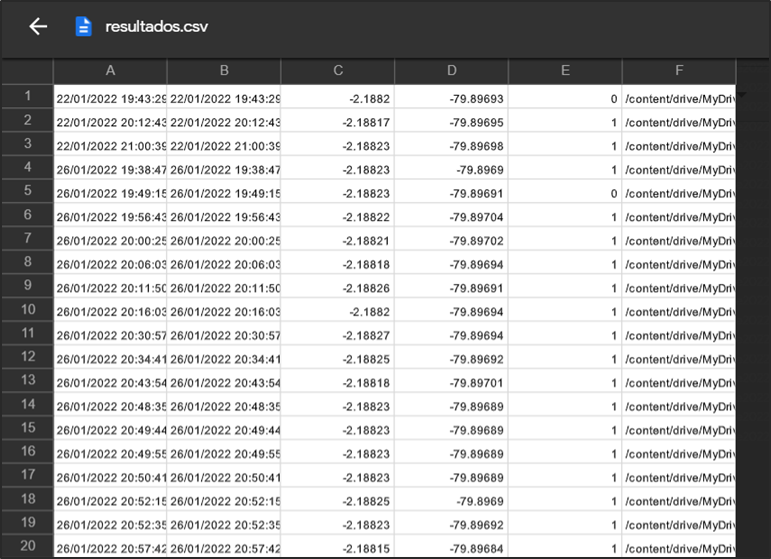
Almacenamiento de datos
Una vez realizada la predicción de la aglomeración de la basura dentro de la aplicación se procede a crear una base de datos a través de la aplicación de Google drive en extensión .csv, en donde se consideran los siguientes parámetros:
– Longitud
– Latitud
– Resultado de la predicción del modelo
– ID de la imagen capturada.
A continuación, se puede observar el archivo final generado con todos los datos que ha recolectado:
Funcionamiento de la interfaz
Herramienta BI
De acuerdo a los resultados que genera el modelo y los datos que guarda la aplicación web. Hemos considerado por uso en el mercado, la facilidad de uso, mejor visualización de objetos y desarrollar el tablero en Power BI.
Power BI es una herramienta que se utiliza principalmente para crear cuadros de mando que facilitan la toma de decisiones.
La información se puede actualizar de manera automatizada o manual y permite la compartición de los informes mediante la propia herramienta.
Por todo lo antes mencionado se procedió en la utilización de dicha herramienta.
Extracción de datos
Una vez que la aplicación web guardó los datos, realizamos los siguientes pasos que muestra la siguiente gráfica.
Figura 20.- pasos de la extracción de datos
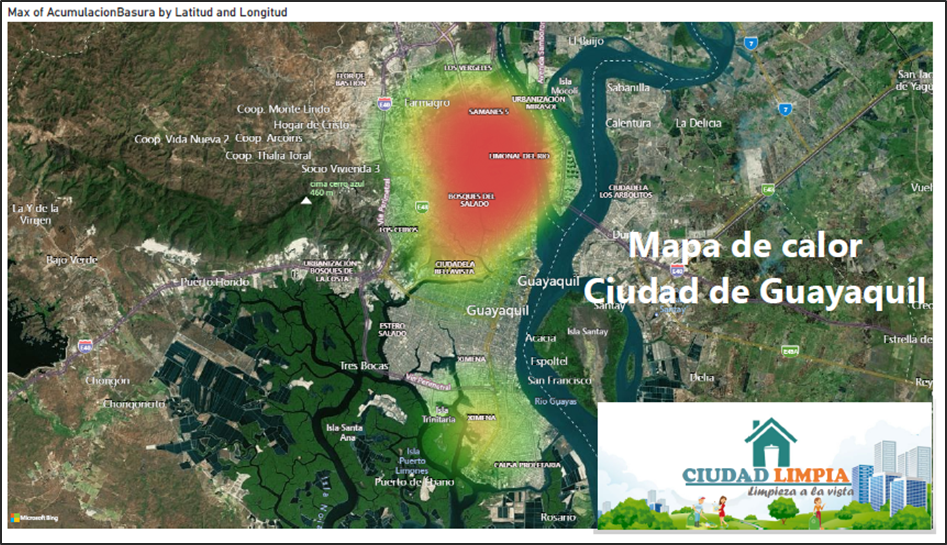
Mediante los campos: latitud, longitud, timestamp, aglomeración (1-Si, 0-No). Creamos un tablero que contenga varios objetos como KPI ‘s, gráficos de barras, gráficos pastel y hasta mapas. Así de manera visual tener una mejor comprensión de los resultados.
Figura 21.- Mapa de calor de la ciudad de Guayaquil
Dicha información nos permite poder identificar a través de un mapa en qué puntos de la ciudad tenemos más aglomeraciones de basura, en qué fechas y día se identificó la mayor cantidad de aglomeración y hacer una mejora en cuanto a la recolección de basura.
Toda la explicación en cuanto a implementación, código, entrenamiento del modelo, uso de interfaz y herramienta BI se puede encontrar en el siguiente link:
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
El brote de COVID-19 y las respuestas sociales adoptadas para combatir su propagación (por ejemplo, el confinamiento y el distanciamiento social) han tenido consecuencias de gran alcance, pero han brindando también una oportunidad única para examinar los efectos que el estrés crónico y la incertidumbre pueden tener en los patrones de sueño de la población en general.
Está bien documentado que el sueño puede verse afectado cuando se está bajo estrés y que los cambios en el sueño pueden tener consecuencias negativas en las emociones y el bienestar mental. Un metanálisis reciente mostró que la pandemia de COVID-19(1) ha provocado una alta prevalencia de trastornos del sueño, que afectan aproximadamente al 40 % de las personas de la población general.
Se sabe que además del estrés debido a la pandemia por COVID-19, hay otros factores que podrían alterar la resiliencia mostrada bajo estrés, por ejemplo,la falta de interacción social, la falta de ejercicio físico, el bienestar económico etc.
Este proyecto tiene como objetivo determinar qué factores pueden afectar la calidad del sueño de la población cuando están sujetas a situaciones de estrés crónico como es el caso de una pandemia. Predecir dichos factores permitiría emitir consejos útiles para la población, de tal forma que estén mejor preparados para futuras pandemias y/o situaciones de estrés crónico que permitan mitigar el impacto emocional causado por la mala calidad de sueño.
Metodología
La base de datos seleccionada para este proyecto ha sido la publicada por la Universidad de Boston2, que consiste de una serie de encuestas realizadas a 1,518 personas a través de redes sociales para evaluar el impacto de la pandemia en el bienestar emocional y mental de las personas dependiendo diversos factores como la edad, el impacto económico, la condición de minoría y o el estado de riesgo.
Una vez seleccionada la base de datos proseguimos a la limpieza y procesamiento de los datos. Después de este proceso, el número de variables de nuestra base de datos fue de 216 y el tamaño de la muestra se redujo a 839 sujetos debido a que no toda la información estaba completa.
Las variables principales incluyen información demográfica (edad, identidad de género, ingresos, etc.), información relativa a los hábitos de sueño, niveles de ansiedad, regulación emocional cognitiva, y personalidad, entre otras.
La métrica elegida para evaluar la calidad del sueño fue la variable del índice total de calidad del sueño de Pittsburgh (PSQI), que tiene una escala de 0 a 21. En dicha escala, una puntuación global de 5 o más indica una mala calidad del sueño; cuanto mayor sea la puntuación, peor será la calidad.
Análisis del dataset
Observamos la distribución de los datos
Puntuación sueño
Observamos la correlación que entra la calidad de sueño con otras variables no asociadas al sueño:
Diferencia de cronotipo pre y post covid
Variable de ansiedad (No consigue dejar de preocuparse)
Variable de personalidad (Se considera relajado)
Variable de ansiedad social (Miedo a extraños post covid)
Modelos
Clasificación
En el conjunto de datos, nuestra métrica elegida para evaluar toma valores del 0 al 18 (no se han observado casos de 19 a 21). Si tomamos estos valores como si fueran clases o subconjuntos podemos aplicar un método de clasificación.
Hemos elegido aplicar el algoritmo de RandomForestClassifier con el que en un principio obtenemos valores muy bajos de precisión rondando el 0,20. A continuación, probamos a recudir las clases agrupando los valores originales de la métrica. A medida que vamos reduciendo las clases observamos que los valores de precisión van mejorando, para 6 clases el resultado mejora en torno a 0,5 y para 4 clases el resultado llega a 0,7.
Para tener una explicación de estos resultados mostramos los shap values de las predicciones:
Podemos observar que las variables que aparecen con más peso, son las que están directamente ligadas con datos de sueño (psqi_*). Las primeras de todas ellas son si la persona ha recurrido a medicinas para dormir, la percepción que declara de su calidad de sueño, y el tiempo que tarda en conciliar el sueño. Dentro de estas variables también observamos que tienen impacto datos de personalidad (big5_*) , como si se considera una persona relajada, o ansiedad (gad_*), como la capacidad de dejar las preocupaciones.
Según lo observado podemos concluir que el algoritmo está funcionando correctamente y que los datos en los que se basa para realizar las estimaciones son los esperados. Creemos que el número de observaciones con las que contamos son muy bajas para el número de clases a predecir y que aumentando los datos se podrían mejorar las predicciones.
Regresión
Para la regresión hemos elegido cuatro algoritmos distintos: RandomForest, Logistic, GradientBoosting y HistGradientBoosting.
El algoritmo que produjo el mayor coeficiente de determinación fue el de GradientBoosting, con un R2=0.9. Lo que significa que el 90% de los puntos se ajustan a la línea de regresión.
Una vez seleccionado el mejor algoritmo intentamos utilizar la optimización de los argumentos usando RandomizedSearchCV pero no obtuvimos nada mejor. Además probamos reducir el número de variables mediante el uso de PCA. Obtuvimos el número óptimo de variables y redujimos el tamaño de la base de datos a ese número, en este caso 138, pero los resultados empeoraron, la R2 disminuyó hasta 0.57.
Análisis PCA para reducir el número de variables
Por esta razón decidimos quedarnos con el resultado obtenido con el algoritmo de GradientBooster como la mejor opción para predecir la calidad del sueño.
Conclusión
Es posible predecir la calidad del sueño con un 90% de precisión. Pudimos observar que la calidad del sueño depende en mayor medida de variables relacionadas con:
Medicación
Tiempo que toma a la persona conciliar el sueño
Entusiasmo por llevar a cabo cosas
Manejo del estrés
Control de las preocupaciones
Esta predicción, aunque intuitiva, puede ser de utilidad para implantar medidas que puedan ayudar a la población a mejorar la calidad del sueño en situaciones de estrés crónico como la sufrida durante una pandemia.
En el futuro, este proyecto se podría mejorar aumentando el número de muestras de la base de datos actual.
Referencias
1. Jahrami, H. et al. Sleep problems during COVID-19 pandemic by population: a systematic review and meta-analysis. J Clin Sleep Med, jcsm-8930. (2020).
2. Cunningham, T.J., Fields, E.C. & Kensinger, E.A. (2021) Boston College daily sleep and well-being survey data during early phase of the COVID-19 pandemic. Sci Data 8, 110. https://www.nature.com/articles/s41597-021-00886-y
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
En la actualidad, el hostigamiento u acoso sexual online es conocido en el lenguaje anglosajón como grooming online; donde un adulto logra tener contacto a través de un medio tecnológico contra un menor de edad, siendo el objetivo del abusador atacar a través de interacciones como: acoso a su moral, hablar de sexo, conseguir material íntimo o acordar un encuentro sexual.
El grooming online se ha incrementado a raíz del confinamiento por el COVID-19. En Argentina aumentó más del 30% en el 2020(2), en datos del INEGI del 2019 arrojan que en México creció el 27%(3) , mientras que el diario ABC de España, reportó un incremento del 410% en los últimos años (4).
Contexto… please!
Los aplicativos actuales para el control parental recurren a bloqueos de aplicaciones, algunos sitios inapropiados, evitar compras online o el acceso de algún virus a los dispositivos como celulares, tablets o computadoras de niños y adolescentes. Sin embargo ninguno analiza conversaciones en redes sociales y tampoco clasifica las que puedan ser catalogadas como peligrosas.
Derivado del confinamiento por el COVID-19 los niños y adolescentes se han visto más vulnerables debido a la necesidad de utilizar los dispositivos móviles como parte de sus actividades diarias, gran parte de eso fue para tomar clases virtuales, realizar tareas y en otras ocasiones como medio de entretenimiento y comunicación, al verse limitados por no poder salir y compartir tiempo con familiares y amigos.
La nula supervisión ha permitido que menores de edad hayan experimentado situaciones indeseadas sin el conocimiento de los adultos.
De acuerdo al sitio salud con lupa, el 39% de los acosos se han experimentado por Facebook, seguida por el 23% en Instagram y un 14% por WhatsApp (5).
La propuesta
Tótem significa protector
Tótem = “Déjalo Navegar sin Preocupaciones”
Sin tanto rollo, esto es lo que hicimos.
Actualmente contamos con un dataset de conversaciones en inglés, las cuales son analizadas y catalogadas como normales o peligrosas, una vez obtenido esté resultado se enviará una notificación al padre o tutor si se detecta una conversación inapropiada.
¡¿Cómo hicieron eso?!
Aquí te explicamos qué fue lo que aplicamos para obtener los resultados que te mostraremos más adelante…
Fase 1 (Aquí vamos…)
Obtención de los datos
Los datos fueron adquiridos del proyecto PAN Lab 20126. La carpeta con los datos fue solicitada y se nos concedió el permiso para usarla. Revisando la data nos encontramos con conversaciones de diversa duración, en las que los participantes tenían diferentes formas de escribir y el archivo del corpus que tenía un formato .xml. Por lo que se procedió con la conversión de la data a un formato .csv, “Comma Separated Values”, para poder proceder con la siguiente fase.
Fase 2 (Analicemos esto…)
Limpieza de datos
La segunda tarea presentó un grado de dificultad alto, debido al ruido de la data. Por lo tanto se siguieron los siguientes pasos.
Se eliminó cualquier tipo de puntuación.
Se convirtieron los números a palabras usando la librería num2words.
Se buscaron abreviaturas y textos con jergas cibernéticas como: “u” para “you”, “ur” para “your”, “what ‘s” para “what is”, entre otras. Además se creó un diccionario con estas palabras nuevas.
Se eliminaron las stopwords como: the, and, that, a, any, an, be, with. Entre otras.
Se eliminaron emojis, URL, hashtags y cualquier tipo de valor alfanumérico.
Se empleó la técnica de lematización, para llevar todos los verbos a su forma en infinitivo. Para así crear incrustaciones a partir de palabras más simples.
Se exploraron los datos, analizando las 100 palabras más comunes en las conversaciones de los predadores.
Fase 3 (Entrenemos esto…)
Vectorización
La extracción de características representó un desafío particular, en primera instancia se optó realizarlo con base a las palabras más frecuentes presentes en las conversaciones de depredadores; no obstante, varias de estas eran de uso común, por lo que fue necesario analizar alternativas para lograr un óptimo desempeño. Es así que se optó por el uso del método TF-IDF (Term Frequency — Inverse Document Frequency), siendo una de sus características el resaltar la importancia de una palabra en un conjunto de documentos (corpus). En ese sentido, para transformar la secuencia de palabras (provenientes de las conversaciones) a vectores de características con representaciones numéricas se usó el vectorizador TF-IDF (TfidfVectorizer) de la librería de scikit-learn. Este transformador permitió generar una matriz de características, con una representación adecuada para realizar el entrenamiento del modelo. Para dicho propósito, se dividió el dataset en:
Datos de entrenamiento: 80%
Datos de testeo: 20%
Entrenamiento
Para el entrenamiento del modelo se usó la librería scikit-learn y se escogió el modelo Support Vector Machines (SVM) para emplear un clasificador binario.
Durante la evaluación del modelo se obtuvieron los siguientes resultados:
Siendo la matriz de confusión la siguiente:
Los resultados del modelo muestran una notable mejora en comparación a aquellos correspondientes al Baseline:
El modelo desarrollado se desplegó en una aplicación web haciendo uso de la herramienta Streamlit, en la cual a través de la interfaz se proporciona la conversación a ser analizada y la aplicación muestra la alerta si es una aplicación normal o peligrosa, a continuación se observa algunos ejemplos del funcionamiento:
Resultado del análisis en una conversación normal
Resultado del análisis de una conversación peligrosa
¿Te hace sentido nuestra propuesta?
Hasta ahora hemos podido analizar y clasificar conversaciones inapropiadas que se pueden reportar y de está forma proporcionar herramientas a los padres para el monitoreo de aplicaciones cuya función no es interferir con la privacidad sino prever situaciones peligrosas en conversaciones online.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Es una de las frases celebres de Greta Thunberg, haciendo alusión al poder de los jóvenes de cambiarlo todo, en particular su forma de ver el mundo y las oportunidades de hacer cosas nuevas en pro de su futuro.
Pero… y sí ese futuro se ve gris y contaminado ¿Entonces cómo pueden hacer la diferencia hoy?
Mascota de conciencIA ecológica
Actualmente, muchos jóvenes se preocupan por los problemas ambientales, volviéndose actores proactivos en la búsqueda de soluciones, esta urgencia de cambio nos motivó a crear ConciencIA Ecológica para enseñar a los niños la forma correcta de clasificar sus residuos de una manera divertida, promoviendo las prácticas de las (4R), Reducir, Reutilizar, Reciclar y Recuperar, utilizando tecnología e inteligencia artificial.
Este equipo conformado por siete (07) apasionados de la inteligencia artificial ha unido tres países como: Ecuador, México y Venezuela, participando en la 2da edición de Saturdays.AI LATAM y a través de su método build to learn elaboró un proyecto basado en Deep Learning llamado ConciencIA Ecológica, enfocado en estudiantes de educación básica de la ciudad de Guayaquil — Ecuador.
Si quieres saber más te invito a seguir leyendo.
Integrantes del equipo del proyecto ConciencIA Ecológica
El problema
De acuerdo al Instituto Nacional de Estadísticas y Censo (INEC), en el año 2017 cada ecuatoriano produjo 860 gramos de residuos sólidos en un día, a pesar de que este número se encontró por debajo del kilogramo de basura por día en América Latina y el Caribe, ese año se tuvo un crecimiento de 48% con respecto al año anterior, por lo que no es sorprendente imaginar, que si no se tomaron medidas a tiempo, estos números sean mayores hoy en día.
De la basura recolectada el 96% se entierra en rellenos sanitarios, celdas emergentes o botaderos a cielo abierto y solo el 4% se recicla. Para tener una idea de las razones por la que el reciclaje es bajo, en el 2016 el INEC realizó una encuesta de hogares detectando que el 59% de los hogares no clasificaron residuos.
Cuando se le preguntó las razones por las cuales no clasificaban, el 43% respondió por la falta de contenedores específicos. Sin embargo, el 57% restante se debió a problemas culturales: “no saben clasificar” (18%), “no le interesa” la clasificación de residuos (16%), dicen “no conocer los beneficios” (15%) o el restante (8%) no confía en los sistemas de recolección de basura.
De esta realidad, Guayaquil es la primera ciudad que produce basura generando el 28% del total de desechos diarios del país, y la más elevada a nivel de porcentaje de desinterés: el 29% de los ciudadanos no le interesa clasificar, el 15% no conoce los beneficios y el 6% no sabe clasificar, este desinterés es seguido por Ambato (20%), Machala (14%), Quito (11%), Cuenca (9%).
Por esta razón nuestro proyecto centra sus esfuerzos en esta ciudad y abre su primer capítulo llamado Guayaquil.
Problema dectectado
Los niños no sólo son el futuro, también son el presente del mundo
Los niños de hoy serán los adultos del mañana, si queremos cambiar la forma como las personas interactúan con nuestro planeta, debemos empezar desde edades tempranas creando hábitos amigables con el ambiente, y estos pueden estimularse en la escuela a través de la educación y la creación de espacios destinados a las buenas prácticas ambientales.
Conscientes de los anterior nace la idea de ConciencIA Ecológica el cual busca enseñar a los niños a clasificar sus residuos de forma divertida.
Este proyecto se enfoca en disminuir el desinterés y el desconocimiento en la clasificación de residuos de estudiantes de educación básica en la ciudad de Guayaquil, a través de contenedores con visión inteligente que oriente a niños desde los 5 años hasta los 14 años, en la correcta clasificación y gestión de residuos, promoviendo las prácticas de Reducir, Reutilizar, Reciclar y Recuperar (4R).
La propuesta une varios conceptos, primero buscando que el niño desde la edad escolar se familiarice con la gestión de residuos, orientándose a través de audio y luces hacia el contenedor correcto, también que gestione correctamente el residuo en su contenedor contribuyendo a la clasificación desde el origen, y creando conciencia en el niño a través de mensajes educativos.
Los contenedores están pensados para poder medir el volumen de residuos y emitir una señal al encontrarse el recipiente lleno, esto permitirá a la escuela vaciarlo a tiempo y evitar daños en la compuerta del recipiente.
Génesis de conciencia ecológica
En este punto existía dos decisiones para el módulo central de ConciencIA Ecológica, la primera ubicar un Jason Nano Nvidia, que condensa en su interior la cámara, la capacidad de cómputo y la posibilidad de conectar el micro controlador, o ubicar una Tablet reciclada, utilizar su cámara y alojar la capacidad de cómputo en la Tablet y que esta coordine la clasificación con las señales a los contenedores, las bocinas y las luces.
La decisión se tomó considerando la base del presupuesto que puede tener una escuela, por lo que la segunda opción parece ser la más viable, ya que por menos presupuesto se podrían llevar ConciencIA Ecológica a más escuelas. El equipo estimo 70$ considerando la donación de una Tablet reciclada.
Luego de decidir cómo realizar la clasificación, se pensó en qué se quería clasificar y utilizando la Norma Ecuatoriana INEN 2841, 2014, referente a la estandarización de colores para recipientes de depósito y almacenamiento temporal de residuos sólidos, se establecieron 5 clases: vidrio, papel, cartón, plástico, orgánico.
Que finalmente se agruparon en:
En un contenedor de color verde: Orgánicos.
En un contenedor de color azul: Plástico.
En un contenedor de color blanco. Vidrio.
En un contenedor de color gris: Cartón y Papel.
En un contenedor negro: Desechos, el cual lo establecimientos como los porcentajes de predicción más bajo que presente el modelo.
Pasos para seguir
1. Dataset
Los datos fueron seleccionados de tres fuentes: Un repositorio abierto de imágenes de desechos llamado “Waste datasets review”, en particular con el data set Trashnet, que contiene 2527 imágenes; fotos en páginas web especializadas de fotografías y fotos captadas desde el celular relacionadas con productos que se consideró etiquetar relacionadas al ámbito escolar.
El dataset se construyó con un total de 5000 imágenes en 5 clases: vidrio, papel, cartón, plástico, orgánico. Para el proyecto no se consideró la clase metal. El dataset se dividió en 80% entrenamiento y 20% para validar.
2. Procesamiento: el ABC
Esta fue la fase más larga por el tiempo invertido para hacer los cuadros delimitadores (bounding box). Para el procesamiento se utilizó LabelImg, el cual es una herramienta gratuita de anotación de imágenes gráficas disponible en pip para python3.0 o superior.
Para cada etiquetado se cuidó encerrar el objeto dentro del cuadro delimitador, lo más ajustado posible a la imagen y haciendo tantos cuadros como objetos existieran.
Ejemplo de la utilización de la herramienta LabelImg
Las imágenes fueron guardadas en formato Yolo (*.txt). Este formato establece la clase y las coordenadas de los cuadros delimitadores con la siguiente estructura:(c, xn, yn, wn, hn)
5 Formato yolo (*.txt)
Donde:
c : es el número de la clase, en este proyecto hay 5 clases, donde c puede tomar el valor 0 para cartón, 1 papel, 2 vidrio, 3 plástico y 4 orgánico.
xn: centro del cuadro delimitador normalizado en la dirección x.
yn: centro del cuadro delimitador normalizado en la dirección y.
wn: ancho normalizado del cuadro delimitador (x).
hn: alto normalizado del cuadro delimitador (y).
3. El modelo
El modelo seleccionado fue el YOLOv5 (You Only Look Once). Este es un sistema de código abierto para la detección de objetos en tiempo real pre-entrenado con el dataset COCO, el cual hace uso de una única red neuronal convolucional (CNN) para detectar objetos en imágenes.
De acuerdo con la revisión bibliográfica, Yolo en su quinta versión es un buen algoritmo para detectar objetos en el campo de la alimentación, robótica, salud, entre otros, logrando un buen posicionamiento y reconocimiento de objetos, más precisos que otros algoritmos, incluso versiones anteriores de Yolo. Este equipo seleccionó YoloV5, por considerarlo un algoritmo robusto con buenos resultados en investigaciones recientes relacionadas con detección.
4. Resultados:
El modelo se entrenó 4 veces utilizando la técnica de “Transferencia de aprendizaje, llegando a obtener una mejora del 50% en el último entrenamiento con respecto al primero. En el modelo se usaron las siguientes variables:
Modelo: Se usó la versión Small (Yolov5s) ya que es el más rápido de entrenar y permitió tener una buena idea del comportamiento de la base de dato y del modelo frente al problema. Sin embargo, la desventaja de la rapidez es que se sacrifica precisión en comparación con otras versiones como la Extra Large (Yolov5x)
Pesos (weights): para el primer entrenamiento se utilizó los pesos predeterminados en Yolo, los cuales provienen del entrenamiento del data set COCO, llamado “yolov5.pt. Durante cada entrenamiento se generó un archivo con el mejor peso encontrado, el cual se utilizó para el siguiente entrenamiento.
Épocas: Se inició el entrenamiento con 10 épocas, llegando hasta 30 épocas.
Batch, se mantuvo fijo en 6 para todo el entrenamiento.
Tamaño de imágenes: El data set se configuro para que cada imagen tuviera un tamaño de 640 x 640.
Se aprecia las ultimas variables de entrenamiento
Los resultados de
Matriz de confusión
Precisión y Sensibilidad (Recall)
La matriz de confusión indica que tipo de error está cometiendo el modelo, en el caso de Yolo para el cálculo utiliza una confianza de 0,25 y un límite de IoU (Intersection over Union) de 0,45. Esto quiere decir que para clasificar un objeto este debe tener un 50% de probabilidad de estar en una clase.
La clase para la matriz de confusión en el cálculo de confianza de 0,25 y un límite de IoU (Intersection over Union) de 0,45
Yolo presenta su matriz en valores relativos, donde cada elemento de la matriz está normalizado al total de la columna, por lo que la suma de los valores de cada columna es igual a 1.
Para el data set, tenemos que el cartón lo clasifica relativamente bien, en el 72% de los casos reconoció esta clase, mientras el restante 24% lo clasificó como background. El vidrio lo reconoció en el 85% de los casos, mientras un 10% lo confundió con plástico quizás por la similitud de la transparencia. El papel un 59%, siendo este el valor más bajo, compartiendo un 8% con cartón, y un 32% con el background. Para el caso del plástico se obtuvo un 64% de asertividad, y el restante 34% con el background. Por último, en orgánico se obtuvo un 85% de verdaderos positivos y apenas un 13% de background.
La precisión promedio de todas las clases del modelo fue 0.748, la cual para este tipo de algoritmo es buena, nos indica que de cada 10 imágenes, aproximadamente 7 la clasifica correctamente. Su sensibilidad (Recall) fue 0.723, lo que es una buena medida de la cantidad de objetos por clase clasificados correctamente, en una clase determinada de cada 10 imágenes 7 son correctas, apenas 3 son falsos positivos.
Resultados de las métricas que nos muestra al obtener de la matriz de confusión
5. El prototipio: su crecimiento
Es importante mencionar que el alcance del proyecto se limitó a realizar el prototipado de ConciencIA Ecológica que consistió en el despliegue, la simulación de los componentes del hardware y un bosquejo de una aplicación que conecta la predicción del modelo con el hardware para clasificar imágenes de seis (6) tipos de residuos: orgánicos, vidrio, plástico, papel, cartón, desechos.
A continuación se explicará el funcionamiento del prototipo.
ConciencIA Ecológica consistirá en cinco (05) contenedores de diferentes colores y un módulo central donde se encontrará una Tablet con cámara. Los contenedores se diseñaron pensando en el tamaño de los niños y la forma más fácil de depositar el residuo en estos.
Diseño propuesto
Se buscará que el aprendizaje se realice a través de la interacción del niño con los contenedores, para ello el niño presentará un residuo a la cámara de la Tablet y a través de un modelo, se podrá reconocer hasta seis (6) tipos de residuos: orgánicos, vidrio, plástico, papel, cartón y desechos en general. Luego de reconocer el residuo, se enviará la predicción a una App alojada en la Tablet en el módulo central, la cual mostrará en pantalla lo reconocido y emitirá un sonido con el nombre del material categorizado y el color del contenedor.
Se presenta un bosquejo del proceso del prototipo
Al mismo tiempo, la Tablet enviará una señal a un micro controlador para abrir el contenedor destinado a recolectar el residuo y se enviará una señal que encenderá una luz ubicada en el contenedor. La App emitirá información sobre la práctica de las 4R para promover su uso. El niño finalmente se dirigirá al contenedor señalado y deposita el residuo.
Se presenta un bosquejo del proceso del prototipo
En cada contenedor se instalará un sensor ultrasónico para medir el volumen de residuos acumulados, el sensor enviará una señal a tres led´s que indicarán tres niveles: Disponible (verde), Intermedio (amarillo) y Lleno (rojo). Esto con el fin de evitar que los contenedores rebasen su capacidad, ya que, de producirse, pueden obstaculizar la apertura de la puerta con la entrada de residuos produciendo daños a los servomotores.
Estructura interna del contenedor (arriba sensor ultrasónico)
6. Despliegue
Por otro lado, la aplicación en esta fase no tendrá interacción física con el niño, por el momento servirá como centralizador de la información que viene del modelo y que dirige la acción de la apertura de los contenedores, mostrar en pantalla el resultado, emitir sonido y prender las luces de los contenedores.
La App debe ser iniciada por el administrador, el cual podrá comenzar a ejecutar Conciencia Ecológica a través de su usuario y contraseña.
Diseño de la aplicación propuesta
Inmediatamente, se despliega un menú el cual mostrará un botón de “comenzar a reciclar” que pondrá a Conciencia Ecológica en modo de reconocimiento de residuos. Al darle al botón se enciende el sensor de aproximación y el sensor óptico (cámara); a futuro se tiene pensado implementar un módulo de estadísticas visible en el menú, a los efectos de esta idea de proyecto se colocará como deshabilitado.
Diseño de la aplicación propuesta-iniciando el proceso
En el modo reconocimiento, cuando el sensor de aproximación se activa, se mostrará un mensaje para que el niño presente el objeto a la cámara, cuando detecte el objeto se realizará la predicción.
App en Android para clasificación, mostrando la categorización en tiempo real.
Una vez realizada, se mostrará en la pantalla la clase identificada y emitirá un sonido con el nombre del contenedor, luego emitirá un corto mensaje educativo.
Diseño de la aplicación propuesta con la interacción del sonido
Al mismo tiempo la App enviará la información por bluetooth al micro controlador, el cual se encargará de abrir la compuerta correcta y emitir la señal para encender los led´s. Abajo se muestra un diagrama simulado en Tinkercad.
Bosquejo del circuito
Su futuro: Próximos pasos
Hasta este punto, tenemos una idea de cómo Conciencia Ecológica de una forma sencilla puede orientar a los niños en la creación de hábitos para Reducir, Reutilizar, Reciclar y Recuperar. Pero…
¿hasta aquí llegamos?
A corto plazo, lo primero sería llevar esta conceptualización a la realidad, mejorando cada uno de los aspectos técnicos contemplados en el prototipo. El financiamiento de la Municipalidad de Guayaquil o una institución interesada seria la chispa para propulsar el proyecto.
A mediano plazo, aumentar la base datos e incluir otros materiales para la clasificación, como por ejemplo metal e incluso escalarse el proyecto a empresas para materiales peligrosos como baterías, bombillos ahorradores, bombillo fluorescentes, que están ocasionando un grave problema al ambiente.
En principio, el diseño de los contenedores educativos esta ajustados a las necesidades de cada región e incluso país, ya que actualmente no existe una regulación internacional que dicte las normas de los colores de los contenedores o qué tipo de material se recicla, se puede adaptar Conciencia Ecológica a las necesidades del usuario.
¿Por qué no buscamos que la inteligencia artificial le responda al niño sus inquietudes y dudas?. La App puede ser mejorada para incluir la interacción con el niño y se podría tener una conversación de reciclaje y de aspectos de interés para la educación de los niños de acuerdo a los programas educativos de cada región o país.
Pensando en el futuro de la información. El sensor ultrasónico, podría generar datos a través de la estimación de volumen de cada contenedor. Estos datos ayudarán a llevar la estadística acumulada en el tiempo, sea por contenedor y en sus 5 categorías; así como también por escuelas.
Esta información se alojará en una base de datos para posteriormente alimentar un dashboard de indicadores que permitirá su monitoreo, así como otras funcionalidades como: el control de dispositivos que no estén en funcionando; las escuelas que no están siendo proactivas; tiempo de contenedores llenos sin gestionar; entre otros. En fin una serie de indicadores primordiales, que permita a través de los entes encargados llevar un control de unidades “contenedores” por escuela e incentivar a estas para que su alumnado aprenda jugando.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!