De todos es conocido que la gestión de datos tiene especial relevancia para la captación de posibles clientes para una empresa. Ahora con la implicación de la IA a la captación de clientes, será mucho más fácil. La reducción de tiempo que conlleva utilizar este tipo de nuevas tecnologías permite que los negocios puedan dedicar más tiempo a otras tareas consiguiendo una mayor eficacia en sus procesos. Os vamos a contar cómo captar a tus clientes usando la IA.
Estudios de mercado
Actualmente, para el estudio de mercados, es necesario tratar la información que tenemos a nuestra disposición y saber administrarla adecuadamente más tarde. Si somos conocedores de las preferencias del consumidor a través de nuestros sistemas de datos podemos conseguir una mayor repercusión siendo a la vez más atractivas para nuestros clientes potenciales. Así pues, por otra parte también debemos tener en cuenta que será necesaria la inversión en la IA para ganar penetración en el mercado.
Gracias a la utilización de IA, se consigue tener un trato más personal y directo con nuestro público de interés. Esto es debido a la posible segmentación de mercado generando un marketing directo. Así pues, los clientes reciben publicidad acorde a sus preferencias y a la vez la empresa puede recibir su feedback, ya sea a través de encuestas, compras u otras actividades.
Chatbots
En el caso de los chatbots es es muy importante que las empresas personalicen el contenido para su consumidor final. Para ello, es necesario satisfacer sus necesidades individualmente y al entablar la conversación con este, se evalúe mediante la prueba de Turing a fin de obtener el mejor de los resultados para que, finalmente, el cliente no perciba que está tratando con IA.
La relación con los clientes es de vital importancia ya que cumplir con los plazos acordados establece confianza y buenas recomendaciones a otros posibles consumidores. En la cadena de subministro hay que priorizar ser especialmente serios y perfeccionistas para no cometer errores.
Recopilación de datos
Por otro lado, la misma IA aplicada al marketing nos genera al mismo tiempo datos para integrar todos estos a las posibles recomendaciones y estadísticas que se darán posteriormente a los responsables de marketing y a los consumidores finales. De la misma forma, conseguimos reducir considerablemente la distancia entre oferta y demanda facilitando las decisiones de los encargados de la gestión de marketing de la empresa.
Aplicar estas nuevas estrategias de marketing cada vez se convierte más en una obligación en vez de una opción. La no aplicación de estas perjudica a las empresas que deciden no adaptarse ya que la competencia tendrá un mayor impacto en las redes y difusión de productos en comparación a las que prefieren caer en la obsolescencia. Dejando de lado las múltiples ventajas que conlleva aplicar la IA, tenemos que tener en cuenta que todavía queda recorrido para mejorar.
Perfeccionar estrategias con el trato con nuestros clientes potenciales sin que estos se den cuenta que están tratando con IA nos permitiría mejorar en el sector del marketing. Por otra parte, también es de especial importancia tomar decisiones ajustadas a partir de los análisis realizados una vez se han obtenido los datos generados por nuestros clientes. La inteligencia artificial permite al marketing ser eficiente y eficaz en muchos contextos, permitiendo adaptar este cada vez más a un comercio a granel en función de las necesidades y demandas de cada uno de los clientes.
Por tanto, ¿Qué hace accesible la aplicación de IA en el marketing en la mayoría de empresas a día de hoy?
El crecimiento del Big Data
La disponibilidad de potencia computacional barata y escalable
El desarrollo de nuevas técnicas para su aprovechamiento
Vocabulario de interés
Chatbots
Programa que simula una conversación con un ser humano.
Prueba de Turing:
Consiste en que un humano mantiene una conversación con una computadora y otra persona, pero sin saber quién de los dos conversadores es realmente una máquina. El objetivo de este experimento es determinar si la inteligencia artificial puede imitar las respuestas humanas.
Bibliografía
1.- Carlos Antonio Cuervo Sánchez. Effects of Artificial Intelligence on Marketing Strategies: Literature Review. ADResearchESIC Nº 24 Vol 24 • Primer semestre, enero-junio 2021 • págs.26 a 41.
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.
Algunas mujeres que debemos de conocer en el mundo son las que os mencionamos a continuación, aunque hay muchas más y esta es solo una pequeña muestra.
La inteligencia artificial (IA) está cada vez más presente en nuestras vidas y por ello cabe plantearse algunas cuestiones sobre ella desde el plano político y económico. Desde cómo regular su uso hasta pensar en cómo ser una de las potencias punteras en su investigación y producción pueden ser cuestiones clave que los países se planteen. Este es el caso de la Unión Europea, que lucha por convertirse en la potencia mundial en inteligencia artificial frente de EEUU y China.
Para conseguirlo se están creando grandes bases de datos disponibles para empresas europeas e invirtiendo más de 20.000 millones al año para los desarrolladores europeos, teniendo presente la creación de millones de puestos de trabajo en los próximos 5 años enfocado en la IA. Pero, todas estas actividades deberían de realizarse bajo un marco jurídico adecuado en el que se marque una acción conjunta de los países europeos respecto al avance de la implementación de la tecnología de la inteligencia artificial.
Definición de IA de la Unión Europea
La Unión Europea ha percibido la importancia, necesidad y potencial de la inteligencia artificial en nuestras sociedades y economías. De hecho, «es preciso un marco jurídico claro y predecible que trate los aspectos difíciles de índole tecnológica» tal y como afirma la Comisión Europea. Para plantearnos estas cuestiones es imprescindible saber cómo definiríamos qué se entiende por IA, o en este caso, qué entiende la UE por inteligencia artificial:
El término «inteligencia artificial» (IA) se aplica a los sistemas que manifiestan un comportamiento inteligente, pues son capaces de analizar su entorno y pasar a la acción –con cierto grado de autonomía– con el fin de alcanzar objetivos específicos.
La UE distingue además dos tipos de inteligencias artificiales:
IA de Software Son los asistentes virtuales, software de análisis de imágenes, motores de búsqueda, sistemas de reconocimiento de voz y rostro.
IA integrada Son las IA relacionadas con el internet de las cosas como “robots, drones, vehículos autónomos».
Niveles de riesgo establecidos por la UE
La Unión Europea ha establecido cuatro niveles de riesgo en los que se pueden clasificar la peligrosidad de las inteligencias artificiales. Que una IA se encuentre en un nivel más alto o más bajo depende de si la tecnología desarrollada está bajo control humano, es imparcial, transparente, ética y segura.
Los cuatro niveles de riesgo
Riesgo mínimo. Por lo que una Inteligencia artificial es de riesgo mínimo si no presentan peligrosidad alguna para la seguridad y derechos de los ciudadanos.
Riesgo reducido. Una IA es de es de riesgo reducido son aquellas que requieren un poco de interacción como los chatbots y solo tienen una ligera autonomía.
Riesgo alto. En cambio, si una IA es de riesgo alto, esta afecta a campos como el de la educación, estructuras críticas, aplicación de legislación, migraciones, seguridad, etc.
Riesgo inaceptable o inasumible. Y por ende, una IA sería inaceptable si esta supone un gran riesgo para la ciudadanía.
Legislación europea sobre la IA
Documentos a tener en cuenta al hablar de la inteligencia artificial en la Unión Europea son:
La IA ha llegado para quedarse. Tanto las inversiones realizadas en el marco de New Horizons 2020 y el Plan Next Generation, continuación del anterior, amplía e intensifica las inversiones en este tipo de tecnologías. Siendo muy importante el rol de la IA, por lo que la UE reafirma su apoyo a la utilización de la IA en los laboratorios, así como su difusión y utilización en empresas pequeñas y usuarios potenciales.
En fechas anteriores a la pandemia contaba con que la inversión propuesta por la comisión era de 1500 millones de euros y una atracción de iniciativa privada a través del Fondo Europeo para Inversiones Estratégicas de al menos 500 millones de euros. Todo ello en el plazo de 2018-2020. Y, seguro que tras la pandemia cabría hacer una revisión sobre estos datos ya que, seguramente, habrá aumentado la inversión en IA tras la pandemia provocada por la COVID-19.
Que la Unión Europea haya decido regular la Inteligencia Artificial muestra la gran presencia que tiene y va a tener la IA en nuestras vidas. Por lo que es un ámbito que conviene regular para el avance de estas tecnologías en los próximos años.
¿Qué puedes hacer tú?
Si quieres contribuir al desarrollo de la IA y a su buen funcionamiento, no dudes en formarte con nuestros cursos. Entra en Saturdays.Ai para más información y para comenzar a ser parte del cambio. Cada vez más profesiones van a requerir de conocimientos sobre IA y vamos a tener que lidiar con ella también en nuestro día a día. No pierdas la oportunidad y únete a nuestra comunidad.
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education
La cadena agroalimentaria está llena de innovaciones. Desde la producción hasta la distribución del producto. Agtech es lo último en el sector, relacionándolo con IA.
Una buena alimentación no solo te da más años de vida, fuerza y salud. Además afecta a tu estado anómico, el estado de tu microbiota y tu rendimiento. Tener una dieta que se adapte a tus necesidades y a tu nutrición, el estilo de vida es clave.
El estrés laboral es uno de los principales problemas de salud en el ámbito laboral y del buen funcionamiento de las entidades. El estrés puede dar lugar a comportamientos disfuncionales y no habituales en el trabajo y contribuir a una mala salud física y mental.
La desertificación afecta a más de 15000 millones de personas en todo el mundo. Generalmente, las más afectadas son aquellas con un estatus social bajo y que viven en las zonas más vulnerables del planeta. Cuando hablamos de desertificación, nos referimos a la degradación que la tierra sufre en zonas áridas, semiáridas y secosubhúmedas. Esto se debe mayoritariamente a la gran exposición de las actividades humanas, como la desforestación o bien la sobreexplotación de recursos y por otro lado, las variaciones climáticas que sufre nuestro planeta en forma de sequías o lluvias torrenciales. La mayoría de veces, esta desertificación es irreversible afectando directamente a la pérdida de productividad.
Algunos de los territorios en riesgo son parte del continente africano, de EUA, América de Sur, Australia o España. Para reducir el impacto que la desertificación produce en estas áreas deben ser tratados los factores políticos, socioeconómicos, científicos y/o sociales del momento con el objetivo de conseguir las medidas adecuadas para reducir los efectos que desafortunadamente este suceso conlleva.
La IA y la desertificación
Para los diferentes estudios de la desertificación en las distintas áreas del planeta con riego se utilizan varias técnicas de inteligencia artificial con la finalidad de poder analizar de una forma más exhaustiva todos los datos conseguidos. Para el aprendizaje automático, los métodos más recurrentes son la utilización de: Vecino más cercano (K-NN), Randomforest (RF) o Support vector machine (SVM). Por otro lado, encontramos también el aprendizaje profundo, entre estos destacar el uso de: Perceptrón multicapa (MLP) o las Redes Neuronales Convolucionales (CNN).
Dejando de lado las metodologías utilizadas para el análisis de datos, debemos considerar también de dos tipos de variables para analizar cada una de las distintas situaciones. Así pues, por un lado encontramos las variables biofísicas y por el otro, las socioeconómicas.
VARIABLES BIOFÍSICAS
–Índice de aridez
Se calcula mediante el ratio de la precipitación anual y la evapotranspiración potencial anual (variable entre el rango de 0.05 y 0.65). Gracias al uso de RandomForest, XGBoostasí como redes neuronales artificiales, podemos predecir la evapotranspiración y la precipitación eficazmente.
Estrés hídrico de la vegetación y estado reservas de agua subterránea:
Las redes neuronales convolucionales se han utilizado para completar datos de anomalías en la estimación de almacenamiento de agua terrestre. Por otro lado, el uso del aprendizaje profundo con imágenes térmicas infrarrojas se ha identificado también como una técnica muy útil para la evaluación del estrés hídrico de los cultivos y de la vegetación natural.
–Identificación precisa de pastizales y de carbono orgánico en el suelo:
A través de la combinación del aprendizaje automático y el profundo conseguimos detectar la vegetación y el tipo de suelo a partir de los resultados precisos generados a partir de los algoritmos.
–Imágenes de satélite:
A partir de señales abruptas debido a los cambios en la cubierta vegetal, posteriormente se pueden elaborar mapas precisos de zonas deforestadas a partir del aprendizaje profundo. En comparación al aprendizaje automático, que este nos permitirá por otro lado, predecir zonas potenciales de deforestación para poder conseguir una mejor gestión del territorio afectado.
VARIABLES SOCIO-ECONÓMICAS
–Densidad de población:
La inteligencia artificial nos puede ayudar a cuantificar las redes comerciales productor-consumidor a nivel global y consecuentemente conocer el impacto de la ciudad en el campo. Además, imágenes de drones, aviones o satélites nos permiten elaborar mapas urbanos precisos que nos ayudan a predecir la expansión del territorio urbano.
–Asociación de la renta media y la desertificación:
Usando imágenes satelitales y aprendizaje profundo podemos entender el bienestar económico de la población en los distintos países.
–La agricultura a gran escala, de regadío y el sobrepastoreo:
La inteligencia artificial está ampliamente aplicada en distintos estudios de la agricultura a fin de poder conseguir una gestión sostenible de los recursos para combatir la desertificación.
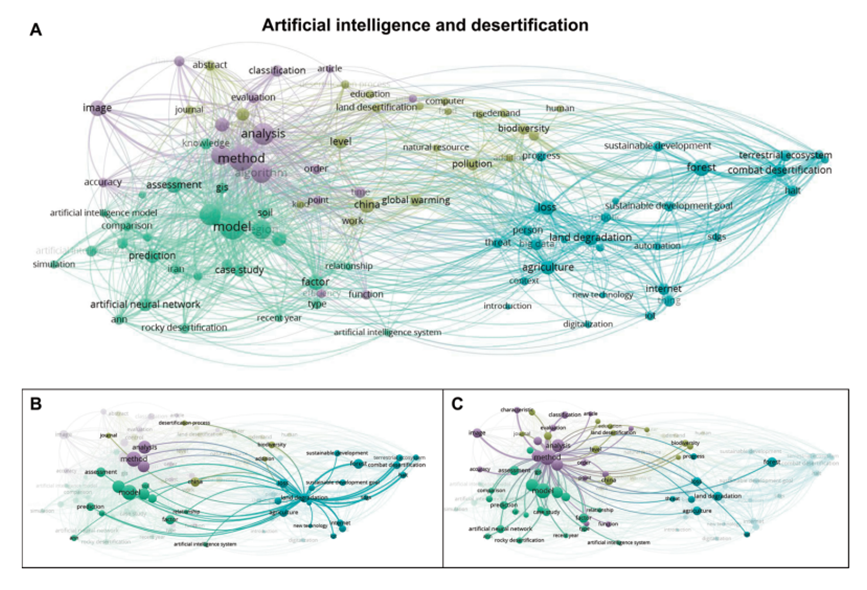
En esta figura podemos observar: A) Mapa conceptual en relación con “inteligencia artificial” + “desertificación” en el que se pueden ver los vínculos entre los términos que actualmente reciben más atención (hasta 2020) en las publicaciones científicas identificadas. B) Conexiones con “landdegradation”. C) Conexiones con los métodos basados en inteligencia artificial, donde se puede observar “neural networks” como término con gran importancia .
En resumen, la inteligencia artificial aplicada en el campo de la desertificación, nos permite dar respuesta a dónde y cuándo podría ocurrir esta. No obstante, cabe remarcar que el estudio es complejo por la cantidad de factores a tener en cuenta. Debemos trabajar de manera síncrona con las distintas escalas espaciales y temporales siendo conscientes de las dificultades que esto supone y teniendo en cuenta además las variables biofísicas y socioeconómicas para tratar la desertificación y abordar el problema que esta ocasiona. Una vez conocido el impacto que tienen estos condicionantes, podremos incidir en las soluciones más adecuadas en cada una de las áreas.
Bibliografía:
1.-Guirado, E., Martínez-Valderrama, J. 2021. Potencial de la inteligencia artificial para avanzar en el estudio de la desertificación. Ecosistemas 30(3): 2250. https://doi.org/10.7818/ECOS.2250
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.
El Four Years From Now (4YFN) en el Mobile World Congress 2022 en Barcelona
Muchos apasionados en el mundo de la tecnología han vuelto al MWC22. Con más ganas que nunca, después de casi dos años de pandemia, y a pesar de los momentos políticos duros que todos estamos viviendo.
En una de las 8 áreas de este congreso tiene lugar lo que se conoce como el Four Years From Now (4YFN) donde diversas start-ups dan a conocer sus proyectos. Objetivo: de hacer difusión entre los diferentes visitantes interesados.
La mayoría somos conscientes que actualmente la IA desempeña un papel fundamental en muchas de las nuevas empresas. Teniendo en cuenta que podemos encontrar este tipo de empresas en eventos como el Mobile World Congres, cabe remarcar las múltiples aplicaciones que esta tiene en ámbitos empresariales tan diversos.
Dos start-up claves
Teniendo presente que eran muchas las start-ups presentes en este espacio compartido en el evento, explicaremos dos de ellas las cuales están relacionadas en el ámbito de la salud y de enorme impacto social dónde aplican la IA para llevar a cabo sus resultados.
Cancer Appy
En primer lugar, Cancer Appy. Este proyecto, a partir de una plataforma digital que proporciona a los centros de salud, hospitales, laboratorios, centros de investigación… permite detectar los marcadores tumorales de los pacientes dando resultados a los especialistas para que posteriormente estos puedan diagnosticar y tratar los diferentes cánceres. Además, permite por otro lado recomendar posibles tratamientos o fármacos a través de los algoritmos diseñados para el programa para las diferentes enfermedades agilizando el proceso. Utilizado así, la IA, el machine learning i la biología a gran escala Cancer Appy permite dar con los mejores tratamientos y subministrar medicinas para los pacientes.
Medbionformatics
Por otra parte, Medbioinformatics es otro tipo de start-up diseñada para el desarrollo potencial de medicamentos a partir de los genes a fin de mejorar la salud de las personas. El programa permite detectar, a partir de un catálogo detallado de todos los genes conocidos a partir de la base de datos, la correlación de las enfermedades existentes con los distintos genes, características y fenotipos. Así pues, se utiliza para mejorar los diagnósticos de las enfermedades, desarrollar nuevos tratamientos o predecir la susceptibilidad individual de tener las enfermedades.
IA, formación necesaria
No es de extrañar pues, que este tipo de nuevas empresas donde todavía les queda mucha inversión e impacto en las distintas áreas de salud así como una mayor repercusión sobre todo en el ámbito público de salud necesite profesionales de distintas áreas. Desde especialistas en detección de enfermedades ya sean estos doctores, biólogos, bioquímicos… hasta profesionales capacitados para tratar datos específicos de las distintas plataformas con IA.
De este modo, comprobamos como la cooperación entre los componentes de equipo es fundamental para tener buenos resultados y generar el impacto social deseado. Ya no solo tratando de cada uno hacer aquello específico en su profesión, sino estar dispuesto a entender otros campos profesionales para traspasar fronteras y poder generar un mayor efecto.
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.
La enfermería es una de las profesiones consideradas con más contacto directo con las personas. A día de hoy, se estudia cómo implementar nuevas estrategias tecnológicas para la sustitución de tareas en este campo con el fin de disminuir las tareas de sus profesionales aportando una notable mejoría en el trato con sus pacientes.
El cáncer de mama es la principal causa de mortalidad en las mujeres. En 2020, alrededor de 685 000 mujeres fallecieron como consecuencia de esa enfermedad. La mayoría de los casos de cáncer de mama y de las muertes por esa enfermedad se registran en países de ingresos bajos y medianos.
El cáncer de mama es el más prevalente entre las mujeres. Se estima que la prevalencia en España en 2020 es de 516.827 personas, según la REDECAN.
Generalmente, el cáncer de mama se origina en las células de los lobulillos, que son las glándulas productoras de leche, o en los conductos, que son las vías que transportan la leche desde los lobulillos hasta el pezón.
A pesar del aumento progresivo de la supervivencia por cáncer de mama, mejorar las tasas de mortalidad de la enfermedad es una necesidad médica y social, puesto que se ha estudiado que un 30% de las pacientes diagnosticadas tendrán una recaída de la enfermedad. Asimismo, el cáncer de mama afecta también a los hombres, siendo más mortal debido a la escasez de tejido mamario, por lo que se extiende a otros órganos con mayor facilidad.
El cáncer de mama es el tumor maligno más frecuente en mujeres y el riesgo de sufrirlo aumenta con la edad, con incidencia máxima a partir de los 50 años. El cribado de este cáncer mediante mamografía, que se realiza entre la población de 50 a 70 años, permite reducir su mortalidad. El 5.4 por mil de los pacientes cribados son positivos. Un diagnóstico precoz de estos casos es fundamental para llevar a cabo tratamiento correcto y eficaz.
Fig. 3 — Mapa de Aragón [Wikipedia]
El año pasado 800 nuevos cánceres de mama fueron detectados tan solo en la comunidad de Aragón.
La tendencia actual es a un incremento de los casos no solo por los hábitos de vida menos saludables, sino que va ligada al incremento de la población en el programa de detección por la llegada de los boomers, como podemos apreciar en el siguiente gráfico. De modo, que la posibilidad de que haya un gran incremento de casos en estos años es bastante alta.
Fig. 4 — Distribución de población objetivo por edades
Como consecuencia de todo lo anterior vemos una necesidad real en la existencia de alguna herramienta que ayude con este problema de detección de cáncer. Es por esto que, animados por el proyecto de Saturdays AI, iniciamos el abordaje de este problema mediante la aplicación del Machine Learning y posterior desarrollo de una herramienta (Mama Mia) de predicción del diagnóstico de Cáncer de Mama.
Fig. 5 — Emblema Saturdays AI
Se trata de una solución que se alinea a la perfección con el ODS 3: Objetivo de Desarrollo Sostenible Salud y Bienestar.
Fig. 6 — ODS 3
Asimismo con el ODS 10 de Reducción de Desigualdades, ya que es en zonas de menores ingresos donde se registran más muertes. Se libera el uso por de todo el trabajo aquí realizado.
Fig. 7 — ODS 10
¿Cómo lo vamos a hacer ?
Como todo proceso en que se quiere implementar una tecnología en algún negocio es necesario una metodología. No reinventaremos la rueda, vamos a hacer uso de la metodología iterativa CRISP-DM (Cross Industry Estándar Process for Data Minnig) que nos facilita una guía estructurada en seis fases, algunas de las cuales son bidireccionales, pudiendo volver a una fase anterior para revisarla.
Conseguidos a partir de una imagen digitalizada de un aspirado con aguja fina (FNA) de una masa mamaria, describen las características de los núcleos celulares presentes en la imagen.
Fase 2 — Data Understanding (Comprensión de los datos)
Hemos comenzado el proyecto viendo con qué datos contamos específicamente. Tras obtener nuestros datos de UCI y entrando en detalle, nuestra base de datos se compone de 31 variables útiles que podemos desglosar en la variable de diagnóstico (si es positivo o negativo) y 10 parámetros que definen las células se dan bajo 3 situaciones: el valor promedio, la desviación estándar y el peor caso.
Radio
Textura: Desviación estándar de los valores de la escala de grises
Perímetro
Área
Uniformidad: Variación local en diámetros
Compactibilidad: Perímetro²/área — 1
Concavidad: Severidad de los puntos cóncavos del contorno.
Puntos cóncavos: Número de puntos cóncavos del contorno
Simetría
Dimensión fractal: aproximación a una esfera perfecta, que corresponde a 1.
Estas 30 variables se obtienen a partir del análisis de la biopsia.
Dentro de nuestros datos tenemos 213 casos malignos y 357 casos benignos.
Fig. 9 — Histograma diagnóstico
Fase 3 — Data preparing (Preparación de datos)
Aparte de las 31 variables útiles encontramos una columna con valores NaN que eliminamos junto con el ID (identificador) de cada caso ya que no aporta ninguna información para la predicción y sustituimos los datos de diagnóstico: M y B por valores numéricos binarios: 1 y 0.
Por lo que lo primero ha sido ver que tipo de datos teníamos: todos números de coma flotante excepto el diagnóstico. Analizando los datos podemos ver que no tenemos valores NaN y tienen los siguientes datos estadísticos:
Tabla 0 — Estadísticas de los datos
Hemos obtenido la gráfica de correlación mediante un mapa de calor para ver cómo se relacionan entre sí las variables y en nuestro caso la relación con la que más nos importa: el diagnóstico (‘diagnosis’).
Podemos ver en la primera fila como hay parámetros con una alta correlación directa (colores claros) y parámetros con una leve correlación inversa (colores oscuros).
Fig. 10 — Mapa de correlación de las variables
Ahora vamos a comprar todas las variables mediante diagramas de caja, separando para cada variable los casos malignos (en rojo) y los casos benignos (en verde). Estas gráficas nos sirven para ser capaces de identificar algunas variables claves. Estas serán aquellas que la distribución de malignos y benignos sea muy diferente.
Fig. 11 — Diagramas de caja casos malignos y benignos (promedio)
Fig. 12 — Diagramas de caja casos malignos y benignos (desviación estándar)
Fig. 13 — Diagramas de caja casos malignos y benignos (peores casos)
Vemos que se producen con bastante frecuencia valores atípicos, normalmente por encima. Esta variabilidad es posible ya que los datos en estudios médicos suelen ser más variables que los que podemos encontrar en otras bases de datos.
Antes de pasar al modelado debemos normalizar las variables para hacer predicciones de mejor calidad.
Fase 4 y 5 — Modeling and evaluation (Modelado y evaluación)
Dada la tipología de datos que tenemos hemos usado modelos supervisados (los datos están etiquetados) y de clasificación (predice una categoría). Los modelos que hemos evaluado son:
Regresión logística
Árbol de decisión
Random forest
Extra tree
Super Vector Machine (SVM)
Gradient Boosting
K — vecinos más cercanos (KNN)
MLP classification
En estos modelos hemos probado con random state 2. Para ello antes de introducirlos en el modelo hemos separado los datos con una relación 70–30 en entrenamiento y evaluación respectivamente.
Tras evaluar estos modelos hemos obtenido los siguientes resultados:
Fig. 14 — Métricas de todos los modelos
Tabla 1 — Métricas de los modelos
Podemos ver cómo obtenemos valores de excatitud (accuracy), precisión (precision), Recall y F-score superiores al 90%. Los modelos con un F-score mayor del 95% son los que destacamos de cara a los mejores modelos de cara a las siguientes etapas, no sin antes comprobar varias elementos del modelo.
Se trata de un modelo con un alto número de características por lo que nos planteamos varias preguntas: ¿Se podría conseguir un resultado con menos variables? ¿Hay dependencias entre estas? ¿Son buenos resultados siempre o ha sido casualidad del random state?
Para ello pasamos a observar la importancia de las variables (en los casos que nos lo permite).
Variables de influencia
Fig. 15— Variables de influencia Regresión logística
Fig 16. — Esquema de decisión del Árbol de decisión
En el caso del árbol de decisión (Decision tree) podemos ver según qué variables va clasificando.
Fig. 17 — Variables de influencia del Árbol de decisión
Fig. 18 — Variables de influencia Random forest
Fig. 19— Variables de influencia Extra tree
Reducción de variables y nuevas métricas
En base a la importancia de las variables que hemos visto hemos elegido 3 combinaciones para simular: con 10, 16 o todas las variables. Elegidas tal que así:
Tabla 2 — Variables de los modelos
Se obtienen los siguientes resultados en las predicciones para cada uno de los 3 casos:
Tabla 3 — Métricas de los modelos 30 parámetros
Tabla 4 — Métricas de los modelos 16 parámetros
Tabla 5 — Métricas de los modelos 10 parámetros
Fijamos un criterio de elección de un F-score de 95% mínimo, por lo tanto elegimos un modelo con 16 parámetros ya que permite predecir con unas métricas suficientemente buenas pero con casi la mitad de parámetros que la opción de 30 parámetros.
Tras esto pasamos a ver cómo es su comportamiento frente a la predicción de probabilidades en relación con el efecto de la semilla. Para ello miraremos en las 200 primeras semillas, cómo se comportan. Para ello realizaremos un histograma donde iremos acumulando las probabilidades con las que predice tanto para verdaderos positivos como negativos, y para falsos negativos y positivos.
Fig. 210— Distribución de probabilidades Decisión tree
Fig. 21 — Distribución de probabilidades Random Forest
Fig. 22 — Distribución de probabilidades Gradient Boosting
Fig. 23 — Distribución de probabilidades Extra tree
Fig. 24 — Distribución de probabilidades Regresión logística
Fig. 25 — Distribución de probabilidades K vecinos más próximos
Fig. 26 — Distribución de probabilidades Perceptrón multicapa
Con todas las simulaciones realizadas vemos como hay ciertos modelos que concentran sus valores en más altas métricas y más concentradas, estas seremos las que elegiremos.
Fig. 27 — Exactitud y Precisión de los modelos
Fig. 28— Recall y F-score de los modelos
Variando únicamente el estado aleatorio inicial, conseguimos muy altas métricas máximas, clasificadas en esta tabla.
Tabla 6 — Métricas máximas de los modelos
Una vez elegimos los mejores modelos (con mayores y más concentradas F-score): SVM, Regresión logística y MLP Classification (Perceptrón Multicapa).
A partir de ahora probaremos a conseguir mayor robustez mejorando los 3 modelos finalistas. Para ello testearemos diferentes combinaciones y una vez seleccionado el modelo (o combinación de modelos finalistas) pasaremos a optimizarlo (si se puede).
Hemos elegido los modelos de Regresión logística, Support Vector Machine, y Perceptrón Multicapa. Ya que tienen altas métricas en un rango que ha variado menos, por lo que suponemos mejor.
Ensamble de varios métodos
Una vez tenemos modelos muy buenos, uno incluso con métricas del 100% decidimos combinarlos. ¿Por qué combinarlos si ya tienen métricas excelentes? Para que sea más robustos y sea más posible que frente a un caso no evaluado ni entrenado acierte el resultado.
Probando con Adaboosting y Bagging obtenemos peores métricas.
Y con voting obtenemos unos valores levemente menores distribuidos tal que así:
Fig. 29— Probabilidades Voting
Con unas métricas de:
Tabla 7— Métricas de voting
Selección de modelo
Seleccionando las mejores semillas obtenemos las siguientes histogramas:
Fig. 30 — Probabilidad Regresión logística
Fig. 31— Probabilidad Super Vector Machine
Fig. 32 — Probabilidad MLP Prediction
Vemos cómo el MLP predice con unas probabilidades mucho más altas, pero con un falso negativo. Destaca la regresión logística que acierta el 100% de los casos. Aquí podemos ver las métricas de los modelos:
Tabla 8 — Comparativa métricas de los modelos
Ajuste hiperparámetros
Vamos a usar la librería de Scikit-Learn para ajustar los hiperparámetros del algoritmo de cara a encontrar cuales serían los valores que mejorasen los datos anteriormente obtenidos.
Hacemos uso de GridSearchCV con los siguientes valores:
Kernel: linear,poly,rbf y sigmoid
C: 1000, 10, 1 y 0.01
Gamma: 0,001 y 0,001
Obteniendo los mejores resultados de 97,11%, con C igual a 1, gamma igual a 0,001 y kernel linear.
No conseguimos ninguna mejora significativa a los parámetros por defecto.
Resultados finales
Elegimos regresión logística ya que es la que mejores resultados ha tenido y la hemos preferido al voting ya que no podemos asegurar que con el voting obtengamos un sistema más robusto.
Fase 6 — Deployment (Despliegue)
Una vez elegido y ajustado el modelo, para evitar realizar de nuevo el proceso, es guardado mediante la librería joblib pudiendo así utilizarlo posteriormente. Para dotar el proyecto de una gran accesibilidad decidimos publicar una web que utilice el modelo, para lo cual, recurrimos a la librería open-source: streamlit, que nos permite de una forma sencilla crear una sencilla aplicación web que utilice dicho modelo.
Tan solo es necesario crear un formulario de recogida de datos para que se rellene y al enviar el formulario, la web normaliza y escala los datos de acuerdo a los datos con los que ha sido entrenado el modelo para pasárselos a este y que realice la predicción.
Fig. 33 — Pantalla principal de la aplicación de MaMamIA
Próximos pasos
Complementar la predicción de diagnóstico del cáncer de mama con la predicción de la recurrencia del cáncer.
Desarrollo de una aplicación con la opción de introducir distinto número de variables en función de la precisión que se busque.
Implementación de predicción mediante fotografías.
Integrantes
Víctor Villanova (vvb.curioso@gmail.com)
Estudiante del Programa conjunto en máster de Ingeniería Industrial y máster de Energías renovables y eficiencia energética. Apasionado de lo desconocido y la naturaleza, manitas y scout.
Miguel E. Calvo (mecalvon@gmail.com)
Actualmente Técnico de Gestión de Sistemas y T. I en el SALUD (Gobierno de Aragón). Curioso e inquieto tecnológico.
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!