La Paz. Deep Learning. 2021
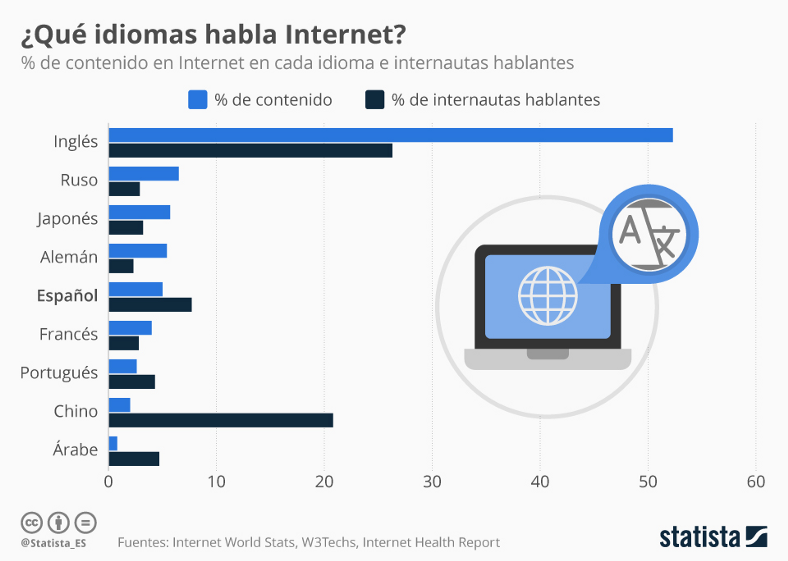
Existen diversos servicios para viajeros, desde páginas de hoteles hasta ofertas turísticas a unos cuantos clics de distancia, no obstante, el ser humano ha conseguido su información por siglos y siglos a través de preguntas y bases de conocimiento, por lo que le es más natural hacer consultas de esa forma, así surge Pangea, como un servicio web de Inteligencia Artificial conversacional con el que el viajero puede interactuar y conseguir las respuestas a sus más inquietantes preguntas.
Un viajero prudente nunca se lanza a viajar si no tiene la información más relevante de su destino, en su cabeza se encuentran preguntas que en primera instancia cuestionan su seguridad, por lo que investiga al respecto y logra resolver sus dudas en probablemente muchos minutos, de igual forma si ya se aventuró a viajar y necesita conocer alguna costumbre, plato típico, música o lugares para visitar, son tantas las preguntas y mucho el tiempo invertido en responderlas, de esa forma los viajeros pierden tan importante recurso.
Por lo que al usar textos como datos a analizar en la tarea de respuesta a preguntas se requiere el uso de Natural Language Processing (NLP) o en español conocido como el procesamiento del lenguaje natural, entiéndase como la rama de la Inteligencia artificial (IA) que entrena a una computadora para comprender, procesar y generar lenguaje (conversacional).
Descripción del problema
Concretamente el problema es el tedioso y tardío acceso a respuestas inmediatas sobre dudas y consultas acerca de un destino turístico, como ser: comida, hospedaje, actividades turísticas, transporte, centros de salud, cultura, música, conflictos políticos, entre otros.
Objetivo
Desarrollar mediante Inteligencia Artificial un servicio web conversacional de pregunta-respuesta para viajeros aplicando NLP mediante la aplicación de un modelo de deep learning.
Técnicas implementadas
Se presentan las técnicas complementarias a la resolución del problema, ya que todo modelo de Deep Learning requiere ser alimentado por datos.
Búsqueda de datos
La Inteligencia Artificial conversacional Pangea se centra en responder preguntas y no sería posible sin cantidades ingentes de información con las cuales interactuar y usarlas como una fuente de conocimiento (contexto), en ese sentido, se realizó la búsqueda de páginas web que contengan las respuestas más coincidentes de acuerdo a la pregunta del usuario viajero; hacerlo de forma manual representaría demasiado trabajo, por lo cual, se decidió usar la biblioteca de Python, Google Search, el cual emplea al motor de búsqueda Google como fuente de información para brindar las URLs de los sitios webs requeridos.
Captura de datos
Una vez obtenidas las URLs de los sitios webs que contienen la información requerida, se empleó la técnica del Web Scraping para obtener el contenido literal de dichos sitios, es decir, los distintos párrafos y textos presentes en el sitio. Web Scraping es una técnica cuyo objetivo es recolectar información de la web a través de código. En este caso se usó la biblioteca Beautiful Soup disponible en pypi.
Selección y evaluación del modelo
Modelo Bert: es un codificador bidireccional de transformers, que aprende a interpretar el lenguaje.
Cuando al modelo Bert se le añade capas adicionales y es entrenado con un propósito o tarea especializada, se obtiene un modelo Bert que resuelve una tarea en específico.
En el proyecto se aplicó ya modelos ajustados para la tarea de pregunta y respuestas, que fueron previamente ajustados mediante el dataset de los conjuntos de datos de respuesta a preguntas Stanford(SQuAD).
Ambos modelos fueron obtenidos y reutilizados de la biblioteca hugging Face Transformers. Dichos modelos reciben una pregunta y un contexto para procesarlo y analizarlo con el fin de devolver las respuestas que mejor se ajusten a la pregunta.
La elección del mejor modelo fue dado en base a los resultados:
- Bert en inglés:bert-large-uncased-whole-word-masking-finetuned-squad
- Bert en español (Beto): distill-bert-base-spanish-wwm-cased-Finetuned-spa-squad2-es

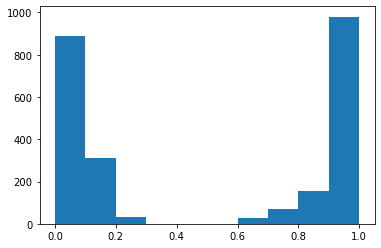
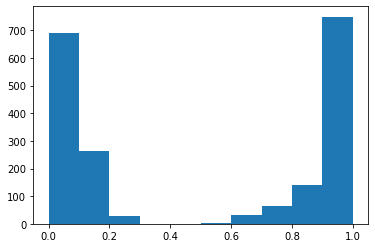
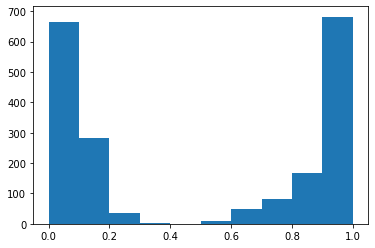
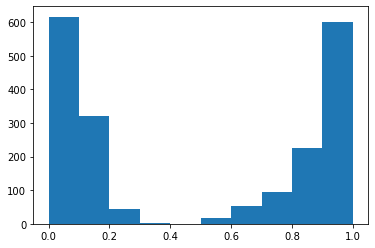
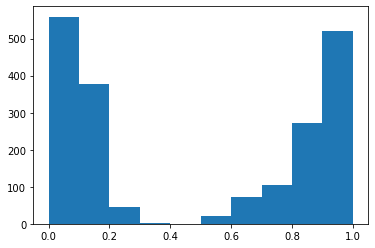
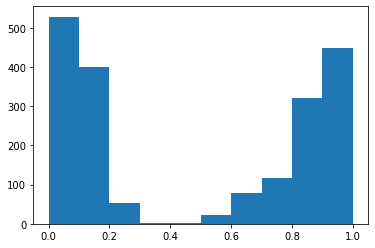
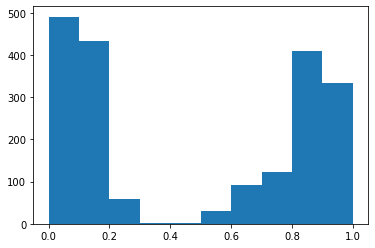
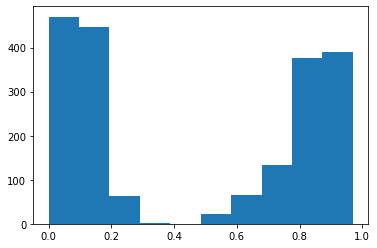
Se seleccionó y grafico un caso en específico, para demostrar como se comportan ambos modelos a una misma pregunta y cuales son las respuestas textuales que dan cada uno en su respectivo lenguaje, figura 1.
Flujo de Trabajo del Sistema
El sistema consta de distintos procedimientos para resolver una determinada pregunta, por lo que el usuario viajero debe partir lanzando una pregunta, posteriormente el sistema realiza una búsqueda con Google Search en relación a tal pregunta y devuelve unas cuantas URLs (máximo 5) con las que el web scraper realiza la tarea de extraer todo el texto (párrafos) del sitio hospedado en la URL para pasarle como contexto al modelo, el modelo utiliza el contexto, la pregunta y lanza una respuesta, se captura la respuesta y la url,ambas son representadas en formato de mensaje de chat, figura 2.
Análisis de resultados (Bert vs Beto)
Pangea devuelve las respuestas y la URLs de donde han sido obtenidas tales respuestas, según la cantidad de pruebas se puede observar que el uso de Beto se adecua más según el porcentaje de aciertos. Y en las gráficas se visualiza como el modelo Beto da respuestas con mayor precisión a la misma pregunta realizada en ambos idiomas de acuerdo al modelo.
Conclusión y recomendaciones
Las conclusiones obtenidas tras el desarrollo y resolución del objetivo general son:
- Se obtuvo un 64.7 % de respuestas correctas de un total de 17 preguntas por parte del modelo BERT en español en relación al 30% del modelo BERT en inglés, en ese sentido, el modelo BERT pre-entrenado con mayor precisión en sus respuestas es el español, ya que las preguntas tuvieron a Bolivia como contexto principal y es razonable puesto que no muchos sitios en inglés tienen información actualizada y específica de Bolivia.
- La técnica del Web Scraping aportó correctamente el contenido web necesario para que el modelo BERT pudiese responder las preguntas adecuadamente.
- Dado que el servicio (Pangea) se desplegó por un momento se logró registrar el uso de 2.5 GB de memoria RAM con una demora de aproximadamente 30 segundos mientras el modelo responde a la pregunta.
- El Servicio Web que se ofreció por unos instantes logró capturar la curiosidad y asombro de los usuarios por su diseño minimalista e interesante forma de interactuar.
Por otra parte las recomendaciones al respecto son:
- El modelo BERT empleado fue afinado (fine-tuning ) con el dataset SQUAD el cual tiene un formato pregunta-respuesta de dominio parcialmente general, por lo que se tiene mayores expectativas con un afinado específico para el área de turismo.
- La información recolectada por el servicio proviene de Google que es un motor de búsqueda, el sistema funcionaría mucho mejor y tendría una mayor calidad en sus respuestas si el motor de búsqueda y los datos que en él residen fueran recolectados cautelosa y selectivamente.
- Como Pangea se centra en el servicio para viajeros y turistas, es recomendable incrementar distintos modelos BERT en varios lenguajes.
Autores del proyecto
- Ana Paola Céspedes Sejas
- Mauricio Serginho Matias Conde
«Equipo ElementAxiom»
Referencias
Google search, https://pypi.org/project/googlesearch-python/
Beautifulsoup, https://pypi.org/project/beautifulsoup4/
Modelo Bert en español, https://huggingface.co/mrm8488/distill-bert-base-spanish-wwm-cased-finetuned-spa-squad2-es
Modelo Bert en inglés, https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squadSaturdays.AI
WRITTEN BY
Ana Paola Cespedes Sejas

Presentación del proyecto: DemoDay
¡Más Inteligencia artificial!
La misión de Saturdays.ai es hacer la inteligencia artificial más accesible (#ai4all) mediante cursos y programas intensivos donde se realizan proyectos para el bien (#ai4good).
Infórmate de nuestro master sobre inteligencia artifical en https://saturdays.ai/master-ia-online/
Si quieres aprender más inteligencia artificial únete a nuestra comunidad en community.saturdays.ai o visítanos en nuestra web www.saturdays.ai ¡te esperamos!
Saturdays.AI
Saturdays.AI is an impact-focused organization on a mission to empower diverse individuals to learn Artificial Intelligence in a collaborative and project-based way, beyond the conventional path of traditional education.