La Paz. 2021
Introducción
El resumen de texto es el proceso de extraer la información más importante de un texto fuente para producir una versión abreviada para un usuario. Los seres humanos llevamos a cabo la tarea de resumen, ya que tenemos la capacidad de comprender el significado de un documento y extraer características destacadas para resumir los documentos utilizando nuestras propias palabras. Sin embargo, los métodos automáticos para el resumen de texto son cruciales en el mundo actual, donde hay falta de trabajadores y de tiempo para interpretar los datos.
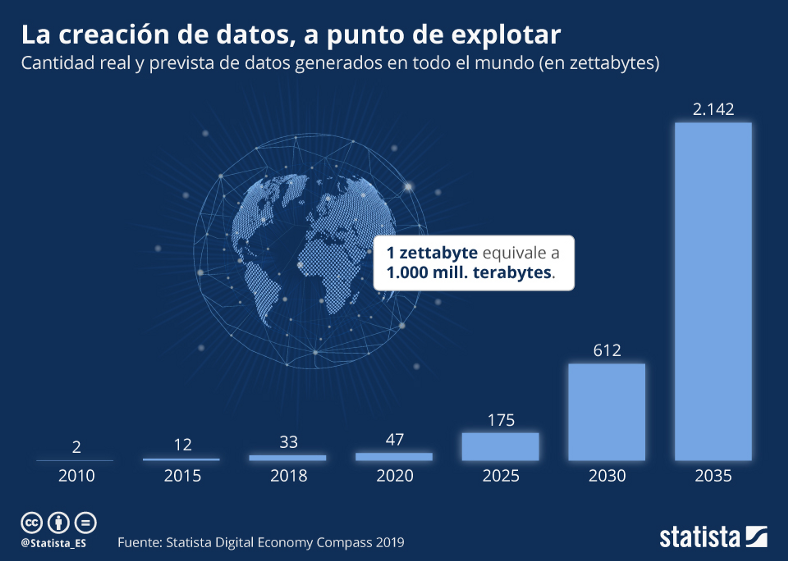
Figura 1: Cantidad de datos generados de manera anual
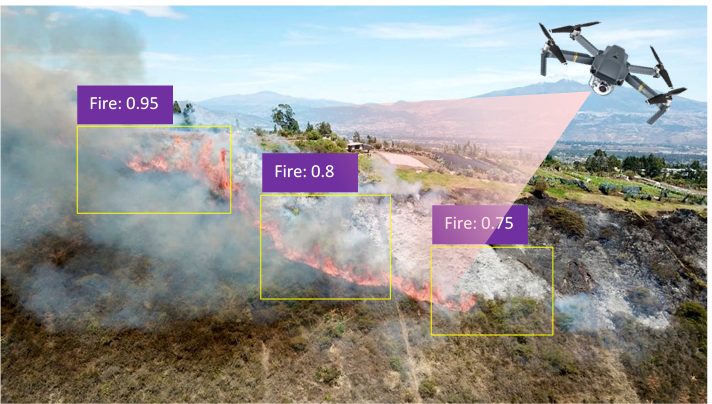
Problema
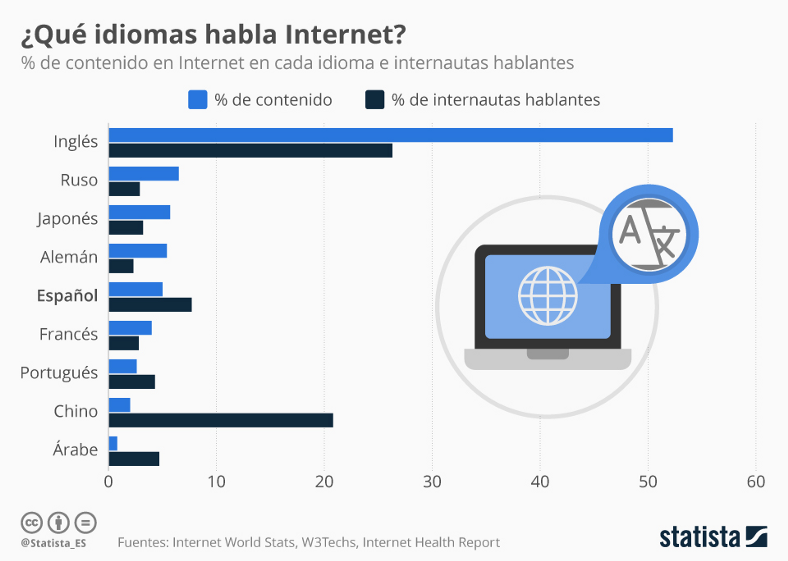
Figura 2: Idiomas predominantes en internet
Hoy en día, con el constante crecimiento de la información el estar actualizados en cualquier tema es una necesidad. Pero las fuentes de información usualmente son extensas y poseen una gran cantidad de texto pero lo más importante es que la información está en inglés.
Objetivo
Desarrollar una aplicación que pueda ayudar a la comprensión de un documento de texto en inglés y acorte el tiempo de comprensión de un texto largo.
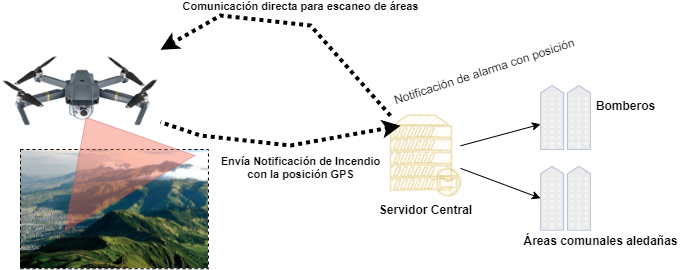
Solución propuesta
Hacer la aplicación en base a métodos de DeepLearning enfocados a attention mechanism. Estas técnicas imitan la atención cognitiva. Esto provoca la mejora en las partes más importantes de los datos de entrada y desvanece el resto.
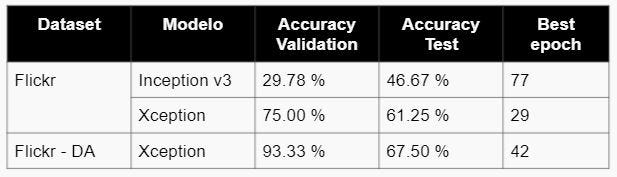
Dataset
CNN Daily Mail es un conjunto de datos de más de 300 mil artículos en inglés escritos por periodistas en CNN y en Daily Mail. El tamaño del conjunto de datos es de 1.27 GiB en la versión actual, esta admite el resumen extractivo y abstracto, aunque la versión original se creó para la lectura y comprensión automática y la respuesta a preguntas abstractas. Los datos se pueden usar para entrenar un modelo para el resumen abstracto y extractivo
Modelo de DL
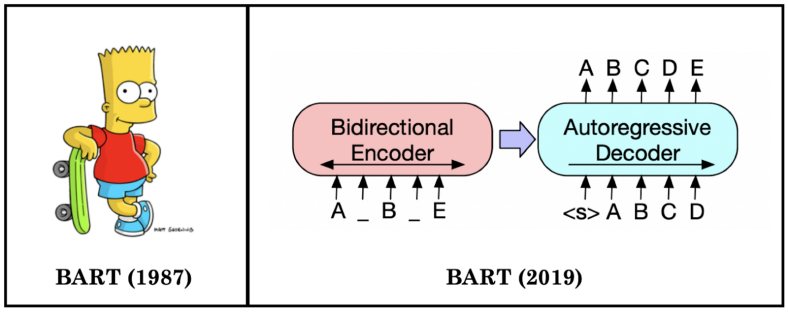
Figura 3: Esquema BART
BART es una arquitectura que se basa tanto en BERT y GPT, BART utiliza la arquitectura de transformer seq2seq estándar pero, después de GPT, que modificamos las funciones de activación de ReLU a GeLU. La arquitectura está estrechamente relacionada con BERT, con las siguientes diferencias:
- Cada capa del decodificador, además, realiza una atención cruzada sobre la capa oculta final del codificador (como en el modelo de secuencia a secuencia del transformador)
- BERT utiliza una feed-forward network antes de la predicción de palabras, lo que BART no hace.
Entonces en pocas palabras usa la comprensión de texto o input de BERT y GPT para el output o la generación de palabras.
Para trabajar con este modelo se lo hizo mediante el modelo base que nos provee HuggingFace.
HuggingFace es una plataforma Open Source que se enfoca en NLP, nos ayuda a construir, entrenar e implementar modelos que son estado del arte. En este caso nos ayudó a construir el modelo y con el dataset.
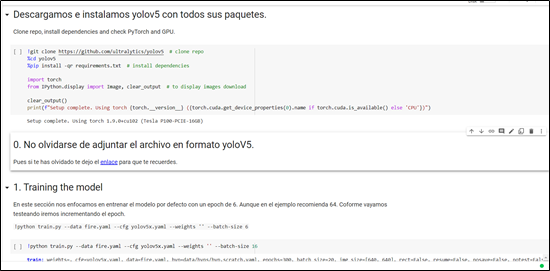
Entrenamiento del modelo
El proyecto fue realizado en base a los modelos provistos por la página de Hugging Face, la cual posee una gran colección tanto de modelos como de datasets para tareas de NLP (Procesamiento de Lenguaje Natural). De todas las opciones se seleccionó el modelo de sumarización abstractiva BART.
El código hace uso de las librerías “datasets” y “transformers” de HuggingFace, además de nltk para realizar la evaluación.
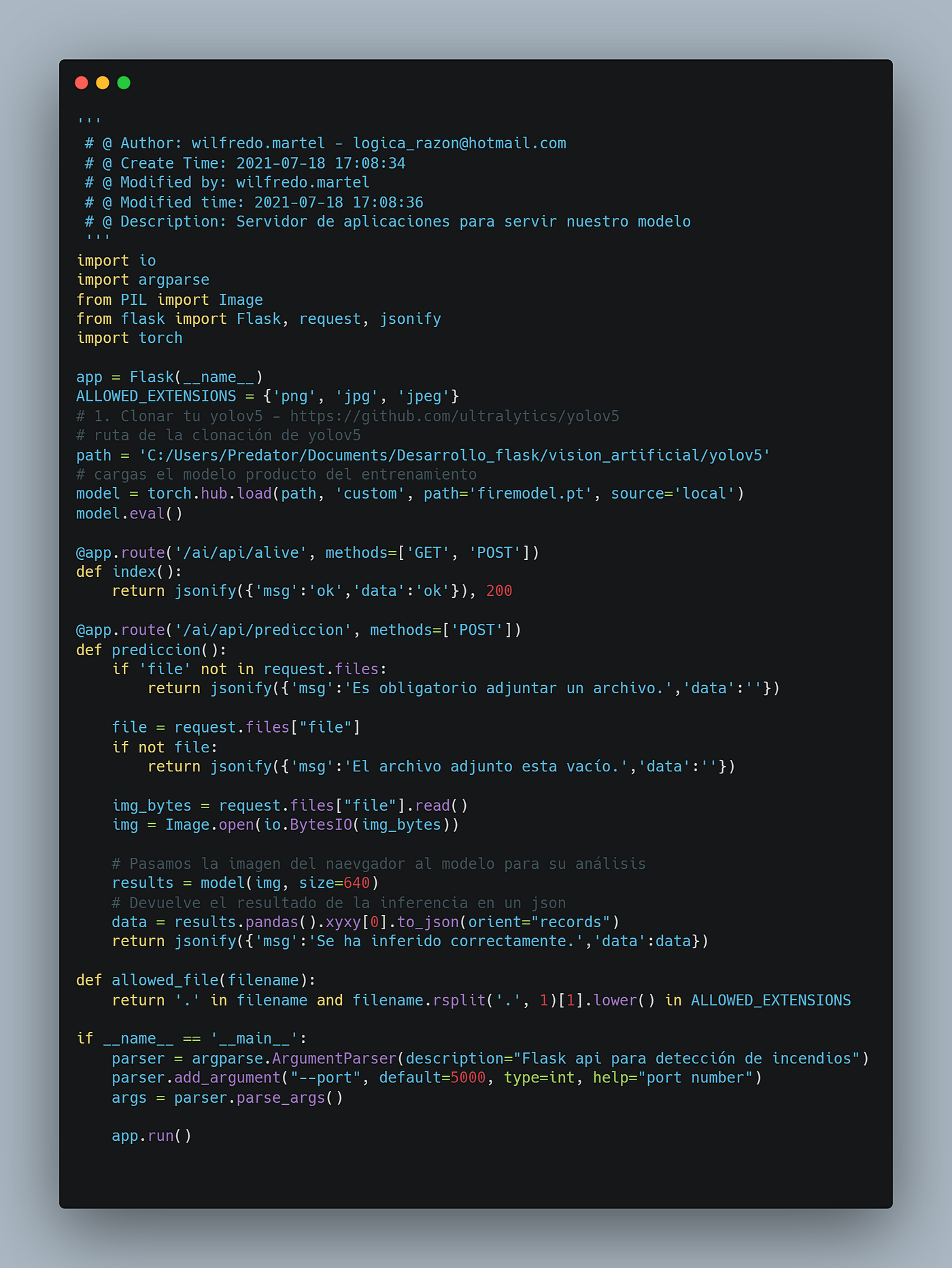
# Imported libraries
from datasets import load_dataset, load_metric
from transformers import AutoTokenizer
from transformers import AutoModelForSeq2SeqLM,
DataCollatorForSeq2Seq, Seq2SeqTrainingArguments, Seq2SeqTrainer
import nltk
import numpy as np
from transformers import pipeline
Para realizar el fine tuning se hizo uso del dataset “cnn_dailymail”, para la evaluación se utilizó la métrica “rouge”, y el modelo base que se usó fue “facebook/bart-base”.
raw_datasets = load_dataset(“cnn_dailymail”, “3.0.0”)
metric = load_metric(“rouge”)
model_checkpoint = “facebook/bart-base”Se cargaron un tokenizer y un modelo haciendo referencia al modelo base seleccionado.
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
Del dataset “cnn_dailymail” se extrajeron los elementos que se encuentran bajo las etiquetas de “article” y “highlights” como datos de entrada y salida respectivamente.
max_input_length = 512
max_target_length = 128def preprocess_function(examples):
inputs = [doc for doc in examples[“article”]] model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(examples[“highlights”], max_length=max_target_length,
truncation=True)model_inputs[“labels”] = labels[“input_ids”] return model_inputstokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
Antes de entrenar el modelo se realiza la configuración de hiperparámetros.
batch_size = 4
args = Seq2SeqTrainingArguments(
“BART_Finetuned_CNN_dailymail”,
evaluation_strategy = “epoch”,
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
gradient_accumulation_steps=2,
weight_decay=0.01,
save_total_limit=2,
num_train_epochs=1,
predict_with_generate=True,
fp16=True,
)Se crea una función para realizar el cómputo de métricas haciendo uso de rouge score.
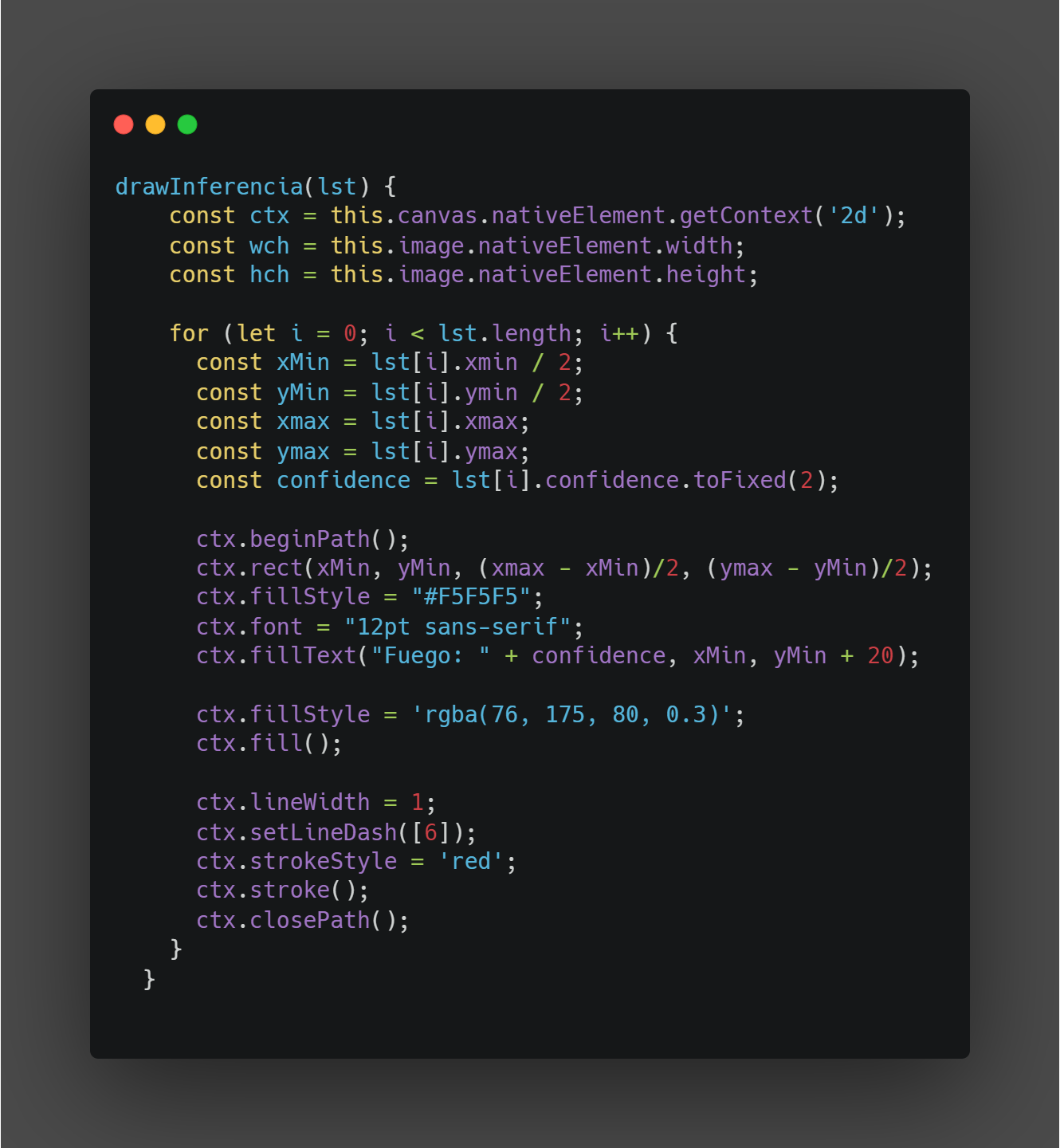
def compute_metrics(eval_pred):
predictions, labels = eval_pred
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
# Replace -100 in the labels as we can’t decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)# Rouge expects a newline after each sentence
decoded_preds = [“\n”.join(nltk.sent_tokenize(pred.strip())) for pred in decoded_preds]decoded_labels = [“\n”.join(nltk.sent_tokenize(label.strip())) for label in decoded_labels]
result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
# Extract a few results
result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
# Add mean generated length
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in predictions]result[“gen_len”] = np.mean(prediction_lens)
return {k: round(v, 4) for k, v in result.items()}
Una vez inicializado el modelo, definidos los hiperparámetros, datasets, tokenizer y métricas creamos un Trainer.
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets[“train”],
eval_dataset=tokenized_datasets[“validation”],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)Descargamos punkt tokenizer que nos permite transformar un texto por oraciones.
nltk.download(‘punkt’)Finalmente realizamos el entrenamiento y la evaluación
trainer.train()trainer.evaluate()
Resultados
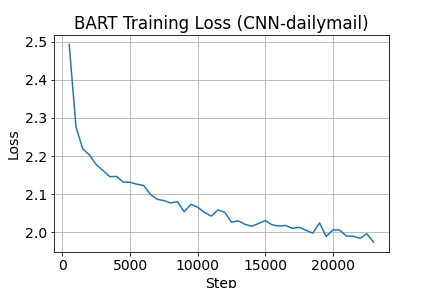
Figura 4: Pérdida a lo largo del entrenamiento
Una vez finalizada la fase de entrenamiento podemos observar la pérdida a lo largo del entrenamiento realizado en el dataset “train”.
Si bien se muestran buenos resultados, se pueden mejorar haciendo mejor sintonización y tiempos de entrenamiento con el modelo.
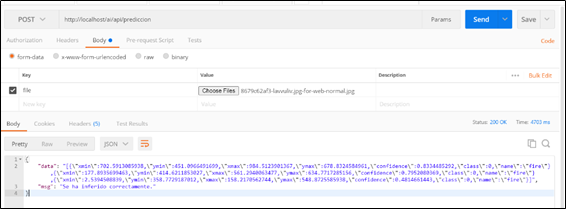
Los resultados obtenidos al evaluar el modelo entrenado con la métrica rouge score fueron los siguientes:
eval_loss: 1.5510817766189575
eval_rouge1: 46.8771
eval_rouge2: 23.5647
eval_rougeL: 39.6525
eval_rougeLsum: 43.3625
eval_gen_len: 17.8154
Conclusiones
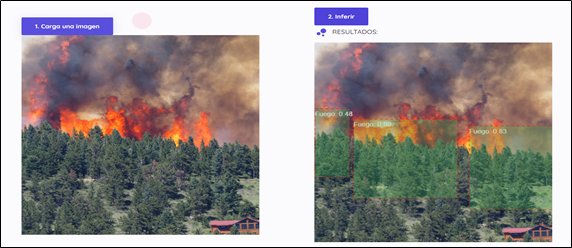
Se logró realizar una aplicación que resume y traduce el texto dado, se vio que los resultados obtenidos son óptimos para la tarea.
Se usó dos modelos para hacer la aplicación, el primer modelo es el que se entrenó de resumen este modelo ya esta en huggingface , para la parte de traducción se usó un modelo ya entrenado de huggingface. (https://huggingface.co/Helsinki-NLP/opus-mt-en-es).
Trabajo Futuro
Mejorar los tiempos de inferencia que tienen los modelos al usar servicios en la nube.
Expandir los tipos de entradas que pueda tener, puesto que ahora solo soporta texto puro. (txt, docx)
Integrantes
Sergio Flores. — www.linkedin.com/in/sergio-flores-ll
Anna Montevilla. — www.linkedin.com/in/anna-i-montevilla
Koichi Sato. — www.linkedin.com/in/koichi-sato-316902182
Josmar Suarez. — www.linkedin.com/in/josmar-suarez-l
Referencias
https://arxiv.org/abs/1910.13461v1
https://huggingface.co/datasets/cnn_dailymail
https://huggingface.co/transformers/model_doc/bart.html
https://arxiv.org/abs/1810.04805
https://medium.com/walmartglobaltech/the-journey-of-open-ai-gpt-models-32d95b7b7fb2
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) a la vez que se realizan proyectos para el bien (#ai4good). Los talleres que realizamos forman parte del programa AI 4 Schools para que cualquier persona “aprenda haciendo” IA sin importar su especialidad o nivel de partida.
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en este link o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
WRITTEN BY