Reconocimiento de emociones mediante el estudio de expresiones faciales con deep learning y computer vision.
Can AI boost tradition?
Tradition, from latin tradere, to transmit, is the act of sharing a behavior or belief from generation to generation. And as such, this heritage becomes part of our ourselves, our identity.
Innovation, in contrast, is the introduction of new ideas, of new ways or approaches that change how things were done before. This new approaches are often seen as a threat to tradition, as the adoption of new methods or behaviors tends to change the way that things were done, the tradition.
However, do things always need to be this way? Can innovation be used to leverage and spread tradition among society?
Donostia. 2021
Bertso, doinu and neurri a glimpse of the basque tradition
Among the various treasures basque culture has manged to keep alive are bertsoak, improvised verses with rhyme that are sung following a doinu, a melody, that has to match with certain neurri, or verse length.
This bertsos are typically sung in front of an audience, and, the bertsolaris, the basque rhyme singers, sing about different topics which are provided by the moderator, gaijartzaile, while they interact with the rest of bertsolaris (in a rather acid way) in pursue of the public’s applause.
How does this look like? Well lets take a look of how a modern bertso saio looks like lets take a look to the following video.

Did you notice that the base used by both of the bertsolari is the same? This base is called doinu(a). Doinus are transmitted from generation to generation, and it is very important for bertsolaris to know them well, because they need to use the doinu suggested by the gaijartzaile (moderator) or the other bertsolaris to sing their bertsoz.
Can we improvise over the improvisation?
Bertsos are like rap, and rap battles happen on the fly, there is no script to follow. This means the abbility of the bertsolari to improvise becomes the cornerstone of the bertso. However, the base, the doinu, is already known by everyone, it is something fixed, rigid.
Which is a pity, isn’t it? If improvisation is part of the great art of the bertsolari… Why not provide an improvised doinu so that the bertso experience becomes even more challenging and unique?
With these thoughts in mind, and with the newly adquiered Deep Learning skillset, @jperezvisaires and @klopetx had an instant match in our mind. If there was anything that could create doinus by itself… that would be a Generative Adversarial Network.
Could bertsolarism be revolutionized with the use of AI?
Well… maybe not that much, but it was worth a try.
GANS where technology and tradition (could) meet
With the insightful courses we had during our SaturdayAI lessons, we learned about the latest innovations on the field of Deep Learning, such as the different architectures, (convolutional, recurrent, autoencoder…) as well as the different uses such as reinforcement learning and generative adversarial networks. The question at this point was, could the magic of generative adversarial networks be used to create new doinus? If so, what did we need for that purpose?
Data! Of course.
Gathering the data
Fortunately for us (and for the basque culture) there exists an entity, Bertsozale Elkartea, who has a webpage that includes all the known doinus, around 3000, with their meta-data included. It is in basque, but just in case you wanted to give it a look.
And well… you know what they say right?
It’s easier to ask for forgiveness than to get permission…
So… We scrapped the web (thank you bertsozale for your work, and sorry for overloading your servers and getting your data wihout formally asking permission).
First we downloaded the metadata of the doinus. We made a selection of the most used ones considering the number of syllables and type, and we donwloaded the ‘Zortziko/Txiki’ ones that had 7 syllables in the first berse followed by 6 in the second which decreased the list of doinus to around 200.
Midi format
«But wait a minute, donwload what exactly?»
Fortunately for us, we had the chance to download the doinus in either mp3 or midi formats.
«Midi? What’s that? I know about mp3 but midi reminds me of how french people names the mid day…»
MIDI (Musical Instrument Digital Interface) is a technological standard used to transfer up to 16 information channels. It transfers messages of events that include musical notation, tone and speed among other things. Basically, this files explain what notes are played, when, for how long and how loud.

Example of a midi.
Feeding our little generative monster
Once the data was ready, we just needed to feed the GAN.
And our experience of using midi directly for the GAN is perfectly summarized by the following poem:
We used the midi as input
Well, at least we tried
we faced some problems
and hence, gave up.
You know, everyone uses Deep Learning with images, why should we do otherwise?
So, instead of using midis directly, we created images with them, cause, due to the nature of the midi files, it is quite simple to visualize/represent them as images.
Once at the more comfortable image domain it was easier to work with the problem, as there is much more content dealing with images and convolutional neural networks.
GAN structure
Let’s take a breath for a second. We started talking about how well GANs are supposed to work in the creation of new unheared soinus, but what are GANs exactly?
GANs were introduced by Goodfellow et. al. and are essentially two separate models that are trained together with an opposed purpose. One of the models, the generator, generates new data samples from a random seed; the second model, the discriminator, tries to tell whether the data is original (real) or if it was created by the generative model (fake). Due to their behavior, they are typicall compared to a counterfeiter and a cop. The counterfeiter keeps improving the quality of the works while the cop gets better at detecting which ones are real or faked.
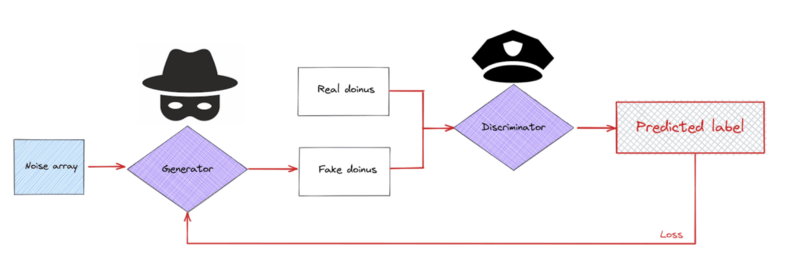
The structure of a GAN fed with doinus.
Basically, during the training process, the counterfeiter should get much better at creating new data (in this case images of new possible doinus) while the cop should improve at the detection of fake doinus, forcing the improvement of the counterfeiter. At some point, the generative model should be good enough at creating doinus that it would become absolutely impossible for the discriminative model to discern among real or fake doinus, meaning we have a model capable of creating good enough doinus.
MiliaGAN, the generator part of the GAN.
Easy peasy lemon squeezy isn’t it?
SPOILER: Nothing went as expected.
Round 1: If what one has to say is not better than silence…
We started to feed our monster (well, monsters actually).
We waited until the training converged.
And we freaked out with the resulting doinus.

Yep, this is not a mistakenly black image, its a “shy” midi with no notes.
Yes, an empty midi. Apparently our GAN was so smart that it preferred to remain silent instead of saying something worse than silence… It went full Simon & Garfunkel and published its own version of the Sound of Silence.
Why?
The images we were trying to create were really sparse, with lots of zeroes and only some ones on the notes being played. The generator initially learnt that by switching all the pixels off, it could trick the dumb discriminator at the beginning. However, during training, at some point, even the dumbest of discriminators was able to detect that a blank image was not a real doinu, which meant that all the efforts made by the generator to produce blank images from noise were now worthless. The generator was not able to adapt fast enough to trick the new discriminator and the training diverged.
To solve the problem of sparse images, we took the argmax of all the columns, esentially turning a 128×1024 image into a a 1×1024 vector. This was possible because the doinus only play one note at a time.
Lesson: Ensure you synthesize your data as much as possible, make life easy for your neural network.
Round 2: Damn it! Who cares about mixing different doinus?
Initially, we wanted the generator to focus on creating one type of doinu only; the most popular doinu: zortziko txikia. We only had about 180 usable samples of this kind of doinu, and it soon became apparent that training GANs requires a substantial amount of data just to get barely passable results. So instead of focusing on a small fraction of the doinus, we decided to take all the database in the end. This meant jumbling all kind of different doinus together, but got us a dataset of around 2700 samples; still really small for GAN training, but worth a shot.
Yeap, the whole database with the different neurris, rhymes etc.
Everything.
Goes.
In.
In addition, we reduced the resolution of the images so that they were less sparse, in order to avoid the problem of the shy gan.
And we reduced the midi resolution even more. We needed to simplify if we wanted to make some kind of progress.
And, surprisingly, the magic happened.
Lessons learned
So, what have we learned after the creation of our little monster, the MiliaGAN?
- The amount of data needed to properly train a GAN is a lot more than we had available, bigger datasets give better results in this kind of networks. Few-shot learning in GANs is a key point being worked on in the academic community right now.
- Time is key in training GANs, if the training is stable and there aren’t any divergences, the results keep improving with training time, sometimes getting pretty good results as the training goes on.
- Simplify the data to be generated and fed to the neural networks as much as possible. Make life easier for your neural networks. Sparse matrices are the devil and should be condensed into a vector if possible, as neural networks love to give outputs full of zeroes if this are available to them.
Final remarks
The MiliaGAN project has been a great chance to learn DeepLearning techniques, and Generative Adversarial Networks in particular. It has only been possible thanks to the help from the AI Saturdays crew, who have created an ideal environment to learn about AI, boost the creation of a great community and the development of new projects and ideas. And, of course, to the rest of Fellows, that have helped and shared their thoughts. We are very grateful to all of you for making MiliaGAN possible. Thank you for creating this great community!
On the personal side, this project has been both challenging and a great source of fun. It combines two key aspects of our identity, our culture and our geekness. It is, additionally, the first time that Jon and Kerman join forces in a crazy technological project (not first time for crazy projects, but this is not the place for this discussion).
Will MiliaGAN revolutionize the world of bertsolarism? We frankly doubt it, but hey, if someone ever asks, we had fun and we learned.
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) a la vez que se realizan proyectos de impacto social (#ai4good). Si quieres aprender más sobre este proyecto (y otros) únete a nuestra comunidad en o aprende a crear los tuyos en nuestro programa AI Saturdays.
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!



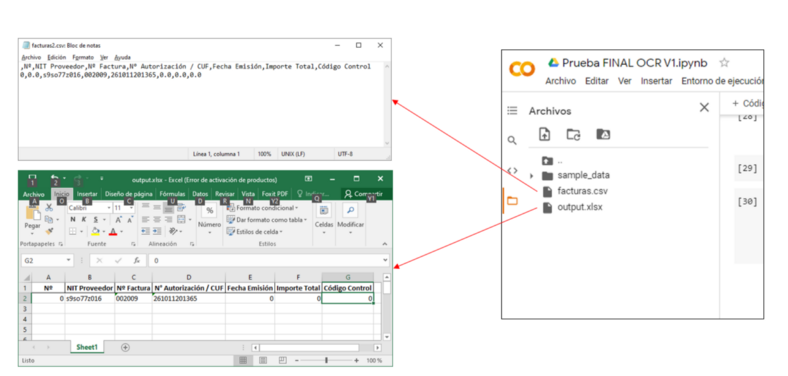


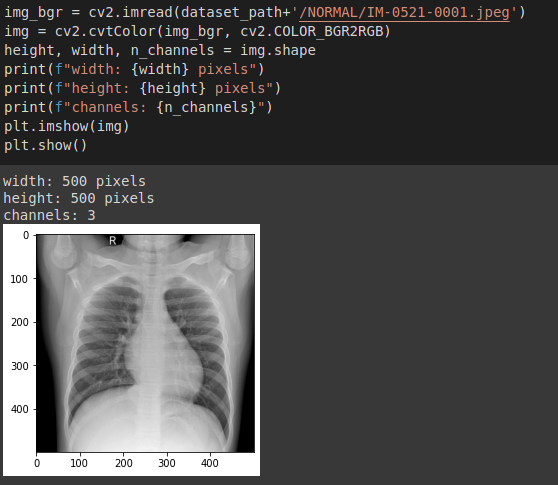
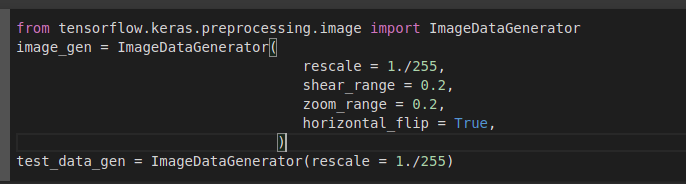
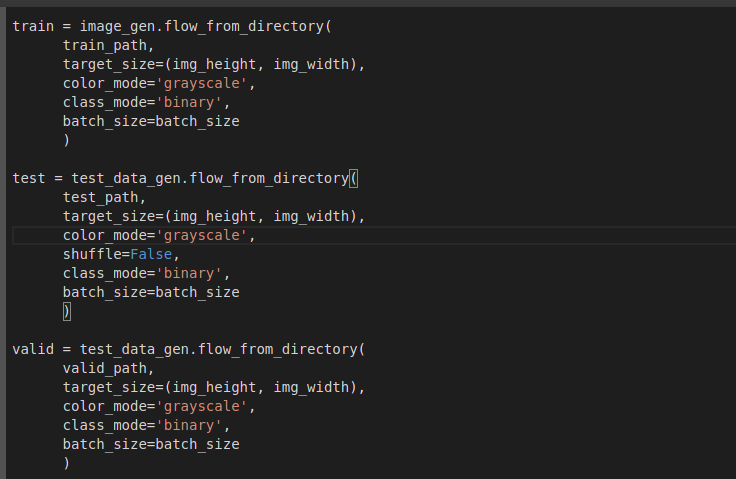
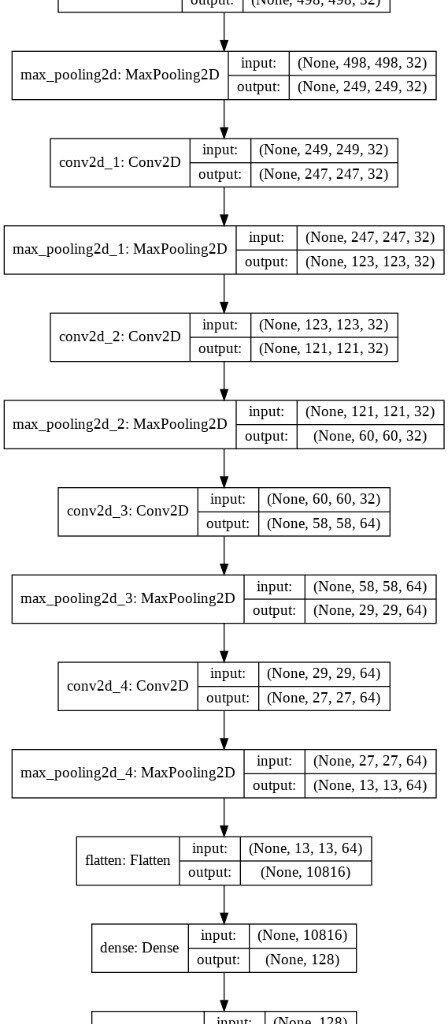



Detección de fatiga en conductores de vehículos mediante Inteligencia Artificial
La Paz. Deep Learning. 2021
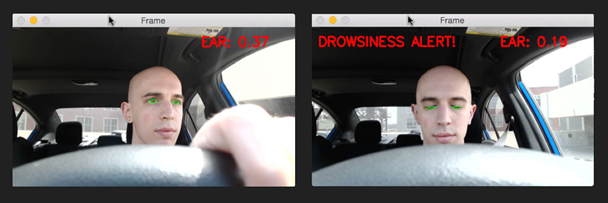
Las herramientas de visión artificial han demostrado vez tras vez el gran potencial que posee en sus distintas áreas de aplicación. Una de estas está justamente relacionada con los vehículos y sus conductores. Abarcando desde movilidades autónomas hasta herramientas de uso personal el espectro es muy amplio. Por ello, en este texto se explica la implementación de un detector de fatiga en conductores mediante Inteligencia Artificial utilizando OpenCV y Dlib.
DESCRIPCIÓN DEL PROBLEMA
Los accidentes de tránsito son una de las principales causas de muerte en ciudadanos de todos los países. Estos se pueden clasificar de acuerdo a sus causas. Se calcula que entre un 20% y un 30% de los accidentes se deben a conductores que conducen con fatiga. Si bien la fatiga al conducir es un riesgo evitable, lastimosamente, muchos conductores no toman las precauciones necesarias cuando conducen por periodos prolongados de tiempo. Por lo tanto, los conductores con fatiga pueden beneficiarse de un sistema de Inteligencia Artificial que los alerte al momento de perder la atención.
OBJETIVO
Diseñar un sistema para detectar la fatiga en conductores.
SELECCIÓN DEL MODELO
Se seleccionó un modelo de visión artificial pre entrenado basado en la librería cv2 de OpenCV y dlib para detección facial.
TÉCNICAS IMPLEMENTADAS
- OpenCV: La biblioteca libre de visión artificial que se está usando para obtener la imagen del conductor.
- Dlib face landmarks: Son 68 puntos que se colocan sobre el rostro detectado para la identificación de facciones faciales, en este caso los ojos.
- NumPy: Esta biblioteca se está usando para el cálculo de la proporción de abertura de los ojos, mediante álgebra lineal y el posicionamiento de los puntos faciales de los ojos.
EVALUACIÓN DE MODELOS
El sistema construido hace uso de un modelo pre entrenado de detección facial. Con ayuda de las bibliotecas previamente mencionadas se realiza un procedimiento como sigue:
- Se carga el modelo detector y predictor que son los que detectan el rostro del conductor así como los 68 puntos faciales.
- Una función lineal detecta la proporción de aspecto en los ojos midiendo distancias entre los puntos oculares.
- Según el valor que se obtenga en esta proporción el programa se ramifica según el estado que considere correspondiente (despierto, cansado o dormido). Para que se considere la transición de un estado a otro debe haber una permanencia en ese estado durante un periodo de tiempo.
- El sistema indica en pantalla el estado identificado, este es el paso donde podría activarse o no una alarma.
- Este procedimiento se realiza fotograma a fotograma para tener una predicción constante del estado de fatiga de la persona.
ANÁLISIS DE RESULTADOS
Como se utilizó un modelo pre entrenado los resultados obtenidos por el detector facial y de los puntos de referencia del rostro son buenos.

Sin embargo, los resultados que obtuvimos en la detección del estado de fatiga son más bien fluctuantes. En ocasiones el sistema es poco sensible y no detecta estados con los ojos cerrados o, por el contrario, el sistema es pronto para indicar un estado posiblemente falso. Las razones que podrían causar este problema incluyen la calidad del video y el enfoque exclusivo en los ojos del conductor (cuando podrían tomarse en consideración otros factores como la boca).

CONCLUSIÓN
El proyecto ha desarrollado un sistema funcional capaz de detectar la fatiga en conductores de vehículos. La consistencia en estas detecciones no es buena así que se proponen algunas sugerencias: Aplicar operaciones de erosión y dilatación para reducir el ruido en la captura de video, implementar un sistema que detecte la proporción de abertura de la boca para aumentar la consistencia, y modificar los umbrales de detección para ajustarse a las necesidades de cada conductor.
INTEGRANTES
Carlos Claure –https://www.linkedin.com/in/carlos-manuel-claure-vargas-475226212
Raquel Calle –https://www.linkedin.com/in/raquel-veranda-calle-zapata-460226212
Liders Limpias –https://www.linkedin.com/in/limpiaslider/
Alejandro Carrasco. –https://www.linkedin.com/in/miguel-alejandro-carrasco-c%C3%A9spedes-785717215/
REFERENCIAS
Presentación del proyecto: DemoDay
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!Saturdays.AI

WRITTEN BY
Raquel Calle

Saturdays.AI
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.
FindPet: Identificación de mascotas perdidas con Inteligencia Artificial
La Paz. Deep Learning. 2021
En este artículo utilizaremos técnicas de Inteligencia Artificial para encontrar mascotas perdidas. Aquellas personas que han perdido a una mascota por diferentes motivos saben que aunque muchas regresan a sus dueños un gran porcentaje no logra el reencuentro. Unas 420,000 mascotas, entre perros y gatos principalmente, se pierden anualmente en el Perú y son muy pocas las que son encontradas o devueltas a sus dueños, debido a que es muy difícil identificarlas.
La identificación de mascotas por lo general se hace a través de plaquitas metálicas colgadas en su cuello, con su nombre y el teléfono del propietario. Otros optan por insertarles un chip bajo la piel y algunos pocos, por lo costoso, prefieren los GPS e, incluso, tatuarlas. Ante la pérdida de sus mascotas, las personas optan por buscarlas mediante carteles pegados en postes, a través de redes sociales, anuncios en medios de comunicación u ofreciendo recompensas en dinero o con entradas a conciertos o partidos de fútbol. Es por ello, que el objetivo de este proyecto es poder ayudar a las personas a encontrar a sus mascotas perdidas mediante Inteligencia Artificial y Deep Learning para la identificación de sus mascotas de manera rápida, precisa y económica.
Problemática
Diariamente, se calcula que se extravían aproximadamente entre 30 y 40 animales domésticos, entre perros y gatos, solamente en Lima. Sin embargo, se estima que esta cifra puede ser mayor, no solo al contabilizar el resto de las ciudades de Perú, sino también porque muchas personas no saben cómo o dónde pueden reportar la pérdida o extravío de su mascota. Muy pocas mascotas son encontradas o retornadas con sus dueños, debido a que es difícil poder identificarlas y hacer el rastreo correcto. Como consecuencia de ello, muchas de las mascotas terminan como animales callejeros causando sobrepoblación que terminan contaminando la ciudad con sus heces y los parásitos que son expulsados a través de estas.
Objetivo
Desarrollar una aplicación que ayude a las personas a reportar y encontrar mascotas perdidas de manera rápida usando Inteligencia Artificial con técnicas de Deep Learning.
Datasets
Se utilizaron datasets existentes y de acceso libre, para la clasificación de razas se utilizaron los datasets de Stanford que contiene imágenes de 120 razas de perros de todo el mundo y Thudogs que contiene 130 razas de perros junto con los bounding boxes de todo el cuerpo y la cabeza del perro en cada imagen; mientras que para la identificación de mascotas se utilizó Flickr que contiene sólo los rostros del perro y está dividido por nombre del perro perteneciendo solo a dos tipos de raza: pugs y huskies.

Proceso de Identificación de Mascotas
El proceso de identificación de mascotas perdidas mediante Inteligencia Artificial consta de cuatro fases como se muestra en la siguiente figura, a continuación se detalla cada una de ellas.
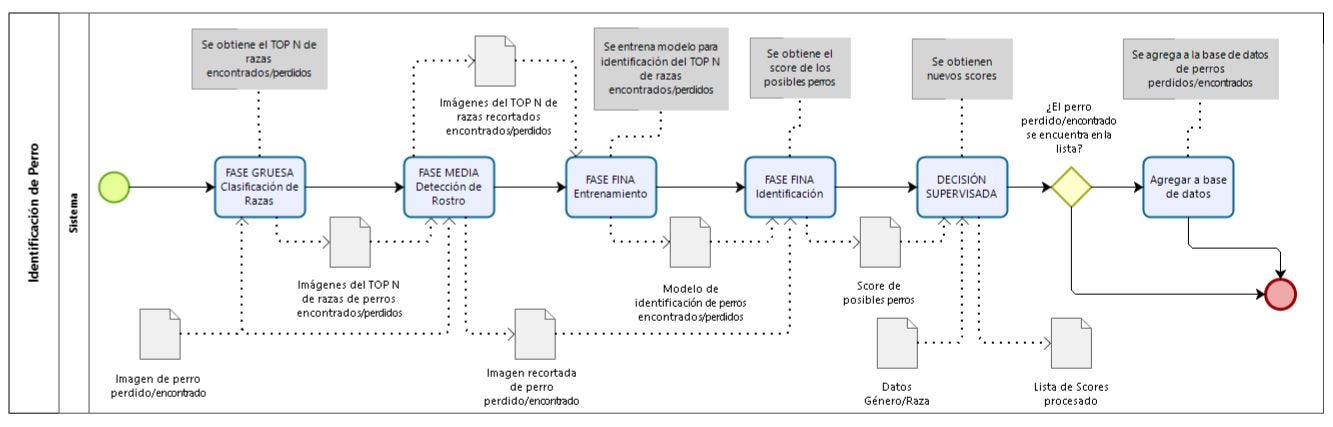
- FASE GRUESA: Clasificación de Razas
En esta fase, ingresa la imagen de un perro perdido o encontrado y se evalúa con el modelo de clasificación de razas y como output se obtiene el top N de razas a la que pertenece el perro, esto sirve como input para la fase media donde solo ingresarán las imágenes que se tenga en base de perros encontrados o perdidos que se tenga de estas “N” razas.
- FASE MEDIA: Detección de Rostro
En esta fase, se tiene como input la imagen del perro encontrado y el resultado de la clasificación de esta imagen obteniendo las imágenes de top N de las razas, para ser evaluados por el modelo de detección de rostros, en este caso yolo v5, obteniendo como output los bounding boxes del rostro del perro para cada imagen.
- FASE FINA: Identificación de la mascota
En esta fase, ingresa como input las imágenes del perro encontrado o perdido junto con las imágenes del top N ya recortadas el rostro utilizando los bounding boxes obtenidos de la fase media, para hacer el entrenamiento del modelo de identificación de rostro.
- DECISIÓN SUPERVISADA
Finalmente, para hacer una decisión más precisa utilizamos decisión supervisada con parámetros como la edad y el género del perro, para poder acotar y tener más precisión para identificar al perro correcto.
Modelos
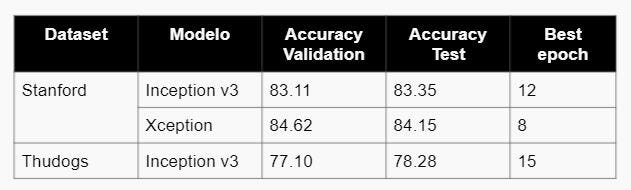
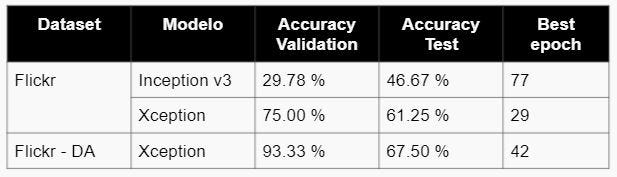
Para la construcción del modelo de clasificación de razas e identificación de mascotas se utilizó Redes Neuronales Convolucionales, específicamene Inception v3 y Xception, ya que que se trata de un problema de clasificación de imágenes con N posibles salidas, donde N es el número de razas o número de nombres de perros, en el caso del dataset de Stanford N tiene un valor de 120 , para Thudogs 130 y Flickr 42. Para la construcción del modelo de detección de rostro de la mascota se usó Yolo v5.
- Inception v3
Inception-v3 es una arquitectura de red neuronal convolucional de la familia Inception que realiza varias mejoras, incluido el uso de Label Smoothing, convoluciones factorizadas 7 x 7 y el uso de un clasificador auxiliar para propagar información de etiquetas en la parte inferior de la red, junto con el uso de batch normalización para capas en la cabecera lateral.
A continuación, se muestra el diagrama de arquitectura de Inception v3:
- Xception
Xception significa “xtreme inception”. Esta arquitectura replantea la forma en que vemos las redes neuronales, en particular las redes convolucionales. Y, como sugiere el nombre, lleva los principios de Inception al extremo.
En una red convolucional tradicional, las capas convolucionales buscan correlaciones tanto en el espacio como en la profundidad. En Inception, comenzamos a separar los dos ligeramente. Usamos convoluciones 1×1 para proyectar la entrada original en varios espacios de entrada más pequeños y separados, y de cada uno de esos espacios de entrada usamos un tipo diferente de filtro para transformar esos bloques de datos 3D más pequeños. Xception lleva esto un paso más allá. En lugar de dividir los datos de entrada en varios fragmentos comprimidos, asigna las correlaciones espaciales para cada canal de salida por separado y luego realiza una convolución en profundidad 1×1 para capturar la correlación entre canales.
A continuación, se presenta el diagrama de arquitectura de Xception, donde los datos pasan primero por el flujo de entrada, luego por el flujo medio que se repite ocho veces y finalmente por el flujo de salida. Tenga en cuenta que todas las capas de convolución y convolución separable van seguidas de la normalización por lotes.
- Yolo v5
Yolo v5 es un modelo de detección de objetos, y su primera versión oficial fue lanzada por Ultralytics. Como YOLO v5 es un detector de objetos de una sola etapa, tiene tres partes importantes como cualquier otro detector de objetos de una sola etapa.
- Model Backbone: se utiliza principalmente para extraer características importantes de la imagen de entrada dada. En YOLO v5, las CSP — Cross Stage Partial Networks se utilizan como backbone para extraer una gran cantidad de características informativas de una imagen de entrada.
- Model Neck: se utiliza principalmente para generar pirámides de características. Las pirámides de características ayudan a los modelos a generalizarse bien en la escala de objetos. Ayuda a identificar el mismo objeto con diferentes tamaños y escalas. Las pirámides de características son muy útiles y ayudan a los modelos a funcionar bien con datos invisibles. Hay otros modelos que utilizan diferentes tipos de técnicas de pirámide de características como FPN, BiFPN, PANet, etc.
- Model Head: se utiliza principalmente para realizar la parte de detección final. Aplicó anchor boxes en features y genera vectores de salida finales con probabilidades de clase, objectness scores, y bounding boxes.
A continuación se muestra el diagrama de arquitectura de Yolo v5:
Resultados
- FASE GRUESA: Clasificación de Razas
- FASE MEDIA: Detección de Rostro

- FASE FINA: Identificación de la mascota
Conclusiones y Recomendaciones
- En la fase gruesa de clasificación de razas, se concluye que el modelo más óptimo es Inception v3 con un accuracy de 83.35% usando el dataset de Stanford y 78.28% para el de Thudogs.
- En la fase media de detección de rostros, se probó únicamente el modelo Yolo v5 obteniendo un MAP de 98.5%.
- En la fase fina de identificación de rostros, se concluye que el modelo más óptimo es Xception con un accuracy de 67.5% para el dataset de Flickr una vez realizado el data augmentation.
- El uso de modelos de deep learning en la identificación de mascotas perdidas disminuirá el tiempo de retorno de la mascota a su hogar, permitiendo hacer el rastreo correcto.
- En la fase fina se recomienda probar GAN’s para data augmentation.
- En la fase gruesa, se sugiere combinar los datasets de Stanford y Thudogs, y probar los modelos desarrollados.
- En la fase gruesa, se recomienda crear un dataset propio para identificación.
- En la fase media, se sugiere probar nuevos modelos adicionales a yolo v5.
Referencias
- Dog Identification using Biometrics and Neural Networks
https://arxiv.org/pdf/2007.11986v1.pdf
- Dog Breed Identification Using Deep Learning
https://www.researchgate.net/publication/328834665_Dog_Breed_Identification_Using_Deep_Learning
- Yolo v5
Presentación del proyecto: DemoDay
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!Saturdays.AI
WRITTEN BY
Mishel Carrion Lopez
Saturdays.AI
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.
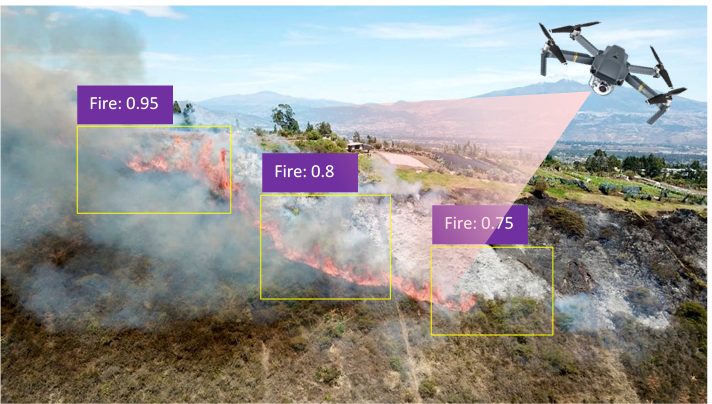
Detección Temprana de Incendios en Áreas Forestales con Inteligencia Artificial- Parte I
Quito. 2021
¿Sabes cuántas hectáreas se queman cada año por causa de incendios forestales? ¿Sabías que producto de esto muchas especies dejan su hábitat en busca de un nuevo hogar?¿Me creerías si te dijera que podemos utilizar la tecnología sobre todo la Inteligencia Artificial para disminuir el impacto de los incendios forestales? En este artículo, utilizaremos la Inteligencia Artificial para detectar de forma temprana incendios en áreas forestales.
Yoal igual que tú estaba un poco escéptico al inicio, pero déjame contarte cómo el ser humano puede ayudarse de la tecnología para frenar estos atentados contra la madre naturaleza. Por eso te invito a leer nuestra idea de cómo detectar incendios desde sus etapas muy tempranas para poder frenarlos y así evitar grandes desastres. ¿Te imaginas un mundo donde podamos minimizar este tipo de incendios forestales? Pues aquí colocamos casi todo lo que necesitas para llevar a cabo este proyecto y te conviertas en un defensor de la Pachamama.
Primero pasos
La idea del proyecto para detectar incendios forestales mediante Inteligencia Artificial comenzó una tarde en el taller que llevábamos en Saturday AI y con los compañeros: Luis Marcelo Viteri Aguilar, Danilo Josue Erazo Quinaluisa, Jonathan Alejandro Zambrano Mejía y Wilfredo Martel; decidimos hacer frente a esta problemática.
Idea General
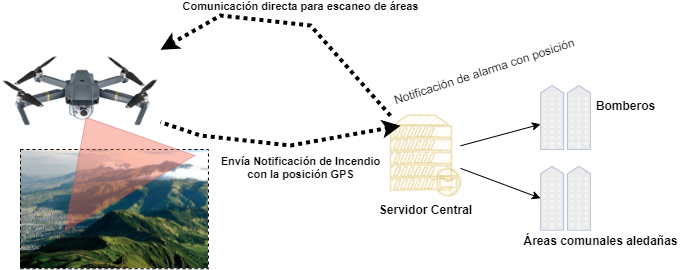
La idea del proyecto de Detección Temprana de Incendios Forestales es utilizar la Inteligencia Artificial con ayuda de un Dron compuesto con un GPS y una cámara para que escaneen áreas forestales y en caso de detectar incendio envíen la alarma a un servidor principal que se encargará de notificar a los bomberos y comunidades aledañas informándoles con una foto del sector, la posición en un mapa y el porcentaje de estimación con la finalidad de evitar que se propague el incendio y arrase con la flora y fauna del sector.
Problemática
Enel 2020, más de 5.5 millones de hectáreas fueron devastadas por incendios forestales a nivel mundial teniendo un gran impacto sobre la flora y fauna salvaje que habitaba en esta área.
En Ecuador, en el mismo año se perdieron aproximadamente 23.462 hectáreas y debido a la estructura montañosa de los lugares es complicado para los bomberos llegar a tiempo. El fuego devastador devoró todo a sus alrededores y tuvieron que pasar en el mejor de los casos semanas para mitigar el incendio y en el peor de los casos meses.
Ante este alarmante problema con impacto social y ambiental se pensaron soluciones que ayuden a detectar a tiempo los incendios forestales, es entonces cómo surge la idea de fusionar la Inteligencia Artificial (de ahora en adelante I.A.) con un dron para la detección temprana de incendios en las áreas forestales de nuestro país. La idea consiste en entrenar un modelo de I.A. (detectar fuego en cualquier superficie) que interactúe con el dron el cual dispondrá de una cámara y un GPS, por lo tanto, en tiempo real se sabrá la posición del incendio y enviará una alarma a los bomberos para su mitigación.
Fase de Ejecución
Para llevar a cabo la ejecución de este grandioso prototipo, que desde ya se observa a la distancia los beneficios, se realizó en cinco fases:
- Fase de recolección de datos (dataset)
- Investigación previa de modelo Pre-entrenados de I.A.
- Reentrenamiento y Validación del modelo
- Deployment del modelo
- Desarrollo de un sitio Web para presentación del Prototipo
Antes de continuar se aclara que la fase de integración con el dron, el servidor, notificación a las comunidades y bomberos queda pendiente para la segunda parte de este artículo.
1. Fase de recolección de datos e Investigación de modelos para Clasificación de Imágenes
Esta fase se enfocó en la recolección de imágenes de incendios forestales ocasionados alrededor del mundo y en nuestro país. Se logró obtener un total de 250 MB de información la cual se empleará como entrada para el aprendizaje de nuestro modelo.
Una vez ya obtenido el dataset, como una tarea en paralelo se realizó una investigación de modelos de I.A. clasificadores de imágenes y el que escogimos debido a su efectividad fue Yolo v5. Esto a la vez significa que se tiene que realizar un proceso de anotación que consiste en dar las coordenadas del segmento a caracterizar dentro de una imagen.
En otras palabras, explicaremos lo que implica en nuestro dataset el utilizar Yolo v5:
1. Se debe anotar o indicar los segmentos a aprender dentro de la imagen. En nuestro caso son poner las coordenadas donde hay fuego y de esta manera la herramienta Yolo V5 pueda aprender y obtener patrones de diferenciación. Para saber más sobre el proceso de anotación de Yolo v5 se recomienda echar una lectura a este enlace para despejar sus dudas.
2. Para el proceso de anotación se utilizó una herramienta de mucha ayuda llamada HyperLabel que la encontramos en enlace.
3. Una vez que se obtuvo las anotaciones, que básicamente es un archivo xml que hace alusión a la imagen con sus coordenadas, se procede a generar un archivo para el formato de Yolo v5. Para este proceso se siguió el código github ai-coodiantor.
Con estos pasos ya ejecutados, se tiene preparado el entrenamiento personalizado con nuestro propio dataset.
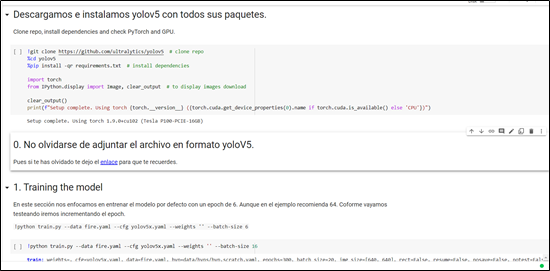
2. Reentrenamiento y Validación del modelo
Para la parte de entrenamiento del modelo ya pre-entrenado se utilizó Google Colab Pro con GPU v100 y un tiempo estimado de 12 horas para su finalización. Al finalizar el proceso se obtuvo como resultado del entrenamiento un modelo de inferencia con extensión .pt. En nuestro caso, nuestro archivo fireModel.pt que servirá de insumo para inferir sobre imágenes de prueba. Antes de avanzar hay que aclarar que este modelo una vez que pase todas las pruebas, se pondrá en un dron mediante una placa Nvidia Jetson TX2 para su procesamiento en tiempo real, en donde cuando se detecte algún indicio de incendio forestal se proceda a enviar la alarma a instituciones tales como: Bomberos, Comunidades aledañas etc.
A continuación, en la Ilustración 2 se muestra el código que se utilizó para entrenar el modelo de detección de incendios.
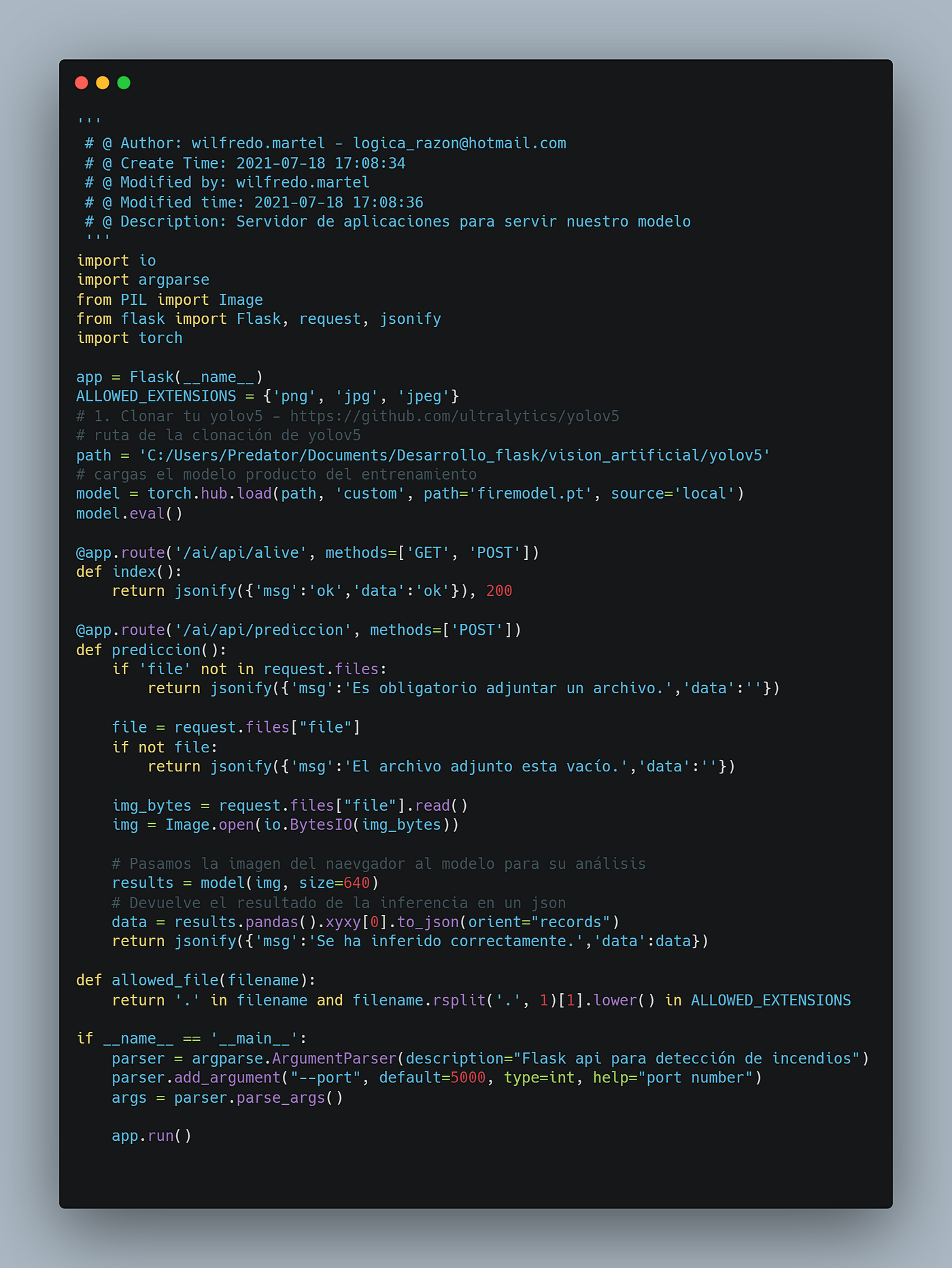
3. Deployment del modelo
Una vez que se obtuvo el modelo fireModel.pt se procedió a realizar un pequeño aplicativo en Python utilizando Flask como servidor de aplicaciones. Es decir, en Flask se tendrá una API que recibirá la imagen a inferir y el modelo fireModel.pt nos retornará el resultado y la sección donde se ha detectado el incendio en la foto con su respectivo porcentaje de predicción. A continuación, en la Ilustración 3 se muestra el código que realiza la descripción previa.
app.py
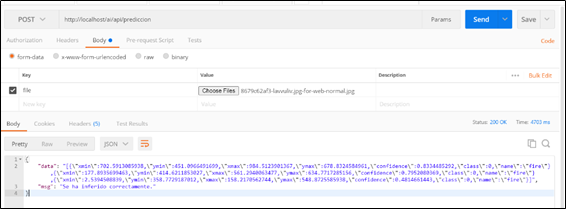
A continuación, en la Ilustración 4 se muestra la prueba del modelo usando Postman.
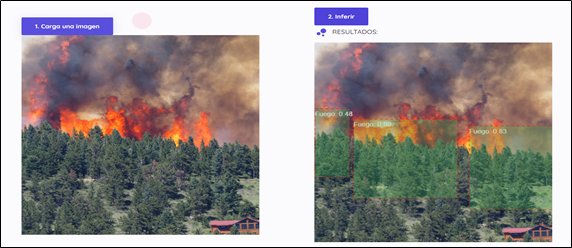
4. Desarrollo de un sitio Web para presentación del Prototipo
Para nuestro prototipo se desarrolló una Landing Page que permite cargar una imagen la cual será enviada al servidor para su procesamiento para que una vez terminada la inferencia de la imagen, los resultados se envíen al cliente con las posiciones de donde se ha detectado el incendio y el porcentaje de predicción.
Las herramientas utilizadas para la página web son:
1. Angular 2+
2. Angular Material
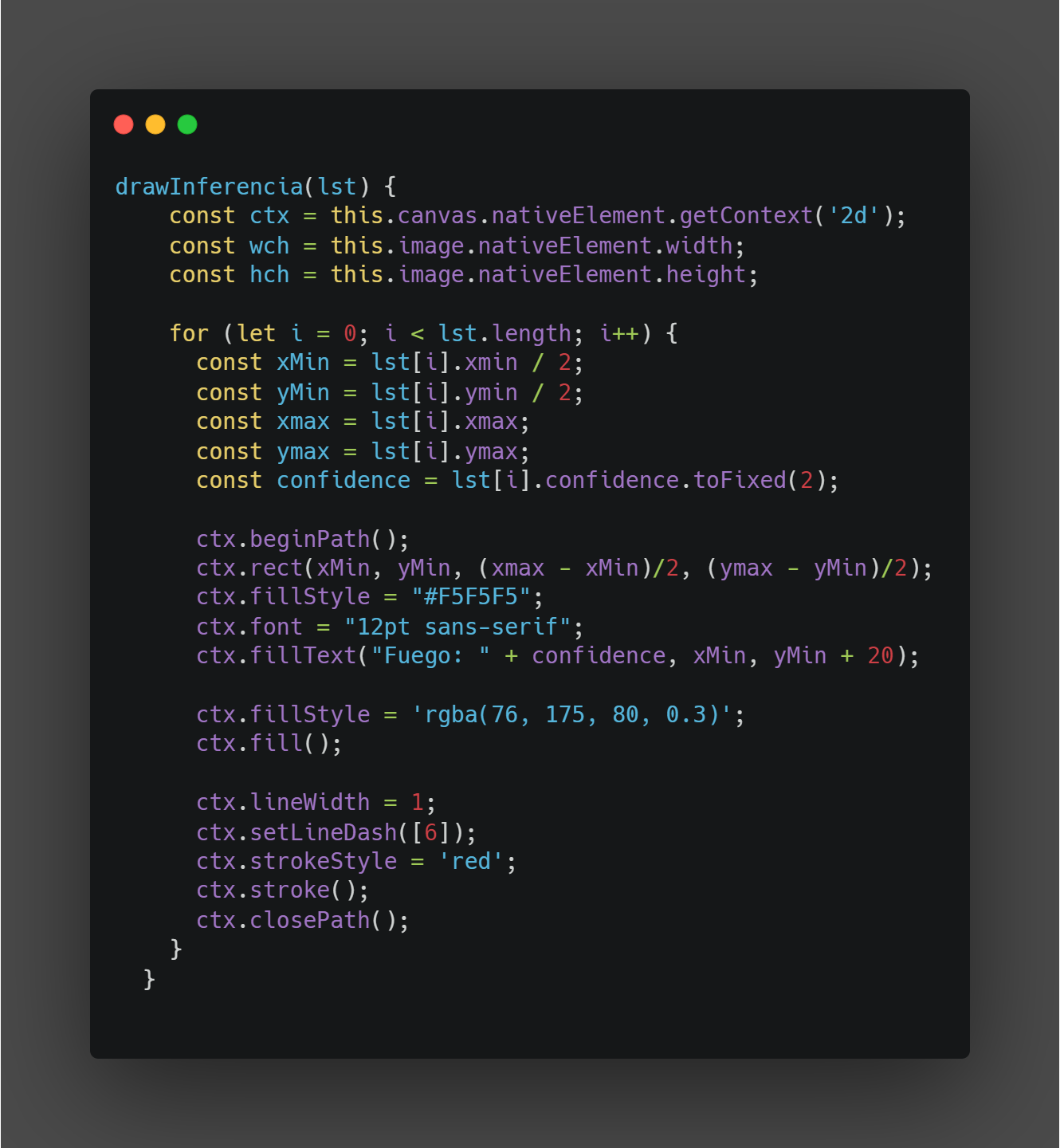
Por otro lado, para pintar los resultados de la inferencia se utilizó canvas para posteriormente dibujar las coordenadas dentro de la imagen cargada. Vale la pena mencionar que, al momento de pintar las coordenadas debido a que las dimensiones no son las mismas se tuvo que adecuar de tal manera que todas tengan las mismas dimensiones. A continuación, en la Ilustración 5 se muestra el código.
Finalmente, en la siguiente ilustración se muestra la Landing Page y los resultados del modelo.

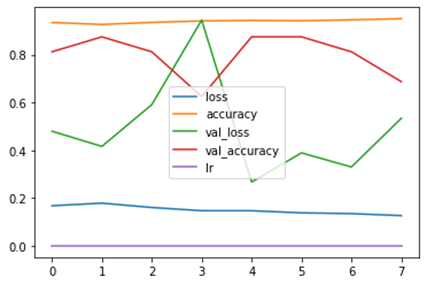
5. Resultado del Entrenamiento
Los resultados obtenidos durante el entrenamiento son muy alentadores a pesar de haber trabajado con un dataset no tan grande. Se ha alcanzado un porcentaje de predicción del 71% lo cual es aceptable. Además, se tiene que las pruebas realizadas con imágenes con incendios forestales, se pudo detectar el incendio absolutamente en todas. Estas imágenes contenían incendios a la luz del sol, faltaría realizar pruebas con imágenes que contengan incendios forestales nocturnos.
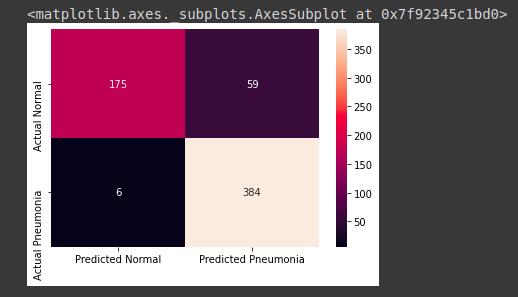
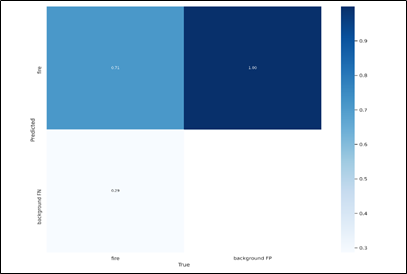
Matriz de confusión
En la Figura 1, se muestra el desempeño de nuestro algoritmo con una predicción del 71% de acierto.
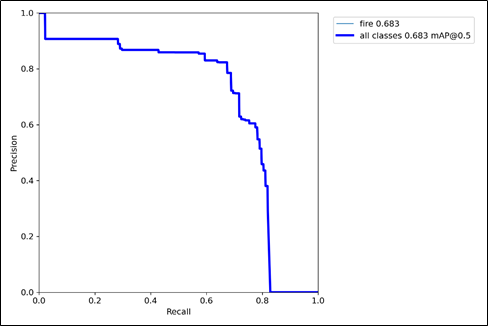
Curva de Precisión de Recuperación (PR)
La curva PR se la utilizó para la evaluación de rendimiento de nuestro modelo. En la Figura se observa que el AP(Promedio de Precisión) es de 0.5, un nivel de precisión normal para empezar. Para conocimiento general, si este valor se acerque más a 1 será mucho mejor el nivel de precisión de nuestro modelo.
Conclusiones
- Se requiere un mayor poder computacional para entrenar modelos que tardan más de 12 horas en terminar el proceso de aprendizaje y los mismos tengan un buen porcentaje de confianza en la predicción.
- El modelo tiene un tiempo corto de respuesta para la inferencia y esto es útil una vez que esté montado en el dron para la vigilancia de los bosques.
- Después de realizar varios experimentos con el modelo se ve un potencial enorme que se puede explotar para detección de incendios de todo tipo.
“Nunca se alcanza la verdad total, ni nunca se está totalmente alejado de ella”. Aristóteles (384 AC-322 AC)
Repositorio
En el siguiente repositorio se encuentra el código usado para desarrollar esa aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Quito/2021/deteccion-temprana-de-incendios_main
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!Saturdays.AI
WRITTEN BY
Wilfredo Martel
I am a very curious and sometimes an intrepid person. I love learning and build new things.
Saturdays.AI
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.

DETECTAA-AI: Inteligencia Artificial en el diagnóstico presuntivo de trastornos del desarrollo en niños
Quito. 2021
Utilizamos la Inteligencia Artificial para ayudarnos a realizar el diagnóstico presuntivo de trastornos en niños en edad escolar.
Saturdays.AI es una iniciativa a nivel global, cuyo principio es promover escenarios para la democratización del aprendizaje de la Inteligencia Artificial para todos y de forma ubicua. Democratizar, significa facilitar el acceso a todos los ciudadanos que deseen alcanzar una formación pertinente, relevante y de calidad, en cualquiera de los niveles educativos o profesionales. Por ese motivo, el equipo de investigación y desarrollo, conformado por: {Andrea Mariana Escobar, Danny Aguirre, Luis Chamba Eras, Marco Chiluiza, Paúl Quezada}, decidió participar en la Tercera Edición del Saturdays AI Quito, que de manera inédita, ubicua y flexible, se desarrolló de manera virtual.
En la primera sesión, se desarrolló la lluvia de ideas, con el objetivo de identificar la línea de investigación base, sobre el cual se desarrollaría el proyecto, sobre todo que tenga un impacto social y relacionado con los objetivos-metas de la Agenda 2030.
Originalmente se propuso el tema “Chatbot para la gestión de emociones de niños autistas”, obteniendo el primer árbol de problemas (Fig. 1), luego, se puso en marcha la estrategia de búsqueda de literatura que permita definir el alcance a la propuesta, se encontró 27 artículos científicos vinculados a esa línea base (ver Tabla 1).
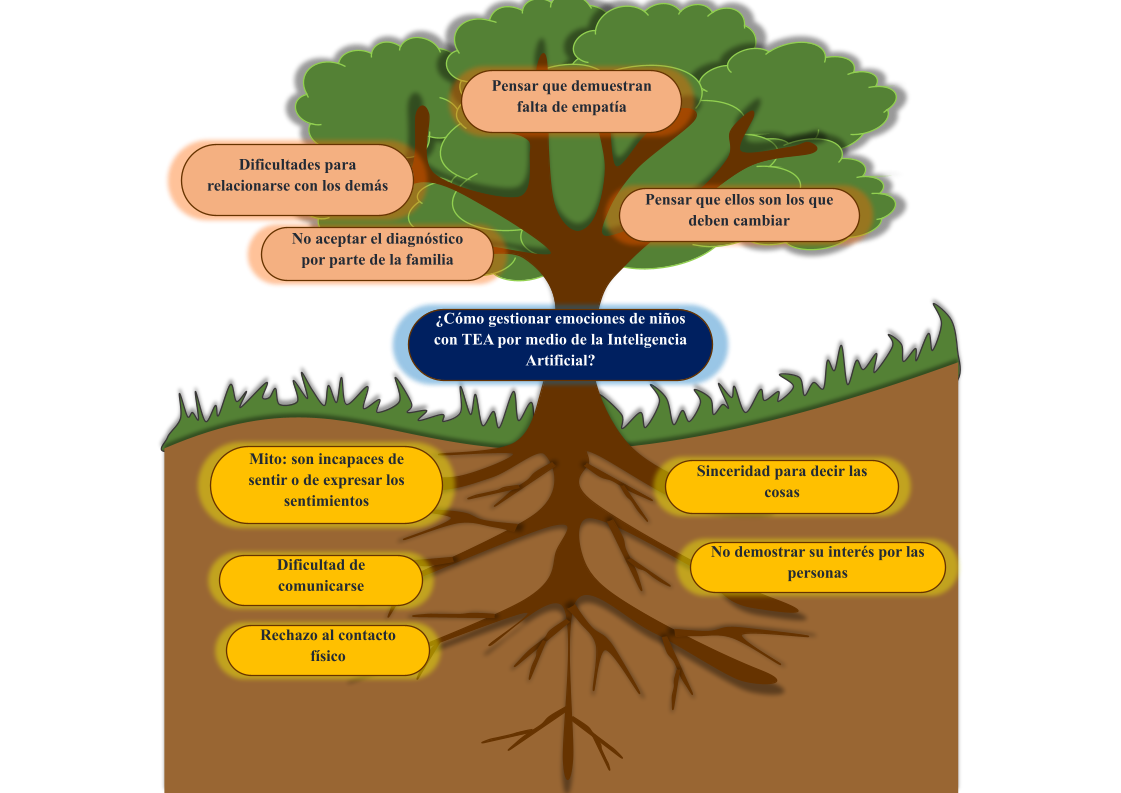
La literatura científica permitió conocer y comprender lo que se ha hecho y lo que se puede hacer en temas con el autismo, con ello se concluyó que el tema es muy amplio y con mucho futuro de trabajo para proyectos vinculados a la parte informática con un fin social. Además, se identificó que no existe un conjunto de datos de acceso libre que sirva como punto de partida para el tema planteado.
Otro punto clave, fue hacer búsquedas en grupos afines al tema del autismo, tanto en redes sociales como en la Web, con ello se observó que es un tema muy delicado y complejo, desde el punto de vista de los que conviven con el autismo, o los que no lo hacemos. Posiblemente es un tema que no ha tenido una visibilidad y democratización que permita, definir políticas para apoyar y educar a todos los que nos relacionamos con personas con autismo, sea de manera directa o indirecta. Con esto, se necesitó acudir con los profesionales o especialistas en campo, para despejar muchas dudas surgidas por la exploración preliminar, y con ello ver la viabilidad de la propuesta.
En el camino surgieron nuevas pistas, se encontró un conjunto de datos en Kaggle (https://www.kaggle.com/gpiosenka/autistic-children-data-set-traintestvalidate), relacionado con el autismo, que ha sido utilizado para construir algunos modelos que permiten por medio de la visión por computador predecir por medio de una fotografía si un niño tiene o no autismo. Con ello, cambió la perspectiva del proyecto, de pasar de las emociones (sin un conjunto de datos) al reconocimiento facial (con un conjunto de datos) en el mismo ámbito del autismo.
Para seguir en línea de conocer la opinión profesional sobre la propuesta, se realizó dos entrevistas, la primera con la especialista Amparito Morales, a la cual, se le presentó nuestra nueva idea, de que por medio de la tecnología se podía ayudar a mejorar en los diagnósticos en el área del autismo, inicialmente, se tuvo resistencia en el uso de la tecnología, pero eso fue bueno, porque permitió como equipo, convencer a la profesional de la utilidad real en escenario como en los grandes colegios o escuelas, en dónde el trabajo de los pocos especialistas (Departamento de Consejería Estudiantil (DECE)) puede ser apoyado por una herramienta que apoye en las tareas de automatización, en este caso, reconociendo cuáles de los niños por medio de una fotografía podría tener su atención prioritaria en la detección temprana del autismo.
De la primera entrevista surgió la segunda, con la reconocida investigadora Catalina López, pionera en el Ecuador por su enfoque senso-perceptivo para identificar los perfiles de autismo de acuerdo a la idiosincrasia de un país.
Actualmente, se encuentra terminando una herramienta de tamizaje orientado para niños y adolescentes de 4 a 17 años (características para alerta al diagnóstico clínico), además, durante la entrevista, Catalina López, validó la idea del proyecto, agregándole nuevas ideas vinculadas con las tecnologías, y que han surgido de sus investigaciones, como por ejemplo, realidad virtual para aplicar las herramientas de tamizaje, automatización de la herramienta de tamizaje considerando la protección de datos, privacidad, anonimato, confidencialidad, código de ética bajo principios mundiales, consentimiento informado, entre otros.
Finalmente, la investigadora propuso que un chatbot mediante la interacción sea por voz o texto, permitiría identificar patrones de comportamiento y el tema de emociones. Esta entrevista, fijó el trabajo o líneas futuras que se derivan del proyecto, centrándo el tema de reconocimiento fácil y una herramienta de tamizaje (Fig. 3), como el límite para la propuesta final del proyecto DETECTAA-AI, con la que se trabajó en el Saturdays AI.
Contexto
Los trastornos del desarrollo, técnicamente conocidos como trastornos del neurodesarrollo, son trastornos con base neurológica que pueden afectar la adquisición, retención o aplicación de habilidades específicas o conjuntos de información. Consisten en alteraciones en la atención, la memoria, la percepción, el lenguaje, la resolución de problemas o la interacción social. Estos trastornos pueden ser leves y fácilmente abordables con intervenciones conductuales y educativas o más graves, de modo que los niños afectados requieran un apoyo educativo particular. Entre los trastornos del neurodesarrollo tenemos: trastorno de déficit de atención/hiperactividad, trastornos del espectro autista, dificultades del aprendizaje, como la dislexia y las deficiencias en otras áreas académicas, discapacidad intelectual, síndrome de Rett.
“El autismo es un trastorno neurológico complejo que generalmente dura toda la vida. Es parte de un grupo de trastornos conocidos como trastornos del espectro autista (TEA). Actualmente se diagnostica con autismo a 1 de cada 68 individuos y a 1 de cada 42 niños varones, haciéndolo más común que los casos de cáncer, diabetes y SIDA pediátricos combinados. Se presenta en cualquier grupo racial, étnico y social, y es cuatro veces más frecuente en los niños que en las niñas. El autismo daña la capacidad de una persona para comunicarse y relacionarse con otros. También, está asociado con rutinas y comportamientos repetitivos, tales como arreglar objetos obsesivamente o seguir rutinas muy específicas. Los síntomas pueden oscilar desde leves hasta muy severos” [1].
El autismo en Ecuador
De acuerdo a la especialista Catalina López, se tiene los siguientes avances:
- Estudio piloto para la validación concurrente del Cuestionario de comunicación social (SCQ), como instrumento de cribado para la detección del espectro autista en una muestra de población ecuatoriana de 0 a 12 años (2016). Reporte Técnico.
- Autismo en Ecuador: un Grupo Social en Espera de Atención (2017). Artículo en Revista.
- Estudio comparativo de las concepciones acerca del autismo, desde la perspectiva de las neurociencias y la neurodiversidad (2019). Reporte Técnico.
A nivel mundial se estima que el 1% puede estar dentro del TEA, según la Organización Mundial de la Salud, en 2018 se reportaron 1.521 en Ecuador, y aproximadamente un 13,75% se tiene diagnósticos erróneos.
¿Cuál es el problema?
El personal que labora en los departamentos de consejería estudiantil de las unidades educativas (DECE) debe realizar evaluaciones para determinar los alumnos que pudiesen presentar problemas de comportamiento. Debido a la gran cantidad de estudiantes asignados a cada profesional de estos departamentos, el proceso de evaluación consume la mayor cantidad de tiempo disponible por este personal, dejando muy pocos recursos para profundizar el diagnóstico y apoyo a los niños que realmente presentan trastornos del desarrollo. En la Fig. 4 se observa el árbol de problemas, que se lo obtuvo, previa lluvia de ideas, lectura de la literatura y luego de las entrevistas.

¿Cómo lo pensamos resolver?
Se desarrollará una aplicación Web formada por dos componentes (Fig. 3).
El primer componente ayudará a predecir qué estudiantes pueden o no tener el TEA basado en una imagen fotográfica (tipo tamaño carné) por medio de visión por computador. Los rasgos que se determinen dependen de las bases de datos disponibles. En una primera fase se utilizará la base de datos disponible en Kaggle (https://www.kaggle.com/gpiosenka/autistic-children-data-set-traintestvalidate) para detección facial de TEA, considerando definir un proceso de entrenamiento del sistema que permita detectar nuevos factores de comportamiento a medida que se disponga de bases de imágenes adicionales.
Técnicamente, el tamizaje corresponde a la aplicación de un test o procedimiento a personas “asintomáticas”, con el objetivo de separarlos en dos grupos; aquellos que tienen una condición que podría beneficiarse de una intervención temprana; y aquellos que no.
El segundo componente realizará un tamizaje, usando el test MCHAT, y que sea la base para en el futuro implementar el procesamiento de lenguaje natural (chatbot de preguntas y respuestas).
¿Cómo se vincula el proyecto con los objetivos de desarrollo sustentables?
Se vincula con dos objetivos:
Primero, con el de Salud y bienestar (ODS 3), meta: reforzar la capacidad de todos los países, en particular los países en desarrollo, en materia de alerta temprana, reducción de riesgos y gestión de los riesgos para la salud nacional y mundial.
Segundo, con la Reducción de las desigualdades (ODS 10), meta: el avance en la reducción de la desigualdad, tanto dentro de los países como entre ellos, ha sido desigual. Todavía se debe dar más peso a la opinión de los países en desarrollo en los foros decisorios de las instituciones económicas y financieras internacionales. Además, si bien las remesas pueden ser un medio de supervivencia para las familias y las comunidades de los trabajadores migrantes internacionales en sus países de origen, el elevado costo de transferir dinero sigue reduciendo los beneficios.
¿Cuál es la hipótesis del proyecto?
El uso de la Inteligencia Artificial permitirá crear un prototipo que permita apoyar al diagnóstico presuntivo de trastornos del desarrollo en niños de edad escolar.
¿Cuál es la población objetivo?
- Niños de 0 a 12 años
- Padres, madres, cuidadores
- Educadores
- Especialistas de los DECE
- Investigadores
¿Qué nos dice la literatura científica sobre proyectos relacionados con el reconocimiento facial?
La literatura científica que soporta nuestro proyecto se resume en la Tabla 2.
¿Qué es la visión por computador?
Es un campo de la Inteligencia Artificial enfocado a que las computadoras puedan extraer información a partir de imágenes, ofreciendo soluciones a problemas del mundo real (Fig. 5).
¿Qué áreas del conocimiento se vinculan?
- Ciencias de la Salud (Salud Mental).
- Ciencias de la Computación (Inteligencia Artificial, Visión por Computador).
Metodología
La metodología que se utilizó fue Desing Thinking, en la Fig. 6 se observa un resumen de cada una de las etapas desarrolladas.
En la Fig. 7, se tiene un lienzo de trabajo proporcionado por https://www.analogolab.co/, para poner en marcha los principios de la metodología Desing Thinking. En este enlace Web, se observa el diseño completo del proyecto.
Resultados
Arquitectura
La arquitectura del proyecto está dividida en una aplicación de Frontend y una aplicación de Backend (ver Fig. 8). El Frontend, desarrollado con Flask (Framework de Python), contiene todas las interfaces con las cuales el usuario final interactúa. Esta, a su vez, se conecta mediante un endpoint al Backend. En el Backend se encuentra una API, desarrollada con Flask, que contiene un modelo de Deep Learning entrenado con librerías de TensorFlow y un conjunto de imágenes obtenidas desde Kaggle. El Frontend también interactúa con un modelo entrenado en Teachable Machine (una plataforma de Google para entrenar modelos de machine learning de forma rápida y fácil).
Enlaces Web a las API y a la aplicación de DETECTAA-AI:
- Teachable Machine: https://teachablemachine.withgoogle.com/models/5O0q09n5c/
- API Modelo Tensorflow: https://reconocimientoteaapi.herokuapp.com/
- FrontEnd: https://detectai.herokuapp.com/
Flujo de trabajo de DETECTAA-AI
Los resultados obtenidos para el primer caso (niño con TEA) son bastante favorables, ya que tanto los modelos como el cuestionario dan un porcentaje alto de detección de TEA en la persona evaluada, tal como se muestra en la Fig. 9.
Los resultados del segundo caso (niña sin TEA), presentan porcentajes aceptables en el diagnóstico de TEA. Tal como muestra la Fig. 10, los resultados obtenidos fueron: Teachable Machine: 100%, TensorFlow: 85.28% y M-Chat: Riesgo Bajo.
En el tercer caso (niño sin TEA) los resultados obtenidos de los modelos y M-chat reflejan resultados diferentes, ya que los modelos de machine learning devuelven diagnósticos acertados en cuanto a la prueba realizada, sin embargo, el M-chat retorna un Riesgo alto de tener un diagnóstico de TEA, como se muestra en la Fig. 11.
Conclusiones
Con el desarrollo del proyecto DETECTAA-AI se llegó a las siguientes conclusiones:
- Es posible detectar indicios de TEA en las personas mediante el uso de modelos de inteligencia artificial.
- Para que un modelo tenga una tasa de confiabilidad más alta, es necesario una mayor cantidad de imágenes de entrenamiento y mejor procesamiento de esa información.
- Los algoritmos de inteligencia artificial sirven como un apoyo a los profesionales de la salud, más no como un reemplazo.
- Es necesario un vínculo entre la academia, estado, empresas, gremios, sociedades, para que estas iniciativas se puedan poner en marcha de acuerdo al contexto Ecuatoriano.
- Combinar la investigación científica a procesos profesionales, permite construir prototipos escalables en el tiempo.
- El prototipo DETECTAA-AI, debe usarse con fines académicos y de investigación, como ejemplo de prueba de concepto, y no para ofrecerla como herramienta de diagnóstico final, ya que se necesita un equipo de profesionales que aporten en la detección del TEA.
Líneas futuras
- Implementar la herramienta de tamizaje con NLP, de tipo de preguntas y respuestas, utilizando el cuestionario propuesto por la Dra. Catalina López en el contexto Ecuatoriano, considerando la privacidad, protección de datos, entre otros.
- Obtener una base de datos propia de imágenes en el contexto de Ecuador, para realizar pruebas al prototipo DETECTAA-AI.
- Es recomendable aumentar una tercera herramienta de detección de TEA por NLP, el cual permita detectar presencia de tea mediante el análisis de patrones en la voz de la persona que se requiera diagnosticar.
- Concientizar a la población que la tecnología puede ser un apoyo muy importante en el contexto de la Salud.
Recursos del proyecto DETECTAA-AI
- Página de Teachable Machine: https://teachablemachine.withgoogle.com/
- Dataset De imágenes de entrenamiento y pruebas: https://www.kaggle.com/gpiosenka/autistic-children-data-set-traintestvalidate
- Repositorio GitHub: https://github.com/detectaai
- Link API: reconocimientoteaapi.herokuapp.com
- Link Aplicación Final: https://detectai.herokuapp.com/
Referencias
[1] https://www.uasb.edu.ec/reconocimiento-a-la-directora-del-area-de-salud-catalina-lopez-id1550289/
Presentación del proyecto: DemoDay
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!Saturdays.AI
WRITTEN BY
Luis Chamba-Eras
Profesor e investigador de la Universidad Nacional de Loja. Investigación en Inteligencia Artificial en Educación.
Saturdays.AI
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.

Clasificación de idiomas originarios de Bolivia con Machine Learning
La Paz. 2021
Usamos técnicas de Machine Learning para la clasificación de idiomas.
Bolivia lucha para que no desaparezcan los idiomas indígenas, sin embargo, es aún muy complicado acceder a recursos que ayuden la asimilación y aprendizaje de los mismos. Es por ello que planteamos crear una herramienta con Machine Learning para la clasificación de idiomas, que si bien es una tarea sencilla es elemental para realizar tareas más complejas como la traducción automática, el análisis de sentimientos, conversión de habla a texto, texto a habla, etc. Este modelo de clasificación se creó usando herramientas de NLP (procesamiento de lenguaje natural) y ML (aprendizaje automático), obteniendo una precisión superior al 99%.
Desde 2006 Bolivia es líder en la defensa y reivindicación de los pueblos y las culturas indígenas en su territorio y en el mundo.
“Hoy en día, las 36 lenguas originarias en Bolivia son idiomas oficiales. En Bolivia se tiene que hablar y enseñar inicialmente un idioma originario» [1].
Pero todo esté trabajo ¿realmente tiene resultados positivos en la asimilación y aprendizaje de las lenguas originarias en Bolivia?.
Descripción del problema
Si bien en nuestro país se lucha porque no desaparezcan estos idiomas indígenas es aún muy complicado acceder a recursos que ayuden la asimilación y aprendizaje de los mismos.
Sin embargo, actualmente se puede usar la tecnología como un aliado para solucionar este problema y la detección de idiomas es un punto inicial y primordial para crear herramientas de traducción automática de texto, de conversión de texto a voz, voz a texto, voz a voz, entre muchas otras aplicaciones.
Objetivo
Crear una herramienta con Machine Learning capaz de identificar y clasificar idiomas originarios de Bolivia, para agilizar tareas relacionadas como la traducción, recuperación de la información, etc.
Límites y alcances
LÍMITES: Debido a la dificultad de conseguir un conjunto de datos suficientemente grande de los idiomas más hablados en Bolivia (quechua, guaraní, aymara), solo nos centramos en el idioma quechua.
ALCANCES: La herramienta de identificación, en una primera etapa, será capaz de clasificar el idioma de frases ya sea como quechua o español.
Metodología
Para la clasificación de idiomas mediante Machine Learning se utilizó una metodología iterativa incremental, que conlleva las siguientes fases:
Captura de datos
Posterior a la creación del dataset nos dimos cuenta que éste estaba desbalanceado porque el número de frases en quechua duplicaban el de español, por esa razón decidimos balancear los datos agregando frases de español obtenidos de un dataset de Kaggle.
Pre-procesamiento
En esta etapa se realizaron diversas formas de pre-procesamiento, desde la ingeniería de características (feature engineering) hasta la vectorización. Las cuales se describen a continuación.
Limpieza de caracteres irrelevantes
Las frases en español de Kaggle tenían caracteres de otros idiomas e irrelevantes para la clasificación, es por ello que antes de unir con el dataset que se tenía se pasó a realizar una limpieza de todos esos caracteres de las frases de Kaggle. Una vez unido el dataset aún se tenían caracteres que no aportaban información como: dígitos, signos de puntuación, etc. y por tanto se realizó una limpieza de estos caracteres.
Técnicas implementadas
En base a la información del dataset se pudo notar que había un dato mal tabulado y se realizó la imputación de datos por valores nulos. Por otro lado, como el dataset cuenta con solo un feature y el target, no se tuvo la necesidad de reducir las dimensiones.
Análisis de los features
Cada idioma tiene sus propias reglas gramaticales y el idioma Quechua no es ajeno a eso, por ende se investigó las reglas de este idioma y se pudo notar ciertas características interesantes que lo diferencian de otros idiomas, por mencionar algunas:
- El alfabeto quechua cuenta con 28 consonantes (algunas consonantes son diferentes al de español como: ch’, chh, qh, p’) y 3 vocales (a, i, u)
- Las consonantes del quechua se clasifican según el modo de articulación, algunas de estas son:
- Oclusivas (p, t, k, q)
- Aspiradas (ph, th, chh, kh, qh)
- Glotalizadas (p’, t’, ch’, k’, q’)
- Semiconsonantes (w, y)
3. Para diferenciar el género de una persona se usan las palabras: warmi y qhari
4. La interrogación en el quechua se realiza agregando a la palabra el sufijo -chu.
Estas y muchas más características de la gramática Quechua, así como la gramática del Español fueron tomadas en cuenta para realizar las gráficas, las cuales nos permiten corroborar estas diferencias entre las reglas gramaticales en el dataset.
Uno de los gráficos que realizamos fue la frecuencia de las vocales por idioma en el dataset (Figura 3). La frecuencia de las vocales fueron calculadas según el número de caracteres de cada frase.
Otras gráficas que realizamos fueron la frecuencia de las consonantes como: K, H, M, R (Figura 4) y caracteres especiales como: á, é, í, ó, ú, ä, ü, ‘ (Figura 4), según el idioma.
Estas gráficas nos permitieron aclarar algunas dudas sobre las diferencias gramaticales entre el idioma Español y Quechua, y representaron un punto clave para realizar el pre-procesamiento de los datos.
Por las diferencias de algunas letras y caracteres utilizados para cada idioma, además de ciertos sufijos o prefijos propios, numeración y demás características, decidimos vectorizar las frases según el modelo n-gram de caracteres. Para capturar características importantes en ambos idiomas delimitamos el modelo n-gram de 1 a 5, esto por temas de rendimiento y también porque consideramos que este número nos permite abstraer aquellas características gramaticales que citamos anteriormente.
Además de vectorizar las frases según la frecuencia de caracteres únicos que tiene cada frase se aplicó la frecuencia TF-IDF, medida estadística que evalúa cuán relevante es un término para un documento en una colección. En este caso cada término es representado por cada carácter y el documento es representado por la frase del idioma en el dataset (colección de frases).
Selección y evaluación de modelos
Con los datos listos se procedió a construir los modelos de predicción. Se utilizaron modelos de clasificación debido a que tenemos un problema de clasificación binaria, sólo se tienen dos posibles etiquetas, “Quechua” y “Español”.
Por lo tanto, se utilizaron los siguientes algoritmos de aprendizaje supervisado:
- Naive Bayes
- Support vector Machine
- Logistic regression
Para encontrar la mejor combinación de hiperparámetros se utilizo GridSearch de la biblioteca Sklearn.
Las matrices de confusión para los 3 modelos son:
Clasificación de nuevos datos
Una vez seleccionado nuestro mejor modelo, es necesario probarlo con algunas frases nunca antes vistas, por ello probamos frases que solo contienen palabras de un idioma, frases que contienen palabras de ambos idiomas que es usual en el habla coloquial de los quechua hablantes y por último una frase sin sentido. Nuestro modelo seleccionado se comporta bien con los dos primeros tipos de frases, sin embargo, al ingresar frases sin sentido que no pertenece ni al español o al quechua, estas frases son clasificadas directamente como quechua, esto se debe a que como manejamos un modelo binario el texto ingresado sea cual sea debe etiquetarlos con una etiqueta u otra.
Conclusión
En general, el modelo de Machine Learning para la clasificación de idiomas basado en Support Vector Machine ofrece el mejor resultado predictivo con una puntuación de precisión balanceada superior al 99%.
Específicamente, el modelo funciona bien para clasificar Español y Quechua dada la alta precisión, y puntajes f1 para estos dos idiomas.
Si bien la mejor precisión se obtuvo con SVM, considerando las variables precisión y rendimiento el mejor modelo sería el basado en Regresión Logística, ya que ofrece un tiempo de ejecución menor al de SVM y tiene una precisión superior al 99%, lo cual es un factor importante en aplicaciones en real time.
Se logró abstraer algunas características del idioma quechua, por lo que es posible realizar el mismo análisis con otros idiomas originarios de Bolivia
Trabajos futuros
Si bien este problema aparenta ser sencillo es un paso necesario para:
- Traducción automática
- Detección de idioma para el uso de boots
- Análisis de sentimientos, etc.
El codigo fuente de este proyecto se puede encontrar en: github
Referencias
ONU – Bolivia, a la vanguardia en la protección y promoción de las lenguas indígenasSaturdays.AI
WRITTEN BY
EVELYN CUSI LOPEZ
Repositorio
En el siguiente repositorio se encuentra el código usado para desarrollar esa aplicación: https://github.com/SaturdaysAI/Projects/tree/master/Lapaz/clasificacion-idiomas-machine-learning-main
¡Más Inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!