Zaragoza. Primera Edición. 2022
El cáncer de mama es la principal causa de mortalidad en las mujeres. En 2020, alrededor de 685 000 mujeres fallecieron como consecuencia de esa enfermedad. La mayoría de los casos de cáncer de mama y de las muertes por esa enfermedad se registran en países de ingresos bajos y medianos.
El cáncer de mama es el más prevalente entre las mujeres. Se estima que la prevalencia en España en 2020 es de 516.827 personas, según la REDECAN.
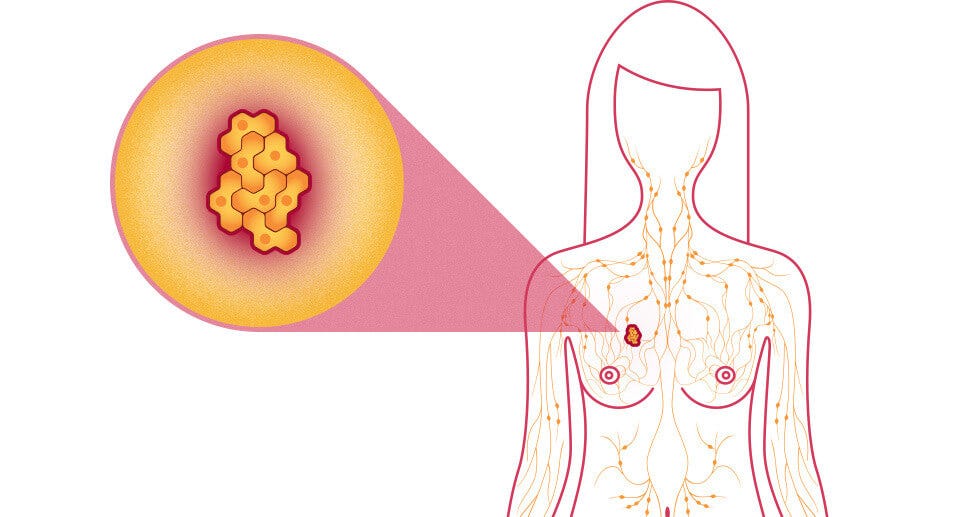
Generalmente, el cáncer de mama se origina en las células de los lobulillos, que son las glándulas productoras de leche, o en los conductos, que son las vías que transportan la leche desde los lobulillos hasta el pezón.
A pesar del aumento progresivo de la supervivencia por cáncer de mama, mejorar las tasas de mortalidad de la enfermedad es una necesidad médica y social, puesto que se ha estudiado que un 30% de las pacientes diagnosticadas tendrán una recaída de la enfermedad. Asimismo, el cáncer de mama afecta también a los hombres, siendo más mortal debido a la escasez de tejido mamario, por lo que se extiende a otros órganos con mayor facilidad.
El cáncer de mama es el tumor maligno más frecuente en mujeres y el riesgo de sufrirlo aumenta con la edad, con incidencia máxima a partir de los 50 años. El cribado de este cáncer mediante mamografía, que se realiza entre la población de 50 a 70 años, permite reducir su mortalidad. El 5.4 por mil de los pacientes cribados son positivos. Un diagnóstico precoz de estos casos es fundamental para llevar a cabo tratamiento correcto y eficaz.
El año pasado 800 nuevos cánceres de mama fueron detectados tan solo en la comunidad de Aragón.
La tendencia actual es a un incremento de los casos no solo por los hábitos de vida menos saludables, sino que va ligada al incremento de la población en el programa de detección por la llegada de los boomers, como podemos apreciar en el siguiente gráfico. De modo, que la posibilidad de que haya un gran incremento de casos en estos años es bastante alta.
Como consecuencia de todo lo anterior vemos una necesidad real en la existencia de alguna herramienta que ayude con este problema de detección de cáncer. Es por esto que, animados por el proyecto de Saturdays AI, iniciamos el abordaje de este problema mediante la aplicación del Machine Learning y posterior desarrollo de una herramienta (Mama Mia) de predicción del diagnóstico de Cáncer de Mama.
Se trata de una solución que se alinea a la perfección con el ODS 3: Objetivo de Desarrollo Sostenible Salud y Bienestar.
Asimismo con el ODS 10 de Reducción de Desigualdades, ya que es en zonas de menores ingresos donde se registran más muertes. Se libera el uso por de todo el trabajo aquí realizado.
¿Cómo lo vamos a hacer ?
Como todo proceso en que se quiere implementar una tecnología en algún negocio es necesario una metodología. No reinventaremos la rueda, vamos a hacer uso de la metodología iterativa CRISP-DM (Cross Industry Estándar Process for Data Minnig) que nos facilita una guía estructurada en seis fases, algunas de las cuales son bidireccionales, pudiendo volver a una fase anterior para revisarla.
Fase 1 — Business Understanding (Comprensión del negocio)
El objetivo de este proyecto es el desarrollo de una herramienta para la predicción del cáncer de mama. Para lo cual contamos con el dataset de
https://archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+(diagnostic)
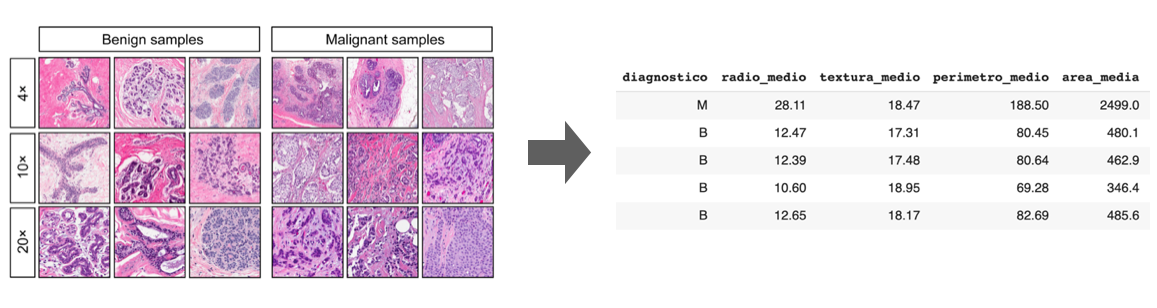
Conseguidos a partir de una imagen digitalizada de un aspirado con aguja fina (FNA) de una masa mamaria, describen las características de los núcleos celulares presentes en la imagen.
Fase 2 — Data Understanding (Comprensión de los datos)
Hemos comenzado el proyecto viendo con qué datos contamos específicamente. Tras obtener nuestros datos de UCI y entrando en detalle, nuestra base de datos se compone de 31 variables útiles que podemos desglosar en la variable de diagnóstico (si es positivo o negativo) y 10 parámetros que definen las células se dan bajo 3 situaciones: el valor promedio, la desviación estándar y el peor caso.
- Radio
- Textura: Desviación estándar de los valores de la escala de grises
- Perímetro
- Área
- Uniformidad: Variación local en diámetros
- Compactibilidad: Perímetro²/área — 1
- Concavidad: Severidad de los puntos cóncavos del contorno.
- Puntos cóncavos: Número de puntos cóncavos del contorno
- Simetría
- Dimensión fractal: aproximación a una esfera perfecta, que corresponde a 1.
Estas 30 variables se obtienen a partir del análisis de la biopsia.
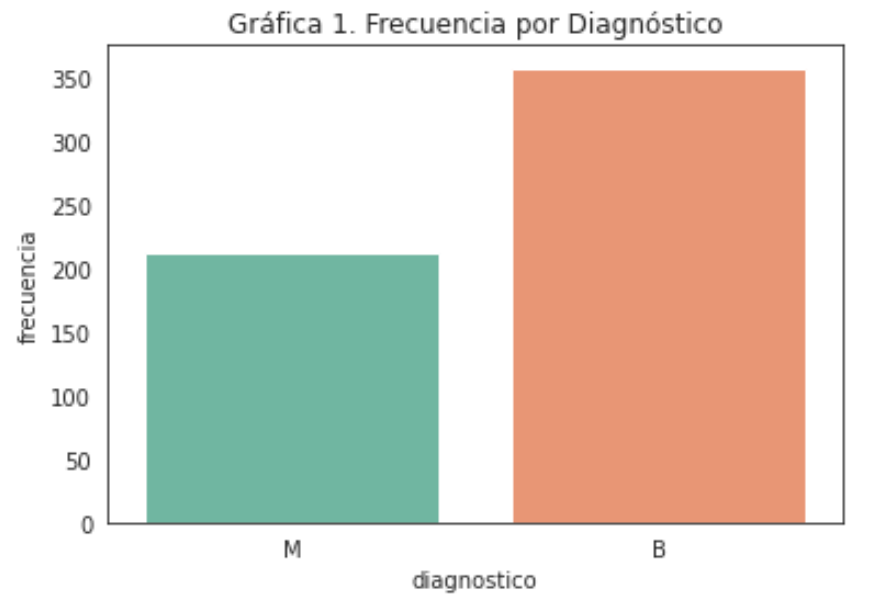
Dentro de nuestros datos tenemos 213 casos malignos y 357 casos benignos.
Fase 3 — Data preparing (Preparación de datos)
Aparte de las 31 variables útiles encontramos una columna con valores NaN que eliminamos junto con el ID (identificador) de cada caso ya que no aporta ninguna información para la predicción y sustituimos los datos de diagnóstico: M y B por valores numéricos binarios: 1 y 0.
Por lo que lo primero ha sido ver que tipo de datos teníamos: todos números de coma flotante excepto el diagnóstico. Analizando los datos podemos ver que no tenemos valores NaN y tienen los siguientes datos estadísticos:

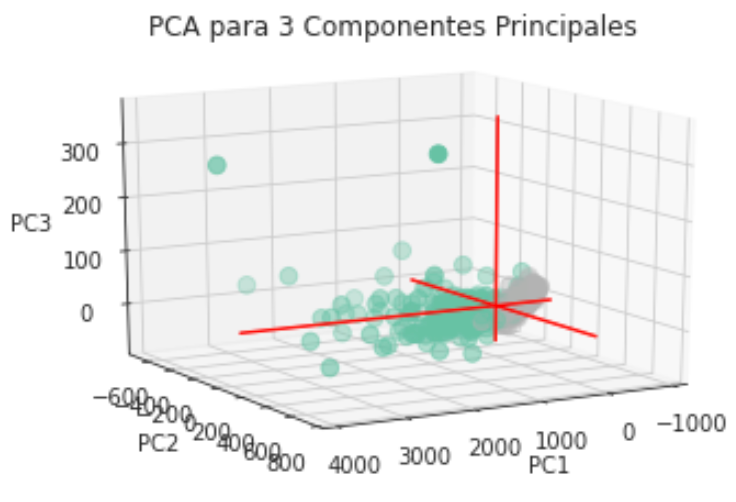
Hemos obtenido la gráfica de correlación mediante un mapa de calor para ver cómo se relacionan entre sí las variables y en nuestro caso la relación con la que más nos importa: el diagnóstico (‘diagnosis’).
Podemos ver en la primera fila como hay parámetros con una alta correlación directa (colores claros) y parámetros con una leve correlación inversa (colores oscuros).
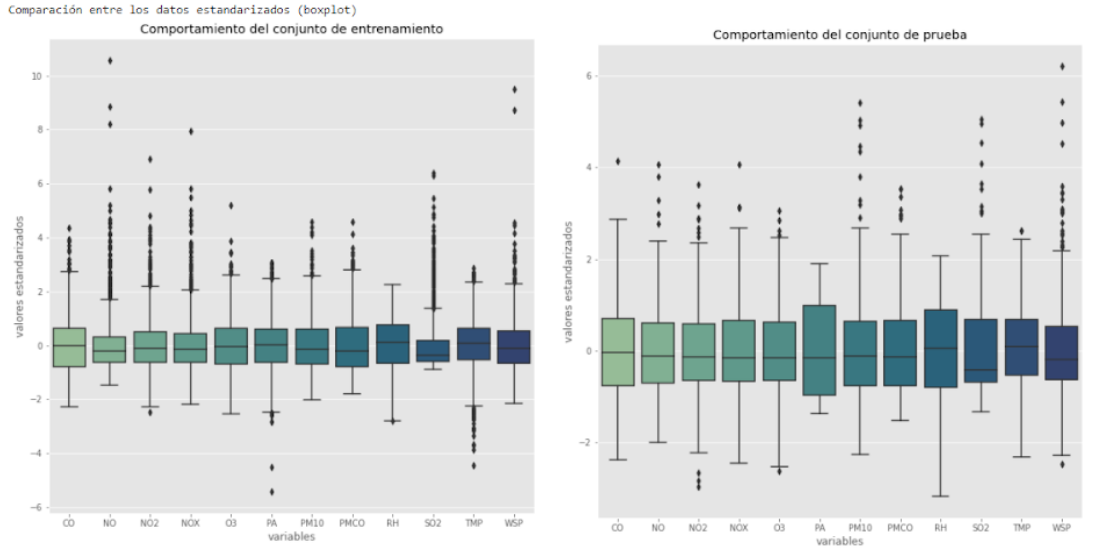
Ahora vamos a comprar todas las variables mediante diagramas de caja, separando para cada variable los casos malignos (en rojo) y los casos benignos (en verde). Estas gráficas nos sirven para ser capaces de identificar algunas variables claves. Estas serán aquellas que la distribución de malignos y benignos sea muy diferente.
Vemos que se producen con bastante frecuencia valores atípicos, normalmente por encima. Esta variabilidad es posible ya que los datos en estudios médicos suelen ser más variables que los que podemos encontrar en otras bases de datos.
Antes de pasar al modelado debemos normalizar las variables para hacer predicciones de mejor calidad.
Fase 4 y 5 — Modeling and evaluation (Modelado y evaluación)
Dada la tipología de datos que tenemos hemos usado modelos supervisados (los datos están etiquetados) y de clasificación (predice una categoría). Los modelos que hemos evaluado son:
- Regresión logística
- Árbol de decisión
- Random forest
- Extra tree
- Super Vector Machine (SVM)
- Gradient Boosting
- K — vecinos más cercanos (KNN)
- MLP classification
En estos modelos hemos probado con random state 2. Para ello antes de introducirlos en el modelo hemos separado los datos con una relación 70–30 en entrenamiento y evaluación respectivamente.
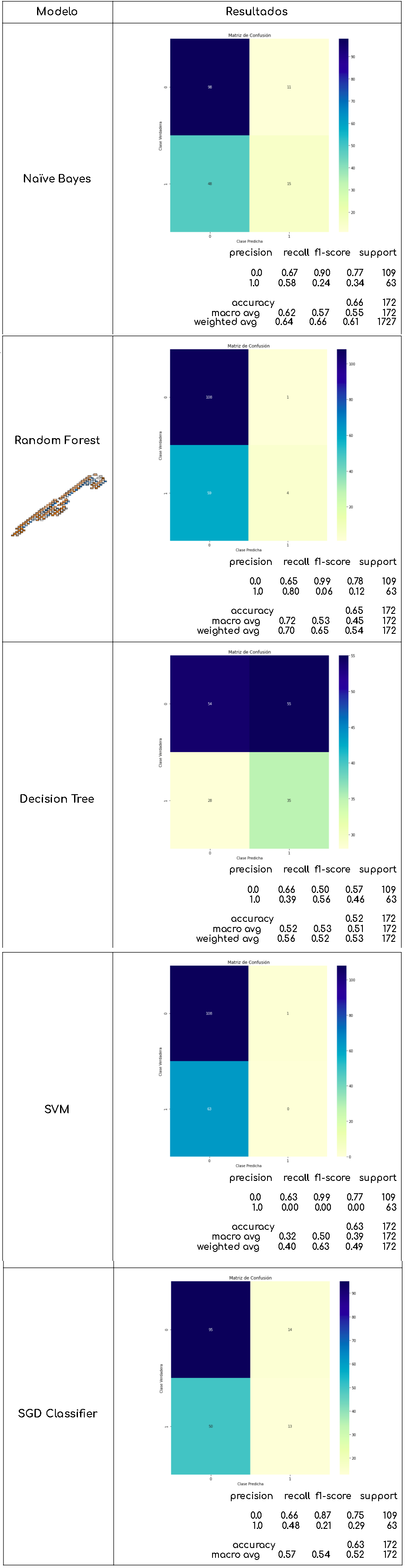
Tras evaluar estos modelos hemos obtenido los siguientes resultados:

Podemos ver cómo obtenemos valores de excatitud (accuracy), precisión (precision), Recall y F-score superiores al 90%. Los modelos con un F-score mayor del 95% son los que destacamos de cara a los mejores modelos de cara a las siguientes etapas, no sin antes comprobar varias elementos del modelo.
Se trata de un modelo con un alto número de características por lo que nos planteamos varias preguntas: ¿Se podría conseguir un resultado con menos variables? ¿Hay dependencias entre estas? ¿Son buenos resultados siempre o ha sido casualidad del random state?
Para ello pasamos a observar la importancia de las variables (en los casos que nos lo permite).
Variables de influencia
En el caso del árbol de decisión (Decision tree) podemos ver según qué variables va clasificando.
Reducción de variables y nuevas métricas
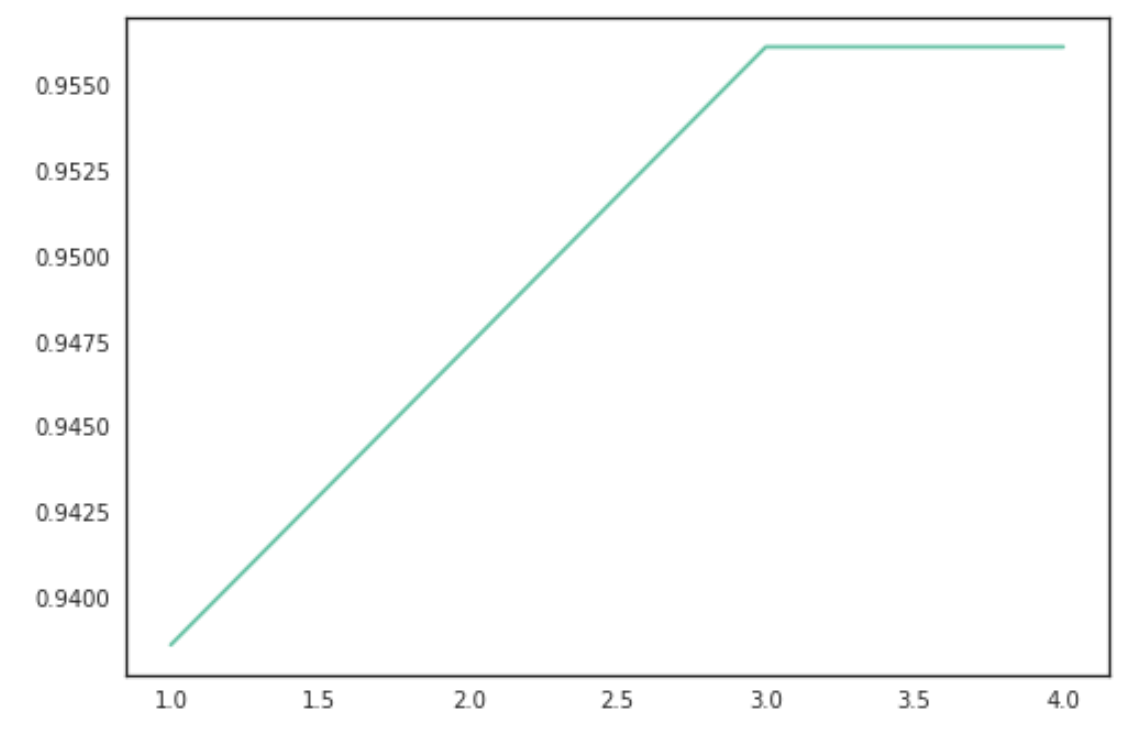
En base a la importancia de las variables que hemos visto hemos elegido 3 combinaciones para simular: con 10, 16 o todas las variables. Elegidas tal que así:

Se obtienen los siguientes resultados en las predicciones para cada uno de los 3 casos:



Fijamos un criterio de elección de un F-score de 95% mínimo, por lo tanto elegimos un modelo con 16 parámetros ya que permite predecir con unas métricas suficientemente buenas pero con casi la mitad de parámetros que la opción de 30 parámetros.
Tras esto pasamos a ver cómo es su comportamiento frente a la predicción de probabilidades en relación con el efecto de la semilla. Para ello miraremos en las 200 primeras semillas, cómo se comportan. Para ello realizaremos un histograma donde iremos acumulando las probabilidades con las que predice tanto para verdaderos positivos como negativos, y para falsos negativos y positivos.
Con todas las simulaciones realizadas vemos como hay ciertos modelos que concentran sus valores en más altas métricas y más concentradas, estas seremos las que elegiremos.
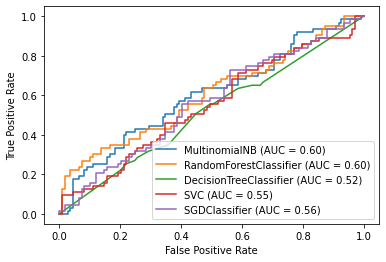
Variando únicamente el estado aleatorio inicial, conseguimos muy altas métricas máximas, clasificadas en esta tabla.

Una vez elegimos los mejores modelos (con mayores y más concentradas F-score): SVM, Regresión logística y MLP Classification (Perceptrón Multicapa).
A partir de ahora probaremos a conseguir mayor robustez mejorando los 3 modelos finalistas. Para ello testearemos diferentes combinaciones y una vez seleccionado el modelo (o combinación de modelos finalistas) pasaremos a optimizarlo (si se puede).
Hemos elegido los modelos de Regresión logística, Support Vector Machine, y Perceptrón Multicapa. Ya que tienen altas métricas en un rango que ha variado menos, por lo que suponemos mejor.
Ensamble de varios métodos
Una vez tenemos modelos muy buenos, uno incluso con métricas del 100% decidimos combinarlos. ¿Por qué combinarlos si ya tienen métricas excelentes? Para que sea más robustos y sea más posible que frente a un caso no evaluado ni entrenado acierte el resultado.
Probando con Adaboosting y Bagging obtenemos peores métricas.
Y con voting obtenemos unos valores levemente menores distribuidos tal que así:
Con unas métricas de:

Selección de modelo
Seleccionando las mejores semillas obtenemos las siguientes histogramas:
Vemos cómo el MLP predice con unas probabilidades mucho más altas, pero con un falso negativo. Destaca la regresión logística que acierta el 100% de los casos. Aquí podemos ver las métricas de los modelos:

Ajuste hiperparámetros
Vamos a usar la librería de Scikit-Learn para ajustar los hiperparámetros del algoritmo de cara a encontrar cuales serían los valores que mejorasen los datos anteriormente obtenidos.
Hacemos uso de GridSearchCV con los siguientes valores:
- Kernel: linear,poly,rbf y sigmoid
- C: 1000, 10, 1 y 0.01
- Gamma: 0,001 y 0,001
Obteniendo los mejores resultados de 97,11%, con C igual a 1, gamma igual a 0,001 y kernel linear.
No conseguimos ninguna mejora significativa a los parámetros por defecto.
Resultados finales
Elegimos regresión logística ya que es la que mejores resultados ha tenido y la hemos preferido al voting ya que no podemos asegurar que con el voting obtengamos un sistema más robusto.
Fase 6 — Deployment (Despliegue)
Una vez elegido y ajustado el modelo, para evitar realizar de nuevo el proceso, es guardado mediante la librería joblib pudiendo así utilizarlo posteriormente. Para dotar el proyecto de una gran accesibilidad decidimos publicar una web que utilice el modelo, para lo cual, recurrimos a la librería open-source: streamlit, que nos permite de una forma sencilla crear una sencilla aplicación web que utilice dicho modelo.
Tan solo es necesario crear un formulario de recogida de datos para que se rellene y al enviar el formulario, la web normaliza y escala los datos de acuerdo a los datos con los que ha sido entrenado el modelo para pasárselos a este y que realice la predicción.

Próximos pasos
- Complementar la predicción de diagnóstico del cáncer de mama con la predicción de la recurrencia del cáncer.
- Desarrollo de una aplicación con la opción de introducir distinto número de variables en función de la precisión que se busque.
- Implementación de predicción mediante fotografías.
Integrantes
- Víctor Villanova (vvb.curioso@gmail.com)
Estudiante del Programa conjunto en máster de Ingeniería Industrial y máster de Energías renovables y eficiencia energética. Apasionado de lo desconocido y la naturaleza, manitas y scout.
- Miguel E. Calvo (mecalvon@gmail.com)
Actualmente Técnico de Gestión de Sistemas y T. I en el SALUD (Gobierno de Aragón). Curioso e inquieto tecnológico.
Repositorio
El código está disponible en https://github.com/gitmecalvon/mamamIA
¡Más inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!